在日常学习工作中,会沉淀许多知识,笔记,但当笔记多起来时查阅不方便,常常会忘记记在哪里,我在想在AI时代,应该让AI学习整理我们的笔记并形成知识库,使用时只需要问答模式即可得到想要的答案。
市面上基于 RAG(检索增强生成)的方案不少,但大多数重度依赖向量数据库和 Embedding 模型,搭建成本高、维护也麻烦。于是我自己动手写了一个轻量级的替代品------AnswerAgent 。
这篇文章聊聊它的设计思路、核心功能和部署方式,感兴趣的可以参考
用户界面:
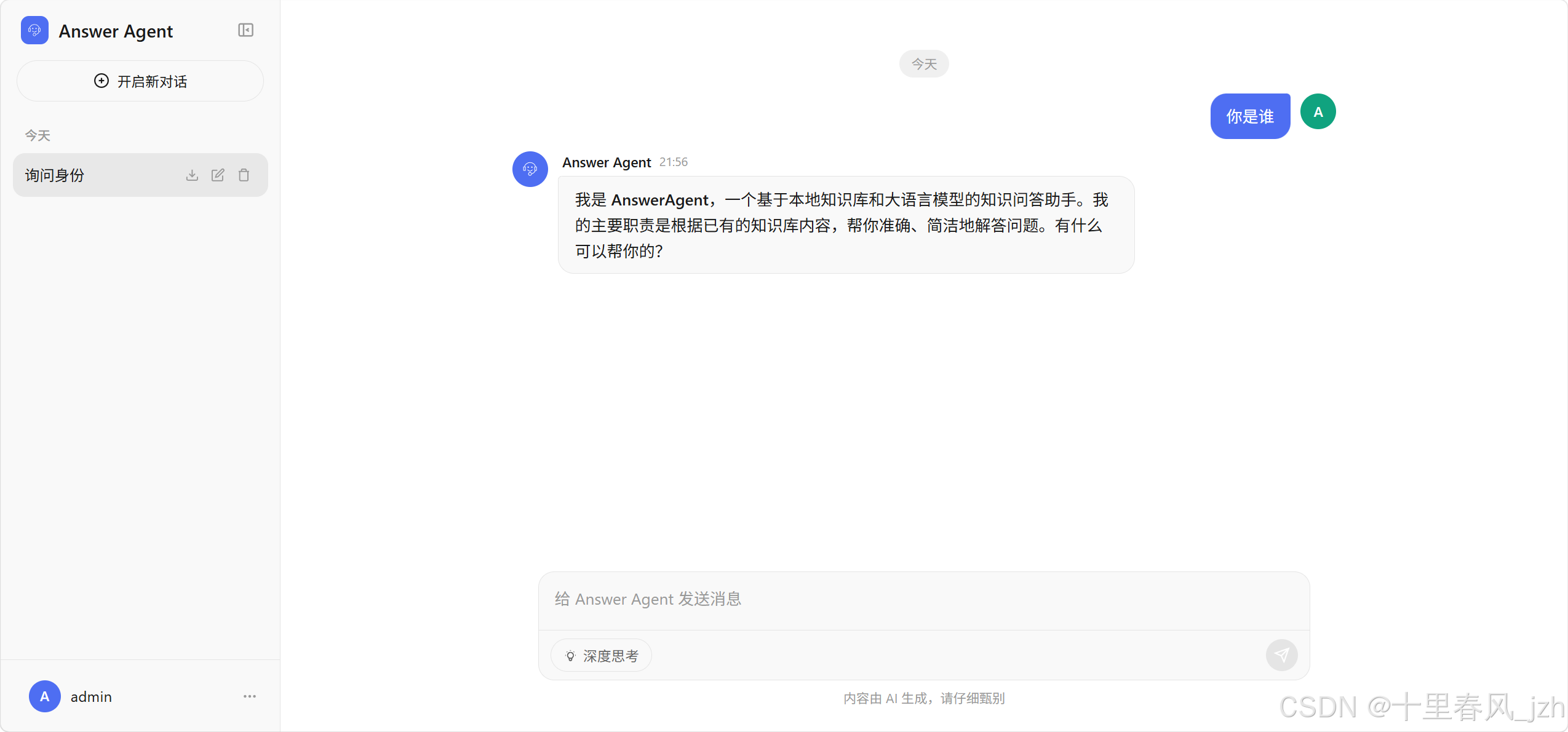
管理后台:
为什么不做 RAG?
先说说技术选型上的取舍。
经典的 RAG 流程是:文档 → 切分 → Embedding → 向量数据库 → 语义检索 → LLM 生成。这套链路本身没问题,但对我来说有几个痛点:
-
Embedding 模型需要额外维护,要么自己部署一套,要么调用商业 API,成本翻倍
-
分块策略很难调,块太大丢失精度,块太小丢失上下文
-
向量数据库多了一个中间件,小团队不值得为这点事上 ES 或 Milvus
-
知识更新需要重新 Embedding ,改了文档还得跑一遍入库流程
AnswerAgent 的思路很直接:文件就放在目录里,LLM 自己读 。
具体来说,采用了两阶段的「关键词粗筛 + LLM 精读」策略:用户提问
→ jieba 分词 + 关键词匹配,粗筛出候选文件(最多 10 个)
→ 把候选文件目录交给 LLM,让它选最相关的(最多 5 个)
→ LLM 读选中文件的内容,生成回答
这套方案的优点是零 Embedding 依赖、零向量数据库、零分块策略,知识库就是一个目录,加个 Markdown 文件就等于更新了知识。缺点也有:当知识库文件量很大的时候,关键词粗筛可能漏掉语义相关但字面不匹配的内容。实际使用下来,对于几百个文件量级的知识库,效果完全够用。
后端基于 FastAPI,数据库用的 SQLite------用户账户、对话元数据、运行时配置都存这里,对话的消息内容则存为 JSON 文件。为什么消息不也存数据库?因为 JSON 文件方便直接翻阅和备份,恢复起来也省事。
亮点功能
1. 多知识库自动路由
知识库是按目录组织的,比如你有一个 backend/knowledge/ 目录:
knowledge/
├── 产品文档/
│ ├── 索引.md
│ ├── 需求文档.md
│ └── 更新日志.md
├── 技术架构/
│ ├── 索引.md
│ ├── API设计.md
│ └── 数据库设计.md
└── 运维手册/
├── 索引.md
├── 部署流程.md
└── 故障处理.md用户问「生产环境怎么部署?」时,AnswerAgent 会先调用 LLM 判断这个问题跟哪些知识库相关(匹配到「运维手册」),然后只从匹配的知识库里检索文件。支持多知识库合并------一个问题同时命中多个知识库时,结果会合并后送给 LLM。
2. 深度思考模式(Deep Agent)
普通的问答模式是把检索到的文件塞进系统提示词,让 LLM 直接回答。这够快,但遇到复杂问题------比如「比较我们新旧两版 API 设计的差异,分析各自的优缺点」------就需要更灵活的推理能力。
深度思考模式切换为 ReAct Agent,它有三个工具可以用:
list_knowledge_bases--- 列出所有知识库search_kb_files--- 在知识库中搜索关键词read_kb_file--- 读取具体文件内容
Agent 会自己规划步骤:先列知识库 → 找到目标 → 搜索关键词定位 → 读取文件 → 综合回答。整个过程在 SSE 流中实时展示思考链和工具调用,前端可以展开查看推理过程。
Agent 自主规划、调用工具、逐步推理,前端实时展示思考链
3. 知识库自动生成
知识库的内容怎么来?手写当然可以,但更酷的方式是------从代码仓库自动生成 。
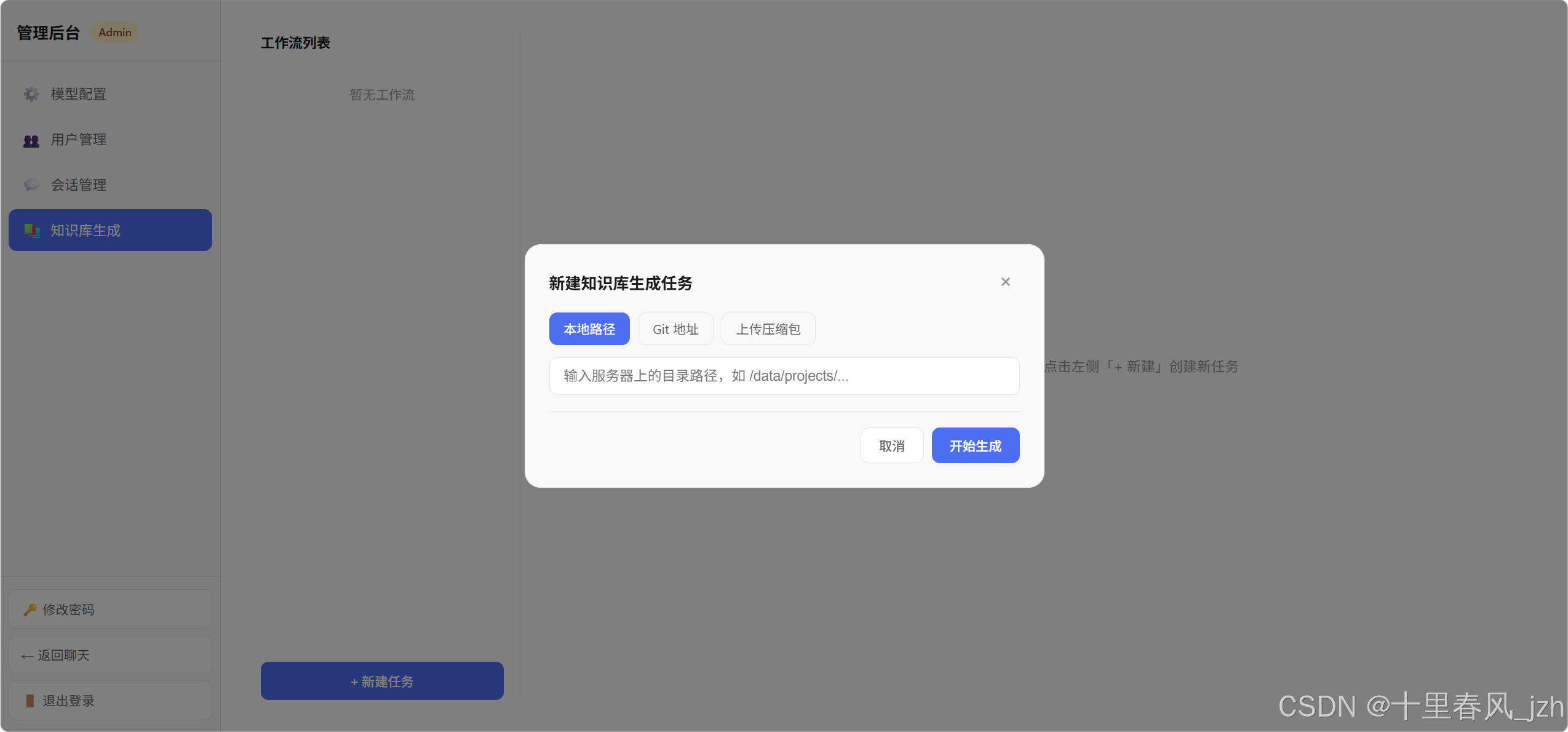
AnswerAgent 内置了一个知识库生成工作流:
- 输入:支持三种方式------本地目录路径、Git 仓库 URL、上传压缩包(zip/tar.gz)
- 预处理:如果是 Git 地址就 clone 下来,压缩包就解压
- 分析:扫描文件结构,判断仓库类型(代码仓库还是文档仓库),LLM 生成任务列表
- 执行 :DeepAgent 配合
kb-generator技能文件,逐个生成模块文档、API 参考、架构说明 - 输出 :一个完整的知识库目录,包含
索引.md和各模块文档
举个例子,把 AnswerAgent 自己的源码仓库丢进去,它就能生成一份关于 AnswerAgent 的知识库文档
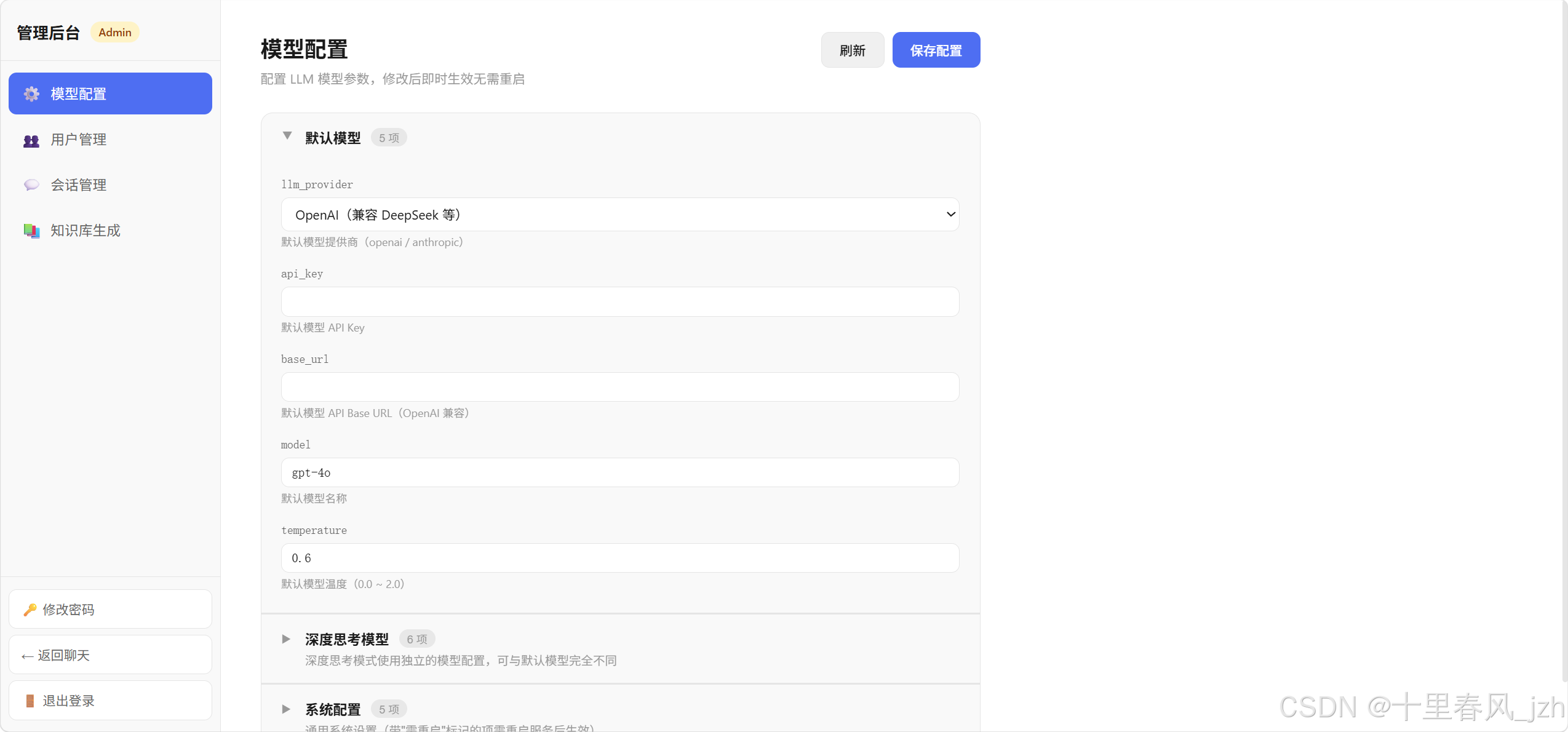
4. 管理后台
管理后台放在 /admin 路径下,有四个功能模块:
模型配置 :LLM 提供商、API Key、模型名称、温度参数等都可以在页面上修改,支持热更新------改完立即生效,不需要重启服务。配置持久化到 SQLite,重启后依然生效。
用户管理:查看注册用户、创建用户、删除用户、切换管理员权限。
会话管理:查看所有用户的对话记录,支持按用户筛选和标题搜索。
知识库生成:触发知识库生成工作流的界面,可以实时查看日志流、暂停/恢复/取消任务。
5. 其他细节
- 双主题:亮色/暗色模式随意切换,偏好会记住
- Markdown 导出:对话可以导出为 Markdown 文件,方便分享
- 外部 API:支持免登录的外部流式问答接口,可以嵌入到其他系统
- SSE 流式输出:Token 逐个展示,体验跟 ChatGPT 一样流畅
部署方式
本地开发
后端启动:
bash
cd backend
pip install -r requirements.txt
cp .env.example .env # 编辑填入 API Key
python -m app.main # 监听 0.0.0.0:8765前端启动:
bash
cd frontend
npm install
npm run dev # 监听 localhost:5173然后打开浏览器访问 http://localhost:5173,注册账号即可使用。默认管理员账号是 admin / admin123,登录后进管理后台配置 LLM。
Docker 部署
生产环境推荐用 Docker Compose 一键部署:
bash
docker compose build
docker compose up -dDocker 部署时有两个设计细节值得一提:
一是 skills 同步机制 。内置的技能文件打包在镜像的 /app/skills_builtin/ 目录下,容器启动时通过 entrypoint 脚本同步到 /app/skills/。如果用户通过 volume 挂载了自己的技能文件,同名文件不会被覆盖------既保留了自定义能力,又不会在升级时丢失定制内容。
二是 数据持久化。知识库、数据库、对话文件配置都通过 volume 挂载到宿主机目录,容器销毁后数据不丢失。
一些使用心得
知识库怎么组织?
经过一段时间的试用,我推荐这样组织知识库:
- 每个知识库一个目录,粒度不宜太细也不宜太粗。比如「产品文档」是一个知识库,「技术架构」是另一个,而不是按每个功能模块拆一个
- 每个知识库根目录放一个
索引.md,用几句话描述这个知识库的内容。LLM 路由时优先看这个文件 - 文件格式优先用 Markdown,它既是人类可读的,也是 LLM 最擅长的格式。代码文件、配置文件可以直接放进去
- 单个文件控制在 20KB 以内,单个知识库控制在 60KB 以内------系统会做截断
什么时候用「深度思考」?
日常简单问答用默认模式就够了。遇到以下场景可以开启深度思考模式:
- 对比分析:比如「对比 v2 和 v3 版本的接口差异」
- 跨知识库综合:比如「从产品需求和技术实现两个角度分析这个功能」
- 需要多步推理:比如「找出所有涉及用户权限的配置项,并说明它们的优先级关系」