我调用通义千问多模态 API 的时候,连续报了两个不同的错,折腾了整整一下午。本来以为只是复制粘贴官方示例就能跑通的小事,结果硬生生从下午两点搞到了晚上七点,连晚饭都忘了吃。
事情是这样的,我想做一个简单的 AI 换装小工具,输入一张人物照片、一张衣服照片和一个姿势参考图,让 AI 自动把人物换成穿那件衣服的样子,再摆成指定的姿势。听起来很简单对吧?通义千问最新的 qwen-image-2.0-pro 模型正好支持多模态生成,我想着花半小时写个 demo 试试水。
第一个坑:环境变量死活读不出来
我先用 vite 快速搭了个项目,项目结构就是最基础的那种:
一开始我图省事,直接把 API 密钥写在了 main.js 里:
javascript
// 千万别这么写!会把你的API密钥暴露给所有人
const apiKey = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx';写完我突然反应过来,这要是不小心提交到 github 上,我的 API 密钥就泄露了,到时候别人用我的账号生成图片,我得被阿里云扣多少钱啊。赶紧改成用环境变量的方式。
我在项目根目录建了个.env文件,写上:
plaintext
QWEN_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx然后在 main.js 里用process.env.QWEN_API_KEY去读,结果一跑,控制台直接报process is not defined。
当时我懵了,这不是 node 里最基础的环境变量用法吗?怎么在 vite 里不行了?我第一反应是 vite 没有加载.env 文件,重启了好几次 dev 服务器,还是不行。又去搜了 "vite 环境变量 读取失败",翻了好几个博客,才看到那行用红色标出来的注意事项:所有暴露给客户端的环境变量都必须以 VITE_开头。
而且 vite 里不能用process.env,必须用import.meta.env。我当时拍了一下脑袋,怎么把这个给忘了。赶紧把文件名改成.env.local(这样 git 就不会提交这个文件了),内容改成:
plaintext
VITE_QWEN_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx然后在代码里这样读:
javascript
// 注意这里必须用import.meta.env,不能用process.env
// 别问我为什么知道,试了三次才发现vite不支持process.env
const apiKey = import.meta.env.VITE_QWEN_API_KEY;这下环境变量终于能读出来了。说实话,vite 这个设计虽然有点反直觉,但是确实很安全。只有以 VITE_开头的变量才会被暴露给客户端,避免了不小心把后端的敏感变量泄露出去的问题。
第二个坑:请求体格式踩了官方文档的坑
环境变量的问题解决了,我信心满满地复制了官方文档里的请求示例,改了改图片链接,就点击了运行。结果又报错了:网页解析失败,可能是不支持的网页类型,请检查网页或稍后重试。
我看了一眼官方文档的示例,是这样写的:
json
{
"model": "qwen-image-2.0-pro",
"input": {
"messages": [
{
"role": "user",
"content": "把图中的女生换成穿红色裙子的样子"
}
]
}
}我以为多图的话,只要把 content 改成数组就行了,于是写成了这样:
javascript
// 这是错误的写法!
body: JSON.stringify({
'model': 'qwen-image-2.0-pro',
'input': {
'messages': [
{
'role': 'user',
'content': [
'https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png',
'https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png',
'https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/gborgw/input3.png',
'图一中的女生穿着图二中的黑色裙子按图三的姿势坐下'
]
}
]
}
})结果就报了那个解析失败的错误。我以为是 fetch 的问题,换成了 axios,结果还是一样的报错。又去检查了图片链接,都是公网可访问的,复制到浏览器里能直接打开。
我盯着请求体看了半天,突然发现官方文档里的 content 是字符串,而我写成了字符串数组。难道多模态的 content 格式和普通的聊天不一样?我赶紧翻到官方文档的多模态部分,才看到正确的格式是这样的:
json
{
"content": [
{"image": "图片链接1"},
{"image": "图片链接2"},
{"text": "文本描述"}
]
}原来每个元素都必须是一个对象,明确指定是 image 还是 text 类型!我之前直接写字符串数组,模型根本不知道哪个是图片哪个是文本,所以就解析失败了。
赶紧改成正确的格式:
javascript
body: JSON.stringify({
'model': 'qwen-image-2.0-pro',
'input': {
'messages': [
{
'role': 'user',
'content': [
{'image': 'https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png'},
{'image': 'https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png'},
{'image': 'https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/gborgw/input3.png'},
{'text': '图一中的女生穿着图二中的黑色裙子按图三的姿势坐下'}
]
}
]
},
'parameters': {
'n': 1,
'size': '1024*1536'
}
})这下解析失败的错误终于消失了。
多模态模型到底在干嘛?
踩完这两个坑,我总算把 demo 跑通了。这时候我才静下心来想,多模态模型到底是怎么理解这三张图片和一段文本的?
其实你可以把多模态模型想象成一个会看图说话的小朋友。你给他看几张图片,再告诉他要做什么,他就能把这些信息整合起来,生成你想要的结果。
比如你给小朋友看一张小明的照片,一张红色裙子的照片,再告诉他 "让小明穿上这条裙子",小朋友就能明白你的意思,画出小明穿红裙子的样子。
但是如果你给小朋友看一张只有一个字的纸,他会觉得这不是一张 "图片",而是一张写了字的纸,他不知道该怎么把这个字和其他图片结合起来。所以模型就会报错说无法解析文本信息。
同样,如果你给小朋友看一张全是线条的骨架图,他可能看不懂这是什么意思,不知道这是一个人的姿势。所以你得给他看一张真人的照片,他才能明白你想要的姿势是什么样的。
原图


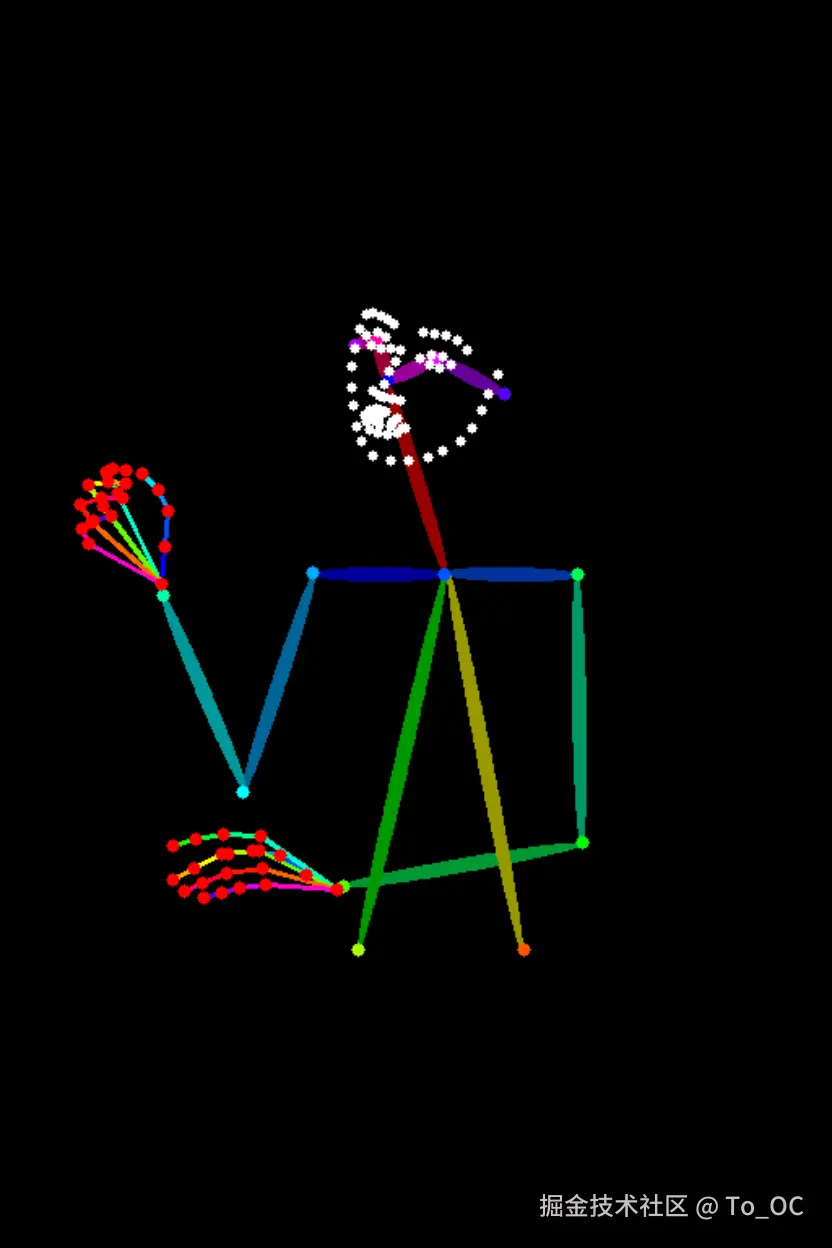
最终能跑通的完整代码
好了,废话不多说,把最终能跑通的完整代码贴出来,你们直接复制就能用:
javascript
// src/main.js
// 注意这里必须用import.meta.env,不能用process.env
// 别问我为什么知道,试了三次才发现vite不支持process.env
const apiKey = import.meta.env.VITE_QWEN_API_KEY;
const root = document.querySelector('#app');
const generateImage = async () => {
// 显示加载状态
root.innerHTML = '<p>正在生成图片,请稍候...</p>';
try {
const res = await fetch('https://dashscope.aliyuncs.com/api/v1/services/aigc/multimodal-generation/generation',
{
method: 'POST',
headers: {
'Authorization': `Bearer ${apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
'model': 'qwen-image-2.0-pro',
'input': {
'messages': [
{
'role': 'user',
'content': [
// 注意:每个元素必须是对象,明确指定type
{'image': 'https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/thtclx/input1.png'},
{'image': 'https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250925/iclsnx/input2.png'},
{'text': '图中的女生穿着图二中的黑色单肩连衣裙,坐在湖边的石头上,手里拿着蒲扇'}
]
}
]
},
'parameters': {
'n': 1,
'size': '1024*1536'
}
})
}
)
if (!res.ok) {
throw new Error(`请求失败:${res.status} ${res.statusText}`);
}
const data = await res.json();
return data.output.choices[0].message.content[0].image;
} catch (error) {
root.innerHTML = `<p>生成失败:${error.message}</p>`;
throw error;
}
}
const renderImage = (imageUrl) => {
root.innerHTML = `<img src='${imageUrl}' alt="生成的图片" style="max-width: 100%; height: auto;" />`;
}
const main = async () => {
try {
const imageUrl = await generateImage();
renderImage(imageUrl);
} catch (error) {
console.error('生成图片失败:', error);
}
}
main();index.html 的代码很简单,只要有一个挂载点就行:
html
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/favicon.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>qwen-image-demo</title>
</head>
<body>
<div id="app"></div>
<script type="module" src="/src/main.js"></script>
</body>
</html>然后在项目根目录创建.env.local文件,写上你的 API 密钥:
plaintext
VITE_QWEN_API_KEY=sk-你的通义千问API密钥运行npm run dev,打开浏览器就能看到生成的图片了。这是我生成的结果:

效果还不错吧?女生穿上了那条黑色的单肩连衣裙,姿势也和我要求的差不多。虽然细节上还有点小问题,比如扇子的颜色有点不对,但是整体效果已经超出我的预期了。
最后说几句
折腾了一下午,总算把这个小 demo 跑通了。现在回头看,其实都是一些很基础的坑,但是第一次踩的时候真的会浪费很多时间。
我总结了三个最关键的点,你们要是也在调用通义千问的多模态 API,一定要记住:
- vite 的环境变量必须以 VITE_开头,而且要用
import.meta.env读取,不能用process.env - 请求体里的 content 必须是对象数组,每个元素明确指定是 image 还是 text 类型
- 不要传内容过于简单的图片,比如纯线条的骨架图、白底黑字的纯文本图片等
当然,这个 API 还有很多限制,比如不能生成太复杂的场景,人物的脸有时候会变形,生成的速度也有点慢。但是作为一个免费试用的模型,能做到这个程度已经很不错了。
要是你还有什么其他的发现,或者遇到了我没提到的问题,欢迎在评论区留言,我们一起讨论。搞懂了记得回来留个言,我也想看看你的理解。