第 04 章:工具调用:让模型只提需求,服务端执行确定性工具
本章最终效果
上一章我们已经完成了 Today 和 Coach Chat 的行动闭环:前端或调用方发来用户消息,Spring 后端补齐可信用户上下文,再把请求交给 Python Agent Service。
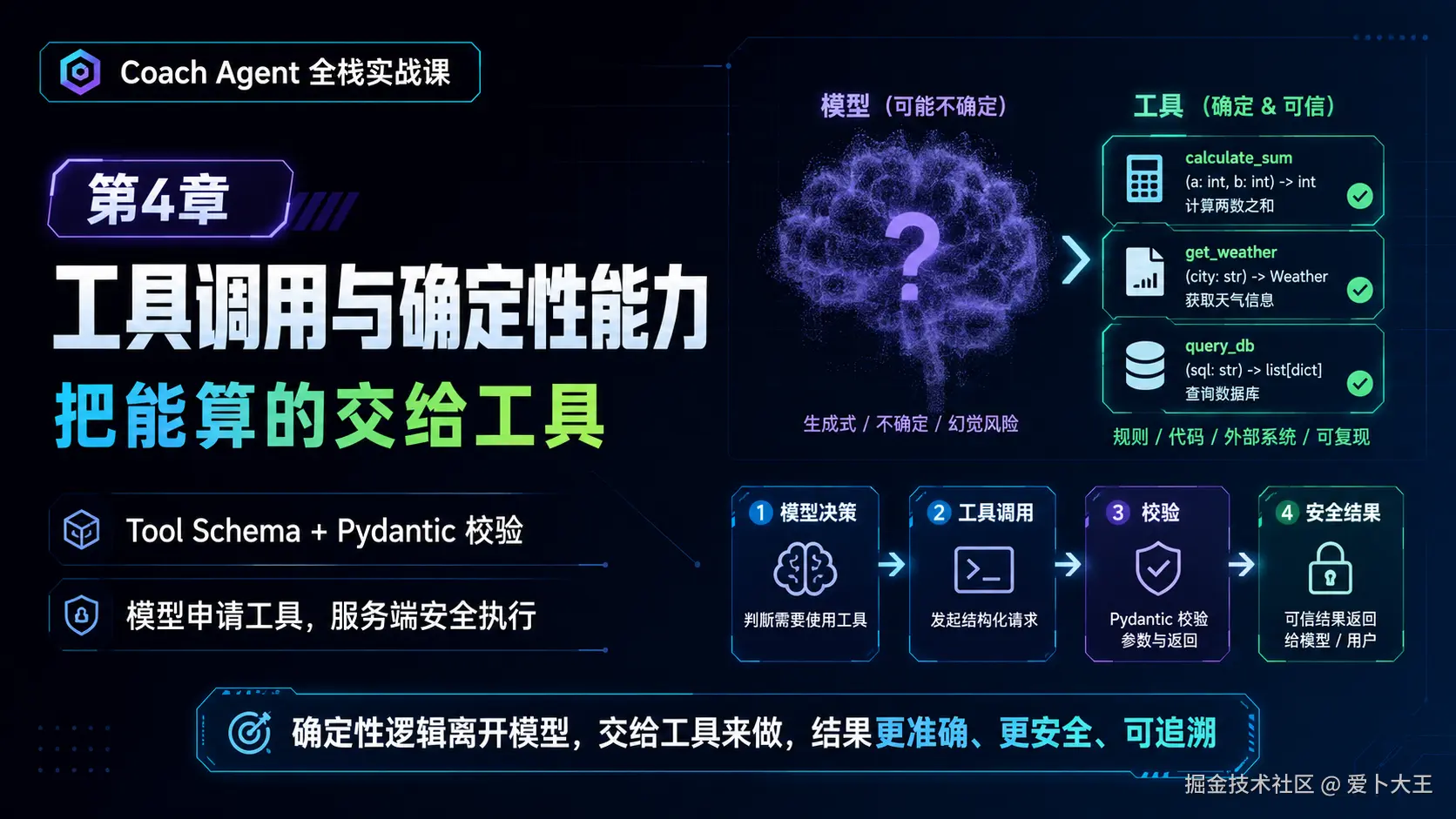
这一章我们要继续往 Agent Service 里加一个非常关键的能力:Tool Registry。
学完本章后,你会得到这几个结果:
services/agent-service/app/tools.py中有两个可被 Agent 调用的工具:calculate_macro_target:根据身高、体重、目标、训练频率计算热量和三大营养素。generate_training_plan:根据目标、训练频率、器械和伤病标记生成训练结构。
- 工具参数会先经过 Pydantic 校验,异常参数不会让服务直接崩掉。
- 模型只能申请调用工具,真正执行哪个函数由服务端白名单
execute_tool()决定。 tests/test_tools.py会锁住两个确定性行为:- 减脂热量不能设计成极端节食。
- 膝盖风险会触发低冲击训练降级。
AgentService.chat()中的工具调用链路会变清楚:- 第一次模型调用:模型判断是否需要工具。
- 服务端执行工具:解析参数、白名单执行、记录 trace。
- 第二次模型调用:模型拿着工具结果生成最终回答。
本章最重要的一句话是:
模型可以理解用户意图,但服务端必须控制工具边界。
如果模型说"这个用户每天吃 500 大卡就行",我们不能相信它;如果模型说"调用一个工具帮我算热量",服务端也不能盲目执行它随便编出来的函数名。工具调用的本质,是把"模型的语言能力"和"后端的确定性能力"分开。
本章复制规则
本章继续使用前几章的复制标记:
[执行命令]:在终端复制运行。[写入文件]:把完整代码复制到指定文件。[理解片段,不要复制]:只用于理解错误写法、最小版本或源码片段,不要写进项目。
注意:本章会出现一段 service.py 里的工具调用片段,它用于理解 Agent 如何接入工具,不要求你替换整个 service.py。完整 service.py 已经在第 01 章写过。
执行目录约定
如果命令前写着:
bash
cd services/agent-service说明你要先进入 Python Agent Service 目录。
如果命令前写着:
bash
cd /Users/aibu/Aibu_System/Work_Projects/codex-template说明你要回到项目根目录。
如果你是从空目录跟着课程做,把上面的绝对路径替换成你自己的项目路径即可。
阶段 1:先理解为什么需要 Tool Registry
1.1 这一阶段要解决什么
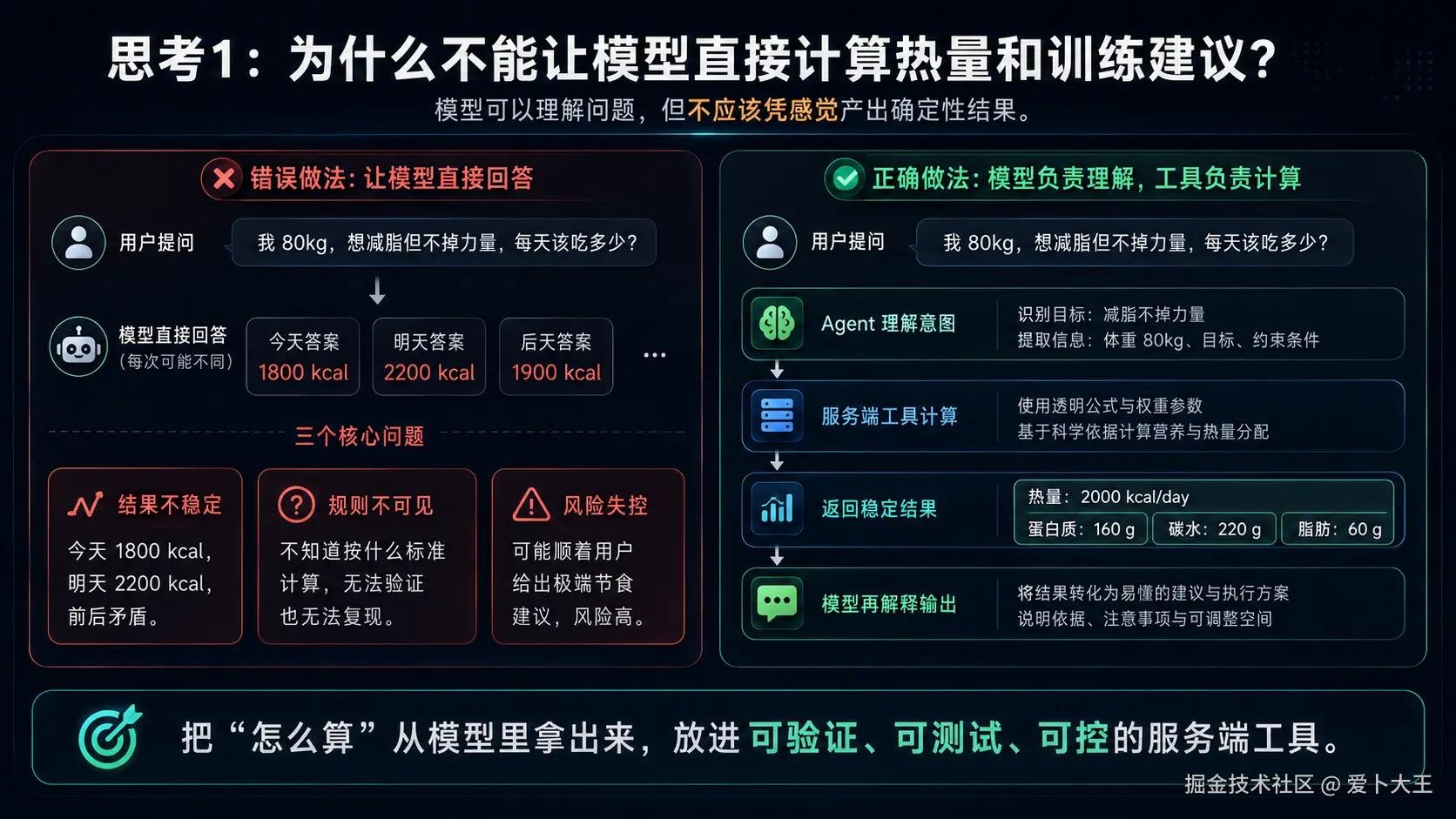
在没有工具之前,Coach Agent 的回答大概是这样的:
用户说:
我 175cm,80kg,想减脂但不想掉力量,一周练 4 天,怎么吃?
模型可以直接回答:
你每天吃 1800 大卡,蛋白质 120g,碳水 160g。
这听起来像一个答案,但工程上有三个问题:
- 模型可能算错。
- 模型可能给出极端建议。
- 你很难用测试锁住它每一次的计算逻辑。
所以高级一点的做法不是让模型直接算,而是把确定性逻辑写成服务端工具。
1.2 理解片段,不要复制 最天真的第一版
如果我刚开始写,可能会先写一个普通函数:
python
def calculate_macro_target(weight_kg: float):
calories = weight_kg * 30
protein = weight_kg * 1.8
return {"calories": calories, "proteinG": protein}这个版本能表达一个意思:热量和蛋白质应该由代码算出来,而不是让模型凭感觉说。
但这个版本马上暴露问题:
- 只传体重,不知道用户目标是增肌还是减脂。
- 没有限制体重范围,
weight_kg=10也能算。 - 没有训练频率,无法判断营养目标是否合理。
- 不是 OpenAI-compatible Tool Calls 能识别的工具声明。
- 没有统一执行入口,后面工具多了会失控。
所以我们需要一步一步长出完整 Tool Registry。
1.3 本章的完整工具链路
本章最终链路是:
TOOL_SCHEMAS把工具名称、描述、参数形状告诉模型。- 模型返回
tool_calls,里面包含工具名和参数 JSON。 - 服务端用
json.loads(raw_args)把参数字符串解析成 Python dict。 - 服务端调用
execute_tool(name, args),只允许执行白名单中的工具。 - 工具内部用 Pydantic 模型再次校验参数边界。
- 工具返回结构化结果,异常参数返回
tool_validation_failed。 - 服务端把工具结果作为
role=tool消息交回模型。 - 模型根据工具结果生成最终自然语言回答。
这条链路里,模型不是执行者,服务端才是执行者。
1.4 执行命令 先确认第 01 章 Python 工程还正常
执行目录:项目根目录。
bash
cd /Users/aibu/Aibu_System/Work_Projects/codex-template
test -f services/agent-service/pyproject.toml
test -f services/agent-service/app/service.py
test -f services/agent-service/app/schemas.py
test -f services/agent-service/tests/test_service.py预期输出:没有任何输出。
如果有输出或命令失败,说明第 01 章 Python Agent Service 的文件还没准备好。先回到第 01 章补齐基础工程,再继续本章。
1.5 执行命令 先确认当前 Python 测试环境可用
执行目录:Python Agent Service 目录。
bash
cd services/agent-service
PYTHONPATH=. pytest --version预期输出类似:
text
pytest 9.0.1版本号不需要完全一样。只要能看到 pytest 版本,就说明当前环境可以运行测试。
如果失败,先检查:
- 是否进入了
services/agent-service。 - 是否已经按第 01 章安装依赖。
- 如果你使用虚拟环境,是否已经执行
source .venv/bin/activate。
阶段 2:从普通函数长出 tools.py
2.1 这一阶段要解决什么
这一阶段我们要写本章的核心文件:
text
services/agent-service/app/tools.py它承担四个职责:
- 定义工具参数模型。
- 定义给模型看的工具 schema。
- 实现真正的工具函数。
- 提供统一白名单执行入口。
这四个职责不要混在一起理解。尤其要分清:
TOOL_SCHEMAS是给模型看的,让模型知道可以申请调用哪些工具。MacroTargetArgs和TrainingPlanArgs是服务端真正校验参数用的。execute_tool()是服务端白名单,决定最终能不能执行。
services/agent-service/app/tools.py
这个文件为什么现在出现
在前几章里,Agent 的主要能力是"理解用户输入,然后生成回答"。但健身教练类 Agent 不能只靠语言生成。
比如热量、蛋白质、碳水、脂肪、训练频率、伤病降级,这些都应该尽量变成可测试、可解释、可复用的代码。
所以现在我们新增 tools.py,把确定性能力从模型回答里拿出来,放进服务端工具。
理解片段,不要复制 只写普通函数会有什么问题
先看一个不够好的版本:
python
def calculate_macro_target(args):
calories = int(args["weight_kg"] * 30)
return {"calories": calories}这段代码的问题不是不能跑,而是边界太弱:
args里面有没有weight_kg不知道。weight_kg是不是数字不知道。weight_kg是否在合理范围不知道。- 出错时会直接抛异常,可能让 API 返回 500。
所以我们不能只写普通函数。我们需要先定义参数模型。
第一步:用 Pydantic 描述服务端参数边界

我们会写出这样的参数模型:
python
class MacroTargetArgs(BaseModel):
height_cm: float = Field(gt=80, lt=230)
weight_kg: float = Field(gt=25, lt=250)
goal: str
training_days: int = Field(ge=0, le=7)
activity_level: str = "moderate"这里的重点不是语法,而是边界:
height_cm必须大于 80、小于 230。weight_kg必须大于 25、小于 250。training_days必须在 0 到 7 之间。activity_level没传时默认是moderate。
Field(gt=80, lt=230) 这类规则是服务端真实校验,不是提示词。模型就算编出一个 weight_kg=10,服务端也会拒绝。
第二步:给模型一个工具说明书
模型并不会自动知道 Python 里有哪些函数。我们要把工具声明成 OpenAI-compatible Tool Calls 能理解的 JSON 结构。
也就是 TOOL_SCHEMAS:
python
TOOL_SCHEMAS: list[dict[str, Any]] = [
{
"type": "function",
"function": {
"name": "calculate_macro_target",
"description": "Calculate safe calorie and macro targets for a fitness user.",
"parameters": {...},
},
}
]它的作用是告诉模型:
你可以申请调用一个叫
calculate_macro_target的函数,这个函数需要身高、体重、目标、训练天数这些参数。
但注意,TOOL_SCHEMAS 只是模型说明书,不是安全边界。真正的安全边界仍然在 Pydantic 和 execute_tool()。
第三步:实现确定性工具函数
工具函数做的是确定性计算:
- 维护热量:
weight_kg * multiplier - 减脂缺口:最多 15%
- 蛋白质:
weight_kg * 1.8 - 脂肪:
weight_kg * 0.8 - 碳水:剩余热量折算,且至少 80g
这些公式不是营养学终极答案,而是课程里的安全示范:
- 不追求极端精准。
- 追求可解释、可测试、不危险。
- 后续可以替换成更专业的业务规则。
第四步:用 execute_tool() 做白名单执行
模型返回的工具名本质上是外部输入。不能因为模型说"执行这个工具",服务端就真的执行任意函数。
所以我们只允许这两个名字:
calculate_macro_targetgenerate_training_plan
其他名字统一返回:
python
{"error": "unknown_tool", "tool": name}如果参数校验失败,返回:
python
{"error": "tool_validation_failed", "details": exc.errors()}这样做的好处是:工具失败也是结构化结果,不会直接把异常穿透到用户界面。
写入文件 services/agent-service/app/tools.py
执行目录:项目根目录。
python
from __future__ import annotations
from typing import Any
from pydantic import BaseModel, Field, ValidationError
class MacroTargetArgs(BaseModel):
height_cm: float = Field(gt=80, lt=230)
weight_kg: float = Field(gt=25, lt=250)
goal: str
training_days: int = Field(ge=0, le=7)
activity_level: str = "moderate"
class TrainingPlanArgs(BaseModel):
goal: str
training_days: int = Field(ge=1, le=6)
equipment: str = "gym"
injury_flags: list[str] = Field(default_factory=list)
training_age: str = "beginner"
TOOL_SCHEMAS: list[dict[str, Any]] = [
{
"type": "function",
"function": {
"name": "calculate_macro_target",
"description": "Calculate safe calorie and macro targets for a fitness user.",
"parameters": {
"type": "object",
"properties": {
"height_cm": {"type": "number"},
"weight_kg": {"type": "number"},
"goal": {"type": "string"},
"training_days": {"type": "integer"},
"activity_level": {"type": "string"},
},
"required": ["height_cm", "weight_kg", "goal", "training_days"],
},
},
},
{
"type": "function",
"function": {
"name": "generate_training_plan",
"description": "Generate a safe training structure with injury-aware downgrade rules.",
"parameters": {
"type": "object",
"properties": {
"goal": {"type": "string"},
"training_days": {"type": "integer"},
"equipment": {"type": "string"},
"injury_flags": {"type": "array", "items": {"type": "string"}},
"training_age": {"type": "string"},
},
"required": ["goal", "training_days"],
},
},
},
]
def calculate_macro_target(args: dict[str, Any]) -> dict[str, Any]:
parsed = MacroTargetArgs.model_validate(args)
multiplier = 30 if parsed.activity_level == "moderate" else 27
maintenance = int(parsed.weight_kg * multiplier)
deficit = 0.15 if "减脂" in parsed.goal or "fat" in parsed.goal.lower() else 0
calories = int(maintenance * (1 - deficit))
protein = int(parsed.weight_kg * 1.8)
fat = int(parsed.weight_kg * 0.8)
carbs = max(80, int((calories - protein * 4 - fat * 9) / 4))
return {
"calories": calories,
"proteinG": protein,
"carbsG": carbs,
"fatG": fat,
"safetyNote": "热量调整不超过估算维持热量的 15%,避免极端节食。",
}
def generate_training_plan(args: dict[str, Any]) -> dict[str, Any]:
parsed = TrainingPlanArgs.model_validate(args)
injury_flags = [item.lower() for item in parsed.injury_flags]
lower_body_risk = any("膝" in item or "knee" in item for item in injury_flags)
blocks = ["热身 8 分钟", "主训练 35 分钟", "低强度收操 8 分钟"]
if lower_body_risk:
blocks = ["关节活动度热身 10 分钟", "上肢/核心训练 30 分钟", "疼痛监测与拉伸 10 分钟"]
return {
"daysPerWeek": parsed.training_days,
"focus": "力量保留 + 渐进减脂" if "减脂" in parsed.goal else parsed.goal,
"blocks": blocks,
"downgradeRule": "疼痛 >= 5/10 或睡眠 < 6h 时自动降级为低冲击训练。",
}
def execute_tool(name: str, args: dict[str, Any]) -> dict[str, Any]:
try:
if name == "calculate_macro_target":
return calculate_macro_target(args)
if name == "generate_training_plan":
return generate_training_plan(args)
except ValidationError as exc:
return {"error": "tool_validation_failed", "details": exc.errors()}
return {"error": "unknown_tool", "tool": name}代码分段解释
第一段:
python
from __future__ import annotations
from typing import Any
from pydantic import BaseModel, Field, ValidationError这三类 import 分别解决三个问题:
annotations让类型标注在运行时更轻量,也方便后续引用较复杂的类型。Any用来描述工具参数和返回值这种"JSON 风格"的字典。BaseModel/Field/ValidationError用来建参数模型、写字段边界、捕获校验错误。
第二段:
python
class MacroTargetArgs(BaseModel):
...
class TrainingPlanArgs(BaseModel):
...这两个类是服务端参数边界。模型传来的参数必须先通过这里,才能进入真正的工具函数。
Field(default_factory=list) 用在 injury_flags 上,是为了每次创建对象时都得到一个新的空列表。不要写成 injury_flags: list[str] = [],因为可变默认值在 Python 里容易造成多个对象共享同一个列表。
第三段:
python
TOOL_SCHEMAS: list[dict[str, Any]] = [...]这是给模型看的工具说明。它让模型知道工具叫什么、能解决什么问题、需要哪些参数。
再次强调:schema 是说明书,不是最终安全边界。模型可能仍然传错参数,所以服务端还要用 Pydantic 校验。
第四段:
python
def calculate_macro_target(args: dict[str, Any]) -> dict[str, Any]:
parsed = MacroTargetArgs.model_validate(args)
...第一行先做 model_validate,意思是"先验票,再进站"。只有参数合法,后面的热量计算才会运行。
第五段:
python
def generate_training_plan(args: dict[str, Any]) -> dict[str, Any]:
...这段工具会根据 injury_flags 判断下肢风险。如果用户有"膝"或 knee 相关标记,就把训练块降级为上肢、核心、疼痛监测和拉伸。
第六段:
python
def execute_tool(name: str, args: dict[str, Any]) -> dict[str, Any]:
...这是工具白名单。这里没有用 globals()[name]() 这种动态调用方式,因为那会让模型传入任意函数名,风险太高。
复制后立即运行:导入检查
执行目录:Python Agent Service 目录。
bash
cd services/agent-service
PYTHONPATH=. python - <<'PY'
from app.tools import TOOL_SCHEMAS, calculate_macro_target, generate_training_plan, execute_tool
print(len(TOOL_SCHEMAS))
print(calculate_macro_target({"height_cm": 175, "weight_kg": 80, "goal": "减脂", "training_days": 4})["calories"])
print(generate_training_plan({"goal": "减脂", "training_days": 4})["daysPerWeek"])
print(execute_tool("unknown_tool", {}))
PY预期输出类似:
text
2
2040
4
{'error': 'unknown_tool', 'tool': 'unknown_tool'}如果失败,先检查:
ModuleNotFoundError: app:执行命令时没有在services/agent-service目录,或者没有加PYTHONPATH=.。ImportError:检查tools.py文件名是否写错。SyntaxError:检查复制代码时有没有漏掉冒号、括号或缩进。
复制后立即运行:参数边界检查
执行目录:Python Agent Service 目录。
bash
cd services/agent-service
PYTHONPATH=. python - <<'PY'
from app.tools import execute_tool
normal = execute_tool(
"calculate_macro_target",
{"height_cm": 175, "weight_kg": 80, "goal": "减脂", "training_days": 4},
)
invalid = execute_tool(
"calculate_macro_target",
{"height_cm": 175, "weight_kg": 10, "goal": "减脂", "training_days": 4},
)
unknown = execute_tool("delete_all_user_data", {})
print("normal:", normal)
print("invalid:", invalid["error"])
print("unknown:", unknown["error"])
PY预期输出中要看到:
text
normal: {'calories': 2040, ...
invalid: tool_validation_failed
unknown: unknown_tool这一步能证明三件事:
- 正常参数会执行工具。
- 异常体重参数会被 Pydantic 拦住。
- 模型编出来的未知工具名不会被执行。
阶段 3:用测试锁住工具行为
3.1 这一阶段要解决什么

工具函数是确定性代码,所以它应该优先被单元测试覆盖。
本章先不测试模型会不会主动调用工具,因为那属于模型行为,可能受 prompt、模型版本、上下文影响。我们先测试工具自身:
- 输入减脂用户,热量和蛋白质是否符合预期。
- 输入膝盖疼痛,训练计划是否降级。
services/agent-service/tests/test_tools.py
这个文件为什么现在出现
只写工具函数还不够。我们需要用测试告诉自己和学员:
这段逻辑不是靠感觉,它有可回归的验收标准。
以后如果我们修改热量公式、训练降级规则或参数边界,测试会立刻告诉我们有没有破坏本章预期。
理解片段,不要复制 只测函数能跑还不够
一个太弱的测试可能这样写:
python
def test_macro_target_runs():
result = calculate_macro_target({"height_cm": 175, "weight_kg": 80, "goal": "减脂", "training_days": 4})
assert result这个测试只能证明"函数没有崩",不能证明结果合理。
我们真正关心的是:
- 热量是不是被限制在温和缺口。
- 蛋白质是不是足够保护力量。
- 膝盖风险是不是能改变训练结构。
所以最终测试要断言关键字段。
写入文件 services/agent-service/tests/test_tools.py
执行目录:项目根目录。
python
from app.tools import calculate_macro_target, generate_training_plan
def test_macro_target_limits_deficit():
result = calculate_macro_target(
{
"height_cm": 175,
"weight_kg": 80,
"goal": "减脂但不掉力量",
"training_days": 4,
}
)
assert result["calories"] == 2040
assert result["proteinG"] == 144
assert "极端节食" in result["safetyNote"]
def test_training_plan_downgrades_knee_risk():
result = generate_training_plan(
{
"goal": "减脂",
"training_days": 4,
"injury_flags": ["左膝疼痛"],
}
)
assert any("上肢" in block for block in result["blocks"])
assert "疼痛" in result["downgradeRule"]代码分段解释
第一段:
python
from app.tools import calculate_macro_target, generate_training_plan测试直接导入工具函数。这里不需要启动 FastAPI,也不需要调用 DeepSeek,因为工具是本地确定性代码。
第二段:
python
assert result["calories"] == 2040
assert result["proteinG"] == 144
assert "极端节食" in result["safetyNote"]这些断言不是随便写的:
- 80kg 中等活动水平,维持热量估算为
80 * 30 = 2400。 - 减脂时最多 15% 缺口,所以
2400 * 0.85 = 2040。 - 蛋白质为
80 * 1.8 = 144。 safetyNote必须提醒避免极端节食。
第三段:
python
assert any("上肢" in block for block in result["blocks"])
assert "疼痛" in result["downgradeRule"]这两行锁住伤病降级逻辑。如果用户有膝盖疼痛,训练结构不能还是普通下肢训练。
复制后立即运行
执行目录:Python Agent Service 目录。
bash
cd services/agent-service
PYTHONPATH=. pytest tests/test_tools.py预期输出类似:
text
tests/test_tools.py .. [100%]如果失败,先检查:
assert result["calories"] == 2040失败:检查activity_level默认值和deficit = 0.15是否复制正确。assert "极端节食" in result["safetyNote"]失败:检查safetyNote文案是否复制完整。- 膝盖降级失败:检查
lower_body_risk里是否同时判断了"膝"和"knee"。
阶段 4:理解 AgentService 如何接入工具
4.1 这一阶段要解决什么
现在我们已经有工具了,但工具还只是本地函数。
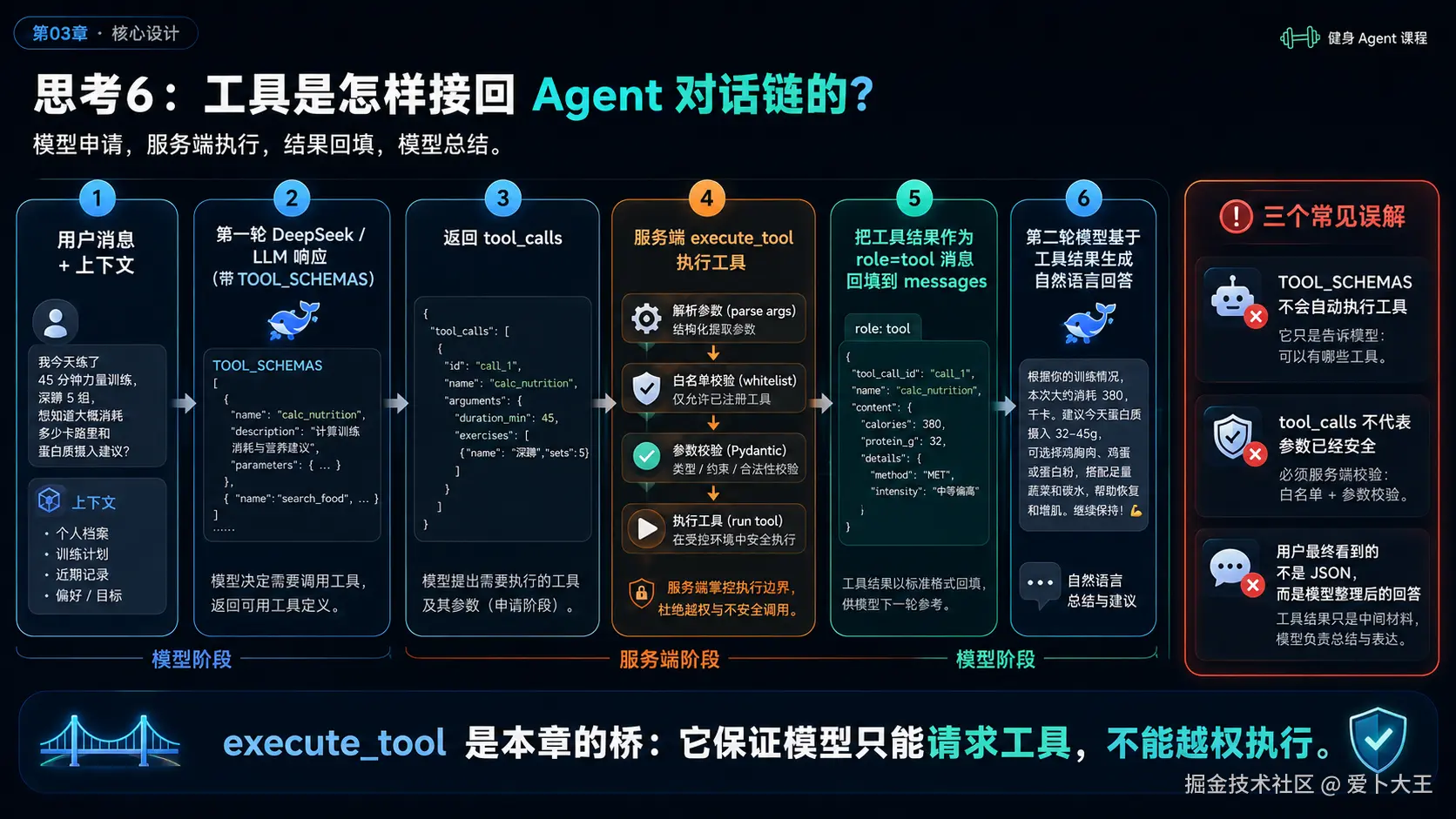
Agent 真正使用工具时,会多出一个消息往返:
- 服务端把
TOOL_SCHEMAS传给模型。 - 模型不直接回答,而是返回
tool_calls。 - 服务端解析工具名和参数。
- 服务端执行
execute_tool()。 - 服务端把工具结果作为
role=tool消息追加回对话。 - 服务端再调用一次模型,让模型基于工具结果生成最终回答。
这就是"模型提需求,服务端执行工具,模型再组织语言"。

4.2 理解片段,不要复制 错误的接入方式
一个危险的写法是:
python
name = call["function"]["name"]
args = json.loads(call["function"]["arguments"])
result = globals()[name](args)不要这样写。
原因很简单:name 是模型输出,模型输出不能决定服务端执行任意函数。如果用 globals()[name] 这种动态方式,模型一旦输出了意料之外的函数名,服务端边界就变弱了。
我们要用 execute_tool() 白名单。
4.3 理解片段,不要复制 当前 service.py 中的真实工具链路
下面这段来自当前 services/agent-service/app/service.py。它用于理解,不要单独复制覆盖文件。
python
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": self._build_user_context(request, citations)},
]
first = await self.client.chat(messages, tools=TOOL_SCHEMAS)
tool_results: list[ToolCallResult] = []
if first.tool_calls:
messages.append(
{
"role": "assistant",
"content": first.content,
"tool_calls": first.tool_calls,
}
)
for call in first.tool_calls:
function = call.get("function") or {}
name = function.get("name") or "unknown"
raw_args = function.get("arguments") or "{}"
args = json.loads(raw_args) if isinstance(raw_args, str) else raw_args
result = execute_tool(name, args)
tool_results.append(ToolCallResult(name=name, arguments=args, result=result))
messages.append(
{
"role": "tool",
"tool_call_id": call.get("id"),
"content": json.dumps(result, ensure_ascii=False),
}
)
self.traces.append(
event(
trace_id,
"tool_call",
"ToolAgent",
input={"name": name, "arguments": args},
output=result,
toolName=name,
toolArgs=args,
)
)
final = await self.client.chat(messages)
answer = final.content
cost = guardrail_cost + first.estimated_cost_cny + final.estimated_cost_cny
else:
answer = first.content
cost = guardrail_cost + first.estimated_cost_cny代码分段解释
第一段:
python
first = await self.client.chat(messages, tools=TOOL_SCHEMAS)第一次模型调用把 TOOL_SCHEMAS 传进去。意思是告诉模型:如果你需要计算热量或训练计划,可以申请调用这些工具。
第二段:
python
if first.tool_calls:模型可能选择调用工具,也可能直接回答。这里先判断有没有 tool calls。
第三段:
python
raw_args = function.get("arguments") or "{}"
args = json.loads(raw_args) if isinstance(raw_args, str) else raw_args
result = execute_tool(name, args)模型返回的 arguments 通常是 JSON 字符串,所以服务端先 json.loads 转成 dict。
但是转成 dict 还不够,后面必须进入 execute_tool()。因为 execute_tool() 才会做白名单分发和 Pydantic 校验。
第四段:
python
messages.append(
{
"role": "tool",
"tool_call_id": call.get("id"),
"content": json.dumps(result, ensure_ascii=False),
}
)工具结果不能只存在 Python 变量里,还要追加回消息列表,让模型在第二次调用时能看到工具结果。
ensure_ascii=False 是为了保留中文,不把中文转成一串 Unicode 转义。
第五段:
python
self.traces.append(...)工具调用会写入 trace。这样后面在 Trace 页面里可以看到:
- 调用了哪个工具。
- 参数是什么。
- 输出是什么。
第六段:
python
final = await self.client.chat(messages)第二次模型调用不再传工具,而是让模型基于工具结果组织最终回答。
这也说明当前实现不是无限工具循环:本章只处理一轮 tool calls,然后进入最终回答。
4.4 执行命令 静态检查工具接入点
执行目录:项目根目录。
bash
cd /Users/aibu/Aibu_System/Work_Projects/codex-template
rg -n "TOOL_SCHEMAS|first\\.tool_calls|execute_tool|role\": \"tool\"|ToolAgent" services/agent-service/app/service.py预期输出中要能看到:
text
TOOL_SCHEMAS
first.tool_calls
execute_tool
ToolAgent如果没有看到,先检查:
- 是否在项目根目录运行。
- 第 01 章的
service.py是否复制完整。 - 当前文件是否被误覆盖成旧版本。
阶段 5:本章最终验证
5.1 执行命令 运行工具单元测试
执行目录:Python Agent Service 目录。
bash
cd services/agent-service
PYTHONPATH=. pytest tests/test_tools.py预期输出类似:
text
tests/test_tools.py .. [100%]这一步证明工具函数本身稳定。
5.2 执行命令 运行 service 层测试
执行目录:Python Agent Service 目录。
bash
cd services/agent-service
PYTHONPATH=. pytest tests/test_service.py预期输出类似:
text
tests/test_service.py ...... [100%]这一步证明 AgentService.chat() 的主要分支仍然正常。
注意:这个测试不要求真实 DeepSeek key。默认测试会使用 fake client 或高风险短路场景,目的是让普通开发验证不消耗预算。
5.3 执行命令 一次性运行本章相关测试
执行目录:Python Agent Service 目录。
bash
cd services/agent-service
PYTHONPATH=. pytest tests/test_tools.py tests/test_service.py预期输出类似:
text
collected 8 items
tests/test_tools.py .. [ 25%]
tests/test_service.py ...... [100%]
============================== 8 passed in 0.17s ===============================时间和版本可能不同,但要看到 passed。
5.4 执行命令 本地 smoke:正常工具、异常参数、未知工具
执行目录:Python Agent Service 目录。
bash
cd services/agent-service
PYTHONPATH=. python - <<'PY'
from app.tools import execute_tool
cases = [
(
"normal_macro",
"calculate_macro_target",
{"height_cm": 175, "weight_kg": 80, "goal": "减脂", "training_days": 4},
),
(
"invalid_weight",
"calculate_macro_target",
{"height_cm": 175, "weight_kg": 10, "goal": "减脂", "training_days": 4},
),
(
"unknown_tool",
"delete_all_user_data",
{},
),
]
for label, name, args in cases:
print(label, execute_tool(name, args))
PY预期输出中至少要看到:
text
normal_macro {'calories': 2040, ...
invalid_weight {'error': 'tool_validation_failed', ...
unknown_tool {'error': 'unknown_tool', 'tool': 'delete_all_user_data'}这一步是本章最直观的安全边界验证:
- 正常工具能跑。
- 参数越界不崩服务。
- 未知工具不执行。
5.5 执行命令 检查本章没有引入真实模型调用
执行目录:Python Agent Service 目录。
bash
cd services/agent-service
PYTHONPATH=. python - <<'PY'
from app.tools import execute_tool
result = execute_tool(
"generate_training_plan",
{"goal": "减脂", "training_days": 4, "injury_flags": ["左膝疼痛"]},
)
print(result["blocks"])
PY预期输出类似:
text
['关节活动度热身 10 分钟', '上肢/核心训练 30 分钟', '疼痛监测与拉伸 10 分钟']这一步不需要 DeepSeek key。因为我们验证的是本地工具,不是模型生成能力。
本章常见报错与修复
1. ModuleNotFoundError: app
通常是执行目录错了。
你应该进入:
bash
cd services/agent-service然后命令前加:
bash
PYTHONPATH=.例如:
bash
PYTHONPATH=. pytest tests/test_tools.py2. pydantic_core._pydantic_core.ValidationError
如果你直接调用 calculate_macro_target(),参数非法时会抛出 Pydantic 的 ValidationError。
这是正常的,因为底层工具函数负责严格校验。
如果你希望得到结构化错误,请通过 execute_tool() 调用:
python
execute_tool("calculate_macro_target", {"height_cm": 175, "weight_kg": 10, "goal": "减脂", "training_days": 4})这样会返回:
python
{"error": "tool_validation_failed", "details": ...}3. unknown_tool 是不是错误?
不是。
unknown_tool 是我们故意设计的安全返回。
当模型申请一个不在白名单里的工具时,服务端不能执行它,而是返回:
python
{"error": "unknown_tool", "tool": name}这说明白名单边界生效了。
4. Field(default_factory=list) 看不懂
它的意思是:每次创建 TrainingPlanArgs 时,都生成一个新的空列表作为默认值。
不要写成:
python
injury_flags: list[str] = []因为列表是可变对象。可变默认值在 Python 中容易造成多个实例共享同一个列表。
5. 为什么 TOOL_SCHEMAS 里没有写 gt=80 这种边界?
本章的 TOOL_SCHEMAS 是给模型看的工具说明书,只描述基本参数形状。
真正强制边界在 Pydantic 模型里:
python
height_cm: float = Field(gt=80, lt=230)
weight_kg: float = Field(gt=25, lt=250)也就是说,模型可以知道"需要身高体重",但服务端最终会决定"这个身高体重是否合法"。
6. 为什么本章不调用真实 DeepSeek?
因为本章验证的是工具本身。
工具是确定性代码,应该可以在没有 API key、没有网络、没有模型预算的情况下测试。
真实模型是否会正确选择工具,是另一个层面的验证。后面章节会通过 Trace、Eval、Red Team 继续补。
7. 工具调用是不是已经有完整权限系统?
不是。
当前实现完成的是最小但关键的三件事:
- Pydantic 参数校验。
execute_tool()白名单。- 工具错误结构化返回。
它还不是完整工具治理系统,没有做到:
- 每个工具的用户授权策略。
- 每请求工具调用次数阈值。
- 预算 fail-closed 熔断。
- 外部 API 沙箱。
- 人工审批流。
不要在简历或课程里把本章夸大成完整工具治理平台。本章是打地基。
本章验收清单
完成本章后,你应该能确认:
services/agent-service/app/tools.py已经写入完整代码。services/agent-service/tests/test_tools.py已经写入完整测试。PYTHONPATH=. pytest tests/test_tools.py通过。PYTHONPATH=. pytest tests/test_service.py通过。- 正常工具调用能返回热量和营养结果。
- 异常体重参数返回
tool_validation_failed。 - 未知工具名返回
unknown_tool。 - 你能说清楚
TOOL_SCHEMAS和 Pydantic 参数模型的区别。 - 你能说清楚模型只提出 tool call,真正执行由服务端白名单控制。
- 你知道当前实现只处理一轮 tool calls,不是无限工具循环。
下一章衔接
这一章我们把"确定性计算"从模型回答里拆了出来,放进了服务端工具。
下一章会继续解决另一个问题:模型本身不会自动记住上一轮对话。我们要让前端复用 sessionId,让后端补齐可信 profile 和 recent checkins,让 Agent 每一轮重新构造上下文。
也就是第 05 章:短期记忆。