导读
本文会做一个简单的智能体,说明 LangGraph 和 LangSmith 的基本使用,有基础概念,有完整的基础实践部分,保姆级教程,帮助想学习智能体开发的前端开发人员一步一步创建一个属于自己的智能体。
基础概念
什么是 LangGraph
LangGraph 是由 LangChain 团队开发的一个用于构建复杂、多 Agent(智能体)以及有状态(Stateful)环形逻辑应用的开源框架。
如果说标准的 LangChain 擅长处理线性的、链式 的步骤(A → B → C),那么 LangGraph 就是为了处理复杂的、有循环的、图状(Graph)的交互逻辑而生的。
核心痛点:为什么需要 LangGraph?
在构建先进的 AI 应用(尤其是 Agent)时,我们经常需要让 LLM 进行自我反思、纠错或循环迭代。
例如:写代码 → 运行测试 → 报错 → 将错误塞回给 LLM 修复 → 重新测试。
传统的 LangChain 链式结构很难优雅地处理这种"回头路",代码会变得极其臃肿。LangGraph 将这种逻辑抽象为"图(Graph)",完美解决了以下问题:
- 支持循环(Cycles): 允许 Agent 在满足特定条件前,反复执行某个步骤。
- 内置状态管理(State Management): 自动在图的各个节点之间传递、维护并持久化上下文状态。
- 人类介入(Human-in-the-loop): 原生支持在某个节点暂停,等待人工审批或修改后继续运行。
LangGraph 的三大核心概念
LangGraph 的设计完全基于图论,主要由以下三个要素构成:
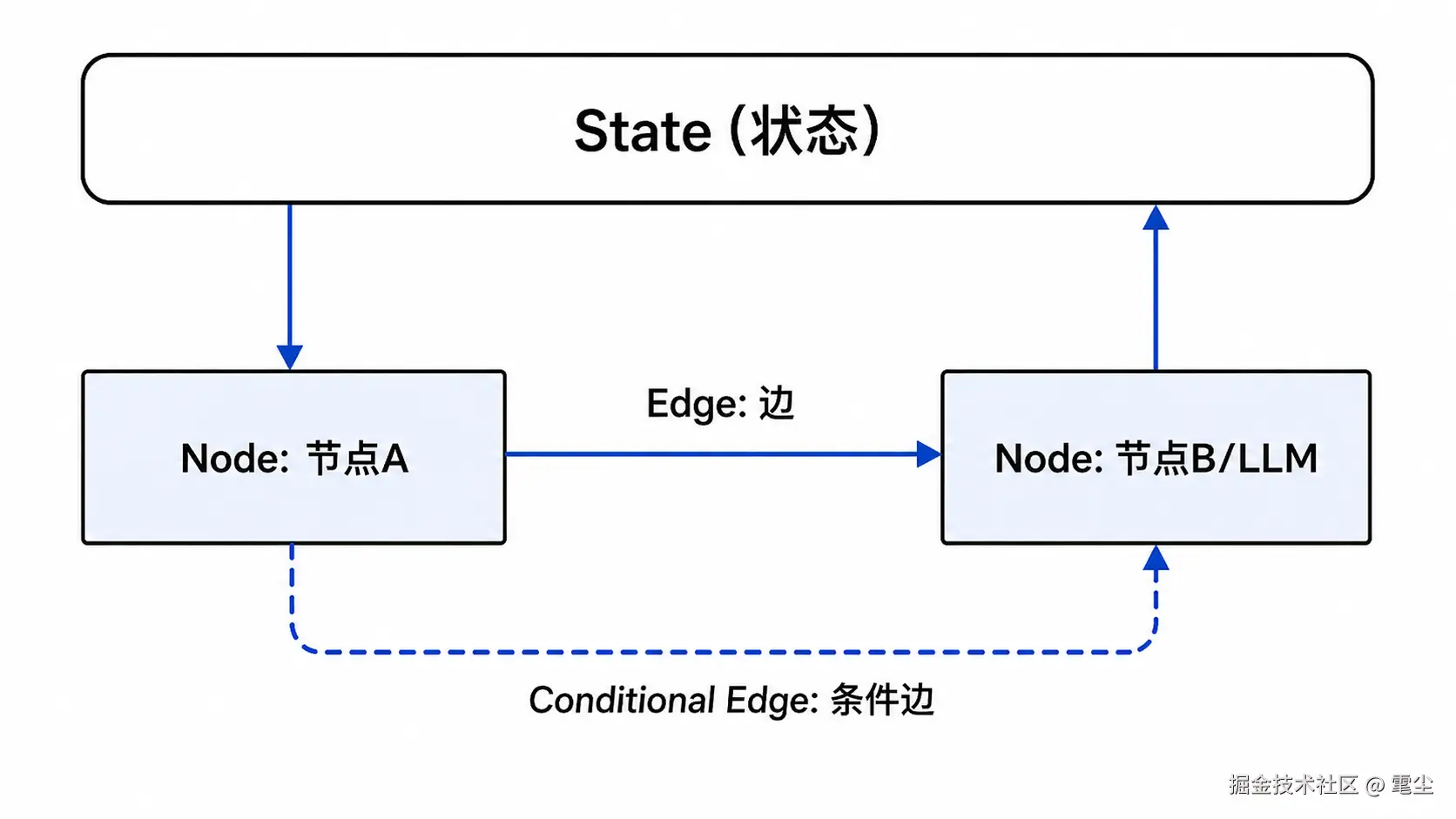
1. State (状态)
图的全局上下文与"单一数据源"。 在 JS 中,它是一个通过 Annotation.Root 定义的强类型对象(或 TS 接口),代表应用运行时的所有记忆。图中的节点不能直接修改全局变量,而是通过返回一个新对象来提交增量更新。框架内置了 reducer 机制,会自动将新数据与原状态进行合并(例如将新消息追加到历史数组中)。
2. Nodes (节点)
图中的具体执行单元。 本质上是一个 JavaScript 异步函数(async function)或 LangChain 的 Runnable 对象。每个节点代表一个具体步骤(如调用 LLM、读写数据库、发起 fetch 请求)。它接收当前的 State 作为输入,执行完业务逻辑后,返回一个包含更新字段的 JS 对象,以此触发状态更新并驱动流程进入下一步。
3. Edges (边)
定义节点之间的控制流与状态流转方向。 它决定了应用如何从一个步骤走向下一个步骤,分为两种:
- 普通边: 无条件连接。使用
.addEdge()明确指定节点 A 执行完后,百分之百直接进入节点 B。 - 条件边: 动态路由。使用
.addConditionalEdges()绑定一个 JS 路由函数。该函数会读取当前State(例如检查 LLM 是否提出了工具调用请求),并返回一个标签,图会根据这个标签动态决定下一步是去调用工具还是直接结束流程。
典型应用场景
- RAG 纠错流(Corrective RAG): 检索出文档后,先让节点 A 评估文档相关性。如果不相关,流转到节点 B 重新生成查询关键词;如果相关,再流转到节点 C 生成回答。
- 多智能体协作(Multi-Agent Teams): 定义多个 Node,每个 Node 代表一个拥有不同 Prompt 和工具的专业 Agent(如:调研员、作家、审核员),它们通过共享的 State 协同完成一个复杂任务。
- 长流程审批系统: AI 生成方案 → 触发条件边暂停 → 等待人类前端确认/修改 → 汇入状态继续执行后续部署。
什么是 LangSmith
简单来说,LangSmith 是由 LangChain 团队推出的一款专门针对大语言模型(LLM)应用和 AI Agent(智能体)的生产级开发者平台。
如果说 LangChain/LangGraph 是帮你把 AI 应用"组装"出来的骨架,那么 LangSmith 就是给这个应用装上的高精雷达、黑匣子和监控仪表盘 。它解决了大模型开发中最大的痛点:黑盒状态、不可控、难以调试和难以评估。
其核心功能与价值主要集中在以下四个核心场景:
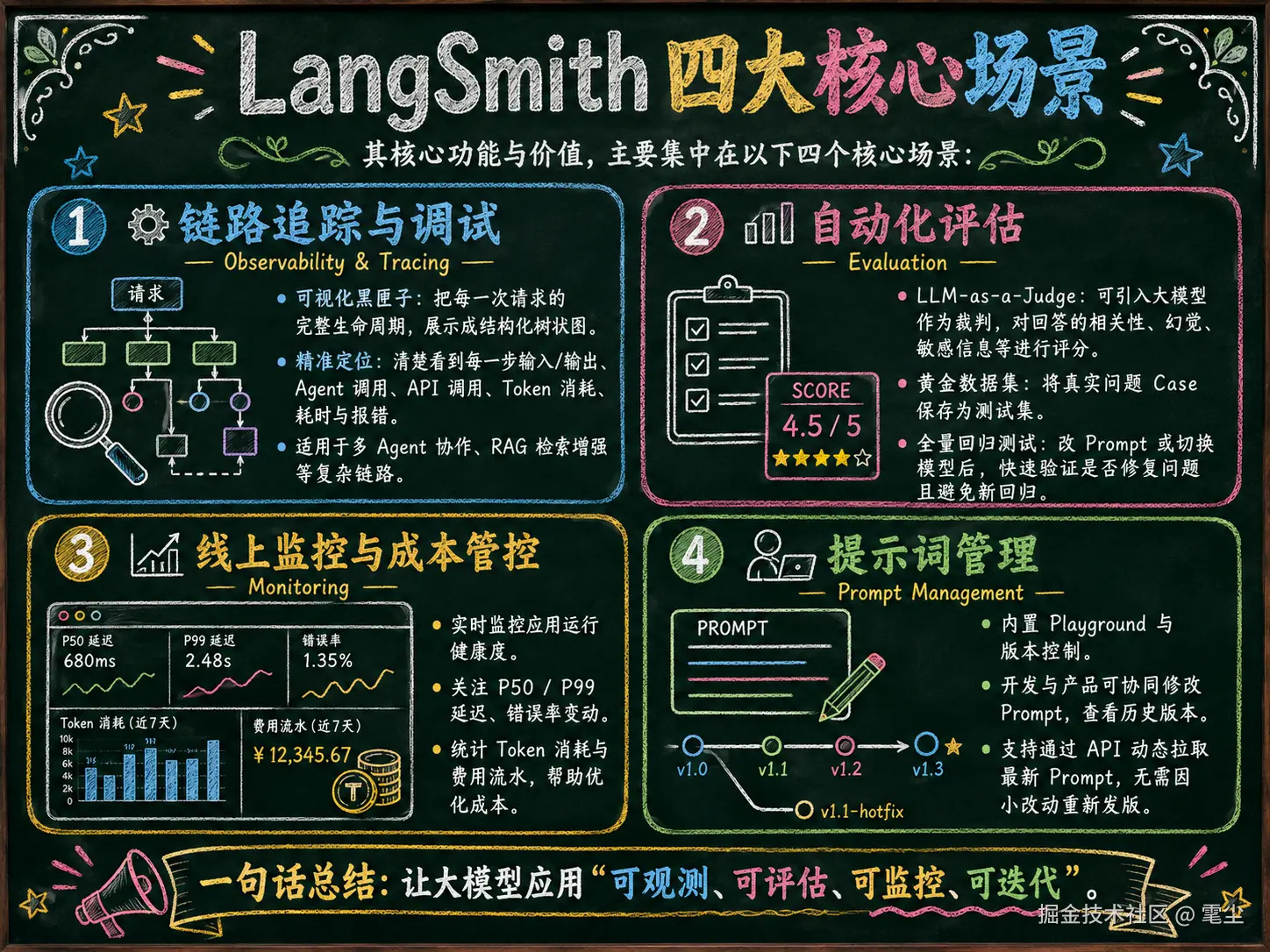
1. 核心功能矩阵
⚙️ 链路追踪与调试(Observability & Tracing)
大模型应用(尤其是多 Agent 协作或 RAG 检索增强架构)的内部执行往往嵌套非常深。一个简单的用户问题,背后可能触发了 3 次检索、2 次工具调用和 4 次 LLM 思考。
- 可视化黑匣子:LangSmith 可以把每一次请求的完整生命周期变成一张结构化的树状图。
- 精准定位:你可以清晰地看到每一步输入了什么、输出了什么、哪个 Agent 调用了哪个 API、花了多少 Token、哪一步耗时最长(延迟瓶颈)或报了什么错。
对比 js 来说,如果 LangGraph 是 redux,LangSmith 就是 # Redux DevTools,可以清楚的看到每个状态是怎么流转的。
📊 自动化评估(Evaluation)
传统的软件测试靠断言(Assertion),但大模型的输出是生成式的,很难用绝对的对错来衡量。
- LLM-as-a-Judge:支持引入另一个大模型来当"裁判",线上实时或线下批量给应用的回答打分(例如评估相关性、是否有幻觉、是否包含敏感信息)。
- 黄金数据集(Datasets) :你可以把生产环境中报错的真实 Case 一键保存为测试集,在修改提示词(Prompt)或更换模型后进行全量回归测试,防止改好 A Bug 却引发 B Regressions。
📈 线上监控与成本管控(Monitoring)
应用上线后,你需要掌握整体的运行健康度。
- LangSmith 提供开箱即用的仪表盘,实时监控 P50/P99 延迟 、错误率变动 、以及最关心的 Token 消耗与费用流水。
🧑💻 提示词管理(Prompt Management)
- 提供内置的 Prompt 游乐场(Playground)和版本控制中心。开发团队和产品经理可以在平台上协同修改提示词,查看历史版本,并直接通过 API 动态拉取最新的提示词,无需因为改个字而重新打包发布代码。
2. LangSmith Engine 的最新演进
平台引入了更深度的 LangSmith Engine(智能体引擎) ,将原先人工看日志、写测试的链路进一步自动化:
- 自动聚类纠错:它会自动分析线上成千上万条 Trace,把相似的错误(比如某个工具描述模糊导致模型频繁调错)聚类成一个 Issue。
- 自动提 PR :如果绑定了代码仓库,它甚至能结合上下文自动生成修复提示词或代码的 Pull Request,并为你配置好防止该错误再犯的线上评估器。
3. 常见误区与生态协同
💡 核心误区澄清:
- 不绑定 LangChain:虽然是同一家公司的产品,但 LangSmith 是**框架无关(Framework-Agnostic)**的。无论你用的是原生的 OpenAI / Anthropic SDK,还是 Vercel AI SDK、LlamaIndex,甚至是自己纯手工用 Python/TypeScript 写的业务代码,只要接入其 SDK 或支持 OpenTelemetry,都能完美打上 Trace。
-
开发流程定位:
LangChain / LangGraph (构建)⟶LangSmith (调试、评估、监控)
如果你正在组建团队开发复杂的 AI 业务、频繁遇到大模型"乱说话/乱调工具"却找不到根因,或者正为线上高昂的 Token 账单与不稳定的响应速度发愁,LangSmith(或者同赛道的 Langfuse、Arize Phoenix 等)是生产环境必不可少的基建工具。
开发实践
1.新建工程项目,导入 LangGraph 相关依赖
bash
mkdir langgraph-agent-demo
cd langgraph-agent-demo
pnpm add @langchain/community @langchain/core @langchain/deepseek @langchain/langgraph @langchain/tavily dotenv| 库名 | 说明 |
|---|---|
@langchain/core |
LangChain 的底层核心,定义模型、链、工具等标准接口 |
@langchain/community |
社区维护的各种工具集(向量库、文档解析、第三方集成) |
@langchain/deepseek |
让 LangChain 能调用 DeepSeek 大模型(如 V3 / Coder) |
@langchain/langgraph |
用来编排多步骤、有状态的 AI 工作流和 Agent |
@langchain/tavily |
给 AI 用的实时搜索工具,用来查最新互联网信息 |
dotenv |
读取 .env文件,管理 API Key 等环境变量 |
例子里面大模型使用的是 deepseek 的库,如果你想用别的,如 OpenAI,改成 @langchain/openai 就行了
2. 在环境变量填好相关的 APIKey
新建 .env 文件,填入你的 APIKey:
js
export DEEPSEEK_API_KEY="你的 DeepSeek apikey"
export TAVILY_API_KEY="你的 tavily apikey"deepseek APIKey 获取地址:platform.deepseek.com/api_keys tavily APIKey 获取地址:app.tavily.com/home
注意:
.env要写入.gitignore中,避免密钥泄露。
3. 编写智能体代码
新建 agent.mts 文件,粘贴如下代码:
ts
import "dotenv/config";
import { TavilySearch } from "@langchain/tavily";
import { ChatDeepSeek } from "@langchain/deepseek";
import { MemorySaver, StateGraph, MessagesAnnotation, START } from "@langchain/langgraph";
import { ToolNode, toolsCondition } from "@langchain/langgraph/prebuilt";
// 定义智能体(Agent)要使用的工具
const agentTools = [new TavilySearch({ maxResults: 3 })];
// 将工具绑定到模型上,以便模型知道它可以调用这些工具
const agentModel = new ChatDeepSeek({ temperature: 0, model: "deepseek-v4-flash" }).bindTools(agentTools);
// 定义调用模型的节点函数
const callModel = async (state: typeof MessagesAnnotation.State) => {
const response = await agentModel.invoke(state.messages);
// 返回一个包含 "messages" 列表的对象。
// MessagesAnnotation 的 reducer 会自动将这些新消息追加到状态历史中。
return { messages: [response] };
};
// 定义状态图(State Graph)
const workflow = new StateGraph(MessagesAnnotation)
.addNode("agent", callModel)
.addNode("tools", new ToolNode(agentTools))
.addEdge(START, "agent")
.addConditionalEdges("agent", toolsCondition)
.addEdge("tools", "agent");
// 初始化内存以在多次图运行之间持久化状态(记忆)
const agentCheckpointer = new MemorySaver();
// 将工作流编译为带检查点的可运行智能体
export const agent = workflow.compile({ checkpointer: agentCheckpointer });关键代码就在于 new StateGraph...,通过增加节点、边和条件边完成整个 Agent 运行的编排,而 MessagesAnnotation 就是整个运行过程中的传递的状态。 节点名称可以自定义("agent"、"tools")只要在 addNode 和 addEdge 中前后呼应即可。
4. 增加测试文件,测试运行效果
新增 test.mts 文件,粘贴如下代码:
ts
import "dotenv/config";
import { HumanMessage } from "@langchain/core/messages";
// 动态导入 agent,避免触发完整编译链
const { agent } = await import("./agent.mts");
// 测试智能体
const agentFinalState = await agent.invoke(
{ messages: [new HumanMessage("北京目前的天气怎么样?")] },
{ configurable: { thread_id: "42" } },
);
console.log(
agentFinalState.messages[agentFinalState.messages.length - 1].content,
);
const agentNextState = await agent.invoke(
{ messages: [new HumanMessage("珠海呢?")] },
{ configurable: { thread_id: "42" } },
);
console.log(
agentNextState.messages[agentNextState.messages.length - 1].content,
);运行命令:
bash
pnpx tsx test.mts成功运行: 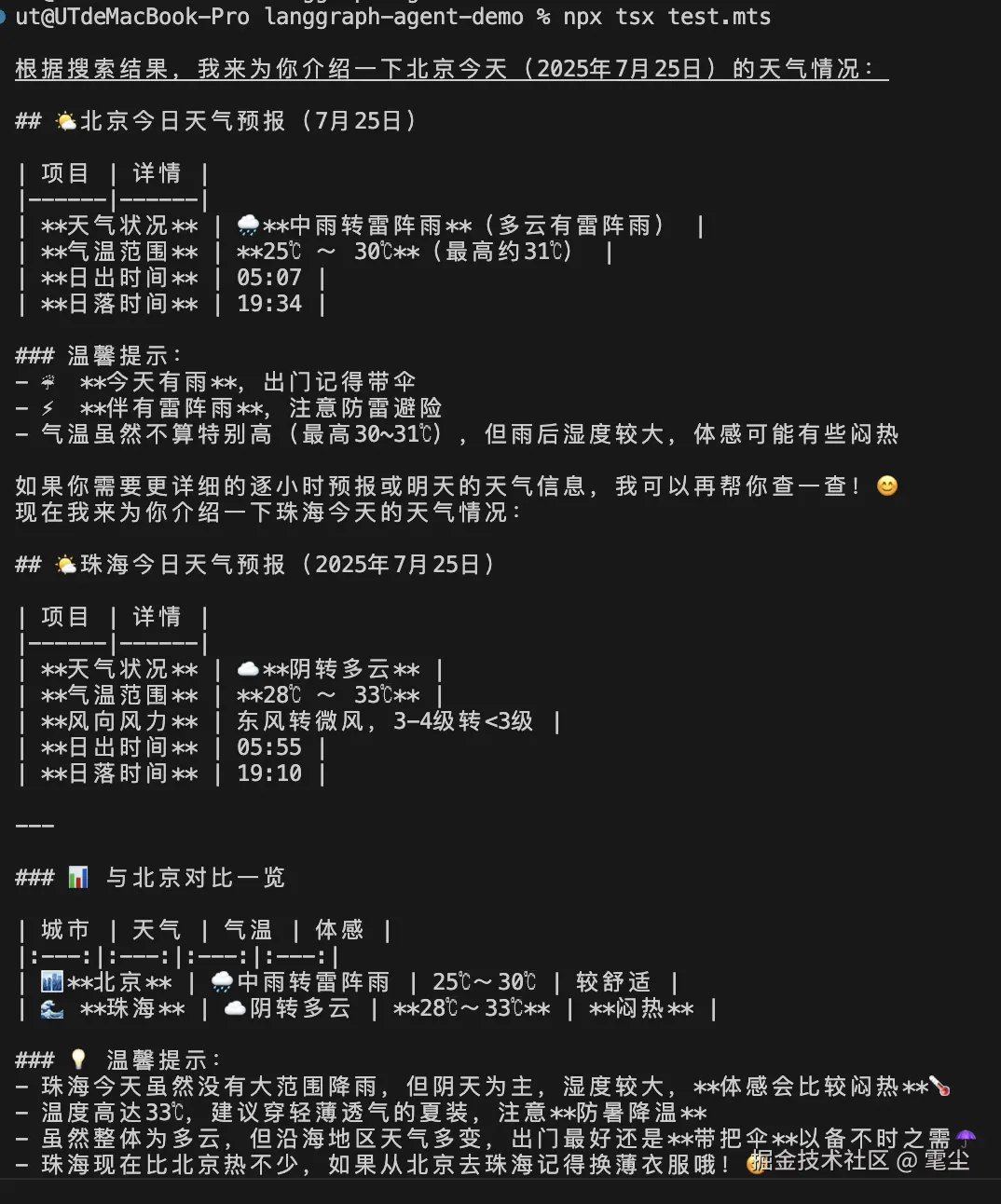
但是这里有一个问题,今天的日期不对,原因是在查询的时候并没有告诉大模型今天是什么时间,大模型只能根据预训练的数据去查询,晚点修复这个问题。
5. 加入 LangSmith
LangSmith 和 LangGraph 是一家公司出的,所以生态衔接非常好,几行代码和命令就可以完成。
1. 添加 LangSmith 依赖:
bash
pnpm add langsmith2. 在 .env 文件中加入配置和 APIkey
js
// 你的LangSmith apikey
export LANGSMITH_API_KEY="你的LangSmith apikey"
// 开启追踪
export LANGSMITH_TRACING="true"
// 项目名称,自定义
export LANGSMITH_PROJECT="weather-search-agent"LangSmith apikey 获取地址:smith.langchain.com/o/0eafdba3-...

点设置,新增一个 apikey,复制过来填入即可。
3. 测试一下,重新运行测试代码
pnpx tsx test.mts然后在 Tracing 标签页面就可以看到你新建的项目数据:
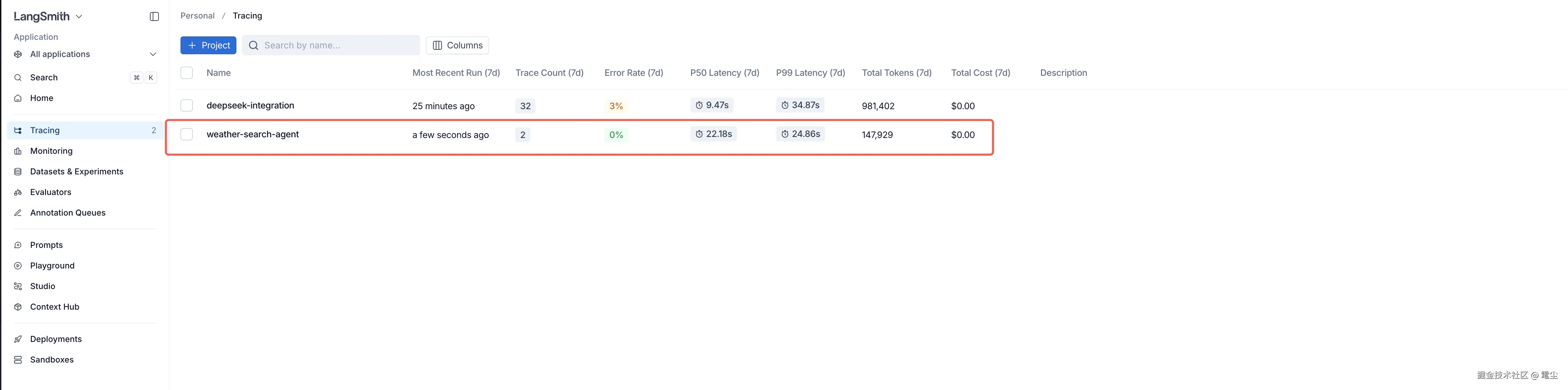
点进去,可以看到记录详情,因为一次测试会运行两次调用,所以会有两条记录: 
再点击具体记录进入,就可以看到,每次执行的时候,具体调用的详情,包括工具调用,大模型返回等:
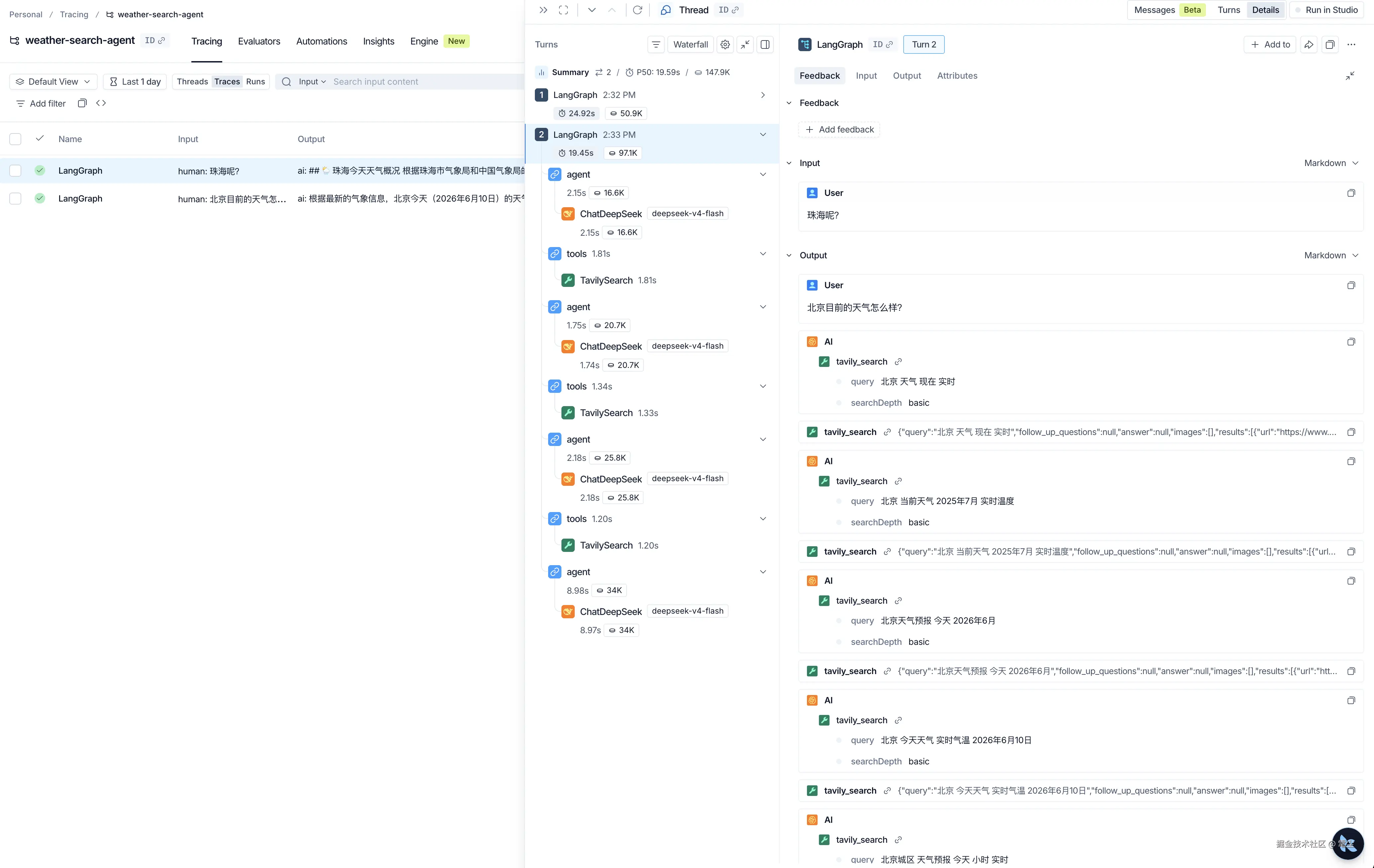
6. 接入 LangSmith Studio
LangSmith 还有一个功能,可以可视化看你的 Agent 编排流程图,运行情况,还可以直接在线调试。这个功能就叫 LangSmith Studio。现在我们来看看具体怎么接入和使用。
1. 修改 package.json:
diff
{
+ "scripts": {
+ "dev": "pnpx @langchain/langgraph-cli dev",
+ "test": "pnpx tsx test.mts"
+ },
"dependencies": {
"@langchain/community": "^1.1.29",
"@langchain/core": "^1.1.48",
"@langchain/deepseek": "^1.0.27",
"@langchain/langgraph": "^1.3.7",
"@langchain/tavily": "^1.2.0",
"dotenv": "^17.4.2",
"langsmith": "^0.7.5"
},
"devDependencies": {
"@types/node": "^25.9.2",
"typescript": "^6.0.3"
}
}2. 新建配置文件,粘贴如下内容:
json
{
"dependencies": ["."],
"graphs": {
"my_agent": "./agent.mts:agent"
},
"env": "./.env"
}这里 ./agent.mts:agent 冒号后面的名称要和你对应代码文件导出 Agent 变量名保持一致。
我这里的代码对应的是这一行,所以是 agent: export const agent = workflow.compile({ checkpointer: agentCheckpointer });
3. 运行服务
pnpm dev 成功运行,会自动打开网页:
成功运行,会自动打开网页: 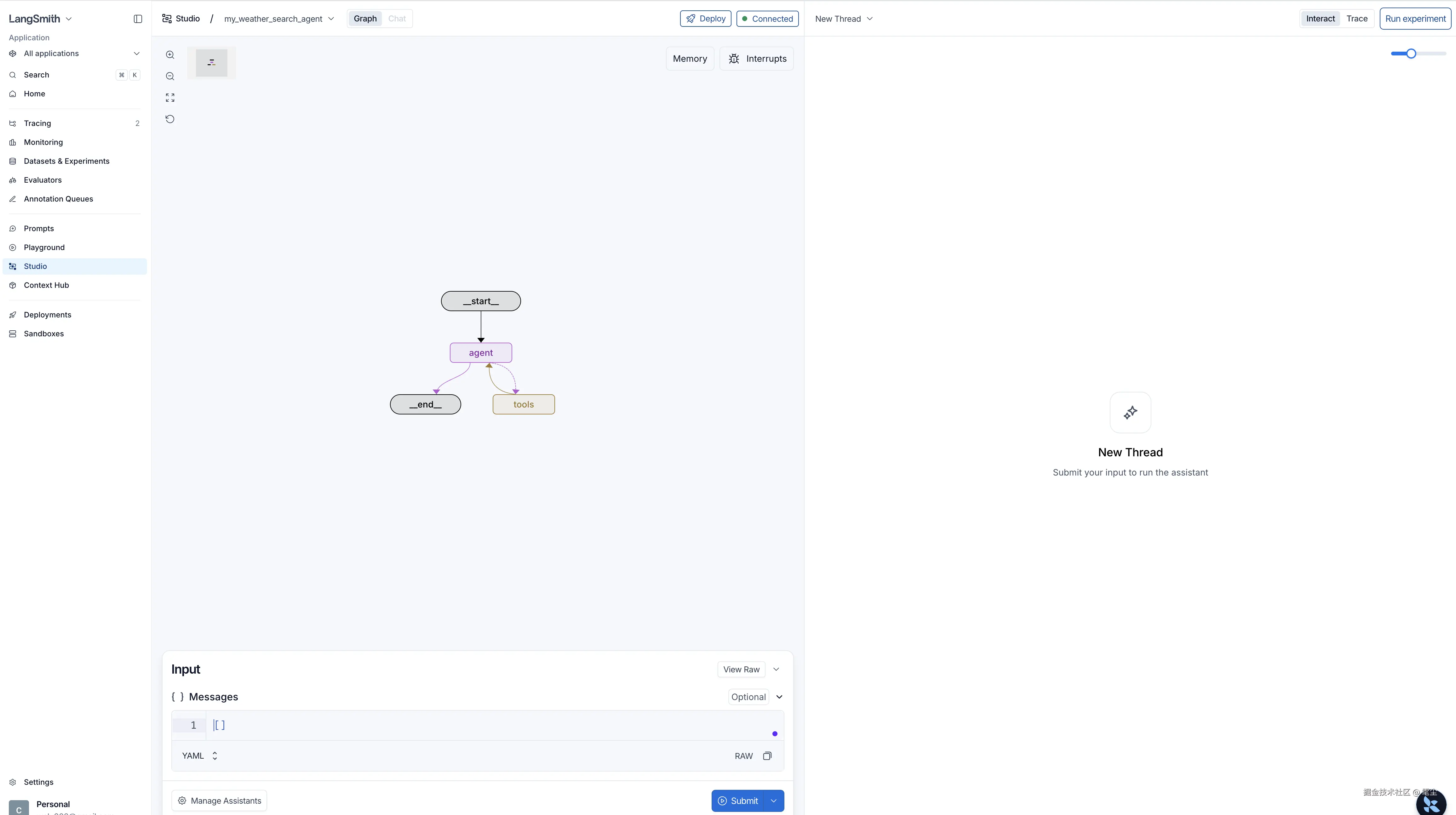
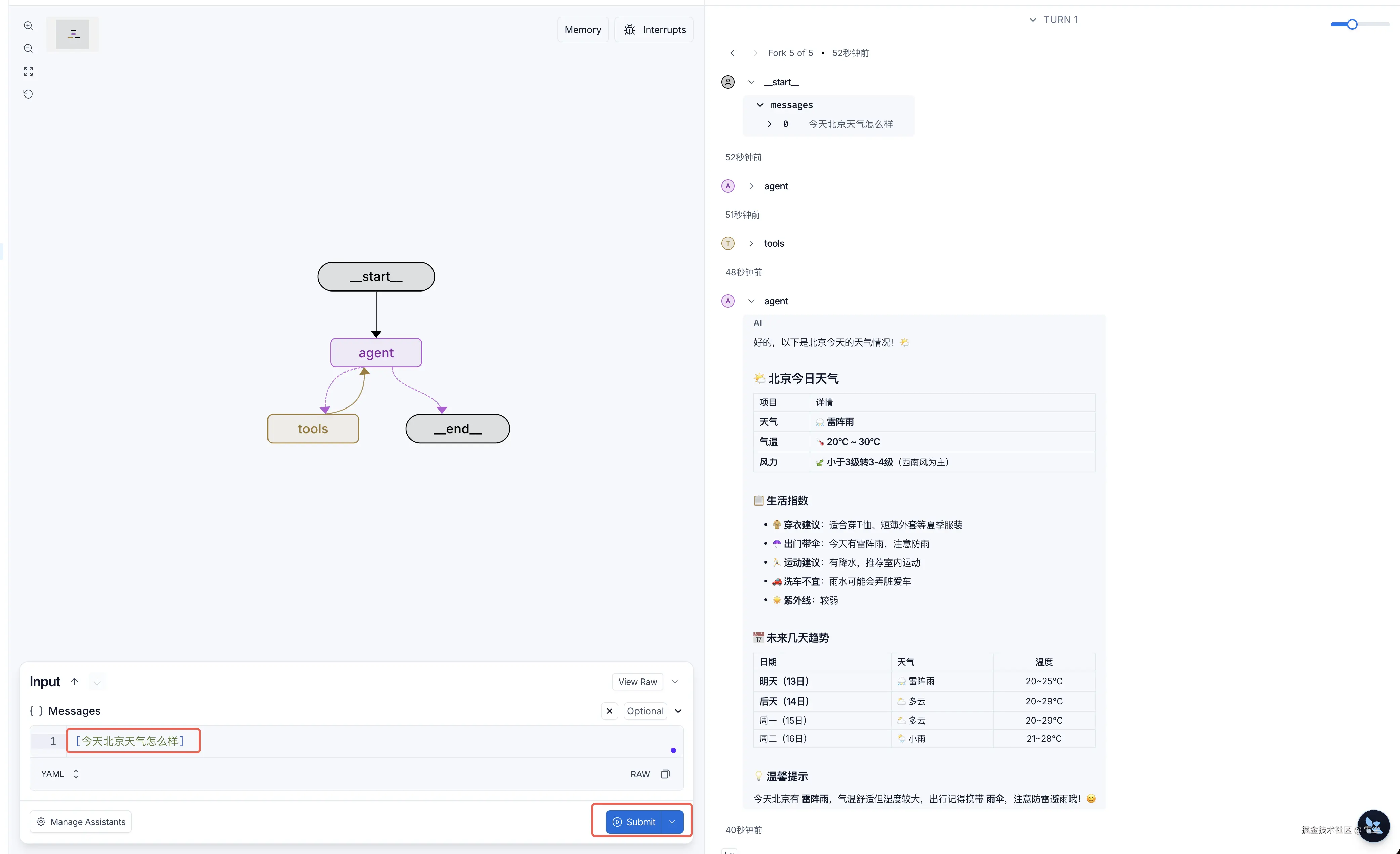
4. 在线调试
输入问题,回车即可监控运行情况:
5. 时间问题修复
现在我们来修复一下判断今天时间不对的问题,我们要新增一个工具,让大模型自动调用获取当前时间。
修改 agent.mts 代码:
ts
import { DynamicTool } from "@langchain/core/tools";
const getCurrentDate = new DynamicTool({
name: "get_current_date",
description: "获取当前日期。当用户询问\"今天\"、\"当前\"、\"现在\"等涉及时间的问题时,调用此工具获取准确的当前日期。",
func: async () => {
const now = new Date();
const year = now.getFullYear();
const month = String(now.getMonth() + 1).padStart(2, '0');
const day = String(now.getDate()).padStart(2, '0');
const weekdays = ['星期日', '星期一', '星期二', '星期三', '星期四', '星期五', '星期六'];
const weekday = weekdays[now.getDay()];
return `今天是 ${year}年${month}月${day}日 ${weekday}`;
},
});
// 定义智能体(Agent)要使用的工具
const agentTools = [getCurrentDate, new TavilySearch({ maxResults: 3 })];重新运行 pnpm dev,再重新提问,就可以看到,现在的回答大模型会自动判断,先调用工具获取时间,然后再调用搜索获取天气情况:
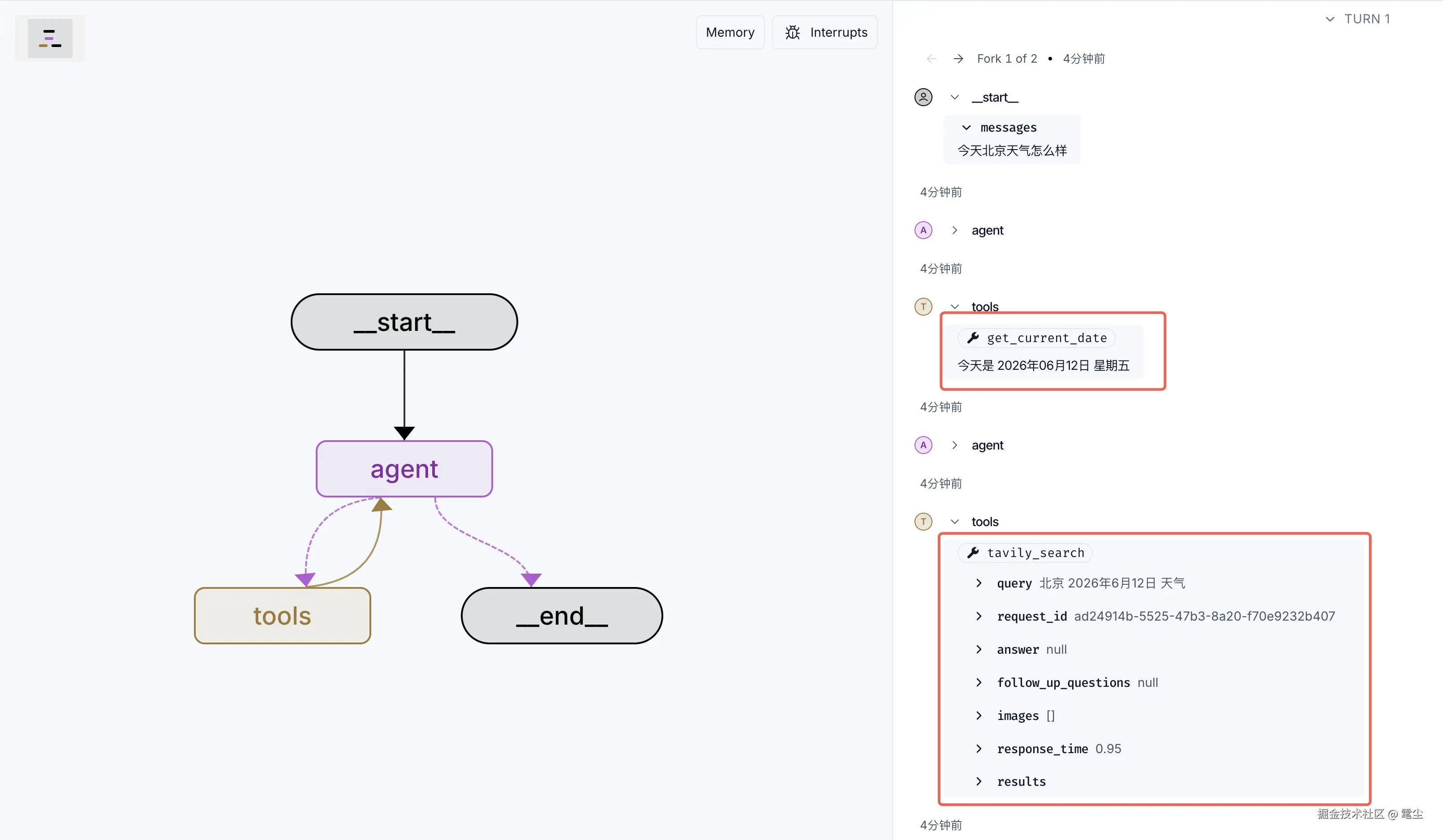
👌问题修复。
总结
通过本文的保姆级教程,我们从零开始,成功使用 LangGraph 和 LangSmith 构建并调试了一个具备实时搜索与时间感知能力的智能体(Agent)。
回顾整个开发流程,智能体的开发核心逻辑清晰可见:
- LangGraph 赋予了 Agent"骨架与大脑" :通过状态(State)、节点(Nodes)和边(Edges)的图状编排,让大模型打破了传统的线性逻辑,能够根据业务场景自由地进行循环迭代 与条件路由。
- LangSmith 赋予了 Agent..."雷达与后盾" :它完美充当了 AI 领域的"黑匣子"与调试神器,让嵌套极深的工具调用链路、Token 消耗以及状态流转变得一目了然。
- 自主扩展工具(Tools) :当遇到大模型的时间感知缺陷时,我们通过自定义
DynamicTool轻松为其扩展了"获取当前时间"的超能力,展示了如何通过工具增强智能体的业务边界。
迈向下一步: 本篇实践只是智能体开发的起点。在此基础之上,你可以尝试为智能体加入人类介入审批(Human-in-the-loop) 、接入更复杂的知识库(RAG) ,或是构建一个多智能体协作(Multi-Agent)的复杂工作流。
掌握了图结构编排与全链路追踪,你就已经拿到了开启下一代 AI 应用开发的钥匙。赶快动手,创造出属于你的高效智能体吧!