一条完整的 RAG 链路,不是把文本塞进 Vector Database 就结束。真正决定结果的,是 Data Loading、Chunking、Metadata、Embedding、Retrieval、Rerank、Generation 与 Evaluation 如何协同。
先把 RAG 看成一条质量链
用户提问后,系统不会让 LLM 凭记忆直接回答,而是先从外部知识库检索证据,再把证据连同问题交给 LLM。这个过程称为 Retrieval-Augmented Generation。

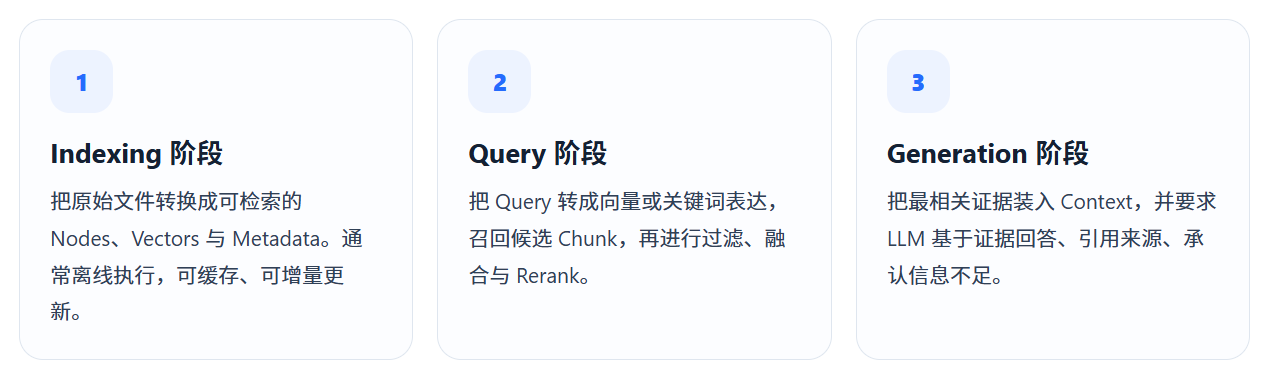
第一步不是 Embedding,而是把数据读对
LlamaIndex 将数据入口抽象为 Document 。PDF、Word、Markdown、网页、数据库记录或 API 返回值,都应先被转换成统一的 Document,再通过 Transformations 生成更细粒度的 Node。
Document 与 Node 的区别
| 对象 | 含义 | 典型用途 |
|---|---|---|
| Document | 较完整的原始数据单元,保留正文、文件名、来源、时间等属性。 | 数据加载、版本管理、增量更新。 |
| Node | 从 Document 切出的可检索单元,继承父文档的 Metadata,并可记录前后关系。 | Embedding、向量索引、检索与引用。 |
工程上应保留稳定的 document_id、source、updated_at 与权限字段。否则文档更新后,很难准确删除旧向量,也难以实现租户隔离与权限过滤
Chunking 决定"检索到的证据长什么样"
Embedding Model 接收的是 Chunk,而不是整座知识库。Chunk 太小,语义被切碎;Chunk 太大,主题混杂、召回不准,还会挤占 LLM Context Window。


参数怎么定
| 参数 | 影响 | 建议 |
|---|---|---|
| chunk_size | 越大,单块上下文越完整,但主题更容易混杂。 | 先以 400--800 tokens 做基线,再根据文档结构与评测调整。 |
| chunk_overlap | 减少边界信息丢失,但增加索引体积和重复召回。 | 通常设为 chunk_size 的 10%--20%,不是越大越好。 |
| separator | 决定优先在哪些位置断开。 | 中文应关注句号、问号、换行、Markdown 标题等边界。 |
| parent-child | 小块负责精确召回,大块负责提供完整上下文。 | 长文档、法律条款、论文适合采用 Small-to-Big 思路。 |
Metadata 让检索从"相似"升级为"可控"
Vector Similarity 只能回答"语义像不像"。真实系统还要判断文档属于哪个部门、何时生效、谁有权限访问、是否为最新版。Metadata 正是这些约束的载体。
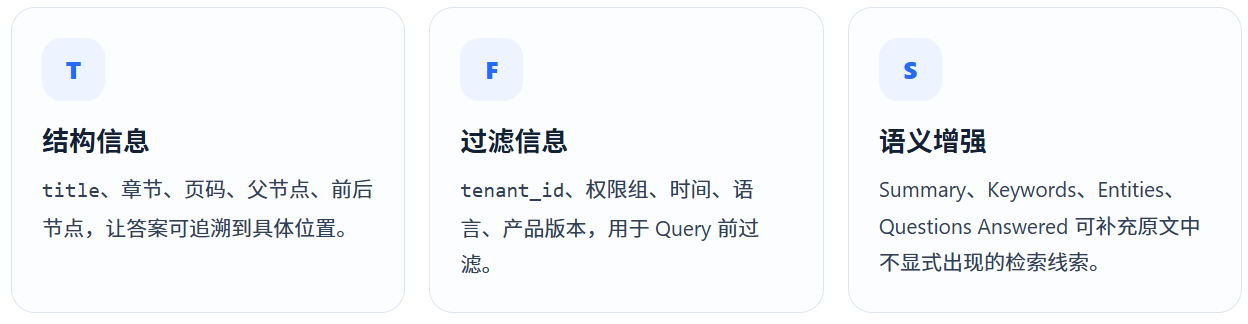
LlamaIndex 的 Metadata Extractor 可以按顺序为 Node 增加 Title、可回答问题、Summary、Keywords 与 Entities。需要注意:LLM 自动生成的 Metadata 会增加成本,也可能生成错误标签,因此应先在高价值文档上使用,并保留原始来源字段。
**权限过滤必须发生在检索阶段。**不能先召回无权访问的内容,再指望 Prompt 让 LLM 忽略它。
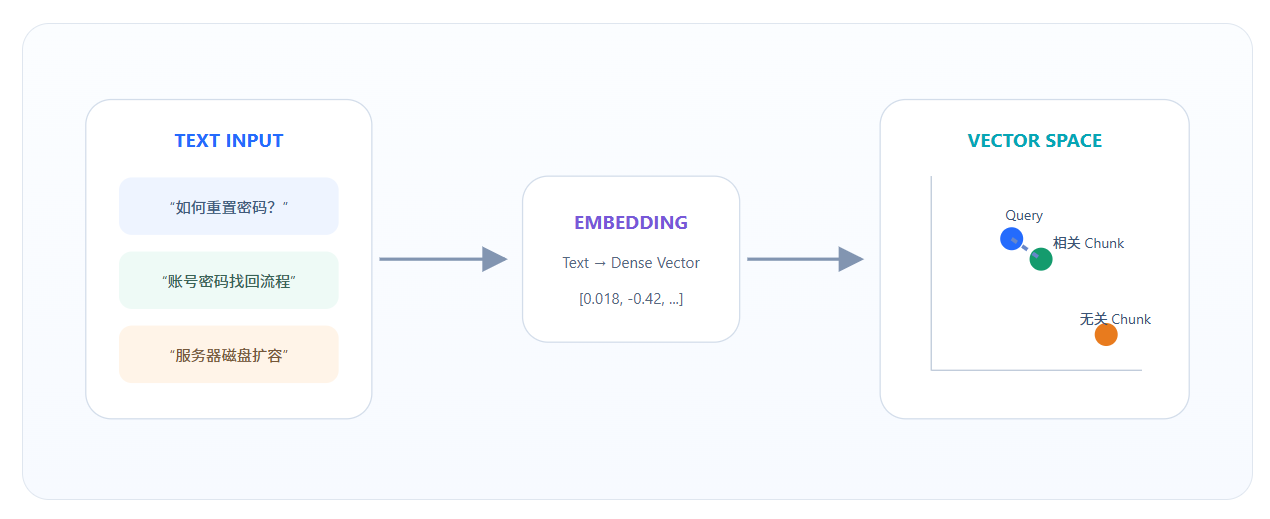
Embedding 把文本映射到语义空间
Embedding 是一个浮点向量。语义相近的文本在向量空间中距离更近,因此可以用 Query Vector 找到最相似的 Chunk Vector。常见用途包括 Semantic Search、Clustering、Recommendation 与 Classification。
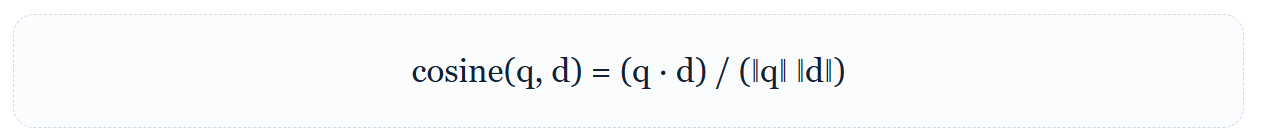
其中 q 是 Query Embedding,d 是 Document Chunk Embedding。Cosine Similarity 越大,通常表示方向越接近、语义越相似。
模型选择关注四件事
- 是否支持中文和目标领域语言
- 最大输入长度是否覆盖 Chunk
- 向量维度、存储成本与检索延迟
- Query 与 Document 是否需要不同指令前缀
**同一索引必须使用兼容的 Embedding 配置。**文档与 Query 应使用同一模型或明确兼容的双塔模型;更换模型后通常需要重新生成全部向量。
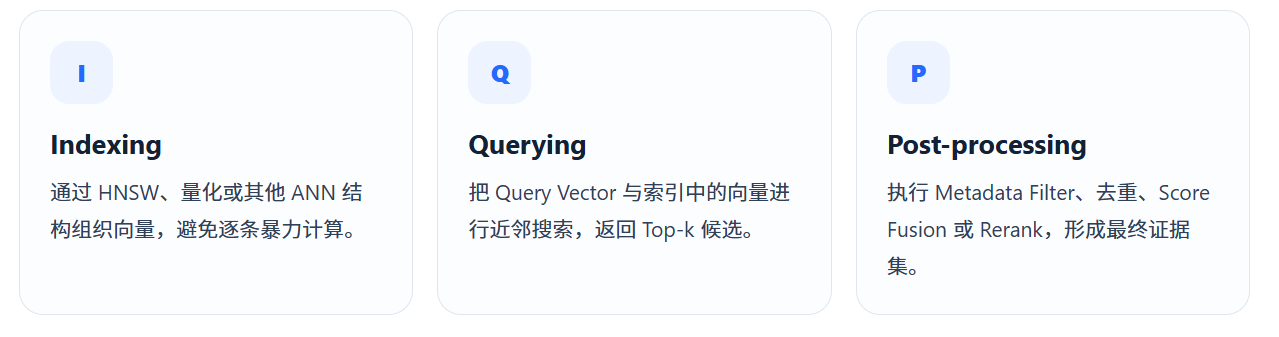
Vector Database 不是"存数组的数据库"
它除了保存 Vector,还要负责 Approximate Nearest Neighbor(ANN)索引、Similarity Search、Metadata Filter、更新删除、扩缩容与低延迟查询。
| 能力 | 关系型数据库 | Vector Database |
|---|---|---|
| 主要查询 | 精确匹配、范围查询、JOIN | 相似度搜索、ANN、Metadata Filter |
| 核心对象 | Scalar 值与表关系 | 高维 Dense/Sparse Vector |
| 结果含义 | 满足明确条件的记录 | 与 Query 最接近的近似邻居 |
| 主要权衡 | 一致性、事务、查询计划 | Recall、Latency、Cost、Freshness |
生产环境要额外关注 Namespace、租户隔离、删除一致性、索引更新时间、备份恢复与观测指标。所谓"查到了旧文档",往往不是 LLM 问题,而是索引刷新或删除链路不完整。
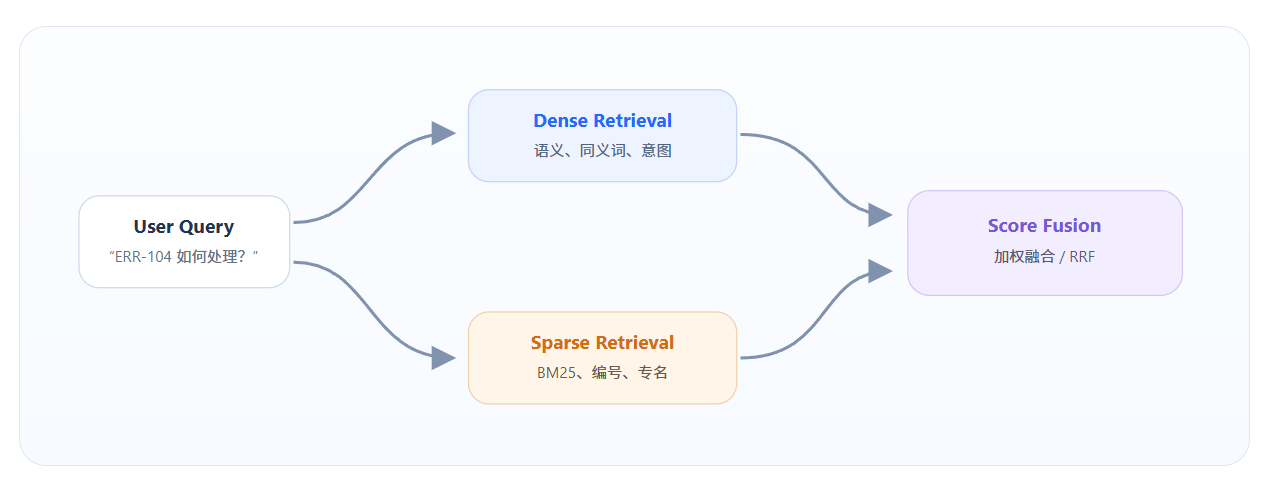
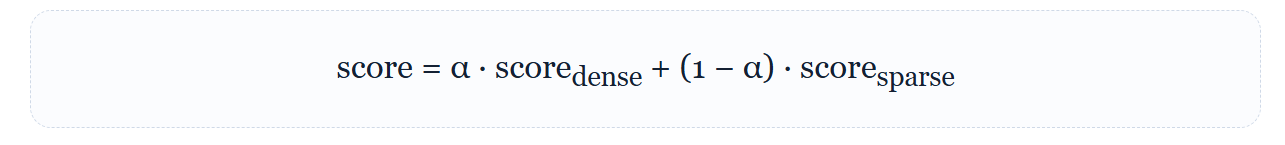
α 控制语义与关键词的权重。实际系统还常用 Reciprocal Rank Fusion(RRF),按排名而不是原始分数融合,避免两种检索器分数尺度不一致。
Retrieval 调优顺序
- 先建立 50--200 条真实 Query 的小型验证集。
- 检查正确证据是否出现在 Top-k,而不是先看最终回答是否"像对的"。
- 分别尝试 Chunk、Embedding、Metadata Filter、Dense/Sparse 权重和 Top-k。
- 候选召回足够后,再引入 Rerank 压缩噪声。
Retrieval 负责不漏,Rerank 负责排准
第一阶段检索通常追求较高 Recall,会返回较多候选。Rerank Model 同时读取 Query 与每个候选 Document,重新计算更精细的相关性,再选择更小的 Top-n 交给 LLM。

Cohere Rerank 的输入可以概括为:一个 query 加一组 documents,输出从最相关到最不相关的排序。与只比较独立向量相比,Cross-Encoder 能看到 Query 与 Document 的交互,因此排序通常更准确,但计算成本更高。
| 阶段 | 目标 | 特点 |
|---|---|---|
| Retriever | 从百万级数据中快速找候选 | 快,适合大规模;相关性判断相对粗糙。 |
| Reranker | 对几十条候选进行精排 | 慢一些,但能更细致理解 Query--Document 关系。 |
| LLM | 基于少量高质量证据生成答案 | 不应承担从大量无关文本中"自行检索"的任务。 |
把证据交给 LLM,也要规定它如何使用证据
RAG 的生成阶段不是简单拼接。需要明确区分 System Instruction、User Query 与 Retrieved Context,并控制 Context 顺序、长度、引用标识与冲突处理。

你是企业知识库助手。
规则:
1. 只依据 <context> 中的资料回答。
2. 每个关键结论标注来源编号,例如 [S1]。
3. 资料不足时直接说明"当前资料无法确认"。
4. 不得把用户问题中的假设当作事实。
5. 若来源冲突,分别列出,不自行裁决。
<context>
[S1] 标题:账号管理手册;版本:2026-05;正文:...
[S2] 标题:故障处理记录;日期:2026-06-02;正文:...
</context>
用户问题:{query}RAG 能降低 Hallucination 风险,但不能保证绝对正确。错误可能来自解析失败、Chunk 丢失、索引过期、召回遗漏、Rerank 误排或模型未遵循证据,因此必须做分层 Evaluation。
不要只问"答案看起来对不对"
Ragas 将 RAG 质量拆成多个维度。这样才能定位问题出在 Retrieval 还是 Generation,而不是只得到一个模糊的总分。

| 指标 | 它在问什么 | 分数低时优先检查 |
|---|---|---|
| Context Precision | 排在前面的 Context 是否真正相关,噪声是否过多? | Retriever、Rerank、Top-k、Chunk 主题混杂。 |
| Context Recall | 回答所需证据是否被检索完整? | Chunk 边界、Embedding、Hybrid Search、过滤条件。 |
| Faithfulness | 回答中的事实是否能由 Retrieved Context 支持? | Prompt、Context 冲突、LLM Hallucination。 |
| Response Relevancy | 回答是否直接解决用户问题? | Prompt、问题改写、无关 Context、回答模板。 |

正确的评测闭环
- 从真实业务日志收集 Query,而不是只由开发者编题。
- 为关键 Query 标注 Reference Answer、Reference Context 或相关文档 ID。
- 每次修改 Chunk、Embedding、Retriever、Reranker 或 Prompt 后跑同一套数据。
- 同时记录质量、Latency、Token Cost 与失败案例。
当问题需要"跨文档连点成线"
Baseline RAG 通常从相似文本片段出发。它适合局部事实问答,却可能难以回答"整个数据集中有哪些主要主题""某个实体与哪些事件间接相关"这类跨文档、全局性问题。
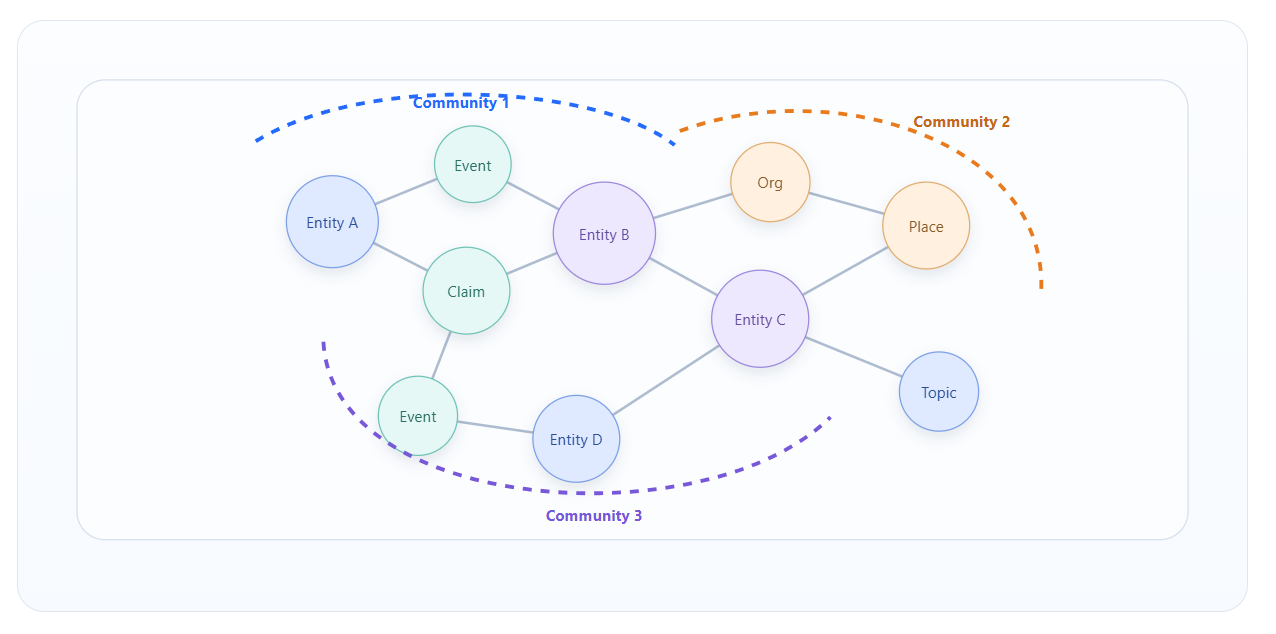
Microsoft GraphRAG 的基本过程
- 把语料切成 TextUnits。
- 从 TextUnits 中抽取 Entities、Relationships 与 Claims。
- 对图进行层次化 Community Detection,并为各层 Community 生成 Summary。
- 查询时,根据问题选择 Global Search、Local Search、DRIFT Search 或 Baseline Search。
| 模式 | 适合的问题 | 主要上下文 |
|---|---|---|
| Global Search | "整个语料的主要风险与主题是什么?" | Community Summaries,用于整体性理解。 |
| Local Search | "实体 A 与哪些人物、事件有关?" | 目标实体、邻居、关系、关联 TextUnits。 |
| DRIFT Search | 既需要实体细节,又需要全局 Community 信息。 | Local 扩展与 Community Context 的结合。 |
| Baseline Search | 局部事实、定义、明确段落问答。 | 标准 Top-k Vector Retrieval。 |