注:本文为 "Linux 系统调用" 相关合辑。
英文引文,机翻未校。
中文引文,略作重排。
如有内容异常,请看原文。
Anatomy of a system call, part 1
剖析系统调用
July 9, 2014
This article was contributed by David Drysdale
System calls are the primary mechanism by which user-space programs interact with the Linux kernel. Given their importance, it's not surprising to discover that the kernel includes a wide variety of mechanisms to ensure that system calls can be implemented generically across architectures, and can be made available to user space in an efficient and consistent way.
系统调用是用户空间程序与 Linux 内核交互的主要机制。鉴于它们的重要性,内核包含各种各样的机制来确保系统调用可以在不同架构上通用实现,并能以高效且一致的方式提供给用户空间,这并不令人惊讶。
I've been working on getting FreeBSD's Capsicum security framework onto Linux and, as this involves the addition of several new system calls (including the slightly unusual execveat() system call), I found myself investigating the details of their implementation. As a result, this is the first of a pair of articles that explore the details of the kernel's implementation of system calls (or syscalls). In this article we'll focus on the mainstream case: the mechanics of a normal syscall (read()), together with the machinery that allows x86_64 user programs to invoke it. The second article will move off the mainstream case to cover more unusual syscalls, and other syscall invocation mechanisms.
我一直在 研究 将 FreeBSD 的 Capsicum 安全框架 移植到 Linux 上,由于这涉及添加几个新的系统调用(包括稍微不寻常的 execveat() 系统调用,我发现自己在调查它们的实现细节。因此,这是探讨内核系统调用(或 syscalls)实现细节的两篇文章中的第一篇。在这篇文章中,我们将关注主流情况:普通系统调用(read())的机制,以及允许 x86_64 用户程序调用它的机制。第二篇文章将偏离主流情况,涵盖更不寻常的系统调用和其他系统调用调用机制。
System calls differ from regular function calls because the code being called is in the kernel. Special instructions are needed to make the processor perform a transition to ring 0 (privileged mode). In addition, the kernel code being invoked is identified by a syscall number, rather than by a function address.
系统调用与常规函数调用的不同之处在于被调用的代码在内核中。需要特殊指令来使处理器执行到环 0(特权模式)的转换。此外,被调用的内核代码由系统调用号标识,而不是由函数地址标识。
Defining a syscall with SYSCALL_DEFINE*n*()
使用 SYSCALL_DEFINE*n*() 定义系统调用
The read() system call provides a good initial example to explore the kernel's syscall machinery. It's implemented in fs/read_write.c, as a short function that passes most of the work to vfs_read(). From an invocation standpoint the most interesting aspect of this code is way the function is defined using the SYSCALL_DEFINE3() macro. Indeed, from the code, it's not even immediately clear what the function is called.
read() 系统调用提供了一个很好的初始示例来探索内核的系统调用机制。它在 fs/read_write.c 中实现,作为一个短函数,将大部分工作传递给 vfs_read()。从调用角度来看,这段代码最有趣的方面是该函数使用 SYSCALL_DEFINE3() 宏定义的方式。事实上,从代码中甚至不能立即清楚这个函数叫什么。
c
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
/* ... */These SYSCALL_DEFINE*n*() macros are the standard way for kernel code to define a system call, where the *n* suffix indicates the argument count. The definition of these macros (in include/linux/syscalls.h) gives two distinct outputs for each system call.
这些 SYSCALL_DEFINE*n*() 宏是内核代码定义系统调用的标准方式,其中 *n* 后缀表示参数数量。这些宏的定义(在 include/linux/syscalls.h 中)为每个系统调用产生两个不同的输出。
c
SYSCALL_METADATA(_read, 3, unsigned int, fd, char __user *, buf, size_t, count)
__SYSCALL_DEFINEx(3, _read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
/* ... */The first of these, SYSCALL_METADATA(), builds a collection of metadata about the system call for tracing purposes. It's only expanded when CONFIG_FTRACE_SYSCALLS is defined for the kernel build, and its expansion gives boilerplate definitions of data that describes the syscall and its parameters. (A separate page describes these definitions in more detail.)
第一个,SYSCALL_METADATA(),构建一组关于系统调用的元数据用于追踪目的。只有当内核构建中定义了 CONFIG_FTRACE_SYSCALLS 时,它才会展开,其展开给出了描述系统调用及其参数的数据的样板定义。
The __SYSCALL_DEFINEx() part is more interesting, as it holds the system call implementation. Once the various layers of macros and [GCC type extensions are expanded, the resulting code includes some interesting features:
__SYSCALL_DEFINEx() 部分更有趣,因为它包含系统调用实现。一旦宏的各种层次和 GCC 类型扩展 被展开,生成的代码包含一些有趣的特性:
c
asmlinkage long sys_read(unsigned int fd, char __user * buf, size_t count)
__attribute__((alias(__stringify(SyS_read))));
static inline long SYSC_read(unsigned int fd, char __user * buf, size_t count);
asmlinkage long SyS_read(long int fd, long int buf, long int count);
asmlinkage long SyS_read(long int fd, long int buf, long int count)
{
long ret = SYSC_read((unsigned int) fd, (char __user *) buf, (size_t) count);
asmlinkage_protect(3, ret, fd, buf, count);
return ret;
}
static inline long SYSC_read(unsigned int fd, char __user * buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
/* ... */First, we notice that the system call implementation actually has the name SYSC_read(), but is static and so is inaccessible outside this module. Instead, a wrapper function, called SyS_read() and aliased as sys_read(), is visible externally. Looking closely at those aliases, we notice a difference in their parameter types --- sys_read() expects the explicitly declared types (e.g. char __user * for the second argument), whereas SyS_read() just expects a bunch of (long) integers. Digging into the history of this, it turns out that the long version ensures that 32-bit values are correctly sign-extended for some 64-bit kernel platforms, preventing a historical vulnerability.
首先,我们注意到系统调用实现实际上名为 SYSC_read(),但它是 static 的,因此在该模块外部不可访问。相反,一个名为 SyS_read() 的包装函数,并 别名 为 sys_read(),在外部可见。仔细查看这些别名,我们注意到它们的参数类型有所不同------sys_read() 期望显式声明的类型(例如第二个参数为 char __user *),而 SyS_read() 只期望一堆 (long) 整数。深入 历史 后,发现 long 版本确保 32 位值在某些 64 位内核平台上被正确符号扩展,防止了一个历史性的 漏洞。
The last things we notice with the SyS_read() wrapper are the asmlinkage directive and asmlinkage_protect() call. The Kernel Newbies FAQ helpfully explains that asmlinkage means the function should expect its arguments on the stack rather than in registers, and the generic definition of asmlinkage_protect() explains that it's used to prevent the compiler from assuming that it can safely reuse those areas of the stack.
我们在 SyS_read() 包装器上注意到的最后一点是 asmlinkage 指令和 asmlinkage_protect() 调用。Kernel Newbies FAQ 有帮助地解释了 asmlinkage 意味着函数应该期望其参数在栈上而不是在寄存器中,而 asmlinkage_protect() 的 通用定义 解释了它用于防止编译器假设它可以安全地重用栈的那些区域。
To accompany the definition of sys_read() (the variant with accurate types), there's also a declaration in include/linux/syscalls.h, and this allows other kernel code to call into the system call implementation directly (which happens in half a dozen places). Calling system calls directly from elsewhere in the kernel is generally discouraged and is not often seen.
为了配合 sys_read() 的定义(具有准确类型的变体),在 include/linux/syscalls.h 中还有一个 声明,这允许其他内核代码直接调用系统调用实现(这在 少数几个地方 发生)。直接从内核其他地方调用系统调用通常不被鼓励,也不常见。
Syscall table entries
系统调用表条目
Hunting for callers of sys_read() also points the way toward how user space reaches this function. For "generic" architectures that don't provide an override of their own, the include/uapi/asm-generic/unistd.h file includes an entry referencing sys_read:
寻找 sys_read() 的调用者也指明了用户空间如何到达这个函数。对于不提供自己覆盖的"通用"架构,include/uapi/asm-generic/unistd.h 文件包含一个 条目,引用 sys_read:
c
#define __NR_read 63
__SYSCALL(__NR_read, sys_read)This defines the generic syscall number __NR_read (63) for read(), and uses the __SYSCALL() macro to associate that number with sys_read(), in an architecture-specific way. For example, arm64 uses the asm-generic/unistd.h header file to fill out a table that maps syscall numbers to implementation function pointers.
这定义了 read() 的通用系统调用号 __NR_read(63),并使用 __SYSCALL() 宏以架构特定的方式将该编号与 sys_read() 关联。例如,arm64 使用 asm-generic/unistd.h 头文件来 填充一个表,将系统调用号映射到实现函数指针。
However, we're going to concentrate on the x86_64 architecture, which does not use this generic table. Instead, x86_64 defines its own mappings in arch/x86/syscalls/syscall_64.tbl, which has an entry for sys_read():
然而,我们将专注于 x86_64 架构,它不使用这个通用表。相反,x86_64 在 arch/x86/syscalls/syscall_64.tbl 中定义了自己的映射,其中有一个 条目 对应 sys_read():
c
0 common read sys_readThis indicates that read() on x86_64 has syscall number 0 (not 63), and has a common implementation for both of the ABIs for x86_64, namely sys_read(). (The different ABIs will be discussed in the second part of this series.) The syscalltbl.sh script generates arch/x86/include/generated/asm/syscalls_64.h from the syscall_64.tbl table, specifically generating an invocation of the __SYSCALL_COMMON() macro for sys_read(). This header file is used, in turn, to populate the syscall table, sys_call_table, which is the key data structure that maps syscall numbers to sys_*name*() functions.
这表示在 x86_64 上 read() 的系统调用号为 0(不是 63),并且对 x86_64 的两个 ABI 都有 common 实现,即 sys_read()。(不同的 ABI 将在本系列的第二部分讨论。)syscalltbl.sh 脚本从 syscall_64.tbl 表生成 arch/x86/include/generated/asm/syscalls_64.h,特别是为 sys_read() 生成 __SYSCALL_COMMON() 宏的调用。这个头文件反过来用于填充系统调用表 sys_call_table,这是将系统调用号映射到 sys_*name*() 函数的关键数据结构。
x86_64 syscall invocation
x86_64 系统调用调用
Now we will look at how user-space programs invoke the system call. This is inherently architecture-specific, so for the rest of this article we'll concentrate on the x86_64 architecture (other x86 architectures will be examined in the second article of the series). The invocation process also involves a few steps, so a clickable diagram, seen at left, may help with the navigation.
现在我们将看看用户空间程序如何调用系统调用。这本质上是架构特定的,因此在本文的其余部分,我们将专注于 x86_64 架构(其他 x86 架构将在本系列的第二篇文章中考察)。调用过程涉及几个步骤,因此左侧的可点击图表可能有助于导航。
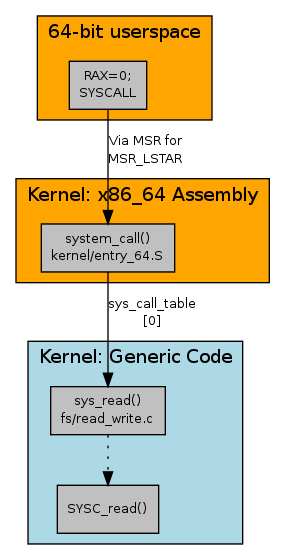
In the previous section, we discovered a table of system call function pointers; the table for x86_64 looks something like the following (using a GCC extension for array initialization that ensures any missing entries point to sys_ni_syscall()):
在前一节中,我们发现了一个系统调用函数指针表;x86_64 的表 看起来像这样(使用 GCC 数组初始化扩展,确保任何缺失的条目指向 sys_ni_syscall()):
c
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
[0 ... __NR_syscall_max] = &sys_ni_syscall,
[0] = sys_read,
[1] = sys_write,
/*... */
};For 64-bit code, this table is accessed from arch/x86/kernel/entry_64.S, from the system_call assembly entry point; it uses the RAX register to pick the relevant entry in the array and then calls it. Earlier in the function, the SAVE_ARGS macro pushes various registers onto the stack, to match the asmlinkage directive we saw earlier.
对于 64 位代码,这个表从 arch/x86/kernel/entry_64.S 中的 system_call 汇编入口点访问;它使用 RAX 寄存器来选取数组中的相关条目,然后调用它。在函数的前面,SAVE_ARGS 宏将各种寄存器压入栈中,以匹配我们之前看到的 asmlinkage 指令。
Moving outwards, the system_call entry point is itself referenced in syscall_init(), a function that is called early in the kernel's startup sequence:
向外扩展,system_call 入口点本身在 syscall_init() 中被 引用,这是一个在内核启动序列早期被 调用 的函数:
c
void syscall_init(void)
{
/*
* LSTAR and STAR live in a bit strange symbiosis.
* They both write to the same internal register. STAR allows to
* set CS/DS but only a 32bit target. LSTAR sets the 64bit rip.
*/
wrmsrl(MSR_STAR, ((u64)__USER32_CS)<<48 | ((u64)__KERNEL_CS)<<32);
wrmsrl(MSR_LSTAR, system_call);
wrmsrl(MSR_CSTAR, ignore_sysret);
/* ... */The wrmsrl instruction writes a value to a model-specific register; in this case, the address of the general system_call syscall handling function is written to register MSR_LSTAR (0xc0000082), which is the x86_64 model-specific register for handling the SYSCALL instruction.
wrmsrl 指令将一个值写入 模型特定寄存器;在这种情况下,通用 system_call 系统调用处理函数的地址被写入寄存器 MSR_LSTAR(0xc0000082),这是 x86_64 用于处理 SYSCALL 指令的模型特定寄存器。
And this gives us all we need to join the dots from user space to the kernel code. The standard ABI for how x86_64 user programs invoke a system call is to put the system call number (0 for read) into the RAX register, and the other parameters into specific registers (RDI, RSI, RDX for the first 3 parameters), then issue the SYSCALL instruction. This instruction causes the processor to transition to ring 0 and invoke the code referenced by the MSR_LSTAR model-specific register --- namely system_call. The system_call code pushes the registers onto the kernel stack, and calls the function pointer at entry RAX in the sys_call_table table --- namely sys_read(), which is a thin, asmlinkage wrapper for the real implementation in SYSC_read().
这给了我们连接从用户空间到内核代码的所有需要。x86_64 用户程序调用系统调用的标准 ABI 是将系统调用号(read 为 0)放入 RAX 寄存器,其他参数放入特定寄存器(前 3 个参数为 RDI、RSI、RDX),然后发出 SYSCALL 指令。该指令使处理器转换到环 0 并调用 MSR_LSTAR 模型特定寄存器引用的代码------即 system_call。system_call 代码将寄存器压入内核栈,并调用 sys_call_table 表中 RAX 入口处的函数指针------即 sys_read(),这是 SYSC_read() 中真实实现的薄 asmlinkage 包装器。
Now that we've seen the standard implementation of system calls on the most common platform, we're in a better position to understand what's going on with other architectures, and with less-common cases. That will be the subject of the second article in the series.
现在我们已经看到了在最常见平台上系统调用的标准实现,我们处于更好的位置来理解其他架构和不太常见的情况正在发生什么。这将是本系列第二篇文章的主题。
Anatomy of a system call, part 2
系统调用剖析,第二部分
This article was contributed by David Drysdale
本文由 David Drysdale 贡献。
The [previous article explored the kernel implementation of system calls (syscalls) in its most vanilla form: a normal syscall, on the most common architecture: x86_64. We complete our look at syscalls with variations on that basic theme, covering other x86 architectures and other syscall mechanisms. We start by exploring the various 32-bit x86 architecture variants, for which a map of the territory involved may be helpful. The map is clickable on the filenames and arrow labels to link to the code referenced:
上一篇文章 以最普通的形式探索了内核系统调用(syscalls)的实现:在最常见的架构 x86_64 上的一个普通系统调用。我们通过对基本主题的变体来完成对系统调用的考察,涵盖其他 x86 架构和其他系统调用机制。我们首先探索各种 32 位 x86 架构变体,为此,一个涉及领域的地图可能会有所帮助。地图上的文件名和箭头标签是可点击的,以链接到引用的代码:
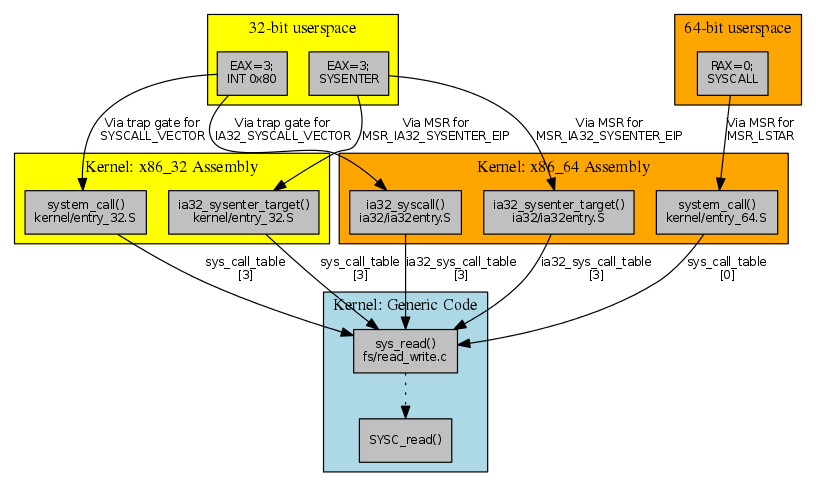
x86_32 syscall invocation via SYSENTER
通过 SYSENTER 进行 x86_32 系统调用
The normal invocation of a system call on a 32-bit x86_32 system is closely analogous to the mechanism for x86_64 systems that was described in the previous article. Here, the arch/x86/syscalls/syscall_32.tbl table has an entry for sys_read:
32 位 x86_32 系统上系统调用的正常调用与上一篇文章中描述的 x86_64 系统机制非常相似。这里,arch/x86/syscalls/syscall_32.tbl 表有一个 条目 对应 sys_read:
c
3 i386 read sys_readThis entry indicates that read() for x86_32 has syscall number 3, with entry point sys_read() and an i386 calling convention. The table post-processor will emit a __SYSCALL_I386(3, sys_read, sys_read) macro call into the generated arch/x86/include/generated/asm/syscalls_32.h file. This, in turn, is used to build the syscall table, sys_call_table, as before.
该条目表示 x86_32 的 read() 系统调用号为 3,入口点为 sys_read(),调用约定为 i386。表后处理器 将生成一个 __SYSCALL_I386(3, sys_read, sys_read) 宏调用到生成的 arch/x86/include/generated/asm/syscalls_32.h 文件中。这反过来用于 构建 系统调用表 sys_call_table,与之前一样。
Moving outward, sys_call_table is accessed from the ia32_sysenter_target entry point of arch/x86/kernel/entry_32.S. However, here the SAVE_ALL macro actually pushes a different set of registers (EBX/ECX/EDX/ESI/EDI/EBP rather than RDI/RSI/RDX/R10/R8/R9) onto the stack, reflecting the different syscall ABI convention for this platform.
向外扩展,sys_call_table 从 arch/x86/kernel/entry_32.S的 ia32_sysenter_target 入口点访问。然而,这里 SAVE_ALL 宏实际上将一组不同的寄存器(EBX/ECX/EDX/ESI/EDI/EBP 而不是 RDI/RSI/RDX/R10/R8/R9)压入栈中,反映了该平台不同的系统调用 ABI 约定。
The location of the ia32_sysenter_target entry point gets written to a model-specific register (MSR) at kernel start (in enable_sep_cpu()); in this case, the MSR in question is MSR_IA32_SYSENTER_EIP (0x176), which is used for handling the SYSENTER instruction.
ia32_sysenter_target 入口点的位置在内核启动时被 写入 一个模型特定寄存器(MSR)(在 enable_sep_cpu() 中);在这种情况下,所讨论的 MSR 是 MSR_IA32_SYSENTER_EIP(0x176),用于处理 SYSENTER 指令。
This shows the invocation path from userspace. The standard modern ABI for how x86_32 programs invoke a system call is to put the system call number (3 for read()) into the EAX register, and the other parameters into specific registers (EBX, ECX, and EDX for the first 3 parameters), then invoke the SYSENTER instruction.
这展示了从用户空间的调用路径。x86_32 程序调用系统调用的标准现代 ABI 是将系统调用号(read() 为 3)放入 EAX 寄存器,其他参数放入特定寄存器(前 3 个参数为 EBX、ECX 和 EDX),然后调用 SYSENTER 指令。
This instruction causes the processor to transition to ring 0 and invoke the code referenced by the MSR_IA32_SYSENTER_EIP model-specific register --- namely ia32_sysenter_target. That code pushes the registers onto the (kernel) stack, and calls the function pointer at entry EAX in sys_call_table --- namely sys_read(), which is a thin, asmlinkage wrapper for the real implementation in SYSC_read().
该指令使处理器转换到环 0 并调用 MSR_IA32_SYSENTER_EIP 模型特定寄存器引用的代码------即 ia32_sysenter_target。该代码将寄存器压入(内核)栈,并调用 sys_call_table 中 EAX 入口处的函数指针------即 sys_read(),这是 SYSC_read() 中真实实现的薄 asmlinkage 包装器。
x86_32 syscall invocation via INT 0x80
通过 INT 0x80 进行 x86_32 系统调用
The sys_call_table table is also accessed in arch/x86/kernel/entry_32.S from the system_call assembly entry point. Again, this entry point saves registers to the stack, then uses the EAX register to pick the relevant entry in sys_call_table and call it. This time, the location of the system_call entry point is used by trap_init():
sys_call_table 表也在 arch/x86/kernel/entry_32.S 中从[system_call 汇编入口点访问。同样,这个入口点将寄存器保存到栈中,然后使用 EAX 寄存器选取 sys_call_table 中的相关条目并调用它。这次,system_call 入口点的位置被 trap_init() 使用:
c
#ifdef CONFIG_X86_32
set_system_trap_gate(SYSCALL_VECTOR, &system_call);
set_bit(SYSCALL_VECTOR, used_vectors);
#endifThis sets up the handler for the SYSCALL_VECTOR trap to be system_call; that is, it sets it up to be the recipient of the venerable INT 0x80 software interrupt method for invoking system calls.
这为 SYSCALL_VECTOR 陷阱设置了 system_call 处理程序;也就是说,它被设置为接收古老的 INT 0x80 软件中断方法以调用系统调用。
This is the original user-space invocation path for system calls, which is now generally avoided because, on modern processors, it's slower than the instructions that are specifically designed for system call invocation (SYSCALL and SYSENTER).
这是系统调用的原始用户空间调用路径,现在通常被避免,因为在现代处理器上,它比专门为系统调用调用设计的指令(SYSCALL 和 SYSENTER)更慢。
With this older ABI, programs invoke a system call by putting the system call number into the EAX register, and the other parameters into specific registers (EBX, ECX, and EDX for the first 3 parameters), then invoking the INT 0x80 instruction. This instruction causes the processor to transition to ring 0 and invoke the trap handler for software interrupt 0x80 --- namely system_call. The system_call code pushes the registers onto the (kernel) stack, and calls the function pointer at entry EAX in the sys_call_table table --- namely sys_read(), the thin, asmlinkage wrapper for the real implementation in SYSC_read(). Much of that should seem familiar, as it is the same as for using SYSENTER.
使用这个较旧的 ABI,程序通过将系统调用号放入 EAX 寄存器,其他参数放入特定寄存器(前 3 个参数为 EBX、ECX 和 EDX),然后调用 INT 0x80 指令来调用系统调用。该指令使处理器转换到环 0 并调用软件中断 0x80 的陷阱处理程序------即 system_call。system_call 代码将寄存器压入(内核)栈,并调用 sys_call_table 表中 EAX 入口处的函数指针------即 sys_read(),SYSC_read() 中真实实现的薄 asmlinkage 包装器。其中大部分应该看起来很熟悉,因为与使用 SYSENTER 相同。
x86 syscall invocation mechanisms
x86 系统调用机制
For reference, the different user-space syscall invocation mechanisms on x86 we've seen so far are as follows:
作为参考,迄今为止我们在 x86 上看到的不同用户空间系统调用调用机制如下:
- 64-bit programs use the
SYSCALLinstruction. This instruction was originally introduced by AMD, but was subsequently implemented on Intel 64-bit processors and so is the best choice for cross-platform compatibility.
64 位程序使用SYSCALL指令。该指令最初由 AMD 引入,但随后在 Intel 64 位处理器上实现,因此是 跨平台兼容性 的最佳选择。 - Modern 32-bit programs use the
SYSENTERinstruction, which has been present since Intel introduced the IA-32 architecture.
现代 32 位程序使用SYSENTER指令,自 Intel 引入 IA-32 架构以来一直存在。 - Ancient 32-bit programs use the
INT 0x80instruction to trigger a software interrupt handler, but this is much slower thanSYSENTERon modern processors.
古老的 32 位程序使用INT 0x80指令来触发软件中断处理程序,但这在现代处理器上比SYSENTER慢得多。
x86_32 syscall invocation on x86_64
在 x86_64 上进行 x86_32 系统调用
Now for a more complicated case: what happens if we are running a 32-bit binary on our x86_64 system? From the user-space perspective, nothing is different; in fact, nothing can be different, because the user code being run is exactly the same.
现在来看一个更复杂的情况:如果我们在 x86_64 系统上运行 32 位二进制文件会发生什么?从用户空间的角度来看,没有什么不同;事实上,不可能有什么不同,因为正在运行的用户代码完全相同。
For the SYSENTER case, an x86_64 kernel registers a different function as the handler in the MSR_IA32_SYSENTER_EIP model-specific register. This function has the same name (ia32_sysenter_target) as the x86_32 code but a different definition (in arch/x86/ia32/ia32entry.S). In particular, it pushes the old-style registers but uses a different syscall table, ia32_sys_call_table. This table is built from the 32-bit table of entries; in particular, it will have entry 3 (as used on 32-bit systems), rather than 0 (which is the syscall number for read() on 64-bit systems), mapping to sys_read().
对于 SYSENTER 情况,x86_64 内核在 MSR_IA32_SYSENTER_EIP 模型特定寄存器中 注册 一个不同的函数作为处理程序。该函数与 x86_32 代码同名(ia32_sysenter_target),但有不同的 定义(在 arch/x86/ia32/ia32entry.S 中)。特别是,它压入旧式寄存器,但使用不同的系统调用表 ia32_sys_call_table。该表从 32 位条目表 构建;特别是,它将有条目 3(如 32 位系统上使用的),而不是 0(这是 64 位系统上 read() 的系统调用号),映射到 sys_read()。
For the INT 0x80 case, the trap_init() code on x86_64 instead invokes:
对于 INT 0x80 情况,x86_64 上的 trap_init() 代码 转而调用:
c
#ifdef CONFIG_IA32_EMULATION
set_system_intr_gate(IA32_SYSCALL_VECTOR, ia32_syscall);
set_bit(IA32_SYSCALL_VECTOR, used_vectors);
#endifThis maps the IA32_SYSCALL_VECTOR (which is still 0x80) to ia32_syscall. This assembly entry point (in arch/x86/ia32/ia32entry.S) uses ia32_sys_call_table rather than the 64-bit sys_call_table.
这将 IA32_SYSCALL_VECTOR( 仍然 是 0x80)映射到 ia32_syscall。该汇编入口点(在 arch/x86/ia32/ia32entry.S 中)使用 ia32_sys_call_table 而不是 64 位的 sys_call_table。
A more complex example: execve and 32-bit compatibility handling
一个更复杂的例子:execve 和 32 位兼容性处理
Now let's look at a system call that involves other complications: execve(). We'll again work outward from the kernel implementation of the system call, and explore the differences from the simpler read() call along the way. Again, a clickable map of the territory we're going to explore might help things along:
现在让我们看看一个涉及其他复杂情况的系统调用:execve()。我们将再次从系统调用的内核实现向外工作,并沿途探索与更简单的 read() 调用的差异。同样,一个我们要探索的领域的可点击地图可能会有所帮助:
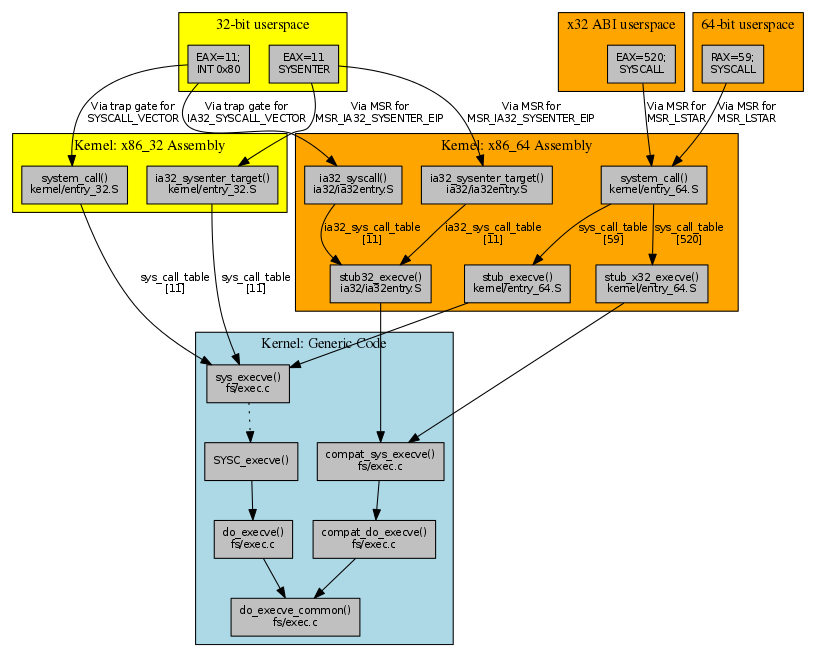
The execve() definition in fs/exec.c looks similar to that for read(), but there is an interesting additional function defined right after it (at least when CONFIG_COMPAT is defined):
fs/exec.c 中的 execve() 定义看起来与 read() 的相似,但在它之后立即定义了一个有趣的附加函数(至少当定义了 CONFIG_COMPAT 时):
c
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
#ifdef CONFIG_COMPAT
asmlinkage long compat_sys_execve(const char __user * filename,
const compat_uptr_t __user * argv,
const compat_uptr_t __user * envp)
{
return compat_do_execve(getname(filename), argv, envp);
}
#endifFollowing the processing path, these two implementations converge on do_execve_common() to perform the real work (sys_execve() → do_execve() → do_execve_common() versus compat_sys_execve() → compat_do_execve() → do_execve_common()), setting up user_arg_ptr structures along the way. These structures hold those syscall arguments that are pointers-to-pointers, together with an indication of whether they come from a 32-bit compatibility ABI; if so, the value being pointed to is a 32-bit user-space address, not a 64-bit value, and the code to copy the argument values from user space needs to allow for that.
沿着处理路径,这两个实现汇聚到 do_execve_common() 来执行实际工作(sys_execve() → do_execve() → do_execve_common() 对比 compat_sys_execve() → compat_do_execve() → do_execve_common()),沿途设置 user_arg_ptr 结构。这些结构保存那些是指向指针的系统调用参数,以及一个指示它们是否来自 32 位兼容 ABI;如果是,被指向的值是 32 位用户空间地址,而不是 64 位值,并且从用户空间复制参数值的 代码 需要考虑到这一点。
So, unlike read(), where the syscall implementation didn't need to distinguish between 32-bit and 64-bit callers because the arguments were pointers-to-values, execve() does need to distinguish, because it has arguments that are pointers-to-pointers. This turns out to be a common theme --- other compat_sys_*name*() entry points are there to cope with pointer-to-pointer arguments (or pointer-to-struct-containing-pointer arguments, for example struct iovec or struct aiocb).
因此,与 read() 不同,后者的系统调用实现不需要区分 32 位和 64 位调用者,因为参数是指向值的指针,execve() 确实需要区分,因为它有指向指针的参数。这原来是一个常见的主题------其他 compat_sys_*name*() 入口点用于处理指向指针的参数(或指向包含指针的结构的参数,例如 struct iovec 或 struct aiocb)。
x32 ABI support
x32 ABI 支持
The complication of having two variant implementations of execve() spreads outward from the code to the system call tables. For x86_64, the 64-bit table has two distinct entries for execve():
拥有 execve() 的两个变体实现的复杂性从代码蔓延到系统调用表。对于 x86_64,64 位表 有两个不同的 execve() 条目:
c
59 64 execve stub_execve
...
520 x32 execve stub_x32_execveThe additional entry in the 64-bit table at syscall number 520 is for x32 ABI programs, which run on x86_64 processors but use 32-bit pointers. As a result of the 64 and x32 ABI indicators, we will end up with stub_execve as entry 59 in sys_call_table, and stub_x32_execve as entry 520.
64 位表中系统调用号 520 处的额外条目用于 x32 ABI 程序,它们在 x86_64 处理器上运行但使用 32 位指针。由于 64 和 x32 ABI 指示符,我们最终将在 sys_call_table 中将 stub_execve 作为条目 59,将 stub_x32_execve 作为条目 520。
Although this is our first mention of the x32 ABI, it turns out that our previous read() example did quietly include x32 ABI compatibility. As no pointer-to-pointer address translation was needed, the syscall invocation path (and syscall number) could simply be shared with the 64-bit version.
虽然这是我们第一次提到 x32 ABI,但我们之前的 read() 示例实际上已经悄悄地包含了 x32 ABI 兼容性。由于不需要指向指针的地址转换,系统调用调用路径(和系统调用号)可以简单地与 64 位版本共享。
Both stub_execve and stub_x32_execve are defined in arch/x86/kernel/entry_64.S. These entry points call on sys_execve() and compat_sys_execve(), but also save additional registers (R12-R15, RBX, and RBP) to the kernel stack. Similar stub_* wrappers are also present in arch/x86/kernel/entry_64.S for other syscalls (rt_sigreturn(), clone(), fork(), and vfork()) that may potentially need to restart user-space execution at a different address and/or with a different user stack than when the syscall was invoked.
stub_execve 和 stub_x32_execve 都在 arch/x86/kernel/entry_64.S 中定义。这些入口点调用 sys_execve() 和 compat_sys_execve(),但也保存额外的寄存器(R12-R15、RBX 和 RBP)到内核栈。类似的 stub_* 包装器也存在于 arch/x86/kernel/entry_64.S 中,用于其他可能需要在与系统调用被调用时不同的地址和/或不同的用户栈重新启动用户空间执行的系统调用(rt_sigreturn()、clone()、fork() 和 vfork())。
For x86_32, the 32-bit table has an entry for execve() that's slightly different in format from that for read():
对于 x86_32,32 位表有一个 execve() 的条目),格式与 read() 的略有不同:
c
11 i386 execve sys_execve stub32_execveFirst of all, this tells us that execve() has syscall number of 11 on 32-bit systems, as compared to number 59 (or 520) on 64-bit systems. More interesting to observe is the presence of an extra field in the 32-bit table, holding a compatibility entry point stub32_execve. For a native 32-bit build of the kernel, this extra field is ignored and the sys_call_table holds sys_execve() as entry 11, as usual.
首先,这告诉我们 execve() 在 32 位系统上的系统调用号为 11,而在 64 位系统上为 59(或 520)。更有趣的是 32 位表中存在一个额外字段,保存兼容性入口点 stub32_execve。对于内核的原生 32 位构建,这个额外字段被 忽略,sys_call_table 照常将 sys_execve() 作为条目 11。
However, for a 64-bit build of the kernel, the IA-32 compatibility code inserts the stub32_execve() entry point into ia32_sys_call_table as entry 11. This entry point is defined in arch/x86/ia32/ia32entry.S as:
然而,对于内核的 64 位构建,IA-32 兼容性代码将 stub32_execve() 入口点 插入 到 ia32_sys_call_table 中作为条目 11。该入口点在 arch/x86/ia32/ia32entry.S 中定义为:
c
PTREGSCALL stub32_execve, compat_sys_execveThe PTREGSCALL macro sets up the stub32_execve entry point to call on to compat_sys_execve() (by putting its address into RAX), and saves additional registers (R12-R15, RBX, and RBP) to the kernel stack (like stub_execve() above).
PTREGSCALL 宏设置 stub32_execve 入口点以调用 compat_sys_execve()(通过将其地址放入 RAX),并保存额外的寄存器(R12-R15、RBX 和 RBP)到内核栈(像上面的 stub_execve() 一样)。
gettimeofday(): vDSO
虚拟动态链接共享对象
Some system calls just read a small amount of information from the kernel, and for these, the full machinery of a ring transition is a lot of overhead. The vDSO (Virtual Dynamically-linked Shared Object) mechanism speeds up some of these read-only syscalls by mapping the page containing the relevant information (and code to read it) into user space, read-only. In particular, the page is set up in the format of an ELF shared-library, so it can be straightforwardly linked into user programs.
有些系统调用只是从内核读取少量信息,对于这些调用,完整的环转换机制开销很大。vDSO(虚拟动态链接共享对象)机制通过将包含相关信息(和读取代码)的页映射到用户空间(只读),来加速一些这些只读系统调用。特别是,该页以 ELF 共享库格式设置,因此可以直接链接到用户程序中。
Running ldd on a normal glibc-using binary shows the vDSO as a dependency on linux-vdso.so.1 or linux-gate.so.1 (which ldd obviously can't find a file to back); it also shows up in the memory map of a running process ([vdso] in cat /proc/*PID*/maps).
在正常的使用 glibc 的二进制文件上运行 ldd 显示 vDSO 作为 linux-vdso.so.1 或 linux-gate.so.1 的依赖(ldd 显然找不到文件来支持);它也出现在运行进程的内存映射中(cat /proc/*PID*/maps 中的 [vdso])。
Historically, vsyscall was an earlier mechanism to do something similar, which is now deprecated due to security concerns. This older article by Johan Petersson describes how vsyscall's page appears as an ELF object (at a fixed position) to user space.
历史上,vsyscall 是一个更早的做类似事情的机制,现在由于安全问题已被弃用。Johan Petersson 的 这篇较早的文章 描述了 vsyscall 的页如何作为 ELF 对象(在固定位置)出现在用户空间。
There's a Linux Journal article that discusses vDSO setup in some detail (although it is now slightly out of date), so we'll just describe the basics here, as applied to the gettimeofday() syscall.
有一篇 Linux Journal 文章详细讨论了 vDSO 设置(虽然现在已经稍微过时),所以我们在这里只描述基础知识,应用于 gettimeofday() 系统调用。
First, gettimeofday() needs to access data. To allow this, the relevant vsyscall_gtod_data structure is exported into a special data section called .vvar_vsyscall_gtod_data. Linker instructions then ensure that this .vvar_vsyscall_gtod_data section is linked into the kernel in the __vvar_page section, and at kernel startup the setup_arch() function calls map_vsyscall() to set up a fixed mapping for that __vvar_page.
首先,gettimeofday() 需要访问数据。为了允许这一点,相关的 [vsyscall_gtod_data 结构 被 导出 到一个名为 .vvar_vsyscall_gtod_data 的特殊数据段中。链接器指令 然后确保这个 .vvar_vsyscall_gtod_data 段被链接到内核的 __vvar_page 段中,在内核启动时,setup_arch() 函数 调用 map_vsyscall() 来 设置固定映射 用于该 __vvar_page。
The code that provides the core vDSO implementation of gettimeofday() is in __vdso_gettimeofday(). It's marked as notrace to prevent the compiler from ever adding function profiling, and also gets a weak alias as gettimeofday(). To ensure that the resulting page looks like an ELF shared object, the vdso.lds.S file pulls in vdso-layout.lds.S and exports both gettimeofday() and __vdso_gettimeofday() into the page.
提供 gettimeofday() 核心 vDSO 实现的代码在 __vdso_gettimeofday() 中。它被标记为 notrace 以防止编译器添加函数分析,并且还获得一个弱别名 gettimeofday()。为了确保生成的页看起来像 ELF 共享对象,vdso.lds.S 文件拉入 vdso-layout.lds.S 并将 gettimeofday() 和 __vdso_gettimeofday() 导出到该页中。
To make the vDSO page accessible to a new user-space program, the code in setup_additional_pages() sets the vDSO page location to a random address chosen by vdso_addr() at process start time. Using a random address mitigates the security problems found with the earlier vsyscall implementation, but does mean that the user program needs a way to find the location of the vDSO page. The location is exposed to user space as an ELF auxiliary value: the binary loader for ELF format programs (load_elf_binary()) uses the ARCH_DLINFO macro to set the AT_SYSINFO_EHDR auxiliary value. The user-space program can then find the page using the getauxval() function to retrieve the relevant auxiliary value (although in practice the libc library usually takes care of this under the covers).
为让新的用户态程序能够访问虚拟动态共享对象(vDSO)页,进程启动时,setup_additional_pages() 函数会将 vDSO 页的地址设置为 vdso_addr() 函数生成的随机地址。采用随机地址能够规避旧式虚拟系统调用(vsyscall)实现中存在的安全隐患,但这也意味着用户程序需要额外方式来获取 vDSO 页的位置。该地址会通过 ELF 辅助变量 暴露给用户态:ELF 格式程序的二进制加载器 load_elf_binary() 借助 ARCH_DLINFO 宏设置 AT_SYSINFO_EHDR 辅助变量。用户态程序可调用 getauxval() 函数读取该辅助变量,进而定位 vDSO 页(实际应用中,这一过程通常由标准库 libc 在底层自动完成)。
For completeness, we should also mention that the vDSO mechanism is used for another important syscall-related feature for 32-bit programs. At boot time, the kernel determines which of the possible x86_32 syscall invocation mechanisms is best, and puts the appropriate implementation wrapper (SYSENTER, INT 0x80, or even SYSCALL for an AMD 64-bit processor) into the __kernel_vsyscall function. User-space programs can then invoke this wrapper and be sure of getting the fastest way into the kernel for their syscalls; see Petersson's article for more details.
为完整起见,我们还应该提到 vDSO 机制用于 32 位程序的另一个重要系统调用相关特性。在启动时,内核确定哪个可能的 x86_32 系统调用调用机制是最好的,并将适当的实现包装器(SYSENTER、INT 0x80,甚至对于 AMD 64 位处理器的 SYSCALL)放入 __kernel_vsyscall 函数中。用户空间程序然后可以调用这个包装器,并确保获得进入内核的最快方式来进行它们的系统调用;更多细节请参见 Petersson 的文章。
ptrace(): syscall tracing
ptrace():系统调用追踪
The ptrace() system call is implemented in the normal manner, but it's particularly relevant here because it can cause system calls of the traced kernel task to behave differently. Specifically, the PTRACE_SYSCALL request aims to "arrange for the tracee to be stopped at the next entry to or exit from a system call".
ptrace() 系统调用以正常方式实现,但它在这里特别相关,因为它可以使被追踪的内核任务的系统调用行为不同。具体来说,PTRACE_SYSCALL 请求旨在"安排被追踪者在下一次进入或退出系统调用时停止"。
Requesting PTRACE_SYSCALL causes the TIF_SYSCALL_TRACE thread information flag to be set in thread-specific data (struct thread_info.flags). The effect of this is architecture-specific; we'll describe the x86_64 implementation.
请求 PTRACE_SYSCALL 导致 TIF_SYSCALL_TRACE 线程信息标志在线程特定数据(struct thread_info.flags)中被 设置。其效果是 架构特定的;我们将描述 x86_64 实现。
Looking more closely at the assembly for syscall entry (in all of x86_32, x86_64, and ia32) we see a detail that we skipped over previously: if the thread flags have any of the _TIF_WORK_SYSCALL_ENTRY flags (which include TIF_SYSCALL_TRACE) set, the syscall implementation code follows a different path to invoke syscall_trace_enter() instead (x86_32, x86_64, ia32). The syscall_trace_enter() function then performs a variety of different functions that are associated with the various per-thread flag values that were checked for with _TIF_WORK_SYSCALL_ENTRY:
更仔细地查看系统调用入口的汇编(在 x86_32、x86_64 和 ia32 中),我们看到一个之前跳过的细节:如果线程标志设置了任何 _TIF_WORK_SYSCALL_ENTRY 标志(包括 TIF_SYSCALL_TRACE),系统调用实现代码会遵循不同的路径来调用 syscall_trace_enter()(x86_32、x86_64、ia32)。然后 syscall_trace_enter() 函数执行与各种用 _TIF_WORK_SYSCALL_ENTRY 检查的每线程标志值相关的各种不同功能:
TIF_SINGLESTEP: single stepping of instructions for ptraceTIF_SINGLESTEP:ptrace 的指令单步执行TIF_SECCOMP: perform secure computing checks on syscall entry
TIF_SECCOMP:在系统调用入口执行安全计算检查TIF_SYSCALL_EMU: perform syscall emulation
TIF_SYSCALL_EMU:执行系统调用模拟TIF_SYSCALL_TRACE: syscall tracing for ptrace
TIF_SYSCALL_TRACE:ptrace 的系统调用追踪TIF_SYSCALL_TRACEPOINT: syscall tracing for [ftrace
TIF_SYSCALL_TRACEPOINT:ftrace 的系统调用追踪TIF_SYSCALL_AUDIT: generation of syscall audit records
TIF_SYSCALL_AUDIT:生成系统调用审计记录
In other words, syscall_trace_enter is the control point for a whole collection of different per-syscall interception functionality --- including TIF_SYSCALL_TRACE syscall tracing. It ends up calling ptrace_stop() with why=CLD_TRAPPED, which notifies the tracing program (via SIGCHLD) that the tracee has been stopped on entry to a syscall.
换句话说,syscall_trace_enter 是整个不同每系统调用拦截功能集合的控制点------包括 TIF_SYSCALL_TRACE 系统调用追踪。它最终调用 ptrace_stop(),其中 why=CLD_TRAPPED,通知追踪程序(通过 SIGCHLD)被追踪者已在进入系统调用时停止。
Epilogue
结语
System calls have been the standard method for user-space programs to interact with Unix kernels for decades and, consequently, the Linux kernel includes a set of facilities to make it easy to define them and to efficiently use them. Despite the invocation variations across architectures and occasional special cases, system calls also remain a remarkably homogeneous mechanism --- this stability and homogeneity allows all sorts of useful tools, from strace to [seccomp-bpf, to work in a generic way.
系统调用几十年来一直是用户空间程序与 Unix 内核交互的标准方法,因此 Linux 内核包含一组设施来使定义它们和高效使用它们变得容易。尽管跨架构的调用变化和偶尔的特殊情况,系统调用仍然保持着一个显著同质的机制------这种稳定性和同质性允许各种有用的工具,从 strace 到 seccomp-bpf,以通用方式工作。
Posted Mar 5, 2015 17:04 UTC (Thu) by drysdale (guest, #95971)
Anatomy of a system call, additional content
系统调用剖析,附加内容
Posted July 9, 2014 by jake
This page holds additional content associated with the "Anatomy of a system call" articles at LWN, but is sufficiently low-level/detailed that it can be placed outside of the narrative flow of those articles.
本页包含与 LWN 上"系统调用剖析"文章相关的附加内容,但其层次足够低/细节足够丰富,可以放在这些文章的叙事流程之外。
Step-by-step expansion of SYSCALL_DEFINE*n*()
SYSCALL_DEFINE*n*() 的逐步展开
As described in part 1, the SYSCALL_DEFINE*n*() macros initially give two distinct chunks of code:
如 第一部分 所述,SYSCALL_DEFINE*n*() 宏最初产生两个不同的代码块:
c
SYSCALL_METADATA(_read, 3, unsigned int, fd, char __user *, buf, size_t, count)
__SYSCALL_DEFINEx(3, _read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
/* ... */The first part provides metadata about the syscall for tracing purposes, and the second gives the syscall implementation. Let's examine the details of each in turn.
第一部分提供用于追踪目的的系统调用元数据,第二部分给出系统调用实现。让我们依次检查每个部分的细节。
Syscall Metadata
系统调用元数据
The first thing to notice about the SYSCALL_METADATA() part is that it's only used for a kernel build with CONFIG_FTRACE_SYSCALLS defined. The definition of this configuration option describes it as enabling a "Basic tracer to catch the syscall entry and exit events", which makes sense.
关于 SYSCALL_METADATA() 部分,首先要注意的是它仅用于定义了 CONFIG_FTRACE_SYSCALLS 的内核构建。该配置选项的 定义 将其描述为启用"用于捕获系统调用进入和退出事件的基本追踪器",这是有道理的。
Expanding the SYSCALL_METADATA() macro gives a bunch of boilerplate code:
展开 SYSCALL_METADATA() 宏会产生一堆样板代码:
c
static const char *types__read[] = {
__MAP(3,__SC_STR_TDECL, unsigned int, fd, char __user *, buf, size_t, count)
};
static const char *args__read[] = {
__MAP(3,__SC_STR_ADECL, unsigned int, fd, char __user *, buf, size_t, count)
};
static struct syscall_metadata __syscall_meta__read;
static struct ftrace_event_call __used event_enter__read = {
.name = "sys_enter""_read",
.class = &event_class_syscall_enter,
.event.funcs = &enter_syscall_print_funcs,
.data = (void *)&__syscall_meta__read,
.flags = TRACE_EVENT_FL_CAP_ANY,
};
static struct ftrace_event_call
__used __attribute__((section("_ftrace_events"))) *__event_enter__read = &event_enter__read;
static struct syscall_metadata __syscall_meta__read;
static struct ftrace_event_call __used event_exit__read = {
.name = "sys_exit""_read",
.class = &event_class_syscall_exit,
.event.funcs = &exit_syscall_print_funcs,
.data = (void *)&__syscall_meta__read,
.flags = TRACE_EVENT_FL_CAP_ANY,
};
static struct ftrace_event_call
__used __attribute__((section("_ftrace_events"))) *__event_exit__read = &event_exit__read;
static struct syscall_metadata __used __syscall_meta__read = {
.name = "sys""_read",
.syscall_nr = -1,
.nb_args = 3,
.types = 3 ? types__read : NULL,
.args = 3 ? args__read : NULL,
.enter_event = &event_enter__read,
.exit_event = &event_exit__read,
.enter_fields = LIST_HEAD_INIT(__syscall_meta__read.enter_fields),
};
static struct syscall_metadata
__used __attribute__((section("__syscalls_metadata"))) *__p_syscall_meta__read = &__syscall_meta__read;There's one more macro of interest to expand here, which is the __MAP(n, m, ...) construct. This applies the provided m argument to n pairs of arguments in turn; here it's used with the __SC_STR_ADECL() and __SC_STR_TDECL() arguments to make strings from the argument name and type name. This changes the types__read and args__read variable definitions to:
这里还有一个有趣的宏需要展开,即 __MAP(n, m, ...) 构造。它将 提供的 m 参数依次应用于 n 对参数;这里它与 __SC_STR_ADECL() 和 __SC_STR_TDECL() 参数一起使用,从参数名和类型名生成字符串。这将 types__read 和 args__read 变量定义改变为:
c
static const char *types__read[] = {
"unsigned int", "char __user *", "size_t"
};
static const char *args__read[] = {
"fd", "buf", "count"
};We're not going to explore this code further, but it's easy to see that this provides a lot of metadata that would help when tracing syscall invocations.
我们不会进一步探索这段代码,但很容易看出这提供了大量元数据,在追踪系统调用调用时会很有帮助。
Syscall Definition
系统调用定义
Now let's expand the __SYSCALL_DEFINEx() part, using its definition.
现在让我们使用其 定义 来展开 __SYSCALL_DEFINEx() 部分。
c
asmlinkage long sys_read(__MAP(3,__SC_DECL, unsigned int, fd, char __user *, buf, size_t, count))
__attribute__((alias(__stringify(SyS_read))));
static inline long SYSC_read(__MAP(3,__SC_DECL, unsigned int, fd, char __user *, buf, size_t, count));
asmlinkage long SyS_read(__MAP(3,__SC_LONG, unsigned int, fd, char __user *, buf, size_t, count));
asmlinkage long SyS_read(__MAP(3,__SC_LONG, unsigned int, fd, char __user *, buf, size_t, count))
{
long ret = SYSC_read(__MAP(3,__SC_CAST, unsigned int, fd, char __user *, buf, size_t, count));
__MAP(3,__SC_TEST, unsigned int, fd, char __user *, buf, size_t, count);
asmlinkage_protect(3, ret,__MAP(3,__SC_ARGS, unsigned int, fd, char __user *, buf, size_t, count));
return ret;
}
static inline long SYSC_read(__MAP(3,__SC_DECL, unsigned int, fd, char __user *, buf, size_t, count))
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
/* ... */We've not yet expanded the __MAP() macros, but we can already see the code structure:
我们尚未展开 __MAP() 宏,但我们已经可以看到代码结构:
- The implementation of the syscall follows this macro expansion, so its name is
SYSC_read(), but it'sstaticand so inaccessible outside of this module.
系统调用的实现遵循这个宏展开,因此它的名称是SYSC_read(),但它是static的,因此在该模块外部不可访问。 - The code also defines a
SyS_read()function to wrapSYSC_read()and do a couple of other things. The wrapper is efficient because theSYSC_read()function being wrapped is also defined to beinline.
代码还定义了一个SyS_read()函数来包装SYSC_read()并做一些其他事情。该包装器是高效的,因为被包装的SYSC_read()函数也被定义为inline。 - The name
sys_read()is defined as an alias to theSyS_read()wrapper function.
名称sys_read()被定义为SyS_read()包装器函数的 别名。
Expanding the various __MAP instances gives:
展开各种 __MAP 实例得到:
c
asmlinkage long sys_read(unsigned int fd, char __user * buf, size_t count)
__attribute__((alias(__stringify(SyS_read))));
static inline long SYSC_read(unsigned int fd, char __user * buf, size_t count);
asmlinkage long SyS_read(__SC_LONG(unsigned int,fd), __SC_LONG(char __user *,buf), __SC_LONG(size_t,count));
asmlinkage long SyS_read(__SC_LONG(unsigned int,fd), __SC_LONG(char __user *,buf), __SC_LONG(size_t,count))
{
long ret = SYSC_read((unsigned int) fd, (char __user *) buf, (size_t) count);
(void)BUILD_BUG_ON_ZERO(!__TYPE_IS_LL(unsigned int) && sizeof(unsigned int) > sizeof(long)),
(void)BUILD_BUG_ON_ZERO(!__TYPE_IS_LL(char __user *) && sizeof(char __user *) > sizeof(long)),
(void)BUILD_BUG_ON_ZERO(!__TYPE_IS_LL(size_t) && sizeof(size_t) > sizeof(long));
asmlinkage_protect(3, ret,fd, buf, count);
return ret;
}
static inline long SYSC_read(unsigned int fd, char __user * buf, size_t count)I've left a couple of unexpanded macros here. Firstly, something like __SC_LONG(unsigned int, fd) expands to:
我这里留下了几个未展开的宏。首先,类似 __SC_LONG(unsigned int, fd) 的宏 展开 为:
c
__typeof(__builtin_choose_expr((__same_type((unsigned int)0, 0LL) ||
__same_type((unsigned int)0, 0ULL)), 0LL, 0L)) fdThis uses various gcc extensions to:
这使用各种 gcc 扩展来:
-
Determine if the provided argument type (here
unsigned int) is actually the same type as either of the0LLor0ULLliterals, i.e. whether it is along long intorunsigned long long int. This is the__TYPE_IS_LL()macro.确定 提供的参数类型(这里是
unsigned int)是否实际上与0LL或0ULL字面量中的任何一个类型相同,即它是否是long long int或unsigned long long int。这是__TYPE_IS_LL()宏。 -
If it is, use the type of
0LL, i.e.long long int.如果是,使用
0LL的 类型,即long long int。 -
If it isn't, use the type of
0L, i.e.long int.如果不是,使用
0L的类型,即long int。
The net of this is to make arguments signed integers, preserving the length of long long arguments.
其净效果是将参数变为有符号整数,同时保留 long long 参数的长度。
The other unexpanded macro is a combination of BUILD_BUG_ON_ZERO() with __TYPE_IS_LL(), which generates a compile-time error if any argument is not a long long-equivalent type, but is still larger than a long. Putting these together we have:
另一个未展开的宏是 BUILD_BUG_ON_ZERO() 与 __TYPE_IS_LL() 的组合,如果任何参数不是 long long 等效类型,但仍然大于 long,则会生成编译时错误。将这些放在一起,我们有:
c
asmlinkage long sys_read(unsigned int fd, char __user * buf, size_t count)
__attribute__((alias(__stringify(SyS_read))));
static inline long SYSC_read(unsigned int fd, char __user * buf, size_t count);
asmlinkage long SyS_read(long int fd, long int buf, long int count);
asmlinkage long SyS_read(long int fd, long int buf, long int count)
{
long ret = SYSC_read((unsigned int) fd, (char __user *) buf, (size_t) count);
asmlinkage_protect(3, ret, fd, buf, count);
return ret;
}
static inline long SYSC_read(unsigned int fd, char __user * buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
/* ... */Expanding asmlinkage
展开 asmlinkage
The actual implementation of asmlinkage is architecture-specific. For example, on x86_64 these markers do nothing, but on x86_32 asmlinkage expands to extern "C" __attribute__((regparm(0))) and our asmlinkage_protect(3, ret, fd, buf, count); expands to:
asmlinkage 的实际实现是架构特定的。例如,在 x86_64 上这些标记 什么都不做,但在 x86_32 上 asmlinkage 展开 为 extern "C" __attribute__((regparm(0))),而我们的 asmlinkage_protect(3, ret, fd, buf, count); 展开为:
c
__asm__ __volatile__ ("" : "=r" (ret) : "0" (ret), "m" (fd), "m" (buf), "m" (count));The gcc docs for the regparm (number) attribute say "On the Intel 386, the regparm attribute causes the compiler to pass arguments number one to number if they are of integral type in registers EAX, EDX, and ECX instead of on the stack." So having regparm(0) makes the compiler expect arguments on the stack as desired.
regparm (number) 属性的 gcc 文档 说:"在 Intel 386 上,regparm 属性使编译器将参数编号一到编号(如果它们是整数类型)通过寄存器 EAX、EDX 和 ECX 传递,而不是在栈上。" 因此 regparm(0) 使编译器按期望在栈上接收参数。
The extended assembly for asmlinkage_protect is structured as (*template* : *output operands* : *input operands*). The template is empty, so no actual assembly is inserted, but the presence of the operands prevents the C compiler from doing any unwanted optimizations. In particular, the output operand ret has a constraint that it should be in a register ("=r"), and the other input registers (fd, buf, count) are memory operands ("m").
asmlinkage_protect 的 扩展汇编 结构为 (*模板* : *输出操作数* : *输入操作数*)。模板是空的,因此没有插入实际的汇编,但操作数的存在阻止了 C 编译器进行任何不需要的优化。特别是,输出操作数 ret 有一个 约束,即它应该在寄存器中("=r"),而其他输入寄存器(fd、buf、count)是内存操作数("m")。
系统调用约定、指令演进、运行机制
1. 系统调用指令
The preferred way of invoking a system call is determined by the kernel at boot time. Modern devices adopt sysenter for system calls, while older hardware uses int 0x80. This design also supports resuming system calls that carry six parameters.
系统调用的执行方式由内核在启动阶段判定。现代设备采用 sysenter 指令实现系统调用,老旧硬件则使用 int 0x80。该机制同时支持对携带 6 个参数的系统调用进行重启恢复。
1.1 32 位 x86 Linux 系统调用约定
The preferred way of invoking a system call is determined by the kernel at boot time. Modern devices adopt sysenter for system calls, while older hardware uses int 0x80. This jump logic is a special implementation to handle the restart of system calls with six parameters.
系统调用的执行方式由内核在启动阶段判定。现代设备采用 sysenter 指令实现系统调用,老旧硬件则使用 int 0x80。该跳转逻辑专门用于处理携带 6 个参数的系统调用重启恢复。
For 32-bit x86 Linux, system call parameters are passed via registers, supporting up to 6 parameters:
32 位 x86 架构 Linux 采用寄存器传参,最多支持 6 个参数,对应寄存器如下:
%ebx-- 1st argument
%ebx--- 第 1 个参数%ecx-- 2nd argument
%ecx--- 第 2 个参数%edx-- 3rd argument
%edx--- 第 3 个参数%esi-- 4th argument
%esi--- 第 4 个参数%edi-- 5th argument
%edi--- 第 5 个参数%ebp-- 6th argument
%ebp--- 第 6 个参数
1.2 x86-64(AMD64)Linux 系统调用约定
On x86-64 Linux, the instruction for system calls is syscall / sysret. It uses a different register calling convention from 32-bit x86.
x86-64(AMD64)架构 Linux 使用 syscall / sysret 指令完成系统调用,传参规则与 32 位 x86 完全不同。
- System call number:
%rax
系统调用号:存放于%rax - Parameters (up to 6 arguments) are passed in order by registers:
前 6 个参数依次通过以下寄存器传递:%rdi-- 1st argument
%rdi--- 第 1 个参数%rsi-- 2nd argument
%rsi--- 第 2 个参数%rdx-- 3rd argument
%rdx--- 第 3 个参数%r10-- 4th argument
%r10--- 第 4 个参数%r8-- 5th argument
%r8--- 第 5 个参数%r9-- 6th argument
%r9--- 第 6 个参数
- Return value is stored in
%rax.
系统调用返回值存放于%rax - If more than 6 parameters are required, the remaining arguments are placed on the user stack.
当参数数量超过 6 个时,多出的参数压入用户栈传递。
2. AMD 与 Intel 快速系统调用指令演进
-
AMD
syscall/sysretfirst appeared on the original K6 CPU, released after Intel Pentium Pro. The origin of these fast system call instructions cannot be fully confirmed. Restrictions and bugs delayed their practical deployment for a long time.AMD 的
syscall/sysret指令最早搭载于初代 K6 处理器,该产品发布晚于 Intel Pentium Pro。这套快速系统调用指令的原始设计归属暂无定论。受缺陷与功能限制,两类指令问世许久后才投入实际使用。 -
Opcodes and execution semantics differ between AMD and Intel fast call instructions. Later AMD adopted Intel
sysenter/sysexit; Intel added support for AMDsyscall/sysret, which only works under 64-bit mode.AMD 与 Intel 的快速调用指令,操作码和执行逻辑均不相同。后续 AMD 兼容了 Intel
sysenter/sysexit指令;Intel 也新增对 AMDsyscall/sysret的支持,且该指令仅在 64 位模式下可用。
3. Linux 下 int 0x80 运行机制
-
In Linux,
int 0x80acts as the standard system call vector. It is processed via a trap gate, which will not mask other interrupts or modify IF flags, differing from traditional hardware interrupts.在 Linux 系统中,
int 0x80是标准系统调用入口。该中断由陷阱门处理,不会屏蔽其他中断、也不会修改 IF 标志位,运行特性区别于传统硬件中断。 -
On Linux 2.6 kernel, the
0x80interrupt jumps to the dedicated system call fixed page. This interrupt is equivalent to a far jump, and the actual system call logic inside the page follows the kernel configured rules.Linux 2.6 内核中,
0x80中断会跳转至专属的系统调用固定内存页。该中断本质等价于一次远跳转,内存页内部会按照内核配置执行对应的系统调用逻辑。
4. 静态链接程序的系统调用规则
-
Static libraries in Linux do not directly use
sysenterfor system calls. Linux provides two official system call methods: executingint 0x80, or calling__kernel_vsyscallin the shared page.__kernel_vsyscallwill invokesysenterwhen conditions permit.Linux 静态库不允许直接使用
sysenter发起系统调用。系统仅提供两种合规方案:执行int 0x80,或调用共享内存页中的__kernel_vsyscall;__kernel_vsyscall会在条件满足时调用sysenter。 -
Static linked programs using
int 0x80have lower execution efficiency compared to fast call paths. Most static libraries do not add detection logic for fast system call support, so they cannot actively call__kernel_vsyscall.采用
int 0x80的静态链接程序,执行效率低于快速调用链路。多数静态库未增加快速系统调用检测逻辑,因此无法主动调用__kernel_vsyscall。 -
glibc implements the
opensystem call based onint 0x80. This mode is retained mainly for backward compatibility, and its performance is close tosysenteron modern processors.glibc 库中
open系统调用基于int 0x80实现。该方案主要为兼容旧版本系统,在现代处理器上,其运行性能与sysenter差距较小。
reference
- Anatomy of a system call, part 1 - July 9, 2014, by David Drysdale
https://lwn.net/Articles/604287/ - Anatomy of a system call, part 2 - July 16, 2014, by David Drysdale
https://lwn.net/Articles/604515/ - Anatomy of a system call, additional content - Posted July 9, 2014 by jake
https://lwn.net/Articles/604406/ - ......