上一篇《cfs调度类深入解刨------HZ科普篇》中讲述了kernel中时钟HZ相关的分析及发展历程。
本篇文章讲述psi的发展背景及使用方式。
psi
"当系统超负荷运行且资源变得紧张时,很难准确判断这对工作负载生产力产生的影响,或者系统离锁定和内存溢出(Out of Memory Error,OOM)有多近。特别是当机器同时处理多个任务时,超负荷运行对单个任务在延迟和吞吐量方面的影响可能非常大。为了在不牺牲单个任务健康或避免整机锁定风险的情况下最大化硬件利用率,kernel 4.20及之后版本增加了压力停滞信息,这是一种量化系统中资源压力的方法。
在/proc/pressure/目录下(以及每个cgroup内部),有几个文件分别展示了系统在CPU、内存或IO上停滞的时间百分比。这些实际使用时间的百分比可以视为压力百分比,它们大致反映了系统健康状况以及资源超量使用所导致的生产力损失。它们还可以指示系统何时接近锁定状态和内存溢出(OOM)。"
https://lwn.net/Articles/759781/
在PSI诞生之前,系统管理员和自动化运维架构(如 Kubernetes)主要依赖以下指标来判断系统是否过载:
CPU Load Average(平均负载) :它将正在运行、等待运行以及处于不中断睡眠(如等待磁盘D状态)的进程混为一谈。如果Load高,你难以分清系统是在疯狂打满CPU,还是卡在了极慢的机械硬盘I/O上。
CPU Utilization(利用率):如果CPU利用率是100%,系统并不一定会卡顿。因为如果这些任务都是低优先级的后台计算,它们会自动让出算力。利用率高不等于业务受到了负面干扰。
传统的指标只告诉你"资源用了多少"(Utilization),而 PSI告诉你"由于资源不够用,导致业务被拖慢了多少"(Pressure)。它直接以"时间损失"为尺度来量化系统的健康度。PSI将每个资源的压力水平细分为两条绝对单调的时间轴:some和full。

some(部分阻塞)
定义 :代表在一段指定的时间窗口内,至少有一个(或一部分)进程/线程由于等待该资源(如等待CPU调度、等待内存分配、等待磁盘数据回传)而处于阻塞/等待状态,而此时其他核心可能还在正常干活。
描述:公司里有一部分员工因为电脑卡(资源不够)在发呆,但别的员工还在干活。公司的整体产出开始变慢。
full(完全阻塞)
定义 :代表在一段指定的时间窗口内,所有(100%)非空闲进程/线程同时由于等待该资源而处于阻塞状态。在这个瞬间,没有任何一个进程能够跑在CPU上推进有用的业务。
描述:公司的停电了(比如内存严重不足引发了全局页交换/Swap狂飙),所有员工全部被迫停工发呆。公司在这段时间内的有用产出彻底归零。
PSI的代码高度内嵌在内核调度器、内存管理以及块设备驱动中,它在以下内核关键断面上动态打点计账:
-
CPU压力产生原理
触发点:当内核调度器在enqueue_task或dequeue_task时,发现就绪队列(Runqueue)的长度大于1,意味着一个任务正在CPU上跑,而另一个可运行的任务处于TASK_RUNNING状态却拿不到CPU,只能白白在队列里等待(Wait Time)。这种等待的时间会被等比例累加到CPU的some轴上。
-
Memory压力产生原理
触发点 :
直接内存回收(Direct Reclaim) :当应用申请内存,而内核空闲内存不足,迫使当前进程原地停止,去同步执行内存释放或垃圾回收。
页交换(Thrashing/Swap In-Out) :当进程访问的代码或数据被换出到了磁盘swap分区,CPU必须等待将其从磁盘重新读回内存。
进程因为上述原因卡住的时间,会同时累加到内存的some或full。
-
I/O压力产生原理
触发点:进程发起了读写请求,但由于块设备队列满、磁盘硬件慢,进程进入了 TASK_UNINTERRUPTIBLE(不可中断睡眠,即D状态)进行等待。此时CPU只能切走,进程在等待数据回传的总时间被计入I/O压力。
PSI伟大的设计不仅仅是提供了一个类似top的查看接口,而是它提供了一套基于用户态通知机制(Event Triggers)的主动防御框架。应用层程序(如Kubernetes的Kubelet,或者自定义运维Daemon守护进程)可以打开/proc/pressure/memory,并写入一个自定义的阈值监控触发条件:
例如写入 :some 150000 1000000(代表:在1秒(1000000微秒)的滑动窗口内,只要内存some阻塞时间超过150毫秒(150000微秒),内核就立刻触发事件)。
无锁唤醒 :应用程序随后通过系统的select、poll或epoll_wait阻塞在该文件描述符上。
完美防御 :一旦系统由于高并发突发大量内存回收,时间触及150ms阈值的瞬间(微秒级延迟),内核会立刻唤醒阻塞在epoll上的用户态程序。
运维程序醒来后,可以赶在OOM杀进程之前,立刻执行主动防御:停止接收外部新连接、紧急把部分非核心业务驱逐、或者动态切断流量(Shedding Load)。
cpu
通过追踪进程在调度器rq队列(Runqueue)中的等待时间(Wait Time),直接反映出CPU资源不足对业务造成的实际拖慢程度。
c
cat /proc/pressure/cpu
some avg10=0.27 avg60=0.58 avg300=0.31 total=5032927633
full avg10=0.00 avg60=0.00 avg300=0.00 total=0CPU压力只记录some,而full轴数据为0,基本不可能有数据:
some的定义 :在指定的滑动窗口内,系统中有至少一个(或一部分)可运行状态的任务(TASK_RUNNING),因为分不到CPU算力,被迫在就绪队列中排队等待。
原生内核没有full(部分企业内核自实现full):full的定义是"100%的非空闲进程都因为等待该资源而卡死,导致没有任何任务能推进业务"。但对于CPU来说,只要就绪队列里有任务,CPU核心就一定会被调度器塞满并全速运转(执行当前正在抢到时间片的那个任务)。也就是说,永远都有任务在利用CPU推进业务,CPU自己绝不可能闲着,因此完全阻塞(full)的物理状态在CPU维度上不成立。
CPU PSI的统计代码内嵌在内核调度器中。它通过监控每个CPU核心就绪队列(Runqueue)的长度以及时间片切换来动态计算时间损失:
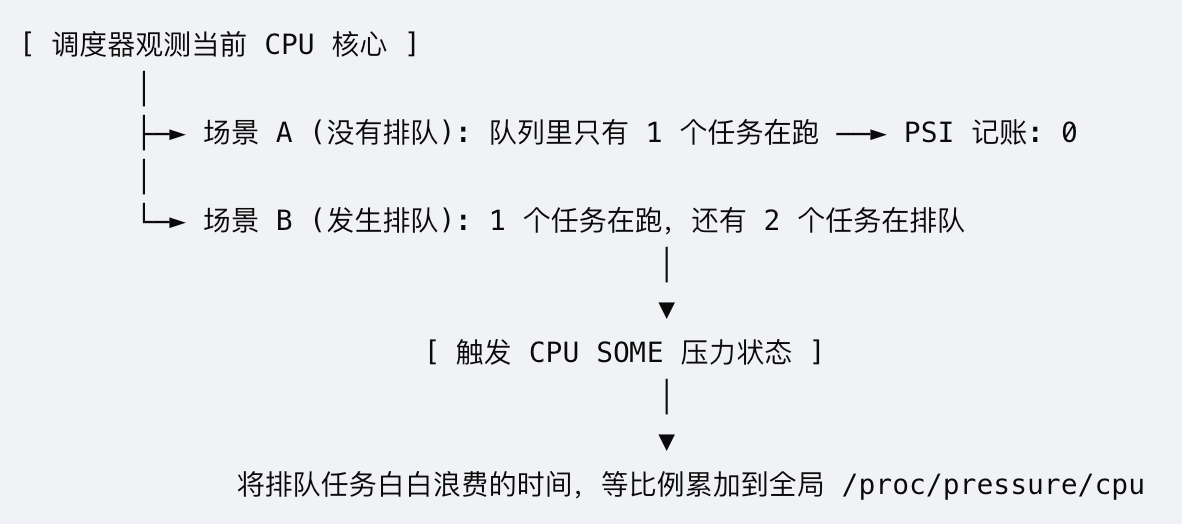
- 状态判定 :
当前核心的rq->nr_running == 1(无排队),即使CPU利用率是100%,CPU的some压力依然为0。当前核心的rq->nr_running > 1(发生竞争),说明有一个任务在跑,其余任务在白白浪费生命等待。 - 时间累加:只要有任务在排队,这段排队等待的时间就会被内核的PSI状态机精准捕获,并按纳秒级累加到该CPU的total计数器中,最终转换为用户态看到的10s、60s、300s窗口的时间百分比。
some字段含义拆解
以some avg10=0.27 avg60=0.58 avg300=0.31 total=5032927633 为例:avg10=0.27在过去10秒钟内,全系统有0.27%的时间(大约27毫秒)至少有一个进程在队列中遭遇了算力排队。total=5032927633:系统自开机(或模块初始化)以来,由于多任务竞争导致任务在队列中白白浪费掉的累计总时间(单位:微秒,此处约合5032.93秒)。
诊断健康阈值(avg10)
< 5%(极致健康) :调度极其顺畅,基本处于"随到随跑,无需排队"的状态。长尾延迟(Tail Latency)非常稳定。
5% ~ 20%(中度警告) :系统上面开始面临明显的CPU瓶颈。任务在就绪队列中的等待时间已经开始产生轻微的业务卡顿或响应延时。
>= 20%(重度阻塞):系统正在遭受严重的算力内卷。有大量的关键业务因为拿不到CPU算力而在队列里苦苦挣扎。
为什么CPU利用率100%,CPU PSI却可能是0
场景(模拟举例,并不正确) :你在服务器上跑了一个编译任务(make -j4),刚好完全占满了4个CPU核心,此时top显示CPU利用率高达100%。
结果 :由于你没有超卖(没有启动第5个高负载任务),这4个编译任务在各自的核上跑得非常顺畅,没有任何人去就绪队列里排队。此时查看 /proc/pressure/cpu,其some指标竟然是0(只存在于逻辑中)。
结论:利用率高不等于有压力。只要没有任务在排队白白浪费时间,业务就是安全的。因此,使用CPU PSI来做自动弹性扩缩容(Auto-scaling)的准确度,远远超过传统的CPU利用率指标。
在现代云原生(Kubernetes/Docker)场景中,PSI配合Cgroups v2可以发挥出极佳的监控威力。传统的容器CPU限制(cpu.shares或cpu.cfs_quota_us)只告诉你这个容器有没有触发硬限流(Throttling)。而Cgroups v2将PSI拓扑直接下放到了每个容器的虚拟目录中:
cat /sys/fs/cgroup/systemd/system.slice/your-service/cpu.pressure
通过这个接口,可以看透本质:这个容器在遭受卡顿,究竟是因为它自身内部的业务多线程产生了疯狂的内卷排队(容器级CPU PSI飙高),还是因为宿主机整体被其他恶棍容器压垮了(系统级CPU PSI飙高)。
memory
Linux内核调优与系统监控体系中,PSI Memory(Pressure Stall Information for Memory)是量化系统 "内存饥饿程度" 的核心机制。与CPU压力不同,内存压力是一个涉及复杂内核回收、页交换(Swap)以及直接阻塞的多维状态。它的报告中同时包含some和full两个轴,能直接反映出内存不足对业务性能产生的真实杀伤力。
c
cat /proc/pressure/memory
some avg10=1.20 avg60=0.55 avg300=0.12 total=5423312
full avg10=0.10 avg60=0.02 avg300=0.00 total=231124内存资源能够完美触发这两种压力状态,其物理边界非常清晰:
-
some(部分进程受阻)
定义 :在指定的滑动窗口内,系统中有至少一个(或一部分)非空闲进程,因为等待内存资源(如执行直接内存回收、等待页换入)而处于阻塞/等待状态,而此时其他核心上的进程可能还在正常推进业务。
描述:服务器上有一部分线程因为内存不够开始发呆(等待内存回收),但别的线程还在全速运行。系统的整体产出开始减速。
-
full(全系统卡死/吞吐量归零)
定义 :在指定的滑动窗口内,系统中所有正在运行(非空闲)的进程,在同一个瞬间全部因为等待内存资源而陷入阻塞状态。
描述:此时没有任何一个进程能够跑在CPU上推进有用的用户态业务(因为全系统的CPU算力都被迫用来做内存回收或陷入死锁边缘)。系统在这段时间内的有用产出彻底归零。
内存PSI的打点和计账代码深度内嵌在Linux内核的内存管理子系统(MM)中。它主要由以下三个高能的内核断面事件驱动累加:
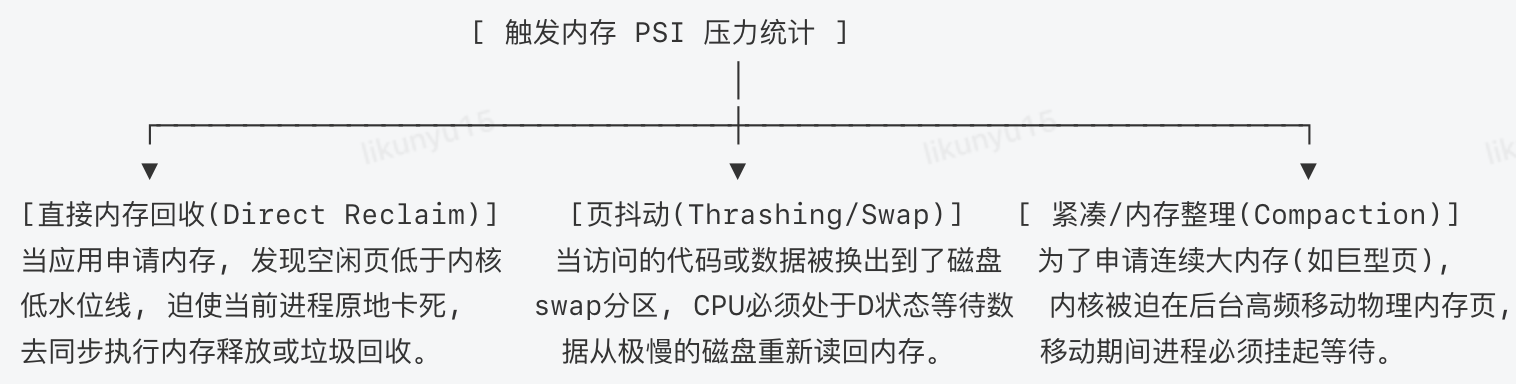
直接内存回收(Direct Reclaim) :当进程调用malloc或内核调用alloc_pages申请物理内存时,如果全系统的空闲内存低于最低水位线(watermarkWMARK_MIN),内核不会立刻报错,而是迫使当前申请内存的进程原地不动,在当前上下文中同步去释放、回收旧的缓存页。
页抖动(Thrashing/Swap In-Out) :当系统物理内存耗尽,内核把一部分长期不用的匿名内存页偷换到了磁盘的Swap分区。当进程下次访问这段内存时,会触发缺页中断(Page Fault),CPU必须强制切入D状态(不可中断睡眠),等待慢速的磁盘将数据读回内存。
内存紧凑/整理(Compaction) :当系统需要申请大块连续内存(如动态申请2MB的巨型页Transparent Huge Pages),而内存碎片化严重时,内核被迫在后台移动物理内存页。在移动期间,涉及到的进程必须挂起等待。
只要系统中有进程在上述三个坑里,这段浪费的时间就会被内核精准捕获,并按纳秒级等比例累加到内存的some和full的total计数器中。
字段含义拆解
以输出some avg10=1.20 ... total=5423312为例:
some avg10=1.20 :在过去10秒钟内,全系统有1.2%的时间(大约120毫秒)至少有一个进程在苦苦等待内存回收或Swap。
full avg10=0.10:在过去10秒钟内,全系统有0.1%的时间(大约10毫秒),所有的非空闲进程全部等在内存回收上,全系统算力完全冻结。
诊断健康阈值
传统的free -m监控只告诉你内存用了95%,但无法告诉你系统卡不卡(因为95%可能是被健康的Page Cache占用了)。使用内存PSI可以实现精准诊断:
some > 5%,full == 0%(预警状态) :内核已经开始高频触发直接内存回收或轻微的 Swap。业务的长尾延迟(Tail Latency)开始受到冲击。
some 飙高,full > 1%(极度危险/雪崩前兆):系统正在遭受致命的Memory Thrashing(内存页抖动)。所有核心的CPU算力都在做毫无意义的Swap读写或直接回收,整个服务器处于"濒死打摆子"状态。
io
Linux内核调优与系统监控体系中,PSI IO(Pressure Stall Information for IO)是用来量化系统 "块设备输入输出(I/O)饥饿程度" 的核心机制。当大并发写日志、数据库高频刷盘、或者网络存储(如NFS、Ceph)遭遇网络抖动时,磁盘I/O往往会成为全系统的瓶颈。与内存压力相似,IO压力报告中也同时包含some和 full两个轴,用以精确评估存储瓶颈对业务吞吐量的真实杀伤力。
c
cat /proc/pressure/io
some avg10=2.30 avg60=1.15 avg300=0.42 total=8432114
full avg10=0.50 avg60=0.20 avg300=0.04 total=1231145IO 资源能够完美触发这两种压力状态,其物理边界定义非常清晰:
-
some(部分进程因IO受阻)
定义 :在指定的滑动窗口内,系统中有至少一个(或一部分)非空闲进程,因为发起了I/O请求(如等待磁盘读数据回传),而被迫陷入阻塞(处于不可中断睡眠的D状态),而此时其他核心上的进程由于不需要读写磁盘,还在正常推进业务。
描述:服务器上负责写日志的线程因为磁盘太慢卡住发呆了,但负责计算核心逻辑的线程由于数据都在内存里,还在全速运行。系统的整体响应速度(Latency)开始变慢。
-
full(全系统非空闲进程被IO卡死)
定义 :在指定的滑动窗口内,系统中所有正在运行(非空闲)的进程,在同一个瞬间全部因为等待I/O资源而陷入阻塞状态。此时,CPU完全处于闲置(iowait)状态,没有一个进程能在用户态推进有用的业务。
描述:全系统的核心业务都在高频读写一个已经卡死的磁盘(或者断线的网络存储),导致所有活着的线程全部进入D状态。虽然CPU 利用率是0%,但全系统的算力和有用吞吐量在这一瞬间彻底冻结。
IO PSI的打点和计账代码深度内嵌在Linux内核的块设备层(Block Layer)、文件系统层(VFS/FS)以及页缓存管理(Page Cache)中。它主要由以下三个内核事件驱动累加:

同步读与缺页阻塞(Sync Read/Page Fault) :当进程发起read系统调用,或者访问一段通过mmap映射文件的内存却发生了缺页中断(Page Fault)时,内核必须跨越慢速的总线去物理磁盘上读取数据。在数据未回传、硬中断未返回之前,调度器会将进程切入TASK_UNINTERRUPTIBLE(D状态)。
强制同步刷盘(Synchronous Writes/fsync) :默认情况下,普通的异步write只是写到了内存的页缓存(Page Cache)中,速度极快。但当数据库执行预写日志(WAL)或应用显式调用fsync、fdatasync时,为了保证数据不丢失,进程会原地卡死挂起,直到磁盘硬件发出"写入成功"的物理电信号,进程才能被重新唤醒。
脏页回写阻塞(Direct Writeback Reclaim):当系统内的写操作极其疯狂,导致内存中的脏页(Dirty Pages)超过了内核设置的硬性限额(vm.dirty_ratio)时,内核会强制剥夺当前正在写入的进程的算力,逼迫它在当前上下文中原地停下,同步去执行磁盘写入,直到脏页降到安全线。
字段含义拆解
以输出 some avg10=2.30 ... total=8432114 为例:
some avg10=2.30 :在过去10秒钟内,全系统有2.3%的时间(大约230毫秒)至少有一个进程卡在磁盘I/O读写上。
full avg10=0.50:在过去10秒钟内,全系统有0.5%的时间(大约50毫秒),所有存活的业务进程全部因为磁盘响应慢而陷入D状态,系统吞吐量在此期间降为0。
诊断健康阈值
传统的iostat监控工具只能告诉你磁盘的%util(利用率)是100%,或者吞吐量是 200MB/s。但它无法告诉你:这个100%的利用率到底有没有把上层的业务给拖慢的。使用IO PSI可以实现精准跨层诊断:
some > 5%,full == 0%(存储亚健康) :系统的存储I/O已经出现排队。部分涉及到磁盘读写的接口响应时间(Latency)已经出现长尾。但是,由于架构做好了读写分离或异步化,非I/O业务目前依然能正常跑满CPU。
some 狂飙,full > 2%(存储引发系统级雪崩):全系统业务进程已经被慢速I/O彻底拖垮。由于核心线程全卡在了fsync或同步读上,导致连接池满、请求积压,全系统进入假死状态。
在实际生产排查中,性能调优架构师必须具备一个高级视角:IO压力常常和内存压力是一对形影不离的"孪生恶魔"。
隐蔽链条 :当你的系统物理内存严重不足时,内核为了腾出空间,会高频地触发直接内存回收(Direct Reclaim)。内核回收内存的最佳手段就是把内存中的文件页"扔掉"。
引发恶果 :当被扔掉的文件页再次被业务访问时,系统被迫高频地触发缺页中断,重新去磁盘读取文件。
指标表现 :此时你会看到/proc/pressure/memory飙高,而紧接着/proc/pressure/io也会连带暴涨。
解决方案:此时问题的根源根本不是磁盘太慢,而是内存不够。盲目去升级SSD固态硬盘无法解决问题,唯有加内存或优化内存泄漏才是正解。
irq
Linux内核调优与系统监控体系中,PSI IRQ(Pressure Stall Information for IRQ)在Linux 6.1内核版本中正式引入,专门用于量化系统由于硬件中断(Hard IRQ)和软中断(SoftIRQ)风暴引发的"算力剥夺"与业务停顿。与CPU压力只有some轴、内存/IO压力同时拥有两个轴不同,PSI IRQ机制最特殊的物理特性是:它只包含full轴,没有some轴。
https://docs.kernel.org/accounting/psi.html
c
cat /proc/pressure/irq
full avg10=0.25 avg60=0.12 avg300=0.02 total=3753500244在底层物理和内核逻辑上,这个设计非常巧妙:
硬件中断的"霸道"特性 :当一个物理硬件中断(如网卡收包)降临在CPU核心上时,它具有最高执行优先级。它会瞬间无条件强行打断当前CPU上正在运行的任何用户态业务进程或内核态线程(上下文硬切换)。
为什么是full :在中断处理程序(IRQ Handler)运行的期间,当前CPU核心上原本的那个进程只能被迫原地完全悬挂卡死。在这一瞬间,该核心在用户态业务上的吞吐量和有用产出直接降为绝对的0(因为所有算力都被中断强行抢走了)。
为什么没有 some:some代表"资源有竞争,有人在用,有人在排队等待"。但中断不是应用层排队,它是强行抢占。中断来的时候,没有"一部分进程可以继续跑,另一部分排队"的概念,它一落地就会立刻将当前核心的业务算力百分之百抽空,表现为局部业务推进的完全冻结。因此,内核将其归类为full压力。
PSI IRQ的代码高度集成在内核调度器与时钟统计模块中。它的启用有一个严苛的前提:内核编译时必须开启了CONFIG_IRQ_TIME_ACCOUNTING=y(中断时间精确统计)。

打点监控 :当CPU遇到硬件中断或软中断,陷入内核热路径(Hotpath)时,内核会高频触发 psi_account_irqtime钩子函数。
时间差值结算 :内核通过读取高精度硬件时钟源(如 TSC),精准记录中断从"咬住 CPU"到"释放 CPU"之间的纯物理纳秒差值。
压力等比例转换:这段由于处理中断而白白导致用户态业务完全停顿的物理时间,会被等比例累加到对应CPU核心及全局的total计数器中,最终通过移动平均算法转化为 10s、60s、300s窗口的百分比指标。
字段含义拆解
以输出 full avg10=0.25 avg60=0.12 avg300=0.02 total=3753500244为例:
avg10=0.25 :在过去10秒钟内,全系统平均有0.25%的CPU物理算力被中断风暴硬生生抢走,导致业务进程发生阶段性假死或挂起。
total=3753500244:该服务器自开机以来,全系统由于处理硬/软中断导致业务进程完全停顿的累计总时间(单位:微秒,此处约合3753.5秒)。
诊断健康阈值
由于中断处理通常只有微秒级,在正常机器上,full指标应该常年无限趋近于0.00。
avg10 > 1%(中度警告) :系统已经产生了肉眼可见的"中断抖动"。高频交易系统、实时音视频处理的长尾延迟(Tail Latency)开始受到冲击。
avg10 > 5%(重度卡顿 / 中断风暴):这意味着系统有超过5%的绝对算力在给硬件打杂(处理中断),业务吞吐量面临严重劣化。
stat
"/proc/pressure/stat"不是标准的上游(linux kernel)内核接口,而是企业级国产操作系统 openEuler(如基于kernel 6.6或OLK-6.6的openEuler 24.03 等版本)中,由华为内核团队专门为"高性能容器资源视图(ICA1GK)"定制引入的高级扩展 PSI 统计接口。
https://gitee.com/openeuler/kernel/issues/ICPMAC
c
cat /proc/pressure/stat
cgroup_memory_reclaim
some avg10=0.00 avg60=0.00 avg300=0.00 total=3103791
full avg10=0.00 avg60=0.00 avg300=0.00 total=3096017
global_memory_reclaim
some avg10=0.00 avg60=0.00 avg300=0.00 total=0
full avg10=0.00 avg60=0.00 avg300=0.00 total=0
compact
some avg10=0.00 avg60=0.00 avg300=0.00 total=0
full avg10=0.00 avg60=0.00 avg300=0.00 total=0
cgroup_async_memory_reclaim
some avg10=0.00 avg60=0.00 avg300=0.00 total=0
full avg10=0.00 avg60=0.00 avg300=0.00 total=0
swap
some avg10=0.00 avg60=0.00 avg300=0.00 total=0
full avg10=0.00 avg60=0.00 avg300=0.00 total=0
cpu_cfs_bandwidth
full avg10=0.00 avg60=0.00 avg300=0.00 total=0cgroup_memory_reclaim(容器级内存回收) :
进程由于触发了Cgroups(容器)级别的内存上限(memory.max或memory.high),被迫在当前容器的内存子系统中执行局部的直接内存回收(Direct Reclaim)所导致的业务停顿时间。
global_memory_reclaim(全局内存回收) :
全系统的物理内存耗尽,触发了全局的直接内存回收(非Cgroups限制)。
compact(内存碎片整理) :
当应用或内核申请大块连续内存(如 Hugepages 巨型页,或者驱动申请大块连续 DMA 内存)时,如果物理内存碎片化严重,内核被迫在后台高频搬移物理页。搬移期间进程必须挂起等待。
cgroup_async_memory_reclaim(容器异步内存回收) :
由后台异步回收线程在没有越过硬硬性水位线时,悄悄在后台帮容器回收内存的时间损耗。
swap(页交换) :
进程访问的代码或数据被交换到了慢速的Swap分区,引发缺页中断,CPU强行切入D状态等待数据从磁盘读回内存。
cpu_cfs_bandwidth(CPU容器限流) :
在云原生场景中,如果一个容器的CPU算力超出了你在 Kubernetes/Docker 中设置的配额限制(如 cpu.cfs_quota_us),内核的CFS调度器将该容器内所有的可运行进程进行限流(Throttled),直到下一个周期到来才释放。
相关结构
c
struct rq {
......
u64 psi_irq_time; 用于PSI(压力停滞信息)的中断时间
......
};
struct task_struct {
......
unsigned sched_psi_wake_requeue:1; 用于PSI(压力停滞信息)唤醒重新排队
unsigned in_memstall:1; 进程是否因内存不足而停滞
unsigned int psi_flags; PSI标志
......
};
struct psi_group_cpu { 每个CPU上维护的PSI组的数据结构
第一缓存行(由调度器更新):
unsigned int tasks[NR_PSI_TASK_COUNTS]
____cacheline_aligned_in_smp; 用于统计处于不同状态的任务数量。任务状态通常包括:可运行(但等待CPU)、等待内存、等待IO等
u32 state_mask; 表示哪些压力状态是活跃的(即当前有任务正在经历该种阻塞)。它是由tasks数组中的计数推导出的聚合压力状态
u32 times[NR_PSI_STATES]; 记录每个压力状态的累计时间(以纳秒为单位)。这些状态通常包括:一些延迟(例如,CPU、内存、IO的压力状态)
u64 state_start; 记录上次任务状态变化的时间(使用运行队列的时钟,即rq_clock)。用于计算状态持续的时间
第二缓存行(由聚合器更新):
u32 times_prev[NR_PSI_AGGREGATORS][NR_PSI_STATES]
____cacheline_aligned_in_smp; 第一维是聚合器的数量(NR_PSI_AGGREGATORS),第二维是压力状态数(NR_PSI_STATES)。用于存储之前采样周期的累计时间,以便检测增量(即每个周期内新增的延迟时间)
};