目录
[一、Diffusion 留下的问题](#一、Diffusion 留下的问题)
[二、Flow Matching 的核心](#二、Flow Matching 的核心)
[三、数学框架:流、向量场与 ODE](#三、数学框架:流、向量场与 ODE)
[3.1 流(Flow)](#3.1 流(Flow))
[3.2 向量场(Vector Field)](#3.2 向量场(Vector Field))
[3.3 与 Diffusion 的关键区别](#3.3 与 Diffusion 的关键区别)
[四、Conditional Flow Matching:让训练变得简单](#四、Conditional Flow Matching:让训练变得简单)
[4.1 线性插值路径](#4.1 线性插值路径)
[4.2 目标向量场:两个公式](#4.2 目标向量场:两个公式)
[6.1 Eluer 方法](#6.1 Eluer 方法)
[6.2 Midpoint 方法(更常用)](#6.2 Midpoint 方法(更常用))
[6.3 与 Diffusion 对比为什么步数更少](#6.3 与 Diffusion 对比为什么步数更少)
本文介绍 Flow Matching 的核心原理,并说明其适合用来建模连续动作分布的原因,以及它是如何衔接到以 为代表的一类 VLA 动作生成头中的。
一、Diffusion 留下的问题
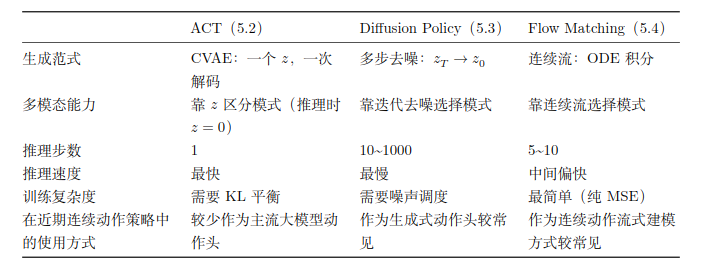
ACT 用 CVAE 实现了用一个隐变量 编码动作模式,一次解码出 action chunk;Diffusion Policy 用一串隐变量
逐步去噪,多模态建模能力更强。但是Diffusion 有一个明显的缺点:推理速度慢。
|--------------------------|--------------|-----------------------------------------|
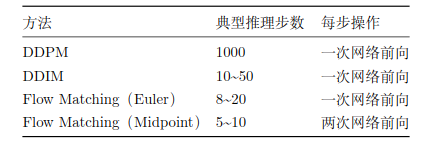
| 方法 | 推理步数 | 推理方式 |
| ACT(CVAE) | 1 步 | 采样 ,一次解码 |
| Diffusion Policy(DDPM) | 10 ~ 1000 步 | 从噪声逐步去噪 |
| Diffusion Policy(DDIM加速) | ~ 10 步 | 跳步去噪 |
即使用 DDIM 加速,diffusion 仍需多步迭代,在实际机器人控制中,每一步都要跑一次完整的神经网络前向传播,非常耗时。Diffusion 需要多步的一个重要原因,为 Diffusion 的前向过程带有随机性,导致常见采样轨迹更像是逐步修正、逐步去噪的过程;步数过少时,离散化误差和建模误差很难收敛。
二、Flow Matching 的核心
Flow Matching 的方法很直接,不走弯路,直接学一个向量场,把简单分布沿直线推到目标分布。
举一个物理类比:
Diffusion 像是墨水滴入水中(扩散),然后试图逆转这个随机过程--路径弯弯曲曲,需要很多步才能走回来;
Flow Matching 像是给每个粒子指定一个速度方向,让它们沿着一条规则的连续路径从起点流到终点。在常见的线性插值设定下,这条路径会更直观,也更容易高效求解。
更具体地说:
1)起点 :从一个简单分布(如标准正态 采样一个点
。
2)终点 :数据分布中的一个真实样本 。
3)学习目标 :学一个向量场 ,告诉每个点在每个时刻应该往哪个方向、以多大速度移动。
4)生成过程 :从 出发,沿着向量场积分到 t=1,得到生成结果。
噪声 ,沿
积分,得到生成的数据
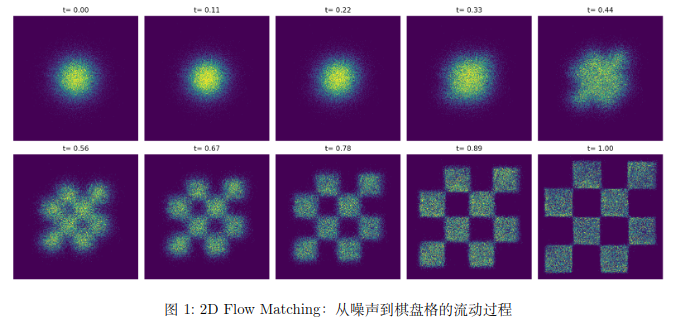
下图展示了一个 2D 棋盘格数据集上的 Flow Matching 过程。从 t=0 的标准正态噪声出发,分布沿着学到的向量场逐步流动,最终在t=1时形成清晰的棋盘格结构:
三、数学框架:流、向量场与 ODE
3.1 流(Flow)
Flow Matching 的核心数学对象是一个流 ,它描述了样本随时间的运动轨迹:
(初始位置为带随机噪声的样本)
是最终生成的样本
流把 t=0 时刻的分布 (简单分布)连续变换到 t=1 时刻的分布
(数据分布)。
3.2 向量场(Vector Field)
流的运动由一个向量场 驱动,向量场告诉每个点在每个时刻的速度:
这是一个常微分方程(ODE),给定初始条件 ,沿着向量场积分就能得到完整的轨迹。
|------------------------------------------|------------------------------------------------|
| 符号 | 含义 |
| | 从初始点 z 出发,在时刻 t 的位置 |
| | 在时刻 t 、位置 x 处的速度向量 |
| | 初始分布(通常是
) |
| | 目标数据分布 |
3.3 与 Diffusion 的关键区别
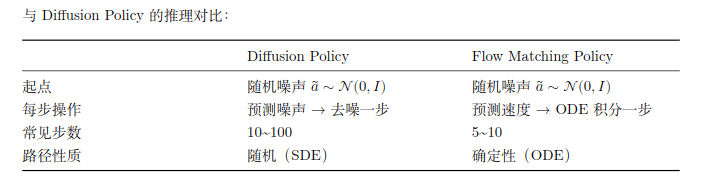
Diffusion 的生成过程本质上是一个随机微分方程(SDE)--- 每一步都有随机噪声;
Flow Matching 的生成过程是一个常微分方程(ODE)--- 完全确定的、没有随机项。
SDE:有随机项dW, ODE:纯确定性。
确定性路径意味着:采样可以被表述成标准 ODE积分问题。在很多常见设定下,这会带来更平滑、更可预测的采样过程,并允许用较少的积分步数得到可用结果
四、Conditional Flow Matching:让训练变得简单
直接学习一个能把整个 po 变换到 p,的全局向量场是困难的。一个关键简化是: Conditional FlowMatching(CFM)。
核心思想: 不直接在难以显式写出的全局向量场上训练,而是在更容易构造的条件概率路径上定义一个条件向量场。假设条件概率路径符合线性插值,则可以把一对端点样本 () 看成这条条件路径的条件信息。
想象你站在某个中间位置 ,想知道该往哪走。全局向量场
很难直接写出来,但如果我们额外知道这条条件路径由哪对端点
生成,那么对应的条件向量场
就会简单得多。在线性插值情形下,甚至就是一个常向量。更进一步,边际向量场可以理解为对这些条件向量场做适当平均后的结果。这样一来,训练就可以转化为回归一个显式、便宜、易采样的条件目标,而不必直接回归难以获得的全局目标。
4.1 线性插值路径
CFM最常用的选择是线性插值(也叫Optimal Transport 路径):
|-------------------------------------|-----------------------------------------------------------|
| 符号 | 含义 |
| | 从先验分布采样的噪声,
|
| | 从数据集采样的真实样本,
|
| | 时刻 t 的差值点,
|
这条路径的含义非常直观:在 t=0 时是纯噪声,在 t=1 时是真实数据,中间是两者的线性混合。下图展示了 1D 情况下的线性插值路径。每条线连接一个噪声点 (左侧)和一个数据点
(右侧),中间的
就是两者的线性混合:

4.2 目标向量场:两个公式
沿着线性插值路径,每个点的速度实常数:
此为神经网络学习的目标向量场:在时刻 t 、位置 处,速度应该是
。
整个 Flow Matching 的核心思想,其实就是两个公式:
第一个公式定义了从噪声到数据的路径(线性插值),第二个公式是这条路径的导数(速度)。神经网络要学的就是这个速度--一个从 指向
的向量。给定当前位置
,模型预测"往哪走、走多快",就能把噪声推向数据。
与 Diffusion 对比:
|------|----------------------------------------------------------------------------------------------------|------------------------------------------------------------|
| | Diffusion(预测噪声) | Flow Matching(预测速度) |
| 差值方式 | (非线性) |
(线性) |
| 学习目标 | 预测加入的噪声 | 预测速度
|
| 路径形状 | 弯曲(受噪声调度影响) | 笔直(线性插值) |
线性路径:是很多 Flow Matching 实现高效的一个重要原因。在常见设定下,更规则的概率路径通常更容易用较少步数进行数值积分。
五、训练目标
训练过程用一句话概括:随机选一个时刻 t,在噪声和数据之间做线性插值得到 ,让网络预测从噪声指向数据的速度。
与 Difusion 训练的对比:

六、采样推理过程
训练好后,生成新样本的过程是求解一个 ODE :
从 t=0 (噪声) 积分到 t=1 (数据) ,得到生成结果。
实际中用数值 ODE 求解器(如 Euler 或 Midpoint 方法)来离散化该过程。
6.1 Eluer 方法
最简单的数值积分:
把 0,1 分成 N 步,步长 ,逐步积分。
6.2 Midpoint 方法(更常用)
先走半步估计中点速度,再用中点速度走完整步:
Midpoint 方法每步需要两次网络前向推理,但精度更高,总步数可以更少。
6.3 与 Diffusion 对比为什么步数更少
关键在于概率路径和采样过程的复杂度。在线性插值等常见设定下,路径更规则,ODE 求解器往往可以用更少步数获得可用结果。
而在 diusion 的常见采样流程里,逐步修正的过程通常对步数更敏感,粗步长更容易带来明显质量损失,因此往往需要更多步来保证精度。
七:路线演进总结
整体技术发展路线如下所示:
ACT(CVAE)-----> Diffusion Policy ------> Flow Matching -----> 等连续动作 VLA
每一代方法,都在解决上一代的核心瓶颈:
1)ACT 解决了朴素 BC 的多模态问题,但推理时放弃了多模态采样(≈=0)。
2)Difusion Policy 恢复了真正的多模态采样,但推理太慢。
3)Flow Matching 保持了多模态能力,并在很多常见设定下减少了推理步数。
这条演进线最终汇入 VLA:连续动作生成不再只停留在单步回归,而是逐步走向更强的分布建模。Flow Matching 是其中一种很自然的落点,因为它既保留了生成式动作建模的表达力,又更容易把采样过程写成少步数的 ODE 积分。以 为代表的一类系统,就把这种思路和视觉-语言 backbone 结合在了一起。