引言
最近一年,我接触到的很多 AI 应用都在做同一件事:把大模型接进一个输入框,再把回答展示在聊天窗口里。 这种方式验证模型能力很快,但当我把它放进教育场景后,问题也很快暴露出来。学生面对的仍然是一大段文字;知识点越完整,阅读压力越大;试题解析即使正确,也缺少教师讲解时的停顿、强调和反馈。系统能够"生成内容",却还不像一个真正参与教学过程的角色。
这也是我开发当前 AI 教育助手项目时最想解决的问题。
项目基于 Vue 3,能够按照学科、主题和难度生成知识点,也能生成选择题、填空题和解答题。为了让生成结果不只停留在页面上,我进一步接入了魔珐星云数字人 SDK,让大模型生成讲解内容,再由数字人实时表达。
魔珐星云官网地址:官网地址
这篇文章不打算泛泛介绍数字人行业,而是从这个项目的真实改造过程出发,讨论五个问题:
-
现有知识生成方案为什么仍然像一个内容工具;
-
LLM、TTS 和渲染各自存在什么局限;
-
星云如何打通从模型到数字人的实时链路;
-
一次"二次函数讲解"如何从静态页面升级为 AI 智能体应用;
-
星云 SDK、API 与项目架构应如何真正落地。

一、现有方案的问题:内容生成出来了,教学交互却没有发生
当前项目已经具备一条比较完整的 AI 内容生产链路。
在知识点生成页,用户选择语文、数学、英语、物理、化学或生物,输入主题并选择难度。前端通过兼容 OpenAI SDK 的模型接口发送提示词,请模型输出 Markdown 内容。
在试题生成页,用户还可以指定选择题、填空题或解答题。系统要求模型只返回 JSON,再将题干、选项、答案、解析和分值归一化为内部数据结构。
bash
用户输入
→ 学科 / 主题 / 难度 / 题型
→ 大模型生成
→ Pinia 保存上下文
→ Markdown、KaTeX 或结构化试题页面展示从功能角度看,这条链路已经可以使用;从教学体验看,它仍然存在四个明显问题。
1. 页面展示代替不了教师讲解
知识点详情页可以正确渲染 Markdown 和数学公式,试题详情页也能展示答案与解析,但"内容展示正确"不等于"学生已经理解"。
例如,大模型生成一篇关于二次函数的知识点,页面里可能包含定义、图像、顶点公式和例题。学生仍然需要自己判断:
- 哪个概念最重要;
- 公式中的参数分别影响什么;
- 当前例题应该先看条件还是先画图;
- 哪一步最容易出错。
真实教师会通过语气、停顿和重复组织这些信息。纯文本只能把内容交给用户,却无法主动引导用户的注意力。
2. 普通"文字转语音"仍然像播放器
一个常见改造思路是把整篇回答交给 TTS,然后在页面中播放音频。它确实减少了阅读负担,但交互仍然是单向的: 生成完整文本 → 合成完整音频 → 点击播放
用户需要等待内容与音频全部准备完成。播放过程中,系统也很难表达"正在思考""开始回答""本轮结束"等会话状态。它更像给文章增加了朗读按钮,而不是构建一个能够持续响应的 AI 教师。
3.传统数字人的核心问题,是高延迟、高成本与低并发
传统数字人并非只能播放预制视频,很多方案同样支持问答和实时交互。但真正进入业务场景后,影响体验的往往不是"能不能交互",而是交互速度、运行成本和并发能力。
在当前项目中,知识点、题型和讲解难度都由用户临时指定,每次生成的内容都不同。用户发起请求后,系统需要依次完成模型内容生成、TTS 语音合成、口型与动作驱动以及画面输出。如果等待模型生成完整讲稿后再启动后续流程,各环节的耗时就会不断叠加,学生很容易在等待中失去耐心。
因此,数字人交互真正需要优化的是整条端到端链路:
用户发起讲解 → 模型生成首段内容 → 语音与动作同步驱动 → 数字人开始表达
只有首段内容能够快速输出,后续内容再以流式方式持续生成、合成和播放,数字人才会让用户产生"正在与我交流"的感觉。同时,它还需要根据会话状态支持暂停、打断和结束,而不是必须等待整段内容播放完成。
除此之外,实时语音、动作和画面驱动还会带来较高的计算成本。当多个用户同时发起讲解时,如何降低单次交互成本、提升系统并发能力,同样是数字人真正进入业务必须解决的问题。
二、单点技术的局限:LLM、TTS、渲染都不能独立完成具身交互
在接入星云之前,我先拆解了项目中的三个核心技术环节。
1. LLM 擅长组织知识,但没有表达身体
项目使用 OpenAI JavaScript SDK 调用兼容接口的模型服务。知识点生成时,我通过系统提示词约束模型扮演中学、高中教研专家;试题生成时,则要求模型按照严格 JSON 输出。 LLM 解决的是"说什么":
- 生成知识结构;
- 控制题目难度;
- 给出答案和解析;
- 把书面内容改写为教师口吻。 但模型返回的仍然是 Token 流。它不知道页面里数字人的初始化状态,也不知道一段文本何时完成口型驱动,更不能单独提供视觉上的拟人反馈。
2. TTS 能生成声音,但声音不等于交互
如果只接 TTS,需要自己处理文本断句、音频流缓冲、播放队列、中断恢复以及音画同步。长文本还要考虑首包等待和后续音频是否连续。
在教育场景里,TTS 的问题不只是"能不能读出来",还包括:
- 公式应该如何口语化;
- Markdown 标记不能直接朗读;
- 题目选项之间需要停顿;
- 答案与解析需要不同语气;
- 用户暂停后,模型流和音频队列是否同时停止。 这些都属于对话编排,而不是一个 TTS 接口能够单独解决的问题。
3. 传统云端视频渲染链路偏重
如果每次回答都走完整的视频生成或云端画面渲染,成本、等待时间和并发压力都会比较高。对当前项目这种由用户即时触发的讲解任务来说,几秒甚至更长的准备时间会明显破坏交互感。
魔珐星云既非传统视频流方案载体,也不是操作系统,而是具身智能数字人开放平台。它通过自研端侧渲染与参数流架构,把形象渲染放到用户终端完成,服务端传输驱动数字人的轻量参数,从而降低传输和云端渲染负担。
在实时交互方案中,端到端约 500ms 的毫秒级响应是一个关键能力目标。对教育项目而言,这意味着模型首段内容到达后,数字人能够尽快接住并开始表达,而不是等待整篇讲稿生成结束。
这套方案关注的不是单独生成一段音频或视频,而是低延时、高并发、低成本、全兼容的连续具身交互。
三、解决方案:用星云打通模型、会话和数字人
与其只停留在"看数字人展示"的阶段,不如亲自完成一次接入,让自己的 AI 从只会生成答案,真正升级为能够表达、互动和服务用户的具身智能体。
对具身数字人开发感兴趣的开发者,可以前往 魔珐星云官网 体验相关能力,也可以进一步查看具身驱动 SDK、视频生成 API 和语音合成 API,尝试将数字人接入自己的 Agent、应用或业务终端。
接入星云后,我把系统划分成四层。
bash
业务交互层
学科、主题、难度、题型、开始/暂停
↓
Agent 编排层
上下文、提示词、状态机、分句、队列
↓
模型与知识层
LLM、教材知识、题库、Markdown/JSON
↓
星云具身表达层
SDK 会话、TTS、参数流、端侧渲染 1. 先把数字人封装成业务组件
项目在 DigitalHuman.vue 中创建 XmovAvatar 实例。数字人的挂载容器、应用信息和网关地址都集中在组件内部,页面只需要调用初始化、说话和断开三个方法。
bash
const avatar = new window.XmovAvatar({
containerId: '#containerId',
appId,
appSecret,
enableDebugger: false,
gatewayServer
})
await avatar.init({
onDownloadProgress: progress => {
console.log(`初始化进度: ${progress}%`)
},
onMessage: message => {
console.log('收到消息:', message)
}
})
组件再通过 defineExpose 向讲解页提供统一接口:
bash
defineExpose({
initDigitalHuman,
disconnect,
speak
})2. 把书面知识改写为可说的内容
当前项目中的知识点可能包含 Markdown 标题、列表、代码块和 LaTeX 公式。这些内容适合页面阅读,却不能直接用于语音输出。 因此,点击"开始讲解"后,系统会再次调用大模型,并要求它以专业教师口吻改写内容,同时移除 Markdown 语法。
bash
const messages = [
{
role: 'system',
content: '你是一名熟悉中学和高中课程标准的资深教研专家。'
},
{
role: 'user',
content: `请以专业教师的口吻讲解以下内容,不要包含 Markdown 语法:${content}`
}
]这一步很重要。页面稿和口播稿是两种不同内容产品。具身 Agent 不应该机械朗读页面,而应该对知识重新组织。
3. 让模型流直接进入数字人链路
项目已经使用 stream: true 获取模型增量输出,并将增量文本交给 speak():
bash
const completion = await openai.chat.completions.create({
messages,
model,
stream: true
})
let index = 0
for await (const part of completion) {
const delta = part.choices[0].delta.content
if (!delta) continue
await xmovHuman.value.speak(
delta,
index === 0,
false
)
index++
}这让系统不必等待完整讲稿生成完成。模型产生内容后,数字人链路即可开始消费。
不过,当前实现仍然是原型:它直接按照模型增量调用 speak()。Token 可能只是单字或半句话,容易造成调用过碎。下一步应该增加语义缓冲层。
bash
let buffer = ''
for await (const part of completion) {
buffer += part.choices[0].delta.content || ''
const sentences = splitCompletedSentences(buffer)
buffer = sentences.rest
for (const sentence of sentences.completed) {
speechQueue.enqueue(sentence)
}
}分句层可以在句号、问号、感叹号处切分,也可以设置最大字符阈值。数字人获得的是完整短句,声音和动作会比 Token 级输入更自然。
4. 用状态机管理"听、想、说、停"
当前页面只使用 isSpeaking 控制按钮,正式版本应该升级为完整状态机:
bash
idle
→ initializing
→ thinking
→ speaking
→ paused
→ completed
→ error每次状态切换都要同时控制:
-
模型请求是否继续;
-
文本缓冲是否接收;
-
数字人播放队列是否消费;
-
开始和暂停按钮是否可用;
-
页面是否显示正在思考或正在讲解。
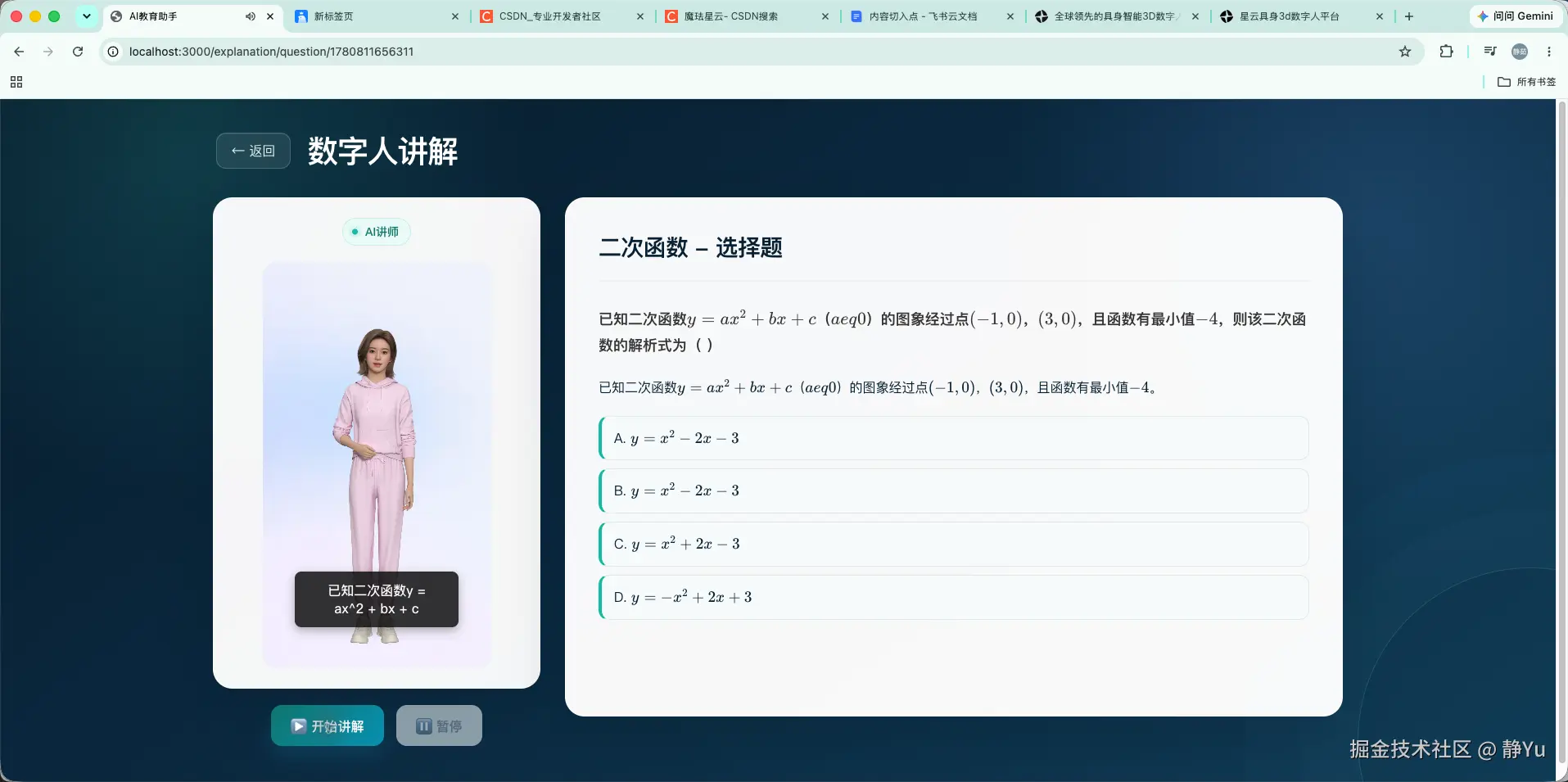
四、真实场景:一堂"二次函数"讲解如何升级为具身 Agent
为了验证这条链路,我选择了项目默认的数学场景:
bash
学科:数学
主题:二次函数
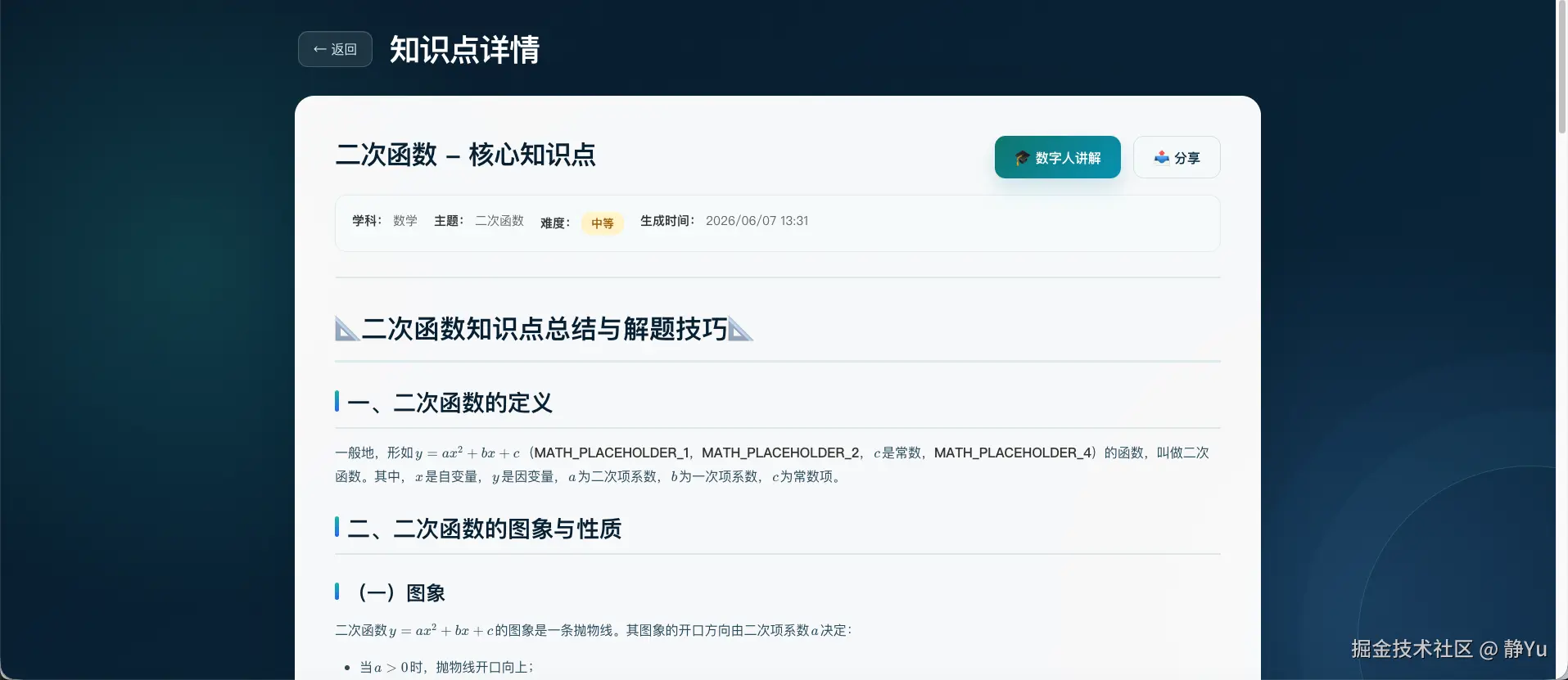
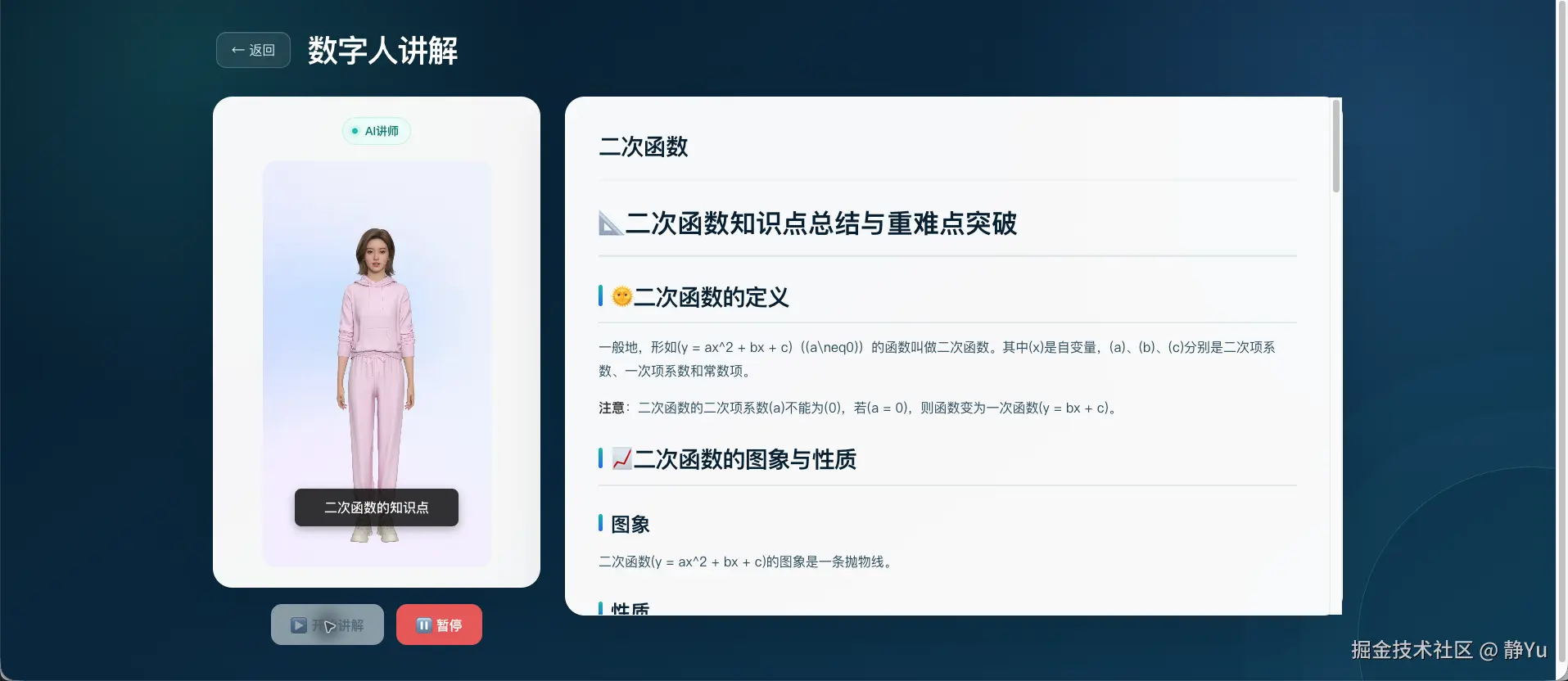
难度:中等第一步:生成可阅读的知识内容
用户提交表单后,模型生成包含二次函数定义、图像特征、顶点、对称轴和例题的 Markdown 内容。系统通过 Pinia 保存生成结果,再跳转到详情页。
详情页使用 Marked 渲染 Markdown,并在渲染前保护 ... 与 ... 公式,最后交给 KaTeX 显示。 此时,系统已经是一份合格的 AI 学习资料,但还不是 AI 教师。
第二步:从"文章"生成"讲稿"
学生点击数字人讲解后,系统读取同一条知识点上下文,让大模型把文章改写为口语化讲稿。 例如,页面上可能写着:
bash
二次函数的一般形式为 y = ax² + bx + c,其中 a ≠ 0。口播稿则可以改写为:
bash
我们先抓住二次函数最基本的形式。大家注意,二次项系数 a 不能等于零;
如果 a 等于零,它就会退化成一次函数。模型负责把知识变成教学语言,数字人负责把教学语言变成可感知的表达。
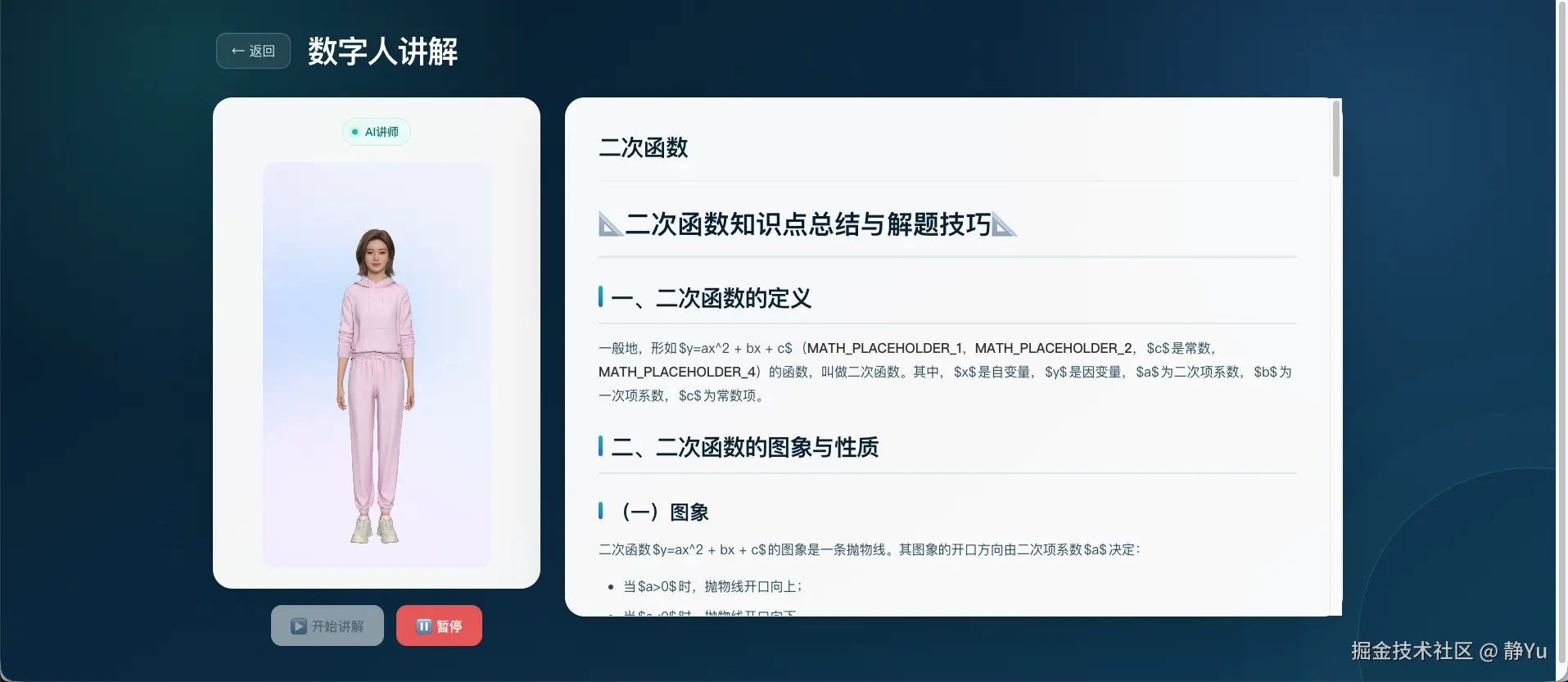
第三步:数字人边接收边讲解
模型返回首段内容后,前端立即将文本送入星云数字人。星云通过参数流驱动端侧数字人渲染,学生在页面左侧看到 AI 讲师,右侧仍然保留完整知识点。
这种双通道设计是我认为当前项目最有价值的部分:
-
视觉通道保留公式和结构;
-
听觉通道负责解释和强调;
-
数字人形象提供持续的交互反馈;
-
用户可以暂停讲解,再回到原文核对。 与单纯播放 TTS 相比,数字人让"谁在讲"变得明确;与预制视频相比,本次讲解内容完全来自用户刚刚生成的知识点。
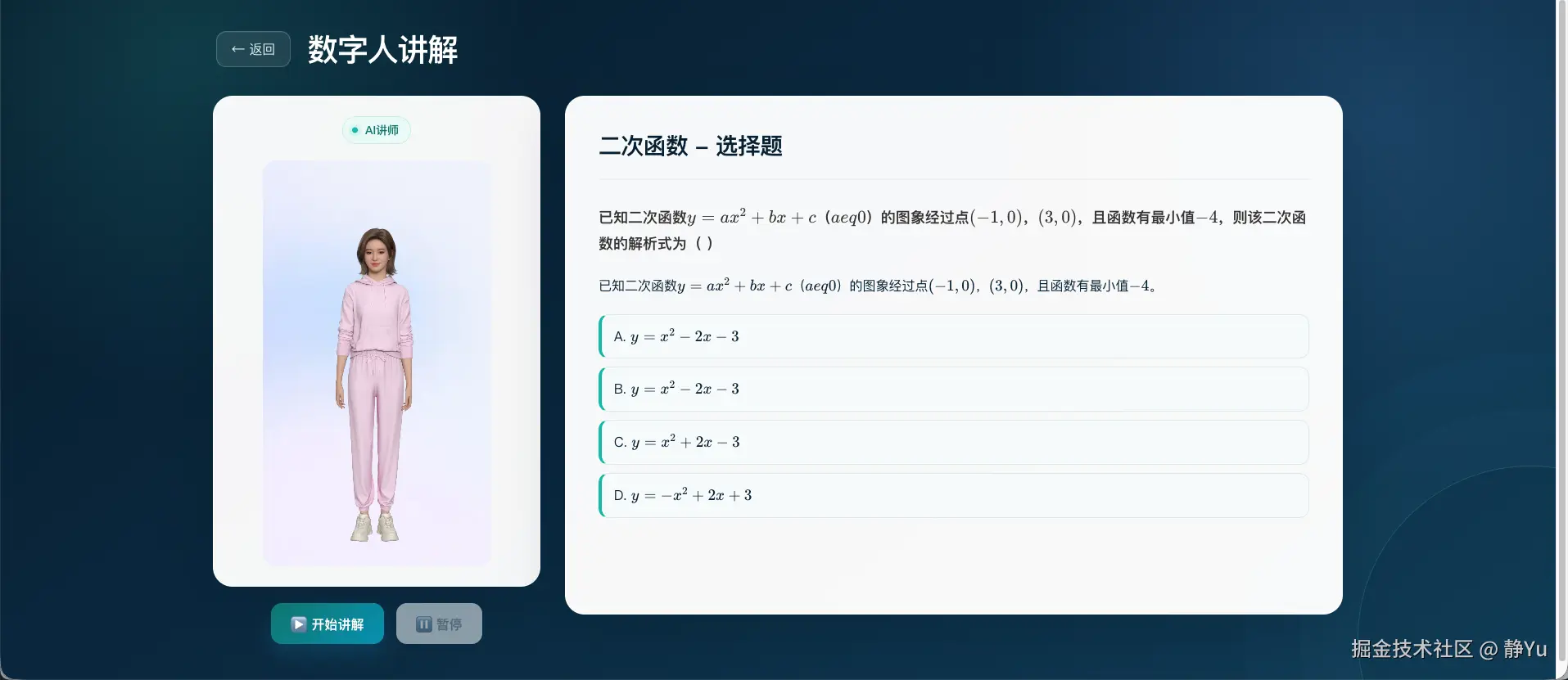
第四步:把同一套能力复用到试题解析
试题场景不需要重新搭建数字人系统,只需要更换讲解策略。 选择题可以按以下顺序组织:
题目背景 → 题干 → 逐项读出选项 → 公布正确答案 → 解释错误选项与关键依据
填空题重点解释答案来源;解答题则围绕审题、答题要点和推导过程展开。
当前项目已经为三类题型准备了不同文本结构,但还有一个需要修正的工程细节:generateExplanationText() 是异步函数,开始讲解时必须先 await 获取结果,否则试题分支的播放队列可能在内容准备完成前就被读取。
bash
const explanations = await generateExplanationText()
if (!explanations.length) return这类问题说明,具身 Agent 的难点不只在模型或数字人 SDK,也在多个异步系统之间的顺序控制。
五、SDK、API 与项目架构的实际落地方式
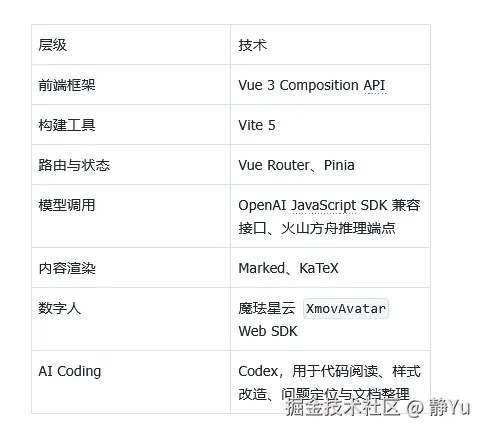
1. 当前项目技术栈
这次开发使用的主要技术包括:
在实际开发中,AI Coding 工具对这类跨模块项目很有帮助。我使用 Codex 同时检查了数字人组件、讲解页面、Pinia Store、模型调用和详情页渲染逻辑,并通过本地构建与浏览器检查验证修改结果。
但 AI Coding 只能加快阅读和实现,不能代替对异步链路与业务状态的判断。例如,模型流应该如何断句、暂停时应取消哪些任务、密钥应该放在哪里,仍然需要开发者明确系统边界。
2. SDK 接入应与业务解耦
我把星云 SDK 放在独立组件中,而不是直接写进讲解页面,原因有三点:
- 统一管理初始化和销毁;
- 避免重复创建数字人会话;
- 方便未来切换不同角色或讲解页面。 组件卸载时必须主动停止并销毁实例:
bash
const disconnect = () => {
const avatar = instance.value
if (!avatar) return
try { avatar.destroy?.() } catch {}
instance.value = null
}如果不清理,路由切换后可能残留连接、音频或渲染资源。
3. 生产环境不能把凭证写在浏览器里
当前项目是演示原型,模型密钥和数字人应用凭证直接出现在前端代码中,并启用了 dangerouslyAllowBrowser。这种方式便于快速验证,但不适合正式部署。
生产架构应该调整为:
浏览器 → 请求业务后端 → 后端持有长期密钥 → 后端调用模型或签发短期数字人会话凭证 → 浏览器只获得最小权限的临时 Token
同时应增加用户鉴权、调用频率限制、日志脱敏和凭证轮换。
4. 为约 500ms 端到端响应设计整条链路
星云的毫秒级实时交互能力不能只靠前端调用一个 speak() 方法实现。若希望接近端到端约 500ms 的响应体验,整条链路都需要围绕低延迟设计:
- 模型使用流式输出,减少首字等待;
- 提示词避免生成冗长前言;
- 语义缓冲控制在短句级别;
- 数字人会话提前初始化;
- 播放队列持续消费,不等待全文;
- 暂停时同时取消模型流和数字人队列;
- 网络异常时提供重连与降级方案。 星云自研端侧渲染与参数流架构降低了画面传输负担,也更适合高并发场景。但项目最终体验仍取决于模型首包、业务后端、网络和队列调度,不能只看某个单点接口耗时。
5. 下一阶段架构
当前项目的下一阶段不应该只是增加更多页面,而应补齐 Agent 能力:
bash
麦克风输入
→ ASR
→ 多轮会话与意图识别
→ 教材 RAG / 题库工具
→ LLM 推理
→ 内容安全与事实校验
→ 语义分句
→ 星云数字人这样,学生才能在讲解过程中追问"为什么 a 大于零时开口向上",数字人也能结合当前知识点继续回答,而不是只能播放预先生成的一轮讲稿。
结语:我的实际体验
完成这次接入后,我对数字人的判断发生了变化。
一开始,我把数字人理解为 AI 内容的展示组件:模型负责生成,数字人负责播放。真正把项目跑通后,我发现这种理解太浅。数字人是否自然,取决于模型首包、内容改写、语义分句、播放队列、状态机、端侧渲染和用户控制是否共同工作。
魔珐星云在这个项目里的价值,是让我能够把大模型生成的临时教学内容直接交给一个可实时表达的数字人,而不必为每一篇知识点提前生产视频。
从实际效果看,项目也不再只是"输入二次函数,得到一篇文章"。用户面对的是一个能够生成知识、展示公式、组织讲稿并实时开口讲解的 AI 教师雏形。
当然,当前版本仍然需要继续完善:前端凭证要迁移到服务端,Token 级输入要升级为语义短句队列,暂停逻辑要与模型取消联动,单轮讲解还要扩展为支持语音追问的多轮会话。
但这次实践至少验证了一件事:当 LLM 的知识能力与星云的实时具身表达能力真正进入同一条业务链路后,数字人才不再是页面旁边的装饰,而开始成为 Agent 与用户之间的交互主体。
资源链接
如果你想动手试试这套方案,以下是相关资源:
魔珐星云开发者文档与 SDK:xingyun3d.com/developers/...
魔珐星云官网: xingyun3d.com?utm_campaign=daily&utm_source=jixinghuiKoc156&utm_medium=&utm_term=&utm_content=