基于 QUIC 的 HTTP/3
背景
QUIC 是一种运行在 UDP 之上的传输协议,用来替代 TCP,承载 HTTP/3。它解决的不是 HTTP,而是传输层的问题。
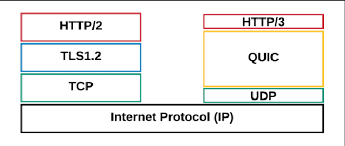
QUIC 基于 UDP 来实现,不是因为 UDP 更快,而是因为 UDP 没有内建连接和可靠性
这样 QUIC 就可以实现 自定义重传、自定义拥塞控制、自定义多路复用、自处理连接迁移等内容。
下面我们简单介绍下关于 QUIC 的一些关联知识
现状
HTTP1
在开发者的 Network 面板里,你会发现大量请求依然是 http/1.1。既然它慢、不支持多路复用,为什么不淘汰它?
-
中间件的"断层": 很多公司的架构是:客户端 -> Nginx/SLB -> 业务网关 -> 微服务。虽然最外层支持 HTTP/2 或 3,但内网环境(网关到微服务)为了极致的解析效率和兼容性,90% 依然跑在 HTTP/1.1 上。
-
调试的便利性: HTTP/1.1 是纯文本协议,工程师用简单的 telnet 或 curl 就能肉眼调试。相比之下,HTTP/2 和 3 是复杂的二进制协议,离开专门的抓包工具几乎无法排查逻辑错误。
-
微服务的成本: 如果将内部成千上万个微服务全部升级到 HTTP/3,其带来的 CPU 加解密开销(因为 QUIC 强制加密)可能会让公司的服务器成本直接飙升。
HTTP/2 在弱网场景下的限制
这是开发中经常遇到的坑:某业务从 h1 升级到 h2 后,用户反馈在移动端(4G/弱网)加载变慢了。
-
单点崩溃: HTTP/1.1 虽然并发受限(6个连接<可调整>),但鸡蛋放在不同篮子里。如果一个连接由于丢包卡住了,另外 5 个可能还在跑。
-
H2 的风险: HTTP/2 把所有请求塞进 1 个 TCP 连接。一旦底层网络发生丢包,由于 TCP 必须按顺序重传,整个连接都会陷入阻塞(队头阻塞)。
HTTP/3 在实际应用中的挑战
作为决策者,你必须面对这些工程障碍:
-
UDP 的二等公民地位: 在很多运营商和公司内网中,UDP 报文的优先级低于 TCP。一旦识别到高频 UDP 流量(QUIC),防火墙可能会直接将其限速甚至丢弃。
-
CPU 的昂贵代价: TCP 是实现在内核里的,很多网卡自带 TCP 分段卸载(TSO)硬件加速。而 QUIC 跑在用户态,所有的数据封装、解密都要靠业务进程的 CPU 去算。在大规模并发下,服务器可能因为解析协议而导致业务处理能力下降 20%。
-
基础设施的僵化: 你的负载均衡器(LB)支持根据 QUIC 的 Connection ID 进行转发吗?如果不支持,用户一换 IP,连接还是会断,QUIC 最核心的连接迁移特性就成了摆设。
名词解释
-
RTT(Round-Trip time):从发送端发送一个数据包开始,到发送端收到来自接收端的确认信号(ACK)为止,所花费的总时间。
-
CID (Connection ID): QUIC 在数据包中引入 Connection ID,用 CID 识别连接身份,使连接不再依赖具体的 IP 和端口,从而支持连接在网络变化时继续使用。
-
Stream & Frame: QUIC 将连接内的数据划分为多个独立的 Stream,每个 Stream 由若干 Frame 组成,具备独立的编号、确认和重传机制,使不同数据流之间互不阻塞。
- 现状:TCP 提供的是有序字节流,数据必须按顺序交付,一旦发生丢包,后续数据无法提前处理
-
QPACK: HTTP/3 中使用的头部压缩机制
-
**Native TLS 1.3: **QUIC 在传输层原生集成 TLS 1.3,所有控制信息和数据默认加密,提升了安全性,同时减少了握手往返次数。
- 现状: 在 TCP 体系中,连接建立和 TLS 加密是分离的阶段,部分传输层信息(如序号)对中间设备可见。
HTTP/3 中的相关特性
在这里主要跟大家介绍 QUIC 带来的某些特性
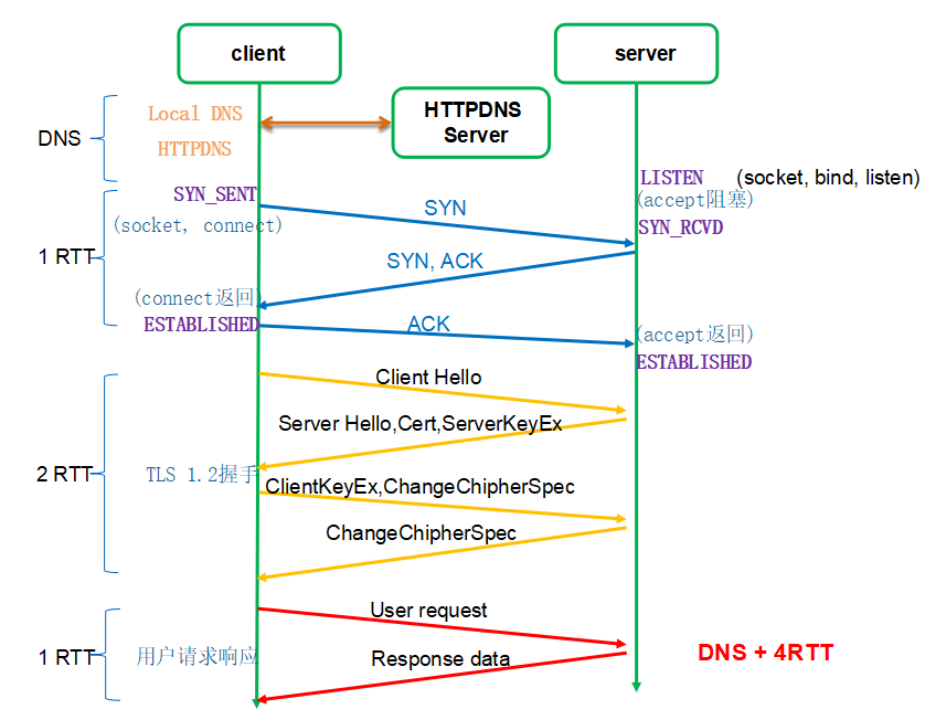
从 TCP 到 QUIC 连接建立方式的演进
- TCP + TLS 1.2:需要 3 个 RTT(往返建联)。TCP 握手 1 次,TLS 握手 2 次,最后再用一个 RTT 进行数据传输,整个下来已经 4 RTT 了
-
QUIC (现在) :仅需 1 个 RTT。
-
原理 :QUIC 内部集成了 TLS 1.3,它将传输握手 和加密握手 合并了。0-RTT 模式 :如果之前连接过,QUIC 可以利用缓存的"票据"直接发送加密数据,实现首包即数据。
-
图示:
-
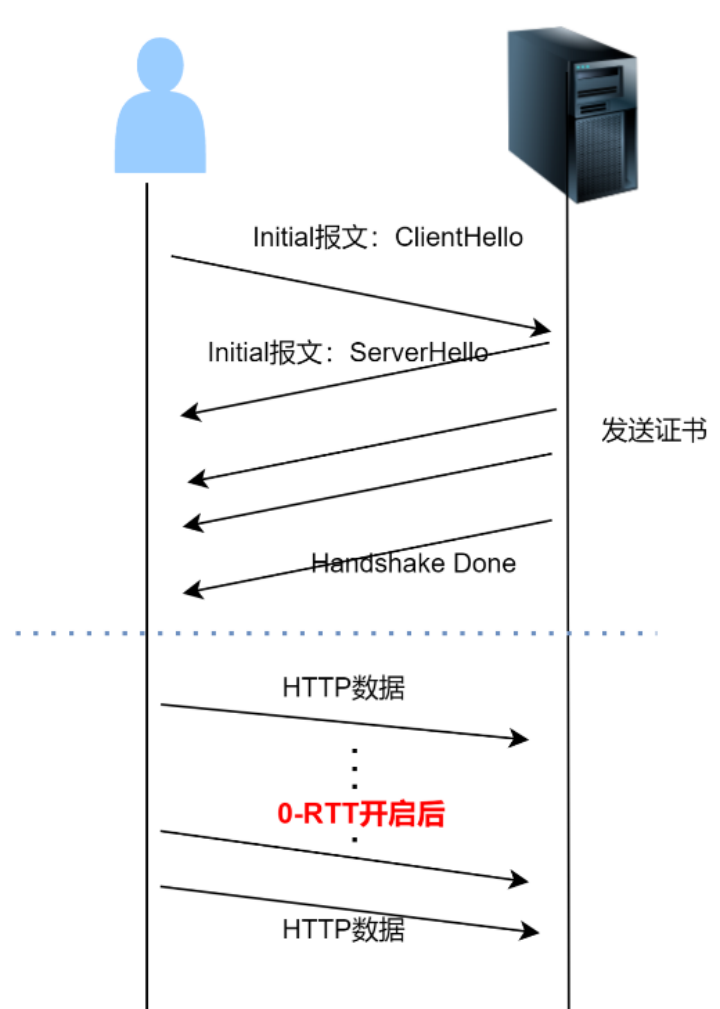
- 如果是 TCP + TLS,正常为 3-RTT,有缓存历史连接信息时为 2-RTT。QUIC 正常是 1-RTT,有缓存历史连续信息时可以实现 0-RTT。
问题:既然 quic 能做到 0RTT 的话,如果 0-RTT 允许还没握手就发数据,那黑客把之前截获的数> 据包'重放'一遍,服务器怎么防范?(0-RTT 重放攻击指黑客截获并重复发送客户端的首包数据,> 导致服务器重复执行非幂等操作,比如重复扣款)。
防范策略:
协议层: 服务器记录并识别近期重复的包标识符。
业务层: 0-RTT 仅允许 GET 等幂等请求,严禁处理 POST 等修改数据的请求。
时效性: 限制 Session Ticket 的有效期,缩短攻击窗口。
队头阻塞问题及其改进
-
TCP 队头阻塞
-
在 HTTP/1.1 中,请求依赖 TCP 顺序传输,同一连接上的数据必须按字节顺序交付;当前面的数据包丢失或变慢时,后续数据即使已到达也不能处理,只能等待。
-
HTTP/2 虽然在应用层支持多路复用,但底层仍使用 TCP,一旦发生丢包,TCP 的顺序交付机制仍会阻塞整条连接,因此队头阻塞问题依然存在。
-
-
QUIC 的多路复用 (HTTP/3 的优势):
- 在 QUIC 中,底层使用 UDP,因为 UDP 不要求按顺序交付数据。QUIC 在此基础上自行实现多路复用,把数据拆分为多个独立的 Stream,每个 Stream 单独编号、单独重传。
当某个 Stream 的数据丢失时,只会阻塞该 Stream,其它 Stream 的数据仍可正常交付给应用,从而避免了 TCP 中"一个包丢失,整条连接被卡住"的队头阻塞问题。
- 在 QUIC 中,底层使用 UDP,因为 UDP 不要求按顺序交付数据。QUIC 在此基础上自行实现多路复用,把数据拆分为多个独立的 Stream,每个 Stream 单独编号、单独重传。
总结来说就是
- QUIC 将 HTTP/2 中用于缓解队头阻塞的 Stream 多路复用机制下放到传输层,通过 Stream 级的编号、确认和重传,避免 TCP 中连接级顺序交付带来的阻塞问题。通过在多个 Stream 之间交错传输数据,可以将丢包影响限制在单个 Stream 内。该策略在现实网络中尤为有效,因为丢包通常以连续突发的形式发生;相比之下,TCP 的拥塞控制和顺序交付机制会在丢包发生时同时阻塞数据交付并降低整条连接的发送能力。
连接迁移机制
**现状:**HTTP/1.1 和 HTTP/2 基于 TCP,TCP 连接由 IP + 端口 标识,连接状态与当前网络环境强绑定
-
**导致的问题:**实际网络环境经常变化,移动场景下 IP 和端口可能频繁改变,一旦地址变化,TCP 无法识别为同一连接。原有连接只能中断并重新建立
-
**结果:**需要重新进行连接和加密握手,已建立的请求和传输被打断,网络切换时延迟明显增加,应用层需要额外处理重连逻辑
**新的机制:**QUIC 在传输层引入 Connection ID,连接由协议级逻辑 ID 标识,网络地址变化时,仅更新通信路径
-
**解决的问题:**原有连接状态得以保留,无需重新握手和建连,网络变化不再等同于连接中断
-
**带来的好处:**网络切换过程更平滑,连接稳定性显著提升,更适合移动网络和弱网环境
我连接迁移的时候我怎么保证我的连接 ID 是不变的呢?
QUIC Connection Context 是服务端为每一个 QUIC 连接维护的一份 完整会话状态对象,它让"连接"不再依赖 IP/端口,而依赖 加密身份 + 协议状态。
连接迁移时,CID 不是不变,而是可识别且可切换的。 QUIC 通过 CID 由服务端生成 + 客户端按指示切换,来保证迁移不断连。
客户端可以用相同的 CID 来进行发包
其他的做法下,服务端也会提前下发备用 CID,客户端网络切换后可以用备用的 CID,服务端也能识别
HTTP/3 的头部压缩机制
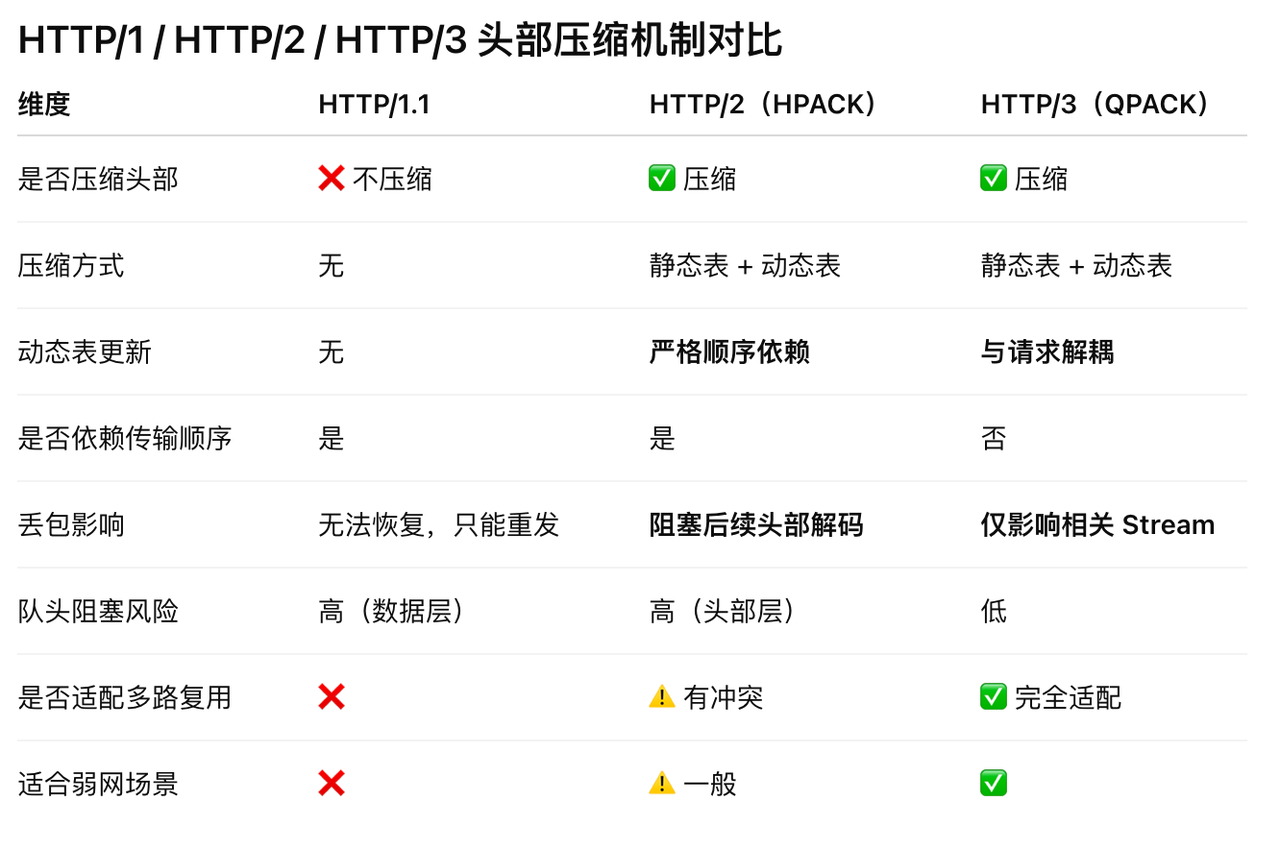
- HTTP/1 选择简单但低效,HTTP/2 用压缩换带宽却受限于顺序,而 HTTP/3 的 QPACK 则在并行传输前提下重新平衡了效率与稳定性。
示例 Demo
以下是代码
HTTP/3 vs HTTP/1.1 队头阻塞对比 Demo
用 Caddy 同时起 HTTP/1.1 和 HTTP/3 两个站点,各自并发加载 30 个资源,对比总耗时,直观感受 QUIC 消除队头阻塞的效果。
目录结构
http3-demo/
├── Caddyfile
├── h1/
│ └── index.html # HTTP/1.1 页面
├── h3/
│ └── index.html # HTTP/3 页面
└── static/
└── payload.bin # 200KB 测试资源Caddyfile
caddyfile
# HTTP/1.1
http://h1.localhost {
root * ./h1
file_server
}
# HTTP/3
https://h3.localhost {
tls internal
root * ./h3
file_server
}h3/index.html(HTTP/3 页面)
html
<!doctype html>
<html>
<body>
<h2>HTTP/3(QUIC)</h2>
<button onclick="run()">开始加载 30 个资源</button>
<pre id="log"></pre>
<script>
const COUNT = 30;
function run() {
const start = performance.now();
let done = 0;
const log = document.getElementById('log');
log.innerText = '';
for (let i = 0; i < COUNT; i++) {
const t0 = performance.now();
fetch('/static/payload.bin?i=' + i).then(() => {
log.innerText += `资源 ${i} 完成 ${Math.round(performance.now() - t0)} ms\n`;
if (++done === COUNT) {
log.innerText += `\n总耗时 ${Math.round(performance.now() - start)} ms`;
}
});
}
}
</script>
</body>
</html>h1/index.html(HTTP/1.1 页面)
与 h3 页面唯一的区别是标题 <h2>,逻辑完全相同:
html
<!doctype html>
<html>
<body>
<h2>HTTP/1.1(TCP)</h2>
<button onclick="run()">开始加载 30 个资源</button>
<pre id="log"></pre>
<script>
const COUNT = 30;
function run() {
const start = performance.now();
let done = 0;
const log = document.getElementById('log');
log.innerText = '';
for (let i = 0; i < COUNT; i++) {
const t0 = performance.now();
fetch('/static/payload.bin?i=' + i).then(() => {
log.innerText += `资源 ${i} 完成 ${Math.round(performance.now() - t0)} ms\n`;
if (++done === COUNT) {
log.innerText += `\n总耗时 ${Math.round(performance.now() - start)} ms`;
}
});
}
}
</script>
</body>
</html>static/payload.bin(200KB 测试资源)
这是个 200KB 的二进制占位文件,内容无所谓,用命令生成即可:
bash
mkdir -p static
head -c 204800 /dev/urandom > static/payload.bin运行
bash
caddy run然后分别访问:
- HTTP/1.1:http://h1.localhost
- HTTP/3:https://h3.localhost
各点一次「开始加载 30 个资源」,对比底部的总耗时。HTTP/1.1 受限于 TCP 队头阻塞和连接数,多个请求会相互排队;HTTP/3 基于 QUIC,多路复用不受单个丢包影响,总耗时通常明显更低。
还需要本地安装一下 CaddyServer
Shell
brew install caddy安装完成后渠道对应目录下执行
Shell
caddy run再访问本地的地址,然后可以根据 F12 来调整网络速度实验
Shell
http://h1.localhost/
和
https://h3.localhost/**为什么用 Caddy (**https://github.com/caddyserver/caddy****)
在整个网页访问与多资源加载的流程中,Caddy 作为服务端协议对端,主要承担 HTTP/1.1 与 HTTP/3 的连接建立、协议状态维护以及静态资源的透明返回。
它不参与业务逻辑、不引入额外调度或延迟,从而保证浏览器端观察到的性能差异主要来源于 协议本身及网络条件。
理论上也可以使用 Go 或其他语言自行实现 HTTP/1 与 HTTP/3 服务,但自实现方案在 QUIC 参数、TLS/ALPN 配置、运行时调度等方面引入的变量较多,容易干扰实验结论。
并且 HTTP/3 必须运行在 TLS 之上,因此一个能够稳定、自动、无歧义地提供 HTTPS 的服务端,是协议对比实验的必要条件。
因此本实验选用 Caddy,以其 原生、成熟且低干扰的 HTTP/3 支持,尽量将服务端对实验结果的影响降到最低。
实验结果
正常网络情况下两者速度差不多,但是在弱网或者网速极慢的情况下,HTTP3 明显优于 HTTP1
正常情况下
- 在低延迟、低丢包的正常网络环境中,HTTP/1.1 与 HTTP/3 在多资源加载场景下整体性能接近。原因在于 TCP 拥塞和重传几乎不被触发,浏览器为 HTTP/1.1 建立的有限并行连接已能满足请求需求,因此 HTTP/3 的 stream 并发优势不明显。
弱网情况下
- 在高延迟或存在丢包的弱网环境中,HTTP/1.1 会因连接数限制和 TCP 连接级阻塞表现出明显的分批排队加载,而 HTTP/3 基于 QUIC 的多 stream 机制能够隔离丢包影响,使资源加载更加平滑稳定,从而显著缩短整体完成时间。
其他
Go 代码中基于 HTTP1 的请求中,提高连接数能解决问题吗?
- Go 代码中常用的 net/http 客户端主要基于 HTTP/1.1(在 HTTPS 场景下可自动升级为 HTTP/2),目前并不原生支持 HTTP/3。虽然可以通过配置提高并发连接数,从而绕开浏览器在 HTTP/1.1 下约 6 个 TCP 连接的限制,但这种方式本质上仍是通过堆叠 TCP 连接提升并发,并未改变协议模型。
在弱网环境下,TCP 连接级阻塞和重传问题依然存在,甚至可能因连接过多而加剧拥塞;而 HTTP/3 通过 单连接、多 stream、丢包隔离 的设计,从协议层面解决了这一问题,因此两者在弱网场景下的表现存在本质差异。
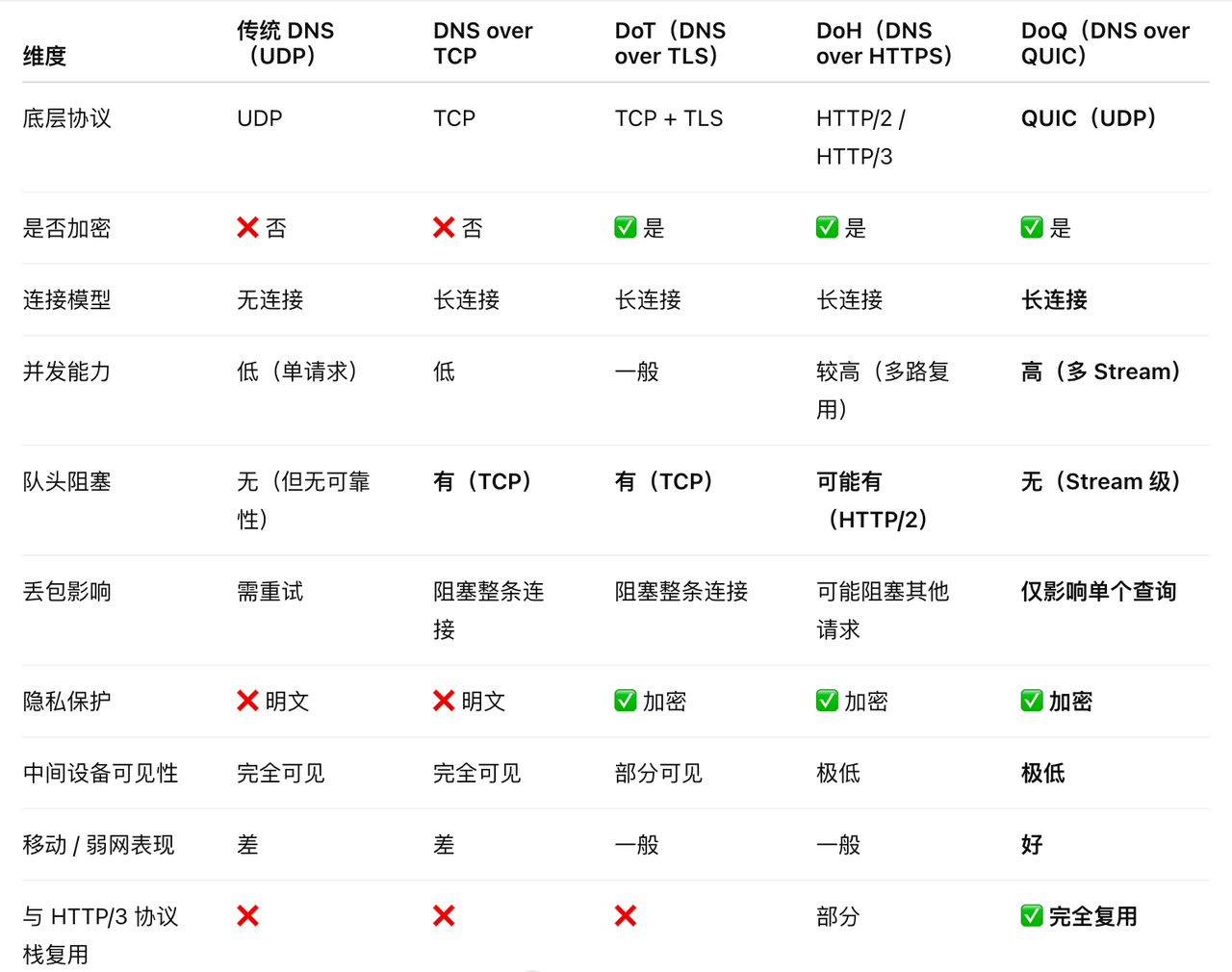
DNS over QUIC (DoQ):
现在的 DNS 解析也存在队头阻塞和明文隐私问题,DoQ 是个趋势。
总结
HTTP/3 并不是让网络更快,而是让真实网络环境下的请求更稳定。在移动网络、弱网或多资源并发场景中,HTTP/3 通过 Stream 隔离、连接迁移和默认加密,减少丢包和网络变化带来的整体阻塞。
QUIC 协议的出现,为 HTTP/3 奠定了基础。面对新的协议,同时也有着各种各样的担忧,QUIC 协议在稳定性上在成熟度上,的确还不如 TCP 协议,但是也经过好几年的发展,成熟度目前也相当不错了,Nginx 近期也支持了 QUIC 协议。但是想将整体应用往新协议上迁移确实还是需要一定的成本。