Function Calling 并不是让模型直接执行 Python 函数,而是建立一套结构化协议: 模型判断需要什么能力、生成参数,你的应用执行真实代码,再把结果交回模型。 本文用同一个订单查询场景,对照 OpenAI Responses API 与 Claude Messages API 的完整写法。
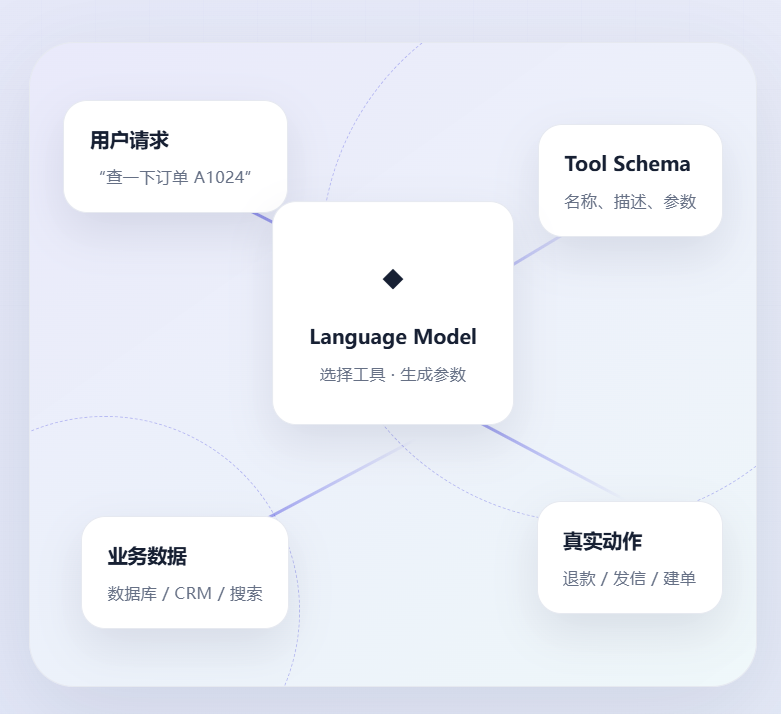
Function Calling 到底是什么
普通对话只要求模型返回文字。Tool Calling 则允许开发者在请求里附上一组工具说明, 例如 get_order_status、create_ticket 或 send_email。 模型读到用户需求后,可以不直接回答,而是返回一个结构化的"调用请求"。
模型不是业务系统的执行者,更像一个会理解自然语言的调度器。 它负责决定"调用哪个工具、传什么参数";你的代码负责权限校验、真实执行和结果回传。
这一区分很重要。模型可以生成 {"order_id":"A1024"}, 但它无法凭空访问你的订单数据库。只有应用收到调用请求后,主动执行数据库查询, 订单状态才真正被取回。

一次工具调用,本质上是五步对话
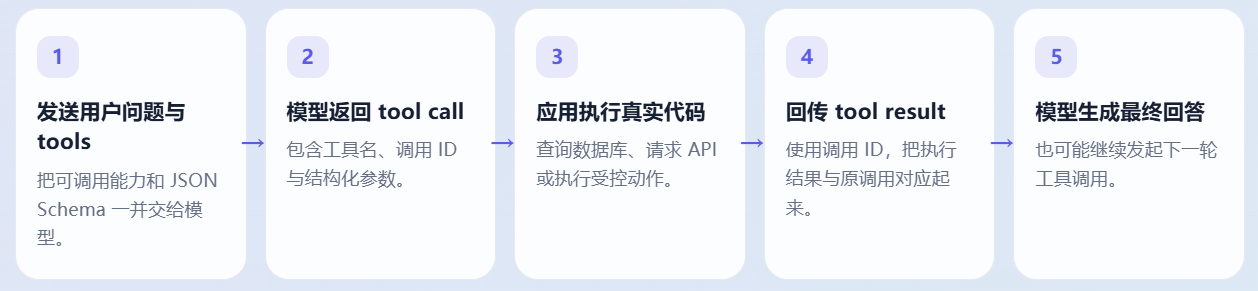
调用 ID 不是装饰字段
OpenAI 使用 call_id,Claude 使用 tool_use_id。 并行调用时,模型需要靠它判断每份结果属于哪一个请求。
Tool Schema 不是接口文档的缩写版
模型只看得到你提供的工具定义。函数名含糊、描述过短、字段含义不清, 都会直接降低选工具和填参数的准确率。一个可用的 Tool Schema 至少要回答四个问题: 这个工具做什么、什么时候用、每个参数表示什么、什么情况不该用。
{
"name": "get_order_status",
"description": "查询已登录用户的一笔订单。仅用于读取订单状态;
不要用它取消订单或修改收货地址。order_id 来自用户提供的订单编号。",
"parameters / input_schema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "订单编号,例如 A1024;不要传入用户姓名。"
}
},
"required": ["order_id"],
"additionalProperties": false
}
}设计时更值得关注的几件事
名称要能区分语义。 与其写 query,不如写 orders_get_status 或 github_list_pull_requests。
用 enum 限制合法状态。 比起让模型自由生成字符串,["pending","shipped","delivered"] 更稳定。
不要让模型填写应用已经知道的值。 当前用户 ID、租户 ID、权限范围应由服务端上下文注入,而不是交给模型猜。
返回高信号结果。 工具输出只保留模型完成下一步所需字段,不要把整张数据库记录原样塞回上下文。
OpenAI:处理 function_call 与 function_call_output
在 Responses API 中,函数工具放在顶层 tools 数组里。 当模型需要查询订单时,response.output 中会出现 type: "function_call" 的 item。参数位于 arguments, 通常需要先做 JSON 解析。
1. 定义工具并发起第一次请求
python
from openai import OpenAI
import json
client = OpenAI()
tools = [{
"type": "function",
"name": "get_order_status",
"description": (
"查询当前登录用户的一笔订单。只读取状态,不修改订单。"
),
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "订单编号,例如 A1024"
}
},
"required": ["order_id"],
"additionalProperties": False
},
"strict": True
}]
input_items = [{
"role": "user",
"content": "帮我查一下订单 A1024 到哪里了。"
}]
response = client.responses.create(
model="gpt-5.5",
tools=tools,
input=input_items
)2. 找出调用、执行函数并回传结果
python
def get_order_status(order_id: str) -> dict:
# 示例:真实项目中应查询数据库或内部服务
fake_db = {
"A1024": {
"status": "shipped",
"carrier": "SF Express",
"eta": "2026-06-14"
}
}
return fake_db.get(order_id, {"error": "order_not_found"})
# 保留模型本轮输出,下一轮需要完整上下文
input_items.extend(response.output)
for item in response.output:
if item.type != "function_call":
continue
args = json.loads(item.arguments)
if item.name == "get_order_status":
result = get_order_status(args["order_id"])
else:
result = {"error": "unknown_tool"}
input_items.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": json.dumps(result, ensure_ascii=False)
})
final_response = client.responses.create(
model="gpt-5.5",
tools=tools,
input=input_items
)
print(final_response.output_text)不要假设一次只会返回一个调用
response.output 中可能有零个、一个或多个 function_call。 路由代码应该遍历全部 item,而不是只取第一个。
Reasoning model 的上下文要完整保留
当模型输出中包含与工具调用相关的 reasoning items 时,也需要随工具结果一起传回。 最稳妥的写法就是把上一轮 response.output 整体加入下一轮输入。
Claude:处理 tool_use 与 tool_result
Claude 的 client tool 同样由你的应用执行,但数据结构不同。 工具参数字段叫 input_schema;模型发起调用时, 响应 content 中出现 tool_use block, 整体 stop_reason 通常为 tool_use。
python
import anthropic
import json
client = anthropic.Anthropic()
tools = [{
"name": "get_order_status",
"description": (
"查询当前登录用户的一笔订单。仅用于读取物流和订单状态,"
"不能取消订单、退款或修改地址。"
),
"input_schema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "订单编号,例如 A1024"
}
},
"required": ["order_id"],
"additionalProperties": False
},
"strict": True
}]
messages = [{
"role": "user",
"content": "帮我查一下订单 A1024 到哪里了。"
}]
response = client.messages.create(
model="claude-opus-4-8",
max_tokens=1024,
tools=tools,
messages=messages
)2. 执行工具,把结果作为 user message 回传
python
# 先把 Claude 的完整 assistant content 放入历史
messages.append({
"role": "assistant",
"content": response.content
})
tool_results = []
for block in response.content:
if block.type != "tool_use":
continue
try:
if block.name == "get_order_status":
result = get_order_status(block.input["order_id"])
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": json.dumps(result, ensure_ascii=False)
})
else:
raise ValueError("unknown_tool")
except Exception as exc:
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": str(exc),
"is_error": True
})
# tool_result blocks 必须放在 content 数组前面
messages.append({
"role": "user",
"content": tool_results
})
final_response = client.messages.create(
model="claude-opus-4-8",
max_tokens=1024,
tools=tools,
messages=messages
)
final_text = "".join(
block.text
for block in final_response.content
if block.type == "text"
)
print(final_text)Client tools 与 Server tools
Claude 文档明确区分工具在哪一侧执行。自定义函数通常属于 client tools: Claude 只生成 tool_use,你的应用负责执行。像 web_search、web_fetch、code_execution 等 server tools,则由 Anthropic 基础设施执行,应用不需要手动运行对应代码。
OpenAI 与 Claude:概念一致,协议不同
| 环节 | OpenAI Responses API | Claude Messages API |
|---|---|---|
| 工具定义位置 | 顶层 tools | 顶层 tools |
| Schema 字段 | parameters | input_schema |
| 函数工具标识 | type: function | 自定义 client tool 通常直接写 name / description |
| 模型发起调用 | function_call output item | tool_use content block |
| 调用参数 | arguments,JSON 字符串 | input,对象 |
| 调用关联 ID | call_id | id,回传时写入 tool_use_id |
| 回传结果 | function_call_output | tool_result |
| 错误标记 | 通常在 output 中返回结构化错误 | 可显式设置 is_error: true |
| 强制调用 | required 或指定 function | any 或指定 tool |
| 禁止调用 | none | none |
| 关闭并行 | parallel_tool_calls: false | disable_parallel_tool_use: true |
所以迁移时不要只做字段名替换。最容易漏掉的是消息历史组织方式: OpenAI 需要把输出 item 和 function_call_output 继续送回; Claude 需要保留 assistant 的 content blocks,再用紧随其后的 user message 发送 tool_result。
并行调用、tool_choice 与 Strict Mode
并行调用:同一轮可能有多个工具请求
用户问"查 A1024 和 B2048 两个订单",模型可能在同一轮生成两个调用。 如果它们互不依赖,可以并发执行;如果后一个动作依赖前一个结果, 更合理的方式是让模型分两轮调用。

OpenAI 可通过 parallel_tool_calls=false 把一轮限制为零或一个函数调用。 Claude 可通过 disable_parallel_tool_use=true 关闭并行。 Claude 同一 assistant turn 中的多个调用在语义上是无序的,不应默认后一个依赖前一个。
tool_choice:控制模型是否必须使用工具
OpenAI
auto:模型自行决定;required:至少调用一个;指定 function:强制调用某个函数;none:禁止工具。还可以用 allowed tools 限定本轮可选子集。
Claude
auto:自行决定;any:必须选一个工具;tool:指定工具;none:禁止工具。部分 thinking 配置对强制模式有额外限制。
Strict Mode:保证"格式正确",不是保证"业务正确"
两家都支持在工具定义中设置 strict: true,目的是让模型输出符合 JSON Schema。 OpenAI 的 strict schema 要求 object 设置 additionalProperties:false, 并把 properties 中的字段全部列入 required;可选字段通常通过允许 null 表达。 Claude 则使用 grammar-constrained sampling 将输出限制在支持的 Schema 子集内。
Strict 不等于安全
Schema 能保证 amount 是 number,却不能判断用户有没有退款权限,也不能判断 100000 是否超过业务上限。身份、授权、额度、资源归属和审计仍必须由服务端完成。
工具失败后,不要伪装成成功
调用外部系统必然会遇到超时、限流、资源不存在和权限不足。 错误应该以模型可理解、程序可记录的形式回传。模型拿到错误后,可以解释失败原因、 请求用户补充信息,或者调整参数再次调用。
{
"ok": false,
"error": {
"code": "ORDER_NOT_FOUND",
"message": "当前账户下不存在该订单",
"retryable": false
}
}Claude 的 tool_result 还可以设置 is_error:true。 OpenAI 一般把错误对象序列化到 function_call_output.output 中。 无论使用哪一家,都不要把异常堆栈、数据库连接串或内部路径直接暴露给模型。
第二次请求不保证一定返回自然语言。模型可能继续调用另一个工具,例如先查订单, 再根据物流异常创建工单。因此应用通常需要一个循环:只要还有 tool calls 就继续执行, 直到模型返回最终文本、达到最大步数,或触发安全终止条件。
必须设置循环上限
建议限制最大工具轮数、单轮调用数、总耗时和总成本。否则参数错误或提示冲突可能造成重复调用。
生产环境真正需要防的,不是 JSON 解析失败
工具名使用 allowlist 路由。 不要根据模型生成的任意字符串动态导入模块或拼接命令。
对参数再次做服务端校验。 即使开启 strict,也要验证资源归属、长度、范围和业务约束。
写操作默认要求确认。 退款、转账、删除、发信、发布内容等动作应分成"预览/确认/执行"阶段。
使用幂等键。 网络重试或模型重复调用时,避免同一笔退款、同一封邮件被执行两次。
工具只返回必要字段。 控制上下文成本,也减少把敏感数据意外带入后续生成的风险。
记录完整 trace。 至少记录 request ID、tool call ID、工具名、耗时、结果状态和脱敏后的参数。
把用户输入与工具输出都视为不可信数据。 外部网页、邮件或数据库文本可能包含 prompt injection。
先做小工具集,再逐步扩展。 可选工具过多会增加选择歧义和 token 成本;大型系统应考虑 tool search 或分层路由。