一、AI 开发这事儿,终于开始从「会提问」变成「会运转」
这两天看到一个说法,叫 Loop Engineering。我一开始看到的时候,说实话,有点烦。
因为 AI 圈现在太爱造词了。今天一个 Context Engineering,明天一个 Agentic Workflow,后天又冒出来一个 Harness Engineering。每个词看起来都很高级,拆开一看,好像又是那点东西。
但 Loop Engineering 这个词,我看着看着,突然觉得不太一样。
它不是在讲怎么把一句 Prompt 写得更漂亮。也不是在讲怎么往模型窗口里塞更多上下文。它讲的是一件更底层的事,怎么让 AI 不再像一个你每次都要手动叫醒的实习生,而是变成一个可以持续运行、持续发现问题、持续推进任务的工作系统。
这个变化,其实挺大的。
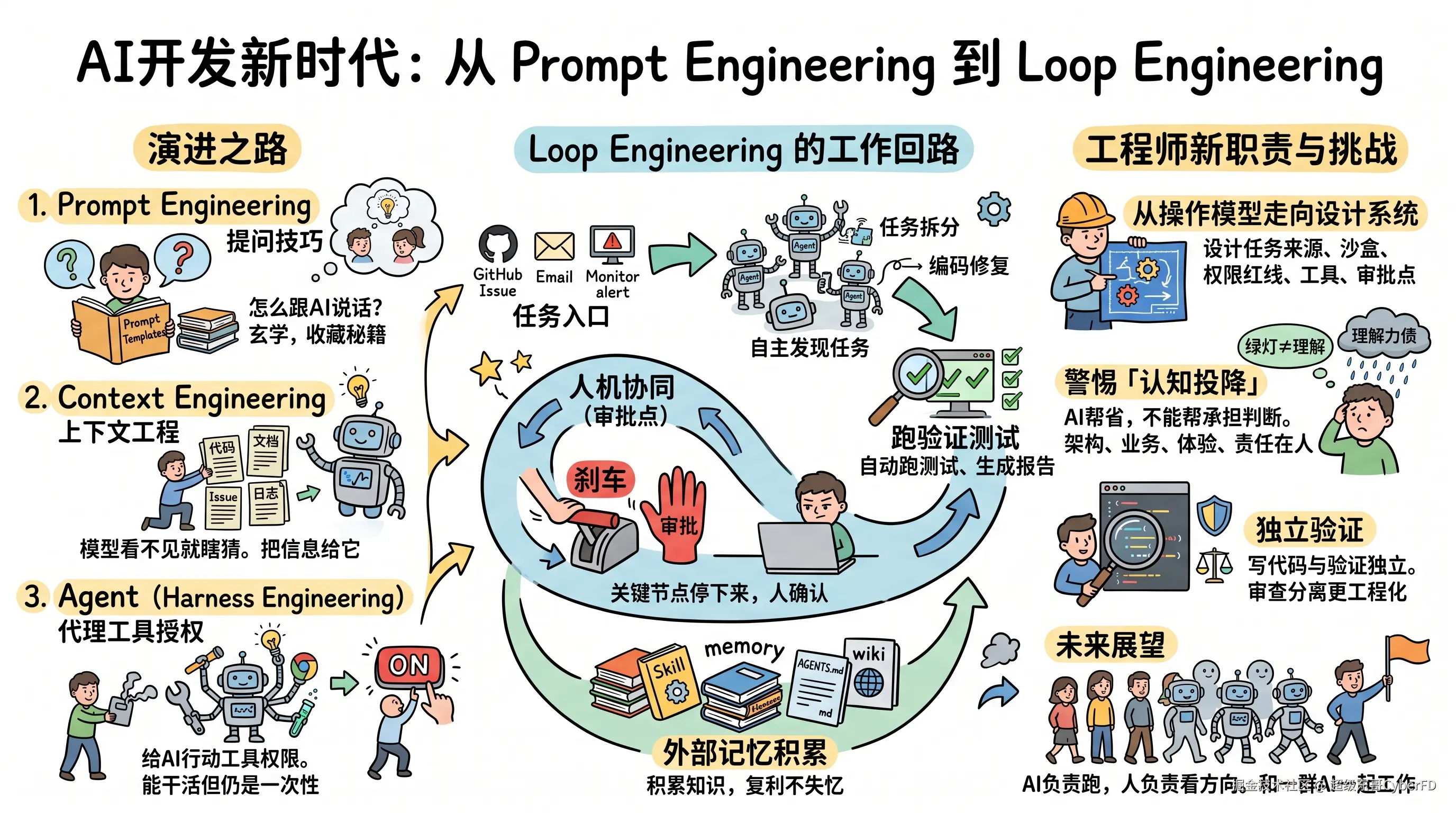
过去三年,AI 工程师的工作重心一直在往外扩。最早大家研究 Prompt Engineering,核心问题是,我该怎么跟模型说话。
那时候非常像玄学。同样一个需求,你加一句「一步一步思考」,效果突然好了。你换个角色设定,让它「扮演资深工程师」,代码看起来又像那么回事了。当时大家疯狂收藏 Prompt 模板,像收藏武功秘籍。
后来大家发现,Prompt 写得再好也有天花板。
因为模型不是你肚子里的蛔虫。它不知道你的代码结构,不知道你的业务约定,不知道你们公司哪个接口有历史包袱,也不知道 README 里那句「不要随便改」背后埋过多少血泪。
于是 Context Engineering 开始变重要。你不能只问问题,你得把正确的信息给它。代码、文档、Issue、日志、数据库结构、历史决策、架构约束,这些东西都要被组织起来,变成模型能理解的上下文。
我自己搞 llm-wiki 的时候,对这点感受特别深。很多时候不是模型不聪明,是它看不见。它看不见你的项目过去发生了什么,看不见某个命名为什么这么奇怪,看不见你上个月为了兼容一个边缘客户做过什么妥协。
看不见,就只能瞎猜。
而瞎猜,是 AI 写代码最可怕的地方。
再往后,Agent 火了。Claude Code、Codex、Cursor、各种本地 Agent,全都开始不满足于只回答问题。它们要能读文件、改代码、跑测试、查日志、调用浏览器、访问数据库。
这时候问题又变了。不是怎么跟 AI 沟通,也不是给 AI 什么信息,而是怎么让 AI 行动。这就是很多人说的 Harness Engineering。
你得给它工具,给它权限,给它执行环境,给它一个能干活的外壳。
但到这里,其实还没完。因为你会发现,哪怕 Agent 已经能行动了,它大多数时候仍然是一次性的。
你说,帮我修这个 Bug。它修了。你说,补个测试。它补了。你说,这里不对,重新改。它重新改。看起来是自动化了,但整个节奏仍然靠人一下一下拨动。
像什么呢。像你面前有一个很强的机械臂,但每动一下都得你亲自按按钮。挺强。但还不够爽。
Loop Engineering 想解决的,就是这个按钮问题。
它关心的不是单次任务怎么完成,而是一个系统能不能自己跑起来。自己发现任务,自己拆分任务,自己分配工作空间,自己调用工具,自己跑验证,自己记录状态,自己判断下一步要干什么。
这玩意听起来很抽象。但你把它翻译成人话,其实就是,把 AI 从聊天窗口里拎出来,放进真实的软件生产流水线里。
二、真正的 Loop,不是让 AI 乱跑,而是让系统有入口、有边界、有刹车
比如 GitHub Issue 里来了一个 Bug。以前是人看到 Issue,打开 IDE,问 AI 怎么修,复制代码,跑测试,再提交。
Loop 的想法是,Issue 本身就是任务入口。系统自动创建一个独立分支或 worktree,拉起一个 Agent,让它读取相关代码和项目规范,尝试修复,跑测试,生成变更说明,再交给另一个审查 Agent 或人类 Review。
如果测试失败,它继续回到循环里。如果发现权限太高,它停下来请求审批。如果结论不确定,它把不确定性写进记录。
这个时候,AI 不再是一个对话框。它变成了一个工作回路。
我觉得这里面最有意思的,不是「AI 更自主了」这句废话。而是工程师的位置变了。
以前我们像是在操作模型。现在我们越来越像是在设计系统。
你要设计任务从哪里来。是 GitHub Issue,还是 CI 失败,还是监控告警,还是一个产品经理丢在飞书里的需求。
你要设计 Agent 在哪里工作。每个任务是不是有独立 branch,每个 Agent 是不是有自己的 sandbox,多个 Agent 会不会互相覆盖。
你要设计它启动时知道什么。哪些是项目规范,哪些是业务规则,哪些是历史坑位,哪些是永远不要碰的红线。
你还要设计它能调用什么。GitHub、Jira、Slack、数据库、浏览器、MCP、企业微信审批。这些工具接进去以后,Agent 才真的能干活。否则它只是一个很会写作文的东西。
这块我之前看 GoHumanLoop 那类人机协同方案时,也有类似感觉。
Agent 真正进入企业流程以后,最关键的往往不是让它一口气全自动,而是在哪里停下来,让人接管一下。比如删数据、发生产请求、审批 Offer、改关键配置。
这些事不是不能让 AI 参与。但你得有审批点。你得知道它为什么要这么做。你得知道谁确认过。你得能追溯。
所以 Loop 不是一味追求无人驾驶。
很多人一听自主 Agent,就开始想象一个系统半夜自己改代码、自己上线、自己发公告,然后你早上醒来发现世界已经变了。不是哥们,这个画面想想就有点吓人。。。
真正靠谱的 Loop,反而一定有刹车。它有自动部分,也有人类确认部分。它让 AI 多做重复劳动,但关键节点还得让人保留判断权。
这也是为什么我觉得 Loop Engineering 不是 Prompt Engineering 的替代品。Prompt 还是重要。Context 还是重要。Harness 还是重要。只是它们都变成了 Loop 里的零件。
Prompt 是一次行动的意图表达。Context 是行动前的视野。Harness 是行动时的手脚。Loop 是让这一切不断跑起来的节奏。
这件事如果放到个人开发者身上,其实也没那么遥远。
你不需要一上来就搞一个全自动 AI 公司。太离谱了,也没必要。
你可以先做一个很小的 Loop。比如给自己的项目建一个固定入口,把所有想法都写成 Issue 或 Markdown 任务。然后每个任务启动时,都让 Codex 或 Claude Code 自动读取 AGENTS.md、项目规范、最近变更、相关测试。再给它一个固定工作方式,先理解代码,再改动,再跑测试,再写总结。
最后把结果记录回任务文件里。
这就是一个小 Loop。
它不炫。但它能复用。
更关键的是,它会积累。
我一直觉得,AI 开发里最被低估的东西就是外部记忆。很多人每次打开一个新对话,都像失忆重开。上次踩过的坑,这次还踩。上次讲过的架构约束,这次还要重新讲。上次某个测试为什么不能跑,过两天又忘了。
这太浪费了。
所以我现在越来越喜欢把项目知识写进 Skill、AGENTS.md、wiki、memory 这种地方。不是为了仪式感。就是为了让下一次循环开始时,系统不是从零出发。
它知道过去发生了什么。
这件事很小,但时间长了,会产生复利。
三、Loop 越顺,人越不能认知投降
还有一个很重要的点,验证必须独立。
这话听着有点刺耳,但我觉得挺真实。你不能让一个 Agent 自己写代码,然后完全相信它自己说「我验证过了」。
人都会自欺欺人,AI 更会。它有时候不是故意骗你,它只是非常擅长给出一个看起来合理的完成叙事。
所以测试、静态扫描、代码审查、人工审批,最好都从 Loop 里独立出来。写代码的是一个环节。验证是另一个环节。审查又是另一个环节。这才像工程系统。
否则就是自己出题,自己判卷,自己给自己鼓掌。
听起来很热闹,但不一定可靠。
我现在看 Loop Engineering,最大的感受是,它把 AI 协作从「技巧问题」推进到了「组织问题」。
你会不会写 Prompt,当然还有用。但更大的差异会出现在,你能不能设计一套让 AI 稳定工作的环境。
有入口,有上下文,有工具,有权限边界,有验证,有记忆,有人类接管点。这些东西连起来以后,模型能力才真的能进入生产。
否则再强的模型,也会被困在聊天框里。
当然,这里也有一个很危险的东西。Loop 跑得越顺,人越容易认知投降。
以前 AI 写一段代码,你还会逐行看。后来它一次修五个文件,你开始扫一眼。再后来它自动开 PR、自动补测试、自动生成说明,你可能就只看绿灯。
绿灯很诱人。
但绿灯不等于理解。
我自己一直很警惕这个事。
AI 可以帮我们省掉很多重复劳动,但不能帮我们承担最终判断。尤其是架构设计、业务取舍、安全边界、用户体验这些东西,最后还是人的责任。
你可以不亲手写每一行代码。但你最好知道系统为什么变成现在这样。
否则积累下来的就不只是技术债。还有理解力债。
这个词我挺喜欢的,理解力债。
代码库越来越大,自动化越来越强,PR 越来越多,但你对系统的理解越来越少。短期看效率很高。长期看,可能某一天你会突然发现,自己已经不敢动这个系统了。
因为它不是你设计出来的,它只是你一次次点确认长出来的。
这就很可怕。
所以我觉得,Loop Engineering 最好的状态,不是让人离开开发过程。而是把人从低价值的反复操作里解放出来,回到更重要的位置。
你去设计循环。你去定义边界。你去判断什么可以自动,什么必须审批。你去决定系统应该记住什么,忘掉什么。你去做那些真的需要人类经验、审美、责任感的判断。
AI 负责跑。
人负责看方向。
这可能才是未来几年工程师最值得练的能力。不是写出最骚的 Prompt。而是搭出一个能持续工作的 AI 协作系统。
它不一定一开始就很完美。甚至一开始会有点笨。会跑错测试,会读错上下文,会在奇怪的地方卡住,会让你怀疑自己是不是在给自己找麻烦。
但很多基础设施一开始都是这样的。CI 刚接入的时候也烦。代码 Review 流程刚建立的时候也慢。类型系统刚加上的时候也痛。
但等它们真的融进工作流,你就很难再回去了。
Loop Engineering 大概也是这样。
一开始像玩具。
后来像工具。
再后来,它会变成工作方式本身。
大时代啊,朋友们。
我们可能正在从「怎么问 AI」走向「怎么和一群 AI 一起工作」。
而这件事,想想就觉得挺兴奋的。
也挺需要清醒的。