《智慧的疆界》读书笔记
- 前言
-
- 图灵机是什么?
- 什么是人工智能?人工智能到底是研究什么东西?
- 关于三大主义学派,以及他们主要是干嘛的?研究什么的?
- 机器学习、深度学习、强化学习的区别?
- [大模型、小模型、预训练、 基模、后训练等基本概念](#大模型、小模型、预训练、 基模、后训练等基本概念)
- 后记
- 参考
前言
前段时间看了《智慧的疆界》一书,书中讲了三大学派、人工智能的发展史以及作者对ai的理解。书是好书,虽说是一本科普,但还是不少内容不太好理解。这里权且谈谈几个问题,作为本书的笔记。
图灵机是什么?
图灵机对于学计算机的人来说应该或多或少都有听过,这个名词大都和一些抽象的、宏观的论述放在一起,"计算机的灵魂呀", "概念机呀","改变了计算机科学"呀, 让人听起来有些不明觉厉。
回归到其最初的定义。
图灵机是一种将人的计算行为 抽象化的概念机。
他是用来抽象人的计算能力的一种模型,通过这个模型可以模拟人类能够进行的任何计算过程。
听起来相当抽象,先来看看图灵机是怎么玩的吧。
其实图灵机本身的运行逻辑还是蛮简单的,它基本思想是通过机械的操作来模拟人们用纸笔来进行数学运算的过程。 主要包括两种重复的机械动作:
- 在可以存储的某个介质中(模型中就是纸带)写入或者擦除某个符号。
- 将注意力(可以理解为指针,当前地址)从介质的一个地方移动到另一个地方。
当某个动作完成之后,人要决定下一个动作是什么,这个动作取决于人类目前所关注的纸上的当前符号,以及人当前的思维状态。
为了模拟这个运算过程,图灵机这台假想的机器有以下几个部分组成:
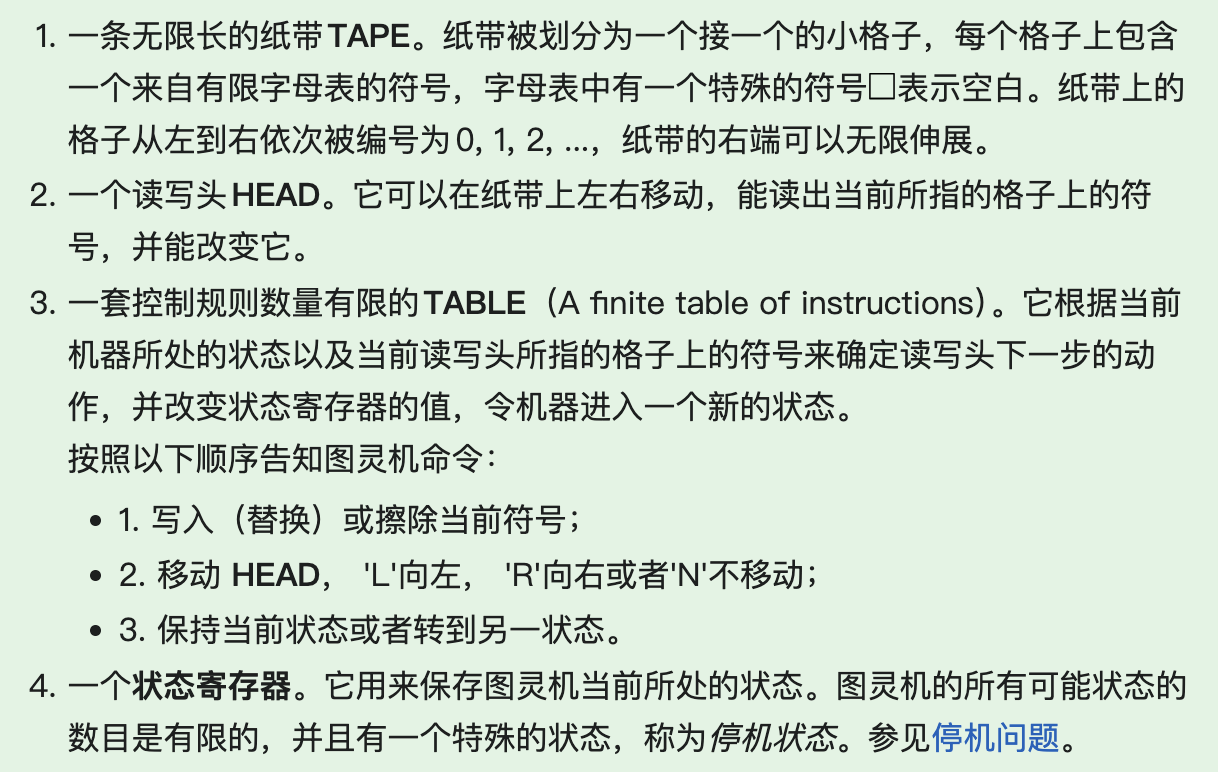
(听起来是不是有点我们现在计算机中程序执行的状态。纸带就相当于内存、读写头就相当于指针,规则表就相当于程序指令或者程序。 不过这个模型可是在 图灵在 1936 年提出来的。)
通过这样一种有限的、机械的 步骤可以实现模拟任何人类能够完成的计算过程。更重要的是,这样简单的模型可以容易的通过机械、电子技术来物理实现(也就是后面发展出来的计算机。 没错,最初的计算机的发明首要解决的问题之一就是计算问题,帮人类来计算哪些原本需要手动运算的方程和算法。 写到这儿突然间想到了一个电影中的片段,我国在设计原子弹的时候,当时技术所限、很多复杂的计算过程都是通过人力手工完成的),这也极大的促进了计算机技术的发展。
说了图灵机,在顺便说说图灵完备 。 如果一个新的计算模型可以解决所有算法上可计算的问题,那么它就是图灵完备的 (也可以说它是图灵等价的)。因此也就可以描述任何人类能够完成的计算过程。
我们身边接触到的很多编程语言都是图灵完备的,比如说c、cpp、java、javascript、go 、lisp等等。他们本质上都是计算模型,只是运行的逻辑不同。所以理论上任何用 C 实现的算法、逻辑,用 go 也可以实现。但是也有一些标记语言,如 HTML、CSS,他们就不是图灵完备的。
我们最初在学 C语言时,教材上说有三种基本的结构,顺序结构、条件结构、循环结构。只要有了这三种基本结构,就可以实现任何算法。当时还不懂什么意思,现在看看,这三种结构就保证了 编程语言的图灵完备性(是充分条件,但不是必要条件。 有兴趣的可以了解下 brainFuck 【3】,仅仅 8 个符号就构造了一个图灵机,但是它就没有明显的条件结构和循环结构)。
什么是人工智能?人工智能到底是研究什么东西?
最近大模型搞得很火,好像提到 人工智能(AI),就是指大模型。这里强调一点,大模型(LLM)是AI,但是AI 并不仅仅只是大模型。
人工智能在维基百科中的定义是:
bash
人工智能是指计算机系统执行通常与人类智能相关的任务的能力,例如学习、推理、解决问题、感知和决策。简单来说一句话,让机器拥有智能(拥有比肩人类智能(识别、计算、推理、决策、思维)的能力)。
细分一下,可以分为两种,一种是强人工智能,这种理念是模仿人类的思维,希望能够研制出各方面与人类智能比肩的智能体,**拥有自己的心智和意识,可以根据自己的意图来展开行动。**看过钢铁侠、黑客帝国等科幻电影的都应该理解,强人工智能讲的就是电影里的那些AI。
还一种是弱人工智能。弱人工智能专注于 让 AI借鉴人类来解决某一类问题而表现出的智能行为,也叫做专用人工智能。 现在我们能见到的大都属于弱人工智能,扫地机器人、vibe coding、自动驾驶、图像识别等等...
AI 作为一名学科来说,涉及的内容非常广,与数学、哲学、信息科学、计算机科学、物理学、心理学、神经科学、认知科学和控制科学等等都有密切的关联。 所以这些科学中只要与 让机器拥有智能 有关联的研究都属于AI 的范畴。
从五六十年代早期的棋类游戏(完全信息对抗游戏)、模式识别、自然语言处理,到现在的图像识别、大模型(生成式内容)、机器人、自动驾驶等等,都是在各种领域、各种场景来赋予机器人类的能力(识别、计算、推理、决策、思维)、都是AI 研究的内容。
可以肯定的说,未来,还会有更多。
关于三大主义学派,以及他们主要是干嘛的?研究什么的?
首先,三大主义学派的内容相当深奥。这里主要对三大主义学派是什么、研究什么做一个非常简单扼要的介绍,旨在提供一个基本的整体认知。
提到AI,就不得不提其发展过程中的三个主要学派,或者说三大主要方向:符号主义、连接主义和行为主义。
符号主义
符号主义主义中的"符号"说起来有些不好理解,我们可能会无意识的理解为类似小学课本中学到的逗号,句号这种标点符号,其实不是的。这里的符号更像是一个名字 ,一个个我们赋予了现实意义的名字。比如说"苹果" 这两个字,是一个名字,是一个我们赋予了那个红红的,甜甜的、水果这种东西。提到苹果,我们想到的是那个具有意义的东西(红红的、甜甜的、水果)。 这里的"苹果" 二字就是 一个符号。 它了苹果,我们还可以把 "apple" 赋予这个含义,符号只是一个抽象概念,重要的是它表示的是一个现实实体(其实也可以是抽象的概念)。

理解了符号主义,我们再来说说符号主义的本质是要研究什么?
符号主义主要是利用符号连接现实的那些知识、概念、联系,然后通过各种推理的逻辑,产生出新的知识或者 做出决策,有或者说表现出人类的智能表现。
这里面设计到不少内容,一个是知识如何表示,或者说用什么样的符号来表示这个现实世界; 这涉及到知识工程中的知识表示 , 有很多中方式、比如说通过谓词逻辑来表示知识, 比如说通过语义网络来表示知识,还有面向对象的表示(对,就是编程语言中的面向对象)等等等等.
还有一个就是如何进行推理,利用确定性的规则,来从A->B。 书中介绍了之前前辈们用的一些推理方式,比如利用 数理逻辑(就是大学中学到的三段论、命题逻辑那些内容)、利用启发式搜索(不寻求一次性最优解,在有限的条件中寻找较优解,然后通过不断迭代进行优化) 等等。
上面的过程简要概括也就是描述已知、推理未知。
后来符号的主义在发展的过程中,发现现实实在是太复杂了。 不仅仅是依靠事先输入的一些知识、规则,所能推理出来的,尤其是涉及到普世的常识方面。 于是,慢慢关注点就放在了让机器拥有自我学习,自我改进的方面,也就是基于符号主义的机器学习。 在20 世纪 70 年代的机器学习最求的目标是从大量数据中自动总结、提炼出隐藏在数据背后的那些知识 。这个部分也叫做基于规则的机器学习 。 (对,机器学习并不仅仅是神经网络那些内容)
人脑虽巧,但是能够解决的问题各种各样。这里的很多问题无法被符号化,或者符号化之后很难找到背后确定的运作机制(无法被确定的规则推理),因此后来人们慢慢开始转变其他方向(开始从基于统计和概率、基于连接等方式)来探索智能。
连接主义
符号主义以确定的规则来推理知识,以此来模仿人类智能。而连接主义走的是另一条路线,既然人的大脑可以产生智能, 那直接模拟人脑结构,是不是通向智能的方向呢?
在十九世纪初,科学界已经慢慢知道人的大脑是通过一个一个的神经元连接来进行工作的。于是有一部分科学家如沃伦.麦卡洛科、皮茨等开始猜想 是否存在某种工作机制,将人类大脑大量神经元机械性放电的过程组织起来(也就是通过模拟神经元直接的连接),由此形成思维、知识和记忆。
那么如何抽象、模拟神经元呢? 或者说神经元的基础模型是什么呢?
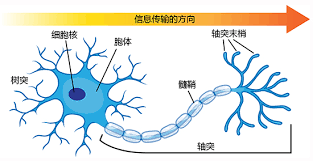
他们发现,神经元细胞的"树突" 收到外部刺激达到一个阈值之后,才会沿着"轴突"方向向其他相连的神经元 放电(发送脉冲信号,刺激"突触"和其他的神经元的树突交换神经递质来完成)。 这个过程要么发射信号、要么不发射信号,很类似逻辑学中的 "与" "或" "非" 逻辑门。 于是,他们尝试是神经元网络建立一个以逻辑学为基础的机械性思维模型。
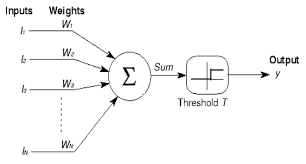
如上图所示,是简单的单个 M-P 神经元模型。 这样一个神经元可以接收其他神经元的输入信号,不同的信号的有不同的权重,以此来代表信号之间的重要性查表。然后信号进过加权求和后与阈值进行比较,输出最终的结果。
然后通过这样一个一个的神经元进行连接,最终形成一个个神经网络。 通过调整神经元之间的权重 ,构造不同的神经网络连接方式来拟合现实世界,以此表现出智能。
但是,上述的两个重点(调整权重、构造不同的神经网络连接)都不容易,再加上网络层次的增加之后会让连接数量暴增,也让最终结果的拟合输出无法解释(这也是为什么现在大模型的底层是个概率模型,无法解释为什么最终会输出成出现的那个结果)这些都是连接主义在发展过程中遇到的各种问题。
以上是对连接主义的方式十分浅显的介绍,详细的可以参照【1】,尤其是连接主义一节中关于感知机case 的介绍,会对神经网络拟合现实有一个感性的认识。
行为主义
符号主义关注的是推理和逻辑,连接主义关注的是通过模拟大脑神经元之间的连接来模拟智能,行为主义关注的则是可感知的行为:只要一个东西的输入输出行为看起来和智能没有区别,那它就是有智能的。 任何系统,不管它是人类、动物、机器、甚至是一块石头,只要它在相同的输入下,能产生和智能系统相同的输出,那么它就是有智能的。
- 不需要知道 AlphaGo 的脑子里是怎么想的,只要它能赢李世石,它就有围棋智能
- 不需要知道波士顿动力的机器人是怎么平衡的,只要它能跑能跳能开门,它就有运动智能
看起来是不是图灵测试有点像?
对,在图灵看来,某种程度上只要某个实体表现出智能的行为,那他就是拥有智能的,不需要管思维呀、逻辑呀这些。
是不是听起来和连接主义研究的内容也有点像?他们好像都不关心中间的拟合过程,把拟合的函数当成的一个黑盒?
我目前的理解是:对,从最终的结果来看,他们都是拟合。但是他们的研究理念不一样,对内部的这个"黑盒"系统的态度是不一样的,一种是真的不关心、一种是假装不关心。 行为主义主观上拒绝探究这个内部的系统。而连接主义会主动去模拟内部结构,通过构建数亿个虚拟的"神经元连接",来模拟世界的统计规律,只是目前我们无法把这些规律翻译成人类能理解的符号。
落地到实际的学习方法,行为主义学派中一个典型的学习方法就是"试错",通过不断的试错,不断的与环境进行交互、然后从环境中接收反馈,从而得到纠正,一句话 智能是被奖励 "喂" 出来的 。 对,没错,这就是强化学习的基本思路。
抽象、学术的先到这儿,下面简单说说一些机器学习的基本概念。
机器学习、深度学习、强化学习的区别?
经常能听到一些书籍呀、资料啊,说到什么机器学习、深度学习、强化学习这些看起来有些类似的概念。对于不熟悉的人或许还是有些疑惑的。这里简单做个概念的区分。

首先机器学习 是上面三个概念中最大的类,它与 AI 的关系就像数学和科学的关系 一样【1】。 自 AI 诞生的早期,学术大家们的一个研究目标就是如何让机器进行学习 ,即机器在运行过程中,根据获得的经验来不断改进自己的能力。
目标确实很宏大,让 机器获取通用的学习能力,不断的自我进化,不断演进,现在看起来还有些遥远(之前说过这是属于强人工智能的范畴)。 现在大家讨论的机器学习主要是根据历史数据,然后采用一定的学习方法和策略(决策树、支持向量机、神经网络等),得到一个模型,然后通过这个模型来对未来数据一种模拟。
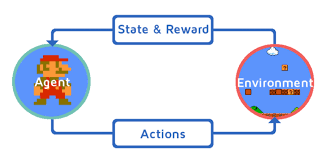
强化学习,如前面行为主义中所说的那样,是一种学习方法、学习范式,通过不断的与环境交互,不断的"试错"、不断的获得奖励,来提升模型的效果。 它是机器学习三大范式(三大学习方法中的一种,另外两种是有监督学 习和无监督学习)。
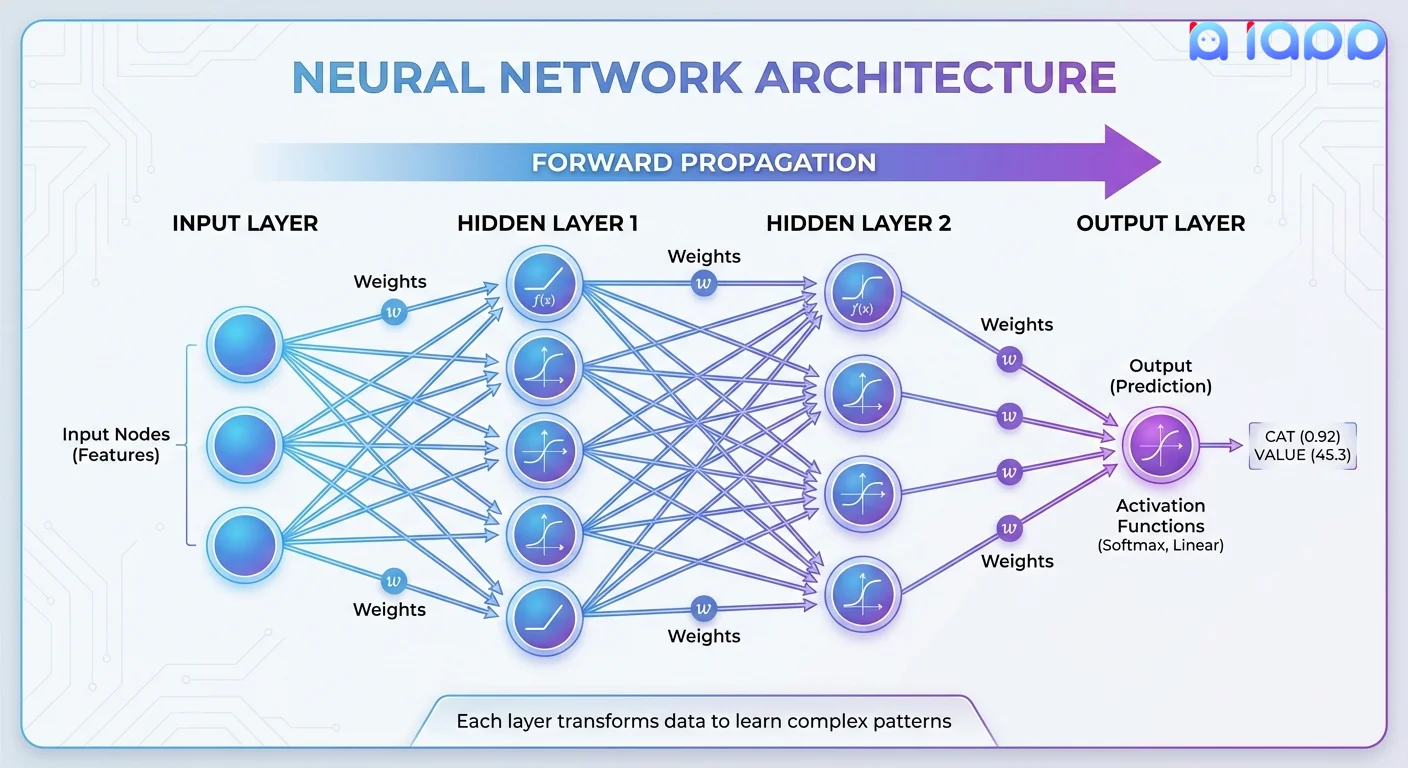
首先归个类,深度学习是一种模型 ,一种来源于神经网络的模型。深度二字主要讲的是神经网络的层次比较深(大于 3 层的神经网络)。 最早期的神经网络的层次比较少,因为受限于当时的环境,神经网络的层次一旦较深,就没有了可用的训练方法。后来以深度学习教父杰弗里.辛顿为代表的一些科学家发明了反向传播算法、逐层预训练等 ,解决了深层次的网络学习无法训练的问题,最终开启了深度学习的热潮。(比起其他的模型学习,深度学习优点就在于其优异的、自动化的特征学习能力,通过深度学习训练出来的模型对数据的特征客户化往往更本质)
既然是一种模型,所以它可以以上述三种不同的机器范式(有监督、无监督、强化学习)进行结合训练,下表是ai 回答的一些结合的参考例子。
| 训练范式 | 深度学习的典型实现 | 最著名的例子 | 核心特点 |
|---|---|---|---|
| 有监督深度学习 | 带标签数据训练的 CNN、RNN、Transformer | 手机人脸识别、ImageNet 图像分类、语音转文字 | 准确率最高,最成熟,需要大量标注数据 |
| 无监督深度学习 | 自编码器、生成对抗网络 (GAN)、聚类神经网络 | 早期的人脸生成、图像降噪、异常检测 | 不需要标注,能发现数据中的隐藏模式 |
| 深度强化学习 | DQN、PPO、Actor-Critic | AlphaGo、波士顿动力机器人、GPT 的 RLHF | 能自主决策,适应动态环境,样本效率低 |
大模型、小模型、预训练、 基模、后训练等基本概念

最后来谈谈最近比较火的语言大模型中的一些基本概念和逻辑吧。
GPT 出来之后,大模型也越来越火了。其实我们平时所说的大语言模型其实也是一种机器学习的模型 (是一种把预测下一个字这件事做到极致的超大号神经网络模型 ),只不过这是个经过了特殊训练过程(深度学习、transformer 机制 ),使这种模型具有了极度适配文本生成(现在除了文本、还有图片、语音、视频等多模态的能力)的能力,而这种能力从人类的角度来看好像是具有了 "理解、推理"的"智能行为"。
大模型的大,主要是指的参数比较大,现在主流的大模型(如GPT、Claude等)都具有了几十、上百 B 的参数规模,正式靠着这种看起来"大力"的方式,形成了这一波生成式浪潮的"奇迹"。
除了大模型,还有一些特殊的任务会用到小模型(参数数量小于 1B)。小模型的参数数量小,训练成本低、运行要求也略低(相反的很多大模型必须得在 GPU 上跑,很多小模型现在可以直接在 CPU 上运行)适用于一些垂直领域、简单的任务。
以用户的视角来看,我们大部分在市面上接触到的
大模型的产生主要是通过大量的数据(基本上是全网级的数据)训练来得到的。从训练的阶段来看,分为预训练和后训练。预训练主要是形成一个基模 ,这是最耗成本(时间成本、经济成本)的一个阶段,形成的基模"学会了"通用语言规律、可以根据概率预测下一个词。
但是基模一般面向面向的不是最终用户,还不能作为一个产品使用(甚至还不具有对话的能力,只有预测下一个词的能力)。作为用户,我们平常听到的那些 GPT、Clade等模型其实是已经是他们自家基模 二次训练(后训练、微调) 之后的成品对话模型(或者是用于其他用途,如编程、多模态等模型)。
后记
上面所总结记录的只是《智慧的疆界》中的很少一部分,算是整本书的一点皮毛,很多内容,比如说机器学习、深度学习的具体过程、涉及到的一些算法,由于知识所限,均未提及。 再次推荐,书是好书,有兴趣可以读读原书。
参考
【1】《智慧的疆界》
【2】图灵机
【3】可计算和停机问题
【4】关于 brainfunc