一、产品概述
PolarDB 分布式版(PolarDB-X)是由阿里巴巴自主研发的云原生分布式数据库 ,是一款基于 Share-Nothing 架构理念,并同时支持在线事务处理与在线分析处理(HTAP)的融合型分布式数据库产品,具备金融级数据高可用、分布式一致性以及极致弹性等能力。
核心数据指标
| 指标 | 数值 |
|---|---|
| 经历双11 | 10+ 次 |
| TPS 峰值 | 8.7 千万 |
| 线下用户数 | 700+ 家 |
| 部署规模 | 10000+ 台 |
发展历程
| 阶段 | 时间 | 里程碑 |
|---|---|---|
| TDDL + AliSQL | 2009 年 | 集团去 IOE |
| 2011 年 7 月 | TDDL + AliSQL 实现商品库去 O | |
| 2012 年 | 首次承载双11,迎接零点峰值 | |
| 2013 年 | 集团完成去 IOE,TDDL 成为集团业务接入标准 | |
| DRDS + RDS | 2017~2019 年 | 产品化输出,产品名:DRDS;国内第一家落地分布式技术的云服务;国家税务、国家路网等基础设施系统上线 |
| PolarDB-X 云原生分布式数据库 | Now | 计算层与存储层深度融合,完整数据库形态输出;All in PolarDB-X(金融云、公有云、零售云);满足金融行业的一致性、业务连续性要求 |
二、典型业务场景
PolarDB-X 适用于以下典型业务场景:
1. 交易订单及相关高并发场景
- 数据量大 / 并发高
- 相互联系较弱
2. 海量数据集中存储、大表拆分 + 高并发
- 数据归集和查询服务
- 数据单表过大有并发
3. 国产化分布式改造
- 核心银行、运营商的部分业务,存在国产化、分布式、去 O 诉求
4. TiDB / MyCat / Sharding-JDBC 的用户
- 自建这些产品,运维管理复杂度非常高
- PolarDB-X 在热点扩容、只读实例等有明确优势
5. 有分布式改造诉求
- 业务未来的数据量非常大
- 对分布式方向认可
三、技术架构
PolarDB-X 整体技术架构由以下核心组件构成:
Application (via MySQL Protocol)
|
+----v----+
| PolarDB-X |
+----+----+
|
+----v-----------------+------------------+------------------+
| CN Cluster | DN Cluster | Columnar Cluster |
| (计算节点) | (存储节点) | (列存节点) |
+----------------------+------------------+------------------+
| | |
TSO/Topology async push CDC
| | |
+----v----+ +----v----+ +----v----+
| GMS | | CDC | | Ecosystem |
| Cluster | | Cluster | | (Data Warehouse / Big Data / BI)
+---------+ +---------+ +----------+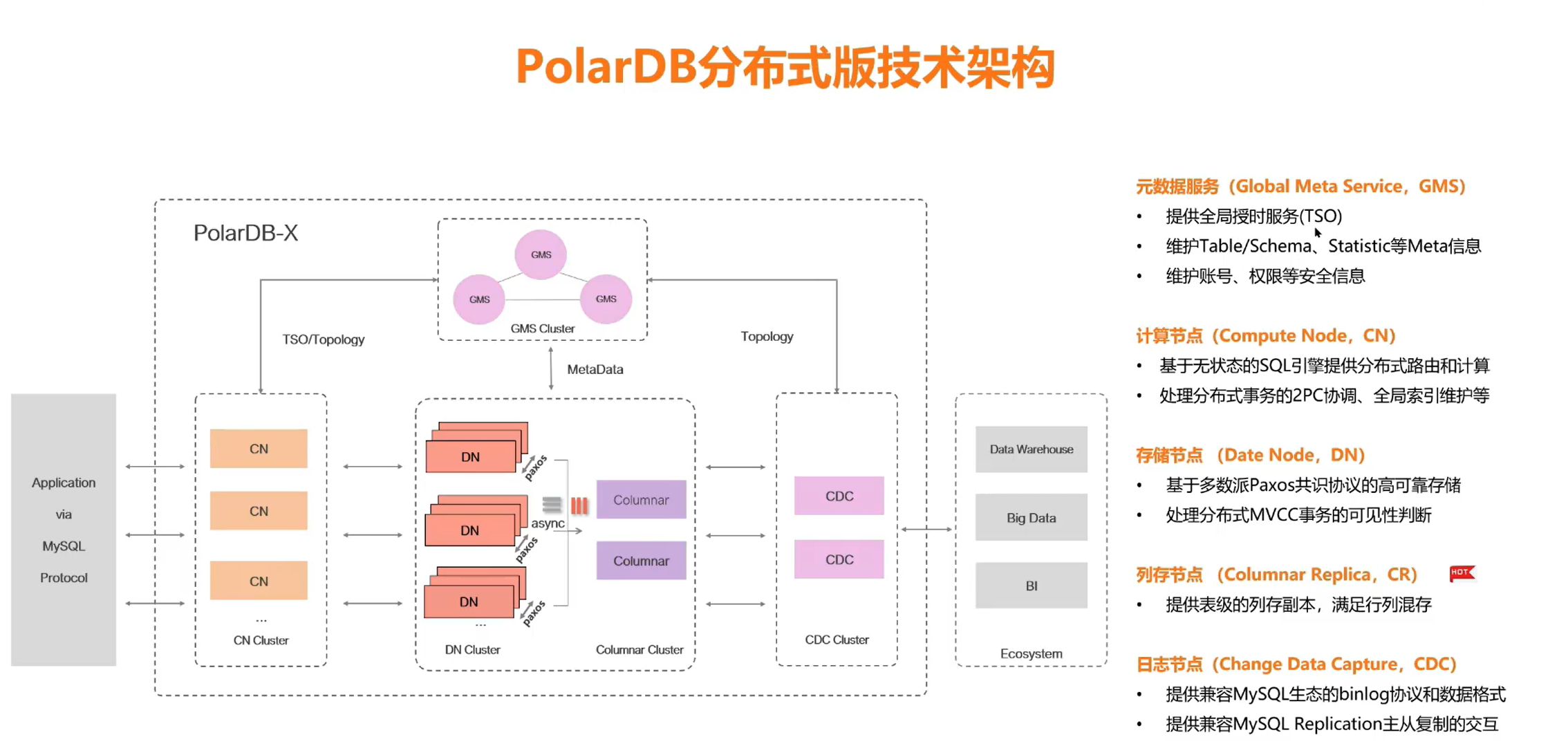
3.1 元数据服务(Global Meta Service, GMS)
- 提供全局授时服务(TSO)
- 维护 Table / Schema、Statistic 等 Meta 信息
- 维护账号、权限等安全信息
3.2 计算节点(Compute Node, CN)
- 基于无状态的 SQL 引擎提供分布式路由和计算
- 处理分布式事务的 2PC 协调、全局索引维护等
3.3 存储节点(Data Node, DN)
- 基于多数派 Paxos 共识协议的高可靠存储
- 处理分布式 MVCC 事务的可见性判断
3.4 列存节点(Columnar Replica, CR)
- 提供表级的列存副本,满足行列混存
3.5 日志节点(Change Data Capture, CDC)
- 提供兼容 MySQL 生态的 binlog 协议和数据格式
- 提供兼容 MySQL Replication 主从复制的交互
四、CN / DN 组件详解
4.1 计算节点(CN)
计算节点具备以下核心能力:
- MySQL 语法高度兼容:经历多年实战磨练
- 完整的 SQL 解析层:实现精准算子下推
- Serverless 无状态:弹性能力对业务透明
- HTAP 并行计算能力:应对混合负载场景
CN 内部架构层次
| 层次 | 组件/功能 |
|---|---|
| MySQL 协议层 | MySQL Protocol |
| 优化器 | SQL 解析、Plan Cache、Outline、Hint、Information Schema、Data Placement (Rule)、Cascades Optimizer (RBO & CBO) |
| 物理计划 | Physical Plan For TP / Physical Plan For AP |
| 执行器 | Sequence、Data Type、Functions、Session、Users、DDL Operators、TP Operators、AP Operators (Shuffle, Driver)、Admin & Profile Operators、DCL Operators、Transaction (TSO/2PC)、GSI |
4.2 数据节点(DN)
数据节点具备以下核心特性:
- 基于 AliSQL 内核:经历多年考验,稳定可靠
- 基于 Paxos 强一致协议:高可用能力进一步提升
- 全局 MVCC 改造:满足金融级一致性要求
- RPC 协议改造:提升节点间通讯性能
DN 内部架构层次
| 层次 | 组件/功能 |
|---|---|
| 存储引擎 | MVCC、Data Type、Functions、Buffer Pool、Plan Cache、Row-based Operator、Vector-based Operator、Row Store、Column Store |
| RPC 协议 | Replication (X-Paxos)、Resource Management (thread/mem/iop) |
五、CDC 组件详解
5.1 CDC 节点
CDC 节点包含三个核心模块:
| 模块 | 全称 | 功能描述 |
|---|---|---|
| EX | Extractor | 并行采集所有 DN 的变更日志 |
| MR | Merger | 分布式事务日志 / DDL 排序重组 |
| DP | Dumper | 全局日志落盘并提供标准 Binlog 服务 |
5.2 全局 Binlog
全局 Binlog 具备以下兼容性能力:
- 兼容事务(分布式事务全局排序)
- 例:基于 TraceId、TSO 信息对 Binlog 全局排序
- 兼容分布式 DDL
- 例:可支持 DDL 同步到下游,比如 ADB
- 兼容分布式扩缩容
- 例:屏蔽内部分片迁移、广播表、索引等数据干扰
5.3 主备 Replication
- 兼容 MySQL 生态的主备复制
- 兼容 DTS 的上下游生态
5.4 上下游对接
CDC 支持与以下数据库和生态产品对接:
- Oracle
- IBM DB2
- SQL Server
- PostgreSQL
- Hadoop
- Kafka
- 以及更多 ...
六、Columnar 组件详解
6.1 列存节点核心能力
- 提供表级别的列存副本,满足行列混存
- 行存纯异步复制到列存副本,不影响 TP 行存
- 基于行存事务 TSO 版本,行和列的副本均满足数据一致性
- 存储采用分布式 shard + 共享存储,满足低成本 + 线性扩展
- 列存对接 CN 节点的 MPP 并行计算,一个入口 + 一套 SQL 引擎
- 优化器智能选择列存索引,提供 Select / ETL 下的行和列混合执行
6.2 列存数据流转架构
DN (Data Node)
|
|-- paxos consensus log
|
v
CDC (transaction binlog)
|
v
Columnar
|-- Extractor
|-- Transformer
|-- Compaction
|
v
Shard Storage
|-- .csv files
|-- .del files
|-- .orc files
|
+---> 云盘 / OSS6.3 存储格式
| 存储类型 | 格式 |
|---|---|
| 行存 | InnoDB B-Tree |
| 列存 | Parquet / ORC |
6.4 CN 与 Columnar 交互
CN 节点通过 RPC 与 Columnar 节点交互,CN 内部通过 MPP(大规模并行处理) 架构实现并行计算,并配备 Local SSD Cache 提升查询性能。
七、总结
PolarDB 分布式版(PolarDB-X)作为阿里巴巴自主研发的云原生分布式数据库,经过多年双11大促的实战验证,具备以下核心优势:
- 金融级高可用:基于 Paxos 强一致协议,满足金融级一致性要求
- HTAP 融合能力:一套引擎同时支持 TP 和 AP 负载
- 极致弹性:Serverless 无状态计算节点,弹性能力对业务透明
- MySQL 生态兼容:高度兼容 MySQL 语法和生态工具
- 行列混存:通过列存节点实现高效的分析查询能力
- 丰富的生态对接:支持主流数据库和大数据生态的上下游对接
文档整理日期:2026-06-13