一,Create 新增
语法:
sql
insert [into] table_name [(column [,column]...)]
values(values_list) [,(values_list)]...SQL中表示字符串,可以使用" "或者' '
use java02;
show tables;
create table student(id int,name varchar(20),gender varchar(1));
insert into student values (1,'张三','男');
select * from student;当执行**insert into student values ('100',1,'男');**的时候可以插入成功,因为SQL中存在"类型转换",即使values后面写的值,类型上不是严格匹配,但是mysql会尽量尝试进行转换,如果转换失败就会报错,如果转换成功就可以插入
因此,SQL这样的语言,称为"弱类型"的编程语言
1.1实例
sql
create table users(
id bigint,
name varchar(20) comment '用户名'
);1.1 .1单行数据全列插入
insert into 表名(部分列名,部分列名,...) values (值,值,...);
sql
insert into users values(1,'张三');1.1.2 单行数据指定列插入
value_list中的值必须和定义表的列的数量及顺序一致
sql
insert into users(id,name) values(3,'王五');
select* from users;1.1.3 多行数据指定列插入
在一条insert语句中也可以指定多个value_list,实现一次插入多行数据
insert into 表名 values (),(),()...
sql
insert into users(id,name) values (4,'赵六'),(5,'钱七');二,查询
2.1 全列查询
全列查询:把一个表的所有行/列都查询出来
语法:select* from 表名;
*是通配符,通配符可以代表各种信息,此处的select*的*代表所有的列
注意:全列查询是一个非常危险的操作
因为全列查询会把表中所有数据都查询出来,涉及到大量的硬盘访问和网络访问
2.2 指定列查询
select列名,列名...from 表名;
例如,查询所有人的编号,姓名和语文成绩
sql
select id,name from users;比如一共几十个列,只需要用到3个列,只指定这三个列即可,能给服务器降低很大的负担
注意:查询结果得到的列是一个"临时表",不能对这个临时表做出任何修改
在select后面的查询列表中指定希望查询的列,可以是一个也可以是多个,中间用逗号隔开
指定列的顺序与表结构中的列的顺序无关
2.3 查询时带有表达式
一边查,一边进行一些计算
eg:把所有人的语文成绩都加10分
select name,chinese +10 from exam;
此时查询得到的结果也是一个临时表,对临时表进行的操作不会影响到数据库服务器硬盘中的原始数据
++所有的select都不影响数据库服务器保存的原始数据++
2.3.1 常量表达式
表达式本身就是一个常量
sql
select id,name,10 from exam;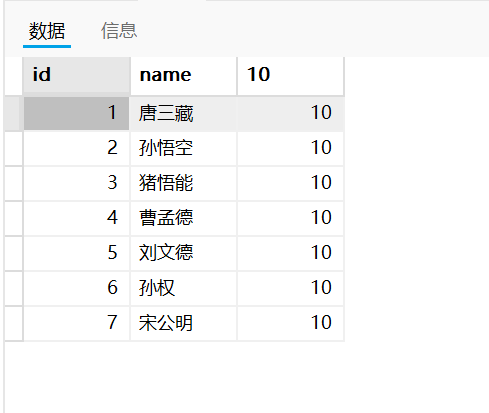
也可以是常量的运算
sql
select id,name,10+1 from exam;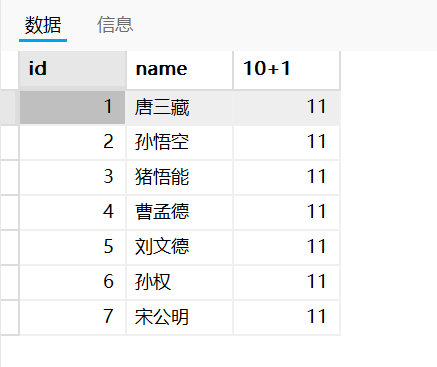
把所有同学的语文成绩加10分
sql
select id,name,chinese + 10 from exam;生成的表是临时表,对临时表进行的操作,不会影响到数据库服务器硬盘中的原始数据
计算所有学生语文,数学和英语成绩的总分
sql
select id,name,chinese + math + english from exam;2.4 查询带有别名
语法:select 表达式 as 别名 from 表名;
(as可以省略,但是不建议省略)
sql
select id,name,chinese+math+english as 总分 from exam;2.5 针对查询结果去重
语法:select distinct 列名 from 表名;
把多个相同的值,合并成一个
当指定多个列去重的时候,必须要求多个列都是相同的值,才能去重
eg:select distinct name ,math from exam;
在这个代码中就要求name和math都相同的时候才会去重
2.6 where条件查询
根据查询条件,对于要查询的行,进行筛选------
条件成立,这一行作为查询结果,如果不成立,这一行就跳过
2.6.1 比较运算符
|---------------|--------------------------------------------|
| 运算符 | 说明 |
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,对于NULL的比较不安全,比如NULL=NULL结果还是NULL |
| <=> | 等于,对于NULL的比较是安全的,比如NULL<=>NULL结果是true(1) |
1,SQL把NULL视为false
2,SQL拿别的值和NULL进行运算,结果还是NULL
eg:chinese > null 结果是null
列名 <=>NULL和列名 is NULL都可以,区别就是第一个可以列名1<=>列名2来比较两个
|-------------------------|---------------------------------------------|
| !=,<> | 不等于 |
| value between a0 and a1 | 范围匹配 |
| value in(option,...) | 如果value在option列表中,则返回true |
| is NULL | |
| is NOT NULL | |
| LIKE | 模糊匹配,%表示任意多个(包括0个)字符; _表示任意一个字符,NOT LIKE则相反 |
2.6.2 逻辑运算符
and,or,not
)别名不能在条件中使用
eg:select name,chinese + english + math as total from exam where total < 200;
这行代码的执行顺序是:
1,先遍历表
2,取出表的每个行,代入条件------使用了别名
3,把符合条件的行筛选出来
4,根据select后面指定的表达式进行计算------定义的别名
可以看出,在别名还未定义之前就使用了别名
也不可以把as total放在where的后面,因为where这里不允许定义别名
注意:and和or中and优先级比or的优先级要高,但是更建议用()手动定义优先级
2.7 模糊查询
like搭配通配符
%代表任意个任意字符
_代表一个任意字符
like模糊匹配功能有限
查询所有姓孙的同学
sql
select * from exam where name like '孙%';查询姓孙且名字只有两个字的同学
sql
select * from exam where name like'孙_';2.8 排序查询
排序查询即针对查询结果排序
一条记录有多个列,排序的时候需要取其中的一个列,或者几个列(需要明确优先顺序),来作为比较的依据
语法:select 列名 from 表名 order by 列名,列名...;(放在前面的列名优先级更高)
(根据此处的查询结果进行排序,默认是升序排序,也可以写asc显示指定升序,asc可以省略)
可以通过desc指定降序排序
order by的时候,空值视为最小的
排序查询,也是针对"临时表"操作的,不影响数据库服务器硬盘上存储的原始数据...
如果一个SQL没有指定order by ,此时意味着查询结果的顺序是"未定义的"
order by可以使用别名作为排序顺序:select name,Chinese+math as total from exam order by total desc;
order by 执行顺序是在表达式计算之后的,别名先定义出来了,然后才运行到order by
2.9 分页查询
语法:select 列名 from 表名 where 条件 order by 列名 limit N;
select 列名 from 表名 where 条件 order by 列名 limit start,num;
select 列名 from 表名 where 条件 order by 列名 limit num offset start;
limit 字句来实现分页查询,获取到前N条数据
limit N offset M 描述了从第M条记录开始,往后获取N条记录~
offset称为"偏移量"相当于"数组下标"
并不存在"下标越界"的情况,最多就是得到"空的结果"
三,修改操作
update 表名 set 列名 = 值 where 条件 order by 列名 limit N;
此时,修改的不是临时表,而是修改数据库服务器硬盘上的原始数据了
//将总成绩倒数前三的三位同学的数学成绩加上30分
sql
update exam set math = math + 30 where chinese+math+english is not null order by chinese + math + english asc limit 3;四,删除操作
delete from 表名 where 条件 order by 列名 limit N;
通过后面的条件等子句限定要删除哪些内容,如果不写条件,就会删除所有数据,最终得到一个空的表
drop table;这个操作是连表都没有了
五,截断表
truncate table tbl_name;
更快速的"清空表"的一个方式,delete的方式删除,本质上是一条一条的删
数据比较多,会删除的慢
截断表只能对整张表操作,不能像delete一样针对部分数据
不对数据操作所以比delete快,truncate在删除数据表的时候,不经过真正的事物,所以无法回滚
会重置auto_increment项
六,插入查询结果
insert into 表名 select 列名 from 表名...
把查询的结果,插入到另一个表里
例如:insert into student2 select*from 表名......
后面查询出来的列数和类型要和前面插入的表的结构相匹配,列的名字是不需要匹配的
6.1 实例
sql
CREATE TABLE t_recored (id int, name varchar(20));
INSERT INTO t_recored VALUES
(100, 'aaa'),
(100, 'aaa'),
(200, 'bbb'),
(200, 'bbb'),
(200, 'bbb'),
(300, 'ccc');
select * from t_recored;6.1.1 删除表中的重复记录,重复的数据只能有一份
实现思路:原始表中的数据一般不会主动删除,但是真正查询时不需要重复的数据,如果每次查询都使用distinct进行去重操作,会严重影响效率。可以创建一张与t_recored表结构相同的表,把去重的记录写入到新的表中,以后查询都从新表中查,这样真实的数据不丢失,同时又能保证查询效率
sql
create table t_recored_new like t_recored;
insert into t_recored_new select distinct * from t_recored;
select * from t_recored_new;
rename table t_recored to t_recored_old, t_recored_new to t_recored;
select * from t_recored;七,聚合函数
聚合函数就是为了进行聚合查询
查询的时候,指定表达式 => 进行"列和列之前运算"
聚合查询,就是在进行"行和行之间运算"
有:count,sum,avg,max,min
八,group by分组查询
把表的若干行进行分组,需要指定"分组依据"
指定某个列,这个列值相同的行就会分到同一个组里
会根据分组后的结果进行聚合查询
语法:select 表达式 from 表名 group by 列名;
(正确的做法:确保select后面写的列要么是group by中指定的列,要么是进行聚合函数的操作)
分组之前指定条件:where(用于对表中的真实数据的条件过滤)
分组之后指定的条件:having(用于对分组结果的条件过滤)
使用group by对结果进行分组处理后,对分组的结果进行过滤时,不能使用where子句,而要使用having子句
九,内置函数
聚合函数只是内置函数的一部分
SQL中的函数调用,一般都是通过select语句进行的,把函数放到select这里的列,查询结果就是函数调用返回的结果
1,select curdate();其中的curdate()当成是"表达式"查询
2,select curdate() as '当前日期' from emp;
写了from表名 之后,就是在遍历表的每一行,针对每一行进行列对应的表达式