上一篇《cfs调度类深入解刨------psi科普篇》讲述了kernel中psi的发展背景及使用方式。
本篇文章详细分析pelt功能及相关特性。
[Util Clamp](#Util Clamp)
pelt
在Linux内核(特别是CFS公平调度器)中,PELT(Per-Entity Load Tracking,每个实体的负载跟踪) 是内核用来量化"CPU核心和进程当前到底有多忙"的最核心数学模型与算法支柱。它是操作系统进行CPU频率动态调节(EAS/CPUFreq)、多核负载均衡(Load Balancing)以及容器算力分配(Cgroups Share)的"感应器官"。
PELT 的核心作用:
- 量化任务最近一段时间的运行行为
- 为CFS负载均衡提供依据
- 为CPU频率调节schedutil提供util信号
- 为异构CPU调度EAS/big.LITTLE提供能耗决策依据
- 为cgroup层级调度提供负载聚合能力
- 为任务迁移、CPU选择、唤醒路径提供实时负载判断
在PELT诞生之前(Linux3.8之前),Linux内核使用的是粗粒度的采样机制:
历史缺陷 :内核只记录"过去这一秒,CPU利用率是80%"。但当调度器需要把一个新任务分配给某个CPU时,内核根本不知道这80%的负载是由100个只跑了1毫秒的"小蚂蚁进程"产生的,还是由 1个持续跑800毫秒的"大象进程"产生的。
PELT的破局:PELT实现了"每个实体(Per-Entity)"的独立跟踪。无论是单个进程(Task)、还是一个容器(Task Group),甚至是一个物理CPU核心,PELT都能以微秒级的精度,单独计算它们各自的负载历史。
PELT版本采用值范围1024,避免负载值过大溢出(7.0及以上内核中有溢出处理方法),负载值过小计算偏差等问题:
define LOAD_AVG_MAX 47742 负载跟踪的最大值
#define PELT_MIN_DIVIDER (LOAD_AVG_MAX - 1024) 负载跟踪的最小值
通过指数加权移动平均(EWMA),按时间衰减负载:
-
时间窗口(Period Window)
PELT将时间划分为一个个连续的、大小固定为1024微秒(约1毫秒)的时间窗口。
-
指数衰减公式
一个进程如果现在疯狂吃CPU,它的负载会立刻飙高;但如果它突然不干活了,它的负载不应该瞬间归零,而是应该像"热铁冷却"一样慢慢滑落。PELT引入了半衰期(Half-life)的概念:
PELT的半衰期固定为32个时间窗口(约32毫秒)。
意味着一个进程如果绝对静止了32ms,它过去积攒的负载影响力就会减半(衰减 50%);再过32ms,再减半(降为25%)。
衰减系数为:y = 0.5^(1/32) ≈ 0.97857206,这意味着每经过一个周期(1024微秒),负载值衰减为原来的约0.9786。
在内核源码中,PELT实际上在并发追踪三个不同的物理量:
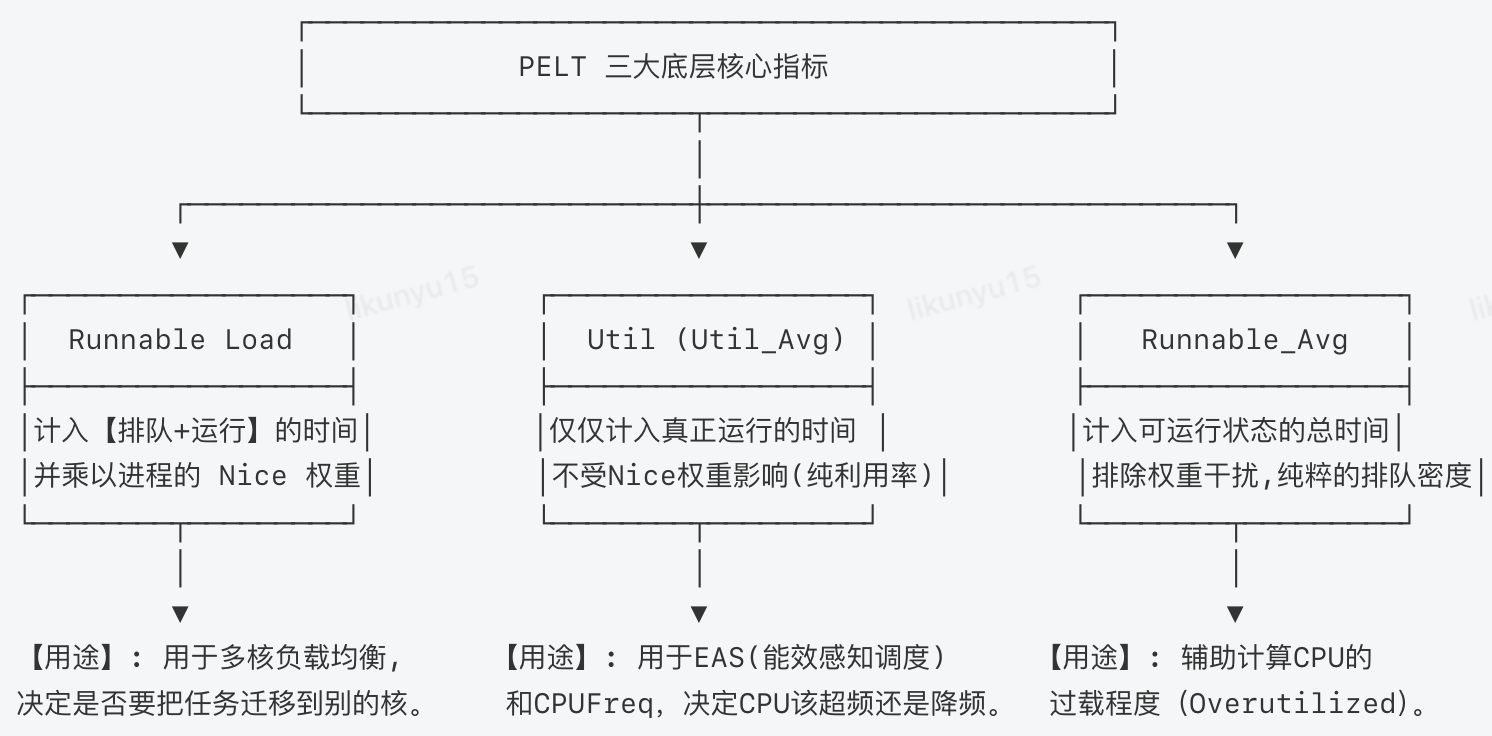
PELT的核心应用场景:
-
动态调频(Schedutil 调速器)
在手机上滑屏或者服务器突发流量时,CPU决定立刻飙高频率的策略
调速器会高频读取当前CPU核心的PELT util_avg指标。
只要检测到util_avg连续突破阈值,内核不需要等传统的1秒采样,而是可以在几毫秒内通知硬件电压芯片(PMIC)直接将CPU主频拉到最高(Turbo Boost),消除卡顿。
-
异构大小核调度(EAS,Energy-Aware Scheduling)
在现代Modern处理器(如智能手机、智能驾驶芯片Orin)中:
当一个新任务被唤醒时,内核会查看该任务自身的PELT util_avg。
如果它的历史PELT值是47742(最大值,属于重度大象任务),调度器会直接将其分配给超大核/性能核。如果它的历史PELT值只有46719(最小值+1,属于后台心跳小任务),调度器会强行将其丢给能效核/小核,从硬件层榨干每一点电能。
-
容器算力动态瓜分(Cgroups CPU Shares)
在云原生场景中,如果你给两个容器分别设置了cpu.shares=1024和cpu.shares=512:
当两边都在疯狂抢算力时,内核利用PELT动态计算这两个容器内部所有任务的runnable_load_avg总和。谁的总和高,CFS调度器在微秒级的时间轴上,就会按2:1的物理比例,精准动态切割CPU的执行时间片。
虽然PELT极其精准,但它的"历史指数衰减"设计带来了一个致命的天然缺陷:延迟不敏感(过载与冷启动延迟)。
冷启动过慢 :如果一个原本极其消耗CPU的高算力任务,在原地深睡了100毫秒(此时它的PELT指标因为半衰期衰减,已经无限跌落到了近乎最小值)。当它突然被唤醒并需要立刻进行极限计算时,PELT机制需要至少几十毫秒的时间窗口,才能把它的指标重新"充能"累加回高位。在这几十毫秒的充能期内,内核会误认为它是个小任务,把它丢在小核或者不给CPU超频,造成严重的启动首帧延迟(First-frame Jitter)。
退场过慢:反过来,当一个高负载任务已经彻底执行完毕并退出了,它的负载贡献值依然会留在那个CPU核心上,按照32ms的半衰期缓慢滑落。在这段滑落期内,内核会误认为这个核还很忙,导致其他新任务不敢迁移过来,造成算力闲置浪费。
为了修正PELT的迟钝,现代Linux内核引入了强力的补丁:
Util Clamp (利用率钳位) :允许用户态直接给特定任务强行打标签(如强制设定该任务的PELT util_min为1024)。这样即使该任务刚刚睡醒,内核也会瞬间视其为满载大王,立刻给予最高主频和最高配额。
PELT衰减加速/突发充能:在某些关键中断唤醒路径上,直接强行改写(Boost)PELT的累加变量,使其跨越数学窗口限制。
pelt与任务状态
pelt主要包括 :
load_avg 负载平均值
runnable_avg 可运行时间平均值
util_avg 利用率平均值
load_sum 负载总和
runnable_sum 可运行时间总和
util_sum 利用率总和
Running状态,任务正在CPU上执行 :
load 增加
runnable 增加
util 增加
Runnable状态,任务在rq队列中等待CPU :
load 增加
runnable 增加
Sleeping状态,任务阻塞、睡眠、等待I/O或定时器 :
load 衰减
runnable 衰减
util 衰减
util_est
util_est(Utilization Estimation,利用率估算)用于弥补pelt(逐实体负载跟踪)对瞬态负载响应迟缓的缺陷,帮助调度器在任务唤醒时更精准地预测其实际CPU需求,从而优化提频与大小核迁移决策。
pelt的缺陷 :基于几何级数衰减,导致重度负载在进入长时间休眠后,利用率(util_avg)会衰减至极低。当该任务再次被唤醒时,util_avg爬升较慢,导致调度器无法及时为其分配高性能 CPU 或触发提频,造成性能抖动。
util_est的作用:在任务运行或退出时记录其真实负载峰值,在任务重新唤醒时直接使用该历史峰值作为利用率评估基础,实现快速提频。
util_est结构体主要挂载在调度实体和cfs_rq队列中,包含以下关键字段:
enqueued :当前正在排队任务的瞬时利用率总和。
ewma:基于指数加权移动平均(EWMA)的历史预估利用率。
工作流触发点 :
dequeue阶段 :任务退出CPU时,内核会评估其在此次生命周期内的实际运行情况,更新EWMA历史预估值。
enqueue阶段:任务再次唤醒时,调度器会比较PELT的util_avg和util_est.ewma,取较大者作为该任务的实际CPU需求基准进行调度决策。
应用场景与性能调优
EAS(能量感知调度) :在 ARM big.LITTLE 架构中,唤醒任务时若依据util_est判断其为重载任务,会直接将其放置在大核(Big Core)上运行,减少在小核(LITTLE Core)上的排队时间并保证性能。
CPU频率调节(cpufreq) :在系统负载频繁波动时,util_est提供的突发高利用率数据能更快触发 CPU升频,降低响应延迟。
参数配置:内核提供了/proc/sys/kernel/sched_util_clamp_min(0-1024)等接口进行阈值和机制微调。
Util Clamp
Util Clamp (简称uclamp) 是自Linux 5.3内核开始引入的一项增强型调度机制,用于对进程或运行队列的 CPU 利用率(Utilization)进行人为的上限和下限钳位约束。
在引入uclamp之前,Linux 内核的PELT (Per-Entity Load Tracking) 或util_est完全基于任务的历史行为去自动"预测"负载。但在实际的移动端(如Android)或云计算混部场景中,操作系统往往需要根据业务的业务优先级(如前台vs后台)进行人工干预。uclamp正是连接上层业务感知与底层调度/调频的桥梁,它取代了早期Android常用的SchedTune机制。
uclamp为每个调度实体(Task)或控制组(cgroup)定义了两个核心属性,其取值范围均在0到1024之间:
UCLAMP_MIN(最小利用率钳位) :
含义:任务被分配的最低利用率天花板。
作用:即使一个任务实际只消耗极少的CPU(例如实际 util_avg = 50),但如果设置了UCLAMP_MIN = 600,调度器和 schedutil 调频器也会把该任务当成600的负载来对待。
目的:强制提频、升核。确保关键任务(如UI渲染、音频线程)在刚唤醒或负载较低时也能跑在高频或大核上,大幅降低响应延迟(Latency)。
UCLAMP_MAX(最大利用率钳位) :
含义:任务被允许使用的最大利用率地板。
作用:即使一个任务在疯狂执行死循环(实际 util_avg = 1024),但如果设置了 UCLAMP_MAX = 300,调度器也会将其限制在300负载的档位。
目的:限频、锁小核、节能。防止非关键任务(如后台备份、系统日志收集)无限制地拉高CPU频率,从而导致设备发热、耗电过度。
uclamp的设计对性能极其敏感,因为它会在每次任务切换(Context Switch)和调频时被调用。核心数据结构:
struct uclamp_se :挂载在struct task_struct或struct task_group中,包含该实体的 value(用户设定的原始值)和 bucket_id(桶ID)。
struct uclamp_rq :挂载在每个CPU的rq队列中。为了加速查找,内核使用了一种基于桶(Bucket)的计数机制:
内核默认将0---1024的范围划分为UCLAMP_BUCKETS(通常为5个)不同的区间。
每个桶记录当前排队任务中属于该区间的任务数量。
通过对非空桶进行位图(Bitmap)检索,内核可以在O(1)的时间复杂度内,迅速找出当前CPU运行队列中所有任务里的最大UCLAMP_MIN和最小UCLAMP_MAX。
相关结构
c
struct sched_avg { 用于调度器负载追踪的结构体sched_avg。这个结构体是PELT(Per-Entity Load Tracking)算法的核心,用于跟踪调度实体(如任务、运行队列)的负载情况
u64 last_update_time; 最后一次更新该结构体的时间(纳秒)。用于计算与当前时间的差值,从而计算衰减后的负载
u64 load_sum; 负载总和,包括正在运行和可运行的状态。它代表了调度实体对CPU的需求,包括正在运行的时间和等待运行的时间。这个值会随着时间衰减
u64 runnable_sum; 可运行时间总和。表示调度实体处于可运行状态(即等待CPU)的时间。与load_sum类似,但只包括可运行状态,不包括实际运行的时间
u32 util_sum; 利用率总和。表示调度实体实际运行的时间。这个值用于计算CPU利用率,是负载均衡和频率调整的重要依据
u32 period_contrib; 在上一个更新周期中,未满1024微秒(一个周期)的贡献时间。PELT算法以1024微秒为一个周期,每个周期结束时会衰减负载。这个字段用于跟踪不足一个周期的部分,以便在下一个周期中继续计算
unsigned long load_avg; 负载平均值。是load_sum经过衰减后的平均值,表示调度实体的平均负载
unsigned long runnable_avg; 可运行时间平均值。是runnable_sum经过衰减后的平均值,表示调度实体的平均可运行时间
unsigned long util_avg; 利用率平均值。是util_sum经过衰减后的平均值,表示调度实体的平均CPU利用率
struct util_est util_est; 利用率估计值。用于快速估计任务的利用率,特别是在任务被唤醒时,避免重新计算衰减的利用率
} ____cacheline_aligned;
struct uclamp_rq { 每CPU运行队列利用率钳位数据结构,用于在rq队列级别维护UClamp的聚合信息
unsigned int value; 当前CPU的有效钳位值
struct uclamp_bucket bucket[UCLAMP_BUCKETS]; 将0---1024的利用率区间,划分为数个固定的"桶"(Buckets)。Linux 内核中默认UCLAMP_BUCKETS 的数量通常是5个
};
struct uclamp_se { 每调度实体利用率钳位数据结构,嵌入在struct sched_entity中
unsigned int value : bits_per(SCHED_CAPACITY_SCALE); 该任务实际被设置的Uclamp限制值
unsigned int bucket_id : bits_per(UCLAMP_BUCKETS); 该任务根据自身的value,被映射到了 uclamp_rq中的哪一个桶(Bucket)
unsigned int active : 1; 该任务当前是否处于活跃状态(即是否正在某个 CPU 队列中排队或运行)
unsigned int user_defined : 1; 该任务的Uclamp值是否是由用户空间显式指定的(例如通过 sched_setattr或 cgroup修改过)
};