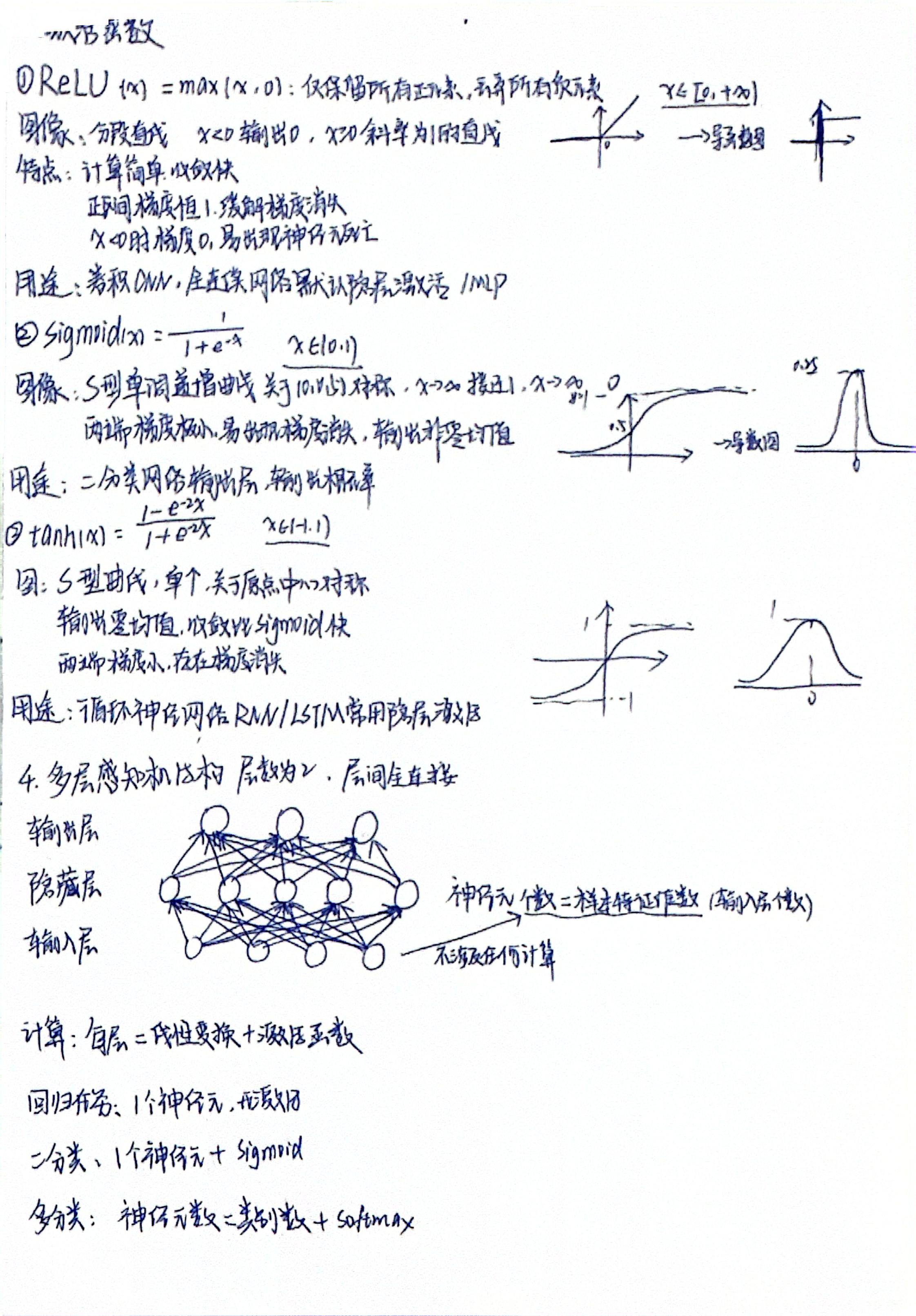
1. torch.ones
创建一个全1 的张量。
torch.ones(3, 4) → 3行4列,所有元素为1。
2. torch.zeros
创建一个全0 的张量。
torch.zeros(2, 5) → 2×5的零矩阵。
3. torch.rand
生成均匀分布 [0, 1)的随机张量。
torch.rand(2, 2) → 每个元素∈[0,1)。
4. torch.randn
生成标准正态分布 (均值0,方差1)的随机张量。
torch.randn(3) → 3个服从N(0,1)的随机数。
5. reshape
改变张量的形状(总元素数不变)。
x = torch.arange(6) # [0,1,2,3,4,5]
x = x.reshape(2, 3) # 2行3列-1可自动推断维度:reshape(2, -1)→ 2行,列自动算。
6. cat (concatenate)
沿指定维度拼接多个张量。
a = torch.ones(2,3)
b = torch.zeros(2,3)
c = torch.cat([a, b], dim=0) # 垂直拼接 → 4×3
c = torch.cat([a, b], dim=1) # 水平拼接 → 2×6要求:除拼接维度外,其他维度大小必须相同。
7. 广播机制 (Broadcasting)
当两个张量形状不同时,PyTorch自动扩展 较小张量,使它们形状兼容后再运算。
规则:
-
从尾部维度开始对齐。
-
某个维度大小为1,则扩展到与另一个相同。
-
缺失维度视为1。
例子:
a = torch.ones(3, 4) # 3×4
b = torch.ones(4) # 4 → 自动变为 1×4 → 广播为 3×4
c = a + b # 结果 3×4注意:若某个维度不为1且不相等,则报错。
8. 梯度 (Gradient)
在深度学习中,梯度是损失函数对模型参数的偏导数向量,指示参数调整的方向和大小。
-
PyTorch中,设置
requires_grad=True的张量会跟踪运算历史。(在反向传播时自动计算梯度,用于自动微分) -
调用
backward()自动计算梯度,累加到.grad属性。 -
用于优化器(如SGD)更新参数:
w = w - lr * w.grad。
x = torch.tensor(2.0, requires_grad=True)
y = x**2
y.backward()
print(x.grad) # 4.0 (因为 dy/dx = 2x)9. 梯度停止 (Stop Gradient)
阻止梯度继续反向传播,常用于:
-
冻结部分网络参数(如迁移学习中固定特征提取层)。
-
阻止梯度流(如GAN中停止判别器梯度传给生成器)。
方法:
-
detach():返回共享数据的新张量,与计算图脱离,不影响原张量。y = x.detach() # y 没有 requires_grad -
with torch.no_grad():上下文管理器:临时禁用梯度计算,内部所有操作不跟踪梯度(用于推理或更新时)。with torch.no_grad(): z = model(x) # 不会构建计算图 -
对参数设置
param.requires_grad = False:从到到尾不跟踪,不参与反向传播。
小总结表
| 操作/概念 | 作用 |
|---|---|
torch.ones / zeros |
创建全1/全0张量 |
torch.rand / randn |
均匀/正态随机张量 |
reshape |
改变形状,总元素不变 |
cat |
沿指定维拼接张量 |
| 广播机制 | 自动扩展形状不匹配的张量 |
| 梯度 | 损失对参数的偏导,指导更新 |
| 梯度停止 | 阻止梯度反向传播 |
1. 如何判断模型是否收敛
收敛指模型训练到某个阶段后,损失函数值不再明显下降,参数趋于稳定。常用判断方法:
-
观察损失曲线 :训练损失和验证损失都变得平坦(下降幅度小于设定的阈值,比如连续多个 epoch 下降 < 1e-4)。
-
验证集性能稳定:准确率、F1等指标不再提升,甚至轻微波动(注意排除过拟合)。
-
参数变化量:权重的更新幅度(梯度的范数)变得非常小(或不在更新)。
-
早停法 (Early Stopping) :验证损失在
patience轮内没有下降,则停止训练并认为已收敛。 -
自定义阈值:当损失小于某个预设值(如 0.01)时认定收敛。
注意:并非损失越低越好,需要结合验证集防止过拟合。有时损失会进入"局部极小"或"鞍点",可尝试降低学习率或调整优化器。
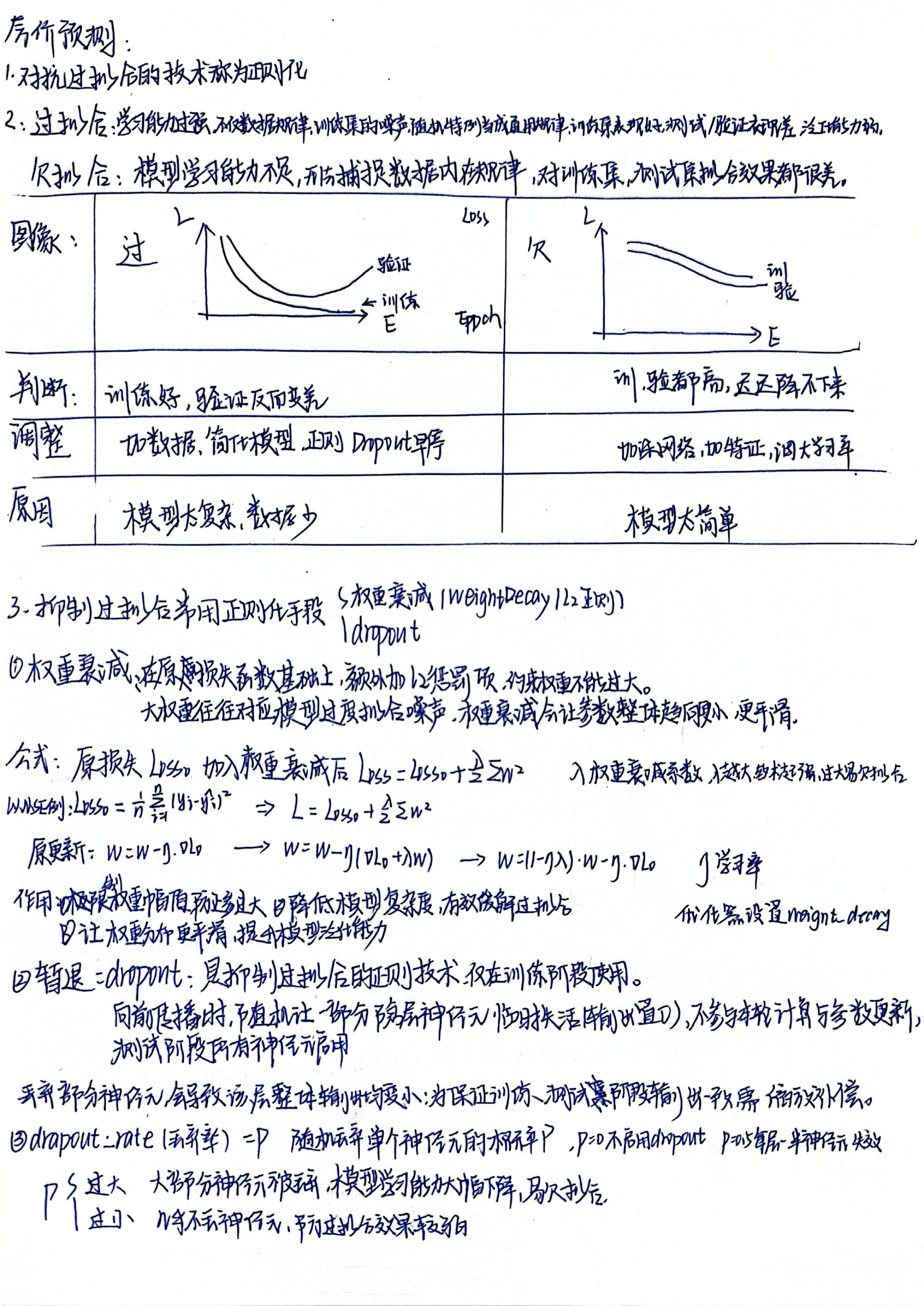
2. 欠拟合与过拟合
-
欠拟合:模型学习能力不足,无法捕捉真实规律,训练测试集效果差。
-
过拟合:模型过度学习,把训练集的噪声、特例当成规律,训练效果好,但测试效果差。
| 现象 | 欠拟合 (Underfitting) | 过拟合 (Overfitting) |
|---|---|---|
| 定义 | 模型太简单,无法捕捉数据规律 | 模型太复杂,记住了训练集噪声 |
| 训练损失 | 偏高(未充分拟合) | 很低(几乎为0) |
| 验证损失 | 同样偏高 | 明显高于训练损失(泛化差) |
| 原因 | 特征不足、模型层数太少、训练不足 | 参数过多、数据量少、无正则化 |
| 解决办法 | 增加模型复杂度、特征工程、增加训练轮数 | 增加数据、正则化(L1/L2)、Dropout、早停、减少网络宽度/深度 |
典型的学习曲线:
-
欠拟合:两条曲线都高且平坦。
-
过拟合:训练曲线下降极低,验证曲线先降后升("开口向上")。
3. 线性回归和 Softmax 的区别
| 对比维度 | 线性回归 (Linear Regression) | Softmax 回归 (常称多类逻辑回归) |
|---|---|---|
| 任务类型 | 回归(预测连续数值) | 分类(预测离散类别概率) |
| 输出 | 单个实数(可正可负) | 一个概率向量,和为1,每个元素∈0,1 |
| 激活/变换 | 无(或恒等映射) | Softmax 函数 |
| 损失函数 | 均方误差(MSE)常用 | 交叉熵损失(Cross-Entropy) |
| 典型例子 | 房价预测、温度预测 | 手写数字识别、图像分类 |
数学形式:
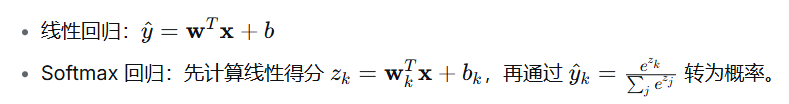
注意:Softmax 回归虽然名字里有"回归",但本质是分类模型。
4. 均方误差 (Mean Squared Error, MSE)
-
公式(对单个样本):
-
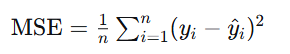
-
适用场景:回归问题(输出连续值)。
-
特点:衡量预测值与真实值之间的数字差距(均方误差),对异常值敏感。适用于需要惩罚较大误差的场景。
-
优点:凸函数(线性回归下全局最优),物理意义直观。
-
缺点:受异常值影响大;与评价指标(如 MAE)有时不一致。
-
代码:nn.MSELoss()
5. 交叉熵 (Cross-Entropy)
-

-
适用场景:分类问题(尤其配合 softmax)。
-
特点:衡量两个概率之间的分布差异。预测越准,交叉熵越小。
-
优点:
-
梯度形式简洁
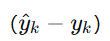 ,训练稳定。
,训练稳定。 -
惩罚错误的高置信度预测很重(log 特性)。
-
与 softmax 结合时,导数不会像 MSE+softmax 那样容易出现梯度饱和。
-
-
与 MSE 对比:分类任务用交叉熵通常比 MSE 收敛更快、效果更好。
-
代码:nn.CrossEntropyLoss()
快速记忆小贴士
| 问题 | 一句话答案 |
|---|---|
| 如何判断收敛 | 损失曲线平坦,验证性能不再提升。 |
| 欠拟合 vs 过拟合 | 欠拟合:训练/验证损失都高;过拟合:训练低、验证高。 |
| 线性回归 vs softmax | 回归(预测数值) vs 分类(输出概率分布)。 |
| 均方误差 | 回归损失,平方误差平均,对大误差敏感。 |
| 交叉熵 | 分类损失,度量分布差异,配合 softmax 使用。 |





1. 批次(Batch)
定义 :将整个训练集分成若干个小集合,每次用一个小集合的数据计算损失并更新参数。
-
批次大小(batch size):每个 batch 含有的样本数量。
-
迭代次数(iteration):一个 epoch 中,更新参数的次数 = 总样本数 / batch size(向上取整)。
三种常见模式
| 模式 | batch size | 特点 | 优缺点 |
|---|---|---|---|
| 随机梯度下降(SGD) | 1 | 每个样本更新一次 | 噪声大,收敛不稳定,但可跳出局部极小 |
| 小批量(Mini‑batch) | 通常 16~512 | 折中方案 | 最常用,稳定性与效率平衡 |
| 批量梯度下降(BGD) | 全部样本 | 准确计算全局梯度 | 内存大,更新慢,难用于大数据集 |
作用
-
决定每次参数更新使用的样本数量。
-
平衡计算效率与梯度估计的准确性。
2. 轮次(Epoch)
定义 :完整地遍历一次整个训练集。
-
1 epoch = 全部数据集样本都被送入模型一次(每个样本参与一次 forward + backward)。
-
通常训练多个 epoch,直到模型收敛。
作用
-
控制模型看到全部训练数据的次数。
-
决定训练的总计算量。
如何选择 epoch 数
-
太小:欠拟合。
-
太大:过拟合(训练太久,泛化变差)。
-
常用方法:早停(Early Stopping),监控验证损失,连续
patience个 epoch 不下降则停止。
3. 学习率(Learning Rate, LR)
定义:控制参数更新步长的超参数,通常记为 η 或 lr。(决定模型学习快慢,直接影响收敛速度与最终效果)
作用
-
控制参数沿着梯度反方向更新的步长。
-
是影响训练收敛性和速度最敏感的超参数。
学习率的影响
| 学习率 | 现象 | 后果 |
|---|---|---|
| 太大 | 损失剧烈震荡,甚至发散(NaN) | 无法收敛 |
| 太小 | 损失下降非常缓慢 | 训练时间过长,可能陷入局部极小 |
| 合适 | 损失平滑下降,收敛到较优解 | ✅ |
MLP(多层感知机) 结构原理
-
输入层:接收原始特征。
-
隐藏层:一个或多个全连接层,每层后通常接非线性激活函数(ReLU、Sigmoid、Tanh)。
-
输出层:根据任务类型决定激活函数(回归:无/线性;二分类:Sigmoid;多分类:Softmax)
-
shuffle=True:每个 epoch 开始前,随机打乱所有样本的顺序。 -
shuffle=False:按照数据集原来的顺序(或上次打乱后固定顺序)依次取 batch。





1. 权重衰减(Weight Decay)
定义
在损失函数中加入权重的 L2 范数惩罚项,使得优化目标变为:
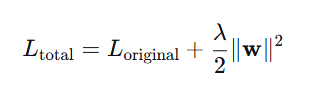
其中 λλ 是正则化强度(超参数)。
对应的参数更新公式(SGD):
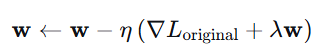
每次更新时,权重都会按比例 衰减 (乘以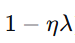 ),因此称为"权重衰减"。
),因此称为"权重衰减"。
作用
-
限制权重的绝对值过大,防止模型对某些特征过于敏感。
-
迫使权重尽可能小且分散,增强模型的平滑性 和鲁棒性。
-
有效降低过拟合,尤其是当样本量较少时。
2. 暂退法(Dropout)
定义
在训练过程中,以概率 p 随机将神经元的输出置为 0(即"丢弃"),被丢弃的神经元在前向和反向传播中暂时不参与计算。
-
常用丢弃概率:p=0.2∼0.5(隐藏层),输入层 p较小(如 0.1)。
-
测试时 不再丢弃,但需要将权重乘以 1−p以保持输出期望一致(或使用
training=False模式自动处理)。
作用
-
防止神经元间的共适应:迫使网络不依赖某些特定神经元,学习到更鲁棒的特征。
-
相当于训练多个子网络的集成(Bagging 思想),提升泛化能力。
-
对缓解过拟合非常有效,尤其在全连接层较多的网络中。


1. unsqueeze:增加维度
定义
在指定的位置插入一个大小为 1 的新维度。
-
语法:
torch.unsqueeze(input, dim)或tensor.unsqueeze(dim) -
参数
dim:新维度插入的位置(可以是负数,表示从尾部计数)。
作用
-
为张量增加一个"虚拟"的维度,便于进行广播(broadcasting) 或满足某些 API 的输入形状要求(如 Conv1d 要求输入为 3D:
(batch, channels, length))。 -
不改变数据本身,只改变视图(view),通常不消耗额外内存。
2. squeeze:删除维度
定义
删除所有大小为 1 的维度(或删除指定位置的大小为 1 的维度)。
-
语法:
torch.squeeze(input, dim=None)或tensor.squeeze(dim) -
dim=None:删除所有形状中大小为 1 的维度。 -
dim指定整数:只删除该位置上的维度(如果该维度大小不为 1,则操作无效,不报错)。
作用
-
去除冗余的单维度,使张量更紧凑,便于后续计算或显示。
-
常用于去除 batch 维度或通道维度中的
1。
数据增强(Data Augmentation) 是一种通过对原始训练数据进行随机变换 来生成更多样化训练样本 的技术,同时保持样本的标签语义不变。它是提升模型泛化能力、缓解过拟合最有效的方法之一,尤其在数据量有限时。
1. 定义
数据增强是在不改变数据真实标签的前提下,对输入样本施加一系列随机、合理的变换(如旋转、翻转、裁剪、加噪等),从而人工扩充训练数据集。
-
核心原则:变换后的样本在语义上仍属于原类别(例如:一张"猫"的图片经过水平翻转后还是一只"猫")。
-
随机性:每次训练 epoch 或每个 batch 都可能应用不同的随机变换,使模型看到"无限"多样的样本。
2. 作用
| 作用 | 具体说明 |
|---|---|
| 增加数据量 | 有效缓解小数据集导致的过拟合问题。 |
| 提高泛化能力 | 模型学习到对平移、旋转、光照等变化不变的特征,在测试集上表现更好。 |
| 增强鲁棒性 | 使模型对噪声、遮挡、变形等干扰更加健壮。 |
| 减少对特定特征的依赖 | 防止模型记住训练样本中的无关细节(如背景、角度)。 |
| 正则化效果 | 相当于引入了数据分布的"软性约束",与权重衰减、Dropout 互补。 |
一、卷积(Convolution)
1. 定义
卷积是使用一个可学习的 卷积核(filter / kernel) 在输入特征图上 滑动 ,在每个位置计算核与对应局部区域的 点积 ,生成输出特征图的操作(严格实现中通常为 互相关,但深度学习中直接称为卷积)。
2. 作用
-
局部特征提取:每个卷积核只关注局部区域,提取边缘、纹理、形状等低级或高级特征。
-
参数共享:同一卷积核在整个输入上滑动,大幅减少参数量(与全连接相比)。
-
稀疏连接:每个输出像素只与输入中局部区域相连,增强平移等变性。
-
堆叠卷积层 :浅层提取简单特征,深层组合成复杂语义。

二、池化(Pooling)
1. 定义
池化是一种 下采样 操作,在局部区域内用一个 统计量(最大值、平均值等)代替该区域,从而降低特征图的空间尺寸。
-
常用池化:最大池化(Max Pooling) 、平均池化(Average Pooling)。
2. 作用
-
降维:减少特征图尺寸,降低计算量和内存占用。
-
增强平移不变性:对微小位移不敏感,提高模型鲁棒性。
-
扩大感受野(后续解释):通过下采样,高层特征图的一个像素对应输入中更大的区域。
-
防止过拟合:减小参数量,并引入一定的局部抽象能力。
-
提取主要特征 :最大池化保留最强响应,平均池化保留整体信息。

三、感受野(Receptive Field)
1. 定义
感受野 是指卷积神经网络中 某一层的一个特征点 在 原始输入图像上所能看到的区域大小(像素范围)。
-
浅层特征感受野较小(看到局部细节)。
-
深层特征感受野较大(看到更大范围乃至全局)。
2. 作用
-
理解网络视野:决定网络能捕捉到多大范围的上下文信息。
-
指导网络设计:分类任务需要最终特征感受野覆盖整个目标;检测/分割需要适中感受野。
-
解释为什么深层能识别整体模式 :因为感受野随层数增加而扩大。


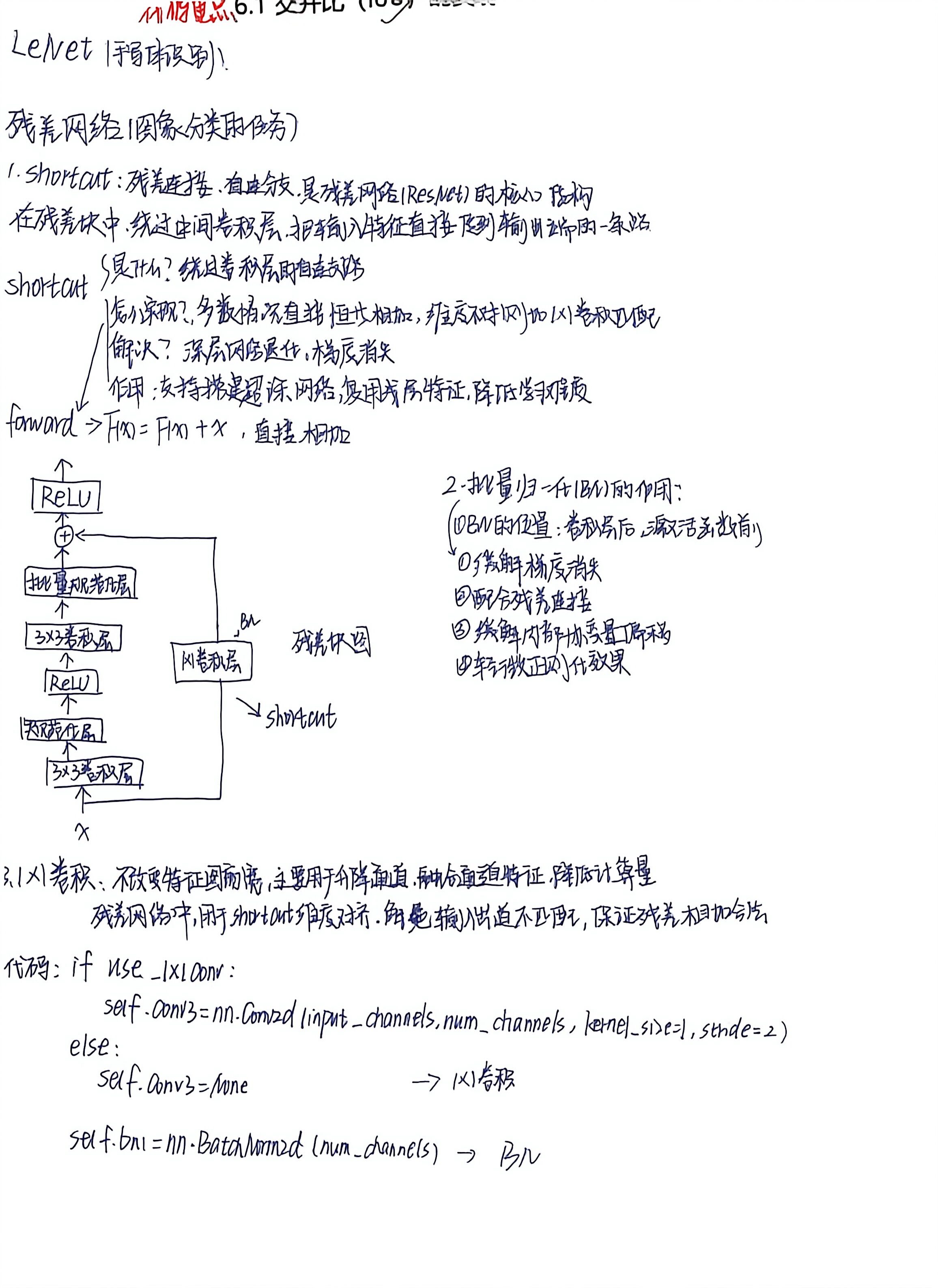
一、Shortcut(跳跃连接 / 恒等连接)
在深度学习中,Shortcut(跳跃连接 / 恒等连接) 最著名的应用是 残差网络(ResNet) 中的核心结构。
1. 定义
Shortcut 是指将网络某一层的输入(或其变换)直接 绕过一层或多层非线形变换 ,与后续层的输出 相加(或拼接) 后再进入下一层。
2. 作用
| 作用 | 详细说明 |
|---|---|
| 缓解梯度消失 | 反向传播时,梯度可以通过 shortcut 直接流向前层,避免经过多层非线性变换后梯度衰减。 |
| 让深层网络可训练 | 理论上网络可以做到上百甚至上千层(如 ResNet-1000)而不退化。 |
| 恒等映射学习目标简化 | 网络不再需要直接学习期望的底层映射 H(x),而是学习残差 F(x)=H(x)−x。当最优映射接近恒等时,残差更容易学习(趋近 0)。 |
| 改善信息流动 | 前向时,信息可以通过 shortcut 直达深层,避免因中间层变换而导致信息丢失。 |
| 集成多个子网络 | 相当于隐式地训练了多条路径的集成,提升泛化能力。 |
二、批量归一化(Batch Normalization,BN)
1. 定义
批量归一化是对一个 mini-batch 的数据在每个特征通道上 进行标准化 (使均值接近 0、方差接近 1),然后再进行可学习的缩放和平移。
2. 作用
-
加速收敛:允许使用更大的学习率,减少对权值初始化的敏感度。
-
缓解梯度消失/爆炸:使中间层输出保持在激活函数(如 Sigmoid、Tanh)的敏感区域(对 ReLU 也有帮助)。
-
正则化效果:每个 batch 的统计量引入噪声,轻微抑制过拟合(可适当降低 Dropout)。
-
允许更深网络:使深层网络训练更稳定,例如 ResNet 等上百层的网络。
-
简化参数初始化:网络对初始权重尺度不那么敏感。
三、1×1 卷积(1×1 Convolution)
1. 定义
卷积核尺寸为 1×11×1 的卷积操作。虽然只覆盖单个像素,但作用于所有输入通道 ,相当于在每个像素位置上对输入向量(长度为 CinCin)做一个线性变换,再加上偏置
2. 作用
| 作用 | 说明 |
|---|---|
| 通道降维/升维 | 灵活改变通道数,例如先降维减少计算量,再升维恢复。 |
| 跨通道信息融合 | 在不改变空间尺寸的前提下,混合不同通道的特征。 |
| 增加非线性 | 在 1×1 卷积后接非线性激活函数(如 ReLU),增强表达能力。 |
| 替代全连接层 | 在全局池化前使用 1×1 卷积可实现类似全连接的效果,同时保留空间结构。 |
| 构建瓶颈结构 | ResNet 的 bottleneck 块:1×1 (降维) → 3×3 → 1×1 (升维),大幅减少计算量。 |

一、迁移学习 (Transfer Learning)
定义
将一个任务上训练好的模型(通常在大规模数据集如 ImageNet 上预训练)作为起点,应用到另一个相关但不同的目标任务上。
作用
-
加速收敛:预训练模型已学到通用特征(边缘、纹理等)。
-
降低数据需求:在目标数据较少时防止过拟合。
-
提升性能:往往比从头训练效果更好。
常见策略
-
特征提取:冻结预训练模型的所有层,只训练新添加的分类层。
-
微调 (Fine‑tuning):解冻部分或全部层,用较小学习率继续训练。
二、微调 (Fine‑tuning)
定义
迁移学习的一种具体实现:在预训练模型的基础上,使用目标任务的数据集继续训练 模型的部分或全部参数,通常采用比初始训练更小的学习率。
作用
-
适应新领域:使模型学习到目标任务特有的特征。
-
提升精度:比固定特征提取能获得更高性能(尤其当目标数据足够多时)。
典型流程
-
加载预训练模型(如 ResNet50 在 ImageNet 上的权重)。
-
替换最后的全连接层(输出类别数改为新任务类别数)。
-
可选:先冻结所有层,只训练新头部若干 epoch(预热)。
-
解冻部分或全部层,使用小学习率(如 10−510−5 或 10−410−4)继续训练。
-
采用早停或验证集监控防止过拟合。
注意事项
-
目标数据集较小(如 <1000 张)时,建议只微调最后几层。
-
目标数据集较大且与预训练数据分布差异大时,可以微调更多层甚至全部层。
三、IOU (Intersection over Union)
定义
交并比:预测边界框与真实边界框的交集面积除以并集面积。
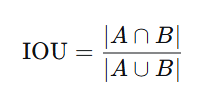
取值范围 0, 1,1 表示完全重合,0 表示无重叠。
作用
-
评估检测质量:判断预测框是否正确(如 IOU ≥ 0.5 视为正检)。
-
非极大值抑制中的相似度度量:根据 IOU 抑制冗余框。
-
损失函数:IOU Loss、GIoU Loss、CIoU Loss 等用于回归框的位置。
四、非极大值抑制 (Non‑Maximum Suppression, NMS)
定义
一种目标检测后处理算法,用于去除高度重叠的重复检测框,每个物体只保留置信度最高的一个框。
作用
-
消除冗余:模型常对同一目标输出多个相近候选框,NMS 筛选出最佳框。
-
提高检测质量:使输出结果清晰、不重叠。
算法步骤
-
将所有候选框按置信度降序排序。
-
选择最高置信度框,加入最终输出列表。
-
计算该框与其余框的 IOU,移除 IOU > 阈值(如 0.5)的框。
-
重复步骤 2‑3,直到没有剩余框。
五、mAP50
定义
在 IOU 阈值固定为 0.5 的条件下,计算所有类别的 平均精度 (AP) 后取平均,得到 mean Average Precision。
-
判定一个检测框是否正确:若预测框与真实框的 IOU ≥ 0.5 则为正检(TP),否则为误检(FP)。
-
然后针对每个类别绘制 Precision‑Recall 曲线,计算曲线下面积(AP)。
作用
-
评估模型在宽松定位要求下的检测性能(PASCAL VOC 标准指标)。
-
数值越高表示模型能够大致定位物体。
六、mAP50‑95 (或 mAP@0.5:0.05:0.95)
定义
在 多个 IOU 阈值 (从 0.5 到 0.95,步长 0.05,共 10 个阈值)上分别计算 mAP,然后对这 10 个值取平均值。
-
每个阈值下都计算一次 mAP(对 IOU 要求从宽松到严格)。
-
最终结果为 10 个 mAP 的均值。
作用
-
更严格的综合评价:同时衡量模型在低 IOU(大致定位)和高 IOU(精确定位)下的表现。
-
是 COCO 数据集官方主要指标,更能反映实际应用中对位置精度的需求。



致谢:本文的撰写与发布得到ZJ与DS的慷慨赞助,特此致谢。如有问题,欢迎私信或在评论区指出。