关键词:wxPython、通义千问 Qwen-VL、SQLite、PyInstaller、多线程、提示词工程
前言
我希望解决一个日常痛点:本地有几千张人物照片,想批量打上"性别 / 国籍 / 年龄 / 发型 / 衣着 / 化妆 / 动作 / 姿势 / 全身或半身"等结构化标签,方便日后筛选与检索。
借助阿里云百炼平台的 通义千问 Qwen-VL-Max 多模态大模型,再用 wxPython 写一个原生桌面 GUI,把识别结果落进本地 SQLite,配合多线程并发与配置持久化,就能做出一个"开箱即用"的本地化工具。
本文完整讲清楚这个项目的设计要点和踩坑过程,所有代码均可复用。
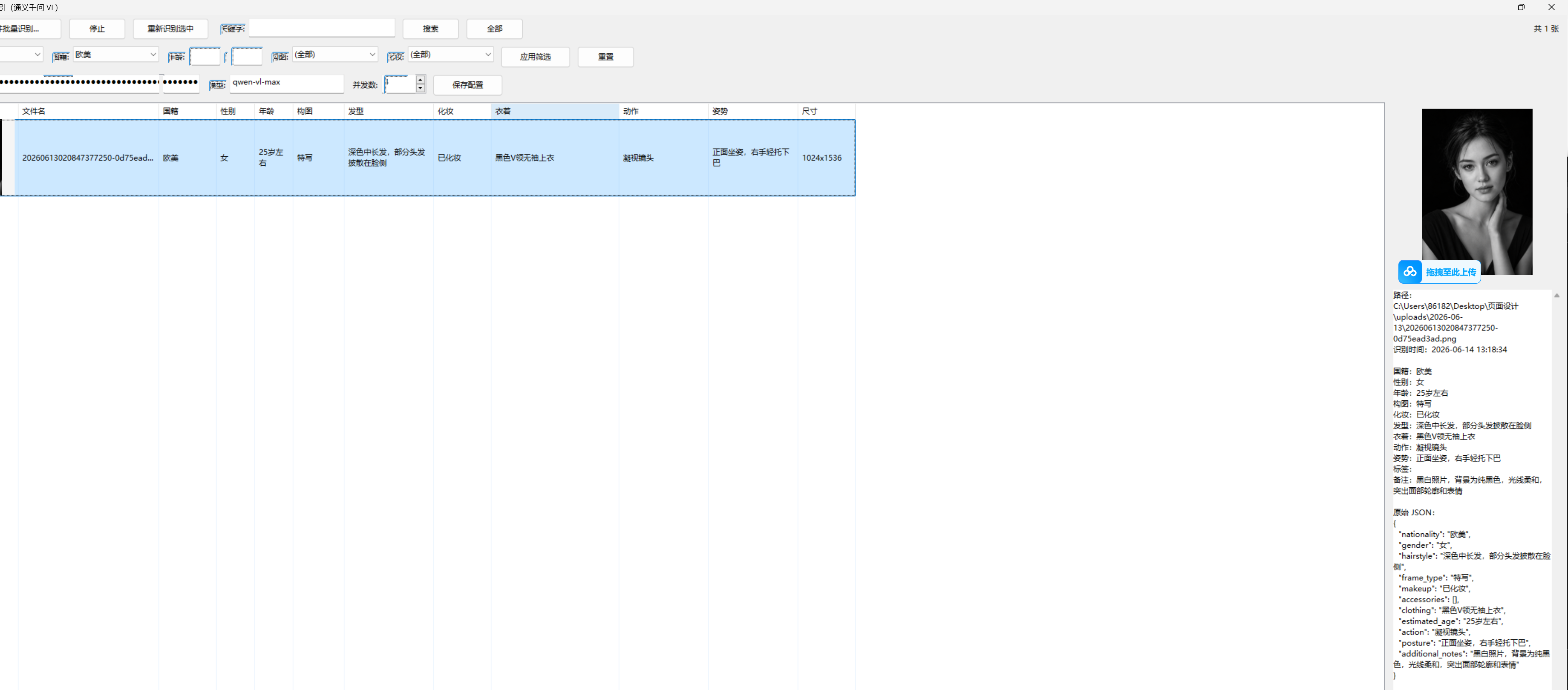
效果截图(功能区):
- 顶部:选择文件夹批量识别、停止、重新识别选中、关键字搜索
- 中部:性别 / 国籍 / 年龄区间 / 构图 / 化妆 等多维筛选
- 配置:API Key、模型名、并发数、保存配置
- 主区:左侧带缩略图的多列结果表,右侧大图预览 + 详细字段 + 原始 JSON
"C:\Users\86182\Desktop\qwenDetectImage\code.py"
一、技术选型
| 模块 | 选择 | 理由 |
|---|---|---|
| GUI | wxPython | 原生外观、跨平台、wx.ListCtrl 支持缩略图列、稳定可打包 |
| 多模态识别 | Qwen-VL-Max(OpenAI 兼容接口) | 国产、便宜、支持 base64 图片直传 |
| 存储 | SQLite | 单文件、零依赖、UNIQUE(path) 天然去重 |
| 并发 | concurrent.futures.ThreadPoolExecutor |
I/O 密集场景(API 调用)线程足够 |
| 打包 | PyInstaller | 一键生成 exe |
二、目录结构与"双形态路径定位"
工具要满足一个隐性需求:直接运行 .py 和打包成 exe 之后,配置文件 / 数据库都必须落在程序同目录 ,不能因为打包了就跑到 C:\Users\xxx\AppData\... 之类的奇怪地方。
只用一个小函数搞定:
python
def get_app_dir():
"""无论是直接运行 .py 还是 PyInstaller 打包后的 .exe,都定位到可执行文件同目录。"""
if getattr(sys, "frozen", False):
return Path(sys.executable).resolve().parent
return Path(__file__).resolve().parent
def get_config_path():
return get_app_dir() / "config.json"
def get_db_path():
return get_app_dir() / "photo_analysis.db"sys.frozen 是 PyInstaller 在运行期注入的属性,借此区分两种形态。配置和 DB 的路径全部从 get_app_dir() 派生,这样:
- 开发期:
code.py同级写读 - 发布期:
xxx.exe同级写读
用户只需把 exe + config.json + photo_analysis.db 整个目录拷走即可迁移。
三、SQLite 表结构与字段去重
所有识别结果落到一张 analyses 表:
python
CREATE TABLE IF NOT EXISTS analyses (
id INTEGER PRIMARY KEY AUTOINCREMENT,
path TEXT NOT NULL UNIQUE,
filename TEXT NOT NULL,
analyzed_at TEXT NOT NULL,
width INTEGER, height INTEGER,
nationality TEXT, gender TEXT, hairstyle TEXT,
frame_type TEXT, makeup TEXT, clothing TEXT,
estimated_age TEXT, action TEXT, posture TEXT,
top_labels TEXT, notes TEXT, raw_result TEXT
)两个细节:
path加UNIQUE:天然去重 + 配合INSERT ... ON CONFLICT(path) DO UPDATE做 upsert,重复识别不会留垃圾。raw_result留底:把模型返回的完整 JSON 序列化保存,万一某次解析失败、字段有变,仍可回填。
写入用 upsert:
python
con.execute("""
INSERT INTO analyses (path, filename, analyzed_at, ...) VALUES (?, ?, ?, ...)
ON CONFLICT(path) DO UPDATE SET
analyzed_at=excluded.analyzed_at,
nationality=excluded.nationality,
...
""", (...))自动迁移老表
迭代过程中字段调整过几次。为了避免老用户每次都手动删 DB,启动时做一次结构校验:
python
REQUIRED_COLUMNS = {"path", "filename", "analyzed_at", ...}
cols = {row[1] for row in con.execute("PRAGMA table_info(analyses)").fetchall()}
if not REQUIRED_COLUMNS.issubset(cols):
con.execute("DROP TABLE analyses")简单粗暴但够用------结构变了就重建。
四、调用 Qwen-VL:OpenAI 兼容接口 + base64
阿里云百炼提供了 OpenAI 兼容的 endpoint,因此可以直接复用 openai SDK,只换 base_url:
python
def image_to_data_url(image_path):
path = Path(image_path)
mime_type = {
".jpg": "image/jpeg", ".jpeg": "image/jpeg",
".png": "image/png", ".webp": "image/webp", ".bmp": "image/bmp",
}.get(path.suffix.lower(), "image/jpeg")
data = base64.b64encode(path.read_bytes()).decode("utf-8")
return f"data:{mime_type};base64,{data}"
def call_qwen_api(api_key, model, image_path, system_prompt, prompt_template):
from openai import OpenAI
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": image_to_data_url(image_path)}},
{"type": "text", "text": prompt_template},
]},
],
temperature=0.1,
)
raw = response.choices[0].message.content
result = extract_json_from_text(raw)
if not result:
raise ValueError(f"模型返回内容不是可解析 JSON:\n{raw}")
return sanitize_result(result)要点:
- 图片 base64 内嵌为 data URL,无需上传到 OSS。
temperature=0.1:识别任务追求稳定。- 返回内容需要从可能带 Markdown 围栏的文本里抠 JSON,单独写了
extract_json_from_text。
extract_json_from_text:三段式兜底解析
python
def extract_json_from_text(text):
candidates = [text.strip()]
fenced = re.search(r"```(?:json)?\s*(.*?)\s*```", text, re.DOTALL | re.IGNORECASE)
if fenced: candidates.append(fenced.group(1).strip())
obj = re.search(r"\{.*\}", text, re.DOTALL)
if obj: candidates.append(obj.group(0).strip())
for c in candidates:
try:
v = json.loads(c)
if isinstance(v, dict): return v
except json.JSONDecodeError:
continue
return None依次尝试:原文 → json围栏内容 → 第一个 {...} 块。能兼容 99% 的"模型不那么听话"的情况。
五、提示词工程:踩过的最大的坑
这是项目里最折腾的部分,值得单独讲。
翻车现场:所有图片返回完全相同的结果
第一版 prompt 我把字段说明写在 JSON 模板的"值"位置:
text
{
"nationality": "判断的国籍或地域,例如:中国、日本、韩国...",
"gender": "男 或 女",
...
}结果:模型把字段说明文字原封不动当作值返回。
第二版我加了"具体示例",比如:
text
{"nationality":"中国","gender":"女","hairstyle":"黑色长直发",...}结果更糟:三张完全不同的图片返回了完全相同的 JSON------模型直接把示例值当成"标准答案"了。
解决方案:System Prompt 描述结构 + User Prompt 极简触发
这是参考了一个能正常工作的版本后顿悟的:
python
DEFAULT_SYSTEM_PROMPT = """你是一个专业的人物图像特征分析专家。请仔细观察提供的照片,并提取人物的特征。
如果某个特征无法从照片中确认,请将其值设置为"未知"。如果照片中没有人物,请在 additional_notes 中说明。
请严格遵循以下 JSON 结构,不要输出任何 Markdown 标记...:
{
"nationality": "人物国籍或种族特征(如:中国、日本、韩国、欧美、东南亚、非洲,或未知)",
"gender": "性别(男、女、未知)",
"hairstyle": "发型描述(如:黑色长直发、棕色短卷发、马尾辫、寸头、未知)",
...
}"""
DEFAULT_PROMPT_TEMPLATE = "请分析这张照片中的人物,并输出 JSON 结果。"关键变化:
- 结构定义放进 system prompt------它对模型而言是"规则",不是"用户问题"。
- user prompt 退化为一句简单触发语------模型不会把它当作"用户已经给出的样例答案"。
- 字段说明用括号备注,不要写"具体如..."或"举例如...",避免模型抄说明。
防御层:sanitize_result 兜底
即便 prompt 调好,模型偶尔仍会泄漏说明文字。再加一层结果清洗:
python
LEAK_KEYWORDS = (
"字段含义", "候选词", "判断该人物的国籍",
"可搜索的中文标签", "0~1 的小数", "必须是整数", "字符串。",
)
def _clean_value(value, allowed=None):
text = str(value or "").strip()
if not text: return "未知"
if any(kw in text for kw in LEAK_KEYWORDS): return "未知"
if allowed is not None and text not in allowed:
for option in allowed:
if option != "未知" and option in text:
return option
return "未知"
return text
def sanitize_result(result):
cleaned = dict(result)
cleaned["gender"] = _clean_value(result.get("gender"), {"男", "女", "未知"})
cleaned["frame_type"] = _clean_value(result.get("frame_type"), {"全身", "半身", "特写", "未知"})
cleaned["makeup"] = _clean_value(result.get("makeup"), {"已化妆", "未化妆", "未知"})
...
return cleaned枚举字段做受控匹配(gender ∈ {男,女,未知}),文本字段做关键字泄漏检测,识别"中招"立刻置为未知。
Prompt 版本号
prompt 已经迭代了 5 版。为了让用户保留的旧 config.json 自动升级,我加了 PROMPT_VERSION:
python
PROMPT_VERSION = 5
# load_config 里:
if int(data.get("prompt_version", 0)) < PROMPT_VERSION:
config["system_prompt"] = DEFAULT_SYSTEM_PROMPT
config["prompt_template"] = DEFAULT_PROMPT_TEMPLATE
config["prompt_version"] = PROMPT_VERSION只要本地版本号低,就强制覆盖 prompt------避免老用户用着老 prompt 出错却完全摸不到头脑。
六、并发识别:跳过已识别 + ThreadPoolExecutor
批量识别如果串行调用,几百张照片要等几十分钟。但是直接 for img in images: call_api(img) 会浪费等待时间,因为单次 API RTT 通常 5--15 秒。
跳过已识别
python
def fetch_analyzed_paths(db_path):
with closing(sqlite3.connect(db_path)) as con:
rows = con.execute("SELECT path FROM analyses").fetchall()
return {row[0] for row in rows}worker 里先做差集,节约 token:
python
images = find_image_files(self.current_folder)
done_paths = fetch_analyzed_paths(self.db_path)
pending = [p for p in images if str(p) not in done_paths]多线程 + 增量回写 UI
API 调用是 I/O 等待,GIL 不构成瓶颈,用线程池足矣:
python
with ThreadPoolExecutor(max_workers=max_workers) as pool:
futures = {
pool.submit(self._process_one, img, api_key, model, sysp, userp): img
for img in pending
}
for future in as_completed(futures):
record = future.result()
wx.CallAfter(self._on_record_ready, record, done, len(pending))并发数由界面 wx.SpinCtrl 配置(1--16,默认 4)。
SQLite 写入加锁
SQLite 默认每个连接只能在一个线程使用,并发写还容易触发 database is locked。封装一把互斥锁:
python
self._db_lock = threading.Lock()
def _process_one(self, image_path, api_key, model, sysp, userp):
width, height = get_image_size(image_path)
result = call_qwen_api(api_key, model, image_path, sysp, userp)
with self._db_lock:
upsert_analysis(self.db_path, image_path, result, width, height)
record = fetch_analysis_by_path(self.db_path, image_path)
return recordAPI 调用并行,DB 写入串行,简单可靠。
边识别边显示
每一张完成都通过 wx.CallAfter 回到主线程,把单条记录追加进 wx.ListCtrl:
python
def _on_record_ready(self, record, done, total):
path = record.get("path")
existing = self._path_to_row.get(path)
if existing is not None:
self.all_records[existing] = record
else:
self.all_records.append(record)
self._path_to_row[path] = len(self.all_records) - 1
if record_matches_filters(record, self._collect_filters()):
idx = next((i for i,r in enumerate(self.visible_records)
if r.get("path") == path), -1)
if idx >= 0:
self._update_list_row(idx, record)
else:
self._append_record_to_list(record)
self.SetStatusText(f"已识别 {done}/{total}:{Path(path).name}")_path_to_row 这个 dict 用来 O(1) 判定路径是否已展示过------避免"重新识别选中"的图片在 UI 上重复出现。
七、UI 细节:缩略图列 + WebP 兼容
wx.ListCtrl 用缩略图
python
self.thumb_images = wx.ImageList(120, 120)
self.list = wx.ListCtrl(panel, style=wx.LC_REPORT | wx.BORDER_SUNKEN)
self.list.SetImageList(self.thumb_images, wx.IMAGE_LIST_SMALL)
for index, (name, width) in enumerate([
("缩略图", 130), ("文件名", 220), ("国籍", 90), ("性别", 60),
("年龄", 60), ("构图", 80), ("发型", 140), ("化妆", 90),
("衣着", 200), ("动作", 140), ("姿势", 140), ("尺寸", 90),
]):
self.list.InsertColumn(index, name, width=width)每行的第 0 列绑定一个 wx.ImageList 索引,列表自然就显示出缩略图。
WebP 加载兜底
wx.Image 默认不支持 webp。直接 wx.Image("xxx.webp") 在 Windows 下会弹错误对话框。处理思路:先用 wx 试,失败再用 Pillow,最后转回 wx.Image。
python
def load_wx_image(image_path):
no_log = wx.LogNull() # 抑制弹错框
try:
image = wx.Image(str(image_path), wx.BITMAP_TYPE_ANY)
except Exception:
image = None
del no_log
if image is not None and image.IsOk() and image.GetWidth() > 0:
return image
try:
from PIL import Image
with Image.open(str(image_path)) as pil_image:
pil_image = pil_image.convert("RGB")
wx_image = wx.Image(pil_image.width, pil_image.height)
wx_image.SetData(pil_image.tobytes())
return wx_image
except Exception:
return Nonewx.LogNull() 是 wx 的一个 RAII 风格的日志静默器,构造期间所有 wx 错误日志都不弹窗。
八、配置持久化:每次都保存
为了"操作简单",几乎所有可设置的字段都自动保存:
python
def _collect_config(self):
self.config.update({
"api_key": self.txt_api_key.GetValue().strip(),
"model": self.txt_model.GetValue().strip() or "qwen-vl-max",
"max_workers": int(self.spin_workers.GetValue()),
"last_dir": self.current_folder,
"window_size": list(self.GetSize()),
"window_pos": list(self.GetPosition()),
"system_prompt": self.config.get("system_prompt", DEFAULT_SYSTEM_PROMPT),
"prompt_template":self.config.get("prompt_template", DEFAULT_PROMPT_TEMPLATE),
"prompt_version": PROMPT_VERSION,
"filters": self._collect_filters(),
})
return self.config触发时机:
- 切换文件夹 / 应用筛选 / 关闭窗口 / 显式点"保存配置"
加载时合并默认值,避免新增字段时老配置文件缺 key 报错:
python
filters = DEFAULT_CONFIG["filters"].copy()
filters.update(data.get("filters", {}) or {})
config.update(data)
config["filters"] = filters九、常见踩坑回顾
| 问题 | 原因 | 解决 |
|---|---|---|
| 所有结果都是 "未知" | 旧 prompt 强调"无法确认填未知",模型偷懒 | 改 prompt 让模型基于视觉证据合理推测 |
| 三张不同图返回完全一样的 JSON | 把示例 JSON 写进了 user prompt | system prompt 描述结构,user prompt 只触发 |
| webp 弹错框 | wx 默认不支持 | Pillow 兜底 + wx.LogNull |
no such column: path |
老表结构不兼容 | 启动时做 PRAGMA table_info 校验,结构不符就 DROP 重建 |
| 选了文件夹"瞬间完成识别" | API Key 为空,每张都立即抛错 | 前置校验,无 Key 直接弹窗中止 |
| 编辑文件后中文乱码 | 重新写 config.json 时用了系统默认编码 |
全程 encoding="utf-8" + ensure_ascii=False |
十、PyInstaller 打包
bash
pip install pyinstaller pillow openai wxpython
pyinstaller --onefile --windowed --name qwenDetectImage code.py参数解释:
--onefile:单文件 exe--windowed:不弹黑色控制台--name:自定义生成名
生成的 dist/qwenDetectImage.exe 直接拷到任意目录,跟 config.json 和 photo_analysis.db 放一起就能用。get_app_dir() 会自动定位到 exe 所在目录。
十一、可改进方向
- 识别失败重试:现在失败就跳过,可加入指数退避重试。
- 批量重识别:多选一组列表项 → 清空 DB 行 → 走识别流程;当前已有"重新识别选中"按钮。
- 导出 Excel/CSV:方便给非技术同事用。
- 本地小模型蒸馏:高频字段(性别、构图)可以用 ResNet 之类做本地预过滤,云调用只跑细字段。
- 图片去重哈希:用 phash 防止两张视觉相同但路径不同的图被重复调用。
十二、完整代码结构速览
qwenDetectImage/
├─ code.py # 单文件实现,约 900 行
├─ config.json # 自动生成的用户配置
├─ photo_analysis.db # SQLite 库
└─ dist/qwenDetectImage.exe # PyInstaller 输出模块拓扑:
[wx.Frame: IndexerFrame]
├─ load_config / save_config (JSON)
├─ init_database / upsert_analysis (SQLite)
├─ ThreadPoolExecutor (并发)
│ └─ call_qwen_api (OpenAI 兼容)
│ ├─ image_to_data_url
│ ├─ extract_json_from_text
│ └─ sanitize_result
└─ wx.ListCtrl + wx.ImageList (缩略图列表)结语
这个工具最初只是"想给本地照片打标",最终变成了一次很好的提示词工程实践------你会反复看到大模型把示例当作答案、把字段说明当作值。Prompt 的位置(system vs user)、措辞(描述 vs 命令)、是否含示例值,都会显著改变模型行为 。再加上一层结果清洗(sanitize_result),能把鲁棒性提升一大截。
如果你也在做"大模型 + 本地数据"的桌面/工具型应用,希望本文中关于 路径定位、配置自治、SQLite 兜底迁移、wx + 多线程增量渲染、prompt 防泄漏 的经验对你有用。
完整代码已开源(如读者需要可在评论区索取仓库链接),欢迎 fork 与改造。
作者一句话:
模型不会读心,它只会读你写下的字。Prompt 写不好,再贵的模型也救不了你。