一.可变参数模板
1.原理

注:引用须遵循引用折叠。用"..."指出一个模板参数或函数参数(Args)来表示一个包,这样在实例化的时候,就可以随意改变形参个数,即有0-N个参数。
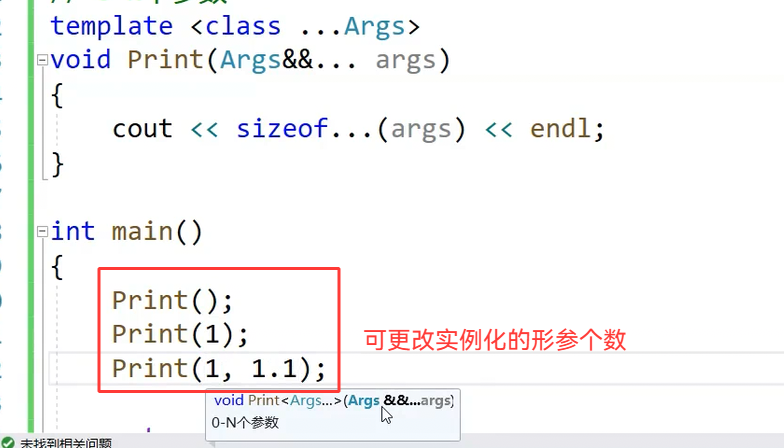
可变参数模板就相当于模板的模板,有了它,就可以让编译器自动实现,生成相应参数个数的函数模板,并由这些模板结合指定数据类型,实例化出相应的函数:
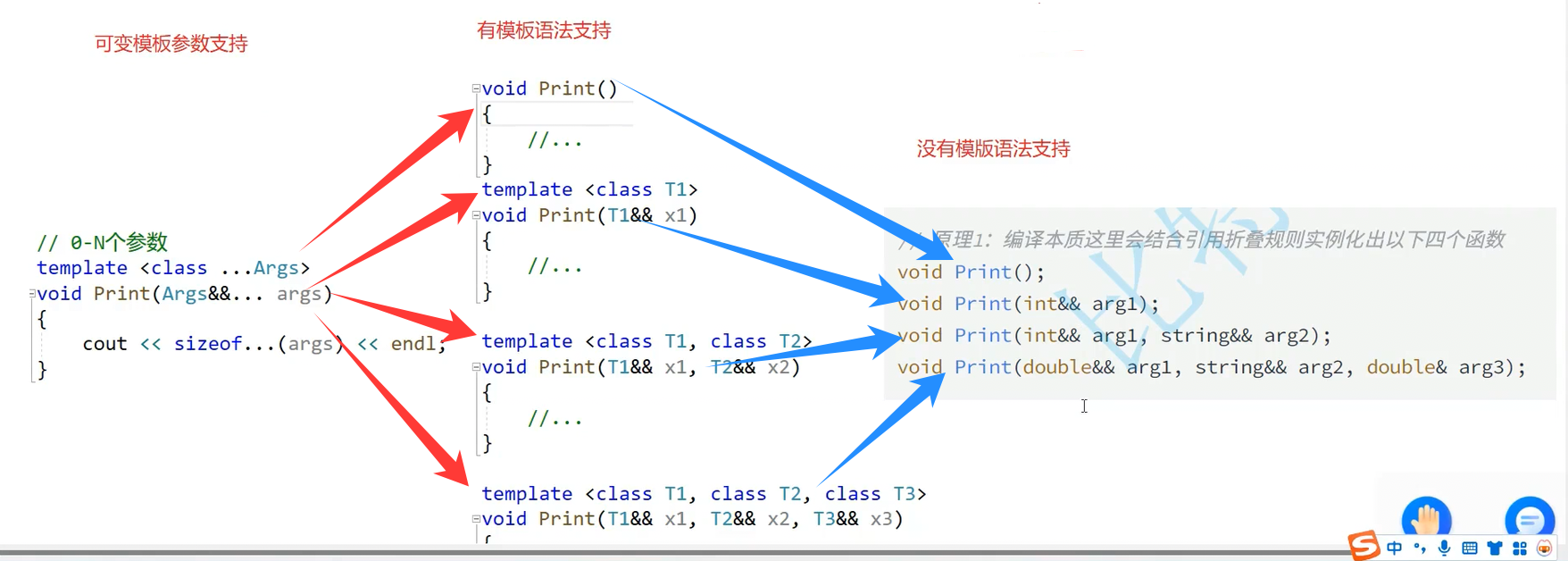
2.包扩展
注:sizeof...是个操作符,可用于求可变参数模板实例化以后,参数包里参数的个数:
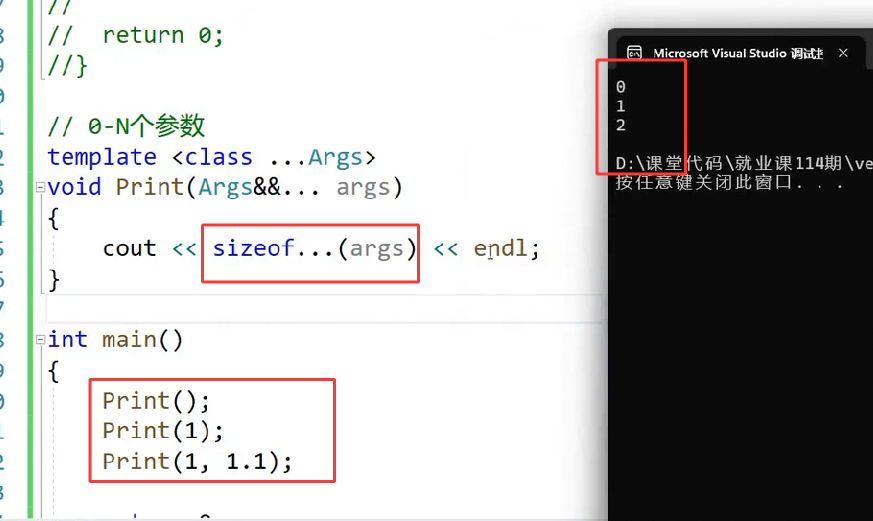
①.问题引入:
如果想要把实例化以后,参数包里的数据(实参)取出来,很多人想到的是这样的方法:
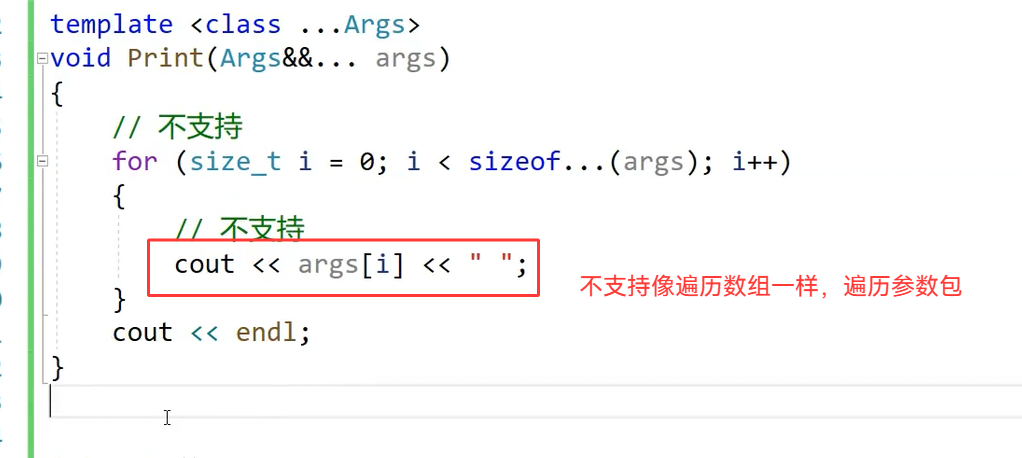
但这样是不支持的。
此时若要解析出参数包的内容,需要进行包扩展:
②.包扩展
玩了一波递归,让参数包第一个参数传给x,其余参数传给第二个参数包args,然后逐个逐个取参数包首参数:
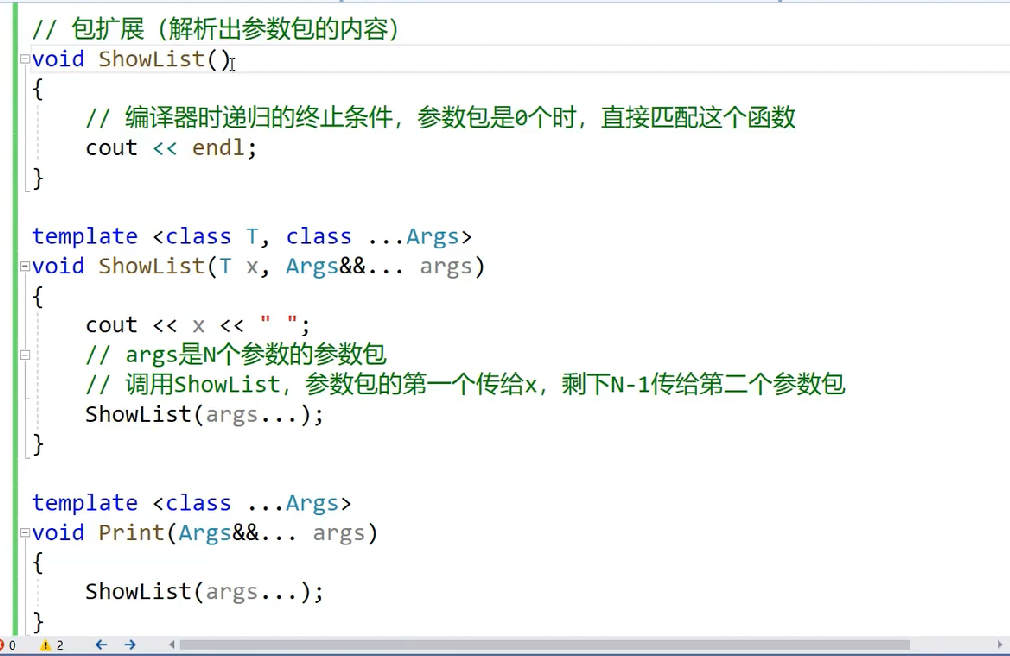
但这里的递归属于编译时递归包的展开,不属于运行时的递归,运行时的递归自己调用自己,连函数参数的数量,种类都是一致的;而递归包的展开,每一层递归的参数数量是在减少的,且递归包里的参数数据类型并不相同:

3.emplace系列接口
Ⅰ.emplace_back和push_back的对比(以list为例)
Ⅰ-1形参的区别

从两个接口的形参可以看出,push_back插入的是定数量的参数,而emplace_back插入的是参数包。
Ⅰ-2使用的区别
传左值:
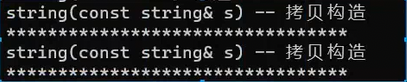
结果没有任何区别,emplace_back和push_back一样,先走拷贝构造,将数据用于构造新节点,然后尾插。实参是左值,push_back就去走形参是左值的重载,emplace_back通过引用折叠,实参处整个引用的性质仍旧是左值。
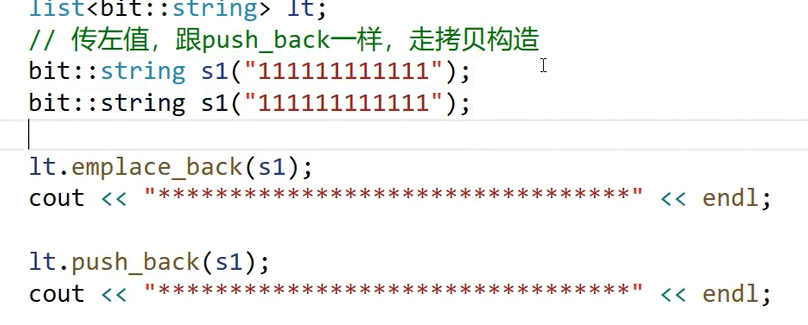
二者运行的结果:
传右值:

结果仍旧相同,只是传右值走的是移动构造而已。

直接传参:

解析过程:
push_back:

链表内节点类型为string,因此push_back被实例化为了string 的push_back。而此时的实参"11111111111111"是个const char* 类型的参数,所以要走一个隐式类型转换, 因此要去调用构造函数,构造一个string类型 的,内容是"11111111111111"的临时变量 。由于临时变量的属性是右值,所以在利用这个临时变量,构造新节点时,走一个移动构造。最后创建好新节点,就执行尾插。

emplace_back:
而emlace_back是根据实参类型来进行实例化的,因为该函数模板是可变参数模板,属于模板的模板,先通过list实例化为函数模板,再由实参"1111111111111" 直接推导出参数类型为const char* ,所以函数模板被实例化为了**const char***类型的函数,由于实参形参类型一致,所以能够直接调用构造函数,构造新链表。构造完后,就执行尾插。

总结:
