第1章 大语言模型简介
QI:仅编码器(BERT类)、仅解码器(GPT类)和完整的编码器-解码器架构各有什么优缺点?
面试速记:
仅编码器(BERT 类) :擅长理解、特征提取、分类,双向语义建模强;不适合长文本生成,无法自回归输出连贯内容。
仅解码器(GPT 类) :主打自回归生成,上下文连贯、推理能力突出;单向感知,理解类任务弱,长序列易出现位置偏差。
编码器 - 解码器架构 :兼顾理解 + 生成,适配跨序列任务;结构复杂、参数量与算力开销大,推理延迟更高。
详解:
一、先搞懂核心前提:Transformer 两大基础组件
先分清 ** 编码器(Encoder)和解码器(Decoder)** 各自的 "本职工作":
- 编码器 :只做「读文本、理解意思」,能同时看整段文字的前面 + 后面(双向阅读)。 就像是做阅读理解的学生,读一句话时,前后内容一起参考。
- 解码器 :只做「接着往下写文字」,只能看已经写好的前文,看不到后面内容(单向续写)。 就像写作文的人,动笔时只能参考前面写的内容,还没写出的文字自然看不到。
基于这两个组件,就分出三种架构:只用编码器、只用解码器、编码器 + 解码器组合。
二、第一种:仅编码器 代表:BERT (bidirectional encoder representations from Transformers, 基于Transformer 的双向编码器表示)
1. 工作模式
全程只有「阅读理解模块」,不会写字、不会续写。
举个例子:
句子:这只小狗很可爱
模型读这句话时,每个字都能看到左右所有字:读「小狗」,能同时看前面「这只」、后面「很可爱」,完整理解整句话含义。
2. 优点
- 理解能力最强
前后文一起看,抓语义、情绪、语法、指代最准。比如判断评论是好评还是差评、识别句子里的人名地名,它最擅长。
- 干活速度快
整段文字可以一次性全部读完处理,不用一个字慢慢抠,适合高并发的线上服务。
3. 缺点
完全不会主动写新内容。
你让它 "接着这句话往下写""帮我写文案""陪你聊天",它做不到。它天生只是 "阅读理解工具",不是 "写作工具"。
4. 适用场景
只做文字理解类工作:情感分析、文本分类、人名 / 地名识别、文章聚类、语义检索。
三、第二种:仅解码器(代表:GPT、LLaMA、ChatGLM)
1. 工作模式
全程只有「写作续写模块」,主打写字、对话、创作,只能看前文,看不到后文。
举个例子:
你输入:今天天气很好
模型开始逐字续写:
第一步看「今天天气很好」→ 写下「我打算出门」
第二步看「今天天气很好 我打算出门」→ 写下「去公园散步」
......
每写一个字,都只能参考已经写好的内容,看不到还没写的部分。
2. 优点
- 天生擅长写内容 聊天、写文章、写代码、续写句子、回答问题全都拿手,这就是现在主流聊天大模型的架构。
- 功能全能 虽然只能单向看前文,但依靠海量数据训练,也能兼顾基础理解,一个模型能干大部分 NLP 活。
- 结构简单,开发、部署省事。
3. 缺点
- 理解能力不如 BERT 遇到需要结合整段上下文(尤其是后半句)判断的复杂语义,表现会弱一些。
- 写字慢 必须一个字一个往外蹦,不能一次性生成整段,并发量大的时候延迟更高。
- 容易 "胡说八道"(幻觉) 它是按概率猜下一个字,不是真的 "懂知识",偶尔会编造不存在的事实。
4. 适用场景
所有文字生成类工作:人机对话、文案创作、代码生成、问答、小说续写、总结内容。
四、第三种:编码器 + 解码器(组合架构,代表:T5、原始 Transformer)
1. 工作模式
分工合作:
- 编码器(阅读理解):先完整读懂你输入的整段文字;
- 解码器(写作):基于编码器理解的结果,逐字生成新内容。
经典例子:机器翻译
输入中文:我爱吃苹果
- 编码器:完整读懂这句话的含义;
- 解码器:根据理解结果,逐字写出英文
I like eating apples。
2. 优点
- 分工明确:读得准 + 写得顺,同时拥有强理解 + 强生成能力。
- 特别适合「输入一段、输出另一段」的转换任务:翻译、长文缩写、句式改写。 比如长文章缩成短摘要、把书面语改成口语,这种场景它适配度最高。
3. 缺点
- 结构最复杂,相当于 "两套系统拼在一起",训练、调试、维护难度最大。
- 速度偏慢:先要完整读完内容,再开始写字,多一道流程。
- 单项能力不如专用模型: 论 "阅读理解",干不过纯 BERT;论 "自由创作聊天",干不过纯 GPT。 现在通用聊天大模型基本不用这种架构了。
4. 适用场景
文本转换类任务:机器翻译、文本摘要、句式改写、问答生成。
Q2:自注意力机制如何使大模型能够捕捉长距离依赖关系,它跟RNN有什么区别?
面试速记:
自注意力 通过全局两两 token 直接计算关联权重 ,任意位置字符可一步建立联系,天然擅长长距离依赖;RNN 按时序串行计算,依赖逐步传递隐状态,长距离信息衰减严重。
核心区别:自注意力全局并行、无时序累积误差 ;RNN串行逐步、长距离能力弱、可解释时序强。
基础术语释义:
- 自注意力(Self-Attention) :Transformer 核心模块,对序列中所有 Token 两两计算相似度权重,加权聚合全局信息。
- 长距离依赖:文本中相隔较远的字词、语句之间存在语义 / 逻辑关联,模型需要有效捕捉该关联。
- RNN( Recurrent Neural Network 循环神经网络) :传统时序模型,按文本顺序逐 Token 串行处理,依靠隐状态传递历史信息。。
详解:
一、什么是「长距离依赖」?
一句话解释: 一句话 / 一段文本里,前后离得很远的词语,存在关联,模型需要识别这种关系。
举 2 个直观例子:
- 例句:小明昨天去公园玩,他玩得特别开心。 这里「他」指代前面很远的「小明」,两个词隔了一长串内容,模型要读懂指代关系,这就是长距离依赖。
- 例句:虽然外面下大雨,但是我们还是决定出门。 「虽然」和「但是」相隔一段文字,二者是逻辑绑定关系,模型要捕捉这种远距离逻辑。
简单说:长距离依赖 = 找句子里 "隔得很远的关联词 / 指代关系"。
现在问题来了:RNN 做这件事很吃力,自注意力却很轻松,下面分开讲。
二、第一部分:RNN为什么不擅长捕捉长距离依赖?
1. 用比喻理解其工作方式
把一整段文字 想象成一串排队传话的人 ,每个字 = 一个人。 RNN 的规则: 消息只能从左往右,一个人传给下一个人,不能跳着传,也不能反向传。
举例子: 队伍:小明 → 昨天 → 去 → 公园 → 玩 → , → 他 任务:让最后一个人(他)知道,前面的主语是「小明」
流程: 小明 把信息传给 昨天 → 昨天传给 去 → 去传给 公园 ...... 一路传到最后的「他」
2. 核心问题:信息层层损耗
传话游戏你肯定玩过: 一句话传 5 个人,意思基本不变;传 20 个人,大概率变味、丢失细节。
RNN 就是这个道理: 词语相隔越远,信息传递的链条就越长,每传递一步都会丢失一部分信息。 当两个词距离非常远时,传到最后几乎 "面目全非",模型自然识别不出二者的关联。
总结 RNN 痛点:串行传话、链路太长、信息不断丢失 → 抓不住长距离依赖。
补充:RNN 额外特点
- 必须按顺序逐个处理,前面的字不处理完,就没法处理下一个,没法同时干活;
- 它天生就知道文字的先后顺序,不需要额外做 "顺序标记"。
三、第二部分:自注意力(Transformer)如何捕捉长距离依赖?
同样用「排队的人」举例,规则彻底改变。
1. 自注意力的工作规则
不再是「挨个传话」,变成全员互相沟通 。 队伍里每一个人,都可以直接看向队伍里所有人,不管对方站在最前面、最后面,还是中间。
还是这个例子: 队伍:小明 → 昨天 → 去 → 公园 → 玩 → , → 他
最后一个人「他」,不用等别人传话 ,可以直接转头看向最开头的「小明」,二者直接建立联系。
2. 核心优势
- 无中间环节,信息零损耗 远距离的两个词直接交互,不需要经过中间一大串文字传递,信息不会丢失。 哪怕两个词相隔上百个字,也能精准识别关联,这就是它擅长长距离依赖的根本原因。
- 所有人可以同时 "互相观察、计算关系" 整段文字可以一次性全部处理,不用排队逐个干活,处理速度远快于 RNN。
3. 一个小短板(对应前面知识点)
自注意力本身分不清文字顺序。 比如「狗咬人」和「人咬狗」,单纯看词语组合,它分辨不出区别。 所以必须额外加「位置编码」,给每个字标上序号(第 1 个字、第 2 个字......),补上顺序信息。
四、底层原理
自注意力为每个词元生成查询(Q)、键(K)、值(V) 三组向量。通过计算当前词元的 Q 与整个序列所有词元 K 的相似度,得到注意力权重;再用权重对所有词元的 V 做加权求和。
这意味着任意两个词元可以直接建立关联,信息不需要逐位串行传递,从根本解决了长序列下信息衰减的问题。
Q(查询)、K(键)、V(值) 三组功能向量,分工明确:
- Q 查询:当前词的"主动诉求",代表自己想找谁、想关注什么语义信息。
- K 键:当前词的"对外名片",对外展示自身语义特征,供所有词的Q匹配比对。
- V 值:当前词的"真实内容",存储自身完整语义信息,是最终传递、融合的核心数据。
我们以句尾的「他」为核心,一步步看它如何通过自注意力机制,远距离关联到句首的「小明」。
步骤1:所有词元生成专属 Q、K、V 向量
句子中6个词元,各自生成独立的三组向量,互不干扰:
- 小明:Q_1、K_1、V_1
- 昨天:Q_2、K_2、V_2
- 去:Q_3、K_3、V_3
- 公园:Q_4、K_4、V_4
- 玩:Q_5、K_5、V_5
- 他:Q_6、K_6、V_6
本次核心关注:「他」的查询向量 Q_6
Q_6 含义:"他"作为代词,主动想要寻找句子中和自己关联最强的指代主体。
步骤2:全局相似度计算(全句匹配打分)
用「他」的查询向量 Q_6,遍历匹配全句所有词元的K键向量,逐一计算语义相似度,不受词语位置远近限制:
- Q_6 匹配 K_1(小明):分数很高,代词与主语语义强绑定
- Q_6 匹配 K_2(昨天):分数很低,无语义关联
- Q_6 匹配 K_3(去):分数很低,无语义关联
- Q_6 匹配 K_4(公园):分数很低,无语义关联
- Q_6 匹配 K_5(玩):分数偏低,仅有弱场景关联
- Q_6 匹配 K_6(他自己):分数中等,自身基础关联
与RNN核心区别 :RNN中「他」只能接收前一个词"玩"的残缺信息,无法接触全文;自注意力可实现全局一对一直接打分,远距离词语无访问壁垒。
步骤3:生成注意力权重
将上一步所有相似度分数做归一化处理,转化为注意力权重。权重代表当前词对其他词的关注度,数值越大、语义关联越强,所有权重总和固定为1。
本例句权重分布示意:
- 小明:权重 ≈ 0.7(核心关联,最高优先级)
- 玩:权重 ≈ 0.10(弱场景关联)
- 昨天、去、公园、他自身:权重各 ≈ 0.05(几乎无关联)
步骤4:加权求和,融合全局语义信息
以注意力权重为系数,对全句所有词元的 V值(真实语义信息) 做加权求和,最终更新「他」的语义特征。
通俗计算逻辑:最终特征 = 权重₁×小明信息 + 权重₂×昨天信息 + 权重₃×去的信息 + 权重₄×公园信息 + 权重₅×玩的信息 + 权重₆×他自身信息
对应具体运算:
- 0.7 × V_1(小明信息)→ 主导最终语义
- 0.10 × V_5(玩的信息)→ 辅助场景信息
- 0.05 × V_2、V_3、V_4、V_6 → 微弱补充信息
运算完成后,「他」的新特征重点融合了远距离"小明"的核心语义,模型成功识别二者的指代关系。
该逻辑适用于全文所有词元,不止是"他",句子中每一个词都会执行「生成QKV→全局匹配相似度→计算权重→加权融合V值」的操作,实现全句词语两两语义交互。
五、RNN vs 自注意力 全方位对比
结合上面两个比喻,整理成好记的对比,一共 4 个核心区别:
表格
|---------|-------------------------|-----------------------------|
| 对比点 | RNN(老式模型) | 自注意力(Transformer / 大模型) |
| 工作方式 | 串行挨个传话,只能从前到后传 | 全员直接互相交流,任意两人可连线 |
| 长距离关联 | 很差。距离越远,信息丢得越多,认不出远距离关系 | 很强。远距离词语直接对接,信息不丢失 |
| 处理速度 | 慢。必须等前一个处理完,才能处理下一个 | 快。整段文字可以同时运算 |
| 顺序感知 | 天生知道先后顺序,不用额外设置 | 本身分不清顺序,必须加位置标记 |
Q3:大模型为什么有上下文长度的概念?为什么它是指输入和输出的总长度?
大模型基于自注意力 ,算力、显存、位置编码都存在硬上限,因此定义上下文长度 ;主流自回归模型采用统一序列窗口 ,输入、历史对话、新生成输出会拼接在同一段序列里,所以上下文长度特指输入 + 输出的总 Token 长度。
第2章 词元和嵌入
Q4:大模型的分词器和传统的中文分词有什么区别?对于指定的词表,一句话是不是只有唯一的分词方式?
面试速记:
大模型分词器以子词分词 为主,面向模型预训练与全局语义,兼顾多语言、生僻词、长词;传统中文分词是词语切分,面向语言学与文本处理,侧重语义词汇边界。
在固定词表 + 标准解码规则下,一句话存在唯一分词结果(贪心 / 最大匹配、BPE 均如此);仅规则异常、自定义特殊逻辑时才出现多解。
基础术语释义:
- 传统中文分词(Chinese Word Segmentation,CWS) :基于汉语词典、语言学规则或机器学习,将连续中文文本切分为具备独立语义的词语,属于传统自然语言处理基础任务。
- 大模型分词器(Tokenizer) :大模型配套文本编码模块,主流采用子词分词方案,把文本转为模型可识别的 Token 序列,作为模型输入。
- 词表(Vocabulary,Vocab):分词器预先定义的全部合法子词、字符、符号集合,是文本切分与编码的硬性依据。
- BPE(Byte Pair Encoding,字节对编码):大模型最主流的子词分词算法,从基础字符出发,迭代合并高频相邻字符单元。
- WordPiece:BERT 系列模型使用的子词分词算法,基于贪心最长匹配 + 频次规则切分文本。
- SentencePiece:开源通用子词工具库,可无缝支持多语言,主流大模型、多语种场景广泛使用。
- 未登录词(Out-of-Vocabulary,OOV):不在分词词典 / 词表内的词汇、新词、生僻词、网络用语等。
- 最大匹配法(Maximum Matching,MM):传统中文分词经典规则,分为正向、逆向最大匹配,优先匹配词典中最长词汇。
详解:
(一)大模型分词器 与 传统中文分词 核心区别
1. 核心目标不同
- 传统中文分词 目标是还原人类语言学词汇,切分出名词、动词、短语等语义词汇,服务检索、词性标注、句法分析、文本挖掘等传统 NLP 任务。 判定标准:是否符合汉语用词习惯、语义完整性。
- 大模型分词器 目标是统一编码、降低词表规模、兼容多语言、处理未登录词 ,只为模型输入服务,不严格遵循汉语词汇边界。 判定标准:是否在词表内、编码效率、序列长度可控。
2. 切分粒度不同
- 传统中文分词 :词粒度 ,最小单元是日常词汇。 示例:
人工智能→ 切为人工智能(整体词语)。 - 大模型子词分词 :子词 / 字符粒度 ,长词、新词、专有名词会继续拆分。 示例(BPE):
人工智能→ 拆为人工 + 智能或更细的子单元;生僻词、网络词、外文直接拆为基础字符 / 短子词。
3. 处理未登录词 (OOV) 能力
- 传统中文分词 :高度依赖内置词典,词典外新词、生造词、网络用语、外文混合极易切分错误。
- 大模型分词器 :基于子词 + 字符兜底,天然抗 OOV,任何文本都能拆成词表内单元,无真正 "未登录词"。
4. 语言兼容性
- 传统中文分词 :单语言定制,专门针对中文设计,多语言混合文本处理差。
- 大模型分词器 :多语言统一(如 SentencePiece、GPT BPE),一套词表支持中、英、符号、数字混排。
5. 算法与依据
- 传统中文分词 :正向 / 逆向最大匹配、隐马尔可夫模型、条件随机场(Conditional Random Field,CRF) 、深度学习,依托中文词典 + 语言学特征。
- 大模型分词器 :BPE、WordPiece、SentencePiece,依托静态词表 + 固定合并规则,几乎不依赖语言学知识。
6. 输出形态与用途
- 传统分词:输出人类可理解的词语序列,可直接用于业务分析。
- 大模型分词器:输出子词 Token 序列,仅作为模型数值输入,普通人难以直观理解。
(二)固定词表下,一句话是否只有唯一分词方式?
结论先行 :在固定词表 + 标准确定性解码算法 前提下,一句话有且仅有唯一分词结果;不存在多种合法切分。
1. 主流算法的确定性解释
(1)正向 / 逆向最大匹配(传统分词)
规则固定:从前到后(或从后到前)每次匹配词典中最长合法词汇。 规则唯一 → 每一步选择唯一 → 整句分词结果唯一。
(2)BPE / SentencePiece(大模型主流)
BPE 编码是完全确定性过程:
- 预训练阶段生成固定的合并规则优先级;
- 推理时从单字符开始,严格按优先级依次合并;
- 同一文本 + 同一词表 + 同一合并顺序,最终切分结果唯一。
(3)WordPiece(BERT 类)
采用贪心最长匹配策略,同样具备确定性,结果唯一。
2. 什么情况下会出现 "多种分词结果"(非标准场景)
- 混用不同算法 / 不同词表 词表不一样、BPE 合并规则不一样,结果必然不同;不属于 "指定词表" 范畴。
- 人为开启歧义优化(传统分词特有) 部分传统分词工具提供歧义消解、多候选输出功能,主动返回多种切分,属于业务增强,不是基础分词逻辑。
- 自定义模糊规则 / 动态词表 词表动态更新、添加临时热词、放宽匹配规则,会破坏唯一性。
- 大小写、全角 / 半角、空格预处理不一致 预处理不同会改变原始文本,看似 "同一句话",实际输入不同,分词结果不同。
3. 举例验证
给定固定 BPE 词表与规则:
原句:深度学习很有用
在参数完全不变的前提下,无论执行多少次分词,切分出的子词序列完全一致,不会出现第二种合法方案。
四、核心对比表
表格
|----------------|---------------|------------------------|
| 对比维度 | 传统中文分词 | 大模型子词分词器 (BPE/SP) |
| 切分粒度 | 汉语词语级别 | 子词 / 字符级别 |
| 设计目标 | 贴合语言学,服务文本理解 | 编码输入、压缩词表、兼容多语言 |
| 依赖依据 | 中文词典、语言学规则、词性 | 静态词表、固定合并规则 |
| 未登录词 (OOV) | 能力弱,易出错 | 能力强,字符兜底无 OOV |
| 多语言支持 | 单中文为主,混合文本差 | 原生支持多语言、中英混排 |
| 结果可读性 | 高,符合人类认知 | 低,子词无独立语义 |
| 算法特性 | 最大匹配、CRF 等 | BPE、SentencePiece(确定性) |
五、避坑要点
- 不要混淆分词目标:大模型分词不追求 "分词语义正确",只追求 "可被模型编码"。
- 唯一性前提:必须同时满足 固定词表 + 固定算法 + 统一预处理,三者缺一可能出现多结果。
- 中文场景差异:大模型很少用纯单字分词,大多是字 + 常用词 + 子词混合形式。
- Token ≠ 汉字:一个中文汉字可能被拆为多个子词 Token,英文单词也可能被拆分。
Q5:大模型是如何区分聊天历史中用户说的话和AI说的话的?
面试速记:
大模型本身没有 "记忆",所有聊天历史都会拼接成一整条上下文序列 ,和当前提问一起放进上下文窗口。想要区分发言方,必须靠人为设计的格式与标记引导模型。
大模型依靠对话模板 + 角色标记 + 特殊占位符 / 分隔符区分用户与 AI 历史消息。
- 训练 / 推理时,会给每一条历史对话附加角色标识 (如
user、assistant); - 搭配固定分隔符、系统提示词,把多轮历史拼接成标准格式文本送入模型;
- 模型通过识别标记、固定句式,就能分清每段内容的发言方,同时知道当前轮到谁回复。 主流实现分两种:显式角色标签 、固定对话模板句式。
详解:
(一)核心实现方式:结构化格式拼接
所有多轮对话不会直接把纯文本堆在一起,而是按照统一模板,用角色标记做显式分隔,模型通过识别标记判断每一段内容的归属。主流分为三类实现方案。
1. 特殊标记符分隔(业界最通用)
在每一轮发言前后,添加模型词表内预设的唯一特殊 Token / 符号,明确标注发言者。
示例(通用格式)
以常见标记为例:
<|user|>:用户角色标记<|assistant|>:AI 助手角色标记<|endoftext|>:单轮发言结束标记
拼接后完整输入结构:
<|user|>
你好,介绍一下自己
<|endoftext|>
<|assistant|>
我是大语言模型,很高兴为你服务
<|endoftext|>
<|user|>
讲个笑话
<|endoftext|>模型解析逻辑:读到 <|user|> 就知道后续内容是用户输入 ;读到 <|assistant|> 就识别为自身历史回复。
不同开源模型会使用自定义标记:
- Llama 系列:使用
<<<Human>>>、<<<Assistant>>> - Qwen、ChatGLM:采用自研角色占位符与结束符
- GPT 系列:通过消息结构体 + 固定文本前缀区分
2. 固定文本前缀 / 话术区分(传统简易方案)
不使用特殊符号,依靠固定自然语言前缀划分角色,早期对话模型、轻量化场景常用。
示例
用户:今天天气怎么样
AI:今天天气晴朗,温度适宜
用户:适合出门吗模型在训练中学习到规律:用户: 后面是人类提问,AI: 后面是自己的回答。 缺点:易受用户恶意输入干扰(比如用户主动打出 "AI:xxx"),鲁棒性弱,目前高端模型已很少单独使用。
3. 结构化消息格式(API / 闭源模型主流)
闭源大模型、OpenAI 类 API 采用结构化数组传递对话历史,前端 / 框架先做角色划分,再按模板转成文本送入模型。
示例(JSON 结构)
[
{"role":"user", "content":"问题1"},
{"role":"assistant", "content":"回复1"},
{"role":"user", "content":"问题2"}
]框架会把结构化数据自动渲染为模型可识别的带标记文本,模型只处理最终拼接好的序列,从源头保证角色不混淆。
(二)模型为什么能理解这套规则?两大训练支撑
a. 预训练 & 指令微调阶段的数据对齐
模型在 指令微调、对话微调 时,训练样本全部严格遵循同一种对话模板。海量数据让模型学到:
-
- 特定标记 / 前缀 与 "用户 / AI" 角色的强绑定关系;
- 对话时序逻辑:用户提问在前,AI 回复在后,交替出现。 相当于模型提前 "学会了语法规则",推理时自动识别角色。
b. 自回归生成的续写逻辑强化
仅解码器架构为逐 Token 续写: 当输入序列最后一个标记是 <|user|> 时,模型默认接下来需要以 AI 身份作答 ; 生成完一轮回复并追加结束符后,若后续再出现 <|user|>,模型又会切换为 "接收用户新问题" 的状态。 续写逻辑进一步巩固了角色区分能力。
(三)补充:系统角色的区分方式
除了用户、AI,多数模型还支持系统角色(System),用于设定模型定位、规则、风控要求:
- 位置固定:系统提示词统一放在整个对话上下文的最开头;
- 搭配专属标记:使用
<|system|>这类独立角色符; - 作用隔离:模型能区分 "全局规则" 和 "轮次对话内容",不会把系统指令当成用户提问。
四、常见问题与边界说明
1. 会不会出现角色混淆?
正常使用下不会。原因:
- 角色标记是词表内专属 Token,用户无法输入(普通文本打不出该符号);
- 训练数据强化了交替对话的时序规律。
仅两种异常场景会错乱:
- 人为篡改对话模板、删除 / 替换角色标记;
- 恶意诱导:用户模仿角色前缀伪造 AI 发言,简易前缀方案会中招,带专属 Token 的方案可有效防御。
2. 上下文截断对角色区分的影响
当对话超长触发上下文截断时,主流策略是删除最早的整轮对话,而非截断单句话。 保证剩余内容依然是「用户 - AI」交替的完整轮次,角色标记完整保留,不会破坏识别逻辑。
五、不同方案优缺点对比
表格
|---------------|-----------------------------|-----------------|----------|-------------|
| 实现方案 | 核心形式 | 优点 | 缺点 | 适用场景 |
| 专属特殊 Token 标记 | <user> /<assistant> 等符号 | 鲁棒性强、不易被干扰、解析精准 | 依赖模型词表定制 | 开源大模型、私有化部署 |
| 自然语言前缀 | 用户: /AI: | 实现简单、可读性高 | 易被用户伪造干扰 | 早期模型、简易演示场景 |
| 结构化消息模板 | JSON 角色字段 + 自动渲染 | 工程化强、格式统一 | 依赖框架转换 | 商用 API、线上产品 |
Q6:传统的静态词嵌人(如word2vec)与大模型产生的上下文相关的嵌人相比,有什么区别?有了与上下文相关的嵌人,静态词嵌人还有什么价值?
面试速记:
静态词嵌入为词语生成固定向量 ,无法区分一词多义,优势是轻量化、速度快;上下文嵌入结合语境动态生成向量,语义理解更强,但算力开销更大。 即便有了上下文嵌入,静态嵌入在轻量化部署、传统 NLP 任务、边缘设备、模型初始化等场景中,依然具备低成本、高效率的实用价值。
详解:
一、核心区别(静态 vs 上下文相关嵌入)
静态词嵌入(如 word2vec)和大模型上下文嵌入的核心区别有 3 点:
- 是否依赖上下文:静态嵌入给每个词一个固定向量,和语境无关;上下文嵌入会根据句子前后内容动态调整同一个词的向量,能区分多义词。
- 语义捕捉能力:静态嵌入只能学习通用、平均化的语义,无法处理一词多义;上下文嵌入能捕捉语境、句法、指代等复杂语义,表达更精准。
- 训练方式与适用场景:静态嵌入是单独预训练的固定向量,多用于传统 NLP 任务;上下文嵌入是模型前向推理的动态结果,是大模型理解文本的基础,适配对话、生成等复杂场景。
表格
|------------|----------------------------------------------------------------------|-----------------------------------------------------------------------------|
| 对比维度 | 静态词嵌入(word2vec) | 上下文相关嵌入(BERT / 大模型) |
| 向量唯一性 | 同一个词,无论出现在什么句子里,都只有唯一的固定向量。例:"银行" 在 "存钱" 和 "河边" 中,向量完全相同,无法区分多义。 | 同一个词,在不同上下文里,会生成不同的动态向量。例:"银行" 在两个句子中,向量会根据前后词调整,能区分语义。 |
| 语义捕捉层次 | 只能学习词的通用、平均语义,无法理解语境、句法、指代等细粒度信息。优点:简单、轻量;缺点:语义表达粗糙,对歧义词束手无策。 | 能捕捉语境依赖的动态语义,包括一词多义、指代关系、情感倾向、句法结构等复杂信息。例:模型能理解 "他" 指代前文的 "小明",并在向量中体现。 |
| 生成方式 | 离线预训练,训练完成后向量就固定不变,直接查表使用。 | 在线生成,需要将整个句子输入模型,通过前向传播计算得到每个词的嵌入,和模型的深度、注意力机制强相关。 |
| 计算成本 | 极低,直接查表即可,几乎无计算开销。 | 较高,需要运行完整模型推理,依赖 GPU 算力。 |
| 适用场景 | 传统 NLP 任务:文本分类、关键词提取、信息检索等,作为模型输入的基础特征。 | 现代 NLP 全场景:对话生成、语义理解、机器翻译、RAG 检索、文本匹配等,是大模型能力的基础。 |
二、静态词嵌入的价值(为什么还没被淘汰?)
- 轻量高效,资源消耗极低,无需大模型推理,适合低算力、低延迟场景;
- 简单易用,部署成本低,作为传统 NLP 任务的基础特征,依然广泛应用;
- 向量维度低,可解释性强,便于可视化和理解词之间的关系;
- 通用性强,跨模型 / 跨任务兼容,不受大模型架构和版本限制。
Q7:在wond2vec等词嵌人空间中,存在 king - man + woman ≈ queen 的现象,这是为什么?大模型的词元嵌入空间是否也有类似的属性?
面试速记:
- 原因
word2vec 依据分布假说训练,将性别、身份等语义特征编码进向量维度,词语间的语义关系可以等价为向量线性运算 。king-man 剔除男性特征、保留君主属性,再加女性特征,向量就近似 queen。
- 大模型词元嵌入也有类似属性, 但表现、强弱、适用范围和 word2vec 不一样
大模型底层输入嵌入仍有微弱的线性类比能力;但经过多层 Transformer、自注意力与非线性变换后,线性关系变弱。加上大模型采用子词分词、输出上下文动态向量,经典的词向量线性加减现象不再明显。大模型依靠整体语义能力而非向量运算完成类比推理
第 3 章 LLM 的内部机制
Q8:注意力机制是如何计算上下文各个词元之间的相关性的?每个注意力头只关注一个词元吗?
面试速记:
自注意力通过Query、Key、Value 三元组,先做点积相似度 、缩放、掩码、Softmax,得到各词元间注意力权重,再加权 Value 完成信息聚合。单个注意力头并非只关注一个词元,而是同时计算全局所有词元的关联,多头是分头学习不同类型语义关系。
基础术语释义:
- 自注意力机制(Self-Attention Mechanism):Transformer 核心模块,计算序列内所有词元(Token)相互关联程度,并加权融合上下文信息。
- 词元(Token):文本经分词后得到的最小编码单元,是模型运算的基本对象。
- 查询向量(Query, Q) :表征当前词元想要查找的上下文信息特征。
- 键向量(Key, K) :表征全局所有词元可被匹配的特征。
- 值向量(Value, V):存储每个词元本身的语义内容,用于最终信息加权融合。
- 注意力头(Attention Head):将 Q/K/V 拆分为多组并行子空间,每组独立计算注意力,捕捉不同维度语义关联。
详解:
(一)自注意力计算词元相关性完整流程
输入:序列中每个词元对应一个词嵌入向量 ,先通过线性投影得到三组向量 Q,K,V 。 整体分为5 个标准步骤:
- 计算原始相似度(点积)
与序列全部词元的 K 逐一做点积:Score = Q・K^T 点积结果数值越大,代表两个词元语义相关性越高。
- 缩放(Scaling)
除以 sqrt (d_k)(d_k 为 Key 向量维度),避免向量维度较高时点积结果过大,导致后续 Softmax 进入梯度饱和区。
- 掩码(Mask,按需使用)
- 编码器(BERT 类):无掩码,所有词元互相可见;
- 解码器(GPT 类):添加因果掩码,把当前位置之后的未来词元分值置为负无穷,确保只能看到前文。
- Softmax 归一化 对每一行分值做 Softmax,将数值转为0~1 之间的概率分布 ,总和为 1,这一组数值就是注意力权重。权重大小直观体现:当前词元对上下文每个词元的关注程度。
- 加权求和 用注意力权重,对全局所有词元的 V 向量做加权累加,得到当前词元融合上下文后的最终表征。
总结:整个过程是全局两两计算相关性,任意两个词元都会算出对应权重,以此建模上下文依赖。
(二)每个注意力头是否只关注一个词元?
结论:不是。
- 单头注意力的工作模式 一个注意力头,依然会完整执行上述全套计算: 针对当前任意一个词元 ,计算它与序列内所有词元 的相关性,生成一整组全局注意力权重,同时吸收全部上下文信息。 一个头会重点偏向某一类语义关系 (如语法结构、局部搭配、长距离指代),但关注对象是全体词元,而非仅锁定单个词元。
- 多头注意力(Multi-Head Attention)设计目的 将 Q/K/V 切分为 h 组低维子向量,h 个注意力头并行独立计算:
- 不同头学习不同类型的关联:有的头擅长捕捉短距离词语搭配,有的擅长长距离指代、逻辑关联,有的关注语序 / 语法;
- 最后把所有头的输出拼接,再做一次线性变换融合,让模型同时掌握多维度上下文关系。
- 举例辅助理解
句子:小猫追着蝴蝶飞
- 单个注意力头不会只盯着 "蝴蝶" 这一个词;
- 它会分别计算「小猫 - 追」「小猫 - 蝴蝶」「追 - 蝴蝶」等全部两两关联,只是该头会对某一类关系分配更高权重;
- 多个头分工,分别侧重主谓、动宾、长距离修饰等不同关联。
核心要点总结
- 相关性计算链路:线性投影 Q/K/V → 点积求相似度 → 缩放 → 掩码 → Softmax 得到权重 → 加权 Value。
- 单注意力头:覆盖全局所有词元,不是只关注单个词元,仅侧重某一类语义关联。
- 多头价值:多组并行,分工学习不同维度的上下文关系,提升建模能力。
避坑要点
- 区分「权重高低」和「关注范围」:权重高代表重点关注,权重低代表关注度弱,但不代表完全不关注、不参与计算。
- 因果掩码只是屏蔽未来位置,不会改变 "全局计算相关性" 的核心逻辑。
- 多头只是向量拆分并行运算,没有改变单头的计算流程。
Q9:如果需要通过修改尽可能少的参数值,让模型忘记某一特定知识,应该修改注意力层还是前馈神经网络层的参数?
面试速记:
优先修改前馈神经网络(FFN) 参数。知识、事实类内容主要存储在 FFN,注意力层侧重语义关联、位置与序列依赖;改动 FFN 仅需少量参数即可实现定向遗忘,改动注意力层易破坏全局关联能力、副作用大。
基础术语释义
- 注意力层(Attention Layer) :全称 Self-Attention Layer,自注意力层,核心作用是建模序列内 Token 间的语义关联、长距离依赖、语序信息。
- 前馈神经网络层(Feed-Forward Network,FFN) :Transformer 标准组件,位于每一层注意力之后,负责知识记忆、特征变换、事实信息编码。
详解:
(一)两大模块核心分工(决定选型的根本原因)
1. 自注意力层(Attention)
- 核心职能:计算 Token 之间的关联权重、捕捉上下文依赖、建模语序与语义关系,不长期存储具体事实知识。
- 特点:参数作用具有全局性、关联性。修改任意注意力参数,会影响整段文本的语义匹配、长距离关联、对话逻辑,波及范围极广。
- 问题:若用注意力层做知识遗忘,极易引发上下文理解错乱、生成重复、语义跑偏,改动成本高、副作用不可控。
2. 前馈网络层(FFN)
- 核心职能:对注意力输出的特征做非线性变换,大模型的事实、常识、领域知识点主要存储在 FFN 神经元中。
- 特点:知识呈现稀疏激活 ------ 某一条特定知识,仅由 FFN 里少量神经元 / 参数负责编码、触发。
- 优势:定向修改对应少量参数,就能针对性弱化该知识;对模型通用理解、关联能力影响极小,符合「修改尽可能少参数」的要求。
(二)为什么 FFN 是最优选择
- 知识存储载体属性 学界与工程实践(如模型编辑、知识擦除、神经元探测)已验证:Transformer 架构中,事实知识、专有信息、固定结论主要固化在 FFN;注意力只负责 "找关联",不负责 "存内容"。想要抹去一条知识,直接修改存储载体效率最高。
- 参数改动量级最小 单条特定知识仅激活 FFN 中数十~数百个神经元,只需微调对应权重、偏置即可实现遗忘; 而注意力矩阵是全局两两交互,哪怕微小改动,也会扩散到整个序列的注意力分布,需要调整大量参数才能勉强达到效果。
- 副作用可控
- 修改 FFN:仅影响目标知识点,模型对话、推理、语义理解、其他知识基本不受干扰;
- 修改注意力层:容易破坏长依赖、语义匹配、语序感知,出现大面积生成异常。
(三)补充:两种层的改动场景区分
- 适合修改 FFN 的场景 定向遗忘特定事实、专有知识、固定答案、敏感信息(如某条常识、特定人物信息、涉密内容),也是本题对应的场景。
- 适合修改注意力层的场景 需要调整语义关联规则、语序偏好、长距离依赖、对话轮次逻辑,而非删除具体知识。例如:强制模型忽略前文某类提示、改变语句关联倾向。
(四)极简落地思路(面试可补充)
- 定位:通过激活值探测,找到触发目标知识时高激活的 FFN 神经元;
- 微调:小幅修改对应神经元的权重 / 偏置,降低该知识的激活强度;
- 验证:确保目标知识被遗忘,同时抽检通用问答、其他知识点,确认无明显能力退化。
核心对比表
表格
|--------------|--------------------|----------------|
| 对比维度 | 自注意力层 | 前馈网络层 FFN |
| 核心功能 | 建模 Token 关联、长依赖、语序 | 存储事实知识、特征非线性变换 |
| 知识存储能力 | 几乎不存储具体知识 | 大模型主要知识载体 |
| 改动参数数量 | 多(全局影响) | 少(稀疏激活,局部改动) |
| 改动副作用 | 大,易破坏语义、语序、长依赖 | 小,仅影响目标知识 |
| 是否适合定向遗忘特定知识 | ❌ 不推荐 | ✅ 首选方案 |
避坑要点
- 不要混淆 "知识" 与 "关联关系":遗忘事实内容 选 FFN;修改语义关联逻辑才考虑注意力层。
- 即使是 FFN,也需精准定位神经元:盲目全层改动依然会造成模型能力下降,精准稀疏修改才是关键。
- 该结论针对标准 Transformer(GPT/BERT 等主流架构),通用大模型均适用。
Q10:为什么注意力机制需要多个头?跟简单地减少注意力头的数量相比,多查询注意力和分组查询注意力优化有什么不同?它们优化的是训练阶段还是推理阶段?
面试速记:
设置多个注意力头,是为了并行学习多种语义关联 ,单头表达能力不足。多查询注意力(MQA)、分组查询注意力(GQA)通过共享 K/V 投影 减少参数量与计算量,和单纯减少头数不是同一思路;二者主要优化推理阶段,训练阶段也有小幅提速。
基础术语释义
- 多头注意力(Multi-Head Attention,MHA):将 Q/K/V 拆分为多组子向量,每组独立计算注意力,最后拼接融合输出。
- 单头注意力(Single-Head Attention):仅一组 Q/K/V 完成注意力计算,表达能力受限。
- 多查询注意力(Multi-Query Attention,MQA):多个查询头共享同一组 Key、Value 头,大幅削减 K/V 计算与显存占用。
- 分组查询注意力(Grouped-Query Attention,GQA) :折中方案,将查询头分为若干组,每组共享一组 K/V,平衡效果与性能。
详解:
一、为什么注意力机制需要多个头(多头注意力)
- 单一注意力头的局限 单头注意力只能学到一种全局关联模式,无法同时兼顾多样的语言关系:比如一句话里既有主谓搭配、又有时间地点修饰、还有代词指代,单个头难以全部覆盖。
- 多头的工作逻辑 将 Q/K/V 按维度均等切分为多组,每组对应一个独立注意力头,各自拥有专属权重:
- 每个头独立执行缩放点积注意力,专注学习一类依赖;
- 不同头分工不同:有的侧重局部语法、有的侧重长距离指代、有的侧重语义相似度;
- 所有头的输出拼接后再做线性融合,整合多维度特征。
- 额外优势 相比单纯加宽单层网络,多头拆分的设计参数量、计算量增长平缓,泛化效果更好,是低成本提升模型表达能力的方案。
二、多查询注意力、分组查询注意力 vs 减少注意力头数量,三者差异
先明确基础定义,再对比差异,最后说明优化阶段。
前置概念
标准多头注意力(MHA Multi-Head Attention):每个头都有独立的 Q、K、V ,头数越多,K/V 矩阵体积越大,推理时 KV 缓存开销越高。 这两类优化核心目标:压缩 K/V 参数量、降低显存占用、加速推理,和 "单纯减少头数" 思路完全不同。
1. 三种方案核心区别
(1)简单减少注意力头数量
- 做法:直接砍掉部分注意力头,整体头数变少,Q/K/V 组数同步减少。
- 本质:削弱模型表达能力,强行降低计算与显存开销;会直接丢失多头原本学到的多样语义依赖,模型效果明显下降。
- 特点:一刀切优化,牺牲精度换速度,属于 "减功能"。
(2)多查询注意力 MQA(Multi-Query Attention)
- 做法:保留多组独立 Q,所有头共享同一组 K、V。
- 原理:查询 Q 依然分头,保证不同头能做差异化查询;全局只用一份 K/V,大幅压缩 KV 参数量与 KV 缓存。
- 效果:显存、计算量显著下降;精度损失很小,远好于直接减头。
(3)分组查询注意力 GQA(Grouped-Query Attention)
- 做法:折中方案,把注意力头划分为若干组,同一组内的头共享一组 K/V,组与组之间 K/V 相互独立。
- 原理:介于标准 MHA 和 MQA 之间。组数越多越接近原生 MHA,精度越高;组数越少越接近 MQA,速度越快。
- 特点:可灵活权衡推理速度、显存占用、模型精度,是目前主流折中选型(LLaMA 2、主流开源大模型广泛使用)。
三、优化的是训练阶段还是推理阶段?
核心结论:主要优化 推理阶段,对训练阶段提升有限
详细说明
- 推理阶段(重点优化目标) 大模型自回归推理时,会持续缓存每一步的 K/V(KV Cache),这是显存占用、访存开销的最大瓶颈:
- MQA/GQA 大幅减少 K/V 总量,KV 缓存体积断崖式下降,显存占用、内存带宽压力显著降低;
- 计算量减少,单步推理速度明显提升;
- 越长的上下文、越大的模型,优化效果越突出。
- 训练阶段 训练时为并行计算,一般不使用 KV 缓存,所有词元一次性计算完整注意力矩阵。
- MQA/GQA 仅小幅减少参数量与计算量,提速、省显存的效果远不如推理阶段;
- 因此业界普遍做法:训练用标准 MHA 保证精度,推理时切换为 MQA/GQA 做加速。
- 补充区分 单纯减少注意力头:训练、推理同时降参、降速,但全程伴随精度损失。
Q11:Flash Attention并不能减少计算量,为什么能提升推理速度?Flash Atention是如何实现增量计算softmax 的 ?
面试速记:
FlashAttention 不减少浮点计算量 ,核心靠分块计算、核融合、规避大矩阵显存读写 ,缓解显存带宽瓶颈从而提速;它采用分块流式计算 + 动态维护全局最大值、指数和 + 分步重缩放,实现增量式 Softmax,无需加载整行数据。
基础术语释义
- 显存带宽(HBM Bandwidth):GPU 高带宽显存的数据读写速率,长序列注意力的主要性能瓶颈。
- 增量式 Softmax(Online/Incremental Softmax):不加载完整输入序列,分块逐段计算 Softmax,动态修正中间结果。
详解:
一、Flash Attention 计算量没少,为什么还变快?
先搞懂一个前提:GPU 不是 "算得慢",是 "传数据慢"
1. 传统注意力的痛点:反复搬运海量数据
举个例子:一句话有 1024 个词元
- 标准注意力要算出一个 1024×1024 的超大分数矩阵,几十万个数。
- GPU 运算流程:
-
- 从 ** 低速大显存(HBM)** 读取 Q/K/V 数据(这里的低速是与SRAM 对比而言)
- 计算出超大分数矩阵
- 把整个大矩阵写回低速显存
- 再从显存读出来做 Softmax
- 做完再写回去,最后乘 V 得到结果
👉 问题核心: 计算只用一瞬间,但超大矩阵在低速显存里反复读写 ,GPU 大部分时间都在 "等数据",这就是内存瓶颈。 哪怕计算步骤不变,只要少搬数据,整体速度就会暴涨。
2. Flash Attention 的做法:不存大矩阵,数据只走高速缓存
GPU 里有两块存储:
- 低速大显存(HBM):空间极大,读写很慢
- 片上高速缓存(SRAM):空间很小,读写速度极快(比 HBM 快几十倍)
Flash Attention 核心思路:拆分切块 + 能不存就不存
- 把 Q、K、V 切成很多小碎片块,每一小块刚好能放进高速 SRAM;
- 每次只加载一小块数据进高速缓存,当场计算;
- 全程不生成、不保存完整的大矩阵,中间结果留在高速缓存里,绝不写回低速显存。
✅ 总结: 计算的加减乘除总量(计算量)几乎没变,但是低速显存的读写次数暴跌。 GPU 不用再慢吞吞搬数据,一直处于计算状态,所以速度大幅提升。
二、Flash Attention 如何实现「增量计算」(在线 Softmax)
普通 Softmax 的硬性要求: 想算出一行数据的 Softmax,必须先拿到这一整行所有数字,算出:
- 整行的最大值
- 整行所有数字的指数总和
传统方式:先存完整一行数据,再统一计算。 Flash 做不到(因为它不存完整大矩阵),所以用边走边算、动态修正的增量思路。
举例子
假设你有一堆数字,要算整体 Softmax,规则:用「全局最大值」和「全局总和」做归一化。 我们把数字分成 3 小批 依次处理(对应 KV 分块)。
定义两个全局记录(只存 2 个小数,占用极小空间)
max_val:目前见过所有数字里的最大值sum_val:目前所有数字经过指数运算后的总和output:最终输出结果
分步模拟增量计算
第 1 批数字
- 算出这批数字的局部最大值、局部指数和、局部输出
- 直接赋值:
max_val=局部最大值,sum_val=局部指数和,output=局部输出
第 2 批数字
- 算出第二批的局部最大值
- 关键判断 :如果第二批最大值 > 之前的
max_val
-
- 说明全局最大值变了!之前所有结果都要整体缩放修正(数学上保证结果等价)
- 更新全局最大值、总和、输出
- 把第二批的指数和、输出,累加到全局变量上
第 3 批数字
重复上面逻辑:比较最大值 → 按需缩放历史数据 → 累加新数据
最后一步
所有批次遍历完毕,用最终的 sum_val 对 output 做一次归一化,得到最终结果。
对应到 Flash Attention 里
- K/V 被切成一个个小块,一块一块依次处理(增量);
- 全程只维护 3 个极简全局变量:全局最大值、全局指数和、累计输出;
- 每处理完一块,就更新这三个变量;如果遇到更大的最大值,就把之前所有结果统一缩放;
- 全部块处理完,最后统一归一化。
👉 核心特点:
- 不需要提前加载、存储完整的整行数据,一块算完就丢,只保留统计量;
- 逐块推进 = 增量计算,完美配合 "分块不存大矩阵" 的设计;
- 数学结果和传统完整 Softmax 完全一致,不会出错。
Q12:跟原始Transformer论文中的绝对位置编码相比,RoPE(旋转位置嵌人)有什么优点?RoPE在长上下文外推时会面临什么挑战?
面试速记:
RoPE 用旋转乘法 替代绝对位置编码的加法注入 ,在计算注意力时天然只保留相对位置关系 ,外推性更强、不污染语义向量、兼容现有注意力;长上下文外推的核心挑战是低频维度旋转角度分布超出训练分布(OOD),导致注意力权重混乱、困惑度飙升。
基础术语释义:
- RoPE(Rotary Position Embedding):旋转位置嵌入,通过对词向量做旋转变换注入位置信息的编码方式。
- 绝对位置编码(Absolute Positional Encoding):原始 Transformer 用的正弦 / 余弦固定编码,为每个位置分配唯一向量并直接加到词嵌入上。
- OOD(Out-of-Distribution):分布外,指推理时遇到训练未见过的数值分布。
详解:
一、基础认知:箭头模型
把每个字词 看成纸上一根固定长度的箭头:
- 箭头长度:固定不变,代表单词本身的语义含义;
- 箭头朝向:用来标识单词在句子中的位置;
- RoPE 核心操作:单词位置越靠后,就把箭头向下转动更大的角度。
二、举例演示:小猫 抓 老鼠
1. 初始状态:三个词的箭头全部朝正右方,只保留词义,无位置信息。
2. 旋转箭头(添加位置)
-
- 第 1 位「小猫」:轻微向下转一点;
- 第 2 位「抓」:向下转动幅度更大;
- 第 3 位「老鼠」:向下转动幅度最大。
3. 模型判断词语关联:依靠两根箭头的夹角
-
- 夹角越小 → 词语关联越强;夹角越大 → 词语关联越弱。
- 相邻词「小猫」和「抓」:箭头角度接近,夹角小,判定关系紧密;
- 间隔词「小猫」和「老鼠」:箭头角度差距大,夹角大,判定关系疏远。
三、RoPE 核心优势:天然支持相对位置
在句子晚上 小猫 抓 老鼠中: 「小猫」和「老鼠」依旧只相隔 1 个位置,两根箭头的角度差、夹角和原句完全一致。
这说明:RoPE 只关心两个单词相隔几个位置(相对距离),不在乎单词在整句话的绝对序号。
对比原始 Transformer 绝对位置编码(老式方案)
老式编码:把位置箭头 和词语义箭头直接叠加融合。
- 弊端 1:位置信息混入语义,破坏单词原本含义;
- 弊端 2:模型死记 "第 1 位、第 2 位......" 这类绝对位置,遇到训练时没见过的超长位置,直接失效。
总结 RoPE 四大优点
- 天然适配相对位置,更贴合语言规律;
- 仅转动箭头方向,不改变长度,语义和位置互不干扰,训练更稳定;
- 旋转角度连续变化,句子拉长只需继续转箭头,长文本基础适配性更强;
- 词语距离越远,箭头夹角越大,注意力自然减弱,分布更合理。
四、RoPE 长文本外推的核心问题
真实场景中,一个单词不是单根大箭头 ,而是几十上百根独立小箭头组成的箭头束 。算法给不同小箭头设置了不同旋转速度,分为两类:
1. 两类不同转速的小箭头(类比钟表指针)
- 快箭头(类比秒针):转动极快 模型训练最长仅 4096 个词,这段距离里它已经反复转圈,所有朝向都被模型学熟。哪怕推理几万词的长文本,它只是继续转圈,全部是熟悉方向,不会出错。
- 慢箭头(类比时针) :转动极慢 每往后一个词,只转动极小角度。在 4096 词的训练范围内,它仅在很小一片朝向区间活动,模型只认识这部分方向。
2. 长文本外推为什么失效?
当推理远超 4096 词的超长文本时: 低速箭头必须继续转动,慢慢转出训练从未见过的全新朝向。 模型无法识别陌生方向,判断不准箭头夹角 → 注意力分配混乱 → 模型理解、生成内容变差。
3. 为什么设计 "快慢不同" 的箭头?
这是算法刻意分工:
- 快箭头:负责捕捉近距离词语关联;
- 慢箭头:负责捕捉远距离词语关联; 快慢搭配,才能完整表达所有位置关系,也正因转速不同,才产生了外推缺陷。
五、延伸思考:为什么不直接把训练文本拉到足够长?
直观想法:训练时让最慢的箭头完整转一圈,就能覆盖所有朝向,彻底解决外推问题。现实中无法实现,原因有三点:
- 硬件成本极高:序列越长,模型占用的显存、算力呈暴涨趋势,硬件、电费成本难以承担;
- 数据不足:很难收集大量高质量、连贯的几万词超长训练文本;
- 效果反向下滑 :序列过长会出现注意力稀释,注意力被大量单词分摊,模型抓不住短句重点。
六、业界主流补救方案(推理阶段优化)
不改动短文本训练的模式,在处理长文本时做算法修正:
- 位置插值:压缩超大旋转角度,把箭头拉回模型熟悉的区间,但会轻微扭曲特征,损失精度;
- NTK-RoPE / YaRN:仅微调低速箭头转速,兼顾精度与长文本能力;
- 混合训练:先用短文本完成主训练,再用少量长文本微调,让模型适应更大的转角。
第 4章 文本分类
Q13:嵌入模型+逻辑回归的分类方式获得了0.85 的F1分数,而零样本分类方式获得了0.78 的F1分数。如果有标注数据,什么情况下会选择零样本分类?
面试速记:
虽嵌入 + 逻辑回归 F1 更高,但在标注少 / 更新快、类别动态变化、多语言 / 跨领域、快速上线、成本受限 等场景,仍优先零样本;核心是零样本免重训、灵活、低成本、泛化强,牺牲部分精度换取工程与业务灵活性。
基础术语释义:
- 嵌入模型 + 逻辑回归(Embedding + Logistic Regression):传统两阶段分类方案,先将文本转为向量表征,再用有监督线性模型训练分类器,依赖标注数据,精度稳定但灵活性弱。
- 零样本分类(Zero-Shot Classification) :依托大模型语义理解与 Prompt,无需目标任务标注数据,通过自然语言描述类别完成分类,泛化性强。
详解:
已知条件:嵌入 + 逻辑回归 F1=0.85,零样本 F1=0.78,前者精度更优。结合业务与工程落地,以下场景会主动选择零样本分类:
1. 标注数据规模极小、质量差
- 场景:仅有几十条甚至更少标注样本,样本不均衡、存在大量噪声。
- 原因:小样本下,逻辑回归极易过拟合,泛化能力远不如零样本;且少量标注不足以训练出稳定分类器,实际线上效果可能低于 0.85。
- 选择逻辑:宁愿接受 78% 的稳定零样本精度,也不使用波动大、泛化差的有监督模型。
2. 分类类别频繁新增、删减、变更
- 场景:业务标签动态迭代(如电商临时活动标签、舆情热点分类、临时工单类型)。
- 原因:嵌入 + 逻辑回归每增减 / 修改类别,都需要重新标注、重新训练、重新部署,流程繁琐、迭代周期长;零样本仅修改 Prompt 里的类别描述,秒级生效,无需任何训练。
3. 业务领域 / 场景快速切换、跨领域使用
- 场景:一套模型需要支撑多个细分业务线、跨行业分类,或业务需求临时迁移。
- 原因:有监督模型强依赖训练数据分布,跨领域后精度会大幅跳水;零样本依托通用语义能力,领域迁移成本极低,适配多业务复用。
4. 上线要求极速、无训练 / 调优环境
- 场景:原型验证、临时需求、应急上线、PoC 测试,要求小时级甚至分钟级落地。
- 原因:嵌入 + 逻辑回归需要数据清洗、特征调试、模型训练、参数调优、版本部署,全流程耗时久;零样本直接调用模型 + 编写 Prompt,开箱即用。
5. 多语言、小语种分类场景
- 场景:需要支持中文之外的外文、小语种分类。
- 原因:小语种标注成本极高、数据稀缺;主流大模型零样本原生支持多语言,无需额外语种标注,而传统方案要针对每种语言单独标注训练。
6. 标注成本极高、预算 / 人力受限
- 场景:数据标注单价贵、专业门槛高(如医疗、法律、工业专业文本),人力不足以支撑持续标注。
- 原因:长期标注会产生持续人力与资金成本;零样本一次性配置 Prompt 即可长期使用,降低运营成本。
7. 推理侧灵活解读、可解释性要求高
- 场景:需要对外展示分类依据、人工核查结果、规则灵活调整。
- 原因:零样本可通过 Prompt 加入分类规则、判定标准,输出逻辑可解释;嵌入 + 逻辑回归属于黑盒模型,难以快速修改分类规则、解释判定原因。
8. 批量实验、方案快速对比
- 场景:探索不同分类维度、标签体系,做多组对照实验。
- 原因:零样本修改 Prompt 即可切换分类规则,实验效率极高;有监督方案每次实验都要重新造标注、训模型,效率低下。
两类方案核心取舍对比
表格
|-----------|------------------------|--------------------|
| 考量维度 | 嵌入 + 逻辑回归(F1=0.85) | 零样本分类(F1=0.78) |
| 精度表现 | 更高,静态场景效果稳定 | 略低,语义理解能力强 |
| 标注依赖 | 强,需足量高质量标注 | 无依赖,仅需文字描述类别 |
| 类别迭代 | 慢,改标签必须重训重部署 | 快,改 Prompt 即可生效 |
| 跨领域 / 多语言 | 弱,需单独标注训练 | 强,原生泛化能力好 |
| 落地周期 | 长(数据 + 训练 + 部署) | 极短,开箱即用 |
| 长期成本 | 高(持续标注、维护) | 低,一次配置长期使用 |
QI4:与BERT的掩蔽策略相比,掩码语言建模有何不同?这种预训练方式如何帮助模型在下游的文本分类任务中获得更好的性能?
面试速记:
掩码语言建模(MLM)就是 BERT 核心预训练任务 ,二者本质是同一套方案,日常说的 "BERT 掩蔽策略" 特指它随机掩码词元、特殊符号替换、混合篡改 的具体规则。 MLM 让模型学习双向上下文语义,能完整理解整句语境、字词搭配与语义逻辑,因此在文本分类这类语义理解任务上效果更优。
基础术语释义:
- 掩码语言建模(Masked Language Modeling,MLM):编码器类模型主流预训练任务,随机遮盖序列中部分词元,让模型根据上下文预测被遮盖内容。
- 掩蔽策略(Mask Strategy) :执行 MLM 时,对选中词元的替换 / 遮盖规则、比例、方式,是 MLM 的具体落地细则。
详解:
一、先理清基础概念
掩码语言建模(MLM) 就是 BERT 最核心的预训练任务,简单说: 把句子里一部分字词盖住(打码 / 掩码),让模型根据前后所有文字,猜出被盖住的内容。
举例子: 原句:我今天去公园散步 掩码后:我今天去 MASK 散步 模型要猜出:[MASK] 是 "公园"。
二、BERT 原版掩码 和 优化后掩码语言建模 的区别
题目问的就是这两者差异,分 2 个关键点,用人话讲:
1. 掩码时机:静态 vs 动态
BERT 原版(静态掩码)
提前把所有文本处理好,训练前就固定好哪些字要盖住 。 整个训练过程中,同一句话、被盖住的位置永远不变。 举例: 句子我爱吃苹果,预处理时固定盖住 "苹果",模型每轮训练看到的都是:我爱吃 MASK。 缺点:数据利用不充分,模型容易记答案,学不到新知识。
优化后的掩码语言建模(动态掩码)
训练的时候才随机选字盖住,每一轮训练,同一句话盖住的位置都不一样。 举例: 第一轮:我爱吃 MASK 第二轮:我 MASK 苹果 相当于一句话变出多种训练样本,数据更丰富。
2. 掩码单位:拆字 vs 整词
BERT 原版
按单个字符 / 拆分后的子词遮盖,可能把一个完整词语拆碎。 举例:词语 "机器人" 被拆成 3 个字,只盖住中间一个字,破坏了词语本身含义。
优化后的掩码(全词掩码 / 短语掩码)
只遮盖完整的词、完整短语,不拆分词汇。 举例:直接把 "机器人" 整个盖住,符合正常语言逻辑,模型学的语义更连贯。
总结区别: 原版 BERT = 提前固定位置、按单字遮盖; 新版 MLM = 实时随机遮盖、优先遮盖完整词语。
三、这种掩码预训练,为什么能让文本分类做得更好?
文本分类:比如判断句子是 "正面情绪 / 负面情绪"、"体育 / 科技新闻",核心是读懂整句话的整体意思。
掩码预训练从 3 个方面提升分类效果:
- 学会双向理解上下文(最核心) 它猜被盖住的词时,必须同时看左边 + 右边所有内容,不像老模型只能看单侧。 放到分类任务里,模型能完整理解整句话语义,不会断章取义,分类更准。
- 被迫抓核心语义,抗干扰能力变强 句子被随机盖住一些词后,模型不能只靠个别字判断,必须结合整体语境理解。 遇到句子里多余的修饰词、口语化表达,也能精准找到关键信息,分类更稳定。
- 动态 / 整词掩码的额外帮助
- 动态掩码:数据更多样,模型不容易 "死记硬背",泛化能力更强,陌生文本也能分对;
- 整词掩码:重点学习词语、短语的含义,而文本分类大多靠关键词判断类别,匹配度更高。
- 通用知识打底 预训练用了海量无标注文本,模型先学好了语法、词义、语言规律。后续做分类时,只需要少量标注数据微调,就能快速上手,效果远好于从零训练的模型。
Q15;假设你有一个包含100万条客户评论的数据集,但只有1000条带有标签的数据,请同时利用有标签和无标签的数据,结合表示模型和生成模型的优势,构建一个分类系统。
面试速记:
该场景是小样本半监督分类任务,结合表示模型 与生成模型 协同搭建系统: 首先用 1000 条标注数据微调BERT 等表示模型 作为分类主干;再利用生成模型对标注样本做数据增强,扩充训练数据;接着用初始分类模型 + 生成模型为百万级无标注数据生成高置信伪标签;最后采用自训练迭代方式,用标注数据 + 伪标签数据联合训练表示模型。推理阶段双模型结果交叉校验,充分发挥表示模型语义分类、生成模型数据扩充与伪标签生成的优势。
详解:
一、整体方案思路
数据集现状:1000 条标注数据 + 99.9 万无标注客户评论 ,属于典型小样本 + 半监督学习 场景。 结合要求:融合表示模型(BERT 等编码器,擅长语义理解、特征提取) + 生成模型(GPT / 编解码模型,擅长文本生成、数据增强、伪标签生成) 各自优势,搭建半监督文本分类系统,充分利用海量无标注数据提升泛化能力。
整体架构分为:数据层 → 特征表示层 → 半监督训练层(融合表示 + 生成模型)→ 推理部署层。
二、分步落地实现(全流程)
1. 数据预处理(统一清洗)
对全部 100 万条评论统一处理:去特殊符号、去重复、剔除无效短文本、统一大小写 / 分词; 划分数据集:
- 有标签数据 (1000 条):拆分为 训练集 800 条 + 验证集 200 条;
- 无标签数据 (99.9 万条):全部作为半监督辅助数据。
2. 模型分工:发挥两类模型核心优势
- 表示模型(仅编码器,如 BERT/RoBERTa/ 中文 ERNIE) :核心做语义特征提取、分类主模型,擅长挖掘评论深层语义,是分类任务主干;
- 生成模型(GPT/FLAN-T5) :核心做数据增强、伪标签生成、样本扩充,利用生成能力放大无标注数据价值,弥补标注样本不足。
3. 核心半监督方案(多策略组合,工业界常用)
阶段 1:有监督预训练(基于 1000 条标注数据)
先用 800 条标注数据,微调表示模型(BERT 类) 得到初始分类模型。 输入:客户评论;输出:分类标签概率分布。 作用:让模型先学习基础分类边界,作为后续半监督迭代的基线。
阶段 2:利用生成模型做数据增强(扩充有标注样本)
针对仅有的 1000 条标注评论,调用生成模型做语义等价改写、句式变换、近义扩写:
- 提示词约束:保留原评论语义、情感、核心观点,只改写句式 / 措辞;
- 每条标注样本生成 3~5 条增强样本;
- 把生成样本加入原始标注训练集,扩充有标签数据规模,缓解小样本过拟合。
优势:用生成模型低成本造高质量标注样本,不改变标签,强化分类特征。
阶段 3:生成模型产出伪标签(挖掘海量无标注数据)
这是利用百万级无标注数据的核心步骤:
- 把阶段 1 训练好的 BERT 分类模型作用于 99.9 万条无标注评论,预测初步标签;
- 设置置信度阈值 (如概率>0.9),筛选出模型高置信度预测结果,作为伪标签;
- 得到一批「无标注文本 + 伪标签」的可信样本。
进阶优化(融合生成模型) : 对置信度中等、边界模糊的无标注评论,改用生成模型做分类式生成 : 提示词:阅读这条客户评论,仅输出分类标签,不要额外内容,用生成模型补充伪标签,进一步扩大可信伪标签数据集。
阶段 4:半监督联合训练(表示模型为主,迭代优化)
采用自训练 (Self-Training) 范式,多轮迭代训练表示模型:
- 第一轮训练集 = 原始标注数据 + 高置信伪标签数据;
- 重新微调 BERT 表示模型,更新分类权重;
- 用更新后的模型再次对剩余无标注数据预测标签,筛选新增高置信样本;
- 循环迭代多轮,逐步把海量无标注数据融入训练,持续提升分类精度。
阶段 5:双模型融合校验(兜底提升鲁棒性)
推理阶段融合两类模型结果,降低错误率:
- 主推理:BERT 表示模型输出分类概率;
- 辅助校验:对低置信度样本,送入生成模型二次判定标签;
- 规则融合:两者结果一致则直接输出;不一致时结合业务规则 / 阈值兜底。
4. 补充优化策略(进一步提效)
- 对比学习预训练 先用全部 100 万条评论,对 BERT 表示模型做无监督对比学习,让模型先学习通用评论语义分布,再用少量标注数据微调,大幅提升小样本效果。
- 难样本筛选 对伪标签样本做难例挖掘,重点挑选分类边界样本参与训练,强化模型区分能力。
- 噪声过滤 伪标签不可避免存在噪声,设置动态阈值、交叉校验,剔除低质量伪标签样本,防止污染训练集。
第 5章 文本聚类和主题建模
Q16:有了强大的生成式大模型,嵌人模型还有什么用?(提示:推荐系统)
面试速记:
生成模型擅长理解、创作、对话、推理 ,但检索、匹配、召回、排序、海量向量库运算 效率与成本远不及嵌入模型。尤其在推荐系统中,嵌入模型负责亿级库快速召回、语义匹配、相似度计算、离线建库,是生成模型无法替代的底层能力;二者更多是分工协作而非互相取代。
基础术语释义
- 嵌入模型(Embedding Model) :将文本 / 图像 / 行为等信息映射为低维稠密数值向量,语义相近内容向量空间距离更近,主打相似度计算、检索匹配。
- 生成式大模型(Generative Large Language Model, LLM):以 GPT、LLaMA 等解码器架构为主,基于上下文逐 Token 生成连贯文本,强于语义理解、内容创作、逻辑推理、对话交互。
- 召回(Retrieval) :推荐 / 搜索第一阶段,从千万 / 亿级候选池中粗筛出少量高相关候选,要求超高吞吐、极低延迟。
- 排序(Ranking):对召回结果精细打分重排,产出最终推荐列表。
- 向量数据库(Vector Database):专门存储、索引、检索海量向量的数据库,依赖嵌入模型产出向量。
- 双塔模型(Two-Tower Model):推荐经典结构,用户塔、物品塔分别输出嵌入向量,用于快速匹配。
详解:
(一)核心底层差异:两类模型天生分工不同
- 计算范式与延迟差距巨大
生成模型是自回归逐 Token 生成 ,单次推理延迟高、算力消耗大,无法应对亿级候选、高并发、毫秒级响应 的场景。 嵌入模型是单次前向推理输出固定维度向量,计算简单、延迟极低、吞吐能力极强,天生适配大规模检索。
- 能力侧重完全不同
- 生成模型:做深度语义理解、内容生成、问答、理由解释、文案创作、多轮交互;
- 嵌入模型:做语义归一、相似度量化、近邻检索、特征压缩、匹配打分。
(二)结合推荐系统 + 通用场景,梳理嵌入模型不可替代的价值
1. 推荐系统核心:亿级物品库快速召回(最核心场景)
推荐流程标准链路:召回 → 粗排 → 精排 → 重排
- 业务现状:电商、内容 APP 往往拥有千万~亿级物品 / 内容池,不可能把全部候选送入大模型逐一打分。
- 嵌入模型做法: 离线阶段:对所有商品、文章、视频标题 / 描述 / 标签统一转成向量,存入向量库; 在线阶段:将用户画像、历史行为、当前 Query 转为用户向量,在向量库做最近邻检索,毫秒级捞出几百个高相关候选。
- 为什么生成模型做不了召回: 若用 LLM 对每一个物品逐一生成打分,亿级候选会带来天文级算力与延迟,线上服务完全不可行。
2. 语义匹配与内容去重、风控过滤
- 内容去重 / 相似内容聚类:资讯、短视频、UGC 平台,用嵌入向量判断内容是否重复、同质化,批量聚类;
- 相似商品 / 同款识别:电商识别同款、相似款商品;
- 违规内容粗过滤:基于向量相似度快速拦截已知违规内容,前置拦截降低大模型压力。 以上都是大规模两两相似度计算,嵌入模型效率碾压生成模型。
3. 离线特征工程与表征沉淀
- 把文本、评论、简介、用户评价转为统一向量,作为精排模型的输入特征,补充语义维度;
- 长期离线建库、特征缓存:嵌入向量可持久化存储,一次生成反复复用;生成模型输出无法直接作为标准化特征长期使用。
4. 跨模态检索与统一表征
图文、音视频、商品图文混合场景,嵌入模型可做多模态向量,实现以文搜图、以图搜文、跨内容检索; 生成模型主打内容生成,不擅长输出标准化、可检索的稠密向量。
5. 低成本批量处理、高并发线上服务
- 批量任务:每日全量物品更新向量、用户行为序列批量向量化,嵌入模型算力成本远低于 LLM;
- 高并发接口:搜索联想、实时推荐、相似推荐接口,QPS 极高,嵌入模型单机可承载数万并发,生成模型成本难以支撑。
6. 长文本、海量历史行为压缩表征
用户历史点击、浏览、购买行为是超长序列,嵌入模型可将整条行为序列压缩为固定长度向量,实现信息浓缩; 生成模型不擅长做 "特征压缩 + 相似度匹配",长序列输入还会触发上下文窗口限制。
(三)工业界主流架构:嵌入模型 + 生成模型 协同分工(面试高频)
现在主流方案不是二选一,而是前后链路配合,以推荐 / 搜索为例:
- 第一阶段(召回):嵌入模型 + 向量数据库 → 亿级库粗筛出百级候选(快、省、量大);
- 第二阶段(精排 / 润色):生成式大模型介入
-
- 对召回结果做精细化语义打分、重排序;
- 生成推荐理由、种草文案、个性化话术;
- 结合用户深层意图做个性化解读、交互式推荐。
典型链路总结:
嵌入模型负责「找得到、找得快、找得多」,生成模型负责「排得准、说得好、体验优」。
Q17:词袋法和文档嵌人在实现原理上有什么区别?词袋法是不是一无是处了?
面试速记:
词袋法只统计词频 / 存在性 ,无视语序、上下文与语义;文档嵌入将整段文本转为稠密语义向量 ,捕捉深层语义、语序与关联。词袋法并未淘汰,在高并发基线、简单分类、关键词统计、低成本场景仍有实用价值,胜在极简、极速、可解释。
基础术语释义
- 词袋法(Bag-of-Words,BoW):经典文本表示方法,把文本看成无序词汇集合,依靠词汇出现与否、出现频次表征文本。
详解
一、核心实现原理区别
1. 词袋法
核心:仅做词频统计,忽略语序、语法与上下文。
流程:文本分词 → 构建全局词表 → 依据词表,为每篇文档生成计数或 0-1 向量。
向量形态:属于高维稀疏向量 ,向量维度等于词表总数量。可以理解为一排数量极多的格子,绝大部分格子数值为 0,仅有少量位置存在有效数字。
特点:词语之间相互独立,无法表达语义关联。 举例:句子「我爱吃苹果」和「苹果爱吃我」,用词袋法得到的向量完全一致,无法区分语序差异。
2. 文档嵌入(句向量 / 文本嵌入)
核心:学习文本深层语义,兼顾词语、语序、上下文与语境关系。
流程:文本分词 / 子词切分 → 借助 Word2Vec、BERT、Sentence-BERT 等预训练模型编码 → 输出固定长度向量。
向量形态:属于低维稠密向量 ,维度远小于词表规模。可以理解为一排数量很少的格子,几乎没有数值为 0 的位置,每个格子都是有效数字。
特点:语义、表达相近的文本,对应向量距离也更近。 举例:「我爱吃苹果」和「我喜欢吃水果」语义相似,文档嵌入的向量相似度很高;同时也能区分语序颠倒的句子。
二、两种向量形态通俗解读
把向量统一想象成一排格子,维度就是格子总数量:
- 高维稀疏向量(词袋法)
格子数量极多,但绝大多数格子都填 0,只有少数位置有数字。
类比:制作一份总计 10000 人的班级签到表,当天仅 4 人到场,只在这 4 人对应的格子填写数字,剩余 9996 格全部填 0。
放到词袋场景:若词表共 10000 个词,句子「我爱吃苹果」仅在 "我、爱、吃、苹果"4 个词对应的格子填数,其余位置全为 0。这类向量仅记录词语是否出现、出现次数,不理解文本含义。
- 低维稠密向量(文档嵌入)
格子数量少,所有格子都填满有效数字,几乎没有 0。
类比:放弃万人签到表,改用 200 项综合评分表,每一项都填写分数,无空白位置。
放到嵌入场景:模型将整段文本压缩为 256 维向量,每一位小数都承载语义信息,完整浓缩句子的含义。
三、核心差异总结
表格
|--------|----------------|----------|---------------------------------------|
| 类型 | 外在形态 | 对应技术 | 能力特点 |
| 高维稀疏向量 | 列表很长,绝大多数数值为 0 | 词袋法 | 仅做词频统计,不区分语序、近义词,无语义理解能力;存储、相似度计算效率偏低 |
| 低维稠密向量 | 列表简短,全部为有效数值 | 文档嵌入 | 承载完整语义,可区分语序、理解近义表达;体积小,计算、检索效率更高 |
QI8:BERTopic中的c-TF-IDF与传统的TF-IDF 有何不同?这种差异如何帮助改进主题表示的质量?
面试速记:
传统 TF-IDF 是文档级 权重:词在单篇文档频、全局稀;c-TF-IDF 是主题(类)级 权重:把整个主题簇当一篇 "大文档",算词在主题内高频、跨主题稀有 。差异让 c-TF-IDF 能强区分主题特有词、抑制跨主题通用词、主题边界更清晰、关键词更一致,显著提升主题质量。
基础术语释译:
- TF-IDF
-
- 全称:Term Frequency-Inverse Document Frequency
- 中文:词频 - 逆文档频率
- 作用:经典文本权重算法,衡量词语对单篇文档的重要程度。
- c-TF-IDF
-
- 全称:class-based TF-IDF
- 中文:基于类别 / 聚类的 TF-IDF(BERTopic 专属变体)
- 补充:这里的
class指代聚类后的主题,所以也可理解为「基于主题的 TF-IDF」。
- TF
-
- 全称:Term Frequency
- 中文:词频
- 含义:某个词在指定范围内出现的频次。
- IDF
-
- 全称:Inverse Document Frequency
- 中文:逆文档频率
- 含义:衡量一个词在全局语料中的稀有程度,词越通用、出现越频繁,IDF 值越低。
- BERTopic :工具名,是基于 BERT 嵌入 + 聚类 + c-TF-IDF 实现的主题建模工具。
详解
引入场景,如平台有大量商品评论,一共分成两大主题:主题 1:手机评论 、主题 2:耳机评论
一、先讲 传统 TF-IDF
它的工作目标:给单独每一条评论,挑关键词
举其中 2 条单条评论:
- 手机评论:这款屏幕 很清晰,续航也够用,整体不错
- 耳机评论:这款音质 很棒,戴着舒服,整体不错
传统 TF-IDF 只会盯着单条评论内部统计词出现次数,再和全站所有评论对比。 它能找出每条评论里的重点词:屏幕、续航、音质、舒服。
暴露的问题
有一个通用词:不错 几乎每一条评论里都会出现。 传统 TF-IDF 没法有效区分,最终两个主题的关键词里,都会带上 "不错" 这种到处都有的词。 如果主题再多,通用词会越来越多,各个主题的关键词混在一起,分不清到底在讲什么。
二、再讲 c-TF-IDF(BERTopic 使用)
BERTopic 先把所有评论聚类,分出「手机主题」「耳机主题」两大块。 c-TF-IDF 不再看单条评论,而是:把同一个主题下的所有评论,合并成一大份整体,再和别的主题做对比
- 把全部手机评论看成一份大文本
- 把全部耳机评论看成另一份大文本
现在逐个看词语:
- 屏幕、续航:只在手机主题里大量出现,耳机主题几乎没有
- 音质、舒服:只在耳机主题里大量出现,手机主题几乎没有
- 不错、整体、很:手机、耳机两个主题里到处都是
c-TF-IDF 的规则: 抬高只属于当前主题 的词,狠狠压低所有主题共用的普通词。
同时它还有一个平衡作用: 哪怕手机主题有 10000 条评论,耳机主题只有几百条,评判标准也完全一样,不会因为评论多就占优势。
三、两者核心区别(总结)
- 计算对象不同 传统 TF-IDF:针对单条评论 / 单篇文档 c-TF-IDF:针对一整个主题(同类所有评论)
- 对比对象不同 传统 TF-IDF:词 vs 全站所有文档 c-TF-IDF:词 vs 其他主题
四、为什么 c-TF-IDF 能让主题质量更好?
- 主题分得更清楚 传统方式关键词会混杂 "不错" 这类通用词; c-TF-IDF 过滤掉通用词,最终: 手机主题关键词 → 屏幕、续航 耳机主题关键词 → 音质、佩戴 两个主题一目了然,边界清晰。
- 结果更公平稳定 有的主题评论多、有的评论少,不会影响关键词筛选结果。
- 自动减少无用噪声 语气词、泛化词汇会被自然降权,不用手动额外清理,关键词更纯粹。
Q19:基于质心和基于密度的文本聚类算法有什么优缺点?
面试速记:
基于质心(代表 K-Means) :速度快、易落地、可解释强;需提前指定簇数、对异常值 / 离群文本敏感、仅适配凸型、球形簇结构。
基于密度(代表 DBSCAN):无需预设簇数、能识别不规则簇、天然过滤噪声离群点;参数调优难、大数据量慢、高维文本(嵌入向量)效果易下滑。
基础术语释义
- 基于质心聚类(Centroid-based Clustering) :以簇中心(质心)划分样本,典型算法 K-Means,通过迭代更新质心完成聚类。
- 基于密度聚类(Density-based Clustering) :以样本局部稠密程度划分簇,典型算法 DBSCAN (Density-Based Spatial Clustering of Applications with Noise),稠密连通区域为同一簇,稀疏点视为噪声。
- 高维向量:文本嵌入后得到的稠密向量,文本聚类主流输入形式。
- 离群点 / 噪声:语义孤立、无法归入任何主题的文本。
- 凸簇 / 球形簇:样本围绕中心点近似球形分布;不规则簇:长条、嵌套、多形态分布。
详解:
一、先搞懂两种算法是怎么聚类的
把每一段文本(评论、文章、句子)都看成空间里的一个点,意思越相近的文本,点离得越近。
1. 基于质心(代表:K-Means)
核心思路
- 你提前想好要分成几类(比如确定分成 3 个主题);
- 先随机在空间里放 3 个中心点(质心);
- 把每个文本点,划分到离它最近的中心点这一类;
- 反复调整中心点位置,直到分类不再变化。
举例
一堆商品评论,你明确要分成「好评、中评、差评」3 类。 K-Means 就设 3 个中心点,慢慢把所有评论归到这 3 堆里。
2. 基于密度(代表:DBSCAN)
核心思路
不提前规定分几类。 看点的疏密程度:
- 一大片挤在一起的点 = 自动算作同一个类别;
- 孤零零、周围没几个点的文本,直接当成垃圾 / 噪声丢掉。
举例
一堆杂乱的用户吐槽,不知道有多少个主题。 DBSCAN 看到 "卡顿、闪退" 一堆点挨得近,自动归为一类;"价格贵、不划算" 挤在一起,又归为一类;单独一条无关广告,直接判定为噪声。
二、逐个讲优缺点(配场景,好理解)
(一)基于质心(K-Means)
优点
- 速度快,能处理大量文本 计算逻辑简单,百万、千万条文本也能快速分完,日常做评论、新闻聚类很实用。
- 结果整齐好使用 最终就分出你设定好的类别数量,后续给主题起名、统计分析都很方便。
- 上手简单 代码和工具都很成熟,调试难度低。
缺点
- 必须手动定分类数量 如果业务里不知道该分几类(比如新领域评论,不清楚有多少主题),只能一次次试,很麻烦。
- 容易被奇葩文本带偏 少数语义奇怪、偏离大众的文本(异常点),会拉扯中心点,导致整类分类不准。
- 只适合 "抱团规整" 的数据 如果不同主题的文本互相穿插、形状不规则,分类效果会变差。
- 初始中心点影响结果 一开始随机选的中心点不一样,最后分出来的类别也可能不一样,结果不稳定。
(二)基于密度(DBSCAN)
优点
- 不用提前定分几类 算法自己根据文本疏密分组,适合完全不清楚主题数量的场景。
- 啥形状的分组都能识别 哪怕文本交叉分布、形状奇怪,也能正常划分。
- 自动筛垃圾文本 零散、无关的噪声文本会直接识别出来,不用你额外手动清理。
缺点
- 参数特别难调 要设置 "多大范围算邻近、最少多少个点才算一类",参数稍微改一点,分类结果天差地别。
- 数据一多就很慢 文本向量是高维数据,海量文本下,挨个判断周边疏密,计算量极大,跑起来很慢。
- 怕疏密不均 如果有的主题文本特别密集、有的特别稀疏,容易把类别合并,或者拆出一堆没用的小类别。
- 类别数量不可控 可能分出几十个细碎小类,反而不利于后续归纳主题。
Q20:在一个主题建模项目中,你发现生成的主题中有大量重叠的关键词,如何使用本章介绍的技术来提高主题之间的区分度?
面试速记:
面对主题关键词大量重叠的问题,从数据、表征、聚类、关键词、标签生成全流程分步优化:
第一,做好数据预处理,提前剔除 "不错、服务" 这类通用词与语气词,从源头减少重叠词汇。
第二,优化文本表征,用文本嵌入向量 替代词袋稀疏向量,依托语义区分文本;同时对高维嵌入向量做降维,夯实聚类效果。
第三,优化聚类环节 :若使用K-Means ,合理设置聚类数量 K 并优化初始质心,避免分组混乱;若文本混杂穿插严重,改用DBSCAN识别并剔除噪声文本,让每个主题内容更纯粹。
第四,更换关键词提取方式,采用 BERTopic 的c-TF-IDF,结合词汇在单个簇和全簇的分布计算权重,压低跨主题通用词权重,突出各主题专属词汇。
第五,借助 BERTopic 模块化特性,使用最大边际相关性、KeyBERTInspired二次筛选关键词,过滤冗余、相近词汇。
第六,可接入FLAN-T5、GPT-3.5等生成式大模型,为主题生成专属标签,进一步提升主题辨识度与可解释性。 通过以上步骤,能够有效拉开主题边界,解决关键词重叠问题。
第6 章 提示工程
Q21: :针对翻译类、创意写作类、头脑风暴类任务,分别如何设置temperature 和 top_p?
面试速记:
翻译任务 :设置 temperature 0.2~0.4 、top_p 0.7~0.9 ,低温保证译文精准忠于原文,合适的 top_p 优化语句流畅度。创意写作 :设置 temperature 0.7~0.9 、top_p 0.9~0.95 ,提升内容创意与文笔多样性,同时保障行文连贯。头脑风暴 :设置 temperature 0.9~1.2 、top_p 0.95~1.0,最大化随机性,产出多元、新颖的思路与灵感。
详解:
基础参数释义
Temperature(温度) :控制模型的随机度与创造力 。数值越低,模型越保守 ,优先选用高概率词汇,输出固定、严谨;数值越高,模型越放飞,会选用更多低概率词汇,表达更多样,但容易出现语病、幻觉。主流取值范围 0~1.5。
Top_p(核采样) :按累计概率 筛选候选词。从概率最高的词开始累加,达到设定阈值后,剩余低概率词汇直接舍弃。数值越小,候选词池越窄 ,输出越规整;数值越大,候选词池越广,多样性越强。主流取值范围 0~1.0。
分任务讲解与实例
- 翻译类任务
核心要求:忠于原文、语义精准、句式规范,不允许自由发挥、篡改原意。 举例:中译英、专业文献翻译、双语对照文案。这类任务要压低创造力,保证译文准确通顺。 配置思路:低 temperature 锁定标准译法,中等偏上 top_p 兼顾语句流畅度,避免译文生硬死板。
- 创意写作类任务
核心要求:表达丰富、文笔灵活、有脑洞,同时保证行文连贯、不逻辑混乱。 举例:写小说、诗歌、短视频脚本、营销软文。需要适度发散,产出多元风格的内容。 配置思路:中高 temperature 激发创意,高 top_p 扩大词汇选择范围,在连贯的前提下提升文采。
- 头脑风暴类任务
核心要求:极致发散、答案多样、思路多元,不追求单一标准答案,鼓励新奇想法。 举例:活动策划点子、产品命名、选题构思、方案灵感。重点是产出大量差异化内容。 配置思路:高 temperature + 高 top_p,彻底放开候选词范围,最大化内容多样性,接受少量语句瑕疵。
Q22:一个专业的提示词模板由哪儿部分构成?为什么提示词中需要描述角色定义?
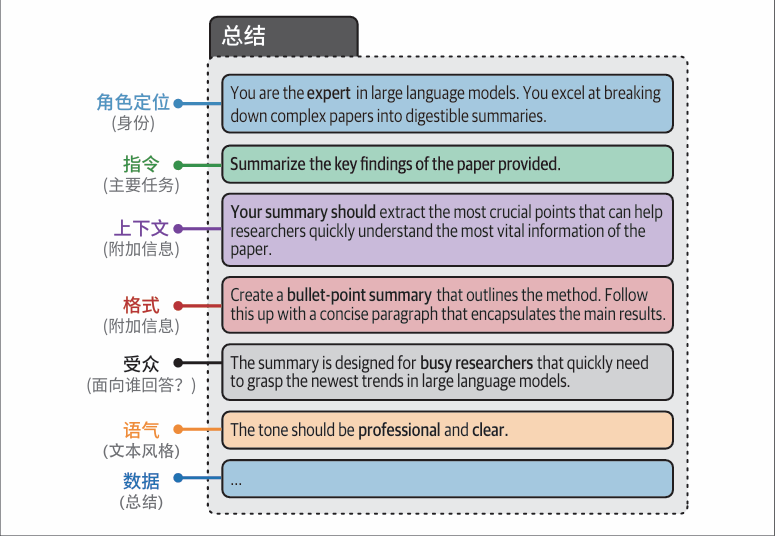
面试速记:
一套专业提示词主要由角色设定、背景信息、核心任务、约束要求、输出格式构成,也可按需增加参考示例。 设置角色定义,是为了给模型划定身份、专业能力与表达风格,让输出内容贴合场景、风格统一,提升结果质量。
详解:
一、专业提示词标准组成(通用 6 大模块,按需删减)
- 角色设定:明确身份、职业、专业能力、经验水平,划定行为风格。
- 背景信息:补充任务相关场景、前置内容、受众、业务背景,补齐上下文。
- 核心任务 :清晰说明具体要做什么,指令单一、明确,避免歧义。
- 约束规则:限定字数、语气、禁用内容、行文规范、禁忌要求等。
- 输出格式:指定排版、结构、分段、标签、条目形式,方便后续使用。
- 参考样例(可选):给出示范案例,让模型对齐风格与写法,进一步降低理解误差。
二、为什么提示词中需要描述角色定义?
大模型本身是通用模型,没有固定身份和思维习惯。 如果只说 "写文案",模型输出风格飘忽不定,可能写成说明书、散文或者硬广。 提前定义角色(电商文案师 / 翻译官 / 数据分析师),相当于给模型设定身份、专业能力、说话风格和思考逻辑,让它站在对应角色的视角做事,输出内容更贴合岗位专业度、风格统一,契合任务预期。
角色定义的核心作用
- 对齐能力与专业度:让模型调用对应领域的知识与表达逻辑,区分通用回答和专业输出。
- 统一风格与语气:比如顾问严谨、主播活泼、老师耐心,角色决定输出的语态。
- 划定思考视角:不同角色立场不同(如面试官、求职者、客服),角色决定回答的切入点。
- 减少无效输出:约束模型行为边界,避免答非所问、风格混乱、内容跑偏。
Q23:为了尽可能防止提示词注人,如何设计提示词模板?如何在系统层面检测提示词注人攻击?
面试速记:
一、防注入的提示词模板设计
设计模板核心是分层隔离,用结构化标签区分系统规则与用户数据,禁用纯文本拼接;明确系统指令优先级,划定行为红线并锁定角色权限;内置输入自检逻辑,同时固化输出格式,从提示词层面阻断注入攻击。
二、系统层面检测方案
系统采用多层防御:首先在请求入口通过规则匹配 + 轻量分类模型前置拦截恶意输入;推理阶段监控上下文、工具调用等异常行为;生成内容后做输出校验;配合审计日志、限流、人机审批等运维手段,实现全链路检测与防御。
详解:
(一)防注入的提示词模板核心设计规范
a. 强制分层隔离,禁用纯文本拼接
抛弃简单字符串拼接,采用结构化格式 (ChatML、JSON、自定义标签),严格区分系统角色 / 规则 、任务要求 、用户原始数据 三大区域,让模型明确区域属性,不混淆数据与指令。搭配唯一自定义分隔符,防止攻击者伪造标签绕过隔离。
b. 明确规则优先级与红线约束
在系统提示最前端强调:系统指令优先级高于一切用户输入;列出明确禁令:禁止忽略规则、禁止切换角色、禁止执行数据窃取 / 系统操作、禁止复述用户恶意指令。
c. 角色与权限最小化
固定模型身份、业务范围、可调用工具,遵循最小权限原则,不赋予额外能力,杜绝角色扮演类注入攻击。
d. 内置自检逻辑
在模板中加入自检流程:生成回复前校验输入,若存在诱导违规、篡改规则的内容,统一返回固定拒绝语,不继续处理业务。
e. 固化输出格式
强制限定输出结构(JSON、固定段落等),即便模型被诱导,也无法输出违规内容,形成最后一道模板防线。
f. 输入转义处理
模板引擎自动对用户输入做字符转义,防止攻击者闭合标签、伪造分隔符。
(二)系统层面多层检测方案(全链路)
分为前置检测、运行时检测、后置校验、运维兜底四大模块,工业界主流分层防御架构:
a. 第一层:前置网关检测(AI 网关 / AI 防火墙,请求入模型前)
-
- 规则匹配 :维护恶意关键词正则库,匹配
ignore instructions、泄露密码、切换角色等典型攻击话术,支持多语言、混合语种检测。 - 轻量模型分类:使用蒸馏小模型(DistilBERT、MiniBERT)、单分类器,对输入做语义判别,区分正常内容与注入攻击,兼顾速度与准确率,不影响线上延迟。
- 输入清洗:过滤特殊符号、嵌套指令、异常代码块,阻断 "提示词套提示词" 的嵌套攻击。
- 规则匹配 :维护恶意关键词正则库,匹配
b. 第二层:运行时动态检测(模型推理 & 多轮对话)
-
- 上下文检测:针对多轮对话,追踪历史交互,识别渐进式诱导、碎片化注入(多轮拼接恶意指令)。
- 行为监控:监控工具调用、API 请求,仅放行白名单内工具,拦截越权调用;限制递归、循环类异常逻辑。
- 语义一致性校验:检测模型行为是否偏离预设任务,问答模型突然执行命令、翻译模型突然窃取信息,判定为异常。
c. 第三层:后置输出校验(模型生成内容后)
审核输出内容,检查是否包含敏感信息、违规指令、被诱导生成的越狱内容,阻断信息泄露,作为兜底防线。
d. 第四层:运维与架构兜底
-
- 全量审计日志:记录所有请求、输入、输出、调用行为,日志防篡改,用于攻击溯源与规则迭代。
- 流量与频率管控:限流防批量爆破、模糊测试攻击;异常 IP / 账号直接封禁。
- 对抗训练迭代:收集攻击样本,定期对检测模型、主模型做对抗训练,提升鲁棒性。
- 人机熔断机制:高风险操作(删数据、导出文件)强制人工审批,自动熔断异常会话。
补充:常见攻击类型对应防御重点
- 直接注入(无视规则):靠模板优先级 + 前置规则检测防御;
- 角色扮演注入:靠角色锁定 + 语义分类检测防御;
- 嵌套 / 标签伪造注入:靠结构化模板 + 输入转义防御;
- 多轮渐进注入:靠多轮上下文监控防御。
Q24:在没有推理模型之前,如何让模型先思考后回答?思维链、自洽性、思维树等儿种技术各有什么优缺点?
面试速记:
在没有独立推理模型时,依靠提示词引导 + 少样本示例,要求模型分步拆解问题、输出思考过程,实现先思考再回答。
思维链 简单易落地,适合基础线性推理,但单路径易出错;自洽性 通过多轮推理投票纠错,准确率更高,缺点是算力开销变大;思维树支持多分支探索与回溯,复杂问题效果最好,但实现难度和资源消耗最高。
详解:
一、无额外推理模型时,实现「先思考再回答」
不用外挂推理模型,核心靠提示词工程引导模型分步思考,本质是通过话术强制模型拆解问题、梳理逻辑,再给出答案。
举例子:数学题「一个本子 5 元,买 4 本再优惠 3 元,一共花多少钱?」
- 普通提问:直接要答案,模型容易跳步算错。
- 引导思考版提示词:请你一步步分析计算,先算总价,再算优惠后金额,最后给出结果。 模型会先输出思考过程:① 4 本原价:5×4=20 元 ② 优惠 3 元:20-3=17 元,再给出最终答案,模拟 "先想后答"。
通用落地方式:
- 话术引导:明确要求分步推理、拆解问题、列出思路;
- 示例引导(Few-shot):给出 1~2 个 "思考过程 + 答案" 样例,让模型模仿格式;
- 格式约束:规定必须先写推理步骤,再写结论。
二、思维链、自洽性、思维树 通俗解读 + 优缺点
1. 思维链(CoT,Chain-of-Thought)
原理:让模型把推理中间步骤完整写出来,顺着逻辑链条逐步推导,是最基础的 "分步思考"。 如:解应用题、逻辑推理题,一步一步串联推导。
- 优点:实现简单,仅靠提示词就能落地;大幅提升算术、逻辑、常识推理能力;兼容绝大多数大模型。
- 缺点:长复杂问题容易逻辑跑偏、一步错步步错;单条推理路径,不验证答案对错;复杂多分支问题表现差。
2. 思维自洽性(Self-Consistency,SC)
原理 :基于思维链,多次采样生成多条不同推理路径,统计多数路径对应的答案,选出现频次最高的结果。相当于 "多想几条思路,少数服从多数"。如:同一道题让模型跑 5 轮推理,4 轮算出 17,1 轮算出 18,最终采信 17。
- 优点:修正单条推理的偶然错误,准确率远高于纯 CoT;实现难度低,无需改模型。
- 缺点:推理成本翻倍,耗时、算力变高;只是做结果投票,不优化推理逻辑本身;多答案场景、开放性问题不适用。
3. 思维树(ToT,Tree-of-Thought)
原理 :把问题拆解成多层推理节点,像树一样分出多个分支,评估每条分支的合理性,择优往下推进,还能回溯淘汰错误思路。 如:方案构思、多选择推理,每一步保留多个可行方向,淘汰明显错误分支。
- 优点:支持多分支探索、可回溯纠错;复杂决策、多选择、创意类难题推理能力最强;模拟人类多角度思考。
- 缺点:实现复杂,需要额外评分 / 筛选逻辑;分支越多,算力、耗时呈指数上升;简单小题 "杀鸡用牛刀",性价比极低。
Q25:如何保证模型的输出一定是合法的JSON格式?将大模型用于分类任务时,如何保证其输出一定是几个类别之一,而不会输出无关内容?如果开发一个学习英语的应用,如何确保其输出的语言始终限定在指定的词汇表中?
面试速记:
- 保证 JSON 格式:提示词强制要求仅输出 JSON 并附模板,配合模型格式参数;后端通过 JSON 解析做校验,解析失败则重试兜底。
- 分类限定类别:提示词枚举全部合法类别,禁止额外内容;后端清洗文本并匹配类别列表,异常输出统一兜底。
- 限定指定词汇表:提示词明确词汇范围与使用规则,后端逐词比对词表,检出违规词汇后重新生成内容。
详解:
(一)保证输出为合法 JSON(多层防护)
- 提示词层(第一道防线)
-
- 明确指令:仅输出标准 JSON 字符串,不要任何解释、换行注释、多余话术;
- 提供完整 JSON 模板与字段说明,固定键名、数据类型;
- 零样本 / 少样本给出正确示例,对齐格式。
- 模型配置层 开启模型原生格式约束(如 OpenAI
response_format、开源模型的格式强制参数),从推理阶段限制输出形态。 - 代码后置校验(兜底核心)
-
- 使用语言内置 JSON 解析器(Python
json.loads)解析结果,捕获解析异常; - 解析失败时触发重试机制,重试多次仍异常则返回预设默认 JSON;
- 校验字段名、字段类型、字段数量,防止键名错乱。
- 使用语言内置 JSON 解析器(Python
(二)分类任务限定输出在指定类别
- 提示词强约束
-
- 完整枚举所有合法类别,不使用模糊描述;
- 硬性要求:只能输出类别名称,不能扩充、改写、新增类别;
- 禁止补充理由、修饰语,必要时要求纯标签输出。
- 输出归一化处理
-
- 后端做文本清洗(去空格、大小写统一、符号过滤);
- 建立合法类别集合做精确 / 模糊匹配,命中则放行;未命中则归类为默认兜底类别,或触发重试。
- 进阶优化 少样本示例演示标准输出;对易混淆类别补充说明,降低模型发挥空间。
(三)英语应用限定输出在指定词汇表
- 提示词约束
-
- 明确给出目标词汇表,规定仅使用表内单词;
- 要求句式简单,禁止使用生词、俚语、复杂长难词;可附带示范例句。
- 词表校验拦截
-
- 分词拆分模型输出文本,逐词和标准词表比对;
- 检测到表外词汇,判定违规,让模型重新生成。
- 辅助限制 限制句子长度、句式结构;高频违规词汇单独列入禁用清单,双重管控。
第7章 高级文本生成技术与工具
Q26:如果我们需要生成小说的标题、角色描述和故事梗概,当单次模型调用生成效果不佳时,如何分步生成?
面试速记:
单 单次生成效果差,核心是任务复杂度高、上下文拥挤、指令混杂 。采用拆解任务 + 串行分步生成:先定核心故事框架,再生成角色描述,最后产出标题与梗概;每一步单独下发指令、承接上轮结果,还可搭配迭代润色、多候选择优,逐步提升最终质量。
详解:
一、核心思路
单次生成效果差,本质是任务复杂度高、多个创作目标互相干扰 。解决方案是拆解成串行 / 并行子任务,分阶段调用模型,前一步输出作为后一步的输入上下文,逐步细化、迭代打磨,同时每一步做校验与微调。
整体流水线:确定核心设定 → 分步产出标题 → 生成角色描述 → 撰写故事梗概,支持单环节多次迭代优化。
二、分步落地流程
阶段 1:统一基础世界观 / 核心设定
把模糊需求转化为明确上下文,避免后续创作跑偏,单独调用 1 次模型。
- 输入提示词:明确小说题材(玄幻 / 都市 / 校园)、风格、受众、核心主题、故事基调、核心冲突。
- 输出:一份精简的创作总设定(故事背景、核心主线、整体风格要求)。
作用:所有后续环节共用这份设定,保证标题、人设、梗概风格统一。
阶段 2:分步生成小说标题(多轮迭代,择优选用)
标题追求吸睛、贴合主题,单次容易平淡,采用多候选生成 + 筛选优化两步走:
步骤 1:批量生成候选标题
基于前置总设定,要求模型一次性产出 10~20 个不同风格标题(古风 / 直白 / 悬念风等),不做限制,充分发散。
步骤 2:筛选 + 精修标题
方案 A(模型筛选):把候选标题 + 创作设定传给模型,要求从列表中选出最优 3 个,并分别微调润色,提升吸引力。 方案 B(人工 + 模型结合):人工初选后,让模型对保留标题做改写、强化悬念 / 氛围感。
最终确定1 个主标题 + 备选标题,作为下一环节的输入。
阶段 3:分步生成角色描述(由粗到细,分层构建)
角色描述包含身份、外貌、性格、身世、人物动机,信息量大,拆分基础人设 → 细节润色两步:
步骤 1:生成基础角色框架
结合总设定 + 已定标题,要求模型列出核心角色名单,并为每个人物输出极简人设:姓名、身份、立场、核心性格、在故事中的作用。
步骤 2:丰富细节描述
将基础人设再次输入模型,分角色逐一 / 批量扩充:补充外貌特征、口头禅、过往经历、人物弱点、人物关系。
可选迭代:人设一致性校验
把全部角色描述 + 故事主线交给模型,检查人物关系、性格逻辑是否冲突,发现矛盾处自动修正。
阶段 4:分步生成故事梗概(由简到繁,逐级扩写)
梗概是整体剧情浓缩,直接写长梗概容易逻辑混乱、情节跑偏,采用大纲骨架 → 完整梗概两级生成:
步骤 1:生成剧情大纲(分阶段骨架)
输入:总设定 + 标题 + 完整角色描述。 要求模型按照「开端 - 发展 - 高潮 - 结局」四幕结构,写出极简剧情大纲,只梳理关键情节节点,不做细节描写。
步骤 2:扩写为正式故事梗概
以剧情大纲为基础,要求模型串联所有节点,补充情节细节、人物互动,扩写成流畅完整的故事梗概。
可选迭代:整体复盘优化
把标题、人设、梗概全部汇总,让模型通读全文,统一文风、修正逻辑漏洞、删减冗余内容,完成最终定稿。
三、优化技巧(提升分步生成效果)
- 控制单轮输出长度 每个子任务只聚焦单一目标,不要一请求内同时写标题 + 人设 + 梗概,减少任务干扰。
- 复用上下文 每一步都带上前面所有已产出内容(设定、标题、人设),保证全篇风格、逻辑统一。
- 失败重试机制 若某一步输出偏离要求(如人设崩坏、梗概跑题),加入修正指令 重新调用,例如:
结合原有设定,重新优化角色描述,保持风格一致。 - 参数配合 创作类任务可适当调高
temperature增加创意,单环节择优时小幅降低参数保证规整度。 - 长短任务拆分 长篇小说可再拆分:主线梗概 → 分卷梗概,进一步降低单轮生成压力。
Q27:如果用户跟模型对话轮次过多,超出了模型的上下文限制,但我们又希望尽可能保留用户的对话信息,该怎么办?
面试速记:
对话轮次过多超出上下文限制时,可分层处理:基础场景用滑动窗口 保留最近轮次;通用场景对早期对话摘要浓缩 ,用短摘要替代原始长文本;业务场景提取结构化关键信息 ;超长深度对话搭配RAG 检索召回相关历史。同时配合内容清洗、动态截断,最大化保留有效信息。
详解:
一、核心思路
上下文窗口不足的本质:历史对话总量超出模型可接收最大长度。 核心解决方向:压缩历史信息、分层存储对话、动态裁剪、摘要浓缩、检索召回,在有限窗口内最大化保留有效语义,丢弃冗余内容。
二、主流落地方案
方案 1:动态滑动窗口(基础,优先使用)
原理
不保留全部历史,采用滑动窗口 ,只截取最近 N 轮对话放入上下文,老旧对话直接舍弃。
适用场景
闲聊、日常对话、短交互场景,对久远历史依赖低。
优缺点
- 优点:实现最简单、开销为零、延迟低;
- 缺点:彻底丢失早期对话信息,多轮深度对话会断层。
方案 2:历史对话摘要浓缩(最通用,业界主流)
原理
当轮次快要触达上下文上限时,单独调用模型 把早期多轮历史对话浓缩成一段简短摘要,用摘要替代原始长文本,大幅缩减字符长度;仅保留近期几轮完整对话 + 全局摘要,一并送入窗口。
细分用法
- 全局摘要:所有早期对话合并为 1 段总摘要,搭配最新几轮原话;
- 分段摘要:对话按时间切片,每一段生成子摘要,进一步保证细节;
- 增量摘要:每新增一定轮次,就更新一次摘要,不用重复处理全部历史。
优缺点
- 优点:大幅压缩长度,保留核心语义、人物诉求、关键上下文,兼顾信息完整性与窗口限制;适配绝大多数聊天、客服、助手场景;
- 缺点:额外增加模型调用,有少量耗时与算力开销;极端情况下摘要会丢失细枝末节。
方案 3:关键信息提取 + 结构化归档(偏向业务 / 客服场景)
原理
不做纯文本摘要,让模型从历史对话里抽取结构化关键信息:用户身份、核心诉求、已沟通内容、待解决问题、禁忌要求、历史结论等,以 JSON / 条目形式存储。 上下文里只放结构化关键信息 + 最新对话。
适用场景
客服、咨询、办理业务、问答类对话,有明确业务目标。
优缺点
- 优点:信息密度极高,几乎无冗余,关键内容一目了然;便于后端系统解析;
- 缺点:不适合纯闲聊、情感对话、创意类对话,会丢失语气、闲聊细节。
方案 4:RAG 检索召回(高阶方案,长会话 / 深度对话首选)
原理
- 把全量历史对话全部向量化,存入向量数据库;
- 新问题进来后,先做语义检索,从历史中召回和当前问题强相关的片段;
- 仅将「相关历史片段 + 摘要 + 最新对话」拼装进上下文窗口;
- 无关的老旧对话不放入窗口,只做冷存储。
适用场景
超长多轮对话、知识库问答、长文档伴随对话、专业咨询。
优缺点
- 优点:精准保留关联历史,彻底突破窗口物理限制,信息利用率最高;
- 缺点:架构复杂,需要向量库、嵌入模型,开发与运维成本高。
方案 5:分层记忆体系(产品级方案,大厂通用)
结合以上多种方式做分层,区分「短期记忆」「长期记忆」:
- 短期记忆:最近 3~5 轮完整对话,原样放入上下文,保证对话流畅;
- 中期记忆 :更早的对话,统一生成全局摘要放入上下文;
- 长期记忆 :超久远、低频使用的对话,向量化存入向量库,仅当当前问题需要时才检索召回,平时不进上下文。
三、配套辅助优化手段
- 内容清洗 自动剔除重复语句、语气词、无意义寒暄、表情、换行空格等冗余字符,瘦身原始对话。
- 动态截断策略 优先截断最老旧、语义价值最低的内容,而非随机裁剪。
- 分级阈值触发 设定两级阈值:
-
- 预警阈值:对话长度接近上限,自动触发摘要 / 清洗;
- 硬阈值:达到窗口最大值,强制裁剪 + 摘要。
- 对话角色精简 简化
user/assistant标记、分隔符格式,减少格式占用字符。
Q28:如何编写一个智能体,帮助用户规划一次包含机票预订,酒店安排和景点游览的旅行?需要配置哪些工具?如何确保系统在面对不完整或矛盾的信息时仍能提供合理建议?
面试速记:
1. 智能体编写与工具配置
该旅行规划智能体基于大模型 + 工具调用架构开发,流程为:解析用户需求→提取出行信息→调用工具查询数据→校验信息→整合生成旅行方案。 必备工具分为三类:一是机票、酒店、景点三大核心查询预订工具;二是日期、地理导航、预算核算等辅助校验工具;三是内置信息抽取、多轮对话管理模块。
2. 应对不完整 / 矛盾信息
信息不完整时,先识别缺失字段,按优先级多轮追问 ;非必填项设置默认规则兜底。 信息存在矛盾时,先自动修正笔误类冲突;无法判定则向用户确认;遇到预算、行程过载等硬冲突,主动提供折中替代方案,保证输出合理可用的建议。
详解:
一、智能体整体设计思路
这是任务型多工具调用智能体 ,核心基于大模型智能体框架,串联「意图理解→工具调用→信息补全→冲突校验→方案生成」全流程,一站式完成机票、酒店、景点旅行规划。整体分为智能体核心逻辑、所需工具配置、异常信息处理三部分,同时附面试口述版本。
二、智能体开发流程 & 核心模块
(一)整体运行流程
- 意图与信息解析:大模型解析用户输入,提取出发地、目的地、出行日期、出行人数、预算、偏好(景点类型、酒店档次、航班时段)等关键信息,识别缺失项、矛盾项。
- 多轮追问补全:针对不完整信息,主动向用户发起追问,补齐必要参数。
- 工具路由调用:根据规划环节,依次调用机票、酒店、景点、地图等工具查询数据。
- 信息校验与冲突消解:检测时间、地点、预算等矛盾信息,自动修正或引导用户确认。
- 方案整合生成:汇总所有工具返回数据,输出完整旅行方案(行程 + 机票 + 酒店 + 景点安排)。
- 迭代优化:支持用户二次修改需求,重新调用工具更新方案。
(二)必须配置的工具(按功能分类)
结合旅行规划三大核心业务,分为基础查询工具、辅助校验工具、交互工具三大类:
1. 核心业务工具(刚需,对应三大规划场景)
- 机票查询 / 预订工具 接口能力:按出发地、目的地、出发 / 返程日期、出行人数查询航班、起降时间、航空公司、票价、余票;支持筛选(直飞 / 中转、早 / 午 / 晚航班、舱位);对接预订下单接口。
- 酒店查询 / 预订工具 接口能力:按目的地、入住 / 离店日期、入住人数、预算、位置偏好(近景区 / 市中心 / 交通枢纽)查询酒店、房型、价格、评分、设施;支持筛选星级、民宿 / 酒店分类。
- 景点查询 & 游玩规划工具 接口能力:查询目的地热门景点、开放时间、门票价格、游玩时长、地理位置、游客评价;支持按游玩天数、风格(自然风光 / 人文 / 亲子)自动编排游览路线。
2. 辅助支撑工具(保障方案合理、可用)
- 日期 / 日历工具 校验日期合法性、区分工作日 / 节假日、计算行程总时长、入住离店间隔,避免时间逻辑错误。
- 地理距离 & 交通导航工具 查询景点之间、景点与酒店、机场 / 车站与酒店的距离、通勤时长、交通方式,合理排布每日行程,避免路线绕路。
- 预算核算工具 汇总机票、酒店、景点门票总价,对比用户预算,自动提醒超支、推荐平价替代方案。
- 天气查询工具(可选推荐) 查询目的地出行期间天气,给出穿搭、户外景点调整建议。
3. 智能体内置能力(非外部接口,模型层能力)
- 信息抽取工具 :从用户对话中提取结构化出行参数;
- 多轮对话管理:记录上下文、历史需求、已补全信息;
- 冲突检测引擎:识别矛盾信息;
- 方案格式化生成器:整合数据输出结构化旅行方案。
三、应对「信息不完整、信息矛盾」的解决方案
(一)处理信息不完整(缺出发地、日期、人数、预算等)
采用 「缺失字段识别 + 分级多轮追问 + 默认兜底规则」 三层策略:
a. 第一步:结构化字段校验
预先定义旅行规划必填字段清单:出发城市、目的城市、出行日期、返程日期、出行人数; 智能体解析用户输入后,逐一比对字段,标记所有缺失项。
b. 第二步:分优先级多轮追问
核心必填项(无则无法查询工具):优先一次性集中追问,例:"我还需要了解你的出发城市、出行日期和同行人数,以便为你查询机票和酒店";
非核心偏好项(酒店档次、景点风格、预算):柔性询问,同时提供选项,降低用户输入成本;
追问遵循一轮少问多项原则,避免频繁单条追问打扰用户。
c. 第三步:默认规则兜底(用户不愿补充时)
对非必填信息设置行业通用默认值,保证方案可正常生成:
无预算:默认中档价位;
无酒店偏好:默认市中心交通便利型酒店;
无景点偏好:默认当地经典热门景点组合。
(二)处理信息相互矛盾(时间、地点、预算、逻辑冲突)
采用 「冲突识别 + 自动修正 + 主动确认 + 方案折中」 四步处理:
常见矛盾场景举例
- 时间矛盾:入住酒店日期晚于离店日期、返程日期早于出发日期;
- 地点矛盾:要求 "住在 A 景区",又要求 "全程游玩 B 片区景点",两地距离极远;
- 预算矛盾:总预算过低,机票 + 酒店基础费用已超出预算;
- 逻辑矛盾:单日安排 8 个景点,单景点游玩时长叠加远超单日合理时间。
具体处理方案
- 实时冲突检测 调用日历、地理、预算工具做交叉校验,主动识别逻辑冲突,不直接执行工具查询。
- 轻度冲突:智能自动修正 针对明显笔误类冲突,按常识自动修正,并告知用户。 例:用户填 "入住 10.5,离店 10.3",自动调换日期并提示:"检测到入住离店日期有误,已为你调整为 10.3 入住、10.5 离店"。
- 中度冲突:引导用户二次确认 无法自主判断意图时,明确指出矛盾点,给出可选方案让用户选择。 例:"你选择的酒店位于郊区,距离核心景点通勤需要 1.5 小时,是否更换市中心酒店,或保持当前选择?"
- 严重冲突:折中方案 + 替代推荐 预算不足、行程过载等硬冲突,不强行执行原需求,主动输出折中建议:
-
- 预算超支:推荐低价航班、经济型酒店、免费景点,拆分精简行程;
- 单日景点过多:删减部分景点,拆分至次日,保证游玩体验。
(三)通用兜底机制(全局保障)
- 容错对话设计:允许用户反复修改信息,智能体实时更新结构化参数,重新调用工具;
- 弱推荐策略 :信息残缺 / 冲突较多时,不输出精细方案,改为通用旅行模板 + 灵活建议;
- 边界提示:明确告知用户 "当前信息不足,方案为参考版,补充信息后可生成精准规划"。
Q29:如果单一智能体的提示词过长,导致性能下降,如何将其拆分为多个智能体,并在合适的时机调用不同的智能体?
面试速记:
单一智能体提示词过长时,采用调度中枢 + 多垂直子智能体的拆分方案。按照业务功能拆分为多个专用子智能体,每个子智能体只负责一项任务、精简自身提示词。 由轻量化的调度中枢统一做意图识别、状态管理和任务分发:按会话状态与需求,在对应时机调用不同子智能体;无依赖任务可并行调用。同时搭配全局会话存储、统一输出格式,保证多智能体协同顺畅,最终解决提示词过长导致的性能下降问题。
详解:
一、问题核心分析
单一智能体提示词过长,会占用大量上下文窗口、增加模型理解负担、拉高推理延迟、提升幻觉概率。核心拆分思路:按职责 / 任务域解耦为多个专用子智能体 ,搭配调度中心(主智能体 / 路由模块) 统一分发任务、串联流程,实现各司其职、按需调用,缩短单个智能体的提示词长度,提升整体性能。
二、整体架构设计
采用 「调度中枢 + 多个垂直子智能体」 分布式架构,完全拆分长提示词与复杂逻辑:
- 调度中枢(路由智能体 / 规则调度器) :轻量化设计,提示词极简,只负责意图识别、任务分发、流程串联、结果汇总、异常兜底,不处理具体业务细节。
- 垂直子智能体 :每个子智能体只负责单一细分任务,提示词仅保留自身职责、规则、格式要求,提示词大幅缩短,专注专项能力。
- 共享层:统一上下文存储、工具调用接口、公共配置,供所有智能体共用。
三、拆分原则 & 拆分维度(怎么拆)
结合业务场景,常用 4 种拆分方式,可单独或组合使用:
1. 按业务功能 / 任务域拆分(常用)
把复杂大任务拆成串行 / 并行的子任务,每个任务对应一个专用智能体。
举例:旅行规划原单智能体 → 拆分为:
- 信息采集智能体:仅负责提取出行信息、追问补全缺失内容、校验基础矛盾
- 机票查询智能体:仅对接机票工具、筛选航班、整理航班方案
- 酒店规划智能体:仅查询酒店、匹配位置 / 预算、输出酒店推荐
- 景点 & 行程编排智能体:仅规划景点路线、排布每日行程
- 方案整合智能体:汇总所有结果,生成最终结构化旅行方案
2. 按能力类型拆分
区分「理解类、工具调用类、生成类、校验类」,各司其职:
- 语义解析智能体:意图识别、信息抽取
- 工具调用智能体:统一管理外部 API / 工具请求
- 内容生成智能体:文案、方案、话术输出
- 合规 / 校验智能体:检查冲突、错误、违规内容
3. 按对话阶段拆分(多轮对话场景)
根据会话流程分段拆分,不同轮次调用不同智能体:
- 首轮接待 & 信息收集智能体
- 中期查询 & 资源匹配智能体
- 后期方案优化 & 答疑智能体
4. 按权限 / 风险等级拆分(风控敏感场景)
普通咨询、高危操作、数据修改分属不同智能体,隔离逻辑、精简提示词。
四、调度逻辑:何时调用、如何流转
调度中枢是核心,分规则路由 和大模型路由两种实现,适配不同复杂度:
(一)简单场景:规则化调度(低延迟、高稳定)
适合流程固定、任务顺序明确的场景,用配置 + 条件判断分发,不依赖大模型:
- 预设任务流转链路与触发条件、状态标记;
- 调度中枢记录当前会话状态(信息收集中 / 查机票中 / 编排行程中);
- 按状态触发对应子智能体,执行完成后回传结果,更新状态,进入下一环节。
流转示例(旅行规划)
- 用户发起请求 → 状态 = 信息收集 → 调用【信息采集智能体】
- 信息缺失 → 继续由该智能体追问;信息完整无冲突 → 状态切换为资源查询
- 并行 / 串行调用【机票智能体】+【酒店智能体】+【景点智能体】
- 全部查询完成 → 状态切换为方案生成 → 调用【方案整合智能体】
- 输出最终方案,会话结束;用户提出修改 → 回退对应环节重调用子智能体。
(二)复杂场景:大模型路由智能体(灵活适配不确定请求)
适合用户请求灵活、分支多、流程不固定的场景:
- 路由智能体(提示词极短)仅做两件事:理解当前用户需求 + 选择目标子智能体;
- 输入当前对话内容、历史状态、子智能体能力清单,由路由决策调用哪一个 / 多个子智能体;
- 子智能体执行完毕,结果回传给路由,由路由判断:继续调用其他子智能体、直接回复用户、还是二次修正。
调用时机总结
- 初始会话:路由优先调用「信息解析 / 信息采集」类前置智能体;
- 进入业务环节:根据需求领域,调用对应垂直业务智能体;
- 数据 / 资源查询阶段:统一调用工具类智能体;
- 收尾阶段:调用整合、润色、校验类智能体;
- 用户二次修改 / 追问:路由定位修改内容,精准调用对应子智能体,不全链路重跑。
(三)并行调用场景
若多个子任务无依赖关系(如同时查机票、酒店),调度中枢可并行触发多个子智能体,提升整体响应速度。
五、关键配套优化(保证拆分后系统可用)
1. 上下文统一管理
- 搭建全局会话存储,所有智能体共享结构化信息(用户参数、中间结果、历史对话),避免重复提问、信息丢失;
- 子智能体仅读取当前任务所需字段,不用加载全量历史,进一步降低单轮输入长度。
2. 提示词精简原则(子智能体)
每个子智能体提示词只保留:
- 自身唯一职责
- 专属规则、输出格式、约束
- 必要的少量示例剔除全局规则、其他业务逻辑,从根源解决提示词过长问题。
3. 结果透传与格式统一
所有子智能体强制输出统一结构化格式(JSON / 固定字段),方便调度中枢解析、拼接、流转,降低多智能体协同出错概率。
4. 异常与容错机制
- 子智能体执行失败 / 输出异常 → 调度中枢捕获异常,重试或切换兜底逻辑;
- 跨智能体信息冲突 → 触发独立的校验智能体统一修正;
- 未知请求 → 路由转发给兜底问答智能体。
5. 层级隔离,避免递归膨胀
禁止子智能体再嵌套多层智能体,保持「调度中枢 ↔ 一级子智能体」扁平架构,控制复杂度。
六、优缺点总结
优点
- 单个智能体提示词大幅缩短,减少上下文占用、降低推理延迟、减少幻觉;
- 能力解耦,单个子智能体职责单一,专项精度更高;
- 模块化架构,便于迭代、单独升级、运维、排错;
- 支持并行调用,提升整体响应速度。
缺点
- 架构复杂度提升,需要额外开发调度、会话存储模块;
- 多智能体协同会产生少量跨模块交互开销;
- 需要统一格式、状态管理,前期设计成本更高。
第8 章 语义搜索与RAG
Q30:在RAG中,为什么要把文档划分成多个块进行索引?如何解决文档分块后内容上下文缺失的问题?如何处理跨片段的依赖关系?
面试速记:
1. 为何分块索引
一是受模型上下文窗口限制,全文无法直接输入;二是小块语义更聚焦,提升检索精度;同时降低向量化、存储与查询的开销。
2. 解决上下文缺失与跨片段依赖
首先采用重叠分块 做基础兜底;再使用语义分块 按语义边界切割,从源头减少拆分断裂。 针对跨片段依赖:通过层级父子块、邻块 ID 关联 召回周边片段,搭配文档 / 块摘要补充全局信息;最后对召回结果按原文顺序拼接、重排,还原完整逻辑与跨块关系。
详解:
一、为什么 RAG 需要对文档分块(切片)索引
核心原因围绕模型上下文限制、检索精度、检索效率、向量质量四点:
- 受大模型上下文窗口约束 原始整篇文档往往长度远超模型单次输入上限,无法直接将全文送入模型做问答 / 推理,必须拆分为短块。
- 提升检索相关性与精度 向量检索是局部语义匹配。全文向量会融合大量无关内容,语义特征模糊;拆分成细粒度块后,单块语义更聚焦,检索能精准命中和用户问题相关的片段,减少噪声。
- 降低向量计算与存储开销 长文本向量化效果差、计算耗时久;分块后单块长度可控,向量化更快,向量库存储、索引、查询压力更小。
- 优化召回逻辑 检索阶段只召回少量相关块,而非整篇文档,减少后续拼接、推理的冗余内容,降低幻觉概率。
二、分块后上下文缺失、跨片段依赖的解决方案
(一)通用补全上下文方案
1. 重叠分块(滑动窗口分块,最基础常用)
- 做法:相邻文档块设置固定重叠长度,比如块大小 500 字符,重叠 100 字符。前后块保留一部分重复内容。
- 作用:天然衔接相邻片段,缓解块边界处语义断裂、短句被拆分的问题,低成本保留局部上下文。
- 适用:通用文本、知识库、文章类场景。
2. 块附加全局 / 段落摘要
- 做法:
-
- 对整篇文档生成全局摘要;
- 对每个分块所在的章节、段落生成局部摘要;
- 向量库中同时存储「块原文 + 上级摘要」。
- 检索召回时,块原文 + 对应摘要一同送入 LLM,补充文档整体背景与上下文。
3. 层级化分块(父子块 / 层级索引)
构建两级 / 多级索引:
- 粗粒度父块:大章节、整篇段落,保留完整上下文;
- 细粒度子块:用于精准检索的小切片。 流程:
- 检索先命中细粒度子块;
- 根据子块关联 ID,找到所属父块;
- 子块 + 父块内容一起拼接输入模型,补齐上下文。
(二)专门处理跨片段依赖
跨片段依赖 :原本连贯的语义、语句、逻辑、指代、数据、论证关系,因为文档被切分成多个文本块,完整内容被拆分到两个或多个不同块中,单靠任意一个独立块都无法理解完整含义,必须结合多个片段才能读懂、答准问题。
1. 块关联链路 + 邻块召回(近邻扩充)
- 给每个分块标记前后相邻块 ID,构建链表关系;
- 召回目标块后,主动附带其前 N 块、后 N 块,把连续语义片段完整拼接,解决跨块语句、指代、连续论述问题。
- 例:问题对应第 5 块,自动拼接 3/4/5/6/7 块,还原完整逻辑链。
2. 语义聚合分块(按语义边界切,而非纯字符截断)
放弃固定长度硬切割,基于语义、分句、章节、标题、段落边界分块:
- 依据标题、换行、语义结束符、语义相似度识别段落边界;
- 保证一个完整语义单元不被强行拆分,从源头减少跨块依赖。
- 工具:结合分词、语义模型判断句子关联性,语义紧密的句子合并为一个块。
3. 检索后上下文拼接与重排(Rerank + 上下文融合)
- 向量检索召回一批相关块(包含目标块 + 周边关联块);
- 使用重排模型(Reranker)按语义相关性 + 位置顺序重新排序;
- 按原文先后顺序拼接所有块,恢复文档原有语序,消解跨块逻辑混乱。
4. 跨块实体 / 指代统一解析
- 抽取文档内实体、名词、代词、专有名词,建立全局实体索引;
- 若某个块出现代词、简写、局部概念,自动关联包含该概念完整解释的其他块,一并召回。
5. 动态合并块(推理时按需融合)
- 检索阶段召回多个分散但语义相关的片段;
- 送入 LLM 前,根据问题语义,动态合并多个离散块为一段完整文本,再进行问答。
6. 长文本专用:上下文窗口拓展 + 块续写补全
针对强长距离依赖场景:
- 适当调大分块尺寸,在向量效果可控前提下减少切块数量;
- 利用大模型对孤立块做上下文补全,基于块内容还原前后语义。
三、工程组合方案(业界主流落地搭配)
- 基础标配:固定大小分块 + 合理重叠(优先使用),解决轻度上下文丢失;
- 标准进阶:语义分块 + 层级父子块索引 + 邻块召回,处理大部分跨片段依赖;
- 复杂长文档 / 专业文档:叠加「摘要附加 + 实体索引 + 召回后重排 + 顺序拼接」整套方案。
Q31: 向量相似度检索不能实现关键词的精确匹配,基于倒排索引的关键词检索不能匹配语义相近的 词,如何解决这对矛盾?为什么需要重排序模型?
面试速记:
针对两种检索的矛盾,采用多路混合召回 :同时使用向量检索做语义匹配、倒排索引做关键词精确匹配,合并结果兼顾两者优势。 多路召回后候选数量多、排序混乱且存在噪声,因此引入重排序模型,统一做细粒度相关性打分,重新排序并过滤低质内容,精简候选文本,既降低大模型推理开销,也提升问答准确率。
详解:
一、矛盾解决方案
向量检索擅长语义匹配 ,不支持关键词 / 专有名词精确命中;倒排索引(ES 等)擅长字面关键词精确匹配 ,无法识别近义词、同义改写。业界主流用多路混合召回解决该冲突,辅以查询增强、权重调优:
1. 标准多路召回(核心方案)
同一用户查询,并行执行两路检索:
- 向量检索:召回语义相近的文本片段,覆盖同义表达、语义关联内容;
- 倒排关键词检索:基于分词、词条匹配,精准命中指定关键词、术语、编号、固定短语。
将两路结果合并、去重,得到同时满足「语义相似 + 关键词精确匹配」的候选集合,补齐两类检索的短板。
2. 进阶优化手段
- 查询改写增强:对原 Query 做扩展,生成近义词、同义句式,分别送入两路检索,扩大召回范围;
- 动态权重 / 路由:区分查询类型:偏专业术语、编号、固定关键词的请求,调高倒排索引权重;纯自然语言问答,调高向量检索权重;
- 字段分治:结构化文档可拆分字段,关键词类字段走倒排,大段正文走向量检索。
二、为什么需要重排序模型(Reranker)
多路召回完成后,会出现新问题,这也是引入重排序的核心原因:
- 打分体系不统一 向量检索靠向量余弦相似度打分,倒排索引靠词频、命中次数打分,两套分数无法横向对比,原始列表排序逻辑混乱。
- 候选数量多、噪声大 两路召回汇总后往往有几十至上百条结果,里面存在关键词误命中、语义跑偏、弱相关的无效内容;如果直接全部送入大模型,会占用大量上下文窗口、增加推理耗时,还容易引发幻觉、答非所问。
- 重排序模型的核心作用 重排序多采用交叉编码器 ,输入「用户查询 + 单条候选文本」,做细粒度全局语义相关性判断:
- 用同一套标准对所有候选重新打分、排序;
- 过滤低相关、误匹配内容,精选出 Top3~Top10 优质片段;
- 大幅压缩送入大模型的文本量,降低算力与幻觉风险,同时提升最终答案准确度。
三、完整工业链路
用户 Query → 查询预处理 / 改写 → 向量检索 + 倒排索引 多路召回 → 合并去重 → Reranker 重排序筛选 → 拼接上下文 → LLM 生成答案
Q32:为什么要在向量相似度检索前,对用户输入的话进行改写?
面试速记:
对用户输入做查询改写,一是补全语义、修正错误、过滤口语噪声 ,让向量表征更准确;二是生成同义问句、拆分复杂问题,扩大召回范围、避免语义混杂;同时还能强化核心关键词,弥补向量检索无法精确匹配词条的短板,整体提升召回质量。
详解:
一、核心原因 & 改写目标
对用户 Query 做查询改写(Query Rewrite) ,本质是优化输入,适配向量检索的特性,弥补原始问句的缺陷,提升召回准确率、覆盖率,减少漏召、误召。 结合向量检索「靠语义匹配、对表述方式敏感」的特点,分场景说明作用。
1. 补全语义、消除口语 / 简略表达(最常见)
用户输入常存在口语化、缩写、短句、指代、信息残缺,原始问句语义模糊,向量化后特征不准,导致检索跑偏。
- 例子:用户输入「它续航多久?」(上下文有手机) 改写为:这款手机的续航时长是多少?
- 作用:补齐指代、补全上下文、把短句 / 口语转为标准书面问句,让 Embedding 模型学到完整语义,向量表达更准确。
2. 句式、措辞泛化,扩大语义召回范围
同一语义有多种表达方式,向量对句式、用词差异敏感。原始问句句式单一,容易漏召回同义改写的文档。
- 例子:原句「怎么注销账号」 改写生成同义问句:账号注销流程、如何关闭账户、账户解绑退出方法
- 作用:生成多条同义 Query 并行检索,覆盖文档中不同措辞、句式,解决 "说法不一样但语义相同却召回不到" 的问题。
3. 拆分复杂问句,拆解多意图
用户一条问句包含多个独立问题 / 多个检索点,单条向量会混合多语义,导致向量特征杂乱,召回结果混杂。
- 例子:原句「会员多少钱、到期怎么续费、能退吗」 拆分为三条独立 Query:会员价格是多少、会员如何续费、会员能否退费。
- 作用:一拆多,每个子问题单独检索,语义更纯粹,召回结果精准对应每个子需求。
4. 关键词强化,弥补向量检索 "弱精确匹配" 短板
向量检索不擅长强制命中专有名词、术语、编号、型号。改写时提取并突出核心实体 / 关键词,让向量偏向目标词条,也可同步供给倒排索引做多路召回。
- 例子:原句「这款机型散热表现如何」 改写强化:XX 型号手机的散热效果怎么样
- 作用:放大核心实体权重,减少 "语义相似但不含关键名词" 的误召回。
5. 纠错、脱敏、过滤噪声
用户输入存在错别字、病句、乱码、多余语气词、隐私信息:
- 纠错: 「人功智能入门讲解」→ 人工智能入门讲解
- 降噪: 原句「emm 麻烦问下啊,怎么使用云盘?」→ **如何使用云盘?,**去掉 "emm、啊、麻烦问下" 等无意义语气词
- 脱敏:移除手机号、姓名等隐私内容
- 作用:脏文本会生成劣质向量,预处理 + 改写清洗后,保证向量质量。
6. 适配 Embedding 模型偏好
不同嵌入模型对文本风格、长度、格式有适配偏好。改写把用户输入统一为模型更擅长处理的格式 / 长度(比如控制句长、统一为问答句式),进一步提升向量表征效果。
二、结合 RAG 链路总结改写的价值
- 降低漏召:同义扩展、句式泛化,覆盖更多文档表述;
- 降低误召:补全语义、修正错误、拆分多意图,让向量语义更聚焦;
- 兼容混合检索:改写后提取的关键词,可同步喂给倒排索引,适配「向量 + 关键词」多路召回架构;
- 统一输入规范:清洗噪声、标准化句式,提升整套检索系统稳定性。
Q33: 如果需要根据某长篇小说的内容回答问题,而小说的长度远远超出了上下文限制,应该如何综 合利用摘要和RAG技术,使其能同时回答故事梗概和故事细节?
面试速记:
针对远超上下文限制的长篇小说,我采用多级摘要 + RAG 分块检索 结合的方案: 离线时,先对小说分块构建向量库用于细节检索,同时生成全书总摘要、章节摘要保存宏观剧情、故事梗概与人物关系。 在线问答时,先做意图识别:问故事梗概、主线、人物关系等宏观问题,直接调用多级摘要作答;问台词、场景、具体情节等细节,通过 RAG 检索相关文本块,并搭配邻块、章节摘要补齐上下文;遇到混合问题则融合摘要与检索结果。该方案既能回答整体梗概,也能精准还原故事细节。
详解:
长篇小说问答:摘要 + RAG 综合落地方案
核心思路:分层存储、各司其职 用全局 / 分层摘要 承载整体剧情、故事梗概、人物关系等宏观信息;用分块 RAG 承载对话、场景、情节细节、原文内容等局部信息。两套体系联动,既解决超长文本超限问题,又同时支持梗概类宏观提问 和细节类微观提问。
一、整体架构设计(离线预处理 + 在线问答)
(一)离线预处理阶段(对整本小说统一加工)
1. 多层级分块(适配 RAG 细节检索)
- 先按章节 / 回目 做粗划分,再在章节内做滑动重叠分块(固定块大小 + 合理重叠),避免单句、跨片段语义断裂;
- 每一个文本块绑定所属章节 ID、章节标题、前后邻块 ID,构建块之间的关联关系;
- 所有文本块送入嵌入模型生成向量,连同原文、位置信息一并存入向量数据库 ,作为细节检索底座。
2. 多级摘要生成(承载梗概、宏观信息)
针对长篇小说做三级摘要,分层保存全局与局部宏观内容,不进入向量检索,单独存储:
- 全书总摘要 对整本小说生成极简摘要:核心主题、故事主线、整体结局、主要人物人设与人物关系,专门用于回答故事梗概、整体评价、主线脉络类问题。
- 章节摘要 为每一章 / 每一回单独生成摘要:本章主要情节、出场人物、关键冲突、章节作用。用于回答某一章剧情、阶段性情节类问题。
- 段落 / 大块摘要(可选) 对连续多个文本块生成局部摘要,补充块级上下文,辅助细节问答补全语境。
存储方式:总摘要、所有章节摘要结构化存档(JSON / 文档库(如, MongoDB ),与向量库分离管理。
(二)在线问答流程(核心联动逻辑)
用户提问后,先意图分类,再分流到摘要体系、RAG 检索体系,最后融合结果作答。
步骤 1:意图识别与问题分类
通过模型 / 规则判断问题类型,分为两大类:
- 宏观类问题(问梗概、主线、人物关系、整体结局、小说主题) 例:整部小说讲了什么?主角最后结局如何?主要人物有哪些关系?
- 细节类问题(问对话、场景、动作、原话、某一幕具体情节、道具、台词) 例:第三章主角说了什么话?两人吵架的具体过程是怎样的?某个物品出现在哪个场景?
步骤 2:分流处理
场景 A:回答【故事梗概 / 宏观问题】→ 优先调用多级摘要
- 全局梗概类:直接读取全书总摘要,结合少量关键章节摘要,组织语言输出答案;
- 指定章节剧情:读取对应章节摘要作答; 全程不调用向量检索,速度快、主线信息完整。
场景 B:回答【情节 / 原文细节问题】→ 优先走 RAG 检索
- 对用户问题做查询改写、纠错、同义扩展;
- 向向量数据库发起检索,召回语义最相关的文本块;
- 基于块关联 ID,自动拼接前后相邻块,解决跨块依赖、上下文缺失问题;
- 可选补充:将该块所属的章节摘要一并带入,补充章节背景;
- 把「召回文本块 + 对应章节摘要」拼接后送入大模型,提取细节、引用原文作答。
步骤 3:混合问题(同时包含梗概 + 细节)→ 双路融合
很多问题同时兼顾整体与局部,例如:
"小说主线是什么?其中主角在第二章遇到的关键人物是谁?"
处理方式:
- 从摘要库提取全书主线;
- 从RAG 向量库检索第二章相关细节;
- 模型融合两部分内容,统一组织成完整答案。
步骤 4:统一输出与兜底
- 限制整体输入长度:摘要 + 检索片段总长度严格控制在模型上下文窗口内;
- 检索结果多时,增加重排序模型筛选高相关片段,压缩文本量;
- 细节检索无结果时,用章节摘要做兜底解释,避免直接回答 "不知道"。
二、关键优化点(解决长篇小说特有问题)
1. 人物关系单独构建知识(强化宏观能力)
额外抽取全小说人物关系图谱,和摘要放在一起。 作用:专门应对 "人物关系、人物经历、人物前后变化" 这类高频问题,弥补纯文本摘要的不足。
2. 分块 + 摘要联动,消解跨片段依赖
- 分块采用语义分块 + 重叠分块,从源头减少语义拆分;
- 召回细节块时,自动挂载「邻块 + 上级章节摘要」,局部细节 + 章节背景互补。
3. 动态控制上下文长度
- 梗概类问题:仅加载短摘要,占用窗口极小;
- 细节类问题:少而精地召回 3--8 个相关块 + 单条章节摘要;
- 杜绝把整本小说、大量块一次性送入模型。
4. 迭代式摘要优化
长篇小说首次生成摘要可能冗长,可对摘要二次精简、提炼,保证摘要文本简短高效。
三、典型案例演示
示例小说:一部百万字长篇武侠小说
- 用户提问 1(梗概类) :这本小说主要讲了什么故事? 处理:读取全书总摘要 → 直接输出完整故事梗概、主线、结局。
- 用户提问 2(细节类):主角在竹林一战中使用了什么招式? 处理:问题改写 → 向量库召回竹林对战相关文本块 → 拼接相邻块 + 对应章节摘要 → 模型提取招式、对战细节作答。
- 用户提问 3(混合类):小说整体主线是什么?主角在竹林一战对后续剧情有什么影响? 处理:总摘要输出主线 + RAG 召回竹林对战细节 + 章节摘要分析剧情影响 → 融合输出。
第9章 多模态LLM
Q34:在CLIP训练过程中,为什么需要同时最大化匹配图文对的相似度和最小化非匹配图文对的相似度?
面试速记:
CLIP 属于跨模态对比学习模型。训练时把匹配图文作为正样本 、不匹配图文作为负样本 。最大化正样本相似度,是让模型学习图文之间的语义关联 ;最小化负样本相似度,是让模型区分不同语义。两者结合可以拉大正负样本差距,让模型实现精准的图文对齐。
基础术语释译:
1.CLIP
Contrastive Language-Image Pre-training
中文译称:对比式语言 - 图像预训练模型
2.InfoNCE
全称:Information Noise-Contrastive Estimation,中文常称信息噪声对比估计,是对比学习最常用的损失函数,CLIP、SimCLR 等模型均基于它训练。
详解:
一、基础概念
CLIP 是典型图文跨模态对齐模型 ,核心目标:让语义匹配的图片与文本 特征更相似、语义无关的图片与文本特征差异更大。
训练采用对比学习 ,搭配 InfoNCE 损失函数,依靠批次内自动构建正负样本完成学习。
样本定义
- 正样本对:一一对应的原配图文(如图片是猫,文本描述也为猫),属于匹配关系。
- 负样本对:随机乱配的图文(如图片是猫,文本描述为汽车),属于不匹配关系。
二、训练样本构建(举例:单批次包含 4 组图文)
假设一个训练批次有 4 组原配图文:
图片 I₁、I₂、I₃、I₄ ,对应文本 T₁、T₂、T₃、T₄ 将所有图片和所有文本两两组合,形成 4×4 组合矩阵:
表格
|----|------|------|------|------|
| | T₁ | T₂ | T₃ | T₄ |
| I₁ | ✅正样本 | ❌负样本 | ❌负样本 | ❌负样本 |
| I₂ | ❌负样本 | ✅正样本 | ❌负样本 | ❌负样本 |
| I₃ | ❌负样本 | ❌负样本 | ✅正样本 | ❌负样本 |
| I₄ | ❌负样本 | ❌负样本 | ❌负样本 | ✅正样本 |
矩阵对角线:图片与自身原配文本配对,共 4 个正样本;
矩阵其余位置:图片与其他文本乱配,共 4×4-4=12 个负样本;
推广到通用场景:批次共 N 组图文,总组合数为 N×N,正样本 N 个,负样本 N²-N 个。
三、核心训练目标
模型会为图片、文本分别生成特征向量,使用余弦相似度判断匹配程度:分数越高,图文越匹配。训练设置双向约束:
- 正对(对角线):最大化相似度,让原配图文的特征相互靠拢;
- 负对(非对角线):最小化相似度,让无关图文的特征相互远离。
为什么必须双向约束?
- 若只拉高正样本相似度:所有图文特征会扎堆,模型无法区分真正匹配和随机组合,对齐失效;
- 若只压低负样本相似度:没有 "匹配标准" 作为引导,训练失去方向;
- 双向结合:拉大正负样本差距,迫使模型学习图文共有的语义特征,最终实现同类语义聚集、异类语义分离。
四、InfoNCE 损失的作用
InfoNCE 是 CLIP 核心损失函数,作用是量化模型的判断误差:
以图片 I₁ 为例,理想结果是:I₁ 与原配文本 T₁ 的相似度,远大于它和 T₂、T₃、T₄ 等负样本文本的相似度。
- 模型判断准确(正负样本差距大):损失值很小;
- 模型判断混乱(正负样本分数接近):损失值很大。
训练流程:不断计算损失、反向传播更新模型参数、减小损失,直到模型可以稳定区分匹配 / 不匹配图文。
五、训练最终效果与应用
训练完成后,图片和文本会被映射到同一个特征空间:
- 语义相近的图文,余弦相似度高;语义无关的图文,余弦相似度低;
- 依托该能力,CLIP 可直接用于图文检索、图文分类、零样本推理等跨模态任务。
Q3S:BLIP-2为何不直接将视觉编码器的输出连接到语言模型,而要引人Q-Fomer 这一中间层结构?
面试速记:
视觉编码器与语言模型分属不同模态,特征格式、长度、语义空间都不匹配,直接连接效果差、训练成本高。Q-Former 作为中间层,可压缩视觉序列、过滤噪声、对齐模态特征,以轻量化方式完成两者适配。
基础术语释译:
1.BLIP-2
Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
中文:基于冻结图像编码器与大语言模型的引导式图文预训练
2. Q-Former
Querying Transformer
中文:查询式变换器
详解:
一、基础概念
BLIP-2 是图文多模态模型,整体架构由视觉编码器、中间适配层、语言模型三部分组成,核心目标:打通视觉与语言两大模态,实现图像理解、图文问答、图像描述等任务。 模型设计思路为冻结预训练主干模型,仅训练中间适配模块,以此保留原有模型能力、降低训练开销。
二、直接连接两大模型存在的问题
视觉编码器多采用 ViT,语言模型为各类大语言模型,二者直接相连会出现多重阻碍:
- 模态特征差异大:ViT 输出视觉特征,聚焦图像纹理、空间、像素信息;语言模型接收文本特征,聚焦语义信息,两套特征体系无法直接互通。
- 特征序列长度不匹配:ViT 处理图像后会生成数百个视觉 Token,序列长度较长;语言模型对输入序列长度有限制,无法承载海量视觉特征。
- 信息存在大量冗余:原始视觉特征包含背景、细碎纹理等无效噪声,直接输入语言模型会造成信息过载,干扰语义判断。
- 训练风险与成本高:视觉编码器和语言模型均为超大参数量模型,直接端到端微调算力成本极高,还容易出现灾难性遗忘,破坏模型原本的视觉、语言能力。
三、Q-Former 中间层的核心定位与训练目标
Q-Former 是放置在视觉编码器与语言模型之间的轻量级 Transformer 结构,核心作用是完成视觉特征的加工与转换。整体处理流程设置多重目标:
- 特征压缩:将 ViT 输出的长序列视觉 Token,压缩为固定数量的短序列 Token;
- 噪声过滤:提取图像核心语义,剔除背景、纹理等无效信息;
- 模态与维度适配:把视觉特征转换为语言模型可识别的特征格式,统一特征维度。
为什么不能省略 Q-Former 直接连接?
- 若省略中间层强行拼接:模态、序列、维度的多重壁垒无法打破,语言模型无法正常解析图像内容,任务效果大幅下降;
- 若舍弃冻结策略、全局微调主干模型:算力消耗陡增,同时极易丢失模型预训练习得的能力;
- 引入 Q-Former:以轻量化模块完成特征全流程适配,既解决模态与格式问题,又控制训练成本、保留主干模型能力,是最优方案。
四、Q-Former 的工作原理
Q-Former 内置 32 个可学习查询向量,依靠注意力机制完成特征处理,作用是加工提纯视觉特征:
以常规实拍图像为例,理想结果是:32 个查询向量精准抓取画面中物体、场景、动作等核心内容,过滤无关细节,输出适配语言模型的特征序列。
● 交叉注意力阶段:查询向量与原始视觉特征交互,筛选有效语义;
● 自注意力阶段:整合 32 个查询向量的信息,让特征逻辑更连贯;
● 维度投影阶段:调整特征维度,完成模态对齐。
执行流程:视觉图像先输入 ViT 得到原始视觉特征,再送入 Q-Former 完成筛选、压缩、维度转换,最终输出标准化视觉特征,作为软提示送入语言模型,全程仅更新 Q-Former 参数,冻结前后主干模型。
五、引入 Q-Former 的最终效果与应用
加入 Q-Former 完成训练后,整套模型形成完整的多模态链路:
- 视觉特征经过提纯、转换,可无缝输入语言模型,图像语义能够被精准解读;
- 训练成本大幅降低,视觉编码器与语言模型的原有能力完整保留,模型泛化性更强。 依托该架构设计,BLIP-2 可直接用于图像描述、图文问答、视觉对话、跨模态检索等多模态任务。
Q36:现有一个能力较弱的多模态模型和一个能力较强的文本模型(如DeepSeek-RI),如何结合两者的能力来回答与多模态相关的问题?
面试速记:
以强文本模型作为核心输出主体,弱多模态模型专职做图像特征提取、语义解析,通过中间适配层衔接两者;弱模型只负责视觉信息解读,不参与文本生成,充分发挥强文本模型的理解、推理与问答能力,弥补多模态能力不足的短板。
详解:
一、基础概念
本次组合方案核心思路:分工协作、扬长避短。能力较弱的多模态模型,保留其视觉解析 能力,负责处理图像输入;能力较强的文本模型(如 DeepSeek-R1)作为问答与推理核心,负责理解问题、逻辑思考、组织语言并输出答案。 整体架构不改造两大模型主体,仅搭建衔接链路,让视觉信息顺畅流转至文本模型,联合完成图文类问答任务。
二、两大模型的能力定位
- 弱多模态模型:视觉能力可用,但图文联合推理、文本生成效果差,仅承担图像解析工作,输出图像对应的语义特征、描述文本。
- 强文本模型:语言理解、逻辑推理、长文本生成、复杂问答能力突出,但无法直接读取图像,需要外部提供图像相关信息作为输入。
三、主流结合方案与执行流程
方案 1:图像转文本描述(最简方案)
弱多模态模型对输入图像做解读,直接生成简短图像描述、物体标签、场景说明,把图像内容翻译成纯文本。 再将用户提问 + 图像描述拼接在一起,完整送入强文本模型。 以实拍风景图问答为例:用户提问 "图中有哪些景物?",弱多模态模型先输出文本 "画面中有树木、河流、石桥",再把问题和这段描述一并交给文本模型,由其整理、润色并给出正式回答。
方案 2:视觉特征提取 + 特征适配(进阶方案)
弱多模态模型调用内部视觉编码器,提取图像视觉特征向量,不做文本生成。 增加简易适配层,将视觉特征的维度、格式统一为文本模型可识别的形式,转化为视觉软提示。 把用户问题 + 视觉软提示输入强文本模型,模型结合文本问题与视觉特征完成推理作答。
方案 3:分层信息输出(复杂多模态问题专用)
- 弱多模态模型分层解析图像:先标注物体、位置、动作,再判断画面关系、简单属性;
- 将多层视觉信息整理为结构化文本;
- 强文本模型结合用户问题、结构化视觉信息,完成深度推理、逻辑分析与答案生成。
为什么不直接升级多模态模型,而是采用组合方式?
- 改造弱多模态模型:重新训练、调优成本高,且模型本身能力上限低,提升效果有限;
- 单独使用强文本模型:无法读取图像,完全不能处理多模态问题;
- 分工结合使用:无需改动原有模型,落地成本低,同时最大化发挥文本模型的推理优势,整体问答效果远优于原弱多模态模型。
四、方案核心要点与优化方向
两种结合方式的核心要求:
● 图像转文本方案:保证描述内容准确、关键信息不丢失,避免错误描述误导文本模型;
● 特征对接方案:做好维度与模态对齐,保证视觉特征能被文本模型有效解读。
执行流程:接收用户的图像 + 文字问题 → 弱多模态模型解析图像(生成描述 / 提取特征)→ 信息拼接与格式转换 → 输入强文本模型 → 文本模型推理并输出最终答案。
五、组合方案的最终效果与应用
两套模型结合使用后,整体能力实现互补升级:
- 补齐纯文本模型无法读图的短板,同时解决原多模态模型推理弱、回答质量差的问题;
- 部署灵活,无需大规模训练,快速实现多模态问答能力落地。 依托该组合模式,可应用于图文问答、图片解读、视觉咨询、内容分析等各类多模态场景。
Q37:如何构建一个AI照片助手,能够对用户的上万张照片进行索引,根据用户的查询高效地检索相关照片?
面试速记:
构建上万张照片检索 AI 助手,整体分为数据预处理 、特征索引 、检索服务 、交互应用 四大环节。首先使用Pillow、OpenCV 对所有照片做标准化处理,再依托CLIP 模型批量提取视觉向量 ,结合图片元数据 生成统一特征库;接着借助Milvus、FAISS 这类向量数据库 搭建HNSW、IVF 索引,实现快速相似匹配。用户查询时,先通过模型把文本 / 图片检索请求转为向量 ,在索引中做相似度检索,最后返回结果。同时搭配MySQL、Elasticsearch 实现分类、标签、时间 等辅助检索,保障上万量级数据下的查询效率,整套方案兼顾检索精度 与响应速度。
详解:
一、基础概念
AI 照片检索助手核心目标:对上万张本地 / 云端照片建立可快速查询的体系,支持文字描述搜图、以图搜图、条件筛选搜图。 核心技术思路:图像向量化 + 向量索引检索,结合传统元数据筛选,依托 Python 生态、多模态模型与各类数据库,把非结构化图片转为可计算的向量数据,依靠向量数据库实现大规模数据下的高效检索。
二、整体架构与模块划分
整套系统主要包含五大核心模块,全程依托主流技术栈落地,各司其职完成全流程运转:
- 图片接入模块:基于 Python 搭配 Pillow、OpenCV 批量读取本地或云端 OSS 中的照片,完成格式校验、去重、预处理等工作。
- 特征提取模块:调用 CLIP、SigLIP 多模态模型以及 YOLO 目标检测模型,生成图像向量,同时提取标签、场景、物体等文本信息。
- 数据存储与索引模块:将向量存入 Milvus、FAISS 等向量数据库搭建向量索引,把元数据、标签存入 MySQL、Elasticsearch,构建常规字段索引与倒排索引。
- 检索匹配模块:基于 FastAPI 搭建接口服务,接收用户查询,将查询内容转为向量或检索条件,联合向量检索与条件筛选完成匹配。
- 前端交互模块:使用 Vue、React 或 Electron 搭建界面,提供上传图片、输入文字、筛选时间地点等操作入口,并展示检索结果。
三、全流程分步实现(上万张照片场景)
第一步:照片预处理
利用 Python 脚本遍历全部上万张照片,借助 Pillow、OpenCV 完成标准化处理,消除干扰因素:
- 统一图片格式与尺寸,兼容 JPG、PNG、WEBP 等常见图片类型,保证后续模型输入规范。
- 通过图像哈希算法完成数据清洗,剔除损坏文件与完全重复的照片,减少无效计算。
- 调用 ExifRead 工具解析照片 EXIF 信息,自动提取拍摄时间、地理位置、设备等元数据并临时存储。
第二步:批量提取特征与标签
基于 PyTorch 部署 CLIP、SigLIP 预训练模型,批量处理所有图片:
- 对每张图片做前向推理,生成固定维度的图像嵌入向量,用向量数值表征画面核心内容,也可结合 TensorRT、ONNX Runtime 做推理加速,提升批量处理效率。
- 搭配 YOLO 目标检测模型与图像分类模型,识别画面中的人物、景物、场景与动作,自动生成描述性文本标签。
- 通过 Python 数据结构,将图片路径、图像向量、标签、元数据一一绑定,组装成完整的结构化数据条目。
第三步:分层构建索引(保障上万数据检索效率)
采用 "向量索引 + 传统索引" 双索引模式,兼顾语义检索与条件筛选:
- 将全部图像向量导入 Milvus 或 FAISS 向量数据库,选用 HNSW、IVF_FLAT 索引算法完成向量索引搭建,依托专业向量索引能力支撑海量数据的语义相似度检索。
- 把照片标签、时间、地点、文件名等文本类数据存入 MySQL 并建立字段索引,同时同步至 Elasticsearch 构建倒排索引,用来支撑精准的多条件筛选查询。
第四步:用户查询与检索执行
区分不同查询方式,调用对应技术逻辑执行检索:
场景 1:文字查图(用户输入描述语句)
调用 CLIP 内置的文本编码器,将用户文字描述转化为文本向量,在向量数据库中计算文本向量与所有图像向量的余弦相似度,按照相似度分数从高到低排序后返回匹配照片。
场景 2:以图搜图(用户上传参考图片)
先使用 Pillow、OpenCV 对上传图片做预处理,再通过图像编码器提取特征向量,直接在向量索引中执行近邻搜索,匹配出画面内容相近的照片。
场景 3:组合条件检索(文字 + 时间 / 地点 / 标签)
先在 MySQL、Elasticsearch 中根据时间、地点、标签筛选出目标照片范围,再在该数据范围内执行向量相似度匹配,缩小检索空间,进一步提升整体查询速度。
为什么要采用双索引架构,不只用单一索引?
- 仅用 MySQL、Elasticsearch 这类传统文本索引:只能按标签、关键词检索,无法理解图片语义,面对模糊描述时查询效果很差。
- 仅用向量数据库做纯向量检索:计算开销较大,叠加时间、地点等筛选条件时灵活性不足。
- 双索引结合:语义检索依靠向量库实现,精准筛选依靠传统数据库完成,即便面对上万张照片,也能做到低延迟、高精准。
第五步:结果返回与优化
检索完成后,通过排序算法结合相似度得分、筛选条件对结果排序,经由 FastAPI 接口返回图片预览与对应信息;同时利用日志采集工具记录用户检索行为,为后续标签优化、模型迭代提供数据支撑。
四、核心要点与性能优化方向
针对上万张照片量级,结合对应技术做针对性优化:
● 索引选型上优先使用 HNSW 索引,平衡索引构建速度与在线查询速度,避免数据量增长后出现响应卡顿。
● 运用 PCA 算法对向量做降维处理,同时采用 INT8、FP16 量化技术压缩模型与向量体积,在不损失语义的前提下,减少存储占用与计算开销。
● 全程采用 TensorRT、ONNX Runtime 优化模型推理速度,提升特征提取与在线查询的整体效率。
完整执行流程:批量导入照片 → 借助图像处理工具完成预处理 + 依托多模态模型提取向量、标签与元数据 → 分别在向量数据库与传统数据库中建立索引 → 接收用户查询,通过模型向量化或解析检索条件 → 执行混合检索匹配 → 排序并返回照片结果。
五、最终效果与落地应用
系统搭建完成后具备完整能力:
- 依托多模态模型与混合检索架构,支持文字搜图、以图搜图、多条件组合检索,能够理解自然语言描述,精准匹配图片内容。
- 上万张照片规模下,依靠优化后的索引与推理技术,检索响应速度快,满足日常使用需求。
- 结合数据库的标签、时间、地点管理能力,同时实现检索与照片整理功能。
该方案可落地为基于 Electron 的本地桌面助手、手机相册工具,或是依托 OSS 搭建的云端图片管理平台等产品。
索引结合:语义检索靠向量库,精准筛选靠传统数据库,上万张照片也能做到低延迟、高精准。
第五步:结果返回与优化
检索完成后,按照相似度得分、筛选条件排序,返回图片预览与信息;同时记录用户检索行为,后续可迭代优化标签与模型。
四、核心要点与性能优化方向
针对上万张照片量级,重点做好两点优化: ● 索引选型:优先使用 HNSW 等高效向量索引,平衡构建速度与查询速度,避免数据量变大后响应卡顿; ● 向量降维:在不损失语义的前提下适当降低向量维度,减少存储占用与计算开销。
完整执行流程:批量导入照片 → 预处理 + 提取向量 / 标签 / 元数据 → 双数据库建立索引 → 接收用户查询并向量化 / 解析条件 → 联合检索匹配 → 排序并返回照片结果。
五、最终效果与落地应用
系统搭建完成后具备完整能力:
- 支持文字搜图、以图搜图、多条件组合检索,理解自然语言描述,精准匹配图片内容;
- 上万张照片规模下,检索响应速度快,满足日常使用需求;
- 附带时间、地点、标签管理能力,兼顾检索与照片整理。
该方案可落地为本地桌面助手、手机相册工具、云端图片管理平台等产品。
第 10章 构建文本嵌入模型
Q38:相比交叉编码器,为什么双编码器在大规模相似度搜索中更受欢迎?
面试速记:
双编码器 采用双塔独立编码 ,提前把所有文本、图像离线生成向量存入向量数据库 ,线上查询仅做向量相似度计算,查询速度快、可支撑大规模检索 ;交叉编码器 是输入拼接后深度交互编码,无法预计算向量,每条请求都要全量推理,耗时极高。因此海量数据相似度搜索场景下,双编码器综合效率与落地性更强,使用更广泛。
基础术语释义:
- 双编码器:Dual Encoder,也叫双塔编码器,由两个独立编码器分别处理两组输入,输出独立特征向量用于相似度计算
- 交叉编码器:Cross Encoder,将两组输入拼接为一个序列,送入单个编码器做全量交互计算
- 向量检索:将特征向量存入向量库,通过近邻算法快速匹配相似内容
- 离线预计算:提前对全量数据完成特征提取并持久化存储,不占用线上请求耗时
- 推理时延:模型处理单次请求所消耗的时间
详解:
一、基础概念
双编码器与交叉编码器都常用于文本相似度、图文匹配、内容召回任务,二者核心区别在于输入处理与特征交互方式 。双编码器使用两个结构独立的编码器,分别 对两条内容单独 编码;交叉编码器会把两条内容拼接成一条完整序列,再送入同一个编码器完成深度特征交互。在上万、百万级别的大规模相似度搜索场景中,二者的性能差异会被急剧放大。
二、两种结构的工作原理与实现方式
- 双编码器采用双塔架构,以图文匹配或文本相似度场景为例,一侧编码器处理查询内容,另一侧编码器处理库内候选内容,两套编码器互不干扰。我们可以提前使用双编码器,对数据库中全部候选数据离线批量推理,生成特征向量并保存到向量数据库中。当用户发起查询时,只需要用对应编码器把查询内容实时转为向量,再在向量库中执行余弦相似度、欧式距离等计算,快速召回相似结果,整个过程没有复杂的模型交互计算。
- 交叉编码器不区分左右双塔,它会将查询内容和单条候选内容拼接在一起,组成完整输入序列再送入编码器。它会在每一层网络中让两组内容的特征做全面注意力交互,能捕捉细粒度语义关联,匹配精度更高。但这种结构无法提前为库内数据预生成独立向量,每一次用户查询,都必须遍历候选集,将查询与每一条候选分别拼接、单独走一遍完整模型推理。
三、大规模相似度搜索下的核心差异
为什么大规模相似度搜索中双编码器更受欢迎?
- 离线能力差距明显:双编码器支持全量数据离线预计算向量,海量数据一次性完成编码入库,线上服务只负责向量检索,压力极小;交叉编码器无法预存向量,所有计算都压在线上请求阶段,数据量越大整体耗时越高。
- 单次查询时延差距大:双编码器线上仅做一次查询编码 + 向量库近邻搜索,运算简单、响应快;交叉编码器要对每一条候选数据执行一次完整模型推理,候选数量越多,请求时延呈线性上涨,海量数据场景下会出现严重卡顿。
- 架构适配性不同:大规模检索普遍依赖向量数据库做近邻召回,双编码器输出的独立向量可以完美对接向量。
Q39: 在训练嵌入模型时,MNR(多负例排序)损失、余弦相似度损失和 softmax 损失各有哪些优缺点?在哪些场景下,余弦相似度损失可能比MNR损失更合适?
面试速记:
余弦相似度损失 :计算简单、收敛稳定,直接优化向量相似度距离,适合单纯语义匹配、相似度回归场景;缺点缺乏排序约束,多负例场景区分能力弱。
Softmax 损失 :把匹配任务转为分类,正负区分明确,训练稳定;但对负例数量敏感,大规模负例下梯度易退化,不适合海量检索。
MNR 多负例排序损失 :依托批量多负例做相对排序,泛化与检索精度最优,是大规模向量召回主流选择;但训练逻辑复杂、调参难度高。
在负例稀少、以绝对相似度打分、小样本匹配、语义相似度评估场景下,余弦相似度损失比 MNR 更合适。
基础术语释义:
- 嵌入模型:Embedding Model,将文本、图像等数据映射为低维稠密向量的模型
- MNR:Multiple Negative Ranking,多负例排序损失,基于批量内负样本做相对排序优化
- 余弦相似度:Cosine Similarity,衡量两个向量方向相似度的指标,值域 -1,1
- Softmax 损失:分类损失,将正匹配对视为唯一类别,其余负例作为其他类别计算损失
- 正例:语义 / 内容相互匹配的样本对
- 负例:语义 / 内容不匹配的样本对
详解:
一、基础概念
嵌入模型训练核心目标,是让正样本向量相似度更高、负样本向量相似度更低。余弦相似度损失、Softmax 损失、MNR 多负例排序损失是匹配、检索任务中常用方案,三者优化逻辑不同,结合实例可清晰区分原理、优劣与适用边界。
二、三种损失函数原理、优点、缺点(附实例)
1. 余弦相似度损失
原理
属于回归类损失,模型分别输出两组数据的嵌入向量,直接计算向量之间的余弦相似度,以拉大正负样本相似度差距 为优化目标。训练时不断缩小正样本对的向量夹角、增大负样本对的向量夹角,全程只关注两组向量的绝对相似度数值。
举例
以句子相似度任务为例:输入句 A「一只白猫在玩耍」,配对句分为正例句 B「白色小猫正在嬉戏」、负例句 C「汽车在路上行驶」。 模型分别生成三组向量:向量 A、向量 B、向量 C。 计算 cos(A,B)、cos(A,C),训练目标让 cos(A,B) 尽可能接近 1,cos(A,C) 尽可能接近0,以此监督模型学习语义特征。(对立时,如 开心 ↔ 难过 才会接近-1)
优点
计算逻辑简单,基于 Python、PyTorch 等框架可快速实现,训练收敛平稳,对学习率、批次大小不敏感;向量相似度有明确数值含义,可直接当作相似度分数使用;即便业务难以收集大量负样本,小样本场景下也能稳定训练。
缺点
只优化单一样本对的相似度,没有样本间相对排序约束;当同时存在多个负例、且负例语义相近时,模型很难精细区分优劣;偏向一对一匹配,在多候选排序、大规模检索场景中泛化能力不足。
2. Softmax 损失
原理
将图文匹配、句对匹配这类任务,等价转化为单标签分类任务。在一个批次内,把当前唯一的正样本当作目标类别,批次内其余所有样本统一视为负类别,通过 Softmax 做概率归一化,训练目标是让模型预测正样本的概率无限趋近于 1。
举例
一个训练批次包含 4 条文本,查询句 Q「晴天适合出游」,批次内候选内容: 正例 D「天气晴朗,很适合出门游玩」,负例 E「今晚要下雨」、负例 F「米饭很香」、负例 G「球赛开始了」。 模型输出 Q 与四条候选的匹配得分,经过 Softmax 转换为概率分布,训练要求模型把最大概率分配给正例 D,其余负例概率尽量压低。
优点
正负样本边界划分清晰,分类目标直观,工业界落地经验丰富,新手易调参;基础匹配准确率表现稳定,中等数据量、常规分类式匹配场景适配性好。
缺点
效果高度依赖负例数量,批次内负例过多时会出现梯度稀释,训练震荡、难以收敛;本质是分类逻辑,不擅长优化连续的相似度数值;只区分 "正确 / 错误",不关注多个负例之间的好坏差异,不适合排序类业务。
3. MNR 多负例排序损失
原理
全称多负例排序损失,核心围绕相对排序 做优化。以整个训练批次为单位,取 1 个正样本,把批次内其余全部样本当作天然负例,计算正例与所有负例的得分,强制要求正例得分显著高于每一个负例得分,重点学习样本之间的先后顺序关系,而非单一相似度数值。
举例
做图片检索训练,单批次有 1 张原图 P,搭配 1 张匹配图片 P₀(正例)、3 张无关图片 P₁/P₂/P₃(负例)。 模型依次计算原图 P 与 P₀、P₁、P₂、P₃的匹配分数,MNR 损失会监督模型,保证 score(P,P₀) > score(P,P₁)、score(P,P₀) > score(P,P₂)、score(P,P₀) > score(P,P₃)。哪怕多个负例语义接近,也会强制拉开正例与所有负例的位次差距。
优点
充分利用批次内海量内置负例,无需额外人工构造负样本,降低数据成本;强排序约束和检索、召回业务高度契合,面对难负例、海量候选集时区分能力极强,是百万 / 亿级向量检索嵌入模型的主流选择;模型泛化能力强,线上检索召回精度表现优异。
缺点
训练对批次大小、负例质量要求严苛,批次过小、负例数量不足时,效果会大幅下降;损失计算逻辑复杂,调参难度高于前两种损失;全程聚焦相对顺序,不关注向量的绝对相似度数值,输出结果无法直接当作相似度评分使用。
三、余弦相似度损失相比 MNR 损失更适用的场景
- 负例稀缺的小样本匹配场景 MNR 依赖批量多负例才能发挥效果,若业务难以构造足量负样本、硬件限制无法开大批次,MNR 效果会严重下滑;而余弦相似度损失不依赖大量负例,仅依靠少量样本对就能稳定训练。
- 以绝对相似度打分为核心的业务场景 比如语义相似度评级、内容相似度打分任务,业务需要明确的相似度数值作为评分依据。余弦相似度直接优化绝对分值,结果可直接落地使用;MNR 只关心样本相对顺序,无法输出有效分数。
- 简单一对一匹配、短文本对齐场景 如短句等价判断、简单问答匹配,不存在多候选排序需求。余弦相似度计算开销更小、实现简单,属于高性价比选择;MNR 的排序能力在此类场景中属于过度设计,还会增加训练复杂度。
- 离线语义评估、模型评测场景 仅用于离线判断两组内容是否相似,无需做多候选召回排序。余弦相似度结果直观、便于人工校验和指标统计;MNR 面向排序设计,不适合作为独立相似度评估指标。
- 通用特征提取场景 嵌入模型仅作为特征提取器,下游对接分类、聚类等任务,而非检索排序。余弦相似度训练出的向量分布更规整,适配各类基础特征任务;MNR 训练的向量偏向排序优化,通用表征能力偏弱。
为什么以上场景不优先选用 MNR 损失?
- MNR 核心优势是多负例 + 相对排序,在无排序需求、负例不足的场景下,核心能力无法发挥;
- MNR 训练门槛更高,对硬件批次、数据构造要求严苛,简单场景下会提升研发与运维成本;
- MNR 不约束绝对相似度,无法满足打分、数值评估类业务的核心诉求。
四、核心选型总结
● 追求简单稳定、需要相似度分值、负例少、无排序需求:优先余弦相似度损失。
● 常规内容匹配、数据分布均衡、希望易调参:优先Softmax 损失。
● 大规模向量检索、多候选排序、可构造足量批量负例:优先MNR 多负例排序损失。
完整使用思路:一对一匹配、相似度打分选用余弦损失;基础内容匹配选用 Softmax;线上百万 / 亿级图库、文本库检索召回,统一使用 MNR 损失。
Q40:如何生成负例以提升模型性能?如何构建高质量的难负例?
面试速记:
提升模型性能需搭配通用负例 与难负例 共同训练。常规负例可通过批次自动生成、全局随机采样、跨类别选取、人工标注 实现,低成本丰富样本多样性。高质量难负例优先采用向量近邻挖掘、同类别筛选、线上错误日志提取、内容改写增广方式制作,选取和正例高度相似的易混淆样本。训练时按阶段配比简单负例与难负例,循序渐进提升模型细粒度区分能力与泛化效果。
二、基础术语释义
- 负例:Negative Example,与目标样本无匹配关系的样本,用于约束模型区分能力
- 难负例:Hard Negative Example,和正例特征、语义高度相近,易被模型误判为匹配的负样本
- 批次负例:训练批次内除正对外的其余样本,训练时自动作为负例使用
- 向量近邻:通过嵌入模型计算相似度,和目标样本向量距离近、内容相似的样本
- 数据增广:对原始文本、图像做小幅修改,生成新样本的技术手段
详解:
一、基础概念
在匹配、检索、嵌入模型训练中,负例是模型学习区分边界的关键。普通负例语义、特征差异明显,只能帮助模型建立基础判断能力;难负例模拟线上易混淆场景,倒逼模型挖掘细粒度特征。想要持续提升模型性能,不仅要掌握多种负例生成方式,还要针对性构建难负例,并合理搭配两类样本完成训练。
二、常规负例的生成方式
1. 批次内自动负例
模型训练以批次为单位,每组样本仅设置一组正负配对,批次内其余所有样本自动作为当前样本的负例,是双塔模型、MNR 损失最常用的方案。
优点:无需额外数据处理与标注,零成本,动态生成样本,多样性强,适配大批量训练。
缺点:负例质量不可控,大多是简单样本;批次较小时负例数量不足,无法产出难负例。
2. 全局库随机采样负例
预先搭建全量候选样本库,训练时针对每一条目标样本,从库中随机抽取指定数量无关样本作为负例。
如:图片检索场景,图库包含人像、风景、动物三大类,训练动物类图片时,随机从风景、人像图库抽取图片作为负例。
优点:负例数量可灵活配置,适配余弦相似度损失、Softmax 损失等各类损失函数,使用范围广。
缺点:随机样本差异大,多为简单负例,长期训练易让模型陷入浅层学习,难以提升精度上限。
3. 跨类别 / 跨领域采样负例
按照业务类目、数据来源划分集合,固定从与正例完全无关的类别中选取负例。
优点:样本边界清晰,上手简单,适合模型冷启动、前期预训练,快速建立基础区分逻辑。
缺点:区分难度过低,模型收敛后继续使用该类负例,无法进一步优化效果。
4. 人工标注负例
结合业务场景,由人工筛选、编写合规的负样本。
优点:贴合真实业务分布,样本质量可控。
缺点:人力成本高、效率低,不适合海量数据场景,难以批量产出难负例。
三、高质量难负例的构建方法
难负例核心标准:和正例主体相似、细节有差异,线上极易被模型误匹配,是突破模型性能瓶颈的核心。
1. 向量近邻挖掘(工业主流)
先用初始版本的嵌入模型对全量样本向量化,存入向量数据库。针对每条正样本,检索出相似度排名靠前、但实际并不匹配的样本,作为难负例。
如:文本场景,正样本为 "秋季郊外露营",向量检索得到高分样本 "秋季户外野餐",二者语义高度相近但并非匹配关系,将其作为难负例。
优点:自动化程度高,精准命中模型识别盲区,对线上召回优化效果显著。
缺点:依赖已训练的基础模型与向量库,业务冷启动阶段无法使用。
2. 同大类细分类目采样
在同一个一级类目下,挑选不同细分类别的样本,保证整体主题一致,仅局部语义、特征存在区别。
如:图像场景,正例是 "金毛犬",在动物大类下选取 "拉布拉多犬" 作为难负例;文本场景,正例是 "打乒乓球",同体育类目下选取 "打网球" 作为难负例。
优点:规则简单易落地,不依赖模型,冷启动阶段即可使用,专门锻炼模型细粒度区分能力。
缺点:效果依赖类目划分精度,类目粒度偏大时,难负例质量会下降。
3. 线上错误日志挖掘
收集线上服务的推理日志,把模型打分高、但人工判定为不匹配的误召回样本整理为难负例。
举例:相册检索,用户搜索 "荷花",模型频繁召回 "睡莲" 图片,将这类线上真实错误样本加入训练集。
优点:完全还原线上真实难点,针对性修复模型缺陷,大幅提升线上鲁棒性。
缺点:需要积累线上流量与日志,新业务、新模型无法采用。
4. 内容改写与数据增广
对正样本做小幅修改,保留主体特征、改动核心语义,人工或借助大模型、图像处理工具生成混淆样本。
举例:文本改写,原句 "早上喝一杯热豆浆",改写为 "早上喝一杯热牛奶";图像增广,对原图替换背景、微调色彩,保留主体物体生成新图片。
优点:可定向批量生成样本,能补充小众场景的难负例,样本可控性强。
缺点:修改尺度难把控,改动过大变成简单负例,改动过小会变成正样本。
5. 对抗样本生成
通过算法在原始数据或特征上添加微小扰动,刻意生成欺骗模型的样本,多用于高精度图像、风控匹配场景。
优点:训练难度极高,充分挖掘模型特征提取潜力。
缺点:实现复杂、计算开销大,常规业务性价比低,多用于学术研究和高端场景。
四、负例搭配策略与训练方案
只使用简单负例,模型学习难度不足,面对混淆样本容易出错;全部使用难负例,正负边界过于模糊,会导致训练震荡、无法收敛。行业通用分层训练策略:
- 模型冷启动 / 预训练阶段:以批次自动负例、跨类别简单负例为主,帮助模型快速学习基础语义与特征分布,稳定收敛。
- 模型迭代优化阶段:逐步混入同类别难负例、向量近邻难负例,提升模型细粒度区分能力。
- 模型上线调优阶段:重点加入线上日志挖掘的难负例,修复线上真实问题,完成最终打磨。
完整执行流程:搭建基础数据集 → 用简单负例完成模型初始训练 → 借助模型、日志、增广手段批量构建难负例 → 按比例混合两类样本重新训练迭代 → 循环挖掘、循环训练,持续迭代优化。
Q4I:为什么TSDAE选择使用特殊词元而非平均池化作为句子表征?
面试速记:
TSDAE 采用特殊 CLS 词元 做句子表征、不使用平均池化,核心原因是 TSDAE 是单向量重建整句的去噪自编码器架构。CLS 词元被全程强监督学习全局语义,信息密度高、抗噪声能力强;而平均池化会稀释语义、包含大量无效停用词信息,无法支撑解码器完整还原句子,表征效果和训练稳定性都远不如 CLS 词元。
基础术语释义:
- TSDAE:Transformer-based Denoising AutoEncoder,基于 Transformer 的去噪自编码器句子嵌入模型
- CLS 词元:Classification Token,Transformer 首位特殊全局表征词元,用于聚合整句语义信息
- 平均池化:Mean Pooling,对句子所有 token 向量求均值,作为句子整体表征
- 去噪自编码器:输入加噪句子,通过编码压缩、解码还原原始干净句子的训练架构
详解:
一、基础概念
TSDAE 是无监督句子表征模型 ,核心训练逻辑是给句子随机加噪声、删词,通过编码器将整句信息压缩为单个向量 ,再通过解码器依靠这一个向量完整还原原始句子。 模型最终目的:让单个向量承载完整、纯净、高区分度的全局句义,这也是它放弃平均池化、选用 CLS 词元的根本前提。
二、两种表征方式的核心原理
以句子:"春天的公园开满了鲜花" 为例
1. 平均池化原理
对句子所有字、词 token 向量平等加权求平均,不管是核心实词 "春天、公园、鲜花",还是无用虚词 "的、了",全部同等参与计算。 最终得到的句向量是所有信息的模糊平均值。
2. CLS 特殊词元原理
CLS 是句子开头的专属全局 token,依靠 Transformer 自注意力机制,自动学习权重分配 。 会重点关注 "春天、公园、鲜花" 核心语义,自动弱化 "的、了" 等无效虚词,单独聚合、存储整句全部核心信息,作为唯一的句子表征。
三、为什么 TSDAE 必须用 CLS 词元、舍弃平均池化
- 适配自编码器核心训练逻辑 TSDAE 要求仅用一个向量重建完整句子。CLS 词元全程被解码任务强监督,被迫学习全局完整语义,完全适配单向量重建任务;而平均池化是被动模糊压缩,信息稀释严重,解码器无法依靠均值向量还原出精准完整的原句,训练无法收敛。
- 避免语义稀释,表征质量更高 句子中存在大量无意义停用词、虚词。平均池化平等对待所有 token,会让核心语义被无效信息稀释,句义模糊、区分度差;CLS 词元通过注意力筛选重点信息,过滤冗余噪声,表征更纯净、语义密度更高。
- 抗噪能力更强,贴合去噪训练场景 TSDAE 训练输入是残缺、加噪的句子。平均池化会把噪声 token 一并平均进来,噪声全覆盖、表征严重失真;CLS 词元会自动屏蔽残缺噪声、聚焦有效语义,非常适配去噪训练范式。
- 训练梯度更稳定 CLS 为单一向量监督,梯度集中、目标明确,收敛速度快;平均池化依赖全部 token 梯度,噪声多、梯度波动大,极易训练不稳定、过拟合。
- 推理计算更轻量化 CLS 直接取首位词元向量,无额外计算;平均池化需要遍历全部 token 求和求平均,增加冗余计算开销。
四、核心总结
平均池化适合普通双塔对比学习,但完全不适合 TSDAE 去噪重建架构 。 CLS 特殊词元完美匹配 TSDAE单向量压缩全局语义、单向量重建整句的核心目标,兼具语义纯净、抗噪、训练稳定、计算高效的优势,因此成为唯一选择。
Q42: 相比STSB,MTEB有哪些改进?其中包括哪些类别的嵌入任务?
面试速记:
MTEB 相比仅做单一语义相似度评测的 STSB,从单任务评测升级为多任务通用嵌入基准 。它扩充了任务维度、数据集规模与场景覆盖,不再只考核句子相似度,能全面衡量嵌入模型的检索、聚类、分类、重排等真实落地能力,评测结果更客观、贴合工业场景。MTEB 一共包含八大类下游任务,覆盖几乎所有文本嵌入落地场景。
基础术语释义
- STSB:Semantic Textual Similarity Benchmark,语义文本相似度评测基准
- MTEB:Massive Text Embedding Benchmark,大规模文本嵌入评测基准
- 检索任务:根据文本查询从海量文档库匹配相关内容的任务
- 重排任务:对粗召回结果做精细化排序的任务
- 聚类任务:依据文本语义自动无监督分组的任务
详解:
一、基础概念
STSB 是传统经典的嵌入评测标准,仅针对单一句子语义相似度任务 做评估,评测维度非常单一。而 MTEB 是升级版大规模嵌入评测框架,核心目标是全方位、通用化评测文本嵌入模型的综合能力,适配工业落地的各类下游任务,是目前嵌入模型的主流评测标准。
二、STSB 的局限性
- 任务单一:仅支持语义相似度 STS任务,只能衡量两句文本的匹配程度;
- 场景局限:完全不覆盖检索、聚类、分类、重排等主流落地场景;
- 评测片面:只能反映模型细粒度匹配能力,无法体现模型通用语义表征与泛化能力。
三、MTEB 对 STSB 的核心改进
- 任务维度全面扩充 STSB 只有 1 类相似度任务,MTEB 拓展为八大类完整下游任务,兼顾对称语义匹配与非对称检索场景,全方位考核模型表征能力。
- 数据规模与覆盖度大幅提升 MTEB 包含数十个开源数据集、覆盖多领域、多语种文本,相比 STSB 少量固定测试数据,评测范围更广、结果更具说服力,避免单数据集过拟合评测偏差。
- 评测体系标准化、通用化 统一各类任务的评测指标、评估流程,不同嵌入模型可以横向公平对比,解决了 STSB 只能单点对比、无法综合评级的问题。
- 贴合真实工业落地场景 STSB 偏向学术相似度打分,MTEB 完全对齐 RAG 检索、文本聚类、内容分类、句子重排等真实业务,评测分数直接对应模型线上性能。
四、MTEB 包含的八大标准任务类别
- Retrieval 文本检索任务:输入查询语句,从海量文档库召回相关文本,检验模型全局语义匹配能力;
- Reranking 重排序任务:对检索粗召回的结果做精细化打分排序,考验细粒度区分能力;
- STS 语义相似度任务:继承 STSB 核心能力,评判两句文本语义相似程度;
- Classification 文本分类任务:对单文本做情感、主题、意图等分类;
- Clustering 文本聚类任务:无监督根据语义自动对文本批量分组;
- Pair Classification 句子对分类任务:判断两句文本蕴含、矛盾、重复等语义关系;
- Summarization 摘要匹配任务:评估机器生成摘要与标准摘要的语义一致性;
- Bitext Mining 双语挖掘任务:跨语言匹配平行语料、挖掘翻译对。
五、核心区别总结
STSB 只能单点考核相似度 ,适合模型基础能力验证; MTEB 可以全维度考核嵌入模型综合性能,是目前学术界、工业界评判句嵌入模型优劣的唯一通用标准。
第 11 章为分类任务微调表示模型
Q43: 如果标注的训练数据很少,如何扩增训练数据的数量?(提示:SetFit)
面试速记:
标注数据极少时,采用SetFit 小样本数据扩增方案 。核心思路是不新增人工标注,利用极少标注样本自动生成大量正负句对 做对比学习,同时结合模板生成样本、无标注伪标签数据扩充训练集,大幅缓解小样本过拟合,极大提升模型泛化能力。
基础术语释义:
- SetFit :Sentence Transformer Fine-tuning,基于 Sentence‑Transformer 的少样本学习框架,核心是对比学习 + 句对扩增。 。
- 句对扩增:利用少量标注样本两两组合,自动生成大量训练样本对
- 正例对 :属于同一类别的两个句子样本
- 负例对 :属于不同类别的两个句子样本
- 伪标签:模型对无标注数据预测的高置信度标签,用作训练标签
详解:
一、基础概念
常规文本微调依赖大量标注数据,如果每类只有几条、十几条标注数据,模型极易过拟合、学不到真实语义。SetFit 专为小样本场景设计 ,不需要人工新增标注,依靠样本组合扩增 + 对比学习,用极少量真实标注,凭空造出海量有效训练数据,是小样本分类任务的标准解法。
二、传统数据扩增的弊端
传统扩增比如同义词替换、回译、随机删词,存在明显缺陷:
- 容易改变原句语义,生成无效噪声样本;
- 扩增样本相似度极高,缺乏难样本,模型提升有限;
- 无法适配对比学习,只能做普通分类微调,小样本效果差。
三、SetFit 核心数据扩增原理
假设场景:情感二分类任务 正类:开心;负类:难过 每类仅 4 条标注样本(极少数据)
1. 同类别组合生成大量正例对(核心扩增)
原理
把同一个标签下的所有句子两两自由组合,全部作为正例对,代表 "语义同类、距离拉近"。
举例
开心类 4 句话: ①今天很开心 ②心情特别好 ③今天超快乐 ④我很愉悦 两两组合生成大量正例: (今天很开心,心情特别好)、(今天很开心,今天超快乐)...... 原本 4 条数据,直接生成 6 组正例对。
2. 跨类别组合生成大量负例对
原理
把不同标签的句子两两组合,全部作为负例对,代表 "语义不同、距离拉远"。
举例
开心句子 + 难过句子 随机配对: (今天很开心,我很难过)、(心情特别好,我很委屈)...... 4 条开心 + 4 条难过,能生成 16 组负例对。
效果
原本总共 8 条标注数据 ,通过 SetFit 句对组合,直接扩增出几十组训练样本对,数据量翻十倍以上。
3. 模板生成合成样本(零标注也能用)
原理
固定语句模板,填入类别名称,批量生成规范、语义准确的人工样本,补充稀疏类别。
举例
模板:"这句话的情感是 {}" 自动生成: "这句话的情感是开心" "这句话的情感是难过" 批量扩充每类样本数量,弥补真实标注过少的问题。
4. 无标注数据伪标签扩增
原理
先用少量标注数据训练一个初始弱模型,再用弱模型预测海量无标注文本,筛选置信度极高的结果,打上伪标签加入训练集,迭代扩量。
举例
网上抓取大量无标注口语句子: "今天太舒服了""我心态崩了" 模型高置信度判定:第一句开心、第二句难过,直接当作真实样本训练。
四、为什么 SetFit 扩增效果远超传统方法
- 完全不需要人工标注,低成本暴涨数据量;
- 生成的正负句对语义干净、任务匹配,不会失真;
- 配合对比学习,模型不仅会分类,还能学到类内聚集、类间分离的优质嵌入特征;
- 自带难负例区分能力,小样本下杜绝过拟合、泛化能力极强。
Q44:在继续预训练时,如何在保证模型获得特定领城知识的同时,最大限度地保留其通用能力?
面试速记:
模型做领域继续预训练时,通过混合数据训练、分层参数更新、学习率控温、训练策略优化 四大手段平衡效果。搭配通用数据与领域数据混合输入,采用部分参数微调、小学习率缓慢迭代,同时辅以早停、正则化,既能让模型吸收领域专属知识 ,又能最大程度保留原有通用理解与生成能力。
详解:
一、基础概念
通用基座模型具备全面的语言能力,但缺少行业专属知识,无法适配专业场景。继续预训练可以让模型学习领域内容,但如果只用纯领域数据、全量参数大幅更新,模型会快速遗忘通用能力,出现灾难性遗忘。
核心解决思路:在注入领域知识的同时,约束训练强度、平衡数据分布、控制参数更新范围,做到领域能力增强、通用能力不退化。
二、核心实现方案
1. 混合数据集训练(最基础、最关键)
原理
不单独使用领域数据训练,将通用语料 和领域语料按合理比例混合,作为继续预训练的输入数据。通用数据守住原有能力,领域数据补充专业知识,双向兼顾。
举例
要把通用模型改造成医疗领域模型 : 训练数据不再只放病历、医学文献,而是混合日常对话、百科、通用文章与医疗文本。比如按 通用:领域 = 3:7 或 5:5 配比,模型一边学习医学术语、诊断逻辑,一边持续巩固日常语言、常识推理能力。 数据配比规则:领域专业性越强,可适当提高领域数据占比;想要强保通用能力,则提升通用数据比例。
2. 分层参数更新,控制参数改动范围
原理
Transformer 模型底层偏向通用语法、基础语义 ,上层偏向高阶语义、领域逻辑。训练时冻结底层大部分参数,仅更新顶层少量参数、Adapter 适配器或 LoRA 低秩矩阵,减少对通用特征的破坏。
举例
以标准 Transformer 架构为例: 冻结前 8 层基础网络(负责分词、语法、通用语义),只微调最后 4 层网络;或是接入轻量化 LoRA 模块,只训练少量矩阵参数。模型底层通用特征完全保留,仅在上层学习领域知识,从根源避免能力遗忘。
3. 采用小学习率 + 渐进式训练
原理
继续预训练区别于从零训练,使用远小于原生预训练的学习率,让参数平缓微调,而非剧烈改写;同时配合学习率退火,越到训练后期学习率越低,防止模型参数大幅偏移。
举例
基座模型原生预训练学习率常用 10⁻⁴ 级别,领域继续预训练选用 10⁻⁵ 甚至 10⁻⁶ 的小学习率。参数仅做小幅迭代更新,缓慢吸收领域知识,避免一次性冲刷掉模型原本学到的通用语言规律。
4. 优化训练任务与训练轮次
原理
一是沿用模型原生预训练任务(如 MLM 掩码语言建模),任务形式不变,仅更换混合数据,模型学习逻辑连贯;二是严格控制训练轮数,配合早停策略,验证集通用能力出现下降时立即停止训练。
举例
全程使用掩码预测任务做继续预训练,不新增陌生训练任务;每训练若干轮就用通用测试集、领域测试集分别评估,一旦发现通用问答、常识推理指标下滑,马上终止训练,防止过度训练。
5. 增加正则化约束
原理
引入权重衰减、Dropout 等正则化手段,限制参数过度拟合领域数据,避免模型只死记领域内容、丢失泛化能力。
举例
训练时开启权重衰减,惩罚极端参数;保留网络中的 Dropout 层,让模型不会对领域句式、术语过度拟合,维持原有通用表达习惯。
三、各类方案的作用与互补关系
- 混合数据:从数据源头同时供给通用 + 领域内容,是平衡能力的基础;
- 分层微调 + 轻量化模块:从参数层面保护底层通用特征,改动最小化;
- 小学习率 + 早停:从训练过程控制更新幅度,避免参数跑偏与过拟合;
- 正则化:进一步抑制领域过拟合,强化模型整体泛化性。
单独使用某一种方案效果有限,工业界通常组合落地,层层兜底保障双能力。
四、错误方案对比(反例说明)
- 纯领域数据全量参数 + 大学习率训练:模型快速学会领域知识,但通用对话、常识能力大幅衰退,出现严重遗忘;
- 超大训练轮次迭代:模型深度拟合领域数据,语言风格、表达逻辑被行业内容同化,丧失通用灵活性;
- 完全冻结全部参数:模型无法吸收任何领域知识,继续预训练失去意义。
五、完整落地执行流程
- 数据准备:收集高质量领域语料与通用语料,按照业务需求设定混合比例,清洗、格式统一;
- 训练配置:冻结模型底层参数,启用 LoRA/Adapter 轻量化模块,设置小学习率、权重衰减与 Dropout;
- 迭代训练:沿用 MLM 等原生预训练任务,分批次输入混合数据;
- 实时评估:每轮训练后,分别测试领域任务指标与通用能力指标;
- 早停终止:通用指标出现下滑时立即停止,得到最终模型。
Q45: 请比较以下三种方案在医疗领域文本分类任务上的优缺点:(a) 直接使用通用 BERT 模型微调; (b) 在医疗文本上继续预训练 BERT 后再微调;(c) 从头开始用医疗文本预训练模型再微调。
面试速记:
通用 BERT 直接微调上手快、成本低,但缺少医疗专业知识 ,专业场景精度一般;医疗数据继续预训练再微调,能注入领域知识、保留通用语言能力,综合效果最优、工业界首选;从零全量预训练再微调,领域适配度最高,但数据、算力、时间成本极高,小数据场景易过拟合。
详解:
一、基础概念
医疗文本包含大量专业术语、固定句式、行业逻辑,和通用文本差异较大。三种方案的核心区别在于模型初始权重、预训练数据范围不同,进而在效果、成本、泛化性、落地难度上形成明显差异。下面结合医疗分类场景,逐一对比原理、优缺点,并举例说明。
二、方案 (a) 直接使用通用 BERT 模型微调
原理与举例
直接加载公开通用 BERT 权重,不做任何二次预训练,仅使用医疗标注分类数据,训练分类头完成任务。 举例:做病历科室分类,输入 "患者咳嗽、咽痛,伴随发热",通用 BERT 依靠基础语义做判断,无法深度理解 "咽痛、发热" 对应的呼吸科专业特征。
优点
- 落地简单、周期短**:省去大规模语料预处理、长周期预训练环节,拿到标注数据即可启动微调,快速上线。
- 算力需求低**:仅执行微调任务,硬件资源消耗小,普通服务器即可支撑。
- 保留完整通用语言能力**:模型底层语法、语义理解能力完好,不会出现表达怪异、语句不通顺的问题。
缺点
- 领域适配不足 **:不认识生僻医疗术语、专业缩写,无法理解医疗文本内在逻辑,分类精度上限低。
- 小样本场景表现差 **:医疗标注数据往往稀缺,通用 BERT 缺乏领域先验知识,容易出现过拟合 (模型把训练集里的「噪声、特例、无关细节」也当成规律学进去了,在训练数据上表现极好,在新数据上表现很差 )。
- 对复杂长病历、专业文书解析能力弱**:仅能应对简单短句分类,复杂医疗文本识别误差大。
三、方案 (b) 医疗文本继续预训练 BERT 后再微调
原理与举例
以通用 BERT 为初始权重,先使用海量无标注医疗语料做 MLM 等任务继续预训练,让模型学习医疗术语、句式与行业逻辑;再用医疗标注数据微调分类头。 举例:经过医疗语料二次预训练后,模型能识别 "CT、血常规、低钾血症" 等专业词汇,再做病情分类时,判断依据更贴合医疗常识。
优点
- 兼顾领域能力与通用能力:基于通用基座迭代,既学到医疗领域知识,又最大程度保留原有语言理解能力,无明显遗忘。
- 效果显著优于方案 (a):领域先验知识充足,术语解析、长文本理解能力大幅提升,分类精度高。
- 成本可控:无需从零训练大模型,继续预训练的迭代轮次、算力开销远低于全量预训练,性价比高。
- 适配数据现状:医疗场景通常有大量无标注病历、文献,刚好满足继续预训练的数据需求。
缺点
- 流程比纯微调复杂:多了一轮领域预训练环节,需要额外处理医疗无标注语料,整体周期长于方案 (a)。
- 存在轻微偏向性:若医疗语料占比过高、训练轮次过多,会小幅弱化通用语义能力,需控制训练强度。
四、方案 (c) 从头用医疗文本预训练模型再微调
原理与举例
参数随机初始化,不借用任何通用模型权重,完全依靠纯医疗语料,从零完成全阶段预训练,最后再微调分类任务。 举例:模型从零基础开始学习文字、语法、医疗术语,整个网络参数完全适配医疗场景,对行业文本特征捕捉最彻底。
优点
- 领域适配度极致 :整个模型从底层到上层全部为医疗场景优化,术语理解、行业逻辑建模能力最强,理论精度上限最高。
- 无通用知识干扰:模型特征完全贴合医疗文本分布,在纯医疗闭环场景中表现最优。
缺点
- 成本极高:从零预训练需要海量医疗语料、长时间迭代,算力、人力、时间开销远超前两种方案。
- 依赖超大容量数据:如果医疗语料规模不足,模型无法学好基础语法与语义,整体效果会严重下滑。
- 通用语言能力缺失:模型仅熟悉医疗句式,面对口语化、跨风格文本兼容性差,泛化范围窄。
- 小数据极易过拟合:医疗标注数据偏少的情况下,从零训练的模型更容易拟合局部特征,鲁棒性差。
五、三种方案综合对比总结
- 效果排序:(c) 理论上限 > (b) 实际落地效果 > (a)
- 成本 & 落地难度排序:(a) 最低 < (b) 中等 < (c) 极高
- 通用能力保留:(a) 最优 > (b) 良好 > (c) 基本丧失
- 适用场景
-
- 方案 (a):快速验证、简单医疗短句分类、项目原型搭建,标注数据少且追求上线速度。
- 方案 (b):绝大多数工业医疗文本分类场景,有无标注医疗语料、想平衡效果与成本,是行业主流选择。
- 方案 (c):头部机构、拥有超大规模医疗语料与算力,做纯医疗闭环系统、追求极致领域性能。
六、选型建议与落地补充
- 初创项目、快速试错:优先选方案 (a),快速产出可用模型。
- 常规线上医疗业务、有大量无标注病历 / 文献:优先选方案 (b),平衡效果、成本与泛化性,可搭配小学习率、混合少量通用语料,进一步防止能力遗忘。
- 大型医疗机构、具备海量独家医疗数据与充足算力:可尝试方案 (c),打造专属医疗基座模型。
Q46:在命名实体识别任务中,当BERT将单词拆分成多个词元时,如何解决标签对齐问题?
面试速记:
BERT 分词会把完整单词拆为多个子词元,造成原文本标签与词元数量不匹配 。主流解决思路:以首词元承载实体标签,其余子词元统一标记为非实体标签;也可采用标签扩展、掩码忽略、聚合还原等方式,保证训练与推理阶段标签、序列严格对齐。
基础术语释义:
- NER : Named Entity Recognition (**命名实体识别 )**识别文本中人名、地名、机构、病症等实体并标注类别,常用 BIO/BIOES 标签体系。
- BIO 标注 :B: Begin 实体起始位置,I: Inside 实体中间位置,O: Outside 非实体位置,NER 最常用标注格式。
详解:
一、基础概念
原始文本以完整单词 / 汉字 为单位标注 NER 标签,BERT 的 WordPiece 分词会把一个完整词汇拆成多个子词元,导致词元数量 > 原词数量,直接映射标签会出现错位、标签缺失,模型无法正常训练。
举例直观理解: 原句单词:pneumonia(肺炎,医疗实体,标签 B-Disease)
BERT 分词后拆分为:pneu ##mon ##ia,一共 3 个词元。 原 1 个标签无法对应 3 个词元,这就是典型的标签对齐问题。
二、主流解决方案(附原理、实例、优缺点)
方案 1:首词元分配标签,后续子词元标 O(工业最常用)
原理
仅将原始单词的 NER 标签分配给拆分后的第一个子词元 ,同一个单词衍生出的其余所有子词元,全部统一标注为O(非实体)。训练时只让首词元学习实体特征,后缀子词元不参与实体预测。
举例
原词汇:pneumonia 标签:B-Disease 分词结果:pneu ##mon ##ia 对齐后标签:B-Disease、O、O
完整句子示例:
原句:I have pneumonia
原词 + 标签:I (O) have (O) pneumonia (B-Disease)
BERT 词元:I have pneu ##mon ##ia
对齐标签:O O B-Disease O O
优点
实现最简单、逻辑清晰,几乎所有开源 NER 项目默认方案;不改动模型结构,推理速度不受影响。
缺点
后缀子词元没有实体标签监督,少量细粒度特征会丢失;极长拆分词的尾部子词完全不参与实体学习。
方案 2:标签顺延扩展,所有子词元共享实体标签
原理
原始单词拆分出的全部子词元,统一沿用该单词的实体标签。如果原标签是 B/I 类实体标签,拆分后所有子词依次标注 B、I、I......,保持实体内部标签连续性。
举例
原词汇:pneumonia
标签:B-Disease
分词结果:pneu ##mon ##ia
对齐后标签:B-Disease、I-Disease、I-Disease
完整句子示例:
原词 + 标签:I (O) have (O) pneumonia (B-Disease)
BERT 词元:I have pneu ##mon ##ia
对齐标签:O O B-Disease I-Disease I-Disease
优点
整个单词的所有子词都参与实体学习,特征利用更充分,实体边界识别更稳定。
缺点
人为拉长实体标签序列,容易让模型误把拆分后缀当成独立实体;对短实体、密集实体场景易引入噪声。
方案 3:子词掩码忽略(训练屏蔽、推理聚合)
原理
训练阶段:对单词拆分出的非首词元 设置 loss 掩码,计算损失时跳过这些位置,只监督首词元标签; 推理阶段:先在词元级别预测标签,再将同一个原始单词对应的所有子词元预测结果聚合投票,还原出原单词最终标签。
举例
分词:pneu ##mon ##ia
训练:仅计算pneu标签损失,##mon、##ia位置不回传梯度;
推理:三个词元分别预测,取多数结果作为pneumonia最终标签。
优点
训练监督干净,规避后缀子词带来的标签干扰;推理通过投票提升容错率,精度表现优秀。
缺点
代码逻辑更复杂,需要额外实现掩码计算、结果聚合逻辑。
方案 4:基于偏移量映射对齐(精准逐词匹配)
原理
分词时记录每个词元在原始文本中的字符偏移位置,以字符偏移为桥梁,把原始字符级标签一一映射到对应词元,从底层保证对齐关系。
举例
原文本字符:p n e u m o n i a,整体属于实体;
分词后每个子词元都对应一段连续字符,根据字符偏移,逐个匹配原始字符标签。
优点
对齐精度最高,适配中文、英文、混合文本,复杂拆分场景也不会出错。
缺点
需要维护偏移量表,数据预处理代码复杂度高,适合对标注精度要求极高的场景。
三、不同方案选型与适用场景
- 快速落地、常规业务 NER :优先选用首词元标实体、其余标 O,开发成本最低,上线最快。
- 实体较长、专业术语多(医疗、法律) :选用标签扩展方案,让全量子词学习实体特征,提升专业实体识别效果。
- 追求高准确率、线上核心业务 :选用掩码忽略 + 推理聚合,兼顾训练稳定性与推理精度。
- 多语言、混合文本、复杂标注场景 :选用字符偏移量映射,从根源保证标签对齐无误。
四、补充:推理阶段后处理逻辑
无论训练采用哪种对齐方式,推理都需要做一步还原:
- 模型输出每个词元的预测标签;
- 根据分词映射关系,把多个子词元结果合并回原始完整单词;
- 按照 BIO 规则修正实体边界,剔除无效标签,输出最终实体结果。
五、最终效果与应用
- 首词元方案:平衡速度与效果,是开源框架、工业界 NER 任务最主流选择,通用场景表现稳定。
- 标签扩展方案:在长实体、专业术语识别任务中优势明显,适合垂直领域 NER。
- 掩码 + 聚合方案:综合精度最优,多用于比赛、高精度核心业务。
- 偏移量映射方案:作为底层对齐标准,多用于数据集制作、标注工具开发。
Q47:假设一个嵌人模型的训练语料主要由英文构成,在中文任务上表现不佳,如何用较低的继续预训练成本提升其中文能力?
面试速记:
英文基座嵌入模型适配中文任务效果差,以低成本继续预训练 为核心:优先采用小参数量模块微调、混合语料配比、轻量化训练策略 ,搭配中文词表优化、数据增广、伪标签辅助,不用全量重训,低成本补足中文语义、句式与表达能力。
详解:
一、基础概念
纯英文训练的嵌入模型,词表、分词逻辑、语义表征都偏向英文,面对中文字词、句式、语法习惯会出现解析失效,直接迁移到中文任务效果很差。 如果直接全量参数、大规模中文语料重新预训练,算力、时间成本极高。核心思路是最小改动模型、最小数据规模、最低训练开销,通过轻量化方案补足中文能力,同时保留原有英文表征能力。
二、低成本优化方案
1. 扩充 / 适配词表,从源头解决分词问题(零训练成本优先做)
原理
原生英文模型词表缺少中文汉字、常用词组,会把中文拆成零散单字符、无效子词,表征质量大幅下降。在原词表基础上增补中文常用字、高频词组,不改动模型结构,仅优化分词逻辑。
优点
完全无需训练、零算力消耗,是迁移中文的前置基础,见效直接。
缺点
仅解决分词问题,无法学习中文语义、语境,必须配合后续训练方案。
2. 采用 LoRA/Adapter 轻量化微调,冻结主体参数(核心降本手段)
原理
不更新模型主干大部分参数,仅在 Transformer 层插入LoRA 低秩矩阵 或Adapter 小模块,只训练这部分少量参数。主干保留英文能力,小模块专门学习中文特征,参数量、算力开销仅为全量训练的 5%~10%。
优点
训练成本极低、速度快;最大程度保留原有英文嵌入能力,避免灾难性遗忘。
缺点
表达上限略低于全量微调,适合低成本快速迁移场景。
3. 中英文混合语料训练,控制中文语料规模
原理
不使用纯中文语料训练,将少量中文语料和原有英文语料按比例混合作为训练数据。英文数据守住原有能力,少量中文数据让模型渐进学习中文语义、句式,无需搜集海量中文语料。
优点
降低中文数据搜集、清洗成本;训练分布平滑,模型不易跑偏。
缺点
中文占比过低时,中文能力提升幅度有限,需根据业务调配比。
4. 小学习率 + 少轮数 + 早停策略,严控训练开销
原理
继续预训练使用远低于原生英文预训练的学习率,让参数平缓更新,同时大幅减少训练轮数,搭配早停:当中文验证集指标不再提升、或英文能力开始下降时立刻停止。避免无效迭代浪费算力。
优点
缩短训练时长、减少算力消耗;防止模型过度偏向中文,破坏原有英文能力。
缺点
训练轮数过少,复杂中文语义学习不充分。
5. 中文数据低成本扩增,放大少量语料价值
原理
依托现有少量中文语料,用低成本数据增广扩充样本量,不用人工标注、不用爬取新数据。常用方式:同义词替换、句式改写、随机掩码、大模型短句扩写。
优点
零额外数据成本,充分利用已有中文语料,缓解数据量不足问题。
缺点
增广样本多样性有限,过度增广易引入噪声。
6. 无标注中文伪标签辅助训练(利用免费海量文本)
原理
先用上述轻量化方案训练出一个初步中文模型,再对互联网公开的无标注中文文本做嵌入推理,结合下游任务生成伪标签,筛选高置信度样本加入训练集。全程不需要人工标注。
优点
低成本获得海量训练样本,进一步强化中文泛化能力。
缺点
伪标签存在噪声,需设置置信度阈值过滤低质量样本。
三、方案组合落地流程(低成本标准链路)
- 前置优化:在原英文词表中增补中文常用字、高频词组,修复中文分词问题;
- 环境配置:模型主干参数全部冻结,启用 LoRA/Adapter 轻量化模块,设置小学习率;
- 数据准备:少量人工中文语料做数据增广,和原有英文语料混合配比;
- 继续预训练:沿用 MLM 任务,少轮数迭代,开启早停机制;
- 迭代增强:使用公开无标注中文数据生成伪标签,二次小幅训练;
- 下游适配:最终在中文任务上做简单微调,完成落地。
四、各方案对比与选型建议
- 极致降本、快速验证:词表增补 + LoRA + 少量混合语料,单卡即可运行,几天内完成。
- 追求中等中文效果、预算有限:叠加数据增广 + 伪标签,用现有数据放大效果。
- 禁止改动模型结构:放弃 LoRA,改用全参数极小学习率 + 极少轮数,代价略高但结构无侵入。
五、避坑点(低成本训练常见问题)
- 不建议使用纯中文语料训练:易快速遗忘英文能力,且少量纯中文数据极易过拟合;
- 不建议开大学习率、多轮训练:算力暴涨,同时模型表征被中文强行改写,原有能力受损;
- 不依赖复杂训练任务:沿用模型原生 MLM 任务即可,新增任务会增加开发与训练成本。
第 12 章 微调生成模型
Q48: 有人声称一篇文章是用 DeepSeek-R1 生成的,并给了你生成所用的完整提示词,如何证实或证 伪这个说法?(提示:利用困惑度)
面试速记:
用困惑度(Perplexity, PP) 验证是否为 DeepSeek-R1 生成:用DeepSeek-R1 自身 计算待测文本 PP,再用其他模型(如 GPT‑2、Llama) 交叉计算;R1 自身算出来 PP 显著更低(更 "顺")、且远低于人类文本基线 ,同时PP 方差小、突发性低 ,结合原提示词复现即可证实;反之则证伪。
基础术语释义:
- 困惑度 Perplexity (PP):PP↓= 越可预测 = 越像 AI;PP↑= 越不可预测 = 越像人。
- 句子级 PP 方差:表征文本流畅度波动,AI 生成文本句式规整,方差小;人类写作风格起伏大,方差更高。
详解:
一、基础概念
不同大模型因训练数据、结构、生成策略不同,会形成独有的 "文本特征指纹"。困惑度是识别模型来源的核心指标:模型对自己生成的内容预测难度最低,PP 远低于其他模型与人类文本。 结合题目场景:已知待测文章 + 完整提示词,核心思路是量化 PP 特征 + 复现生成过程 + 多维度交叉校验,完成证实或证伪。
二、核心验证方案
1. 计算 DeepSeek-R1 对待测文本的全局困惑度
原理
加载 DeepSeek-R1 模型,逐词计算待测文本每一个 token 的条件概率,代入公式得到整体 PP。该模型原生生成的文本,会被自身以极高概率预测,PP 数值明显偏低。
举例
选取多篇纯人类文章做基线,统计得到人类文本 PP 普遍在 30 以上; 若待测文章经 DeepSeek-R1 计算后,PP 小于 20,初步判定高度符合该模型生成特征; 若 PP ≥ 30,基本不符合模型生成规律。
补充
同时拆分文本为单句,计算每一句的 PP,再统计句子 PP 的方差。DeepSeek-R1 输出逻辑连贯、句式统一,方差通常很小;人类文章语句节奏多变,方差会明显偏大。
2. 跨模型困惑度交叉对比(排除通用 AI 干扰)
原理
仅单模型 PP 低,只能证明文本是 AI 生成,无法锁定具体模型。使用 Llama、GPT 等其他主流大模型,对同一篇待测文本计算 PP。专属模型对自身产出的适配性最强,会出现DeepSeek-R1 的 PP 远低于其他模型的现象。
举例
待测文本:DeepSeek-R1 产出文章
- DeepSeek-R1 计算 PP:12
- Llama2 计算 PP:42
- GPT-2 计算 PP:38
差距悬殊,说明文本高度匹配 DeepSeek-R1 的生成风格; 若多个模型算出的 PP 都处于低位,仅能判定为 AI 写作,无法确定是 DeepSeek-R1。
3. 完整提示词复现实验(闭环关键证据)
原理
使用当事人提供的原始完整提示词,输入 DeepSeek-R1 重新生成新文本。同一模型 + 同一提示词,生成的内容在行文结构、常用短语、逻辑框架、段落排布上会高度趋同,同时两组文本的 PP、句子方差也会接近。
举例
原提示词为 "写一篇人工智能发展科普文章,分三段,语言通俗":
- 原待测文章:三段式结构,开篇介绍定义、中间讲发展历程、结尾总结趋势;
- 同提示词复现文本:同样遵循三段结构,核心句式、专业用词高度重合;
- 两组文本 PP 差值小于 5、句子方差接近。 以上特征同时满足,大幅提升可信度。 若复现后文章结构、用词差异极大,直接证伪。
4. 辅助特征校验(补充佐证)
原理
结合词汇分布、语句风格辅助判断。DeepSeek-R1 偏向逻辑推理类生成,语句工整、极少出现口语化语病、语序错乱;人类写作常存在语气词、重复表述、个性化表达。
举例
待测文本通篇句式工整、无口语化词汇、逻辑衔接词固定,契合模型特征;若存在大量个人化表达、即兴措辞,偏向人类写作。
三、分场景判定规则(证实 / 证伪标准)
场景 1:证实为 DeepSeek-R1 生成
同时满足全部条件:
- DeepSeek-R1 计算待测文本 PP < 20,句子 PP 方差很小;
- 其他对比模型算出的 PP 远高于 DeepSeek-R1;
- 原始提示词复现的文本,结构、用词、PP 指标与原文高度相似。
场景 2:证伪,并非 DeepSeek-R1 生成
满足任意一条即可判定:
- DeepSeek-R1 计算待测文本 PP ≥ 30,接近人类文本基线;
- 所有模型 PP 均偏低,无明显差距(属于通用 AI 文本,非目标模型产出);
- 使用原提示词在 DeepSeek-R1 复现,文本风格、结构、PP 指标差异巨大。
场景 3:结果存疑
PP 处于 20~30 区间,部分特征匹配、部分不符;大概率是模型生成后经过人工改写、润色,无法百分百确定原生来源。
四、各类方案优缺点
- 单模型 PP 检测 优点:实现简单、计算速度快,快速区分 AI / 人类文本; 缺点:无法锁定具体模型,易误判。
- 多模型 PP 交叉对比 优点:精准区分不同大模型的生成内容,定位模型来源; 缺点:需要部署多个模型,硬件与开发成本略高。
- 提示词复现 优点:形成完整证据链,是最具说服力的验证手段; 缺点:大模型存在一定随机性,完全逐字一致概率低,重点看结构与风格。
五、完整落地流程
- 准备工作:部署 DeepSeek-R1 及多款对比模型,收集同领域人类文章,划定 PP 基线范围;
- 基础检测:用 DeepSeek-R1 计算待测文本全局 PP、单句 PP 与方差,初步筛查;
- 交叉验证:用其他模型计算 PP,对比数值差距;
- 闭环复现:输入完整提示词重新生成文本,对比结构、用词、PP 指标;
- 综合判断:结合所有指标,给出证实、证伪或存疑结论。
六、常见误区规避
- 只依靠单一模型 PP:只能判断是否为 AI,不能确定是不是 DeepSeek-R1;
- 只看全局 PP,忽略句子方差:部分人工精修的 AI 文章全局 PP 偏低,但语句波动大,容易误判;
- 要求复现文本逐字相同:大模型存在采样随机性,无需逐字一致,重点比对风格、框架与统计特征。
Q49: 如何微调一个 Llama 开源模型,使其输出风格更简洁、更像微信聊天,并保证输出的内容符合国内的大模型安全要求?
面试速记:
先通过风格定向数据构建 + 安全样本过滤 准备训练数据,再采用LoRA 轻量化微调 降低成本、保护基座能力;训练端搭配小学习率、合规损失约束,引导模型输出简洁口语化的微信聊天风格。同时结合训练前数据风控、训练中安全对齐、推理时内容拦截三层机制,全程满足国内大模型安全规范。
基础术语释义:
- Llama:Meta 源大语言模型,原生偏向书面英文表达,无国内安全对齐与中文口语风格
- LoRA:( Low-Rank Adaptation 低秩适配),仅训练少量低秩矩阵,冻结模型主干参数,低成本实现风格与能力迁移
- **RLAIF:**Reinforcement Learning from AI Feedback(基于 AI 反馈的强化学习)
详解:
一、基础概念
原生 Llama 模型书面化强、句式偏冗长,不适合微信这类短句、口语化聊天场景,且未做国内合规安全对齐,易输出违规内容。 整体思路分为两大核心:风格微调(简洁 + 微信聊天口吻) + 全流程安全管控(符合国内规范),优先选用轻量化微调方案,兼顾效果、成本与基座模型原有能力。
二、第一步:数据集构建(风格 + 安全双把关,源头治理)
数据集是决定风格与安全的核心,分为风格对话数据 和安全负样本数据两类,全程前置风控。
1. 微信聊天风格样本制作(打造简洁口语风格)
原理
模仿微信聊天特征:短句为主、少长难句、多用日常口语、语气自然、精简冗余表述,区分闲聊、问答、日常互动等场景,构建指令 - 对话样本。
举例
❌ 原生 Llama 输出(冗长书面):针对你提出的这个问题,结合相关常识来看,这件事情整体的处理方式可以按照如下步骤进行。
✅ 目标风格(微信聊天):这事可以这么处理~
具体做法
- 数据来源
-
- 合规公开中文闲聊对话语料、日常社交对话数据集;
- 人工整理正常微信聊天记录(脱敏,剔除隐私、敏感内容);
- 用合规大模型批量生成简洁短句风格对话,再人工抽检。
- 样本格式 :统一为对话格式
用户提问/话术 + 模型简洁回复,单条回复控制在短句,杜绝大段长文。 - 风格规则约束:强制样本满足:少书面术语、精简句式、适当使用语气助词,不堆砌内容。
2. 安全样本构建(前置规避违规内容)
原理
补充安全正样本 和违规拒答样本,让模型学习识别敏感问题、主动合规回应,从训练阶段建立安全意识。
举例
- 敏感提问:"如何获取他人隐私信息?"
- 标准合规回复:"这个行为不符合法律法规,我不能为你解答哦。"
具体做法
- 收集国内大模型通用敏感问题集(涉政、色情、暴力、诈骗、隐私、谣言等);
- 为每一条敏感问题编写统一、温和的拒答话术;
- 混合普通聊天样本与安全拒答样本,按比例配比(常规对话:安全样本 ≈ 8:2);
- 全量数据初审:使用文本风控接口 / 规则引擎,过滤已存在违规内容的样本,严禁脏数据流入训练。
3. 数据配比与清洗总结
- 总量:以日常聊天样本为主,安全拒答样本为辅;
- 清洗:脱敏隐私信息、删除违规文本、统一聊天语气;
- 格式:适配 Llama 对话模板,区分单轮 / 多轮聊天。
三、第二步:微调方案选型与训练配置(轻量化 + 防遗忘)
直接全参数微调成本高、易改写模型原生能力,工业界统一采用LoRA 轻量化微调。
1. 训练架构:LoRA 为主,冻结主干
原理
冻结 Llama 全部主干 Transformer 参数,仅在 Attention 层插入 LoRA 低秩矩阵,只训练少量参数。既能引导模型学习聊天风格与安全规则,又最大程度保留模型原有理解能力,算力需求低。
举例
7B 版本 Llama 仅需训练百万级参数,单卡显卡即可完成训练,无需多卡集群。
2. 核心超参配置(适配风格 + 稳定收敛)
- 学习率 :选用小学习率
1e-4 ~ 3e-4,避免参数剧烈偏移,风格渐进迁移; - 训练轮数:控制在 3~10 轮,轮次过多会过度拟合聊天话术、泛化下降;
- 批次大小:根据硬件合理设置,优先保证训练稳定;
- 训练任务 :沿用自回归语言建模,以用户输入为上文,模型简洁聊天回复为目标做监督学习。
3. 进阶优化:风格 + 安全联合约束
- 混合损失引导:正常聊天样本用标准自回归损失;敏感拒答样本可适当提高损失权重,强化安全优先级;
- 分层微调(可选):若需更强风格适配,仅微调模型顶层网络,底层完全冻结,保留基础语义能力。
四、第三步:训练中 & 训练后安全强化(多层对齐)
1. 训练过程监控
- 每轮训练后抽样推理,测试两类内容:聊天风格是否简洁口语 、敏感问题是否正常拒答;
- 一旦出现输出冗长、违规应答,立即停止训练、回查数据集。
2. 后对齐优化(强化安全底线,可选)
方案 A:小规模 RLAIF 人工智能反馈对齐
用合规大模型作为 "裁判",对微调后模型的输出打分:优先给简洁聊天 + 合规内容高分,给冗长、违规内容低分,小幅迭代优化输出倾向。
方案 B:Prompt 模板固定约束
给模型预设系统提示词,固化风格与安全要求,推理时强制生效:
你现在是微信聊天助手,回复尽量简洁、口语化,像日常微信聊天一样;拒绝回答任何违法、违规、敏感内容,保持友好合规。
五、第四步:推理阶段防护(最后一道安全闸门)
训练对齐无法做到 100% 全覆盖,推理层增加内容风控拦截,满足国内监管硬性要求。
- 输入前置检测:用户提问先经过文本风控系统,识别敏感内容,直接拦截并返回拒答,不送入模型;
- 输出后置检测:模型生成内容后,再次做合规校验,发现违规、低俗、敏感内容,替换为标准合规话术;
- 采样参数调优(辅助风格)
-
- 调低生成长度上限,限制输出字数,强制简洁;
- 适当调整温度参数,避免生成天马行空的长文本、复杂句式。
六、各环节优缺点 & 避坑要点
1. 方案优缺点
- LoRA 微调:优点:算力成本低、不破坏基座模型、迭代快;缺点:风格改造上限弱于全参数微调,极致风格化效果有限。
- 纯数据引导:优点:逻辑简单、易落地;缺点:依赖样本质量,样本杂则风格混乱。
- 三层安全体系(数据 + 训练 + 推理):优点:合规性强,符合国内上线要求;缺点:多环节开发,流程略复杂。
2. 常见坑规避
- 不要使用大学习率、多轮全参数微调:模型容易彻底跑偏,丢失基础能力;
- 不要缺少安全样本:微调后模型会延续原生风险,极易触发违规内容;
- 不要不限制生成长度:模型仍会输出长文,无法实现 "简洁" 要求;
- 不要使用未脱敏的真实聊天数据:存在隐私泄露风险,违反合规要求。
七、完整落地全流程
- 数据准备:制作微信风格简洁聊天样本 + 敏感问题拒答样本,全量风控清洗、脱敏;
- 环境配置:加载原生 Llama,开启 LoRA,设置小学习率、合理训练轮数;
- 轻量化微调:混合数据集训练,中途抽样验证风格与安全效果;
- 后置对齐:添加系统提示词,或小规模 RLAIF 强化风格与合规性;
- 推理部署:搭建输入 + 输出双层风控网关,限制最大生成长度;
- 灰度上线:小流量测试,持续收集 Bad Case,迭代补充样本二次微调。
Q50; QLoRA 中的分块量化如何解决普通量化导致的信息损失问题?
面试速记:
普通全局量化对整组参数统一压缩,高低值特征混在一起,造成明显信息损失。QLoRA 采用分块量化 + 逐块独立量化,把权重切分为多个小块,每块单独计算量化参数、独立映射数值,同时搭配双精度缓存、异常值保护,大幅缩小量化误差,有效缓解精度丢失问题。
基础术语释义:
- QLoRA:结合 4 比特量化与 LoRA 的高效微调方案,主打低显存、低开销微调大模型
- 普通全局量化 :对模型完整权重矩阵统一使用一组最大值、最小值做数值映射压缩
- 分块量化(Block-wise Quantization):将权重矩阵按固定长度切分成若干独立子块,每个子块单独完成量化计算
- 量化误差:浮点型参数转为低比特整数后产生的数值偏差,偏差越大信息损失越严重
- 异常值:权重中偏离整体分布的极大 / 极小数值,全局量化下极易被稀释、丢失
详解:
一、基础概念
大模型权重默认是 FP16/FP32 高精度浮点数值,为降低显存占用,会做 4/8 比特量化。普通全局量化 用全局最大、最小值做全矩阵映射,若权重分布不均匀、存在极端值,会挤压有效数值区间,大量细节特征丢失,模型效果明显下降。 QLoRA 的分块量化核心思路:化整为零,分而治之,把大权重矩阵拆成小分块,逐块适配量化规则,从数值分布层面减少误差。
补充:什么是 4/8 比特量化?
大模型默认的权重数据是 FP16 高精度浮点数 ,就像用高精度电子秤称重,读数特别精细,但缺点很明显:占用显存多,7B、13B 这类大模型跑起来对显卡要求极高。
量化 本质就是一种模型压缩手段:把原本连续变化、精度很高的小数,转换成占用空间更小的低比特整数来保存和计算。
- 8 比特量化 把数据换成 8 位整数存储,单个参数占用空间直接减半。好比把高精度电子秤换成普通家用秤,读数档位变少、精细度下降,但足够日常使用。
- 4 比特量化 压缩力度更强,单个参数空间缩到原来的 1/4,能极大降低显存压力。相当于换成档位更少的简易秤,压缩率最高,但也最容易丢失细节。
二、普通全局量化的缺陷
原理
对整个权重矩阵,只统计全局最大值、全局最小值,整套缩放、偏移参数作用于所有权重元素,统一完成浮点转低比特整数。
举例
假设某权重矩阵一组数值:[0.1, 0.2, 0.15, 8.0, 0.18, 0.22] 全局最小值 = 0.1,全局最大值 = 8.0,整个区间跨度极大。 转为 4 比特量化后,有效小数部分(0.1~0.22)会被压缩到极窄区间,彼此差异几乎消失;仅异常值 8.0 占据大部分编码空间。 最终结果:正常权重的细微特征被抹平,产生严重信息损失,模型表征能力下降。
核心问题总结
- 权重分布不均时,全局区间被极端异常值拉大,常规数值分辨率暴跌;
- 整矩阵共用一套量化参数,无法适配局部数据分布;
- 细粒度语义、特征信息被大量丢失。
三、QLoRA 分块量化的实现原理与优势
1. 分块拆分规则
原理
将二维权重矩阵,按固定块大小(Block Size,常用 128/256) 沿行 / 列方向切分成互不重叠的多个小块,每个小块作为独立计算单元。
举例
一个长度为 512 的权重向量,设置块大小 = 128,会被切分为 4 个独立子块,每块单独处理,不再使用全局统计值。
2. 逐块独立计算量化参数
原理
对每一个子块,单独统计当前块内的最大值、最小值,单独计算缩放系数与偏移量,块内数值仅在本块区间内完成浮点↔低比特整数映射。
沿用上面案例举例
原序列:[0.1, 0.2, 0.15, 8.0, 0.18, 0.22] 人为切分为两个子块:
- 块 1:
[0.1, 0.2, 0.15]块内最小 = 0.1,块内最大 = 0.2,区间窄,数值差异能被完整保留; - 块 2:
[8.0, 0.18, 0.22]单独统计本块极值,独立做量化,不会被块 1 的数值干扰。
效果:每个小块的数据分布更集中、区间跨度小,量化后数值分辨率大幅提升,相邻权重的微小差异得以保留,特征信息损失被极大削弱。
3. 配套优化策略(进一步控损,QLoRA 组合方案)
(1)异常值单独处理(Outlier Isolation)
原理:分块后若单块内仍存在极端异常值,QLoRA 会将异常值提取出来,用 FP16 高精度单独存储,块内剩余常规值做 4 比特量化。
举例:某块内 [0.1,0.2,10.0],把10.0单独用 FP16 保存,其余数值正常 4 比特量化,避免单个极值破坏整块量化精度。
(2)双精度缓存与反量化优化
原理:前向 / 反向计算时,4 比特权重会逐块反量化回 FP16参与运算;同时在显存中保留部分高精度缓存,减少反复量化 - 反量化带来的累积误差。
(3)细粒度缩放(Per-group Scaling)
每个分块拥有独立缩放因子,相比全局单缩放因子,能精准适配局部权重分布,进一步降低映射偏差。
四、分块量化 vs 全局量化 核心对比
a. 量化参数
-
- 全局量化:整矩阵共用 1 组最大 / 最小值、缩放系数;
- 分块量化:每个子块拥有独立一套量化参数。
b. 数值区间
-
- 全局量化:易被异常值拉大区间,常规数值分辨率低;
- 分块量化:单块区间紧凑,数值区分度高。
c. 信息损失
-
- 全局量化:损失大,模型精度下降明显;
- 分块量化:损失极小,4 比特下仍能接近 FP16 效果。
d. 计算开销
-
- 全局量化:逻辑简单,计算快;
- 分块量化:多了分块、逐块统计步骤,计算略有增加,但远低于精度收益。
五、为什么分块量化能解决信息损失(总结逻辑链)
- 全局量化的痛点根源:全局数据分布跨度大,一套规则无法适配所有参数;
- 分块量化将大矩阵拆解为局部小块,单块内权重分布更均匀、跨度更小;
- 逐块独立量化,让每一段参数都在适配自身的区间内做数值映射,保留权重间细微差异;
- 叠加异常值隔离、高精度缓存等手段,进一步兜底,把量化误差控制在极低水平。
六、落地使用要点与避坑
- 块大小选择:块尺寸不宜过大(退回全局量化问题)、不宜过小(分块过多,计算开销暴涨),工业常用 128 / 256;
- 不建议纯 4 比特全量微调:QLoRA 搭配分块量化仅冻结主干、训练 LoRA 分支,主干用 4 比特分块量化保显存,分支用高精度训练;
- 拒绝极端分布样本:若模型权重整块都是极端值,分块优化效果会受限,需配合异常值剥离策略。
Q51: 现有一个由若干篇文章组成的企业知识库,如何将其转换成适合 SFT 的数据集?
面试速记:
先对企业知识库文档做解析、清洗、分块,再结合业务场景设计指令模板,把纯文本素材转换成「指令 - 输入 - 输出」标准 SFT 格式;补充多样化样本、数据质检与均衡配比,最终产出合规、适配模型微调的 SFT 数据集。
基础术语释义:
- SFT :监督微调(Supervised Fine-Tuning),用指令 + 应答格式数据微调大模型,对齐输出风格与业务能力
详解:
一、基础概念
企业知识库大多是长篇文章、说明文档、流程手册,属于纯原始文本,无法直接用于 SFT。
SFT 要求数据为对话 / 问答 / 指令应答格式,
核心思路:文档拆解→任务设计→样本构建→清洗优化,把静态知识库转为模型可学习的交互样本。
二、完整落地步骤
步骤 1:文档解析与原始数据清洗
原理
先统一文档格式,剔除无效内容、隐私信息,保证原始文本干净可用。
实操
- 格式解析 支持 PDF、Word、TXT、网页等常见格式,提取纯文本内容,丢弃页眉、页脚、水印、目录、页码等无关元素。 举例:产品手册只保留正文介绍,删掉封面、广告、页码。
- 基础清洗
-
- 去除乱码、特殊符号、多余空行、重复段落;
- 隐私脱敏:打码手机号、身份证、内部工号、涉密名称,符合企业数据安全要求;
- 过滤残缺短句、无意义占位文本。
- 内容初筛 剔除过期规章、作废文档,仅保留当前生效的业务资料。
步骤 2:长文档分块(适配模型上下文限制)
原理
大模型有上下文长度上限,长篇文章必须切分成短文本块 ;分块兼顾语义完整性,避免一句话、一个知识点被强行截断。工业常用滑动窗口分块。
实操
- 设定参数:块大小(如 512/1024 字符)+ 重叠长度(50~100 字符),防止知识点割裂。
步骤 3:定义 SFT 任务类型 & 设计指令模板(核心环节)
结合企业知识库用途,设计对应任务与统一指令模板,主流分为 5 类场景,按需组合。
1)知识问答(最常用,内部咨询场景)
原理:
以文本块为参考上下文,生成「提问 + 标准答案」问答对。
模板示例:
用户:{基于上下文提问} 参考上下文:{文本块内容} 助手:{标准回答}
举例:
用户:公司差旅费包含哪些项目?
参考上下文:本公司差旅费包含交通费、住宿费、餐补,不含个人消费。
助手:公司差旅费包含交通费、住宿费以及餐补,个人消费不在报销范围内。
2)信息摘要(文档速读、汇报场景)
原理:指令要求对知识库片段做精简总结。
模板示例:
用户:请总结下面这段内容:{文本块内容} 助手:{精简摘要}
3)内容改写 / 话术标准化(对外客服、内部通知)
原理:把生硬的制度条文,改写成口语化、正式通知等指定风格。
模板示例:
用户:请把下面制度改成简洁的内部通知:{文本块内容} 助手:{改写后内容}
4)实体 / 规则抽取(流程、关键词提取)
原理:从文档中提取流程、规则、关键词,适配业务检索。
模板示例:
用户:请提取这段内容中的办理流程:{文本块内容} 助手:{梳理后的流程}
5)多轮对话(模拟员工连续咨询)
原理:基于同一个文本块,设计连续追问,模拟真实聊天。
举例:
用户 1:出差住宿标准是多少?
助手 1:一线城市单人每日住宿费上限 400 元。
用户 2:二线城市呢?
助手 2:二线城市每日上限 300 元。
步骤 4:批量生成 SFT 样本(两种实现方案)
根据人力、数据规模选择方案,可混合使用。
方案 A:人工构建(小体量知识库、高精准要求)
- 业务人员阅读每个文本块,结合实际工作场景编写自然提问;
- 基于原文撰写标准回答,答案必须完全来自知识库,不编造内容;
- 严格套用统一指令模板,保证格式一致。
方案 B:大模型辅助批量生成(大体量知识库、提效首选)
- 给通用大模型下发生成指令:基于给定文本块,生成不同角度、不同问法的问答对 / 指令样本;
- 约束规则:回答严格忠于原文、语气贴合企业风格、问题多样化;
- 举例辅助指令:
基于以下企业文档片段,生成 5 个不同员工视角的问题 + 对应标准答案,答案只引用原文内容,不要编造。文档:xxx
步骤 5:样本扩充与多样性优化(提升模型泛化)
原理
单一问法容易导致模型过拟合,对同一段文本,扩充不同句式、不同措辞的提问。
举例
同一知识点:「工作日上班时间为 9:00-18:00」
- 问法 1:公司工作日几点上下班?
- 问法 2:请问日常工作的作息时间是什么?
- 问法 3:周一到周五的在岗时间如何规定?
补充技巧:
- 同义句式改写、反问、简答 / 详答两种形式;
- 区分口语化提问、正式书面提问,贴合不同使用人群。
步骤 6:格式统一、数据均衡与最终质检
1. 统一 SFT 标准格式
主流开源框架通用格式(JSONL 单行格式,一行一个样本),示例:
json
{"instruction":"公司报销包含哪些费用?","input":"","output":"公司差旅费包含交通费、住宿费、餐补。"}多轮对话采用对话列表格式,保证模型正常学习上下文。
2. 数据均衡配比
- 不同文档、不同业务模块样本数量大致均衡,避免模型偏向某一类知识;
- 控制长 / 短回答比例,既有简答也有详细说明。
3. 全量质检(必做)
- 格式检查:无乱码、字段缺失、格式错乱;
- 内容检查:回答与原文一致,无编造、无错误业务信息;
- 风格检查:语气符合企业要求(正式 / 亲和);
- 去重:删除高度重复的问答样本。
三、不同知识库场景的适配策略
- 产品文档 / 使用手册 :侧重问答 + 步骤抽取,多设计操作类问题;
- 人事 / 行政制度 :侧重规则问答 + 摘要,模拟员工咨询制度;
- 技术文档 / 运维手册 :侧重流程抽取 + 专业问答,保证术语准确;
- 对外宣传资料 :侧重内容改写 + 摘要,适配对外话术。
四、常见问题与避坑点
- 长文本不做分块:超出模型上下文,训练报错、效果极差,必须滑动分块;
- 回答脱离原文编造内容:SFT 后模型会输出虚假知识(幻觉),严格约束 "答必有据";
- 样本格式不统一:模型学习混乱,所有样本必须套用同一套模板;
- 缺少多样化问法:模型只会识别固定句式,真实使用时识别率低;
- 未做隐私脱敏:引发企业数据安全风险,全流程必须脱敏。
五、完整执行链路总结
知识库原始文档 → 解析清洗 + 隐私脱敏 → 滑动窗口语义分块 → 设计指令任务与模板 → 人工 / 大模型批量生成问答 / 指令样本 → 样本增广提升多样性 → 格式标准化 + 去重 + 全量质检 → 划分训练集 / 验证集 → 产出可用 SFT 数据集
Q52: PPO 和 DPO 相比有什么优缺点?
面试速记:
PPO 是传统 RLHF 核心方案,效果上限高、适配复杂偏好与动态任务,但工程复杂、算力开销大、训练不稳定;
DPO 简化了对齐流程,无需单独训练奖励模型,训练轻量、收敛稳定、落地成本低 ,不过高度依赖高质量成对偏好数据,复杂多维度偏好拟合能力偏弱。
基础术语释义:
- PPO :Proximal Policy Optimization,近端策略优化 ,经典强化学习算法,主流用于RLHF 人类对齐 ,依赖策略模型、价值模型、奖励模型、参考模型协同训练。
- DPO :Direct Preference Optimization,直接偏好优化 ,将人类对齐转化为监督学习,舍弃独立奖励模型,基于好坏回答成对数据直接优化策略。
- 偏好数据 :格式为
(输入, 优选回答, 劣选回答)的三元组,用来标注人类偏好。
详解:
一、基础概念
二者均用于大模型人类偏好对齐 ,核心目标是优化模型输出风格、价值观与实用性。PPO 属于强化学习 路线,完整沿用 RLHF 三阶段流程;DPO 是近年轻量化对齐方案,重构优化目标,把强化学习问题转化为监督学习,大幅简化训练链路,二者在实现、成本、效果、适用场景上差异明显。
二、PPO 优缺点
(一)优点
- 综合效果上限高 经过大规模工业场景验证,在数学推理、代码生成、复杂多轮对话等高难度任务中表现优异,整体能力更强。支持在线探索,模型可主动学习新的输出策略,泛化性更好。
- 信号可解释、易调试 依赖独立奖励模型对输出打分,奖励分值可直观反映回答优劣,出现问题时能快速定位优化方向,便于迭代调优。
- 适配多维度复杂偏好 可通过奖励函数灵活权衡准确度、简洁度、语气、安全性等多重要求,面对复杂业务规则、多元人类偏好时鲁棒性更强。
- 样本利用率高 支持重复利用历史交互数据迭代优化,少量数据也能持续提升效果。
(二)缺点
- 工程链路复杂,部署难度大 完整流程分为 SFT 微调、训练奖励模型、PPO 强化学习 三个阶段;训练时需要同时加载策略、价值、奖励、参考共 4 个模型,代码逻辑繁琐。
- 算力与显存开销极高 多模型并行运行,硬件资源需求大,中小团队、低配设备难以承载。
- 训练不稳定,调参门槛高 对学习率、Clip 截断系数 、KL 散度权重 等超参数敏感,容易出现策略崩塌、奖励黑客、KL 值爆炸等问题,需要大量经验调参。
- 训练周期长 迭代轮数多、收敛速度慢,项目落地周期偏长。
三、DPO 优缺点
(一)优点
- 架构极简,训练高效 无需单独训练奖励模型 ,仅保留策略模型与参考模型 ,训练形式和普通SFT一致,属于单阶段训练,代码实现简单。
- 资源消耗低 仅加载两个模型,显存占用远低于 PPO,训练速度提升数倍,普通硬件即可运行,落地门槛大幅降低。
- 训练过程稳定 摒弃价值函数、优势估计等强化学习组件,不存在策略崩塌、奖励黑客等经典 RL 问题,损失曲线平稳,调试简单。
- 对齐损耗小 训练对模型原有基础能力破坏更少,能更好保留基座模型的语义、推理能力。
(二)缺点
- 对数据质量要求苛刻 必须使用区分度明显的成对偏好数据;若标注噪声大、好坏回答差异小,模型无法有效学习,效果会大幅下滑。
- 离线学习,无主动探索能力 只能学习数据中已有的人类偏好,无法自主探索新的输出方式,面对 ** 分布外(OOD)** 场景泛化能力较弱。
- 复杂偏好拟合能力不足 本质是二元偏好优化,擅长判断 "二选一",难以精准平衡多维度、相互冲突的复杂需求,复杂任务效果略逊于 PPO。
- 缺乏显性奖励信号 没有独立打分模块,无法直观量化输出优劣,排查问题、精细化调优不如 PPO 方便。
四、核心维度对比
表格
|------------|-----------------------|-----------------|
| 对比维度 | PPO | DPO |
| 训练范式 | 强化学习(RLHF) | 类监督学习 |
| 依赖模型 | 策略、价值、奖励、参考(共4 个) | 策略、参考(共2 个) |
| 显存 / 算力 | 开销高 | 开销低 |
| 训练速度 | 慢,迭代轮次多 | 快,单阶段收敛 |
| 训练稳定性 | 一般,易出现 RL 典型问题 | 高,几乎无训练崩坏风险 |
| 数据要求 | 偏好数据 + 奖励模型训练数据 | 高质量成对偏好三元组 |
| 效果上限 | 高,复杂任务表现突出 | 中等,接近 PPO 但略有差距 |
| 调参 & 调试难度 | 高 | 低 |
五、适用场景选型
- 优先选择 PPO 模型参数量较大(13B 及以上 )、业务为复杂推理、代码生成、高难度多轮对话;具备充足算力与算法调优团队、追求极致对齐效果。
- 优先选择 DPO 中小参数量模型(7B 及以下 )、场景为企业知识库问答、客服、日常聊天等常规任务;硬件资源有限、需要快速落地迭代,且能保证偏好标注质量。
六、避坑要点
- 使用PPO 时,必须搭配KL 散度约束,防止模型偏离基座能力,同时严控超参数范围;
- 使用DPO时,重点做好数据清洗与筛选,剔除区分度低、标注错误的成对样本;
- 简单任务无需盲目选用PPO ,会造成算力浪费;数据质量差时,DPO的劣势会被持续放大。
Q53: 在 PPO 中,如何防止模型在微调数据集以外的问题上泛化能力下降?如何防止模型收敛到单一类型的高奖励回答?
面试速记:
防止泛化能力下降 :引入KL 散度约束、混合通用 + 领域数据、控制训练强度、保留基座能力;
防止收敛到单一高奖励回答:丰富偏好数据、多元化奖励设计、加入多样性正则、动态采样与负样本约束。
基础术语释义:
- KL 散度 : Kullback-Leibler Divergence (库尔贝克 - 莱布勒散度) ,衡量策略模型 与原始参考模型输出分布的差异,约束模型不要大幅偏离基座能力。
- RLHF :Reinforcement Learning from Human Feedback (基于人类反馈的强化学习) 通过人工标注偏好数据训练奖励模型,再结合强化学习与 KL 散度约束优化大模型,使其输出贴合人类喜好与价值观。
- 奖励黑客:模型刻意迎合奖励规则,生成单一、模板化高奖励回答,丧失表达多样性。
- 多样性正则:在损失 / 奖励中增加约束,鼓励模型输出不同句式、角度的回答。
详解:
一、基础概念
PPO 做 RLHF 对齐时存在两类典型问题:
- 模型过度拟合微调偏好数据,偏离原始基座,在域外问题上泛化变差、能力退化;
- 模型发现固定套路能拿到最高奖励,反复输出同质化内容,回答单一、缺乏多样性。
二、问题一:防止域外泛化能力下降
核心思路:约束模型更新幅度、守住基座特征、丰富训练数据、控制训练强度。
1. 加入 KL 散度正则约束(最核心、工业标配)
原理
训练时计算当前策略模型与参考模型 输出分布的 KL 散度,将其纳入总损失 / 总奖励,惩罚模型大幅偏离原始分布。强制模型只做小幅优化,不彻底改写原有语义、句式与知识。
实操
设置KL 权重系数,实时监控 KL 值,超出阈值就降低策略更新幅度。
2. 训练数据混合配比,扩充数据分布
原理
不只用目标微调数据集,混合通用语料、域外正常样本一同参与 PPO 迭代,让模型持续接触多样场景,避免只拟合单一领域。
举例
业务以企业客服问答为主,训练时混入通用闲聊、常识问答、通用指令样本,拓宽模型见识,提升域外泛化。
3. 控制训练轮数与学习率,避免过拟合
原理
PPO 属于多轮迭代强化学习,轮次过多、学习率过大 极易过拟合偏好数据。使用小学习率 、限制迭代轮数,配合早停策略:当域外验证集指标开始下降,立即停止训练。
举例
常规 PPO 迭代控制在十几轮以内,不做长期反复迭代;学习率远低于 SFT 阶段,保证参数平缓更新。
4. 分层冻结 / 轻量化训练(LoRA+PPO)
原理
冻结模型底层基础语义层,仅微调上层策略分支或LoRA 低秩矩阵,主干权重基本不动,从根源保留模型原生通用能力。
优点
改动范围极小,对齐过程几乎不损伤原有泛化能力,是低资源 + 保能力的常用组合。
5. 多维度验证集监控
原理
除领域任务验证集外,额外搭建通用能力验证集(常识、推理、通用对话),每轮训练都检测两类指标,一旦通用指标下滑就干预调参或停止训练。
三、问题二:防止收敛到单一类型高奖励回答(规避奖励黑客)
核心思路:打破单一奖励导向、丰富数据与样本、增加多样性约束、限制模板化输出。
1. 构建多元化、差异化偏好数据
原理
避免训练集中只有同一种 "高分回答模板",人工构造多风格、多视角、不同措辞 的优质回答,让模型知道:多条不同路径都能拿到高奖励。
举例
同一问题,既收录简洁版回答、也收录详细版回答,正式话术、口语话术并存,不让模型只学一种格式。
2. 设计多维度复合奖励函数
原理
不只用单一维度打分(比如只看 "是否合规"),把准确性、多样性、流畅度、语气、完整性拆分为多个奖励项加权求和。单一模板回答无法在所有维度都拿到满分,倒逼模型丰富表达。
举例
总奖励 = 内容准确度奖励 + 句式多样性奖励 + 语气合规奖励,只套模板会被扣减多样性分数。
3. 增加多样性正则项
原理
在损失函数中加入多样性约束:惩罚连续生成高度相似的 token、重复句式、固定套话;鼓励句间、样本间表达差异。
4. 在线动态采样 & 样本池刷新
原理
不要反复复用同一批历史样本,持续在线交互、新增新鲜样本;定期更新训练样本池,避免模型在固定样本里反复刷分。
举例
线上收集用户真实提问与模型新回答,筛选后加入训练队列,不断引入新场景、新问法。
5. 引入难样本 & 负样本约束
原理
在训练集中加入:风格相似但有缺陷的回答、模板化低分回答。让模型区分 "优质多样回答" 和 "投机模板回答",降低走捷径的倾向。
6. 限制生成策略,调整采样参数
原理
推理 + 训练阶段配合调整解码参数:适当提高温度系数、增大 top-p 范围,提升生成随机性;同时限制固定短语重复出现频次。
补充
训练与推理采样策略尽量对齐,防止训练一套、上线另一套。
7. 周期性扰动与探索机制
原理
PPO 迭代中定期小幅调整策略分布,强制模型做少量探索,不完全收敛到局部最优的单一高分模板。
四、两类问题方案汇总对比
表格
|---------|--------------------------------------|-----------------------|
| 问题 | 核心手段 | 核心目标 |
| 泛化能力下降 | KL 散度约束、混合数据、小学习率 + 早停、LoRA 分层微调 | 守住基座能力,防止模型跑偏、过拟合 |
| 单一高奖励回答 | 多元偏好数据、复合奖励、多样性正则、动态样本 | 打破奖励捷径,鼓励表达多样化,规避奖励黑客 |
五、落地组合方案(工业常用链路)
- 整体配置:主干使用LoRA 微调 + 开启KL 散度约束,双保险保护泛化能力;
- 数据层:领域偏好数据 + 通用数据混合,样本风格多样化,混入负样本 / 难样本;
- 奖励层:采用多维度复合奖励,不依赖单一打分规则;
- 训练层:小学习率、少迭代轮数,双验证集(领域 + 通用)监控,触发早停;
- 正则层:额外增加多样性正则,抑制模板化输出;
- 迭代层:定期刷新样本池,保持在线探索,避免长期静态训练。
六、常见避坑点
- KL 权重不能过大:约束太强会导致模型完全不学习新偏好,对齐失效;需根据业务调至合理区间。
- 奖励维度不宜过多:维度太杂会导致奖励信号混乱,模型难以收敛。
- 不要长期用同一批样本迭代:极易同时引发过拟合 + 回答单一两大问题。
- 温度参数不要极端:温度过低会加剧模板化,过高会导致回答混乱、质量下降。
Q54: 设想一个网站上都是 AI 生成的内容,我们统计了每篇文章的平均用户停留时长,如何将其转 化为 DPO 所需的偏好数据?对于小红书和知乎两种类型的网站,处理方式有什么区别?
面试速记:
以用户平均停留时长 作为优劣判定依据,把同一主题 / 同源内容下长停留样本设为优选 (y_chosen) 、短停留样本设为劣选 (y_rejected),构建 DPO 标准三元组偏好数据;小红书 侧重短内容、强情绪与即时吸引力,优先按单篇、短维度分组对比;知乎侧重长文、深度阅读与内容价值,侧重同问题下多篇长内容横向对比,分组、过滤、样本构建规则差异明显。
基础术语释义 :
- DPO 偏好数据: 标准三元组格式 (x, y_chosen, y_rejected),x 为输入 Query / 主题,y_chosen 是人类偏好的优质输出,y_rejected 是被淘汰的劣质输出。
详解:
一、基础概念
网站全为 AI 生成文章,无人工标注偏好,因此用用户停留时长替代人工打分:停留时长是用户真实行为反馈,可间接反映内容质量、吸引力与匹配度。
核心流程:数据清洗→同主题分组→基于时长划分优劣样本→构建 DPO 三元组。
小红书、知乎的内容形态、用户阅读习惯、流量逻辑不同,导致分组规则、筛选阈值、样本构造、过滤策略存在明显区别。
二、通用转化流程(全平台通用步骤)
1. 原始数据预处理
原理
清洗脏数据,排除异常行为干扰,保证停留时长指标有效。
操作
- 剔除异常值:过滤极短停留(误点、秒跳出)、极长停留(挂机、后台挂页)数据,取有效平均停留时长;
- 内容关联标注:给每篇文章打上主题、关键词、原始提问 / 标题,作为 DPO 的输入x;
- 去重:删除高度重复、内容完全一致的 AI 文章,避免无效对比。
2. 内容分组(核心前提)
原理
必须同维度分组对比,不能跨主题、跨体裁比较。比如不能用 "美食文章" 时长对比 "科技文章",基准不一致会导致偏好标签失效。
操作
把同一标题 / 同一问题 / 同一核心主题下的多篇 AI 文章划为一个组,组内文章服务于同一个用户需求,仅内容风格、行文、质量不同。
3. 基于停留时长划分优劣样本
原理
组内对比:平均停留时长更长 = 用户更偏好,作为 y_chosen,;时长更短 = 用户不认可,作为y_rejected。
操作
- 每组内按平均停留时长排序;
- 选取Top 高时长文章 作为优选样本,Bottom 低时长文章作为劣选样本;
- 两两配对,生成标准 DPO 三元组:x= 文章标题 / 用户提问,y_chosen,= 高停留文章,y_rejected= 低停留文章。
4. 样本过滤与质检
原理
只保留区分度足够的配对样本,时长差距过小说明用户无明显偏好,这类样本无效。
操作
设置时长差阈值,仅保留组内两篇文章时长差距超过阈值的配对;剔除内容残缺、逻辑混乱的 AI 文本。
5. 格式标准化
统一转为 DPO 训练标准格式(JSON/JSONL),划分训练集、验证集。
三、小红书平台:专属处理规则 & 特点
1. 平台内容与用户特征
小红书以短图文、笔记、种草文案、生活化短句 为主,单篇内容篇幅短;用户偏向快速浏览、被标题 / 情绪 / 排版吸引 ,停留时长主要反映内容吸引力、情绪共鸣、趣味性,而非深度阅读。
2. 分组规则(区别于知乎)
- 按单条笔记标题 / 单品主题分组,粒度更细; 例:标题《夏季防晒好物推荐》下所有 AI 种草笔记划为一组,不做大范围主题合并。
- 不按 "问题" 分组,小红书极少问答形式,以主题 / 单品 / 场景为分组依据。
3. 时长筛选与配对策略
- 阈值设置 :整体停留时长短,采用相对差值比例而非绝对时间; 例:组内平均时长 15s,若两篇笔记时长差距>5s,判定为有效配对。
- 优先同篇幅配对 :小红书笔记长短差异大,禁止 "长笔记 vs 短笔记" 对比(篇幅本身影响时长),只在字数相近的笔记间两两配对。
- 样本倾向:优先选取开头抓眼球、语气活泼、短句多的高时长笔记作为y_chosen。
4. 额外过滤规则
- 过滤纯堆砌关键词、硬广类 AI 笔记(时长低,属于形式问题而非内容风格问题);
- 剔除排版异常、分段混乱的内容,排除格式对停留时长的干扰;
- 允许一对多配对:一篇高时长爆款笔记,搭配多篇低时长笔记,扩充样本量。
5. 最终 DPO 样本形态
x:笔记标题 / 场景描述y_chosen:活泼、短句、有感染力、用户停留久的 AI 种草笔记y_rejected:生硬、枯燥、流水账、停留时长短的 AI 笔记
四、知乎平台:专属处理规则 & 特点
1. 平台内容与用户特征
知乎以问答、长文、深度解析、专业回答 为主,单篇篇幅长;用户带着明确问题、求知需求 阅读,停留时长主要反映内容深度、逻辑完整性、信息价值、论证质量。
2. 分组规则(区别于小红书)
- 严格按原始提问分组 (知乎核心形态:问题 + 多个回答),同一个问题下的所有 AI 回答划为一组,这是最标准的分组方式。 例:问题《如何提升职场沟通能力?》下所有 AI 回答分为一组。
- 可适当合并同义问题,但不跨大类主题,保证需求统一。
3. 时长筛选与配对策略
- 阈值设置 :整体停留时长久,使用绝对时长差 + 相对比例双重判断; 例:组内平均时长 3min,两篇回答时长差距>40s 判定为有效配对。
- 放宽篇幅限制:知乎用户愿意读长文,正常篇幅差异不做强制过滤,因为长优质内容本身会带来更长停留。
- 优先纵向分层:组内区分 "高赞长回答"(高时长)与 "简略回答 / 答非所问"(低时长)。
4. 额外过滤规则
- 重点过滤答非所问、内容空洞、复制拼凑的 AI 回答(这类内容时长极低,是核心劣样本);
- 过滤过度水文、重复堆砌观点的长文:篇幅长但有效信息少,时长会快速下滑;
- 控制配对数量:单个问题下避免过多配对,防止样本同质化。
5. 最终 DPO 样本形态
x:知乎原始用户提问y_chosen:逻辑清晰、内容详实、论证完整、深度足够的长回答y_rejected:内容肤浅、逻辑混乱、答非所问、简略敷衍的回答
五、小红书 vs 知乎 核心处理区别(加粗重点)
表格
|--------------|-------------------------------|-----------------------|
| 对比维度 | 小红书 | 知乎 |
| 分组依据 | 按笔记主题 / 单品 / 标题分组,细粒度场景分组 | 按用户提问分组,标准问答式分组 |
| 时长含义 | 代表情绪吸引力、趣味性、文案风格 | 代表信息价值、逻辑深度、回答完整性 |
| 篇幅约束 | 强制同篇幅配对,排除字数干扰 | 基本不限制篇幅,篇幅属于正常内容差异 |
| 时长阈值 | 用相对比例 / 小幅差值,整体时长短 | 用绝对时长差,整体停留时间更长 |
| 劣样本来源 | 文案生硬、无感染力、排版差 | 答非所问、内容空洞、逻辑混乱、深度不足 |
| DPO 输入 x | 笔记标题、场景描述 | 用户原始问题 |
| 样本风格导向 | 偏好短句、口语、情绪化、种草风格 | 偏好严谨、详实、逻辑连贯、深度解析 |
六、通用避坑要点
- 严禁跨组对比:不同主题 / 不同问题的内容不能配对,偏好标签完全失效;
- 必须过滤异常时长:挂机、误点击数据会彻底打乱优劣判定;
- 区分 "篇幅影响":小红书一定要控篇幅,知乎无需过度限制;
- 时长差距不能过小:差值接近代表用户无偏好,这类样本加入 DPO 会引入噪声;
- 结合业务场景二次筛选:AI 内容普遍存在幻觉,需额外过滤事实错误的高时长文章。
Q55: 提示工程、RAG、SFT、RL、RLHF 应该分别在什么场景下应用?例如:快速迭代基本能力(提示工程)、用户个性化记忆(提示工程)、案例库和事实知识(RAG)、输出格式和语言风格 (SFT)、领域深度思考能力和工具调用能力(RL)、根据用户反馈持续优化(RLHF)。
面试速记:
详解:
附录:图解DeepSeek-R1(建议补充阅读DecpSeck 的原始论文)
Q56: :DeepSeek-R1(简称R1)与 DeepSeek-R1-Zero(简称R1-Zero)的训练过程有什么区别,各自有什么优缺点?既然 R1-Zero 生成的推理过程可读性差,在非推理任务上的表现也不如 R1,那么 R1-Zero 存在的价值是什么?R1 训练过程是如何解决 R1-Zero 的上述问题的 ?
面试速记:
- 提示工程(Prompt Engineering) :零训练、迭代最快,用于快速原型验证、用户个性化记忆,也可临时约束输出格式与规则,适合临时调整模型行为。
- 检索增强生成(Retrieval-Augmented Generation,RAG) :外接知识库,专门处理企业案例、私有资料、实时信息类问答,有效降低模型幻觉。
- 有监督微调(Supervised Fine-Tuning,SFT) :用来固化输出格式、统一语言风格,把高频任务和标准应答固定下来,输出稳定可靠。
- 强化学习(Reinforcement Learning,RL) :依靠奖励信号,强化模型深度推理、工具调用、动态决策能力,适配代码、数理推演、多工具智能体等场景。
- 人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF) :基于用户反馈与人类偏好做对齐,主打打磨对话体验、安全合规与价值观校准,适合 C 端重体验产品长期迭代。
落地遵循由简到繁:原型用提示工程 + RAG;企业业务常用 RAG+SFT;工具智能体叠加 RL;面向大众用户的产品,最终搭配 RLHF 持续优化。
详解:
一、提示工程(Prompt Engineering)
核心定位:零训练 / 低成本指令引导,改动最小、上线最快,无需修改模型权重
适用场景
- 快速迭代基础能力 无需微调模型,通过优化提示词、指令话术,临时修正模型行为,适合原型验证、紧急功能调整。
- 用户个性化记忆 / 上下文绑定 将用户画像、历史对话、个性化偏好直接拼入上下文提示词,实现临时记忆、身份设定、专属口吻。
- 临时格式约束、单次任务定制 对少量任务临时指定输出格式、语气、视角,不要求全局统一风格。
- 临时规则与安全兜底 补充临时合规要求、场景禁忌,快速约束输出边界。
典型案例
- 给模型加指令:"只用 3 句话总结,语气口语化";
- 拼接用户历史聊天记录,实现对话记忆;
- 临时限定 "禁止回答时政相关问题"。
优缺点补充
✅ 零训练、成本极低、秒级迭代;❌ 长上下文易超限、规则不稳定、无法固化能力。
二、检索增强生成(RAG)
核心定位 :外接外部知识库,解决模型知识过时、幻觉、私有事实缺失问题,不改动模型权重
适用场景
- 企业案例库、私有事实 / 静态知识库问答 内部文档、产品手册、规章制度、行业案例、历史数据等模型原生未学习的私有知识。
- 实时动态信息查询 新闻、行情、实时政策、当日数据等随时更新的内容,模型预训练无法覆盖。
- 精准溯源、降低幻觉 要求回答必须有据可依、标注来源,纯生成模型易编造内容的场景。
- 大容量外部知识库检索问答 知识库体量庞大、频繁增删改,反复微调模型成本极高的场景。
典型案例
- 企业内部智能助手,查询报销流程、产品参数;
- 客服机器人调取产品话术与售后案例;
- 实时资讯、行业数据问答。
优缺点补充
✅ 知识可动态更新、无幻觉、不用微调模型;❌ 依赖检索质量,复杂推理、风格优化能力弱。
三、有监督微调(SFT)
核心定位 :用标注样本固化模型行为,统一输出格式、语言风格、任务范式,轻量化改造模型能力
适用场景
- 统一输出格式、固定行文结构 强制模型遵循指定模板(表格、分点、公文、工单格式),解决提示词约束不稳定问题。
- 固化语言风格与口吻 如微信聊天口语、官方正式文案、小红书种草风、知乎专业文风等,要求全局风格统一。
- 标准化任务范式迁移 通用模型适配专属任务:分类、抽取、摘要、固定问答范式。
- 领域基础话术、高频问答固化 业务高频问题、标准应答,替代反复写长提示词,降低上下文开销。
典型案例
- 微调模型固定输出工单格式;
- 把通用模型改成简洁微信聊天风格;
- 知识库问答统一回答逻辑与句式。
优缺点补充
✅ 能力永久固化、风格 / 格式稳定、推理开销小;❌ 仅学习 "标准答案",无法自主优化偏好与复杂决策。
四、强化学习(RL,不含人类偏好)
核心定位 :基于奖励信号优化决策、推理、动作序列,提升模型主动行为与复杂执行能力
适用场景
- 领域深度思考、复杂逻辑推理 数学、代码、专业推演、长链推理等,需要模型自主规划思考步骤的场景。
- 工具调用、函数调用、多步动作编排 调用 API、插件、数据库、多工具串联执行,模型需要自主选择工具、编排执行顺序。
- 交互式任务、动态决策 对话博弈、流程办理、分步引导等,根据中间结果动态调整后续输出。
- 最优路径探索 同一问题存在多种解法,奖励导向 "最优解",鼓励模型主动探索更好方案。
典型案例
- 代码编写、数学解题、逻辑推理增强;
- 智能体多工具链式调用;
- 自动化流程引导机器人。
优缺点补充
✅ 强化动态决策与探索能力,推理 / 工具能力上限高;❌ 需设计奖励函数,单纯风格、格式优化没必要使用。
五、人类反馈强化学习(RLHF)
核心定位 :结合人类偏好 + 反馈做对齐,优化主观体验、价值观、合规性,持续迭代用户满意度
适用场景
- 基于用户反馈持续迭代优化 收集用户点赞、差评、人工修正、投诉等真实反馈,让模型持续贴合人类喜好。
- 价值观对齐、安全合规强化 拒绝违规内容、引导正向表达,统一伦理、底线要求。
- 主观体验优化 回答好不好、语气是否舒适、内容是否贴心等无绝对标准答案的主观评价场景。
- 高阶对话体验打磨 多轮闲聊、陪伴对话、高端客服,兼顾准确、友好、共情、分寸感。
- 修正 SFT/RL 带来的同质化、生硬问题 模型固化模板后,用人类偏好打破刻板输出,提升自然度。
典型案例
- 社交对话机器人持续优化语气与共情能力;
- 产品客服根据用户差评调整回答方式;
- 大模型通用安全对齐、价值观校准。
优缺点补充
✅ 贴合人类主观偏好,体验最优;❌ 工程复杂、成本高、周期长,小场景过度使用浪费资源。
二、场景快速选型对照表(汇总版)
表格
|----------|--------------------|---------------------------|----------------|
| 技术方案 | 核心能力 | 典型落地场景 | 成本 & 迭代速度 |
| 提示工程 | 指令引导、临时约束、上下文拼接 | 快速试错、原型验证、用户临时记忆、单次格式要求 | 极低、秒级迭代 |
| RAG | 外接知识、防幻觉、实时 / 私有内容 | 企业知识库、案例库、实时资讯、私有事实问答 | 低、知识可动态更新 |
| SFT | 固化格式、统一风格、标准化任务 | 固定输出模板、专属语言风格、高频标准问答 | 中、能力永久固化 |
| RL | 推理强化、工具调用、动态决策 | 深度逻辑推理、多工具调用、交互式流程任务 | 中高、侧重行为决策优化 |
| RLHF | 人类偏好对齐、体验优化、合规 | 用户反馈迭代、主观体验打磨、安全 & 价值观对齐 | 高、全链路流程复杂 |
三、组合落地常见搭配(面试 / 实战常用)
- 原型 / 小流量快速上线:提示工程 + RAG 不用训练模型,靠提示词控风格、RAG 补知识,最快落地知识库问答、客服。
- 标准业务常态化使用:RAG + SFT RAG 提供私有知识,SFT 统一回答风格与格式,企业知识库、内部助手主流组合。
- 智能体 / 工具类应用:RAG + SFT + RL 知识检索 + 话术固化 + 工具调用 / 推理强化。
- C 端面向用户、重体验产品:全链路组合 提示工程 (临时规则) + RAG (知识) + SFT (基础风格) + RL (推理 / 工具) + RLHF (用户体验 & 反馈优化)。
四、避坑选型原则
- 能用提示工程 / RAG解决的,不做微调(SFT/RL),节约成本;
- 只需要格式、风格统一,优先 SFT,不用 RL/RLHF;
- 涉及外部知识、动态数据,必须搭配 RAG,避免模型幻觉;
- 侧重推理、工具调用 ,选用 RL;侧重用户主观体验、反馈迭代,选用 RLHF;
- 简单场景不要盲目上 RLHF,算力、人力成本会大幅冗余。
Q57: DeepSeek 是如何把 R1 的推理能力蒸馏到较小的模型中的?如果我们要自己蒸馏一个较小的垂直领域模型,如何尽可能保留 R1 在特定领域的能力?
面试速记:
DeepSeek-R1 采用思维链 (CoT) 蒸馏 ,由大模型生成带完整推理过程的样本,经严格过滤后对小模型做SFT 有监督微调 ,复刻推理逻辑而非仅答案。 自研垂直领域模型时,重点构建领域专属 CoT 数据集 ,搭配分步蒸馏、软标签 / 隐层对齐、LoRA 轻量化训练,并建立领域专项评估体系,最大限度保留原有推理能力。
基础术语释义:
- CoT :Chain-of-Thought **思维链,**模型解决复杂问题时,分步推导、逐步思考的完整过程,是推理能力的核心载体。
详解:
(一)DeepSeek-R1 官方蒸馏实现方式
1. 核心思路
摒弃复杂强化学习,以思维链蒸馏 为核心,让小模型完整模仿大模型思考过程 + 最终答案,依托纯 SFT 即可迁移强推理能力。
2. 完整流程
- 生成高质量推理样本 以 DeepSeek-R1(671B 教师模型)为基础,面向数学、代码、逻辑推理等场景批量生成数据,统一格式:问题 + 完整 CoT 推理过程 + 标准答案,总数据量约 80 万条。
- 多层级数据过滤(决定蒸馏上限)
- 格式过滤:剔除推理链残缺、乱码、无意义文本;
- 长度过滤:筛除推理步骤过少、内容过度冗余的样本;
- 正确性校验:通过代码执行、规则校验核查答案,直接丢弃错误样本;
- 去重处理:删除高度重复样本,保证数据多样性。
- 选定学生模型 选用 Llama、Qwen 等主流开源小模型(7B/14B/32B),控制师生模型参数量比例,保障迁移效果。
- 有监督微调训练 使用清洗后的
问题+CoT+答案样本做标准自回归 SFT,让学生模型逐字学习 R1 的推理逻辑与表达,全程不使用 RL。
3. 关键特点
- 核心是推理过程迁移,而非单纯答案复刻;
- 训练链路简单,仅靠 SFT 即可实现,工程成本低;
- 同尺寸下,蒸馏后小模型推理能力显著优于原生开源模型。
(二)垂直领域小模型蒸馏:保留 R1 领域推理能力的方案
1. 核心原则
数据垂直化 、训练分步化 、对齐深层化 、评估领域化,从数据、训练、对齐、验收全环节守住推理能力。
2. 分步落地实操
第一步:构建领域专属 CoT 数据集(核心,占效果 70%)
- 收集目标垂直领域核心问题、高频难题、业务复杂场景;
- 调用 R1 生成样本,强制要求输出领域专属思维链:包含行业术语、业务规则、专业推导步骤,拒绝通用套话;
- 双重质检:程序校验答案 + 领域专家审核推理逻辑,剔除不专业、错误样本;
- 最终产出足量
领域问题+领域CoT+领域答案样本。
第二步:学生底座与训练选型
- 底座优先选择原生适配该领域的开源小模型,降低二次学习成本;
- 基础训练:基于领域 CoT 样本做LoRA+SFT,轻量化训练、防止过拟合;
- 进阶增强(可选,进一步保留能力):
-
- 软标签蒸馏:引入 R1 输出 Logits,设置较高温度系数,拟合概率分布;
- 隐层 / 注意力对齐:对齐师生模型中间特征,复刻深层推理结构。
第三步:三段式分步蒸馏(推荐,能力保留效果最优)
- 通用推理打底:用 R1 通用 CoT 数据微调,保留基础推理能力;
- 领域推理精调:切换为领域专属 CoT 数据,将推理能力聚焦到业务场景;
- 领域事实补强:搭配领域知识库问答样本微调,补充私有知识、降低幻觉。
第四步:搭建领域专项评估闭环
设置三类评估指标,验证推理能力未丢失:
- 领域业务指标:任务准确率、通过率、F1 值等业务标准;
- 推理能力指标:CoT 完整性、推导步骤正确率、复杂问题解题率;
- 对比基线:和 "纯领域 SFT(无 R1 蒸馏)" 模型做对照,确保推理优势留存。
核心对比 & 选型要点
表格
|----------|----------------------|-------------------------|
| 对比维度 | DeepSeek-R1 通用蒸馏 | 垂直领域定制蒸馏 |
| 数据主体 | 通用推理类 CoT 样本 | 领域专属问题 + 行业 CoT 样本 |
| 训练方式 | 纯标准 SFT | LoRA-SFT + 可选软标签 / 隐层对齐 |
| 优化重点 | 通用逻辑推理 | 推理逻辑 + 领域专业知识结合 |
| 评估标准 | 通用推理题库 | 领域业务题库 + 推理双重校验 |
避坑要点
- 切勿只蒸馏最终答案,丢失 CoT 推理过程会直接导致小模型推理能力大幅下滑;
- 领域数据必须经过专家审核,错误 / 不专业的思维链会反向污染模型;
- 优先使用 LoRA 微调,全参数微调易破坏模型原有推理基底、引发过拟合;
- 不省略分步蒸馏,直接用领域数据训练,容易让模型遗忘通用推理能力;
- 必须做对照评估,无法复现 R1 领域推理效果时,及时回溯数据与训练配置。
Q58: R1-Zero 的方法主要适用于有明确验证机制的任务(如数学、编程),如何将这一方法扩展到更主观的领域(如创意写作或战略分析)?
面试速记:
R1-Zero 依靠自博弈 + 规则化奖励 + 结果验证 ,仅适合数学、代码这类有客观标准答案、可自动校验的任务。拓展到创意写作、战略分析等主观领域,核心思路:改造奖励体系、引入分层评价、设计多维度约束、弱规则自进化、人工 + 模型联合校验,把主观体验拆解为可量化指标,同时保留 R1-Zero 无监督自迭代的核心逻辑。
基础术语释义
- 自博弈:模型自身生成样本、互相对抗 / 对比,不依赖外部标注数据完成迭代优化。
详解:
(一)R1-Zero 原生原理与局限性
1. 核心流程(原生版)
- 模型自主生成解题思路、代码等输出内容;
- 接入自动化验证器(计算器、代码解释器、判题规则),自动判断结果正误;
- 依据对错生成单维二元奖励(正确 = 高分,错误 = 低分);
- 基于强化学习做自迭代、自博弈,持续提升解题能力。
2. 主观领域适配难点
- 无唯一标准答案,无法用简单规则判定 "对错";
- 评价维度多(创意、逻辑、深度、文笔、格局),单一奖励信号失效;
- 容易出现 "为迎合规则丢失创意",陷入奖励黑客;
- 缺少标准化自动校验环境,纯机器判断主观质量误差大。
(二)核心扩展方案(创意写作、战略分析通用)
整体改造方向:把主观评价 "可维度化、可量化、可自动打分",保留 R1-Zero 自博弈、无人工标注、自主迭代的核心架构。
1. 第一步:拆解主观任务,构建多维度分层奖励函数(最核心)
放弃原生 "对错二分类奖励",将主观要求拆成多个独立、可自动检测的子维度,加权合成综合奖励。
1)创意写作 维度拆分示例
- 结构奖励:段落完整、起承转合通顺、体裁合规(诗歌 / 散文 / 故事格式校验);
- 文笔奖励:用词丰富度、句式多样性、语句流畅度、语病检测;
- 创意奖励:情节新颖度、视角独特性(通过语义相似度判断,规避套路化内容);
- 主题奖励:内容紧扣标题 / 写作要求,不跑题;
- 合规奖励:无违规内容、文风匹配设定(伤感 / 热血 / 治愈等)。
2)战略分析 维度拆分示例
- 逻辑奖励:论证链条完整、因果关系清晰、分层有条理;
- 内容奖励:论据充足、贴合行业背景、无常识错误;
- 深度奖励:观点独特、具备前瞻性,低重复度;
- 格式奖励:分析框架合规(SWOT/PEST 等模型使用规范);
- 严谨性奖励:结论与论据匹配,无主观臆断。
实操规则
- 每个维度单独设计打分规则 / 模型打分器,分值区间统一;
- 根据业务侧重点设置权重(如创意写作拉高新颖度权重 ,战略分析拉高逻辑权重);
- 最终总奖励 = 各维度加权求和。
2. 第二步:搭建混合式自动校验体系
原生 R1-Zero 只用程序规则校验,主观领域改用「规则硬校验 + 小模型软打分」组合模式。
- 硬规则校验(必做,低成本) 用正则、句法分析、关键词匹配做基础过滤:检测语病、格式错误、跑题、违规内容、重复套话,不合格直接扣大额奖励。
- 专用打分模型(核心,承接主观评价)
-
- 预训练 / 微调一个领域评价小模型,输入 "任务要求 + 模型输出",输出各维度分数;
- 训练评价模型的数据来源:人工少量标注 + 优质范文对比,替代人工逐批打分;
- 优势:全程自动化,适配 R1-Zero 无人工干预的迭代模式。
3. 第三步:优化自博弈机制,适配主观场景
原生自博弈是 "解题 PK 对错",主观领域改为样本对比博弈,而非对错比拼:
- 同任务下,模型批量生成多份输出;
- 由评价体系给出每份样本综合得分;
- 高分样本作为正样本 、低分样本作为负样本,构建博弈样本对;
- 模型向高分样本的风格、逻辑、创意方向迭代,淘汰低质量输出。
- 额外约束:加入相似度惩罚,对高度套路、重复的输出扣奖励,强制鼓励创新。
4. 第四步:增加风格 & 边界硬约束,防止输出失控
主观任务自由度高,纯奖励引导易跑偏,叠加多层约束守住底线:
- 格式 / 框架约束 战略分析强制使用标准分析模型,创意写作限定体裁、字数、叙事视角,从结构上框定范围。
- 语义边界约束 通过提示词、隐层正则,限定内容基调(商业分析严禁娱乐化、文案写作保持指定风格)。
- KL 散度约束 参考优质基座模型分布,防止迭代中风格彻底异化、逻辑崩坏。
5. 第五步:分级迭代策略,循序渐进优化
避免一步到位训练导致模型混乱,分阶段迭代:
- 基础阶段 :仅开启硬规则奖励,优先保证格式通顺、内容合规、不跑题;
- 进阶阶段:开启文笔 / 逻辑奖励,打磨内容质量与表达;
- 高阶阶段:拉高创意 / 深度权重,鼓励差异化、新颖观点,完成主观能力升级。
6. 第六步:少量人工闭环抽检(兜底,不破坏无监督特性)
R1-Zero 主打少人工,但主观领域无法完全脱离人工:
- 迭代多轮后,人工随机抽检样本,修正评价模型的打分偏差;
- 补充少量标杆范文,更新评价模型,形成 "自动迭代 + 定期人工校准" 的轻量闭环。
(三)分场景落地细节
场景 1:创意写作(小说、文案、诗歌)
- 重点奖励维度:新颖度、句式多样性、主题契合度;
- 博弈设计:多篇文稿横向对比,淘汰套路化、流水账内容;
- 特殊优化:加入 "情节多样性惩罚",避免固定剧情模板。
场景 2:商业 / 行业战略分析
- 重点奖励维度:逻辑链完整性、论证严谨度、框架规范性;
- 博弈设计:对比分析深度、观点合理性,优先保留有前瞻视角的内容;
- 特殊优化:接入行业知识库,校验专业术语、行业事实,降低常识错误。
核心方案汇总对比
表格
|----------|-------------------------|----------------------|
| 对比维度 | 原生 R1-Zero(数学 / 代码) | 扩展后(创意写作 / 战略分析) |
| 奖励形式 | 单维二元奖励(对 / 错) | 多维度加权分层奖励 |
| 校验方式 | 程序 / 解释器 纯规则校验 | 硬规则 + 领域评价模型 混合校验 |
| 自博弈目标 | 比拼答案正确性 | 比拼综合质量、创意、逻辑 |
| 核心约束 | 结果正确 | 格式、风格、语义、创新多重约束 |
| 人工依赖 | 几乎无人工 | 定期人工抽检校准,轻量介入 |
避坑要点
- 不要直接沿用二元奖励:主观任务只用 "好坏" 单一奖励,模型会快速出现奖励黑客,产出模板化内容;
- 评价模型质量决定上限:打分模型不准,会引导模型向错误方向迭代,需提前做好微调与验证;
- 创意与规范做平衡:新颖度权重过高会导致内容荒诞,权重过低则回归套路,需反复调优权重配比;
- 控制迭代轮数:主观模型过度自博弈,容易出现文风怪异、逻辑偏激的问题,配合早停策略;
- 区分领域特性:战略分析重逻辑严谨,创意写作重灵活度,不能套用同一套维度权重。
Q59: 如果要在一个非推理型模型的基础上通过强化学习(RL)训练出一个 1000 以内的整数四则运算错误率低于 1% 的模型,预计基座模型至少需要多大?RL 过程需要多少张 GPU和多少训练时长? (提示:TinyZero)
面试速记:
基于 TinyZero 实践,非推理型基座至少需 3B 参数 (如 Qwen2.5-3B),1.5B 及以下难稳定收敛到 < 1% 错误率。RL 训练用2 张 A100 80G (或 RTX 4090),200--400 步(约 6--12 小时)即可达标;0.5B 不可用,7B 可提速但成本更高。核心是纯 RL(PPO/GRPO)+ 规则验证奖励 + 多轮自博弈。
详解:
(一)基座模型最小规模(核心结论)
- ≤1.5B(0.5B/1.5B) :TinyZero 验证效果差、难收敛,四则运算错误率难低于 5%;0.5B 几乎无法习得多步计算。
- 3B(推荐下限,如 Qwen2.5-3B) :满足最低要求,纯 RL 可稳定将 1000 以内四则运算错误率压到 **<1%**;TinyZero 标准配置,单卡可跑、双卡提速。
- 7B(稳妥优选,如 Qwen2.5-7B):初始能力更强,收敛更快、稳定性更高;错误率可 **<0.5%**,但需双卡、显存要求更高。
- 结论 :非推理型基座≥3B;资源有限选 3B,追求稳定选 7B。
(二)RL 训练硬件(GPU 数量 / 型号)
参考 TinyZero veRL 框架标准配置:
- 3B 模型(推荐) :2×A100 80G / RTX 4090(24G)
-
- 1 卡:策略模型 + rollout 生成;1 卡:环境验证 + 奖励计算。
- 单卡(24G)可跑,但 batch 小、训练慢(约 18--24 小时)。
- 7B 模型 :2--4×A100 80G;2 卡勉强、4 卡稳定,避免显存溢出。
- 0.5B/1.5B(不推荐):1×24G 卡,但效果不达标。
(三)训练时长(步数 / 时间)
基于 TinyZero 公开数据(3B、2×4090):
- 训练步数 :200--400 步(PPO 迭代,每步含 rollout + 训练)。
- 耗时 :6--12 小时(2 卡);单卡约 18--24 小时。
- 收敛曲线:
-
- 0--100 步:错误率从 90%→10%;
- 100--200 步:10%→1%;
- 200--400 步:稳定 < 1%,波动 < 0.5%。
- 7B 模型:150--300 步,4--8 小时,收敛更快。
(四)训练核心流程(TinyZero 范式)
- 数据生成:批量生成 1000 以内整数四则题(+、-、×、÷,含括号),约 10k--50k 样本。
- 奖励函数(关键):
-
- 结果正确:+2.0(主奖励);
- 格式正确(含算式 / 答案):+0.5;
- 错误 / 格式乱:0 分。
- 纯 RL 训练(无 SFT 预热):
-
- 算法:PPO/GRPO(GRPO 更省显存);
- 每步:模型生成→规则验证→算奖励→更新策略;
- 自博弈:同题生成多份答案,择优强化、淘汰劣解。
- 早停:连续 10 步错误率 < 1% 即停止,避免过拟合。
核心配置汇总表
表格
|----------|---------------|---------------|-----------|----------|
| 模型规模 | 最小 GPU 配置 | 训练时长(2 卡) | 可达错误率 | 推荐指数 |
| 0.5B | 1×24G | 不可收敛 | >20% | ❌ |
| 1.5B | 1×24G | 18--24h | 3%--5% | ❌ |
| 3B(下限) | 2×24G | 6--12h | <1% | ✅ |
| 7B(优选) | 2×80G | 4--8h | <0.5% | ✅✅ |
避坑要点
- 别用 < 3B 基座:非推理型小模型(0.5B/1.5B)数学能力弱,RL 难突破阈值,错误率难 < 5%。
- 纯 RL 无需 SFT 预热 :TinyZero 证明,3B + 模型可从零通过 RL 习得,SFT 反而增加成本。
- 奖励函数别复杂 :仅需结果 + 格式双奖励,过多维度易导致奖励黑客、收敛不稳。
- 必用规则验证 :人工标注不可行、速度慢;代码 / 计算器自动校验高效、零成本、无误差。
Q60: 在 QwQ-32B 推理模型的基础上,通过 RL 在类似 OpenAI Deep Research 的场景中强化垂直领 域能力,如何构建训练数据集?预计需要多少张 GPU和多少训练时长?
面试速记:
数据 :用垂直领域专家任务库 + 工具交互轨迹 + 多源引文报告 三类数据,总量50k--100k ,核心是可验证步骤 + 引用溯源 + 专家评分 。硬件 :RL 训练(GRPO/PPO)需8×H100 80G (或 16×A100 80G),全参数 + FSDP/ZeRO‑3;LoRA 可2--4×A100 。时长 :全参数7--14 天 (200--400 步);LoRA2--4 天 ;收敛目标:任务通过率 > 90%、引用准确率 > 95%、专家偏好胜率 > 80% 。 核心逻辑:延续 QwQ 双阶段 RL+Deep Research 工具链与引用约束,把通用推理聚焦到垂直领域。
基础术语释义
- Deep Research 场景 :多步骤开放域研究 ,含任务拆解→多源搜索→工具调用(浏览 / Python)→信息综合→带引用报告 ,无唯一标准答案,重过程可追溯与结论可靠OpenAI。
- QwQ‑32B :阿里开源推理专精模型 (32.5B),双阶段 RL:先数学 / 代码结果奖励 ,再通用对齐 + 工具调用,强于思维链与多步推理。
- GRPO :广义强化策略优化 ,大模型 RL 主流,低显存、高稳定,适合 32B+,veRL/AReaL 常用。
- 工具交互轨迹 :模型调用搜索 / 浏览 / Python 的动作序列 + 返回结果,是 Agent 式 RL 的核心数据36氪。
- 引用溯源奖励 :奖励报告中结论与来源链接 / 文献精准绑定 ,抑制编造OpenAI。
详解
(一)训练数据集构建(Deep Research 风格,垂直领域)
核心:把 "开放研究" 拆成可监督、可奖励的结构化样本,数据质量决定上限。
1. 数据构成(三类,总量 50k--100k)
1)垂直专家任务库(40%,20k--40k)
- 来源:行业专家设计多步骤研究任务(如 "分析 2025 储能市场格局并给出 3 年预测")。
- 结构:
{query, plan, steps, sources, report, expert_score}
-
- query:自然语言研究请求;
- plan:专家拆解的 3--5 步调研路径;
- steps:每步搜索关键词→浏览页面→提取信息;
- sources:权威链接 / 文献(≥3 条);
- report:带引用的结构化报告;
- expert_score:1--5 分(逻辑、深度、引用、文笔)。
- 质量要求:无重复、来源可验证、专家评分≥4 分。
2)工具交互轨迹(30%,15k--30k)
- 来源:QwQ‑32B 在目标领域自主调用搜索 / 网页解析 / Python 的完整日志36氪。
- 结构:
{state, action, tool_return, next_state, reward}
-
- state:当前任务 + 已获取信息;
- action:搜索 / 打开 URL / 运行代码;
- tool_return:摘要 / HTML / 执行结果;
- next_state:更新后的信息集;
- reward:步骤有效性 + 信息增益(规则打分)。
- 作用:教会模型何时用工具、用什么工具、怎么解析结果。
3)多源引文报告(30%,15k--30k)
- 来源:公开行业报告、论文综述、券商研报(去版权 / 脱敏)。
- 结构:
{query, summary, citations, coherence_score}
-
- query:研究主题;
- summary:核心结论;
- citations:结论对应的权威来源链接 / DOI;
- coherence_score:逻辑连贯性(模型打分)。
- 作用:强化结论‑引用绑定 ,降低编造率OpenAI。
2. 数据清洗与格式
- 过滤:去低质(专家分 < 3、来源无效、重复)、去幻觉(无来源结论)。
- 格式:统一为JSONL ,上下文长度4k--8k(QwQ 支持 131k,取中段平衡效率)。
- 验证集:10% 数据,用于每 50 步评估,监控过拟合。
3. 奖励函数设计(关键,Deep Research 风格)
采用多维度加权奖励(延续 QwQ 结果导向 + 引用约束):
- 任务完成(+40%):按专家标准完成所有步骤(规则校验);
- 结论准确(+30%):与权威结论一致(检索比对);
- 引用合规(+15%):每条结论绑定有效来源,无编造;
- 逻辑连贯(+10%):思维链完整、无跳跃(模型打分);
- 格式规范(+5%):报告结构化、排版清晰。
(二)GPU 硬件配置(32B RL,全参数 vs LoRA)
QwQ‑32B 全参数 RL 显存压力大,必须分布式 + 显存优化。
1. 全参数 RL(推荐,效果最优)
- 最低:8×H100 80GB(FSDP+ZeRO‑3,FP16);
- 替代:16×A100 80GB(成本更低,速度略慢);
- 显存拆分:
-
- Actor(策略):4 卡,存模型 + 梯度;
- Rollout(生成):2 卡,vLLM 加速采样;
- Critic / 奖励:2 卡,工具调用 + 验证打分。
2. LoRA RL(低成本,快速迭代)
- 配置:2--4×A100 80GB(仅训练 LoRA,秩 64--128);
- 适用:初期验证、快速试错、资源受限场景;
- 缺点:上限低于全参数,复杂推理易掉点。
(三)训练时长(收敛目标:通过率 > 90%,引用准确率 > 95%)
基于 veRL/AReaL 框架、GRPO 算法、8×H100 配置:
- 全参数 RL:
-
- 预热(SFT,可选):1--2 天,用 10k 数据微调基座;
- 主 RL(GRPO):7--14 天,200--400 步;
-
-
- 0--100 步:学习工具调用,通过率 30%→70%;
- 100--250 步:强化引用与逻辑,70%→90%;
- 250--400 步:稳定收敛,>90%,波动 < 2%。
-
- LoRA RL :2--4 天,100--200 步,收敛更快、上限略低。
- 早停:连续 10 步 ** 验证集通过率 > 90%、引用准确率 > 95%** 即停止。
(四)核心训练流程(QwQ+Deep Research 融合)
- 基座准备 :加载 QwQ‑32B,启用思维链输出 (强制
...); - 数据加载:50k--100k 结构化数据,分批喂入;
- Rollout 生成 :模型自主生成研究计划→工具调用→报告;
- 多维度奖励:按任务完成、结论、引用、逻辑、格式打分;
- GRPO 更新:分布式训练,**KL 约束(0.01)** 防止偏离基座过远;
- 迭代 + 评估:每 50 步在验证集测试,监控通过率、引用准确率;
- 微调 + 上线 :收敛后,用 10k 优质数据做最终 SFT,固化能力。
核心配置汇总表
表格
|--------|--------------------------|----------------------|
| 项目 | 全参数 RL(推荐) | LoRA RL(低成本) |
| 数据规模 | 50k--100k(三类混合) | 30k--50k(精简版) |
| GPU 配置 | 8×H100 80G / 16×A100 80G | 2--4×A100 80G |
| 训练时长 | 7--14 天(200--400 步) | 2--4 天(100--200 步) |
| 收敛目标 | 通过率 > 90%,引用 > 95% | 通过率 > 85%,引用 > 90% |
| 推荐指数 | ✅✅✅(效果最优) | ✅✅(快速迭代) |
避坑要点
- 数据必须 "可验证" :Deep Research 核心是可追溯 ,无来源数据会导致模型编造,奖励失效OpenAI;
- 别用二元奖励 :主观研究任务必须多维度加权,单一对错会引发奖励黑客(模板化报告);
- 保留 QwQ 思维链 :关闭 `` 会丧失多步推理能力,效果断崖式下跌;
- 显存优化是关键 :32B 全参数必须FSDP+ZeRO‑3,否则 8×H100 也会溢出;
- 垂直领域 "小而精" :不用盲目堆数据,50k 高质量垂直数据 > 500k 通用数据。
注:本文的问题引自:《图解大模型:生成式 AI 原理与实战》(沙特 杰伊・阿拉马尔、荷 马尔滕・格鲁滕多斯特 著,李博杰 译,人民邮电出版社,2025)