一、 投影(Projection):精准控制数据返回
投影操作对应 find() 方法的第二个参数,其核心作用是控制返回文档中包含或排除的字段。合理使用投影不仅能减少网络传输开销,还能触发底层的"覆盖索引(Covered Query)"优化。
1. 包含与排除的严格互斥规则
在 MongoDB 中,投影字段的值 1 表示包含,0 表示排除。一个极其重要且常被忽视的规则是:除 _id 字段外,禁止在同一个投影文档中混用包含和排除操作。
- 合法操作 :
db.collection.find({}, { name: 1, _id: 0 })(仅包含 name,并显式排除默认的 _id)。 - 非法操作 :
db.collection.find({}, { name: 1, balance: 0 })(执行将直接报错)。
2. 数组投影的"三剑客"
当文档中包含数组字段时,MongoDB 提供了三种强大的投影操作符,需根据业务场景精准选择:
$slice:按位置截取数组子集。不进行条件过滤,仅支持偏移量和数量(支持负数)。
{<field>: { $slice: [ <skip>, <limit>] } } 或 { contact: { slice: `` } } 例如:`{ contact: { slice: [1, 2] } }截取第 2 和第 3 个元素。{ contact: { slice: 3 } }` (返回数组的前 3 个元素) `{ contact: { slice: -2 } }` (返回数组的最后 2 个元素)$elemMatch:返回数组中首个满足独立筛选条件的元素。适用于投影内需要定义独立查询条件的场景。$(位置操作符) :复用find()查询条件,返回数组中首个匹配的元素。适用于查询与投影条件完全一致的场景,避免重复书写条件。
二、 排序(Sort):执行顺序与内存限制
排序操作通过 sort() 方法实现,{ field: 1 } 为升序,{ field: -1 } 为降序。排序不仅是数据展示的需求,更是分页查询和排行榜等场景的性能瓶颈所在。
1. 核心执行顺序:Sort → Skip → Limit
无论代码中的书写顺序如何,MongoDB 查询引擎在处理游标时,强制遵循以下执行顺序:
先排序(SORT) → 再跳过(SKIP) → 最后限制(LIMIT) 。
这意味着,即使你只需要第 10 页的 10 条数据,数据库也必须先将前 100 条数据全部在内存中排好序,然后丢弃前 90 条。这也是为什么在大数据量分页时,过度依赖 skip() 会导致严重性能问题的原因。
2. 内存排序的 100MB 限制
当 MongoDB 无法利用索引完成排序时,必须将数据加载到内存中进行内存排序。为了防止耗尽系统资源,MongoDB 对内存排序设置了严格的 100MB 限制。如果排序数据超过此阈值,查询将直接失败并抛出 Sort exceeded memory limit 错误。
- 解决方案 1(最优):创建复合索引,让排序操作直接走索引扫描(IXSCAN),完全避免内存排序。
- 解决方案 2 :在聚合管道(Aggregation)中使用
.allowDiskUse(true),允许将临时排序结果溢写到磁盘。
三、 投影与排序的底层交互与优化
1. 查询执行流程图
以下流程图展示了 MongoDB 处理带有投影和排序的查询时的底层执行逻辑:
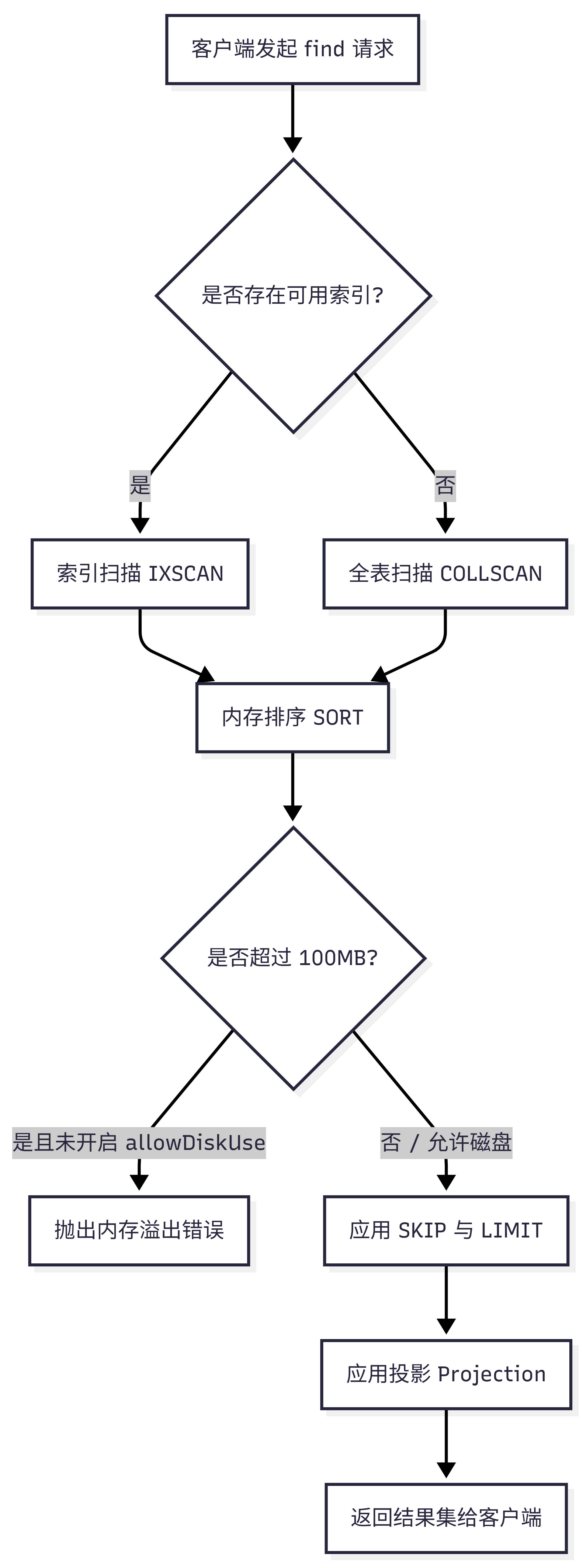
2.核心机制对比与总结
| 维度 | 投影 (Projection) | 排序 (Sort) |
|---|---|---|
| 核心作用 | 减少网络 I/O,触发覆盖索引 | 数据有序展示,支撑分页与聚合 |
| 语法规范 | 1(包含)/0(排除),除 _id 外严禁混用 |
1(升序)/-1(降序),支持多字段复合排序 |
| 性能瓶颈 | 返回过多无用大字段导致带宽浪费 | 内存排序超 100MB 报错,深分页性能差 |
| 最佳实践 | 始终显式指定所需字段,排除 _id |
结合复合索引遵循 ESR 规则,大分页用范围查询替代 skip |
3. 架构级优化建议:ESR 规则
在设计复合索引以同时支持过滤、排序和投影时,应遵循 ESR(Equality, Sort, Range)规则:
- E (Equality):将精确匹配的过滤条件字段放在索引最左侧。
- S (Sort):将排序字段紧跟其后。
- R (Range):将范围查询字段放在最后。
遵循此规则创建的索引,能够确保 MongoDB 在排序阶段直接通过索引顺序获取数据,彻底消除内存排序开销。
使用正确的索引消除内存排序,本质上是把"运行时的计算开销(CPU排序)"转化为了"写入时的存储开销(维护B-Tree的有序性)" 。 因为数据在写入数据库时就已经被 B-Tree 结构排好序了,查询时自然就可以直接"坐享其成",从而彻底避免了内存排序。
四、 综合实战演练:电商订单列表查询
1.投影,排序,limit查询
在实际业务中,投影与排序通常是配合使用的。以下我们将通过一个电商系统的真实场景,从数据准备到查询结果,完整演示如何优雅地编写 find 语句。
1. 场景背景
假设我们有一个订单集合 orders,包含大量历史数据。现在前端需要展示一个"最新订单列表",要求:
- 仅展示
orderNo(订单号)、userName(用户名)、amount(金额)和status(状态)。 - 不需要返回默认的
_id字段。 - 按照订单创建时间
createTime从新到旧(降序)排列。 - 仅展示最新的 10 条记录。
2. 测试数据准备
为了直观展示查询效果,我们先向 orders 集合中插入 5 条模拟数据(实际生产中可能是百万级数据):
javascript
db.orders.insertMany([
{ orderNo: "ORD20231024001", userName: "Alice", amount: 199.00, status: "PAID", createTime: ISODate("2023-10-24T10:00:00Z") },
{ orderNo: "ORD20231023098", userName: "Bob", amount: 59.90, status: "SHIPPED", createTime: ISODate("2023-10-23T14:30:00Z") },
{ orderNo: "ORD20231023095", userName: "Charlie", amount: 320.50, status: "PENDING", createTime: ISODate("2023-10-23T09:15:00Z") },
{ orderNo: "ORD20231022012", userName: "David", amount: 88.00, status: "PAID", createTime: ISODate("2023-10-22T18:00:00Z") },
{ orderNo: "ORD20231021005", userName: "Eve", amount: 450.00, status: "CANCELED", createTime: ISODate("2023-10-21T08:45:00Z") }
]);3. 基础 find 实战代码
结合投影(第二参数)与排序(sort 方法),标准的 MongoDB 查询语句如下:
javascript
db.orders.find(
{}, // 1. 查询条件:无过滤条件,查询所有
{ // 2. 投影(Projection):精确控制返回字段
orderNo: 1,
userName: 1,
amount: 1,
status: 1,
_id: 0 // 显式排除默认的 _id 字段
}
)
.sort({ createTime: -1 }) // 3. 排序(Sort):按创建时间降序
.limit(3) // 4. 限制:为演示方便,这里取前 3 条(实际业务中为 10)4. 预期查询结果
执行上述命令后,MongoDB 将严格按照 createTime 降序排列,并返回高度精简的结果集(去除了 _id 及未投影的字段),极大减少了网络带宽的消耗:
json
[
{ "orderNo": "ORD20231024001", "userName": "Alice", "amount": 199.00, "status": "PAID" },
{ "orderNo": "ORD20231023098", "userName": "Bob", "amount": 59.90, "status": "SHIPPED" },
{ "orderNo": "ORD20231023095", "userName": "Charlie", "amount": 320.50, "status": "PENDING" }
]5. 执行分析(explain)
在生产环境中,强烈建议使用 .explain("executionStats") 来验证上述 find 语句的执行计划。
- 理想情况 :如果我们在
{ createTime: -1 }上建立了索引,且投影的字段都在索引中(覆盖索引),executionStats中的executionTimeMillis应为 0 或极小,且stage为IXSCAN(索引扫描),SORT阶段的nReturned为 3。 - 危险信号 :如果
stage出现了SORT且sortAlgorithm为external(外部排序),说明数据量已经超出了内存排序的限制,此时必须立刻检查是否遗漏了排序字段的索引。
2.数组投影"三剑客"
在电商或内容系统中,文档内嵌套数组是非常常见的数据结构。假设我们有一个商品集合 products,里面包含商品信息和多个评论。
1. 测试数据准备
首先,我们插入两条包含 comments 数组的模拟数据:
javascript
db.products.insertMany([
{
productName: "机械键盘",
comments: [
{ user: "Alice", score: 90, text: "手感极佳" },
{ user: "Bob", score: 60, text: "有点重" },
{ user: "Charlie", score: 85, text: "性价比不错" }
]
},
{
productName: "无线鼠标",
comments: [
{ user: "David", score: 40, text: "经常断连" },
{ user: "Eve", score: 95, text: "办公神器" }
]
}
]);2. 三剑客实战演示
① $slice(按位置截取子集)
-
业务场景:在商品列表页,只展示每款商品最新的 2 条评论。
-
实战命令 :
javascriptdb.products.find({}, { productName: 1, comments: { $slice: -2 } }) -
查询结果 (以机械键盘为例,返回数组的最后 2 个元素):
json{ "productName": "机械键盘", "comments": [ { "user": "Bob", "score": 60, "text": "有点重" }, { "user": "Charlie", "score": 85, "text": "性价比不错" } ] }
② $elemMatch(独立条件匹配首个元素)
-
业务场景 :在商品详情页,需要单独高亮展示一条"高分好评"(
score >= 85),但不关心查询条件是什么。 -
实战命令 :
javascriptdb.products.find( { productName: "机械键盘" }, { productName: 1, comments: { $elemMatch: { score: { $gte: 85 } } } } ) -
查询结果 (仅返回
comments数组中第一个满足score >= 85的元素):json{ "productName": "机械键盘", "comments": [ { "user": "Alice", "score": 90, "text": "手感极佳" } ] }
③ $ 位置操作符(复用查询条件匹配)
-
业务场景:后台管理员想要快速定位并查看"用户 Bob 发表的那条评论"。此时,查询条件和投影条件完全一致。
-
实战命令 :
javascriptdb.products.find( { "comments.user": "Bob" }, // 查询条件 { productName: 1, "comments.$": 1 } // 投影复用上面的条件 ) -
查询结果 (精准提取出 Bob 的评论):
json{ "productName": "机械键盘", "comments": [ { "user": "Bob", "score": 60, "text": "有点重" } ] }
3. 核心差异总结
- 如果只想看"前几条/后几条",用
$slice。 - 如果想在投影时用一个"全新的条件"去捞数据,用
$elemMatch。 - 如果投影的条件和
find()里的查询条件一模一样,为了少写一遍代码,用$。
五、 常见面试题与深度解答
Q1:在 MongoDB 中,如果我执行 db.users.find().sort({age: 1}).limit(10),数据库是如何执行的?如果数据量达到千万级会有什么风险?
答 :执行顺序是严格的 SORT → LIMIT。数据库会先将所有匹配的文档按 age 升序排列,然后取前 10 条。如果数据量达到千万级且没有 {age: 1} 索引,数据库将尝试在内存中对千万级文档进行排序,一旦超过 100MB 限制就会直接报错崩溃。必须为 age 字段创建索引,使排序操作转化为低成本的索引扫描。
Q2:为什么 MongoDB 禁止在投影中混用包含(1)和排除(0)?
答 :这是由 MongoDB 底层文档构建引擎的设计决定的。混用会导致引擎在解析文档结构时产生歧义,增加不必要的 CPU 计算开销。为了保证查询计划的确定性和执行效率,官方强制要求投影逻辑必须清晰单一(全包含或全排除,_id 作为默认字段被特殊豁免)。
Q3:什么是"覆盖索引(Covered Query)"?投影在其中扮演什么角色?
答:当一个查询的所有过滤条件字段、排序字段以及投影字段都包含在同一个复合索引中时,MongoDB 可以直接从索引树中获取所有需要的数据,完全不需要回表(Fetch)查询原始文档。此时,投影操作是触发覆盖索引的关键条件之一,它能带来数量级的性能提升。
Q4:面对百万级数据的深度分页(如 skip(100000).limit(10)),除了创建索引,还有什么架构层面的优化方案?
答 :应弃用 skip,改用"基于范围的游标分页(Cursor-based Pagination)"。例如,记录上一页最后一条数据的 _id 或时间戳,下一页查询时使用 { _id: { $gt: last_id } } 进行过滤。这种方式无论翻到第几页,性能都等同于查询第一页,完美避开了 SORT → SKIP 带来的内存与计算开销。
Q4:面对百万级数据的深度分页(如 skip(100000).limit(10)),除了创建索引,还有什么架构层面的优化方案?
答 :应弃用 skip(),改用"基于范围的游标分页(Cursor-based Pagination)"。其核心思想是:以上一页最后一条记录的排序字段值作为下一页查询的起点,利用范围查询直接定位,从而完美避开 SORT → SKIP 带来的内存与计算开销。
** 实战演示:以"按创建时间倒序"为例**
假设有一个包含百万级数据的日志集合 logs,需要按 createdAt 降序分页展示。
第一步:创建复合索引(关键)
为了保证游标分页的高效性,必须将排序字段与 _id 结合建立复合索引,以确保排序的绝对唯一性(避免相同时间戳导致的数据丢失或重复):
javascript
db.logs.createIndex({ createdAt: -1, _id: -1 });第二步:获取第一页数据
第一页无需游标,正常查询即可。注意必须带上 limit,并记录最后一条数据的游标值:
javascript
// 获取第 1 页(每页 10 条)
let pageSize = 10;
let page1 = db.logs.find()
.sort({ createdAt: -1, _id: -1 })
.limit(pageSize)
.toArray();
// 提取上一页最后一条记录的游标(Cursor)
let lastDoc = page1[page1.length - 1];
let lastCreatedAt = lastDoc.createdAt;
let lastId = lastDoc._id;第三步:获取第二页及后续数据(核心)
下一页查询时,利用 $or 构造范围条件,从游标位置继续向后读取,完全不需要使用 skip():
javascript
// 获取第 2 页
let page2 = db.logs.find({
$or: [
// 条件 1:创建时间严格小于上一页最后一条的时间
{ createdAt: { $lt: lastCreatedAt } },
// 条件 2:创建时间相同,但 _id 严格小于上一页最后一条的 _id(保证唯一性)
{ createdAt: lastCreatedAt, _id: { $lt: lastId } }
]
})
.sort({ createdAt: -1, _id: -1 })
.limit(pageSize)
.toArray();性能对比与架构总结:
- 传统
skip方式:翻到第 10,000 页时,数据库需要扫描并丢弃前 99,990 条数据,耗时可能高达数秒,且 CPU 占用极高。 - 游标分页方式 :无论翻到第几页,查询复杂度始终为 O(logN)O(\log N)O(logN),响应时间稳定在毫秒级。
- 适用场景:此方案非常适合移动端 APP 的"无限滚动"、消息流、日志列表等场景。其唯一的限制是不支持"跳转到指定页码(如直接跳到第 500 页)",但在绝大多数现代业务中,用户体验更倾向于连续的上下翻页。