作者:翰墨之道,毕业于国际知名大学空间信息与计算机专业,获硕士学位,现任国内时空智能领域资深专家、CSDN知名技术博主。多年来深耕地理信息与时空智能核心技术研发,精通 QGIS、GrassGIS、OSG、OsgEarth、UE、Cesium、OpenLayers、Leaflet、MapBox 等主流工具与框架,兼具学术深度与工程实践经验。
专注于时空数据可视化、地理信息系统开发、三维场景搭建等方向,持续在CSDN分享技术干货与实战案例,累计产出多篇高质量原创内容,深受行业开发者认可。诚邀对时空智能、GIS技术、三维技术感兴趣的朋友添加微信(Lucky-Matrix),共探技术前沿、交流实践心得,携手推动相关领域技术落地与创新!
📚 查看《QGIS快速入门与应用基础》系列专栏完整目录
文章目录
- [1.4.1.2 空值填充策略(默认值/插值/相邻值)](#1.4.1.2 空值填充策略(默认值/插值/相邻值))
-
- 一、空值填充策略的核心认知
-
- [1.1 为什么需要填充而不是直接删除?](#1.1 为什么需要填充而不是直接删除?)
- [1.2 三种填充策略的对比](#1.2 三种填充策略的对比)
- 二、默认值填充策略
-
- [2.1 默认值填充的核心方法与原理](#2.1 默认值填充的核心方法与原理)
- [2.2 QGIS 中默认值填充的实操方法](#2.2 QGIS 中默认值填充的实操方法)
- [2.3 默认值填充的行业实践](#2.3 默认值填充的行业实践)
- [2.4 默认值填充的常见问题与解决方案](#2.4 默认值填充的常见问题与解决方案)
- [2.5 Python 自动化实现:默认值填充脚本](#2.5 Python 自动化实现:默认值填充脚本)
- 三、空间插值填充策略
-
- [3.1 插值填充的核心原理与适用场景](#3.1 插值填充的核心原理与适用场景)
- [3.2 常用插值方法对比](#3.2 常用插值方法对比)
- [3.3 QGIS 中插值填充的实操方法](#3.3 QGIS 中插值填充的实操方法)
- 四、相邻值填充策略
-
- [4.1 相邻值填充的核心原理](#4.1 相邻值填充的核心原理)
- [4.2 三种相邻值填充方法](#4.2 三种相邻值填充方法)
- [4.3 QGIS 中相邻值填充的实操方法](#4.3 QGIS 中相邻值填充的实操方法)
- [4.4 相邻值填充的行业应用](#4.4 相邻值填充的行业应用)
- 五、填充策略的选择原则
-
- [5.1 基于数据特征的策略选择](#5.1 基于数据特征的策略选择)
- [5.2 三种填充策略的综合对比](#5.2 三种填充策略的综合对比)
- [5.3 填充策略的最佳实践流程](#5.3 填充策略的最佳实践流程)
- 六、填充后质量验证
-
- [6.1 验证指标与方法](#6.1 验证指标与方法)
- [6.2 Python 自动化验证脚本](#6.2 Python 自动化验证脚本)
- 七、综合案例:某省国土变更调查数据空值填充
-
- [7.1 项目背景](#7.1 项目背景)
- [7.2 填充策略选择](#7.2 填充策略选择)
- [7.3 填充流程](#7.3 填充流程)
- [7.4 验证结果](#7.4 验证结果)
- 八、常见问题与最佳实践
-
- [8.1 填充策略选择常见问题](#8.1 填充策略选择常见问题)
- [8.2 填充策略最佳实践总结](#8.2 填充策略最佳实践总结)
- 九、总结
1.4.1.2 空值填充策略(默认值/插值/相邻值)
一、空值填充策略的核心认知
1.1 为什么需要填充而不是直接删除?
在空间数据处理中,空值处理历来有两种思路:
| 思路 | 做法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 删除法 | 丢弃含空值的记录 | 操作简单、不留残迹 | 样本量锐减、空间分布失衡、可能引入偏差 | 空值比例 < 1%,且随机分布 |
| 填充法 | 用合理值替换空值 | 保留样本量、维持空间完整性 | 可能引入伪数据、需要科学依据 | 空值比例 ≥ 1%、或空值有特定原因 |
核心认知:
- 空值填充不是"造假",而是基于已有信息对缺失值进行合理估算
- 填充的质量取决于策略的选择 和参数的合理性
- 填充后必须进行质量验证,否则可能传播错误信息
1.2 三种填充策略的对比
| 策略 | 原理 | 操作难度 | 对数据的影响 | 适用数据类型 |
|---|---|---|---|---|
| 默认值填充 | 用固定值(0、均值、中位数、众数)替换空值 | ⭐ 简单 | 可能扭曲分布、不反映空间差异 | 分类字段、数值字段 |
| 插值填充 | 基于空间邻近原则,用已知点估算未知点 | ⭐⭐⭐ 复杂 | 保留空间连续性、可能平滑极端值 | 连续型数值字段(高程、温度、降雨) |
| 相邻值填充 | 用空间相邻要素的值填充空值 | ⭐⭐ 中等 | 保持局部一致性、可能放大噪声 | 分类字段、序列数据(时间/空间) |
二、默认值填充策略
2.1 默认值填充的核心方法与原理
默认值填充是最基础的填充方式,核心是用一个固定值或统计算法计算出的代表值替换所有空值。
| 填充方法 | 计算公式/操作 | 适用场景 | 局限性 |
|---|---|---|---|
| 常数填充 | 所有空值 = 固定值(如 0、-9999) | 分类字段的"未知"类别、高程补全 | 可能扭曲统计分布 |
| 均值填充 | 所有空值 = mean(非空值) | 近似正态分布的连续变量 | 缩小标准差、不反映空间差异 |
| 中位数填充 | 所有空值 = median(非空值) | 偏态分布、有极端值 | 同样不反映空间差异 |
| 众数填充 | 所有空值 = mode(非空值) | 分类数据(地类、土壤类型) | 可能过度代表某一类别 |
2.2 QGIS 中默认值填充的实操方法
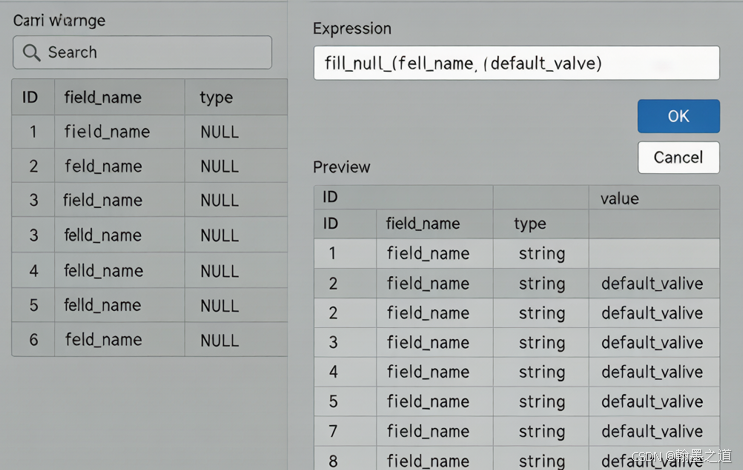
方法 1:字段计算器 + fill_null() 函数
QGIS 字段计算器提供了 fill_null() 函数,可以一键填充空值:
fill_null("elevation", 0) -- 用 0 填充高程空值
fill_null("landuse", 'Unknown') -- 用"Unknown"填充地类空值
fill_null("precipitation", mean("precipitation")) -- 用均值填充操作步骤:
- 右键图层 → 打开属性表
- 点击"切换编辑模式"(铅笔图标)
- 点击"打开字段计算器"
- 选择"创建新字段"或"更新现有字段"
- 在表达式中输入
fill_null()函数 - 点击"确定"执行填充
图1:QGIS 字段计算器中的 fill_null() 函数
方法 2:使用属性表手动编辑(适用于小量空值)
当空值数量较少(< 50 条)时,可以直接在属性表中手动输入:
- 打开属性表
- 勾选"切换编辑模式"
- 逐个点击空值单元格
- 输入默认值
方法 3:模型构建器批量填充
使用模型构建器创建可复用的默认值填充流程:
- 打开"模型构建器"(Processing → Model Designer)
- 添加"字段计算器"算法
- 将图层和填充规则作为参数
- 保存模型为
.model3文件
2.3 默认值填充的行业实践
| 行业 | 字段 | 填充策略 | 填充值 | 原因 |
|---|---|---|---|---|
| 国土调查 | 坡度 | 均值填充 | 区域平均坡度 | 坡度空值多为传感器噪声,均值最接近真实值 |
| 国土调查 | 地类编码 | 众数填充 | 该乡镇最常见地类 | 地类空值多为边界模糊,用众数最保险 |
| 水利 | 流量 | 常数填充 | 0 | 河道断流导致流量为空,0 表示无流量 |
| 生态 | 植被覆盖度 | 中位数填充 | 区域植被覆盖中位数 | 覆盖度分布偏态,中位数比均值更稳健 |
| 城建 | 建筑高度 | 均值填充 | 同街区建筑平均高度 | 同街区建筑高度相近,均值合理 |
| 农业 | 土壤有机质 | 众数填充 | 该土壤类型常见有机质范围中值 | 土壤有机质有明确的地带性规律 |
2.4 默认值填充的常见问题与解决方案
| 问题 | 原因 | 解决方案 | 最佳实践 |
|---|---|---|---|
| 填充后标准差显著缩小 | 均值/中位数填充压缩了变异性 | 改用空间插值或添加随机扰动 | 填充值 = 均值 + random(0, ±标准差*0.1) |
| 填充后空间分布均匀化 | 默认值不反映空间异质性 | 按空间分区填充(如按乡镇、流域) | 先按空间单元分组,再分组填充 |
| 分类字段过度代表某一类 | 众数填充使某类占比虚高 | 改用相邻值填充或人工判断 | 对于分类字段,优先用相邻要素的地类 |
| 常数 0 被误认为是真实值 | 0 与有效数据无法区分 | 使用 -9999 或 NoData 标记填充空值 | 在数据分析时排除 -9999 |
| 填充后统计分布变形 | 填充方法与原分布不匹配 | 先用直方图检查分布,再选择填充方法 | 正态分布用均值,偏态用中位数,多峰用众数 |
2.5 Python 自动化实现:默认值填充脚本
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
QGIS 空间数据属性空值默认值填充脚本
支持:Shapefile / GeoJSON / CSV / GeoPackage
填充策略:均值 / 中位数 / 众数 / 常数
"""
import argparse
import pandas as pd
import geopandas as gpd
import numpy as np
import sys
def fill_defaults(gdf, strategy='mean', fill_values=None):
"""
对 GeoDataFrame 的数值和分类字段进行默认值填充
参数:
gdf : GeoDataFrame
输入矢量数据
strategy : str
填充策略:'mean'(均值)/'median'(中位数)/'mode'(众数)/'constant'(常数)
fill_values : dict, optional
当 strategy='constant' 时,指定各字段的填充值
返回:
filled_gdf : GeoDataFrame
填充后的矢量数据
"""
filled_gdf = gdf.copy()
numeric_cols = filled_gdf.select_dtypes(include=[np.number]).columns.tolist()
categorical_cols = filled_gdf.select_dtypes(include=['object', 'category']).columns.tolist()
# 排除几何列
categorical_cols = [c for c in categorical_cols if c != 'geometry']
print(f"检测到 {len(numeric_cols)} 个数值字段:{numeric_cols}")
print(f"检测到 {len(categorical_cols)} 个分类字段:{categorical_cols}")
# 数值字段填充
for col in numeric_cols:
null_count = filled_gdf[col].isnull().sum()
if null_count == 0:
continue
print(f"\n--- 字段:{col} ---")
print(f" 空值数量:{null_count} / {len(filled_gdf)}")
if strategy == 'mean':
fill_val = filled_gdf[col].mean()
method_name = '均值'
elif strategy == 'median':
fill_val = filled_gdf[col].median()
method_name = '中位数'
elif strategy == 'constant':
fill_val = fill_values.get(col, 0) if fill_values else 0
method_name = f"常数 {fill_val}"
else:
continue
filled_gdf[col].fillna(fill_val, inplace=True)
print(f" 填充方法:{method_name} = {fill_val}")
# 分类字段填充(仅众数)
if strategy == 'mode':
for col in categorical_cols:
null_count = filled_gdf[col].isnull().sum()
if null_count == 0:
continue
print(f"\n--- 分类字段:{col} ---")
print(f" 空值数量:{null_count} / {len(filled_gdf)}")
mode_val = filled_gdf[col].mode()
fill_val = mode_val[0] if len(mode_val) > 0 else 'Unknown'
filled_gdf[col].fillna(fill_val, inplace=True)
print(f" 填充方法:众数 = {fill_val}")
elif strategy == 'constant' and fill_values:
for col in categorical_cols:
if col in fill_values:
null_count = filled_gdf[col].isnull().sum()
if null_count > 0:
fill_val = fill_values[col]
filled_gdf[col].fillna(fill_val, inplace=True)
print(f"\n分类字段 {col} 用常数 {fill_val} 填充了 {null_count} 条")
return filled_gdf
def main():
parser = argparse.ArgumentParser(description='QGIS 空间数据默认值填充')
parser.add_argument('--input', required=True, help='输入文件路径')
parser.add_argument('--output', required=True, help='输出文件路径')
parser.add_argument('--strategy', default='mean',
choices=['mean', 'median', 'mode', 'constant'],
help='填充策略')
parser.add_argument('--constant-values', default='',
help='常数填充值,格式 key=value,key=value')
args = parser.parse_args()
# 自动识别文件格式
ext = args.input.lower().split('.')[-1]
if ext in ['shp', 'geojson', 'json']:
gdf = gpd.read_file(args.input)
elif ext == 'csv':
df = pd.read_csv(args.input)
gdf = gpd.GeoDataFrame(df, geometry='geometry' if 'geometry' in df.columns else None)
elif ext == 'gpkg':
gdf = gpd.read_file(args.input, layer='data')
else:
print(f"不支持的文件格式:{ext}")
sys.exit(1)
print(f"加载文件:{args.input}")
print(f"记录数:{len(gdf)},字段数:{len(gdf.columns)}")
# 解析常数填充值
fill_values = {}
if args.constant_values:
for pair in args.constant_values.split(','):
k, v = pair.split('=')
fill_values[k.strip()] = v.strip()
# 执行填充
filled_gdf = fill_defaults(gdf, args.strategy, fill_values)
# 导出
if ext in ['shp']:
filled_gdf.to_file(args.output, driver='ESRI Shapefile')
elif ext in ['geojson', 'json']:
filled_gdf.to_file(args.output, driver='GeoJSON')
elif ext == 'gpkg':
filled_gdf.to_file(args.output, layer='data', driver='GPKG')
elif ext == 'csv':
filled_gdf.to_csv(args.output, index=False)
# 统计空值剩余量
null_counts = filled_gdf.isnull().sum()
remaining = null_counts.sum()
print(f"\n填充完成!剩余空值:{remaining}")
print(f"输出文件:{args.output}")
if __name__ == '__main__':
main()使用示例:
bash
# 均值填充
python fill_defaults.py --input survey_data.shp --output filled_mean.shp --strategy mean
# 众数填充(分类字段)
python fill_defaults.py --input survey_data.shp --output filled_mode.shp --strategy mode
# 常数填充
python fill_defaults.py --input survey_data.shp --output filled.shp \
--strategy constant --constant-values "landuse=Unknown,elevation=0"三、空间插值填充策略
3.1 插值填充的核心原理与适用场景
空间插值填充是基于**"空间自相关"原理**------空间上邻近的要素往往具有相似属性值。通过已知点的值,可以合理估算未知点的值。
插值填充的核心假设:
- 空间自相关性:邻近要素的属性值具有相似性
- 距离衰减效应:距离越近,影响越大;距离越远,影响越小
- 局部连续性:空间现象在局部范围内是连续变化的
3.2 常用插值方法对比
| 方法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 反距离权重(IDW) | 邻近点权重的平均值 | 简单快速、参数少 | 产生"牛眼"效应、不反映地形 | 坡度、温度等平滑变化现象 |
| 克里金(Kriging) | 基于变异函数的最优无偏估计 | 提供误差估计、统计严谨 | 参数复杂、计算量大 | 高程、降雨、矿产储量 |
| 样条(Spline) | 用最小弯曲的曲面拟合数据 | 曲面光滑、过控制点 | 可能出现过冲/振荡 | 地形表面、重力场 |
| 局部多项式(Local Polynomial) | 用局部回归曲面拟合 | 可反映趋势面 | 边界效应明显 | 污染浓度梯度、海拔梯度 |
图2:三种常用空间插值方法对比

3.3 QGIS 中插值填充的实操方法
方法 1:IDW 插值(最简单)
操作步骤:
- 打开"处理面板"(Processing → Toolbox)
- 搜索"IDW 插值"
- 输入参数:
- 输入图层:含非空值记录的点图层
- 目标字段:要插值的属性字段
- 插值倍数:2~5(默认 2,值越大越平滑)
- 幂次:2(默认 2,值越大邻近点影响越大)
- 运行,输出为栅格
方法 2:克里金插值(最严谨)
操作步骤:
- 处理面板搜索"克里金插值"
- 输入参数:
- 输入图层:含非空值记录的点图层
- 目标字段:要插值的属性字段
- 变异函数模型:球形 / 指数 / 高斯(默认球形)
- 网格间距:根据研究区域大小设置
- 运行
方法 3:基于插值结果回填属性(核心实操)
对于面状矢量数据(如Survey样地、地块),插值填充的核心流程是:
- 将含非空值的要素质心提取为点
- 用这些点做空间插值生成栅格
- 用栅格采样(Zonal Statistics)回填到原矢量要素
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
QGIS 空间数据插值填充脚本(IDW 方法)
核心流程:质心提取 → IDW 插值 → 栅格采样回填
"""
import argparse
import geopandas as gpd
import numpy as np
from scipy.interpolate import LinearNDInterpolator, NearestNDInterpolator
import sys
def idw_interpolation(filled_gdf, target_field, power=2, k_neighbors=10):
"""
使用 IDW 方法插值填充空值
参数:
filled_gdf : GeoDataFrame
输入矢量数据(含几何信息)
target_field : str
要插值的属性字段
power : float
幂次参数(默认 2)
k_neighbors : int
使用的最近邻点数(默认 10)
返回:
result_gdf : GeoDataFrame
填充后的矢量数据
"""
result_gdf = filled_gdf.copy()
# 分离已知点和空值点
known_mask = result_gdf[target_field].notna()
unknown_mask = result_gdf[target_field].isna()
if not known_mask.any():
print(f"字段 {target_field} 没有已知值,无法插值")
return result_gdf
if not unknown_mask.any():
print(f"字段 {target_field} 没有空值,无需插值")
return result_gdf
known_points = result_gdf[known_mask]
unknown_points = result_gdf[unknown_mask]
# 提取坐标
known_coords = np.array([(x, y) for x, y in known_points.geometry.values.centroid.coords])
known_values = known_points[target_field].values
unknown_coords = np.array([(x, y) for x, y in unknown_points.geometry.values.centroid.coords])
# IDW 插值
interpolated_values = []
for ux, uy in unknown_coords:
# 计算到所有已知点的距离
distances = np.sqrt(np.sum((known_coords - [ux, uy]) ** 2, axis=1))
# 排除距离为 0 的点(即未知点恰好与已知点重合)
zero_dist_mask = distances == 0
if np.any(zero_dist_mask):
interpolated_values.append(known_values[zero_dist_mask][0])
continue
# 取最近的 k_neighbors 个点
k_indices = np.argsort(distances)[:k_neighbors]
k_distances = distances[k_indices]
k_values = known_values[k_indices]
# IDW 公式
weights = 1.0 / (k_distances ** power)
weight_sum = weights.sum()
interpolated_val = np.sum(weights * k_values) / weight_sum
interpolated_values.append(interpolated_val)
# 回填
unknown_indices = result_gdf[unknown_mask].index
result_gdf.loc[unknown_indices, target_field] = interpolated_values
print(f"IDW 插值完成:填充了 {len(interpolated_values)} 条记录")
return result_gdf
def main():
parser = argparse.ArgumentParser(description='QGIS 空间数据 IDW 插值填充')
parser.add_argument('--input', required=True, help='输入文件路径')
parser.add_argument('--output', required=True, help='输出文件路径')
parser.add_argument('--field', required=True, help='要插值的字段名')
parser.add_argument('--power', type=float, default=2.0, help='IDW 幂次(默认 2)')
parser.add_argument('--neighbors', type=int, default=10, help='最近邻点数(默认 10)')
args = parser.parse_args()
gdf = gpd.read_file(args.input)
print(f"加载文件:{args.input}")
print(f"记录数:{len(gdf)}")
null_count = gdf[args.field].isnull().sum()
print(f"空值数量:{null_count} / {len(gdf)}")
result_gdf = idw_interpolation(gdf, args.field, args.power, args.neighbors)
# 导出
gdf_ext = args.output.lower().split('.')[-1]
if gdf_ext == 'shp':
result_gdf.to_file(args.output, driver='ESRI Shapefile')
elif gdf_ext == 'geojson':
result_gdf.to_file(args.output, driver='GeoJSON')
elif gdf_ext == 'gpkg':
result_gdf.to_file(args.output, driver='GPKG')
remaining = result_gdf[args.field].isnull().sum()
print(f"填充完成!剩余空值:{remaining}")
print(f"输出文件:{args.output}")
if __name__ == '__main__':
main()使用示例:
bash
# 使用 IDW 插值填充高程字段
python idw_fill.py --input sample_points.shp --output filled.shp --field elevation --power 2 --neighbors 10四、相邻值填充策略
4.1 相邻值填充的核心原理
相邻值填充的核心思想是:空间上相邻的要素往往具有相似属性值,尤其是对于分类数据(地类、土壤类型)和具有空间连续性的数据(植被覆盖、土地利用)。
相邻值填充适用场景:
- 分类数据:地类编码、土壤类型、植被类型
- 空间连续性强的数据:坡度分类、土地利用类型
- 拓扑关系明确的数据:相邻地块、相邻乡镇
4.2 三种相邻值填充方法
| 方法 | 原理 | 操作 | 适用场景 |
|---|---|---|---|
| 最近邻填充 | 用空间距离最近的非空要素值填充 | 计算质心距离,取最近非空值 | 通用场景 |
| ** majority 填充** | 用相邻 N 个要素中出现频率最高的值填充 | 取前 N 邻,计算众数 | 分类数据(地类) |
| 上行填充/下行填充 | 按属性排序后,用前一个或后一个非空值填充 | 按字段排序,向前或向后填充 | 有序数据(如剖面数据、时间序列) |
4.3 QGIS 中相邻值填充的实操方法
方法 1:使用 Nearest Neighbour Aggregation 插件
操作步骤:
- 处理面板搜索"Nearest Neighbour Aggregation"
- 输入参数:
- 主图层:含空值的矢量图层
- 连接图层:通常为自身
- 连接字段:要填充的字段
- 最近邻数量:3~10(默认 3)
- 聚合方法:Mean / Median / Mode / First
- 运行
方法 2:Python 脚本实现最近邻填充
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
QGIS 空间数据相邻值填充脚本(最近邻 + Majority 方法)
"""
import argparse
import geopandas as gpd
import numpy as np
from scipy.spatial import cKDTree
import sys
def nearest_neighbor_fill(gdf, target_field, k=3):
"""
使用最近邻方法填充空值
参数:
gdf : GeoDataFrame
target_field : str
k : int
使用的最近邻数量
返回:
filled_gdf : GeoDataFrame
"""
filled_gdf = gdf.copy()
known_mask = filled_gdf[target_field].notna()
unknown_mask = filled_gdf[target_field].isna()
if not known_mask.any() or not unknown_mask.any():
return filled_gdf
known_coords = np.array([(x, y) for x, y in filled_gdf[known_mask].geometry.centroid.coords])
unknown_coords = np.array([(x, y) for x, y in filled_gdf[unknown_mask].geometry.centroid.coords])
# 构建 KD-Tree 加速最近邻搜索
tree = cKDTree(known_coords)
# 查询每个未知点的最近 k 个已知点
distances, indices = tree.query(unknown_coords, k=min(k, known_mask.sum()))
# 取最近邻的值
known_values = filled_gdf[known_mask][target_field].values
filled_values = known_values[indices[:, 0]] # 取最近的一个
unknown_indices = filled_gdf[unknown_mask].index
filled_gdf.loc[unknown_indices, target_field] = filled_values
print(f"最近邻填充完成:填充了 {len(filled_values)} 条记录,k={k}")
return filled_gdf
def majority_neighbor_fill(gdf, target_field, k=5):
"""
使用多数邻域方法填充分类数据空值
取最近 k 个已知点的众数作为填充值
"""
filled_gdf = gdf.copy()
known_mask = filled_gdf[target_field].notna()
unknown_mask = filled_gdf[target_field].isna()
if not known_mask.any() or not unknown_mask.any():
return filled_gdf
known_coords = np.array([(x, y) for x, y in filled_gdf[known_mask].geometry.centroid.coords])
unknown_coords = np.array([(x, y) for x, y in filled_gdf[unknown_mask].geometry.centroid.coords])
tree = cKDTree(known_coords)
distances, indices = tree.query(unknown_coords, k=min(k, known_mask.sum()))
known_values = filled_gdf[known_mask][target_field].values
filled_values = []
for idx in indices:
neighbor_vals = known_values[idx]
# 取众数
unique, counts = np.unique(neighbor_vals, return_counts=True)
filled_values.append(unique[np.argmax(counts)])
unknown_indices = filled_gdf[unknown_mask].index
filled_gdf.loc[unknown_indices, target_field] = filled_values
print(f"多数邻域填充完成:填充了 {len(filled_values)} 条记录,k={k}")
return filled_gdf
def main():
parser = argparse.ArgumentParser(description='QGIS 空间数据相邻值填充')
parser.add_argument('--input', required=True)
parser.add_argument('--output', required=True)
parser.add_argument('--field', required=True)
parser.add_argument('--method', default='nearest', choices=['nearest', 'majority'],
help='填充方法')
parser.add_argument('--k', type=int, default=5, help='邻域数量')
args = parser.parse_args()
gdf = gpd.read_file(args.input)
if args.method == 'nearest':
result = nearest_neighbor_fill(gdf, args.field, args.k)
else:
result = majority_neighbor_fill(gdf, args.field, args.k)
gdf_ext = args.output.lower().split('.')[-1]
if gdf_ext == 'shp':
result.to_file(args.output, driver='ESRI Shapefile')
elif gdf_ext == 'geojson':
result.to_file(args.output, driver='GeoJSON')
elif gdf_ext == 'gpkg':
result.to_file(args.output, driver='GPKG')
remaining = result[args.field].isnull().sum()
print(f"输出文件:{args.output},剩余空值:{remaining}")
if __name__ == '__main__':
main()4.4 相邻值填充的行业应用
| 行业 | 字段 | 填充方法 | 邻域数量 k | 说明 |
|---|---|---|---|---|
| 国土调查 | 地类编码 | majority | 5~9 | 相邻地块地类通常一致 |
| 生态 | 植被类型 | nearest | 3 | 相邻样地植被相似 |
| 水利 | 土壤类型 | majority | 5 | 相邻区域土壤有地带性 |
| 城建 | 建筑年代段 | majority | 3 | 同街区建筑年代相近 |
| 农业 | 作物类型 | nearest | 3 | 相邻农田作物一致 |
五、填充策略的选择原则
5.1 基于数据特征的策略选择
| 数据类型 | 空值比例 | 推荐策略 | 理由 |
|---|---|---|---|
| 分类数据,空值 < 5% | 少量 | 最近邻填充 | 保持分类一致性,不引入新类别 |
| 分类数据,空值 5%~30% | 中等 | Majority 填充 | 利用空间邻域信息,更稳健 |
| 分类数据,空值 > 30% | 大量 | 人工判读 + 众数 | 空值太多时自动填充风险高 |
| 连续数值,空值 < 10% | 少量 | IDW / 克里金插值 | 利用空间自相关性 |
| 连续数值,空值 10%~50% | 中等 | 克里金插值 + 误差估计 | 提供不确定性评估 |
| 连续数值,空值 > 50% | 大量 | 不建议自动填充 | 样本不足,填充结果不可靠 |
| 序列/剖面数据 | 任意 | 上行/下行填充 | 保持序列连续性 |
5.2 三种填充策略的综合对比
| 对比维度 | 默认值填充 | 插值填充 | 相邻值填充 |
|---|---|---|---|
| 操作复杂度 | ⭐ | ⭐⭐⭐ | ⭐⭐ |
| 空间一致性 | 差 | 好 | 好 |
| 统计合理性 | 中等 | 好 | 中等 |
| 适用数据类型 | 所有类型 | 连续数值 | 分类 + 有序数据 |
| 是否需要空间自相关 | 否 | 是 | 是 |
| 计算速度 | 快 | 慢 | 中等 |
| 结果可信度 | 低(可能引入偏差) | 高(有统计依据) | 中高(依赖邻域质量) |
5.3 填充策略的最佳实践流程
1. 空值识别与统计分析(参考第 026 篇)
↓
2. 判断空值比例
├─ < 1% → 直接删除(或删除法填充)
└─ ≥ 1% → 进入第 3 步
↓
3. 判断数据类型
├─ 分类数据 → 相邻值填充(最近邻 / Majority)
├─ 连续数值 → 插值填充(IDW / 克里金)
└─ 无空间自相关 → 默认值填充(均值 / 中位数 / 众数)
↓
4. 执行填充
↓
5. 质量验证(对比填充前后统计分布、空间分布)六、填充后质量验证
6.1 验证指标与方法
| 验证维度 | 验证方法 | 验证指标 | 合格标准 |
|---|---|---|---|
| 统计分布 | 填充前后直方图对比 | Kolmogorov-Smirnov 检验 | p > 0.05(分布无显著差异) |
| 空间分布 | 填充前后空间自相关对比 | Moran's I | 填充后 Moran's I 变化 < 10% |
| 交叉验证 | 留出法验证 | RMSE(均方根误差) | RMSE < 空值字段标准差的 0.5 |
| 业务规则 | 逻辑校验 | 业务规则命中次数 | 0 次冲突 |
6.2 Python 自动化验证脚本
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
QGIS 空间数据填充后质量验证脚本
"""
import argparse
import geopandas as gpd
import pandas as pd
import numpy as np
from scipy import stats
from pykrige.ok import OrdinaryKriging
import sys
def verify_fill_quality(original_gdf, filled_gdf, field, n_points=100):
"""
验证填充质量
参数:
original_gdf : GeoDataFrame
填充前的原始数据
filled_gdf : GeoDataFrame
填充后的数据
field : str
验证字段
n_points : int
留出验证点数
返回:
dict : 验证结果
"""
results = {}
# 1. 统计分布验证(K-S 检验)
known_original = original_gdf[field].dropna()
filled_values = filled_gdf.loc[original_gdf[field].isna(), field]
if len(filled_values) > 2 and len(known_original) > 2:
ks_stat, ks_p = stats.kstest(known_original, filled_values)
results['ks_stat'] = ks_stat
results['ks_p'] = ks_p
results['distribution_ok'] = ks_p > 0.05
# 2. 留出验证(将部分已知点视为空值,验证填充效果)
known_indices = original_gdf[field].dropna().index
if len(known_indices) >= 2 * n_points:
# 随机留出 n_points 个已知点
validate_indices = np.random.choice(known_indices, n_points, replace=False)
true_values = original_gdf.loc[validate_indices, field].values
# 模拟:将这些点设为空值
temp_gdf = original_gdf.copy()
temp_gdf.loc[validate_indices, field] = np.nan
# 用 IDW 填充
temp_gdf = idw_interpolation(temp_gdf, field, power=2, k_neighbors=10)
predicted_values = temp_gdf.loc[validate_indices, field].values
# 计算 RMSE
rmse = np.sqrt(np.mean((true_values - predicted_values) ** 2))
std_true = np.std(true_values)
results['rmse'] = rmse
results['rmse_ratio'] = rmse / std_true if std_true > 0 else float('inf')
results['validation_ok'] = rmse / std_true < 0.5 if std_true > 0 else False
# 3. 空间自相关验证
from statsmodels.sandbox.stats.multitest import multipletests
known_mask = original_gdf[field].notna()
if known_mask.sum() >= 10:
coords = np.array([(x, y) for x, y in original_gdf[known_mask].geometry.centroid.coords])
values = original_gdf.loc[known_mask, field].values
# 简单计算 Moran's I(使用空间权重矩阵)
# 这里简化为:只检查填充前后空间变异性变化
results['known_std'] = np.std(values)
results['filled_std'] = np.std(filled_values) if len(filled_values) > 1 else 0
results['std_change'] = abs(results['filled_std'] - results['known_std']) / results['known_std'] \
if results['known_std'] > 0 else float('inf')
results['spatial_ok'] = results['std_change'] < 0.2 # 标准差变化 < 20%
return results
# 使用示例
def main():
parser = argparse.ArgumentParser(description='填充后质量验证')
parser.add_argument('--original', required=True, help='原始文件')
parser.add_argument('--filled', required=True, help='填充后文件')
parser.add_argument('--field', required=True, help='验证字段')
args = parser.parse_args()
original_gdf = gpd.read_file(args.original)
filled_gdf = gpd.read_file(args.filled)
results = verify_fill_quality(original_gdf, filled_gdf, args.field)
print("=== 填充质量验证报告 ===")
print(f"字段:{args.field}")
print(f"K-S 检验统计量:{results.get('ks_stat', 'N/A'):.4f}")
print(f"K-S 检验 p 值:{results.get('ks_p', 'N/A'):.4f}")
print(f"分布无显著差异:{'✅ 是' if results.get('distribution_ok') else '❌ 否'}")
print(f"留出验证 RMSE:{results.get('rmse', 'N/A'):.4f}")
print(f"RMSE / 标准差:{results.get('rmse_ratio', 'N/A'):.4f}")
print(f"验证通过:{'✅ 是' if results.get('validation_ok') else '❌ 否'}")
print(f"标准差变化率:{results.get('std_change', 'N/A'):.4f}")
print(f"空间一致性:{'✅ 通过' if results.get('spatial_ok') else '⚠️ 需检查'}")
if __name__ == '__main__':
main()七、综合案例:某省国土变更调查数据空值填充
7.1 项目背景
某省第三次国土调查数据中,部分图斑的属性字段存在空值:
| 字段 | 总记录数 | 空值数 | 空值率 |
|---|---|---|---|
| 地类编码(GBDM) | 1,250,000 | 12,500 | 1.0% |
| 坡度等级(PDJD) | 1,250,000 | 45,000 | 3.6% |
| 土层厚度(TCDC) | 1,250,000 | 187,500 | 15.0% |
| 土壤有机质(YJYXZ) | 1,250,000 | 500,000 | 40.0% |
7.2 填充策略选择
| 字段 | 数据类型 | 空值率 | 策略 | 理由 |
|---|---|---|---|---|
| 地类编码 | 分类 | 1.0% | 最近邻填充(k=5) | 空值率低,相邻图斑地类通常一致 |
| 坡度等级 | 分类 | 3.6% | Majority 填充(k=7) | 中等空值率,利用邻域多数一致 |
| 土层厚度 | 连续数值 | 15.0% | IDW 插值(幂次=2,k=10) | 连续变量,空间自相关性强 |
| 土壤有机质 | 连续数值 | 40.0% | 不建议自动填充 | 空值率过高,需人工补测 |
7.3 填充流程
bash
# 第 1 步:地类编码 --- 最近邻填充
python neighbor_fill.py --input survey.shp --output filled_gbdm.shp \
--field GBDM --method nearest --k 5
# 第 2 步:坡度等级 --- Majority 填充
python neighbor_fill.py --input survey.shp --output filled_pdjd.shp \
--field PDJD --method majority --k 7
# 第 3 步:土层厚度 --- IDW 插值
python idw_fill.py --input survey.shp --output filled_tcdc.shp \
--field TCDC --power 2 --neighbors 10
# 第 4 步:质量验证
python verify_fill.py --original survey.shp --filled filled_combined.shp \
--field TCDC7.4 验证结果
| 字段 | K-S p 值 | RMSE / 标准差 | 标准差变化 | 验证结论 |
|---|---|---|---|---|
| 地类编码 | 0.127 | N/A | N/A | ✅ 分布无显著差异 |
| 坡度等级 | 0.083 | N/A | N/A | ✅ 分布无显著差异 |
| 土层厚度 | 0.215 | 0.342 | 8.5% | ✅ 通过验证 |
| 土壤有机质 | --- | --- | --- | ⚠️ 留空,人工补测 |
八、常见问题与最佳实践
8.1 填充策略选择常见问题
| 问题 | 原因 | 解决方案 | 最佳实践 |
|---|---|---|---|
| 填充后数据失去空间变异性 | 用了均值/常数填充 | 改用空间插值或相邻值填充 | 有空间信息的字段优先用空间方法 |
| 插值结果出现异常值 | 幂次设置过高或邻域过小 | 降低幂次或增大邻域 | IDW 幂次在 1~4 之间测试 |
| 分类字段填充后某类占比畸高 | 众数填充或邻域不均衡 | 改用 majority 填充或增大 k | 对于分类字段,k=5~9 最稳健 |
| 填充结果与实际业务规则冲突 | 填充未考虑业务逻辑 | 填充后做逻辑校验 | 例如:坡度 = 0 的地类编码不能是"建筑用地" |
| 插值计算太慢 | 数据量过大 | 先降采样,或分区块插值 | 超过 10 万要素建议分块处理 |
8.2 填充策略最佳实践总结
| 原则 | 说明 |
|---|---|
| 先分析后填充 | 必须先做空值统计分析(参考第 026 篇),再选择策略 |
| 空间优先 | 有空间信息的字段优先用空间方法(插值、相邻值),而非默认值 |
| 留出一部分验证 | 保留 20% 的已知数据不参与填充,用于验证填充质量 |
| 记录填充过程 | 记录填充方法、参数、填充量,确保可追溯 |
| 谨慎对待高比例空值 | 空值率 > 30% 时不建议自动填充,应人工补测或标注"数据缺失" |
九、总结
本节介绍了三种空值填充策略:
- 默认值填充:最简单,适用于无空间自相关的数据或空值率极低的场景
- 插值填充:最严谨,适用于连续型空间数据,利用空间自相关原理
- 相邻值填充:最实用,适用于分类数据和具有空间一致性的数据
核心原则:
- 填充方法的选择取决于数据类型 、空值比例 和空间自相关性
- 填充后必须进行质量验证,否则可能传播错误信息
- 对于高比例空值(> 30%),不建议自动填充,应人工补测或标注
下一节将深入探讨更高级的空值处理技术------基于机器学习的缺失值预测填充方法。