前言:面试官的连环炮
在日常开发或大厂面试中,很多同学都能熟练地写出:
java
CompletableFuture.supplyAsync(() -> {
return "Hello Zifeng";
});但当面试官抛出以下连环追问时,往往会卡壳:
-
supplyAsync到底在哪个线程池执行? -
ForkJoinPool是什么?为什么它在大数据量计算时比传统线程池快? -
工作窃取(Work-Stealing)的底层指针是如何运作的?为什么偷尾不偷头?
-
为什么
CompletableFuture默认线程池不适合传统的 I/O 密集型任务?
今天,我们就由浅入深,从分治思想的缺陷一路手撕到 CompletableFuture 的底层源码,彻底打通你的并发任督二脉。
第一部分:从传统线程池的痛点聊起
1. 普通线程池的"贫富不均"问题
假设我们现在有一个高并发计算任务:求 1 到 10 亿的和 。 我们很容易想到利用分治思想(Divide And Conquer),将任务切分成 4 个子任务,丢给拥有 4 个核心线程的传统线程池:
-
任务 1:1 ~ 2.5 亿
-
任务 2:2.5 亿 ~ 5 亿
-
任务 3:5 亿 ~ 7.5 亿
-
任务 4:7.5 亿 ~ 10 亿
然而,在实际的复杂业务场景中,由于数据的异构性,可能会出现:
-
线程 1 领到的任务计算极其复杂,忙得脚不沾地。
-
线程 2、3、4 领到的任务很简单,瞬间执行完毕,极度清闲。
在传统的 ThreadPoolExecutor 中,闲置的线程只能眼睁睁看着核心队列或者别人的任务发呆,造成了极大的 CPU 资源浪费。
2. ForkJoinPool 的救场:工作窃取(Work-Stealing)
为了解决这种"忙死忙死、闲死闲死"的现象,ForkJoinPool 应运而生。其核心宗旨就是:让忙碌的线程少干点,让闲置的线程帮忙干(Work Stealing)。
当 Worker-2 线程将自己队列里的任务执行完毕后,它不会阻塞,而是主动充当"小偷",去 Worker-1 的任务队列中窃取一部分任务来帮其执行,从而将整个系统的 CPU 利用率拉满。
第二部分:深度剖析工作窃取(Work-Stealing)算法
1. 核心结构:独占双端队列
要理解工作窃取,首先要看明白它的数据结构。
-
普通线程池 (
ThreadPoolExecutor) :所有核心线程共享一个BlockingQueue。在高并发下,100 个线程同时去抢一个队列的头节点,锁竞争极度激烈。 -
ForkJoinPool :每个工作线程(
ForkJoinWorkerThread)都拥有一个独立属于自己 的特殊队列------WorkQueue(双端队列)。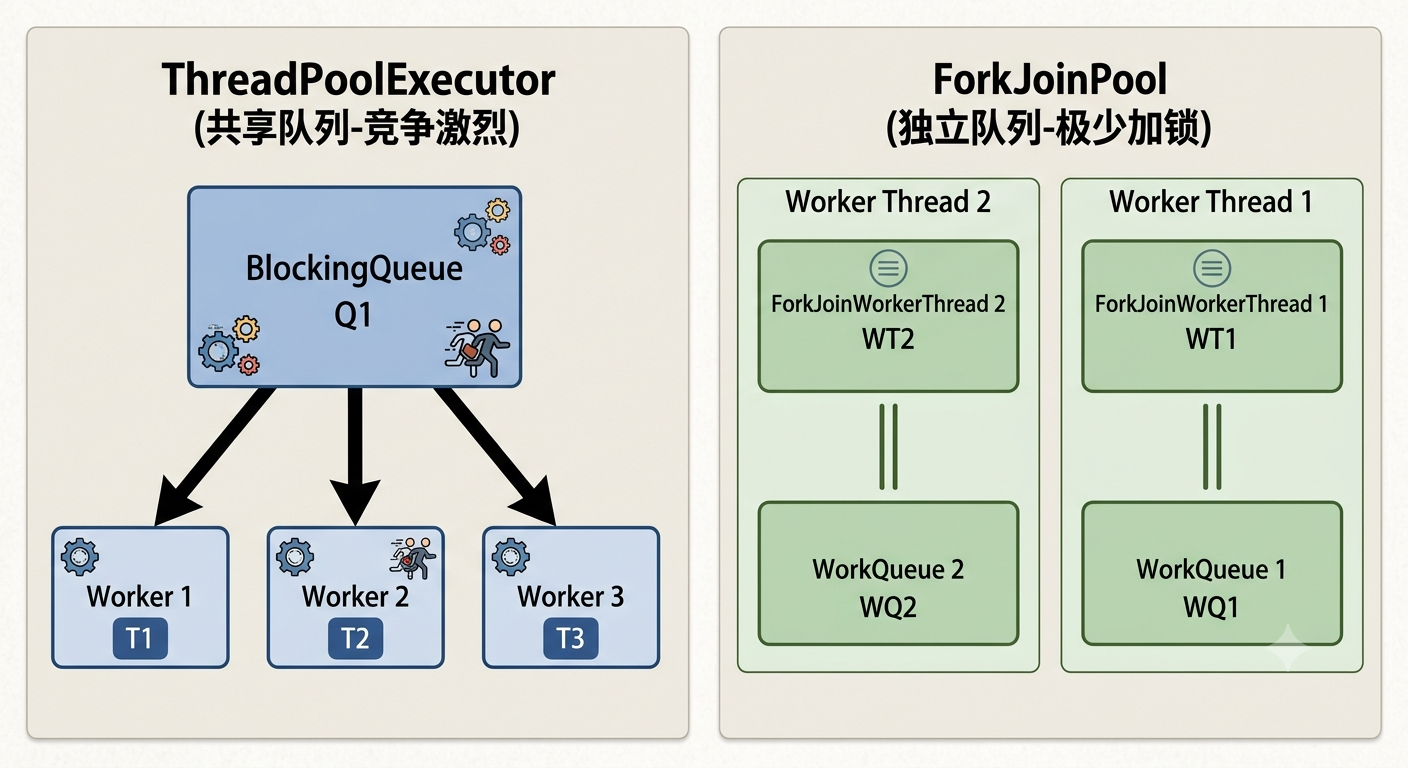
2. 核心面试题:工作窃取怎么偷?为什么"偷尾不偷头"?
这是各大厂面试官最喜欢抠的底层细节。
当 Worker-1 自己处理任务时,它和 Worker-2 (窃取者)的操作方向是完全相反的:
-
本地线程(Worker-1) :采用 LIFO(后进先出) 或 FIFO 策略,默认从双端队列的 头部(Head) 获取任务执行。
-
窃取线程(Worker-2) :永远从被窃取队列的 尾部(Tail) 偷取任务。
Worker-1(本地线程)--> 从 [Head] 取任务
↓
[Task A] [Task B] [Task C] [Task D]
↑
Worker-2(窃取线程)--> 从 [Tail] 偷任务
💡 为什么这么设计?
减少锁冲突:本地线程操作头,窃取线程操作尾,绝大多数情况下两者互不干扰,可以通过无锁的 CAS 操作完成,性能极高。
压榨大任务 :在分治算法中,越靠近队列尾部 的任务(最初
fork出来的祖先任务)通常体积越大、包含的子任务越多。偷一个大任务过来继续拆分,可以有效减少后续重复窃取的次数。
第三部分:手撕 ForkJoinPool 核心源码与机制
1. ForkJoinTask 的家族谱系
ForkJoinTask 类似于传统线程池里的 Runnable / Callable,它有两大核心子类:
-
RecursiveTask<V>:有返回值的分治任务。 -
RecursiveAction:无返回值的分治任务。
2. 核心模板与 fork() / join() 源码逻辑
我们在使用 RecursiveTask 时,核心逻辑都写在 compute() 方法中:
java
public class SumTask extends RecursiveTask<Long> {
private final long start;
private final long end;
private static final long THRESHOLD = 10000L; // 阈值
public SumTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 1. 如果任务足够小,直接计算
if ((end - start) <= THRESHOLD) {
long sum = 0;
for (long i = start; i <= end; i++) sum += i;
return sum;
}
// 2. 否则,切分成子任务
long middle = (start + end) / 2;
SumTask leftTask = new SumTask(start, middle);
SumTask rightTask = new SumTask(middle + 1, end);
// 3. 核心调用
leftTask.fork(); // 异步推入当前线程的 WorkQueue
Long rightResult = rightTask.compute(); // 当前线程直接原地计算右半部分(不浪费线程)
Long leftResult = leftTask.join(); // 等待左半部分结果
return leftResult + rightResult;
}
}🛠️ 源码深度剖析:
-
fork()做了什么?很多人以为调用
fork()会像new Thread().start()一样立即启动新线程。大错特错!源码中,
fork()最终调用的是WorkQueue.push()。它仅仅是把当前切分出来的子任务放入当前工作线程的WorkQueue队头中,等待被调度或被别人窃取。 -
join()做了什么?join()的底层绝不是盲目死等(如Object.wait())。它会检查当前任务的状态。如果任务还没执行,当前线程会主动把这个任务弹出来自己执行 ;如果任务被别人偷走了,当前线程会去协助执行那个偷走自己任务的线程的队列,或者干脆去偷别的任务。总之,当前线程绝不闲着!
第四部分:CompletableFuture 底层与线程池策略
1. supplyAsync 到底在哪个线程池执行?
翻开 JDK 源码,我们会看到如下定义:
java
private static final Executor ASYNC_POOL = USE_COMMON_POOL ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) {
return asyncSupplyStage(ASYNC_POOL, supplier);
}结论 :在默认情况下(没有指定自定义 Executor 且 CPU 核心数大于 1),CompletableFuture 默认使用的是 ForkJoinPool.commonPool()(公共的 ForkJoin 线程池)。
2. commonPool 的线程数陷阱
ForkJoinPool.commonPool 的默认并行度(线程数)是:

为什么要减 1?
因为需要留出一个核心给当前发起调用的 Main 主线程,防止整个系统的 CPU 被异步任务完全占满导致主流程卡死。
3. 黄金法则:CPU 密集型 vs I/O 密集型
-
为什么适合 CPU 密集型?
因为
ForkJoinPool的设计初衷是为了高效率利用多核 CPU 进行数学计算、图像处理、矩阵流转等。配合工作窃取,能将 CPU 颗粒度榨干到极限。 -
为什么极其不适合 I/O 密集型?
如果你的异步任务是查数据库、调用第三方 HTTP 接口、读写文件 ,线程会长时间处于
WAITING或BLOCKED状态。由于commonPool的线程数默认只有 N - 1个,一旦全部阻塞,后续所有的CompletableFuture任务都将在队列中死等,整个系统的接口响应吞吐量出现断崖式下跌!
🚨 生产环境生产避坑指南:
在企业级开发中,只要涉及 I/O 操作,强烈严禁 直接使用默认的
supplyAsync(Supplier)!必须传入自定义的线程池:
Java
javaExecutor ioExecutor = Executors.newFixedThreadPool(100); // 针对I/O密集型加大线程数 CompletableFuture.supplyAsync(() -> { /* 查数据库 */ }, ioExecutor);
第五部分:高频面试点------异步编排与电商实战
1. 傻傻分不清:thenApply vs thenCompose
这两个方法都是用于上一步执行完后流转到下一步,但区别极其关键:
-
thenApply(Function<T, U>):将上一步的结果T 转换成 U。如果你的 Function 内部返回的又是一个CompletableFuture,那它的返回值会变成极其恶心的嵌套结构 :CompletableFuture<CompletableFuture<Result>>。 -
thenCompose(Function<T, CompletableFuture<U>>):类似于 Java Stream 里的flatMap。它会将内部返回的CompletableFuture自动平铺展开 ,最终返回的是干净的CompletableFuture<Result>。
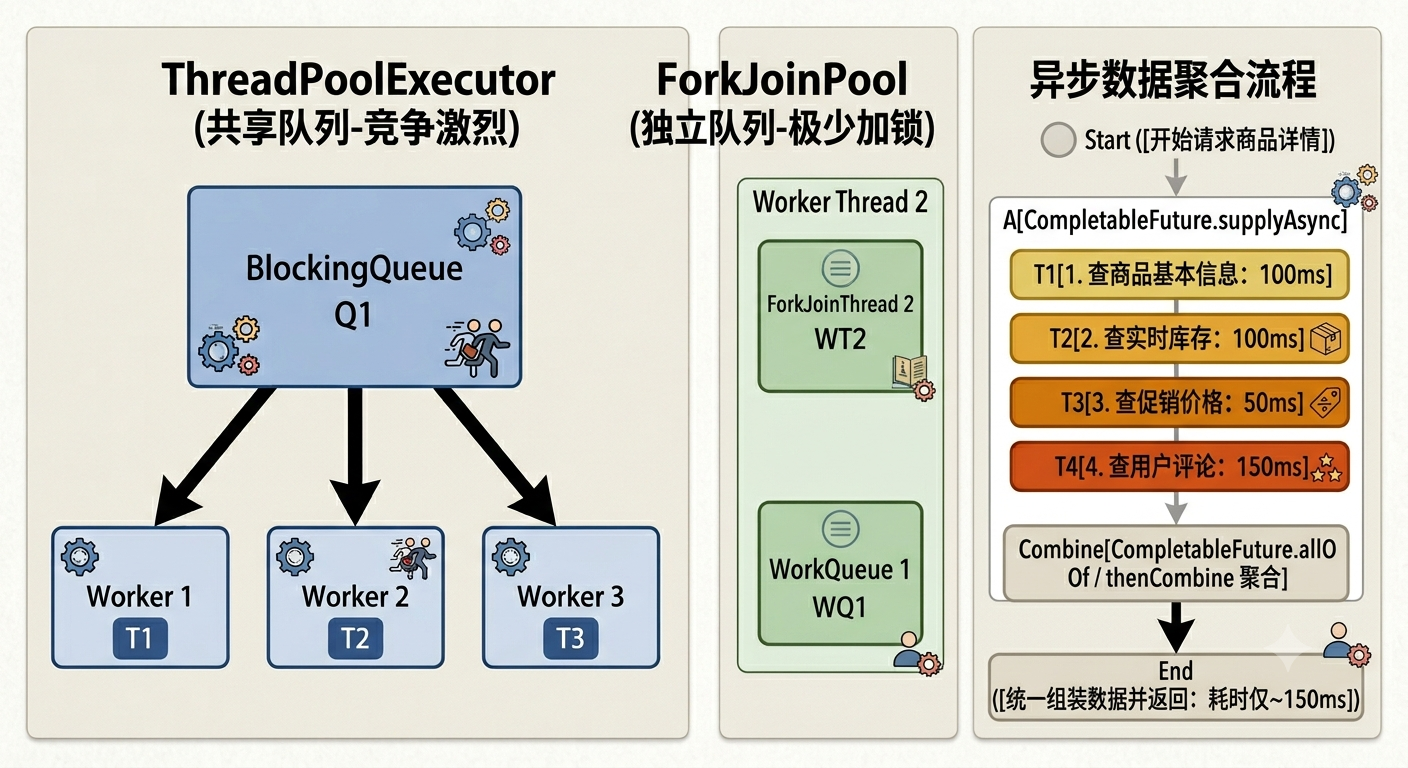
2. 大厂经典:电商商品详情页的异步编排优化
电商的商品详情页是一个典型的 I/O 密集型汇总接口。一个页面展示需要聚合:商品基础信息、库存状态、真实价格、用户评论、推荐商品。
-
传统串行方案:5 个接口依次调用,100ms + 100ms + 50ms + 150ms + 100ms = 500ms。
-
CompletableFuture 并行编排方案 :利用
allOf或thenCombine将无依赖的任务并发化,最终耗时取决于最慢的那个接口,即max(100,100,50,150,100) = 150ms!
总结:面试必背黄金八股文
为了方便大家应对面试,小哥把上面所有的精华提炼成 4 句可以直接背诵的"金句":
-
ForkJoinPool 为什么高效?
答:它摒弃了传统线程池共享单队列造成的锁竞争,为每个线程配备了独立的双端队列;同时利用工作窃取算法 ,让空闲线程从其他忙碌线程的队尾通过无锁 CAS 偷取任务执行,实现了极高的 CPU 利用率。
-
为什么工作窃取是"偷尾不偷头"?
答:因为本地工作线程永远从队头 拿任务,外部窃取线程从队尾偷任务。这样将两者的读写冲突降到了最低。同时,队尾往往是刚开始切分出来的大任务,偷过去更划算。
-
CompletableFuture 默认线程池有什么坑?
答:默认使用
ForkJoinPool.commonPool(),其核心线程数是 CPU - 1。它非常适合 CPU 密集型计算,但极不适合 I/O 密集型任务。在生产环境下进行数据库或网络 I/O 操作,必须传入自定义的线程池。 -
thenApply 和 thenCompose 的本质区别是什么?
答:
thenApply负责对结果进行普通的 Map 转换,如果返回类型是 Future 会产生嵌套;而thenCompose类似于flatMap,它能将多层嵌套的 Future 结构打平,返回一维的CompletableFuture。
📌 码字不易,技术干货深度复盘!
如果这篇文章帮你看清了 MyBatis-Plus 查询的底层底细,别忘了 点赞、关注、收藏 三连走一波!支持作者不迷路,更多底层源码干货持续输出中!🚀
让我们一起学习面试知识,拿到自己想要的offer!