Agent 干了半小时活,为什么越来越慢?上下文管理机制拆解
你好,我是程序员无隅
个人主页: 无隅的主页
技术永无止境,希望我的内容能帮到你
热门专栏: Java 面试八股文 | Claude Code 源码解读

你用一个 Agent 编程工具跑稍微复杂的任务,比如重构一个模块。
Agent 先读十几个文件了解代码结构,然后改五六个文件,中间跑几次测试和编译。刚开始一切都很顺,但越到后面,你会发现两个现象越来越明显:
- 响应变慢了。
- Token 用量蹭蹭往上涨。
第一轮对话可能只用了 1000 多个 input tokens,到第二十轮可能已经飙到十几万。
这不是 Agent 突然变笨了,也不是模型"累了"。更底层的原因是:
一句话:Claude API 是无状态的,Agent 每一轮请求都要重新背着完整上下文去调用模型。
上下文管理要解决的核心问题也就一句话:
在有限的 Token 预算里,保留最有价值的信息,丢掉或者外移可以牺牲的信息。
这篇文章就从通用的 Agent 上下文管理机制出发,讲清楚一个生产级 Agent 为什么需要上下文压缩,以及"两层压缩 + 决策冻结"是怎么让长任务继续跑下去的。
一、先讲本质:为什么 Agent 会越跑越慢?
先退一步看 API 调用。
在普通 Web 后端里,一次请求处理完就结束,服务端可以把状态放在数据库、Redis 或内存里。下一次请求来了,再按需取状态。
但 Claude API 的聊天调用本身是无状态的。它不知道你上一轮说了什么,也不知道 Agent 上一轮读过哪些文件。每一轮请求,客户端都要把完整消息列表重新发过去。
所以 Agent 跑得越久,消息列表越长:
用户需求
+ Agent 的分析
+ 工具调用请求
+ 文件读取结果
+ 命令输出
+ 搜索结果
+ 测试日志
+ 后续对话这些内容会一轮一轮堆上去。
200K tokens 听起来很大,但在 Agent 场景下并不夸张。一个 1000 行左右的源文件可能就有 1 万多 token,读 10 个文件,再加上命令输出、搜索结果和模型回复,很容易逼近窗口上限。
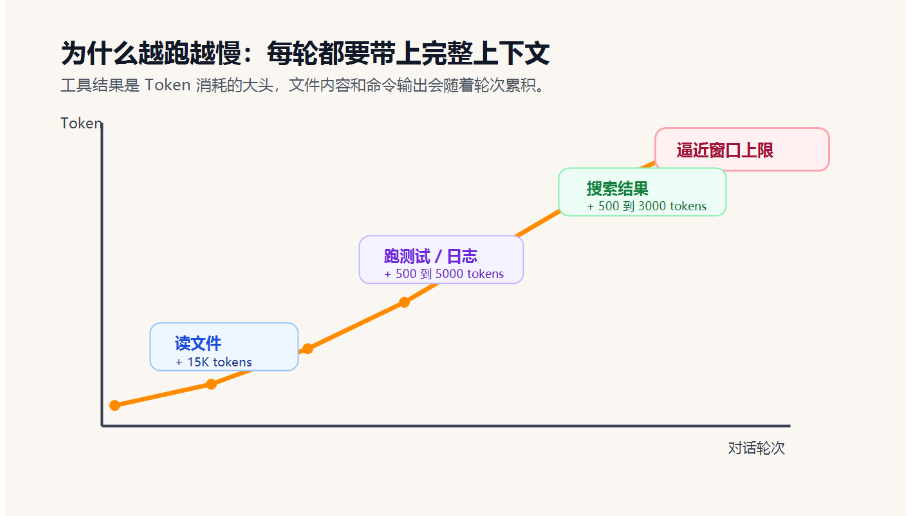
Token 主要花在哪里?
很多人第一反应会以为:Token 主要花在用户输入和 AI 回复上。
实际不是。
在 Agent 场景里,最大的消耗通常是工具结果,尤其是文件内容和命令输出。
| 消息类型 | 典型 Token 量 | 大致占比 |
|---|---|---|
| 固定开销:角色设定、环境信息、工具描述 | 5,000 - 15,000 | 约 10% |
| 用户输入 | 50 - 500 | 约 1% |
| AI 文字回复 | 200 - 2,000 | 约 3% |
| 工具调用请求 | 50 - 200 | 约 1% |
| 工具结果:文件内容 | 5,000 - 20,000 | 约 55% |
| 工具结果:命令输出 | 500 - 5,000 | 约 20% |
| 工具结果:搜索结果 | 500 - 3,000 | 约 10% |
可以看到,工具结果大概能占到 80% 以上。
更关键的是,很多工具结果的"保质期"很短。比如 Agent 第 3 轮读了 handler.py,第 5 轮又改了它。到了第 10 轮,第 3 轮那个旧版本的文件内容还占着 Token,但它对当前任务的价值已经下降了。
所以压缩上下文,最先要盯住的不是用户的话,而是工具结果。
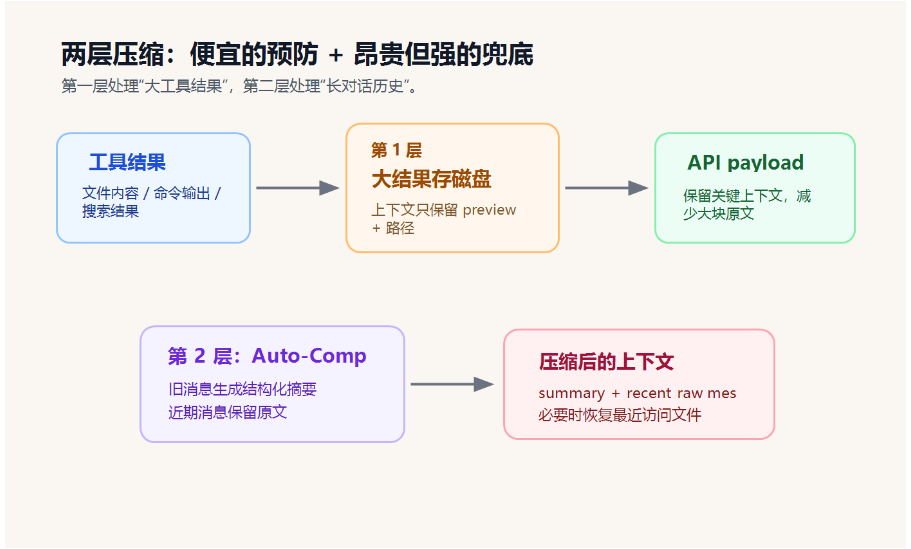
二、第一层压缩:大结果不要塞上下文,先存磁盘
第一层策略很朴素:
工具结果太大时,不把完整内容塞进对话历史,而是把原文写到磁盘,只在上下文里留下预览和文件路径。
这层解决的是"单次工具输出太大"的问题。
2.1 单个工具结果超限
假设一个工具结果超过 50,000 个字符,大约 12,500 tokens。成熟的 Agent 客户端不会把完整内容直接放进消息列表,而是做两件事:
- 把完整结果写到磁盘文件里。
- 在对话历史中只保留一段预览文本和文件路径。
模型看到的不是 50,000 字符的日志,而是类似这样的信息:
这段工具结果太长,完整内容已保存到某个本地文件。
如果后续需要完整内容,可以通过 ReadFile 重新读取。这一层几乎没有信息损失,因为完整内容并没有丢,只是从上下文窗口里搬到了磁盘。
从输入输出看,这一步很清楚:
- 输入:工具返回的原始结果。
- 输出:原文保留,或者"预览 + 文件路径"。
- 负责环节:发送 API 请求前的消息预算处理。
2.2 只限制单个结果还不够
如果只看单个工具结果,会漏掉一种情况。
一轮 Agent 循环里,模型可能并行调用多个工具。假设同一轮里有 5 个工具结果:
A = 42K 字符
B = 38K 字符
C = 45K 字符
D = 40K 字符
E = 44K 字符每一个都没超过 50K 的单条阈值,但它们会被放进同一条 user 消息里。加起来就是 209K 字符,已经超过单条消息的聚合预算。
所以还需要做"每条消息的聚合限制":当一条消息里的工具结果总量超过 200,000 字符时,就从里面挑最大的结果存盘,直到总量降下来。
这个例子里,C 是最大的 45K,于是 C 被存盘替换,A、B、D、E 保留原文。
2.3 为什么要幂等写入?
存盘还有一个细节:文件名使用 tool_use_id,并且采用"文件已存在就跳过"的写入方式。
原因很简单:每次调 API 前,系统都会重新走一遍消息预算处理。如果同一个工具结果每轮都重新写一次磁盘,既浪费 I/O,也可能破坏后面的 Prompt Cache 稳定性。
tool_use_id 是唯一的,工具结果内容也是确定的。写过一次就够了。
三、容易被忽视的一点:压缩不能破坏 Prompt Cache
第一层看起来只是"把大结果存到磁盘",但这里还有一个很容易忽略的坑:Prompt Cache。
Anthropic 的 Prompt Cache 依赖一个前提:本轮请求的消息前缀和上一轮请求的消息前缀必须逐字节一致。
如果前缀一致,API 可以复用前缀部分的处理结果,只处理新增消息。长会话里,这个优化非常关键。
问题来了:很多 Agent 客户端并不会修改原始 conversation.history。原始历史里保存的永远是工具返回的原文。每次发 API 前,系统都会临时遍历历史消息,把"是否替换成预览"的决策重新应用一遍,组装出真正发送给 API 的 payload。
如果每一轮都重新评估所有工具结果,就可能出现前缀漂移:
- 这一轮决定 C 要替换。
- 下一轮因为磁盘文件状态、排序、预览字符串生成方式等细节变化,结果略有不同。
- 消息前缀只要有一个字节不同,Prompt Cache 就失效。
Cache 一旦反复失效,模型每轮都要重新处理几万甚至十几万 tokens 的前缀,延迟和成本都会上去。
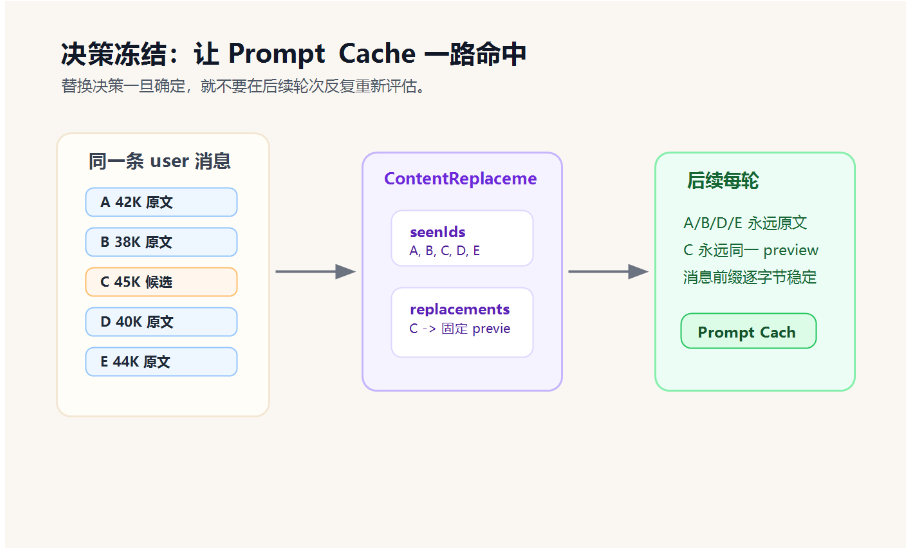
通用做法:决策冻结
系统维护一个 ContentReplacementState,记录每个 tool_use_id 的替换决策。
它本质上有两本账:
seenIds:这个工具结果已经评估过。replacements:这个工具结果需要被替换成哪一段预览文本。
规则很直接:
一旦某个工具结果被决定"不替换",后续整个会话都不再重新评估;一旦决定"替换",后续每轮都使用完全相同的预览字符串。
回到刚才 A、B、C、D、E 的例子。
第一次评估时,C 被替换成预览,A、B、D、E 保留原文。于是系统记账:
seenIds = A, B, C, D, E
replacements = C -> 固定 preview 字符串后面几轮再遇到这条老消息:
- A 命中
seenIds,但不在replacements,说明以前判断过,结论是不替换,直接跳过。 - C 命中
replacements,直接使用同一段 preview。 - B、D、E 同理。
这就是"决策冻结"的价值。
它不只是为了少算几次,而是为了保证发给 API 的消息前缀稳定。前缀稳定,Prompt Cache 才能持续命中。
很多自己做 Agent 的人会漏掉这个点:上下文管理不仅要考虑"保留什么信息",还要考虑"改动对话前缀的代价"。
四、第二层压缩:Auto-Compact 摘要旧消息,保留近期原文
第一层解决的是大工具结果,但它挡不住另一种情况:
Agent 连续读了 20 个小文件,每个文件都没超过 50K 字符阈值,所以第一层不触发。但几十轮对话累积下来,总 Token 仍然会逼近窗口上限。
这时就需要第二层:Auto-Compact。
它的核心思路是:
把较早的消息摘要掉,同时保留近期原文,让模型既不会撑爆窗口,又能看清最近发生了什么。
4.1 什么时候触发?
以 200K Token 的上下文窗口为例,可以预留两部分空间:
- 20K:留给摘要输出。
- 13K:自动压缩安全余量,防止两次检查之间突然新增大工具结果。
所以自动压缩阈值大概是:
200K - 20K - 13K = 167K也就是说,已用上下文接近 167K 时,就该触发 Auto-Compact 了。
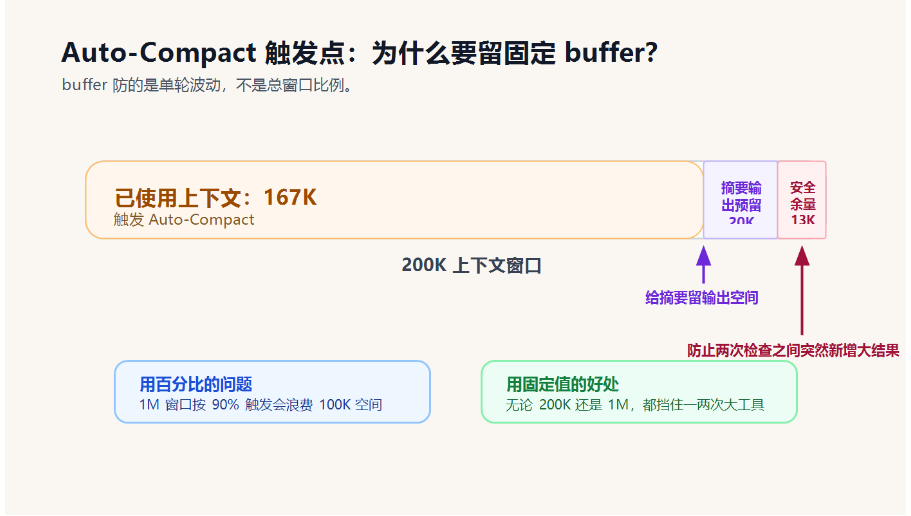
这里有个容易被问到的点:为什么是固定 buffer,而不是"用到 90% 就触发"?
原因是 buffer 防的是"单轮波动",不是总量。
一次 ReadFile 读大文件,不管你的总窗口是 200K 还是 1M,它新增的 token 量都差不多。风险来自"下一轮突然多一个大工具结果",而不是窗口总大小。
如果用百分比,200K 窗口下 90% 触发只剩 20K,刚好够一次大文件;但 1M 窗口下 90% 触发会剩 100K,白白浪费很多可用空间。
固定 buffer 更符合 Agent 的真实波动模型。
4.2 Token 估算不能一直靠字符数粗算
自动压缩要知道"当前用了多少 token"。如果每轮都靠字符数粗略估算,误差会随着历史变长不断累积。
更稳的做法是:
- 历史大部分 token 数,锚定上一次 API 返回的真实 usage。
- 只有上次 API 之后新增的那一小段消息,才用字符数做增量估算。
这样误差只集中在最新增量里,不会污染整段历史。13K 的安全余量也就足够兜住估算误差。
4.3 摘要不是把所有内容一刀切掉
Auto-Compact 不是把整段对话都压成一段摘要。
它会做两件事:
- 较早的消息生成结构化摘要。
- 最近一段原文保留下来。
近期原文很重要。
因为模型刚刚做了什么、刚刚改了哪些文件、刚刚跑了什么测试,这些信息如果只靠摘要,很容易丢细节。所以压缩逻辑会从尾部往回保留一段原始消息,比如最近 1 万 token,或者至少 5 条消息,并且不会从中间切断 tool_use 和 tool_result 的配对。
摘要则负责保留更早的上下文,比如:任务目标、用户要求、已经做过的关键操作、重要决策、错误与修复、后续待办等。
4.4 摘要 Prompt 也有工程设计
摘要质量直接决定压缩后 Agent 会不会"失忆"。
一个好的摘要 Prompt 至少要注意三件事。
第一,用户说过的话要尽量原文保留。
比如用户说:"不要用 interface{},用 any。"如果你摘要成"用户偏好现代语法",模型下一轮可能会误解。用户原话里包含意图、偏好和约束,不能随意改写。
第二,先让模型打草稿,再输出正式摘要。
可以让模型先产出一个 <analysis> 草稿块,梳理对话中发生了什么,然后再产出正式 <summary>。最终只保留 summary,analysis 作为中间产物丢掉。
这个设计有点像写文章先列提纲。它会多用一点输出空间,但能明显提高摘要质量。
第三,禁止摘要模型调用工具。
摘要调用的目标是生成纯文本摘要,不是继续执行任务。如果模型在摘要阶段"好心"调用工具,反而会浪费请求甚至打乱流程。
所以可以在摘要调用里不传 tools,或者在 Prompt 首尾明确强调:只输出纯文本,不要调用任何工具。
五、撞墙之后怎么办:紧急压缩和手动 /compact
自动压缩是预防,但预防不可能 100% 挡住所有情况。
比如某一轮工具结果异常巨大,或者 token 估算出现偏差,正常请求发出去后,API 返回了 prompt_too_long。
这说明上下文已经超过模型窗口硬限制。
如果没有兜底,Agent 就会直接报错停工,用户只能手动压缩再重试。
一种更稳的做法是在 Agent Loop 里捕获这个错误,然后立刻触发一次 ForceCompact:
正常请求 -> prompt_too_long
-> ForceCompact
-> 用压缩后的消息列表重试原请求这就是紧急压缩。
它和 Auto-Compact 的关系可以这样理解:
- Auto-Compact:撞墙前提前减速。
- ForceCompact:已经撞墙了,先救回来再继续。
为了防止死循环,系统还需要熔断机制。如果全量摘要因为网络、API 错误或 prompt-too-long 连续失败 3 次,就停止自动触发,让用户介入处理。
除了自动机制,用户也可以主动输入 /compact。
两个典型场景:
- 预防性压缩:你知道接下来要读一大堆文件,提前压缩腾空间。
- 话题切换:前面在修 bug A,现在要处理 bug B,压缩掉旧细节,减少噪声。
六、放回上下文管理链路里看:每轮 API 前到底做了什么?
把前面的机制串起来,每轮调用模型前,系统大致会走这样一条链路:
1. 读取原始 conversation.history
2. applyToolResultBudget 处理大工具结果
3. 使用 ContentReplacementState 冻结替换决策
4. autoCompact 判断整体上下文是否逼近窗口上限
5. buildAnthropicMessages 组装最终 API payload
6. 调 Claude API
7. 执行工具,产生新的 tool result
8. 进入下一轮循环这里要注意两个层级的职责边界。
第一层 applyToolResultBudget 管的是"单条消息里工具结果太大"。它更像预防性处理,优先把大结果从上下文搬到磁盘。
第二层 autoCompact 管的是"整个对话历史太长"。它会动用一次额外 LLM 调用,把早期上下文摘要掉。
这两个层级不是重复设计,而是处理不同维度的问题。
一个常见场景是:Agent 执行命令输出了 80K 字符日志。第一层直接把日志存盘,只留预览;整体上下文还没接近上限,所以第二层不触发。
另一个场景是:Agent 连续读了 20 个小文件,每个都没超过单条阈值。第一层什么都不做,但总 Token 数累积到 167K 附近,第二层触发,把早期历史压缩成摘要。
七、如何验证这个机制有没有生效?
如果自己实现类似机制,不要只看"能不能跑"。更应该看下面几个信号。
第一,看大工具结果有没有被外移。
当命令输出、文件内容超过阈值时,对话里应该只留下预览和可读取路径,而不是完整日志。
第二,看 Prompt Cache 是否稳定命中。
如果每轮都重新评估老工具结果,消息前缀可能反复变化。表现出来就是 cache 命中率很差,长会话越跑越贵、越跑越慢。
第三,看 Auto-Compact 后模型是否还知道当前任务状态。
压缩后模型应该知道:任务目标是什么,已经改了哪些关键点,用户有什么明确要求,下一步该做什么。它不一定记得所有旧细节,但不能丢掉主线。
第四,看 prompt-too-long 是否能自救。
当正常请求撞到窗口上限时,系统应该能触发一次紧急压缩并重试,而不是直接中断任务。
八、面试话术沉淀
问题 1:Agent 长任务为什么会越跑越慢?怎么优化?
【问题】
Agent 执行长任务时,上下文为什么会膨胀?如何做上下文管理?
【一句话】
因为 LLM API 本身无状态,每轮都要重新发送完整消息历史;优化的核心是把低价值或可恢复的信息移出上下文,再用摘要兜底长历史。
【关键词】
无状态 API、工具结果膨胀、上下文窗口、工具结果存盘、Auto-Compact、Prompt Cache。
【项目里怎么做】
这类 Agent 客户端可以做两层压缩。第一层在工具结果过大时把完整内容写到磁盘,只在上下文里保留预览和路径;第二层在总 Token 接近窗口上限时触发 Auto-Compact,把早期消息摘要掉,同时保留近期原文。为了保证 Prompt Cache 命中,还会冻结每个 tool_use_id 的替换决策,避免每轮消息前缀漂移。
【面试追问】
为什么不能每轮重新评估所有工具结果?为什么 Auto-Compact 要保留近期原文?为什么 buffer 更适合用固定值而不是百分比?
问题 2:为什么大工具结果存盘几乎没有信息损失?
【问题】
把工具结果从上下文里移出去,会不会导致模型丢信息?
【一句话】
不会直接丢,因为完整结果仍然保存在磁盘里,上下文里只是换成了一个可恢复的引用。
【关键词】
spill file、preview、ReadFile、信息外移、按需恢复。
【项目里怎么做】
当单个工具结果超过阈值,或者同一条消息里的多个工具结果合计超预算时,系统会把大结果写入本地文件,然后在消息里放入预览文本和路径。模型后续如果确实需要完整内容,可以再通过文件读取工具拿回来。
【面试追问】
文件名为什么适合用 tool_use_id?如果 spill 文件被删除了怎么办?为什么替换预览字符串要保持稳定?
九、本章小结
Agent 变慢的本质,不是模型能力下降,而是上下文越来越重。
Claude API 是无状态的,长任务里每一轮都要重新发送完整对话历史。真正吞 Token 的不是用户输入,而是文件内容、命令输出、搜索结果这些工具结果。
这套上下文管理可以总结成两层:
- 第一层:大结果存磁盘,解决单次工具输出过大的问题,几乎零信息损失。
- 第二层:Auto-Compact 摘要旧消息、保留近期原文,解决对话历史整体过长的问题。
中间最关键的工程细节是"决策冻结":不要每轮重新生成替换决策,否则消息前缀会漂移,Prompt Cache 很难命中。
对我们自己做 Agent 来说,这套设计有很强的参考价值:
先用低成本手段处理大工具结果,再用摘要机制兜底长对话;能轻则轻,必要时再动用昂贵压缩。
这也是 Agent 从"短任务工具"走向"长时间工作伙伴"必须补上的一课。