文章目录
概要
LOSI:基于隐式对手策略识别的多智能体强化学习优化方法
英文全称:LOSI: IMPROVING MULTI-AGENT REINFORCEMENT
LEARNING VIA LATENT OPPONENT STRATEGY IDENTI FICATION
1 问题引入
协作式多智能体强化学习任务中,智能体不仅需要应对队友同步决策带来的环境非平稳性,还要处理对手多样化、不分可观测的策略行为。现有多智能体强化学习算法即便在复杂决策任务重表现优异,但往往会对特定对手行为产生过拟合,一旦早于未见过的对手策略,性能便会大幅下降。
2 创新点
该文章是受表征学习与元强化学习相关研究的启发(这类研究通过学习隐式上下文变量捕捉任务核心动态标准),提出了隐式对手策略识别框架 。其中包含量大核心模块:其一是编码器 ,可将观测到的短时对手轨迹映射为低维嵌入向量;二是条件式多智能体策略网络 ,依托嵌入向量动态调整决策。
创新点如下:
- 提出一种基于对比学习的无监督对手策略识别方法,无需显示标签即可完成对手策略的区分性表征学习
- 将LOSI与主流多智能体强化学习结合,在包含混合对手策略的高难度SMAC-Hard场景中验证了方法的有效性
- 对模型学习到的嵌入空间展开详细分析,证明即便缺少真实策略表示,infoNCE损失仍能驱动模型按照对手策略完成轨迹聚类
注:InfoNCE 是一个损失函数,训练目标只有一个:在向量空间中,拉近相似样本(正样本)、推开无关样本(负样本),让模型自动学习数据内在的相似结构,全程不需要人工标注标签(无监督)。
2.1 整体架构
本文针对对手策略混合、且无法获取对手真实身份的场景设计框架。LOSI 引入对手编码器,从环境局部观测中提取对手的隐式策略信息。受元强化学习启发,编码器处理单智能体维度的信息:当前观测 、上一时刻动作与上一时刻奖励 并借助 门控循环单元(GRU) 捕捉时序依赖关系。
LOSI 对效用网络进行扩展,将编码器输出的对手嵌入向量,作为额外输入。
所有智能体的局部值会输入混合网络完成聚合。该混合网络由超网络生成权重与偏置,输入同时包含全局状态 s s s与全局平均对手嵌入向量 z t z_{t} zt。
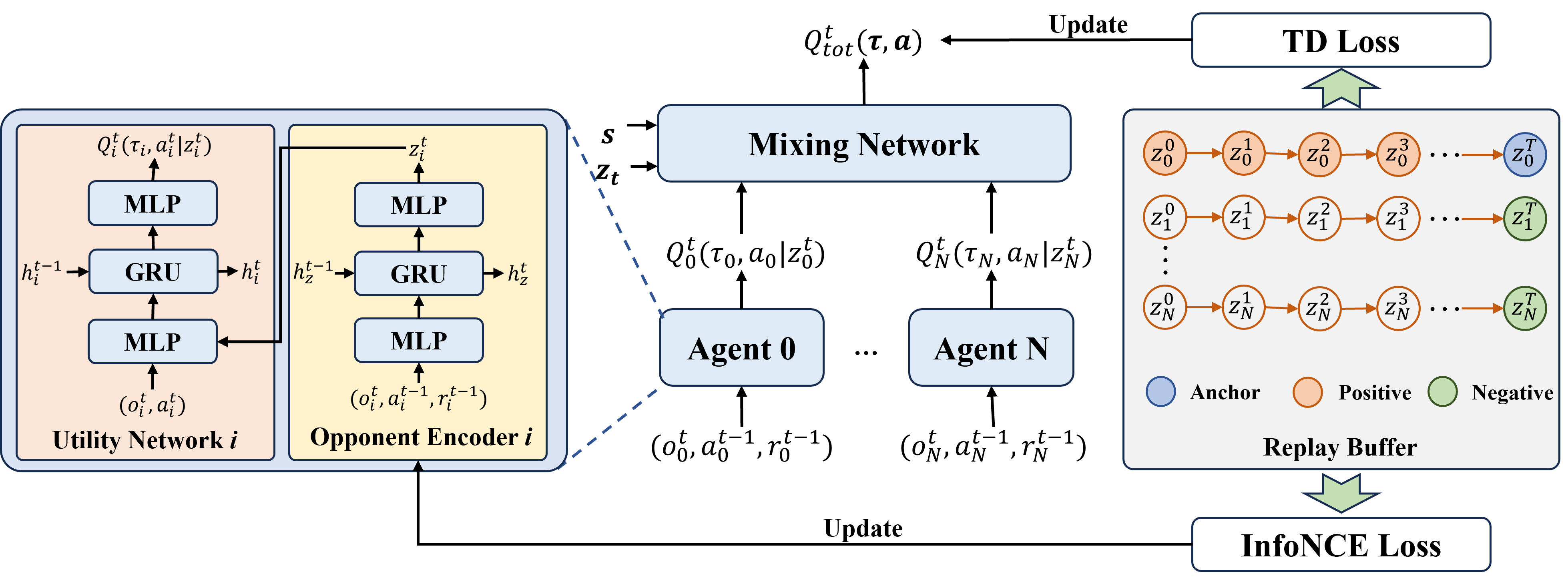
2.2 基于对比识别的隐式嵌入
训练过程中,优化编码器的目标为:同一对手策略生成的轨迹,其嵌入向量相互聚类;不同对手策略的嵌入向量保持距离。
本文引入对手编码器 E ϕ E_\phi Eϕ,将观测、动作、奖励组成的序列映射为隐式嵌入向量 z ′ z' z′,且 z t = E ϕ ( τ t ) z^t = E_\phi(\tau^t) zt=Eϕ(τt)
该嵌入向量同时约束智能体效用网络与混合网络,为值函数提供上下文信息,让模型适配对手的隐式策略。
2.3 基于原型的对比学习
为保证嵌入向量具备区分度、同时提升训练稳定性,本文采用基于原型的InfoNCE损失。模型维护一个记忆库,存储 K K K个原型向量。
该损失函数会引导同一对手策略对应的嵌入向量向所属原型靠拢,同时维持不同策略之间的特征区分度。原型机制可有效避免表征坍缩,让整个训练过程中隐式表征的学习更加稳定。
对于任意轨迹嵌入向量 z z z,首先匹配距离最近的原型:
k ∗ = arg min k ∥ z − p k ∥ 2 2 (4) k^* = \arg\min_k \|z - p_k\|_2^2 \tag{4} k∗=argkmin∥z−pk∥22(4)
最终对比损失定义为:
L N C E = − log exp ( sim ( z , p k ∗ ) / τ ) ∑ j = 1 K exp ( sim ( z , p j ) / τ ) \mathcal{L}{NCE} = -\log \frac{\exp\left(\text{sim}(z, p{k^*}) / \tau\right)}{\sum_{j=1}^K \exp\left(\text{sim}(z, p_j) / \tau\right)} LNCE=−log∑j=1Kexp(sim(z,pj)/τ)exp(sim(z,pk∗)/τ)
其中相似度函数 sim ( u , v ) = u ⊤ v ∥ u ∥ ∥ v ∥ \text{sim}(u, v) = \frac{u^\top v}{\|u\| \|v\|} sim(u,v)=∥u∥∥v∥u⊤v 为余弦相似度, τ \tau τ 为温度系数。
原型向量通过指数移动平均在线更新:
p k ∗ ← α p k ∗ + ( 1 − α ) z (6) p_{k^*} \leftarrow \alpha p_{k^*} + (1 - \alpha) z \tag{6} pk∗←αpk∗+(1−α)z(6)
2.4 联合优化
本文最终的训练目标为时序差分损失与基于原型的对比损失加权求和:
L ( θ , ϕ ) = L T D ( θ , ϕ ) + λ ( t ) L N C E ( ϕ , { p k } ) (7) \mathcal{L}(\theta, \phi) = \mathcal{L}{TD}(\theta, \phi) + \lambda(t)\mathcal{L}{NCE}\left(\phi, \{p_k\}\right) \tag{7} L(θ,ϕ)=LTD(θ,ϕ)+λ(t)LNCE(ϕ,{pk})(7)
其中时序差分损失计算公式为:
L T D = E ( y t − Q t o t ( τ t , a t ; θ , ϕ ) ) 2 (8) \mathcal{L}_{TD} = \mathbb{E}\left\\left(y_t - Q_{tot}\\left(\\tau_t, a_t; \\theta, \\phi\\right)\\right)\^2\\right \tag{8} LTD=E(yt−Qtot(τt,at;θ,ϕ))2(8)
时序差分目标值定义为:
y t = r t + γ max a ′ Q t o t ( τ t + 1 , a ′ ; θ − ) (9) y_t = r_t + \gamma \max_{a'} Q_{tot}\left(\tau_{t+1}, a'; \theta^-\right) \tag{9} yt=rt+γa′maxQtot(τt+1,a′;θ−)(9)
权重系数 λ ( t ) \lambda(t) λ(t) 采用退火策略动态平衡值函数学习与对比学习:
λ ( t ) = λ m a x ⋅ ( 1 − e − β t ) (10) \lambda(t) = \lambda_{max} \cdot \left(1 - e^{-\beta t}\right) \tag{10} λ(t)=λmax⋅(1−e−βt)(10)
2.5 整体训练伪代码
输入 : 智能体效用网络 Q i ( θ ) Q_i(\theta) Qi(θ)、混合网络 f θ f_\theta fθ、对手编码器 E ϕ E_\phi Eϕ、原型记忆库 { p k } k = 1 K \{p_k\}_{k=1}^K {pk}k=1K、经验回放池 D D D
-
遍历每一个训练对局:
- 重置环境,初始化各智能体隐状态 h i 0 h_i^0 hi0、编码器状态 z 0 z_0 z0
- 遍历时间步 t = 1 , 2 , ... , T t = 1,2,\dots,T t=1,2,...,T:
- 每个智能体 i i i 根据 π i ( o i t , h i t , z t ) \pi_i(o_i^t, h_i^t, z_t) πi(oit,hit,zt) 选择动作 a i t a_i^t ait
- 执行联合动作 a t a_t at,获取即时奖励 r t r_t rt 与下一时刻观测 o t + 1 o_{t+1} ot+1
- 更新智能体隐状态 h i t + 1 h_i^{t+1} hit+1,并通过编码器计算新的嵌入向量 z t + 1 = E ϕ ( τ t + 1 ) z_{t+1} = E_\phi(\tau_{t+1}) zt+1=Eϕ(τt+1)
- 将轨迹样本 ( τ t , a t , r t , τ t + 1 , z t ) (\tau_t, a_t, r_t, \tau_{t+1}, z_t) (τt,at,rt,τt+1,zt) 存入经验回放池 D D D
-
从经验回放池 D D D 中采样批次样本 B B B
-
遍历批次内每一条对局轨迹:
- 通过编码器计算轨迹嵌入向量 z = E ϕ ( τ ) z = E_\phi(\tau) z=Eϕ(τ)
- 匹配距离最近的原型: p k ∗ = arg min k ∥ z − p k ∥ 2 p_{k^*} = \arg\min_k \|z - p_k\|_2 pk∗=argmink∥z−pk∥2
- 计算 InfoNCE 对比损失 L N C E \mathcal{L}_{NCE} LNCE
-
通过指数移动平均更新原型: p k ∗ ← α p k ∗ + ( 1 − α ) z p_{k^*} \leftarrow \alpha p_{k^*} + (1 - \alpha) z pk∗←αpk∗+(1−α)z
-
计算时序差分目标值: y t = r t + γ max a ′ Q t o t ( τ t + 1 , a ′ ) y_t = r_t + \gamma \max_{a'} Q_{tot}(\tau_{t+1}, a') yt=rt+γmaxa′Qtot(τt+1,a′)
-
计算时序差分损失: L T D = ( y t − Q t o t ( τ t , a t ) ) 2 \mathcal{L}{TD} = \left(y_t - Q{tot}(\tau_t, a_t)\right)^2 LTD=(yt−Qtot(τt,at))2
-
构建联合损失: L = L T D + λ ( t ) L N C E \mathcal{L} = \mathcal{L}{TD} + \lambda(t)\mathcal{L}{NCE} L=LTD+λ(t)LNCE
-
基于梯度下降更新网络参数 θ \theta θ、 ϕ \phi ϕ
前期侧重强化学习,后期侧重对手表征学习
3 实验
该文章在全协作式 SMAC-Hard 高难度微操作场景中验证 LOSI 框架的性能,评价指标为各场景下的平均胜率。实验分为两部分:在 6 个标准 SMAC-Hard 任务上开展测试,同时在 6 个全新设计、复杂度更高的场景中做进一步验证。此外,本文还通过消融实验,分析对手策略识别模块的有效性,以及智能体技能机制对模型的影响。
4 额外补充
4.1 InfoNCE
InfoNCE 是一个损失函数,训练目标只有一个:在向量空间中,拉近相似样本(正样本)、推开无关样本(负样本),让模型自动学习数据内在的相似结构,全程不需要人工标注标签(无监督)。
- **锚点样本:**当前要编码的目标样本(比如一张图片、一段文本、一条智能体轨迹);
- **正样本:**和锚点语义 / 属性高度相似的样本;
- **负样本:**和锚点完全无关的样本。
模型通过区分 "正 / 负样本" 完成训练:让锚点与正样本相似度最大化,与所有负样本相似度最小化
本文中:
- 锚点 :单条对手行为轨迹经过 GRU 编码器输出的嵌入向量 z z z;
- 正样本 :该轨迹所属策略对应的最近原型 p k ∗ p_{k^*} pk∗;
- 负样本 :原型库中所有其他原型 p j p_j pj(代表其他对手策略)。
总结
该方法的核心就是充分利用CTDE的特征,在超网络中融合了对手的表征进行训练,并且通过额外构建知识库的方式,借助对比学习的方式,达到区分不同对手的效果。