Python Requests库教程
-
- [1. Request库](#1. Request库)
-
- [1.1 Request库安装和简介](#1.1 Request库安装和简介)
- [2. 发送HTTP/HTTPS 请求语法](#2. 发送HTTP/HTTPS 请求语法)
-
- [1. 基本请求方法:](#1. 基本请求方法:)
- [2. 通用核心参数(所有请求都能用)](#2. 通用核心参数(所有请求都能用))
- 3.发送GET请求:获取数据
- [4. 发送POST请求](#4. 发送POST请求)
- [3. Session](#3. Session)
-
- [4. 超时处理 (Timeout)](#4. 超时处理 (Timeout))
- [5. 自动重试 (Retry)](#5. 自动重试 (Retry))
- [6. 身份认证 (Auth)](#6. 身份认证 (Auth))
- [7. JWT认证](#7. JWT认证)
- [8. 文件上传与下载](#8. 文件上传与下载)
- [6. Cookie 和 Session 的区别](#6. Cookie 和 Session 的区别)
- [7. 获取指定响应数据](#7. 获取指定响应数据)
-
- [1. 获取状态码](#1. 获取状态码)
- [2. 获取响应头](#2. 获取响应头)
- [3. 获取响应体](#3. 获取响应体)
- [4. 获取指定字段(从 JSON 响应中提取)](#4. 获取指定字段(从 JSON 响应中提取))
- [5. 案例](#5. 案例)
- [7. 处理编码问题](#7. 处理编码问题)
- [8. 异常情况处理](#8. 异常情况处理)
1. Request库
1.1 Request库安装和简介
简介
Requests 是一个基于 Python 编写的 HTTP 库,它构建在 urllib 之上,提供了更加简洁易用的 API。该库专门用于:
- 调用各类接口
- 发送 GET/POST 等 HTTP 请求
- 进行接口自动化测试
- 爬取网页数据
安装方法
方法一:命令行安装(最常用)
bash
pip install requests方法二:国内镜像加速(网络较慢时推荐)
bash
pip install requests -i https://pypi.douban.com/simple/安装成功后,命令行会显示类似下图的信息:
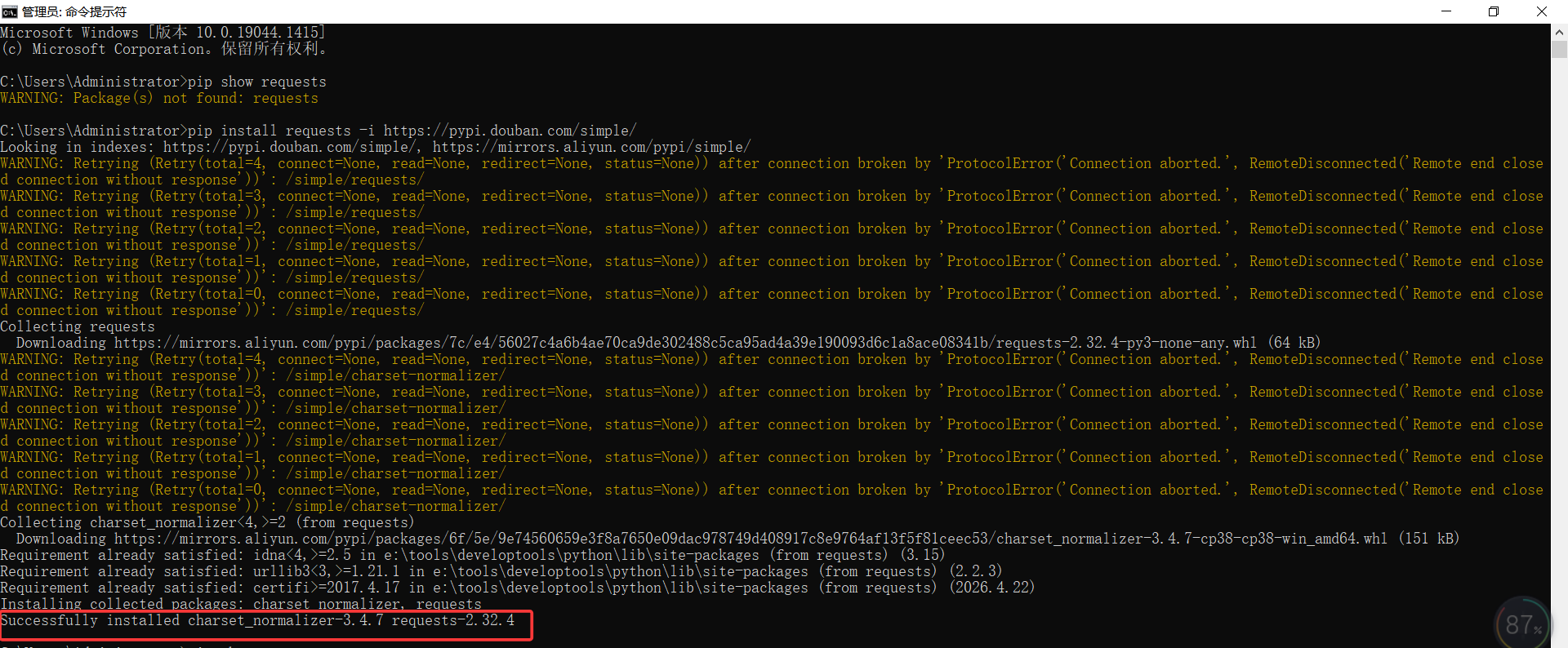
验证安装是否成功
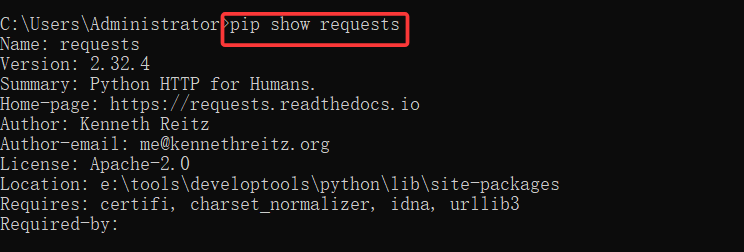
1. 通过 pip 查验
bash
pip show requests执行命令后会显示类似下图的版本信息:
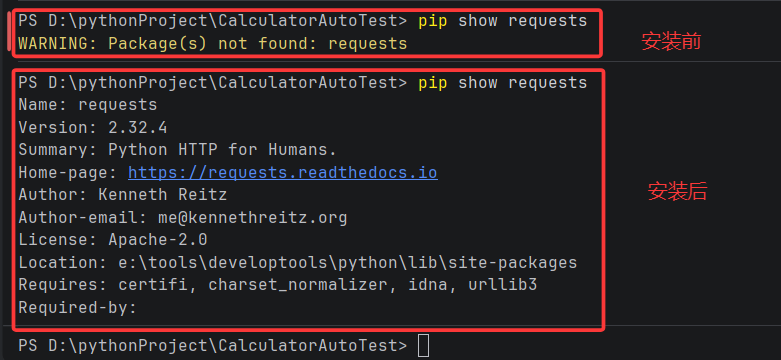
2. 在 PyCharm 中查验
- 命令行方式 :同样使用
pip show requests命令
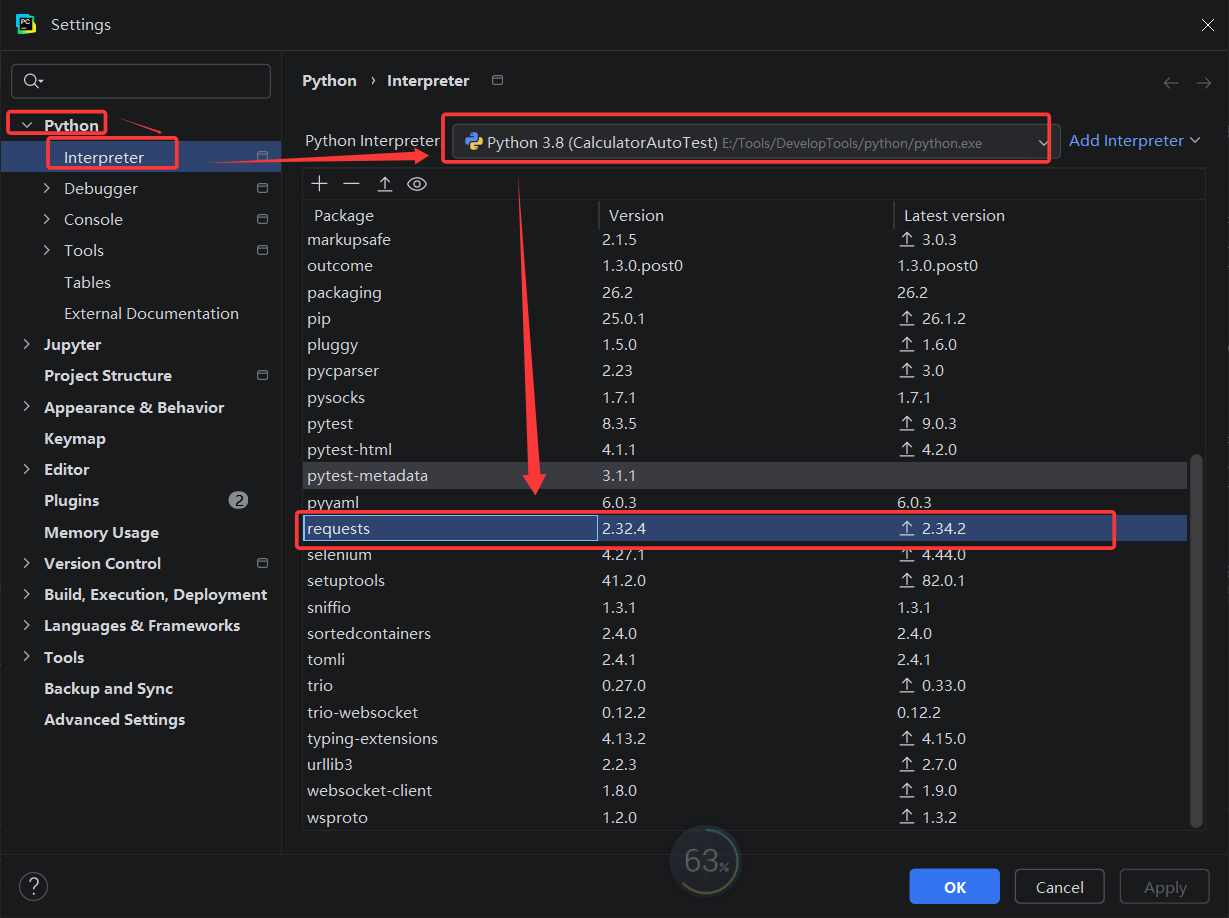
- 图形化界面方式:依次点击【File】→ 【Settings】→ 【项目名】→ 【Python】 → 【Interpreter】,在已安装包列表中查找 requests
2. 发送HTTP/HTTPS 请求语法
以下是 Requests 库发送 HTTP/HTTPS 请求 的核心语法总结,包含常见请求方法、参数说明和示例。
1. 基本请求方法:
kwargs 表示通用参数,下面详细说明。
- 请求方法列表:
| 方法 | 语法 | 说明 |
|---|---|---|
| GET | requests.get(url, params=None, **kwargs) | 获取资源 |
| POST | requests.post(url, data=None, json=None, **kwargs) | 创建资源 |
| PUT | requests.put(url, data=None, **kwargs) | 完整更新资源 |
| PATCH | requests.patch(url, data=None, **kwargs) | 部分更新资源 |
| DELETE | requests.delete(url, **kwargs) | 删除资源 |
| HEAD | requests.head(url, **kwargs) | 获取响应头 |
| OPTIONS | requests.options(url, **kwargs) | 获取支持的请求方法 |
2. 通用核心参数(所有请求都能用)
| 参数 | 说明 | 示例 |
|---|---|---|
| url | 请求地址 | url = 'https://www.baidu.com' |
| params | 字典或字节序列,拼接到 URL 的查询字符串 | params={'key':'value'} |
| data | 字典、字节或文件对象,作为表单数据发送 | data={'username':'test'} |
| json | 字典,自动序列化为 JSON 并设置 Content-Type: application/json | json={'title':'foo'} |
| headers | 字典,自定义请求头 | headers={'User-Agent':'my-app'} |
| cookies | 字典或 RequestsCookieJar,发送 Cookie | 字典或 RequestsCookieJar,发送 Cookie |
| auth | 元组 (用户名, 密码),支持 HTTP 基本认证 | auth=('user','pass') |
| timeout | 浮点数或元组 (连接超时, 读取超时),单位秒 | timeout=5 或 (3,5) |
| proxies | 字典,设置代理 | proxies={'http':'http://proxy:8080'} |
| verify | 布尔或字符串,控制 SSL 证书验证 | verify=False(跳过验证)或 verify='/path/cert.pem' |
| allow_redirects | 布尔,是否允许重定向(默认 True) | allow_redirects=False |
| stream | 布尔,是否流式下载响应体 | stream=True |
3.发送GET请求:获取数据
用 requests 从 JSONPlaceholder 获取一篇假文章
python
import requests
# 目标地址:获取id为1的待办事项(Todo)
url = "https://jsonplaceholder.typicode.com/todos/1"
# 发送GET请求
response = requests.get(url)
# 检查请求是否成功(状态码200表示成功)
if response.status_code == 200:
# 将返回的JSON数据解析为Python字典
todo_item = response.json()
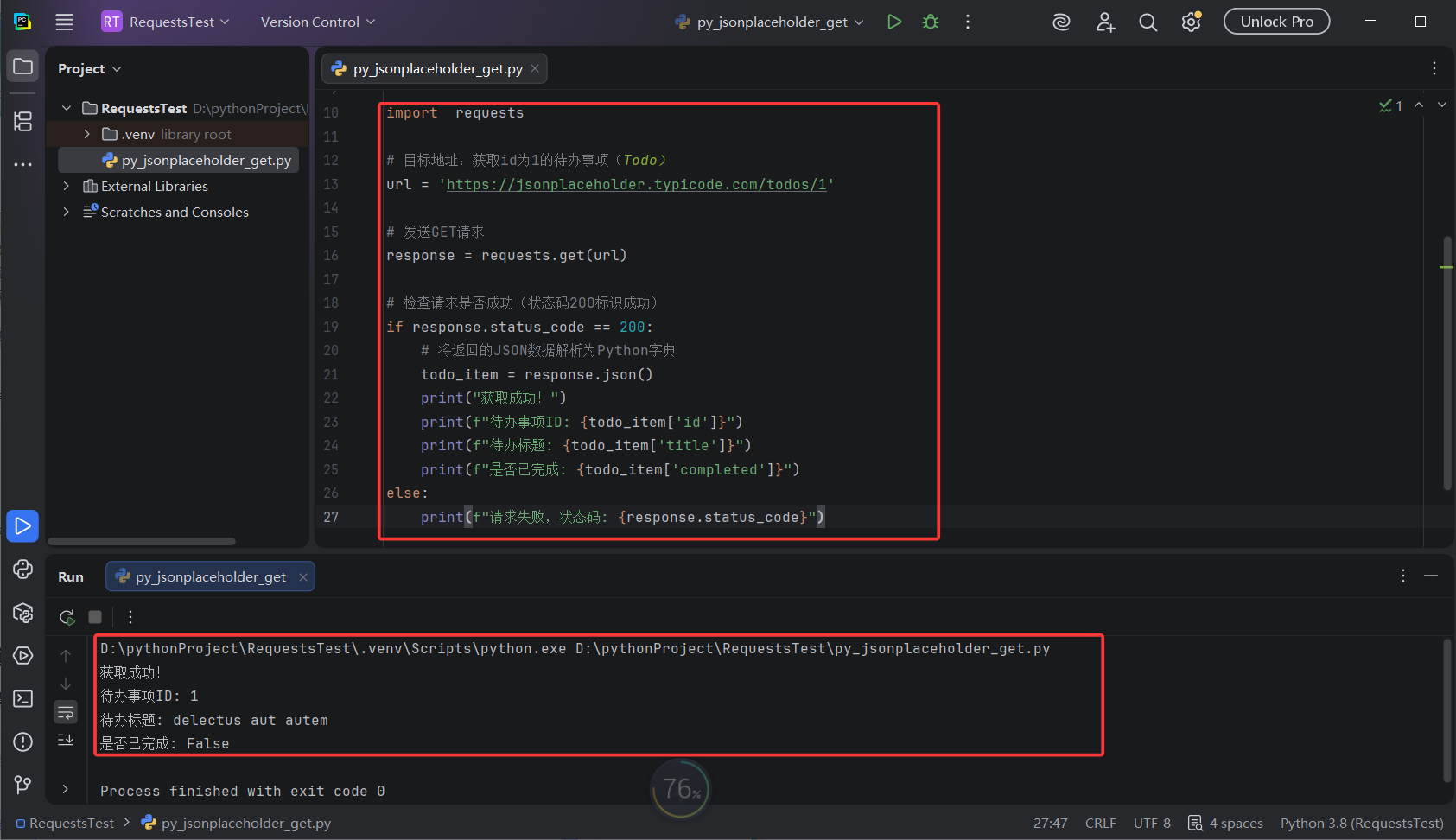
print("获取成功!")
print(f"待办事项ID: {todo_item['id']}")
print(f"待办标题: {todo_item['title']}")
print(f"是否已完成: {todo_item['completed']}")
else:
print(f"请求失败,状态码: {response.status_code}")执行结果:
4. 发送POST请求
与GET不同,POST请求通常用于向服务器提交数据,比如填写表单、发布新文章等。这里的关键区别在于数据的传递位置:
GET: 参数以 ?key1=value1&key2=value2 的形式放在 URL 后面。
POST: 数据放在请求的"身体"(Body)里。
① 提交表单数据 (data参数)
当你登录一个网站或提交一个搜索表单时,浏览器通常是以 application/x-www-form-urlencoded 这种表单格式提交数据的。httpbin.org 提供了一个 /post 接口来帮助我们模拟这个场景.
python
import requests
# httpbin的/post接口会返回你发送的任何请求数据
url = "https://httpbin.org/post"
# 准备要提交的表单数据
form_data = {
'username': 'test_user',
'password': 'hello_world',
'remember_me': 'yes'
}
# 发送POST请求,使用data参数来提交表单数据
response = requests.post(url, data=form_data)
if response.status_code == 200:
# 打印服务器返回的结果,其中'form'字段就是我们提交的数据
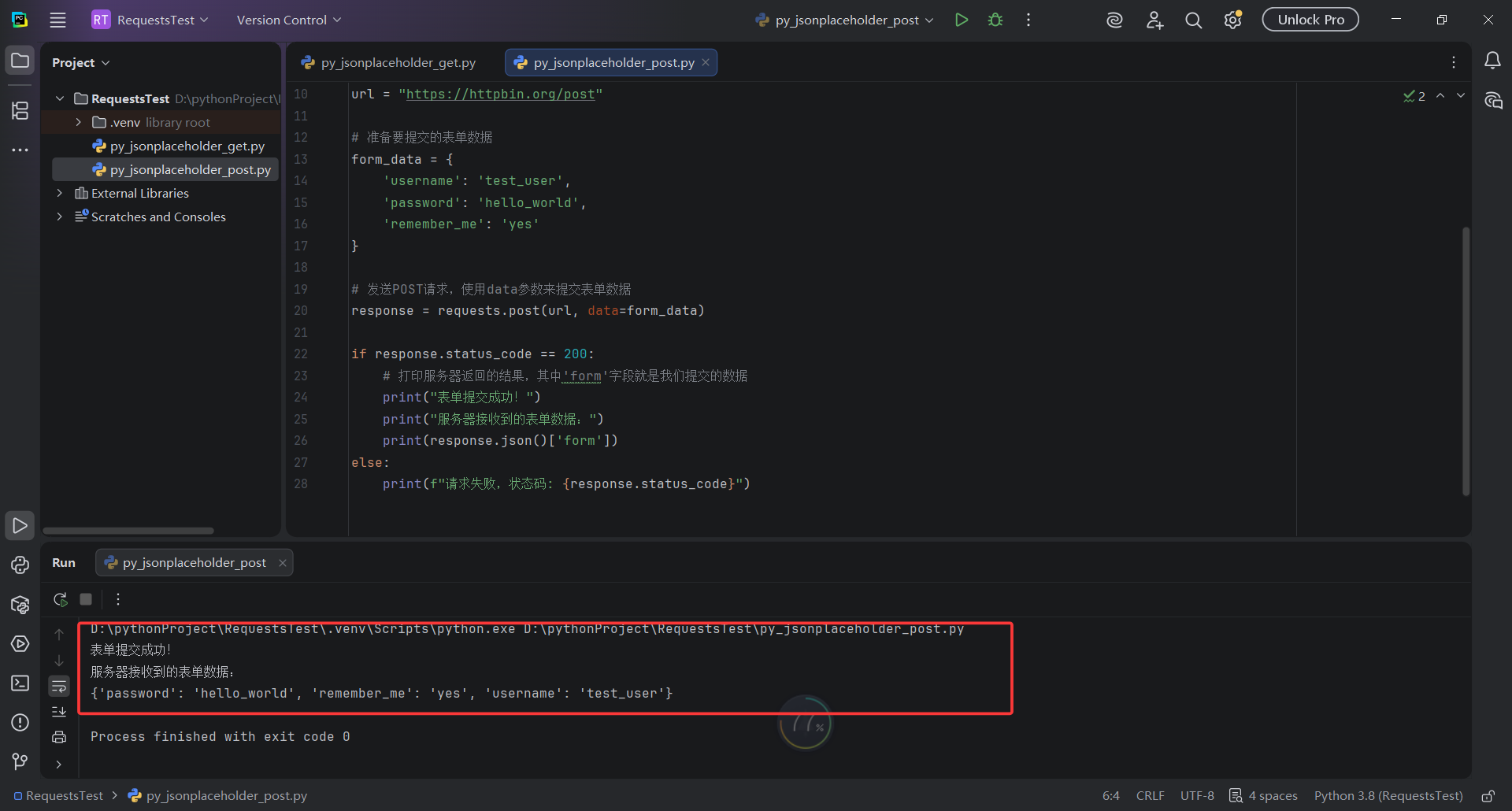
print("表单提交成功!")
print("服务器接收到的表单数据:")
print(response.json()['form'])
else:
print(f"请求失败,状态码: {response.status_code}")执行结果:
② 发送JSON数据 (json参数)
python
import requests
url = "https://jsonplaceholder.typicode.com/posts"
# 准备要提交的JSON数据,模拟一篇新的文章
new_post_data = {
'title': 'Hello, Requests!',
'body': 'This is a post created by Python Requests library.',
'userId': 1
}
# 发送POST请求,使用json参数来提交JSON数据
response = requests.post(url, json=new_post_data)
if response.status_code == 201: # 201 Created 是创建资源成功的标准状态码
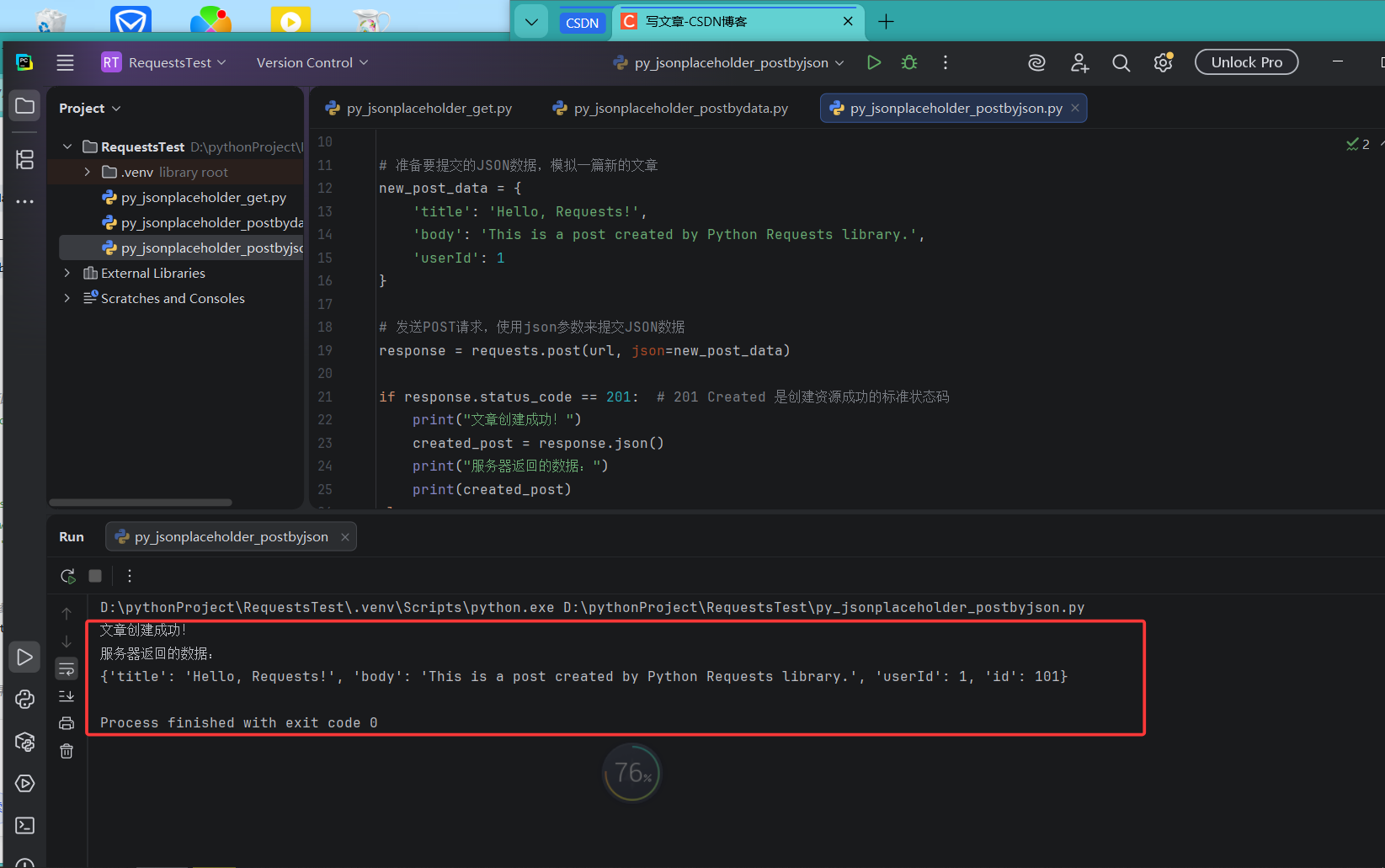
print("文章创建成功!")
created_post = response.json()
print("服务器返回的数据:")
print(created_post)
else:
print(f"请求失败,状态码: {response.status_code}")执行结果:
3. Session
当你登录一个网站后,网站可能会给你的浏览器设置一个"会话ID"(通常存储在Cookie中)。requests 库的 Session 对象可以自动帮你存储和发送这些会话信息,让你在连续请求中保持"已登录"状态。
python
import requests
# 创建一个Session对象
session = requests.Session()
# 模拟第一次访问,设置cookie (请求httpbin.org来设置一个cookie)
session.get('https://httpbin.org/cookies/set/session_id/123456')
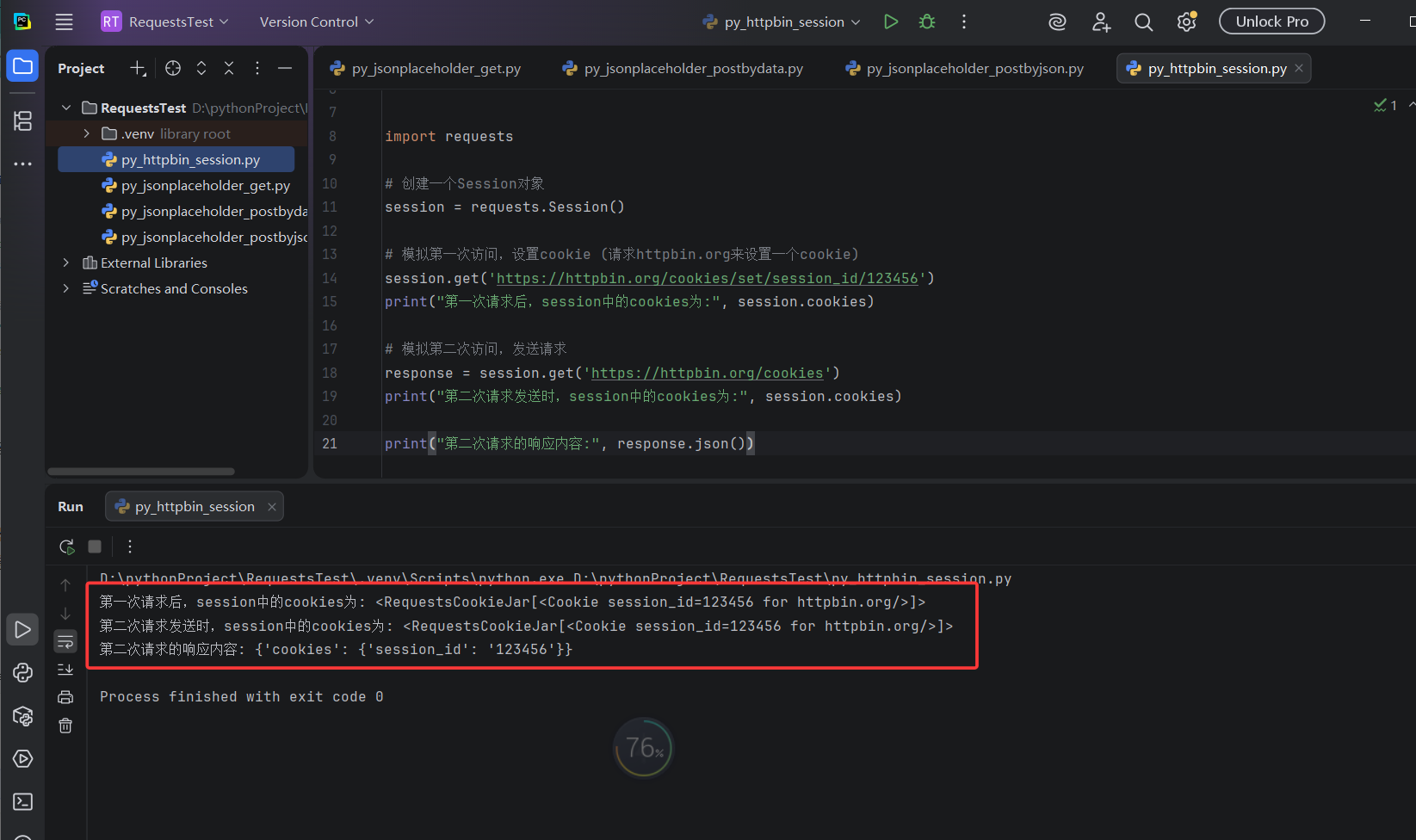
print("第一次请求后,session中的cookies为:", session.cookies)
# 模拟第二次访问,发送请求
response = session.get('https://httpbin.org/cookies')
print("第二次请求发送时,session中的cookies为:", session.cookies)
print("第二次请求的响应内容:", response.json())执行结果:
4. 超时处理 (Timeout)
在网络请求中,如果服务器迟迟没有响应,程序可能会一直卡住。为此,务必加上 timeout 参数,它告诉 requests:如果在规定秒数内没收到响应,就停止等待并报错。
python
import requests
from requests.exceptions import Timeout
url = "http://httpbin.org/delay/3" # 这个接口会故意延迟3秒再响应
try:
# 设置超时时间为1秒
response = requests.get(url, timeout=1)
except Timeout:
print("请求超时!服务器未在规定时间内响应。")5. 自动重试 (Retry)
网络波动不可避免,配置重试机制可大幅提升成功率:
python
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# 创建一个Session对象并挂载自定义的适配器
def requests_retry_session(
retries=3, # # 最多重试 3 次
backoff_factor=0.5, # 重试间隔: 1s, 2s, 4s...
status_forcelist=(500, 502, 504),# 遇到这些状态码时重试
):
session = requests.Session()
retry = Retry(
total=retries,
read=retries,
connect=retries,
backoff_factor=backoff_factor,
status_forcelist=status_forcelist,
)
adapter = HTTPAdapter(max_retries=retry)
session.mount('http://', adapter)
session.mount('https://', adapter)
return session
# 尝试访问一个故意挂掉的接口
url = 'https://httpbin.org/status/500' # 该接口会返回500错误
session = requests_retry_session()
try:
response = session.get(url, timeout=5)
print(f"最终响应状态码: {response.status_code}")
except requests.exceptions.RequestException as e:
print(f"请求最终失败: {e}")执行结果:
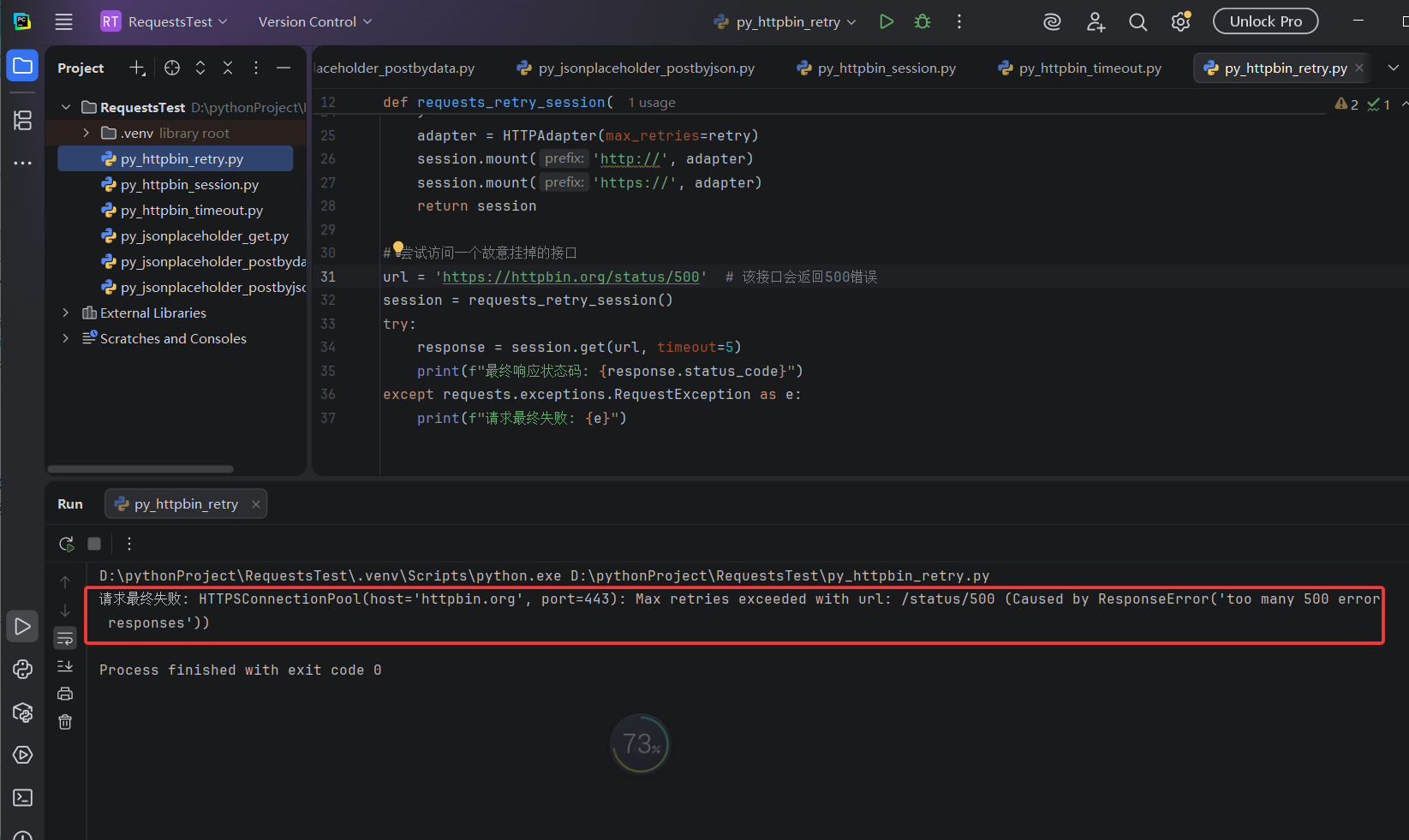
6. 身份认证 (Auth)
许多API需要身份验证才能访问。最常见的是"Basic Auth",即使用用户名和密码。requests 库通过 auth 参数提供了简洁的支持。
python
import requests
from requests.auth import HTTPBasicAuth
# 使用httpbin的/basic-auth/{user}/{passwd}接口进行测试
user = "testuser"
passwd = "testpass"
url = f"https://httpbin.org/basic-auth/{user}/{passwd}"
# 正确用户名和密码
response_correct = requests.get(url, auth=HTTPBasicAuth(user, passwd))
print("正确凭据:", response_correct.status_code) # 返回200
# 错误用户名和密码
response_wrong = requests.get(url, auth=HTTPBasicAuth("wrong", "wrong"))
print("错误凭据:", response_wrong.status_code) # 返回401执行结果:
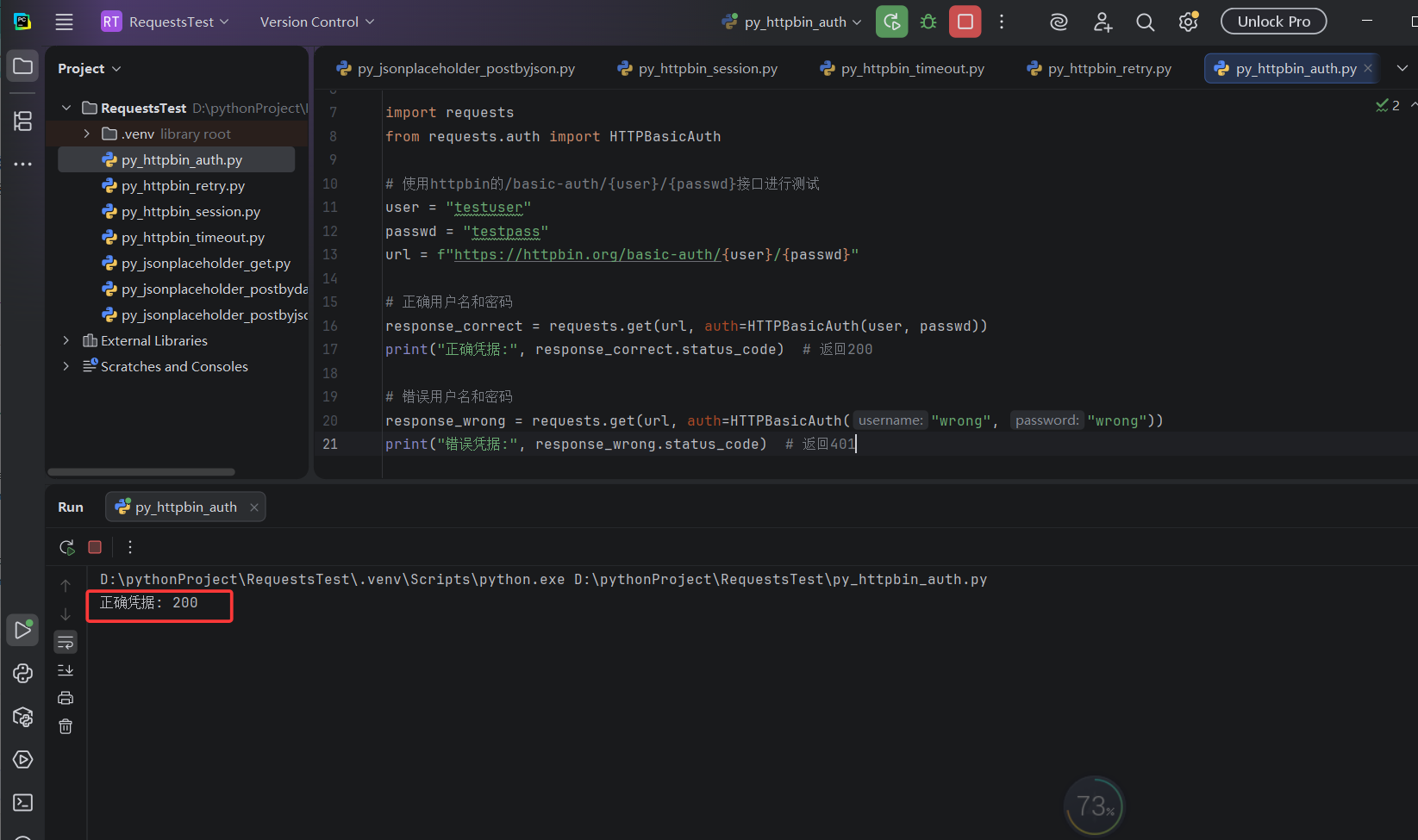
7. JWT认证
JWT是一串编码后的字符串,包含头部、载荷与签名,用于身份验证。在实际应用中,JWT通常由API的登录接口返回
python
import requests
# 1. 模拟获取到的JWT (演示令牌,实际来自登录接口)
demo_jwt = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c"
# 2. 发送受JWT保护的API请求
url = "https://httpbin.org/bearer" # 一个模拟Bearer Token认证的测试接口
headers = {
"Authorization": f"Bearer {demo_jwt}" # JWT以Bearer Token形式放入Authorization头
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print("JWT 认证成功!")
print("响应内容:", response.json())
else:
print(f"JWT 认证失败, 状态码: {response.status_code}")执行结果:
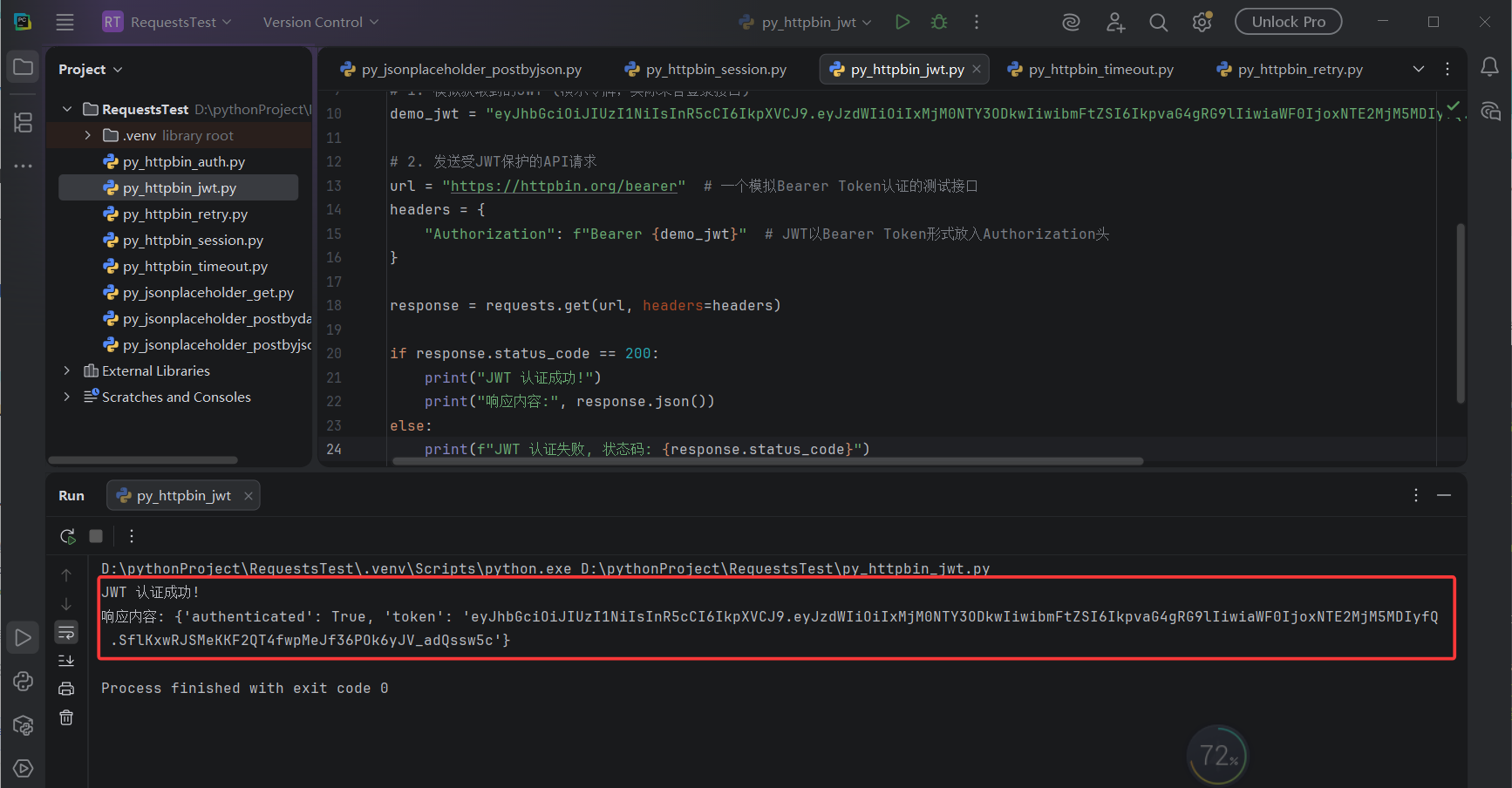
8. 文件上传与下载
python
import requests
import os
# ------------------ 上传测试 ------------------
def upload_single_file():
url = "https://httpbin.org/post"
test_file = "demo_upload.txt"
with open(test_file, "w") as f:
f.write("This is a test file for requests upload.")
with open(test_file, "rb") as f:
files = {"file": f}
response = requests.post(url, files=files)
os.remove(test_file) # 清理临时文件
if response.status_code == 200:
print("[上传] 成功,服务器回显内容:", response.json()["files"]["file"])
else:
print("[上传] 失败")
# ------------------ 下载测试 ------------------
def download_small_file():
url = "https://www.python.org/static/img/python-logo.png"
local = "python_logo.png"
response = requests.get(url, timeout=10)
response.raise_for_status()
with open(local, "wb") as f:
f.write(response.content)
print(f"[下载] 小文件保存为 {local},大小 {len(response.content)} 字节")
if __name__ == "__main__":
upload_single_file()
download_small_file()执行结果:
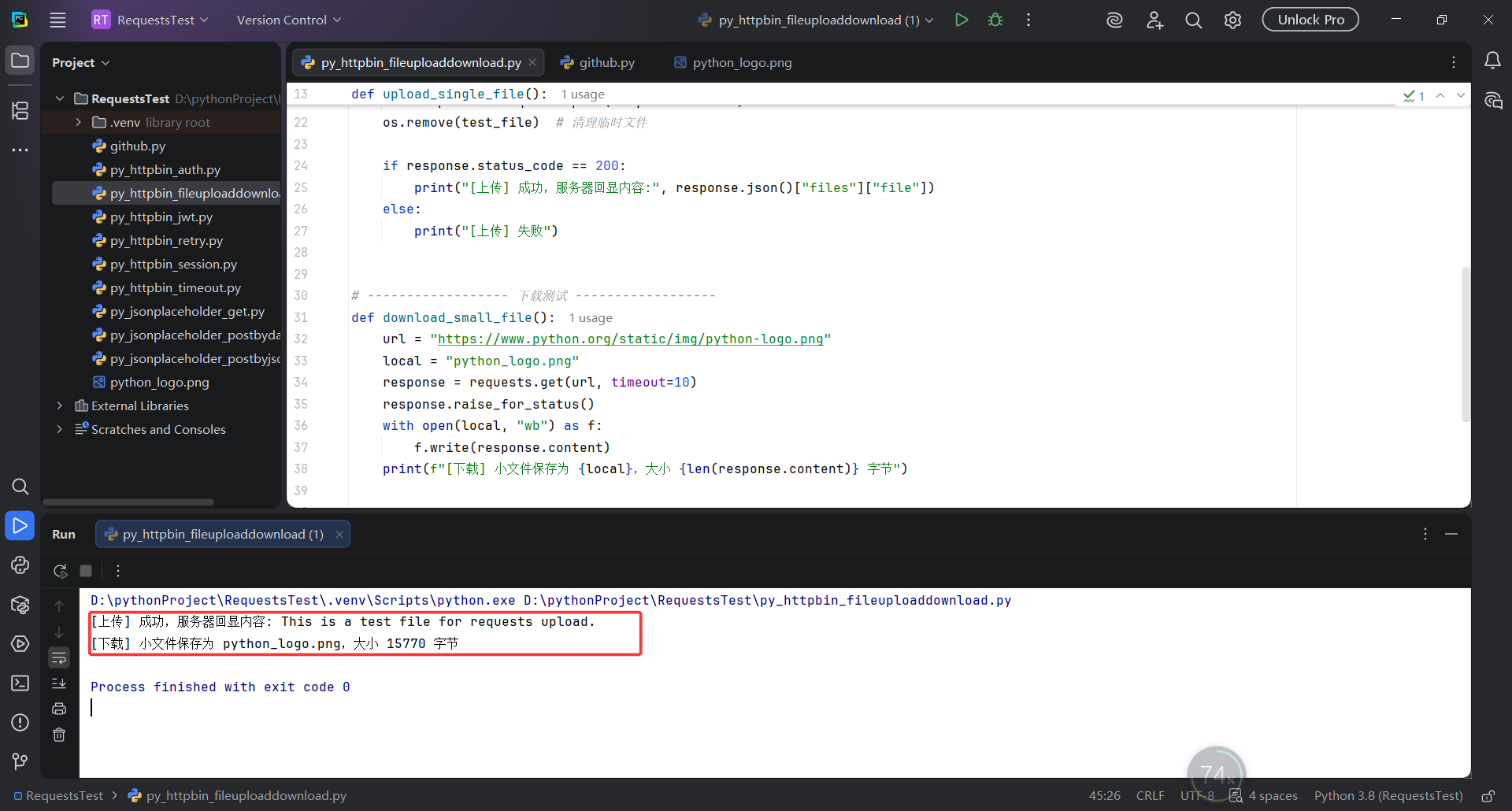
6. Cookie 和 Session 的区别
| 对比项 | Cookie | Session |
|---|---|---|
| 存储位置 | 浏览器(本地) | 服务器(内存 / 数据库) |
| 存储大小 | 很小(约 4KB) | 很大,无限制 |
| 安全性 | 低(可被查看、篡改) | 高(服务器控制,不可见) |
| 生命周期 | 可长期保存(设置过期时间) | 默认关闭浏览器就失效 |
| 数据类型 | 只能存字符串 | 可存对象、列表、字典等 |
| 依赖关系 | 不需要 Session | 不需要 Session |
工作原理:
- 用户第一次登录
- 服务器生成一个 Session(保存登录信息)
- 服务器把 SessionID 放进 Cookie 发给浏览器
- 之后每次请求,浏览器自动带上 Cookie
- 服务器通过 Cookie 里的 ID 找到 Session → 识别用户
7. 获取指定响应数据
1. 获取状态码
状态码表示请求结果(如 200 成功,404 未找到)。
python
import requests
response = requests.get('https://httpbin.org/status/200')
print(response.status_code) # 200常见状态码:
-
200 OK
-
201 Created
-
301 永久重定向
-
400 错误请求
-
401 未授权
-
403 禁止
404 未找到
500 服务器内部错误
2. 获取响应头
响应头以字典形式存储在 response.headers 中,键名不区分大小写。
python
response = requests.get('https://httpbin.org/get')
print(response.headers['Content-Type']) # application/json
print(response.headers.get('content-type')) # 同样有效
print(response.headers) # 打印所有响应头3. 获取响应体
根据返回内容的不同格式,有三种常用方式:
- 获取文本内容(.text): 适用于 HTML、XML、纯文本等。.text 会自动根据响应头中的 charset 解码,你也可以手动设置编码:
python
response = requests.get('https://httpbin.org/html')
print(response.text[:200]) # 打印前200个字符
#手动设置编码
response.encoding = 'utf-8'
print(response.text)- 获取二进制内容(.content): 适用于图片、文件、压缩包等。
python
response = requests.get('https://www.python.org/static/img/python-logo.png')
with open('python_logo.png', 'wb') as f:
f.write(response.content) # 直接保存二进制数据- 解析 JSON 数据(.json()): 适用于 API 返回的 JSON 格式数据,直接返回 Python 字典/列表。
python
response = requests.get('https://jsonplaceholder.typicode.com/posts/1')
data = response.json() # 解析为字典
print(data['title']) # 获取特定字段【注意】:如果响应不是 JSON 格式,.json() 会抛出 json.decoder.JSONDecodeError。
4. 获取指定字段(从 JSON 响应中提取)
获取指定字段(从 JSON 响应中提取):
示例:获取第一篇文章的标题
python
response = requests.get('https://jsonplaceholder.typicode.com/posts')
posts = response.json() # 列表,每个元素是一篇文章的字典
first_title = posts[0]['title']
print(first_title)5. 案例
python
import requests
# 1. GET 请求
url = "https://jsonplaceholder.typicode.com/posts/1"
resp = requests.get(url, timeout=5)
# 2. 获取状态码
print("状态码:", resp.status_code)
# 3. 获取响应头中的 Content-Type
print("Content-Type:", resp.headers.get('Content-Type'))
# 4. 获取 JSON 数据
post_data = resp.json()
# 5. 提取指定字段
print("文章ID:", post_data['id'])
print("标题:", post_data['title'])
print("内容:", post_data['body'][:50] + "...")7. 处理编码问题
有时响应文本乱码,可以手动指定或自动检测。
python
# 手动设置编码
response.encoding = 'utf-8'
# 或使用 chardet 自动检测(需安装 chardet 库)
# import chardet
# encoding = chardet.detect(response.content)['encoding']
# response.encoding = encoding8. 异常情况处理
网络请求可能失败,建议捕获异常。
python
try:
response = requests.get('https://httpbin.org/status/404', timeout=5)
response.raise_for_status() # 状态码不是2xx时抛出HTTPError
data = response.json()
except requests.exceptions.HTTPError as e:
print(f"HTTP错误: {e.response.status_code}")
except requests.exceptions.ConnectionError:
print("网络连接错误")
except requests.exceptions.Timeout:
print("请求超时")
except requests.exceptions.RequestException as e:
print(f"其他错误: {e}")