一、引言
在数据湖场景中,写入操作并非简单的"append",不同业务场景对数据写入有截然不同的需求:
- CDC 增量同步:需要高效的 upsert 能力,同时还需处理上游的 DELETE 事件
- 日志类数据:追求高吞吐的纯追加写入
- 历史数据回填:需要大批量的初始加载
- 分区级数据重刷:需要原子性的覆盖写入
- 数据合规删除(GDPR/CCPA):需要精准定位并物理移除记录
Hudi 通过提供多种 Write Operation 类型,让用户根据场景精确控制写入行为,从而在写入性能、数据一致性、存储效率之间取得最优平衡。
二、Hudi Write Operations 详解
Hudi 提供以下核心 Write Operation 类型与定位:
| Write Operation | 是否去重 | 是否更新 | 索引查找 | 主要用途 |
|---|---|---|---|---|
| UPSERT | ✅ | ✅ | ✅ | CDC 场景,增量更新 |
| INSERT | ❌(可选去重) | ❌ | ❌ | 确认无重复的追加写入 |
| BULK_INSERT | ❌ | ❌ | ❌ | 大批量初始加载 |
| DELETE | - | - | ✅ | 硬删除指定记录(传入 key + partition path) |
| INSERT_OVERWRITE | ❌ | 覆盖 | ❌ | 分区级数据重刷 |
| INSERT_OVERWRITE_TABLE | ❌ | 覆盖 | ❌ | 全表数据重刷 |
1. UPSERT
UPSERT 是 Hudi 最核心的写操作,也是 COW 和 MOR 表的默认写操作。其核心逻辑是:先通过索引定位记录是否已存在,存在则更新,不存在则插入。
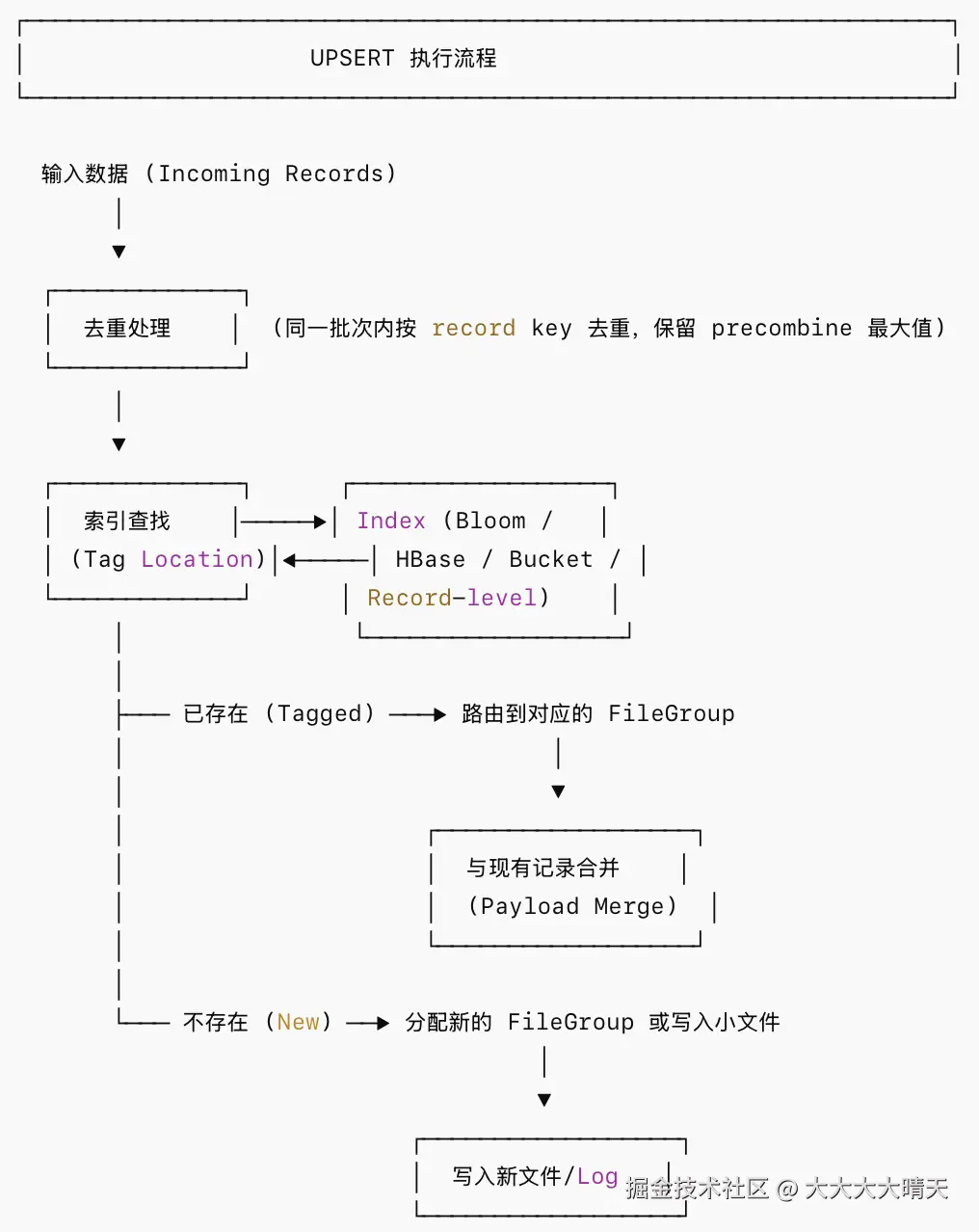
COW 表的 UPSERT:
- 更新操作会重写整个文件(Copy-On-Write),即读取原始 Parquet 文件,合并更新记录后写出新版本文件。
- 写入放大较高,但读取时无需合并,查询性能最优。
MOR 表的 UPSERT:
- 更新操作写入 Delta Log 文件,不立即重写 Base 文件。
- 写入效率高,但读取时需要合并 Base + Log。
- 通过后续 Compaction 操作将 Log 合入 Base 文件。
关键配置:
ini
# 写操作类型
hoodie.datasource.write.operation=upsert
# Payload 合并策略
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.OverwriteWithLatestAvroPayload
# precombine 字段(必须指定,用于同 key 去重)
hoodie.datasource.write.precombine.field=ts
# 并行度控制
hoodie.upsert.shuffle.parallelism=2002. INSERT
INSERT 操作跳过索引查找步骤,直接将数据写入新文件或追加到现有小文件中(小文件合并策略)。

关键特点:
- 不执行索引查找,因此写入性能高于 UPSERT
- 如果数据中存在与已有数据重复的 key,不会去重(除非显式开启
hoodie.combine.before.insert,该配置仅做批次内去重) - 适用于能从业务层保证无重复的场景
与 UPSERT 性能对比:
makefile
性能(吞吐量): BULK_INSERT > INSERT > UPSERT
数据正确性保障: UPSERT > INSERT > BULK_INSERT3. BULK_INSERT
BULK_INSERT 专为大批量初始数据加载设计,绕过了索引查找和小文件分配逻辑,直接利用 Spark/Flink 的排序能力对数据进行组织后写入。
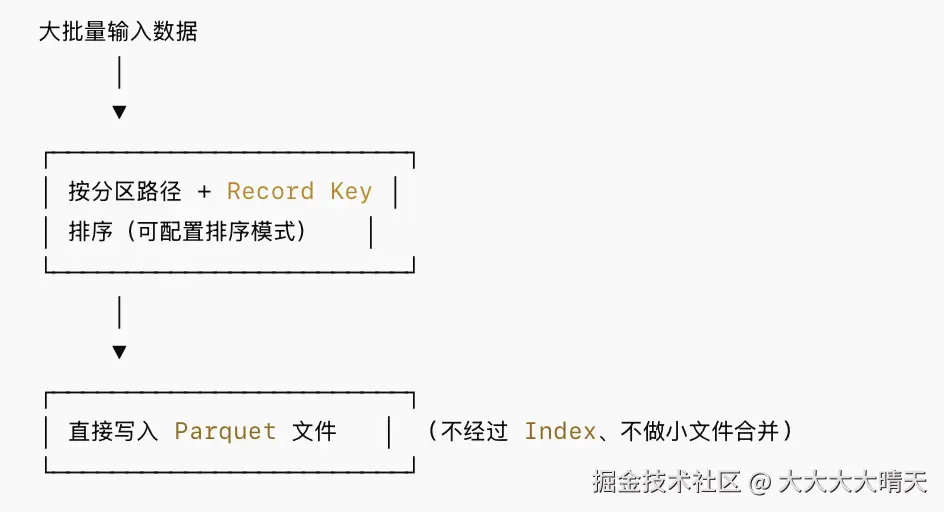
排序模式(hoodie.bulkinsert.sort.mode):
| 模式 | 说明 | 适用场景 |
|---|---|---|
| GLOBAL_SORT | 全局排序,数据分布最优 | 数据量适中,追求最优文件布局 |
| PARTITION_SORT | 分区内排序 | 大数据量,平衡性能与布局 |
| NONE(默认) | 不排序,最快 | 极大数据量且后续会 cluster |
| PARTITION_PATH_REPARTITION | 按分区路径重分区 | 确保分区对齐 |
| PARTITION_PATH_REPARTITION_AND_SORT | 重分区 + 排序 | 兼顾分区对齐与排序 |
关键配置:
ini
hoodie.datasource.write.operation=bulk_insert
hoodie.bulkinsert.sort.mode=PARTITION_SORT
hoodie.bulkinsert.shuffle.parallelism=3004. DELETE
Hudi 的删除并非单一机制,而是提供了一组完整的删除能力体系,涵盖软删除和硬删除两大类。

1.软删除
软删除保留记录在存储中的存在,但将所有非主键字段(除 record key、partition path 和 precombine field 外)置为 null。
python
# 软删除示例:保留 key 字段,其余置空
soft_delete_df = spark.createDataFrame(
[(record_key, partition_path, precombine_val, None, None, ...)],
schema
)
soft_delete_df.write.format("hudi") \
.option("hoodie.datasource.write.operation", "upsert") \
.option("hoodie.table.name", "my_table") \
.mode("append") \
.save(path)适用场景:需要在增量查询(Incremental Query)中感知到"删除事件"的下游消费者。
2.硬删除
硬删除会从存储中彻底移除记录(经 Compaction 和 Clean 后物理删除)。
- DELETE Operation
最直接的方式,传入的 DataFrame 只需包含 record key 和 partition path:
vbnet
# 硬删除 - DELETE operation
delete_df = spark.createDataFrame(
[(record_key, partition_path)],
["id", "partition"]
)
delete_df.write.format("hudi") \
.option("hoodie.datasource.write.operation", "delete") \
.option("hoodie.datasource.write.recordkey.field", "id") \
.option("hoodie.datasource.write.partitionpath.field", "partition") \
.option("hoodie.table.name", "my_table") \
.mode("append") \
.save(path)- EmptyHoodieRecordPayload
通过指定空 payload,使得 UPSERT 写入时将匹配记录标记为删除:
ini
hoodie.datasource.write.operation=upsert
hoodie.datasource.write.payload.class=org.apache.hudi.common.model.EmptyHoodieRecordPayload_hoodie_is_deleted字段
在 CDC 管道中最为常用,可以将 insert/update/delete 事件统一在一个 UPSERT 流中处理:
less
from pyspark.sql.functions import lit, when, col
# CDC 事件流统一处理
cdc_df = cdc_df.withColumn(
"_hoodie_is_deleted",
when(col("op") == "d", lit(True)).otherwise(lit(False))
)
cdc_df.write.format("hudi") \
.option("hoodie.datasource.write.operation", "upsert") \
.option("hoodie.table.name", "my_table") \
.mode("append") \
.save(path)3.不同表类型的删除行为与选型建议
不同表类型下的删除行为:
| 表类型 | 删除行为 |
|---|---|
| COW | 重写整个 Parquet 文件,输出中不包含被删除的记录 |
| MOR | 向 Delta Log 中写入 delete block,后续 Compaction 时物理移除记录 |
删除方式选型建议:
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| CDC 管道中处理 DELETE 事件 | _hoodie_is_deleted 字段 | 与 insert/update 统一管道,无需拆分流 |
| 批量精确删除指定记录 | DELETE operation | 语义清晰,只需提供 key |
| GDPR 合规删除 | DELETE operation | 硬删除,配合 Cleaner 物理移除 |
| 需要下游感知删除事件 | Soft Delete | 增量查询可见删除记录 |
| 整个分区废弃 | INSERT_OVERWRITE + 空 DataFrame | 分区级原子删除 |
5. INSERT_OVERWRITE
NSERT_OVERWRITE 以分区级别进行原子替换,它为目标分区创建全新的 FileGroup,然后在 Timeline 上原子性地将旧文件标记为替换。

核心优势:
- 原子性:要么全部成功,要么全部回滚
- 不影响未涉及的分区
- 无需索引查找,性能好
- 自动清理旧数据(通过 Cleaner)
- 可用于分区级删除(写入空 DataFrame)
关键配置:
vbnet
# Spark 示例:分区级数据重刷
df.write.format("hudi") \
.option("hoodie.datasource.write.operation", "insert_overwrite") \
.option("hoodie.datasource.write.partitionpath.field", "dt") \
.option("hoodie.datasource.write.recordkey.field", "id") \
.option("hoodie.table.name", "my_table") \
.mode("append") \
.save("s3://bucket/my_table")6. INSERT_OVERWRITE_TABLE
与 INSERT_OVERWRITE 类似,但作用范围是全表。整表数据被新写入的数据完全替换。
适用于全量刷新场景,如每日全量快照表、维度表全量更新。
三、版本差异与选型建议
相较于 0.x 版本,Hudi 1.x 在写入路径上有以下关键演进:
| 维度 | 0.x 版本 | 1.x 版本 |
|---|---|---|
| 并发控制 | 基于 OCC(乐观并发) | 非阻塞并发控制(NBCC) |
| 索引体系 | 以 Bloom Index 为主 | Record-level Index 增强,支持多种索引类型 |
| 写入引擎 | Spark 为主 | 多引擎统一(Spark / Flink / Kafka Connect) |
| 表服务 | 与写入耦合 | 异步表服务(Async Table Services) |
| 存储格式 | HFile / Parquet | 统一存储层抽象 |
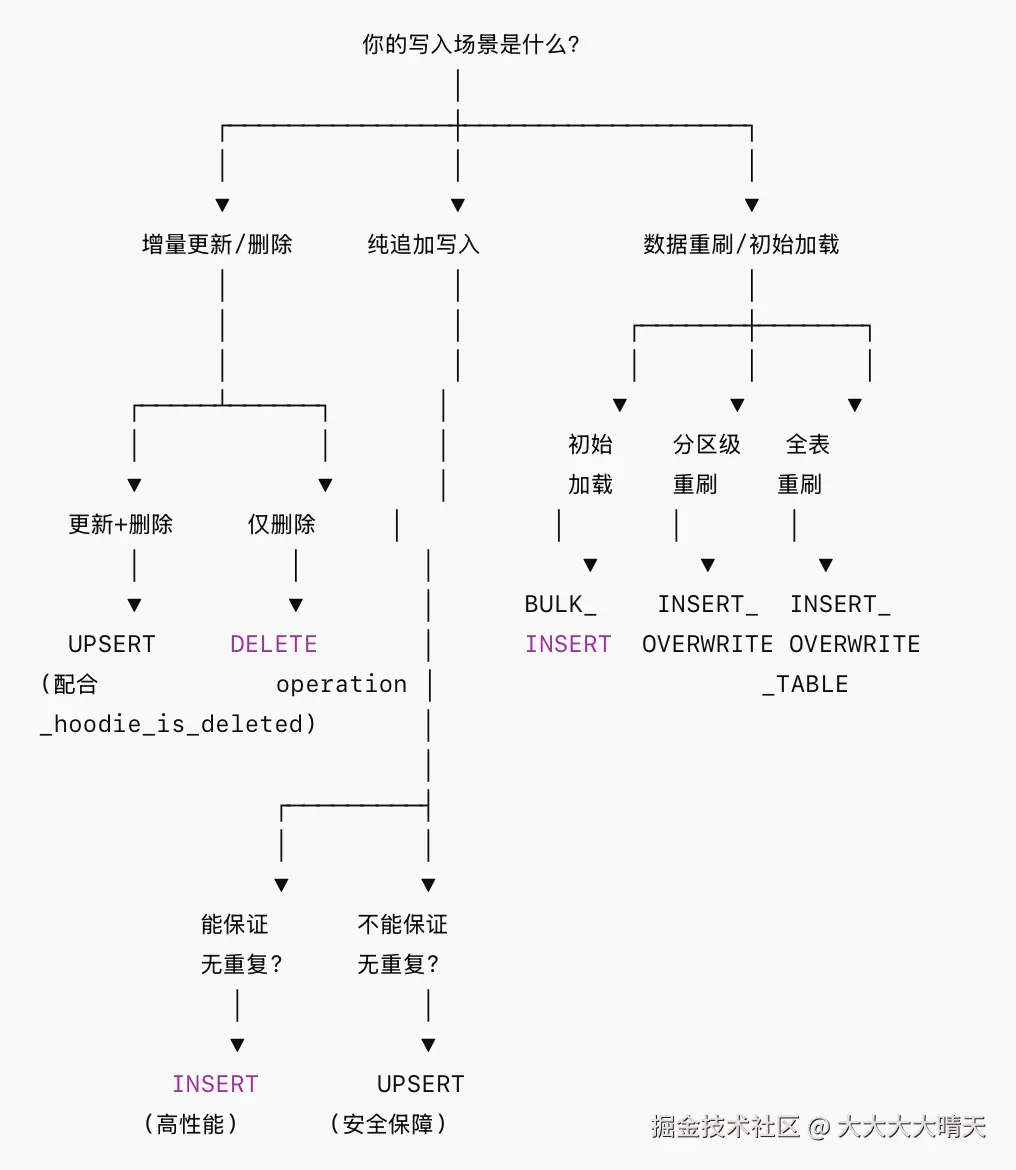
Hudi写操作场景选型决策指南:
四、最佳实践
- UPSERT 性能优化
ini
# 1. 索引选型 - 根据数据规模选择
# 小规模(< 10亿记录):Bloom Index
hoodie.index.type=BLOOM
hoodie.bloom.index.filter.type=DYNAMIC_V0
# 大规模 + 高频更新:Bucket Index(Hudi 1.x 推荐)
hoodie.index.type=BUCKET
hoodie.index.bucket.engine=CONSISTENT_HASHING
hoodie.bucket.index.num.buckets=256
# 2. 并行度调优
hoodie.upsert.shuffle.parallelism=<num_partitions * 2~3>
# 3. precombine field 必须指定
hoodie.datasource.write.precombine.field=updated_at- BULK_INSERT 初始加载
ini
# 建议配置
hoodie.datasource.write.operation=bulk_insert
hoodie.bulkinsert.sort.mode=PARTITION_SORT
# 控制文件大小(避免过多小文件)
hoodie.parquet.max.file.size=134217728 # 128MB
hoodie.parquet.small.file.limit=0 # 关闭小文件合并
# 并行度 = 数据总量 / 目标文件大小
hoodie.bulkinsert.shuffle.parallelism=<total_data_size / 128MB>- MOR 表 + UPSERT 的 Compaction 策略
ini
# Compaction 触发策略
hoodie.compact.inline=false # 生产环境关闭 inline compaction
hoodie.compact.schedule.inline=true # 在写入时调度 compaction plan
hoodie.compact.inline.max.delta.commits=5 # 每5次提交触发一次
# 异步 Compaction(推荐)
# 通过独立作业执行 compaction,避免影响写入延迟