前言
AutoMQ 在兼容 Kafka 协议与语义的前提下,将本地 Log/Segment 映射为 S3 上的 Stream 存储模型。
本文从 Kafka 数据目录出发,沿 Log → Segment → Stream → S3 这条主线,梳理 AutoMQ 的存储抽象、读写路径与 Compaction 机制。
注:
1)本文基于AutoMQ1.6.6版本,WAL仅支持S3;
2)KIP-1150 Kafka无盘Topic:cwiki.apache.org/confluence/...;
一、Log&Segment&Stream
Kafka的数据目录组织形式如下:
sql
tree -a
.
├── .kafka_cleanshutdown
├── .lock
├── Test1-0
│ ├── 00000000000000000000.index
│ ├── 00000000000000000000.log
│ ├── 00000000000000000000.timeindex
│ ├── 00000000000000001872.index
│ ├── 00000000000000001872.log
│ ├── 00000000000000001872.timeindex
│ └── leader-epoch-checkpoint
├── cleaner-offset-checkpoint
├── log-start-offset-checkpoint
├── meta.properties
├── recovery-point-offset-checkpoint
└── replication-offset-checkpointLog:数据目录下的唯一目录={Topic}-{PartitionId},如Test1-0,存储了该分区的所有数据。Log数据由多个Segment组成,如0000是第一个segment,1872是第二个segment,文件名是该segment的起始offset,如0000存储了offset=[0,1872)共1872条消息。
Segment:每个Segment由4个文件构成
a)log:消息数据文件,追加写,大小超过segment.bytes=1G触发滚动;
b)index:offset索引文件,通过mmap读写,大小=segment.index.bytes=10M,key=相对segment起始offset的offset(4byte),value=消息在log的写入位置(4byte);
c)timeindex:时间索引文件,通过mmap读写,大小=segment.index.bytes=10M,key=时间戳(8byte),value=相对segment起始offset的offset(4byte);
d)txnindex:事务索引文件;
leader-epoch-checkpoint:每个Log一份,记录每个分区leader任期的起始offset。
节点级别数据文件:
a)meta.properties:数据和broker+cluster的关联关系;
b)checkpoint文件 :记录每个分区不同业务的offset进度;
- recovery-point-offset-checkpoint:offset=消息刷盘进度,log.flush.offset.checkpoint.interval.ms=60秒刷盘一次;
- replication-offset-checkpoint:offset=高水位HW,replica.high.watermark.checkpoint.interval.ms=5秒刷盘一次;
- log-start-offset-checkpoint:offset=Log Start Offset,log.flush.start.offset.checkpoint.interval.ms=60秒刷盘一次;
- cleaner-offset-checkpoint:offset=压缩topic分区的处理进度;
c)kafka_cleanshutdown:broker正常关闭标记文件,如果不存在,代表kafka进程异常关闭。
d)lock:文件锁,一个数据目录同时只能有一个进程访问。
Broker侧AutoMQ和Kafka的对应关系如下:
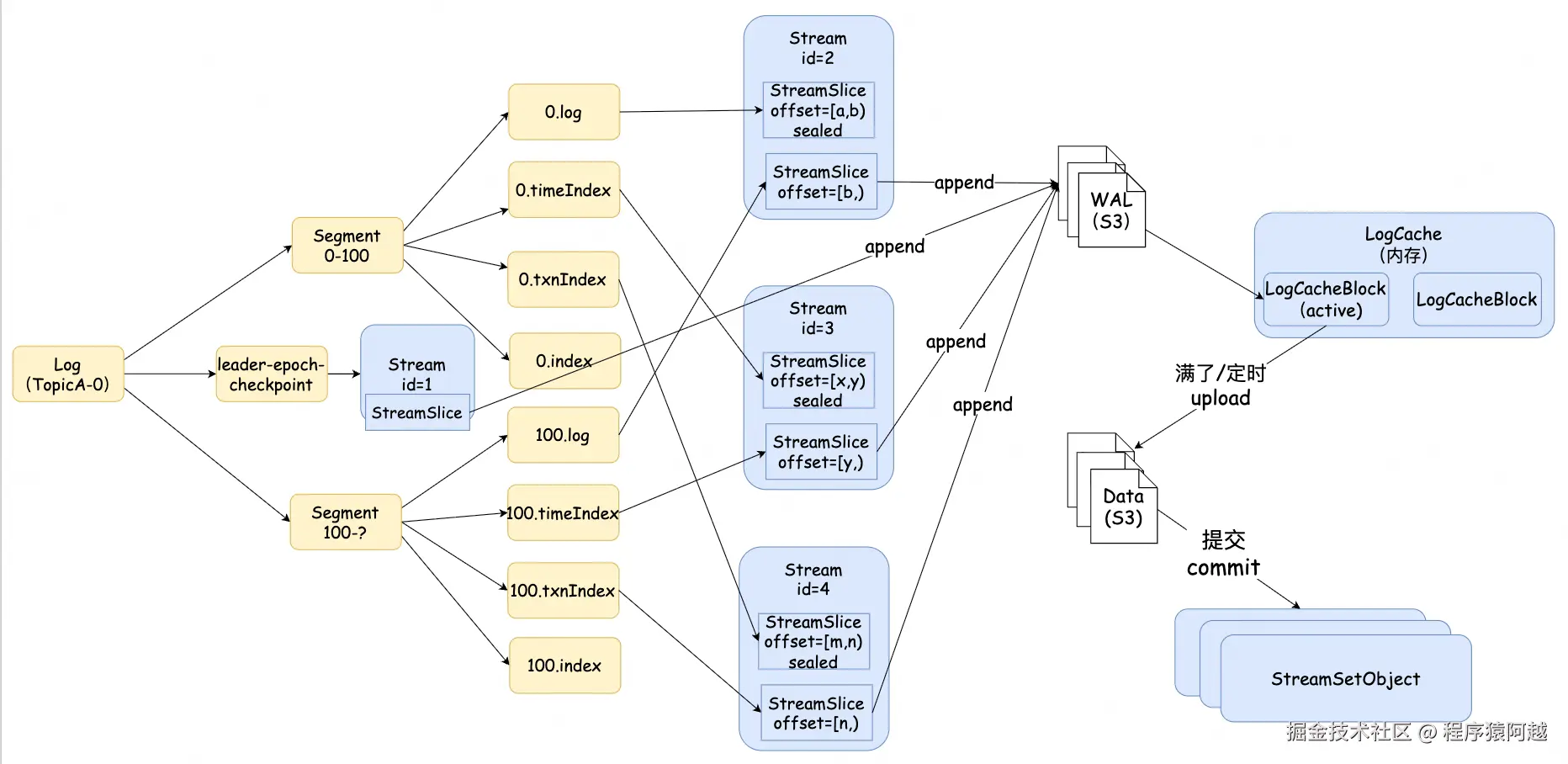
Stream :一个分区Log对应4个Stream,分别是:元数据 、数据log 、时间索引 、事务索引。
java
public class S3Stream implements Stream, StreamMetadataListener {
// id
private final long streamId;
// 分区LeaderEpoch
private final long epoch;
// 起始offset
private long startOffset;
// 下一个写入offset
private final AtomicLong nextOffset;
// 已经写入成功的offset
final AtomicLong confirmOffset;
// S3Storage读写Stream
private final Storage storage;
}元数据MetaStream包装Stream,kv存储如:
1)ElasticLogMeta:每个segment的元数据;
2)ElasticPartitionProducerSnapshotsMeta:事务状态快照;
3)ElasticPartitionMeta:对应Kafka数据目录下的checkpoint,只是按照分区拆分了,另外存储cleanedShutdown标记;
4)ElasticLeaderEpochCheckpointMeta:对应Log目录下的leader-epoch-checkpoint,每个LeaderEpoch的起始offset;
java
public class MetaStream implements Stream {
// ElasticLogMeta
public static final String LOG_META_KEY = "LOG";
// ElasticPartitionProducerSnapshotsMeta
public static final String PRODUCER_SNAPSHOTS_META_KEY = "PRODUCER_SNAPSHOTS";
// ElasticPartitionMeta
public static final String PARTITION_META_KEY = "PARTITION";
// ElasticLeaderEpochCheckpointMeta
public static final String LEADER_EPOCH_CHECKPOINT_KEY = "LEADER_EPOCH_CHECKPOINT";
// S3Stream 实际写S3
private final Stream innerStream;
// key value
private final Map<String, MetadataValue> metaCache;
}
public class ElasticLogMeta {
// log/tim/txn -> segment里的3个stream对应StreamId
private Map<String, Long> streamMap = new HashMap<>();
// n个segment的元数据
private List<ElasticStreamSegmentMeta> segmentMetas = new LinkedList<>();
}
public class ElasticStreamSegmentMeta {
// segment的baseOffset,以前是看文件名
private long baseOffset;
private long createTimestamp;
private long lastModifiedTimestamp;
private String streamSuffix = "";
private int logSize;
// log的offset区间
private SliceRange log = new SliceRange();
// time索引的offset区间
private SliceRange time = new SliceRange();
// 事务索引的offset区间
private SliceRange txn = new SliceRange();
private long firstBatchTimestamp;
private TimestampOffsetData timeIndexLastEntry = new TimestampOffsetData();
}StreamSlice:Stream切片,一个Stream包含多个StreamSlice,一个StreamSlice对应一段数据区间。
对于Segment来说,一个Segment里的一个文件(如log文件)对应一个StreamSlice,只有最新的Slice可以写入(sealed=false)。
java
public class DefaultElasticStreamSlice implements ElasticStreamSlice {
private final long startOffsetInStream;
// 通过Stream写入数据
private final Stream stream;
private long endOffset = Offsets.NOOP_OFFSET;
// 是否封存
private boolean sealed = false;
// 写
public CompletableFuture<AppendResult> append(AppendContext context, RecordBatch recordBatch) {
if (sealed) {
return FutureUtil.failedFuture();
}
return stream.append(context, recordBatch).thenApply(AppendResultWrapper::new);
}
// 读
public CompletableFuture<FetchResult> fetch(FetchContext context, long startOffset, long endOffset, int maxBytesHint) {
long fixedStartOffset = Utils.max(startOffset, 0);
return stream.fetch(context, startOffsetInStream + fixedStartOffset, startOffsetInStream + endOffset, maxBytesHint)
.thenApply(FetchResultWrapper::new);
}
}二、Stream管理
Stream元数据会存储在Controller里,内存中的形式如下:
java
public class StreamControlManager {
// 自增streamId -> createStream
private final TimelineLong nextAssignedStreamId;
// streamId -> Stream元数据
private final TimelineHashMap<Long, StreamRuntimeMetadata> streamsMetadata;
}
public class StreamRuntimeMetadata {
private final long streamId;
// leaderEpoch
private final TimelineLong currentEpoch;
// rangeIndex自增生成器
private final TimelineInteger currentRangeIndex;
// 起始offset
private final TimelineLong startOffset;
// 结束offset
private final TimelineLong endOffset;
// CLOSE or OPEN
private final TimelineObject<StreamState> currentState;
// tags
private Map<String, String> tags;
// rangeIndex -> range元数据
private final TimelineHashMap<Integer, RangeMetadata> ranges;
// objectId -> streamId+startOffset+endOffset
private final TimelineHashMap<Long, S3StreamObject> streamObjects;
}
public class RangeMetadata implements Comparable<RangeMetadata> {
private long streamId;
// 创建这个range的leaderEpoch
private long epoch;
private int rangeIndex;
private long startOffset;
private long endOffset;
// 独占这个range的节点id
private int nodeId;
}
public class S3StreamObject {
private final long objectId;
private final long streamId;
private final long startOffset;
private final long endOffset;
}ElasticLog.apply:重写Kafka的LocalLog,Broker成为某个分区Leader,需要创建Partition,触发创建&开启MetaStream,用于读写分区元数据。
scala
def apply(...): ElasticLog = {
val key = formatStreamKey(namespace, topicPartition, topicId)
// 【1】topicPartition->streamId(MetaStream)
val value = client.kvClient().getKV(KeyValue.Key.of(key)).get()
val topicIdStr: String = topicId.map(u => u.toString).getOrElse(topicPartition.topic())
var partitionMeta: ElasticPartitionMeta = null
val metaNotExists = value.isNull
var metaStream: MetaStream = null
var logStreamManager: ElasticLogStreamManager = null
val replicationFactor = 1
val streamTags = new util.HashMap[String, String]()
streamTags.put(StreamTags.Topic.KEY, topicIdStr)
streamTags.put(StreamTags.Partition.KEY, StreamTags.Partition.encode(topicPartition.partition()))
try {
// 【2】MetaStream(S3Stream) kv存储stream
metaStream = if (metaNotExists) {
// 没创建stream,分配streamId并存储,开启Stream
val stream = createMetaStream(client, key, replicationFactor, leaderEpoch, streamTags, logIdent = logIdent)
stream
} else {
// 已经创建了stream,从kv获取分区对应MetaStream的streamId
val metaStreamId = Unpooled.wrappedBuffer(value.get()).readLong()
// 请求Controller开启Stream,当前节点独占Stream CLOSE->OPEN
val stream = client.streamClient().openStream(metaStreamId, OpenStreamOptions.builder().epoch(leaderEpoch).tags(streamTags).build())
// S3Stream -> MetaStream(S3Stream)
.thenApply(stream => new MetaStream(stream, META_SCHEDULE_EXECUTOR, logIdent))
.get()
stream
}
// MetaStream 读当前分区的元数据流,恢复内存元数据
val metaMap = metaStream.replay().asScala
// MetaStream checkpoint数据
val partitionMetaOpt = metaMap.get(MetaStream.PARTITION_META_KEY).map(m => m.asInstanceOf[ElasticPartitionMeta])
// MetaStream 事务状态快照
val producerSnapshotsMeta = metaMap.get(MetaStream.PRODUCER_SNAPSHOTS_META_KEY).map(m => m.asInstanceOf[ElasticPartitionProducerSnapshotsMeta]).getOrElse(new ElasticPartitionProducerSnapshotsMeta())
// MetaStream 每个segment的元数据
val logMeta: ElasticLogMeta = metaMap.get(MetaStream.LOG_META_KEY).map(m => m.asInstanceOf[ElasticLogMeta]).getOrElse(new ElasticLogMeta())
// streamName(log/tim/txn) -> S3Stream
logStreamManager = new ElasticLogStreamManager(...)
// streamName(log/tim/txn) -> DefaultElasticStreamSlice(S3Stream、startOffsetInStream、endOffset)
val streamSliceManager = new ElasticStreamSliceManager(logStreamManager)
// Map<Long, ElasticLogSegment> segments
val logSegmentManager = new ElasticLogSegmentManager(...)
val segments = new CachedLogSegments(topicPartition)
// 【3】重写kafka的LogLoader,加载Segment(StreamSlice)
val offsets = new ElasticLogLoader(...).load()
// MetaStream 分区leader的checkpoint
val leaderEpochCheckpointMetaOpt = metaMap.get(MetaStream.LEADER_EPOCH_CHECKPOINT_KEY).map(m => m.asInstanceOf[ElasticLeaderEpochCheckpointMeta])
val elasticLog = new ElasticLog(...)
if (partitionMeta.getCleanedShutdown) {
partitionMeta.setCleanedShutdown(false)
elasticLog.persistPartitionMeta()
}
elasticLog
}
}ElasticLog.createMetaStream:因为MetaStream只是在S3Stream上封装了自己的KV存储逻辑,所以和普通Stream创建和使用逻辑一致。
1)createStream:请求Controller申请唯一streamId;
2)openStream:请求Controller,传入streamId/nodeId/leaderEpoch,Controller标记Stream开启,创建一个新的StreamRange区间,该区间属于当前nodeId,返回Stream的起始offset和写入offset(比如对于log的Stream,就是logStartOffset和logEndOffset-LEO),Broker构建S3Stream;
3)putKVIfAbsent:针对MetaStream,把partition和streamId的关系存储到Controller,下次分区Leader可以再次获取到该MetaStream。其他如log和索引Stream,通过MetaStream中的ElasticLogMeta可以定位自己的streamId,不需要这一步;
scala
private[streamaspect] def createMetaStream(client: Client, key: String, replicaCount: Int, leaderEpoch: Long, streamTags: util.Map[String, String],
logIdent: String): MetaStream = {
val options = CreateStreamOptions.builder().replicaCount(replicaCount).epoch(leaderEpoch)
streamTags.forEach((k, v) => options.tag(k, v))
val metaStream = client.streamClient().createAndOpenStream(options.build())
.thenApply(stream => new MetaStream(stream, META_SCHEDULE_EXECUTOR, logIdent))
.get()
val streamId = metaStream.streamId()
val valueBuf = ByteBuffer.allocate(8)
valueBuf.putLong(streamId)
valueBuf.flip()
client.kvClient().putKVIfAbsent(KeyValue.of(key, valueBuf)).get()
metaStream
}
// S3StreamClient#createAndOpenStream
public CompletableFuture<Stream> createAndOpenStream(CreateStreamOptions options) {
return runInLock(() -> {
checkState();
TimerUtil timerUtil = new TimerUtil();
// 1. 从controller申请streamId
return FutureUtil.exec(() -> streamManager.createStream(options.tags()).thenCompose(streamId -> {
// 2. 请求controller stream open,内存创建S3Stream
return openStream0(streamId, options.epoch(), options.tags(), OpenStreamOptions.builder().epoch(options.epoch()).tags(options.tags()).build());
}), LOGGER, "createAndOpenStream");
});
}下面看一下对应Segment 纬度的StreamSlice,多种场景下会创建Segment:
1)Log下没有Segment,即MetaStream中ElasticLogMeta为空,创建新的Segment;
2)与1相反,从ElasticLogMeta中恢复n个Segment;
3)写Log触发Segment滚动;
ElasticLog.createAndSaveSegment:创建Segment,baseOffset=Segment的起始offset,Kafka中Segment的baseOffset提现在文件名上。
scala
private def createAndSaveSegment(logSegmentManager: ElasticLogSegmentManager, suffix: String = "", logIdent: String)
(baseOffset: Long, dir: File, config: LogConfig, streamSliceManager: ElasticStreamSliceManager, time: Time)
: (ElasticLogSegment, CompletableFuture[Void]) = {
val meta = new ElasticStreamSegmentMeta()
meta.baseOffset(baseOffset)
meta.streamSuffix(suffix)
meta.createTimestamp(time.milliseconds())
// 创建Segment
val segment: ElasticLogSegment = new ElasticLogSegment(dir, meta, streamSliceManager, config, time, logSegmentManager.logSegmentEventListener(), logIdent)
var metaSaveCf: CompletableFuture[Void] = CompletableFuture.completedFuture(null)
// 持久化segment元数据到metastream
metaSaveCf = logSegmentManager.create(baseOffset, segment)
(segment, metaSaveCf)
}
// ElasticLogSegmentManager
final Map<Long, ElasticLogSegment> segments = new HashMap<>();
public CompletableFuture<Void> create(long baseOffset, ElasticLogSegment segment) {
// 内存管理segments
segments.put(baseOffset, segment);
// 持久化MetaStream
return asyncPersistLogMeta();
}ElasticLogSegment:一个Segment=log+时间索引+事务索引3个StreamSlice=3个分区纬度的Stream里的一段。
java
public class ElasticLogSegment extends LogSegment implements Comparable<ElasticLogSegment> {
// segment元数据
private final ElasticStreamSegmentMeta meta;
private final long baseOffset;
// log StreamSlice
private final ElasticLogFileRecords log;
// 时间索引 StreamSlice
private final ElasticTimeIndex timeIndex;
// 事务索引 StreamSlice
private final ElasticTransactionIndex txnIndex;
public ElasticLogSegment(
File dir,
ElasticStreamSegmentMeta meta,
ElasticStreamSliceManager sm,
LogConfig logConfig,
Time time,
ElasticLogSegmentEventListener segmentEventListener,
String logIdent
) throws IOException {
super(null, null, null, null, meta.baseOffset(), logConfig.indexInterval, logConfig.segmentJitterMs, time);
this.meta = meta;
baseOffset = meta.baseOffset();
String suffix = meta.streamSuffix();
// log的StreamSlice
log = new ElasticLogFileRecords(sm.loadOrCreateSlice("log" + suffix, meta.log()), baseOffset, meta.logSize());
// 时间索引的StreamSlice
TimestampOffset lastTimeIndexEntry = meta.timeIndexLastEntry().toTimestampOffset();
timeIndex = new ElasticTimeIndex(
LogFileUtils.timeIndexFile(dir, baseOffset, suffix),
baseOffset,
logConfig.maxIndexSize,
new DefaultStreamSliceSupplier(sm, "tim" + suffix, meta.time()),
lastTimeIndexEntry,
timeCache
);
// 事务索引的StreamSlice
txnIndex = new ElasticTransactionIndex(
baseOffset,
LogFileUtils.transactionIndexFile(dir, baseOffset, suffix),
new DefaultStreamSliceSupplier(sm, "txn" + suffix, meta.txn()),
txnCache
);
}ElasticStreamSliceManager.loadOrCreateSlice:加载或创建StreamSlice。
如果是新Segment(不是从MetaStream恢复的),创建新StreamSlice。
如果Stream不存在,级联触发Stream创建(获取streamId,开启Stream);如果Stream存在,触发Stream开启(当前节点获取一个新的Stream Range区间)。
java
private final Map<String, ElasticStreamSlice> lastSlices = new ConcurrentHashMap<>();
private final ElasticLogStreamManager streamManager;
public ElasticStreamSlice loadOrCreateSlice(String streamName, SliceRange sliceRange) throws IOException {
if (sliceRange.start() == Offsets.NOOP_OFFSET) {
return newSlice(streamName);
}
return new DefaultElasticStreamSlice(streamManager.getStream(streamName), sliceRange);
}
public ElasticStreamSlice newSlice(String streamName) throws IOException {
// 关闭stream中上一个slice(segment),不能再写入数据
ElasticStreamSlice lastSlice = lastSlices.get(streamName);
if (lastSlice != null) {
lastSlice.seal();
}
// 创建新slice,区间为[-1,-1]
Stream stream = streamManager.getStream(streamName);
ElasticStreamSlice streamSlice = new DefaultElasticStreamSlice(stream, SliceRange.of(Offsets.NOOP_OFFSET, Offsets.NOOP_OFFSET));
lastSlices.put(streamName, streamSlice);
return streamSlice;
}
// ElasticLogStreamManager
// key=log/tim/txn value=s3stream
private final Map<String, LazyStream> streamMap = new ConcurrentHashMap<>();
public LazyStream getStream(String name) throws IOException {
if (streamMap.containsKey(name)) {
return streamMap.get(name);
}
LazyStream lazyStream = new LazyStream(name, LazyStream.NOOP_STREAM_ID, streamClient, replicaCount, epoch, tags, snapshotRead);
lazyStream.setListener(innerListener);
// log和时间索引,立即创建或开启S3Stream
boolean warmUp = "log".equals(name) || "tim".equals(name);
if (warmUp) {
lazyStream.warmUp();
}
streamMap.put(name, lazyStream);
return lazyStream;
}后续数据写入,即找到最后一个Segment→3个StreamSlice→3个Stream。
三、写
3-1、写Write-Ahead Log
3-1-1、写入路径:Log→Segment→Stream→S3Storage
Partition.appendRecordsToLeader:AutoMQ写入口
scala
def appendRecordsToLeader(...): LogAppendInfo = {
val (info, leaderHWIncremented) = inReadLock(leaderIsrUpdateLock) {
leaderLogIfLocal match {
case Some(leaderLog) =>
// 写log
val info = leaderLog.appendAsLeader(...)
}
}ElasticLog.append:写入主流程。
1)找到最后一个Segment写入消息---异步任务;
2)更新LEO,不等Segment写入完成;
3)Segment写入完成后(cf完成),更新confirmOffset;
4)confirmOffset更新成功,回调Partition.handleLeaderConfirmOffsetMove,更新高水位HW=confirmOffset,响应挂起的acks=-1的生产者请求;
scala
// lastOffset=records最后一条消息的offset
override private[log] def append(lastOffset: Long, records: MemoryRecords): Unit = {
val activeSegment = segments.activeSegment
// 写segment
activeSegment.append(lastOffset, records)
val endOffset = lastOffset + 1
// 不等wal写入完成,就更新LEO
updateLogEndOffset(endOffset)
val cf = activeSegment.asInstanceOf[ElasticLogSegment].asyncLogFlush()
cf.whenComplete((_, _) => {
APPEND_PERMIT_SEMAPHORE.release(permit)
})
cf.thenAccept(_ => {
breakable {
// 写segment完成后触发cf,更新confirmOffset
while (true) {
val offset = _confirmOffset.get()
if (offset.messageOffset < endOffset) {
_confirmOffset.compareAndSet(offset, new LogOffsetMetadata(endOffset, activeSegment.baseOffset, activeSegment.size))
notify = true
} else {
break()
}
}
}
// 调用Partition.handleLeaderConfirmOffsetMove
if (notify) {
appendAckQueue.offer(endOffset)
lastAppendAckFuture = appendAckThread.submit(new Runnable {
override def run(): Unit = {
appendCallback(startNanos)
}
})
}
})
}
private def appendCallback(startNanos: Long): Unit = {
// Partition.handleLeaderConfirmOffsetMove
confirmOffsetChangeListener.foreach(_.apply())
}
// Partition.handleLeaderConfirmOffsetMove
private def handleLeaderConfirmOffsetMove(): Unit = {
log match {
case Some(leaderLog) =>
// 更新HW=confirmOffset
if (maybeIncrementLeaderHW(leaderLog)) {
// 响应客户端(acks=-1)
tryCompleteDelayedRequests()
}
}
}
private def maybeIncrementLeaderHW(leaderLog: UnifiedLog, currentTimeMs: Long = time.milliseconds): Boolean = {
leaderLog match {
case elasticLog: ElasticUnifiedLog =>
val confirmOffset = elasticLog.confirmOffset()
newHighWatermark = confirmOffset
this.confirmOffset = confirmOffset.messageOffset
case _ =>
}
// ...
}ElasticLogSegment.append:Segment写入,最终调用StreamSlice(Stream)写入。
AutoMQ没有offset索引,只有时间索引,且索引间隔从4KB放大到1MB。
java
// StreamSlice
private final ElasticLogFileRecords log;
// StreamSlice
private final ElasticTimeIndex timeIndex;
public void append(
long largestOffset,
MemoryRecords records) throws IOException {
if (records.sizeInBytes() > 0) {
// append the messages
long appendedBytes = log.append(records, largestOffset + 1);
for (RecordBatch batch : records.batches()) {
// ...
// index.interval.bytes=1MB (kafka 4kb)
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
timeIndex().maybeAppend(maxTimestampSoFar(), shallowOffsetOfMaxTimestampSoFar());
bytesSinceLastIndexEntry = 0;
}
}
}
}
// ElasticLogFileRecords
private final ElasticStreamSlice streamSlice;
public int append(MemoryRecords records, long lastOffset) throws IOException {
int appendSize = records.sizeInBytes();
int count = (int) (lastOffset - nextOffset());
com.automq.stream.DefaultRecordBatch batch = new com.automq.stream.DefaultRecordBatch(count, 0, Collections.emptyMap(), records.buffer());
AppendContext context = new AppendContext();
CompletableFuture<?> cf;
// streamSlice写
cf = streamSlice.append(context, batch);
}
// ElasticStreamSlice
private final Stream stream;
public CompletableFuture<AppendResult> append(AppendContext context, RecordBatch recordBatch) {
if (sealed) {
return FutureUtil.failedFuture();
}
return stream.append(context, recordBatch).thenApply(AppendResultWrapper::new);
}S3Stream.append0:在消息批次外额外封装一层StreamRecordBatch,追加streamId、epoch-leaderEpoch、baseOffset-批次起始offset、count-消息数量,调用S3Storage写入。
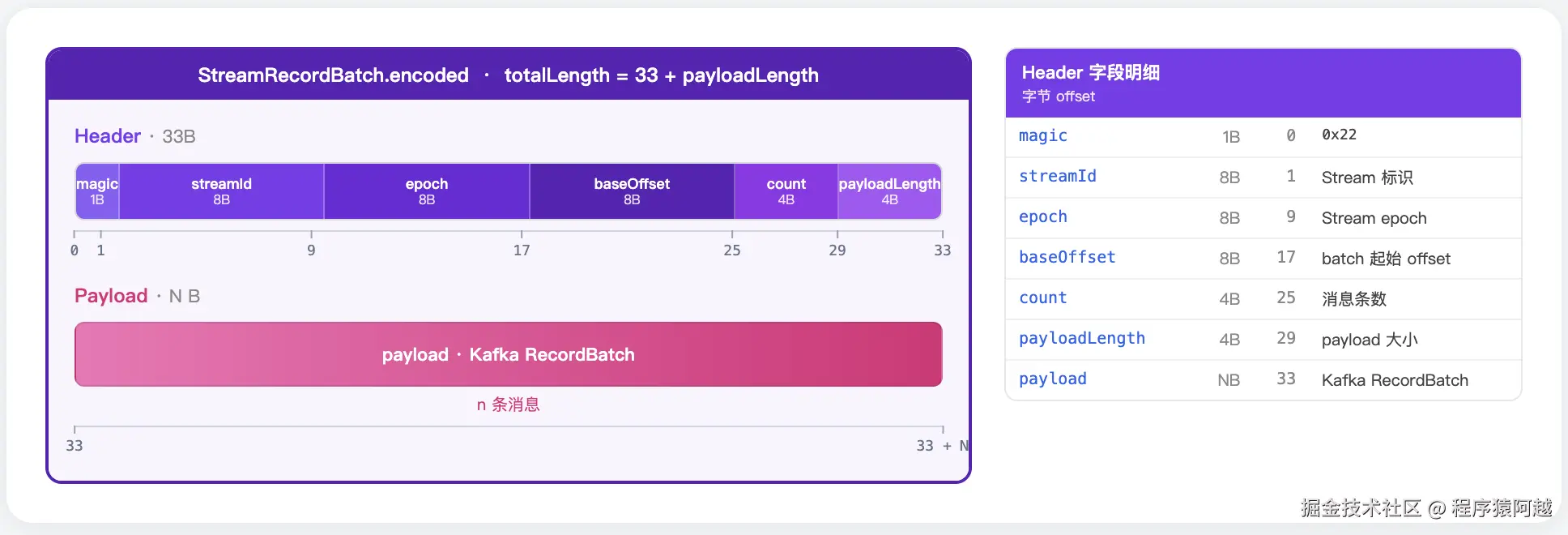
java
// S3Storage
private final Storage storage;
private CompletableFuture<AppendResult> append0(AppendContext context, RecordBatch recordBatch) {
long offset = nextOffset.getAndAdd(recordBatch.count());
StreamRecordBatch streamRecordBatch = StreamRecordBatch.of(streamId, epoch, offset, recordBatch.count(), Unpooled.wrappedBuffer(recordBatch.rawPayload()));
CompletableFuture<AppendResult> cf = storage.append(context, streamRecordBatch).thenApply(nil -> {
updateConfirmOffset(offset + recordBatch.count());
return new DefaultAppendResult(offset);
});
}
public static StreamRecordBatch of(long streamId, long epoch, long baseOffset, int count, ByteBuf payload,
ByteBufSupplier alloc) {
int totalLength = HEADER_SIZE + payload.readableBytes();
ByteBuf buf = alloc.alloc(totalLength);
buf.writeByte(MAGIC_V0);
buf.writeLong(streamId);
buf.writeLong(epoch);
buf.writeLong(baseOffset);
buf.writeInt(count);
buf.writeInt(payload.readableBytes());
buf.writeBytes(payload);
payload.release();
return new StreamRecordBatch(buf);
}3-1-2、聚合写入&对象布局
S3Storage.append:消息封装WAL请求,写S3。
java
private final WriteAheadLog deltaWAL;
public CompletableFuture<Void> append(AppendContext context, StreamRecordBatch streamRecord) {
final long startTime = System.nanoTime();
CompletableFuture<Void> cf = new CompletableFuture<>();
WalWriteRequest writeRequest = new WalWriteRequest(streamRecord, null, cf, context);
append0(context, writeRequest, false);
return cf.whenComplete((nil, ex) -> {
});
}
public boolean append0(AppendContext context, WalWriteRequest request, boolean fromBackoff) {
CompletableFuture<AppendResult> appendCf;
try {
try {
StreamRecordBatch streamRecord = request.record;
streamRecord.retain();
// 写s3
appendCf = deltaWAL.append(new TraceContext(context), streamRecord);
} catch (OverCapacityException e) {
// 触发wal upload写真实数据
maybeForceUpload();
return true;
}
} catch (Throwable e) {
request.cf.completeExceptionally(e);
return false;
}
appendCf.thenAccept(rst -> {
// 缓存到LogCache(L1读缓存)
handleAppendCallback(request);
});
return false;
}DefaultWriter.append0:多个Stream会调用公共的WAL服务写入数据,多个Stream的数据可能合并到一个Bulk中。每个Bulk可能由于容量(8MB软限制、64MB硬限制)或延迟(10-250ms),刷写到S3中的某个WAL对象。
java
private Bulk activeBulk = null;
public CompletableFuture<AppendResult> append0(
StreamRecordBatch streamRecordBatch) throws OverCapacityException, WALFencedException {
// 1g没wal没写,异常,触发upload,写s3 data
if (bufferedDataBytes.get() > config.maxUnflushedBytes()) {
throw new OverCapacityException();
}
int dataSize = streamRecordBatch.encoded().readableBytes() + RecordHeader.RECORD_HEADER_SIZE;
Record record = new Record(streamRecordBatch, new CompletableFuture<>());
lock.writeLock().lock();
try {
if (activeBulk == null) {
activeBulk = new Bulk(nextOffset.get());
}
// 如果加上新批次,超出64mb,老bulk必须先写s3 wal,让新批次加入新bulk
if (dataSize + activeBulk.size > DATA_FILE_ALIGN_SIZE) {
uploadActiveBulk();
this.activeBulk = new Bulk(nextOffset.get());
}
bufferedDataBytes.addAndGet(dataSize);
// wal加入内存bulk,攒批写s3 wal
activeBulk.add(record);
// bulk+新批次 > 8mb,bulk写s3 wal
if (activeBulk.size > config.maxBytesInBatch()) {
uploadActiveBulk();
}
} finally {
lock.writeLock().unlock();
}
return record.future.whenComplete((v, throwable) -> {
bufferedDataBytes.addAndGet(-dataSize);
});
}
class Bulk {
private int size;
private final long baseOffset;
private final List<Record> records = new ArrayList<>(1024);
private final long startNanos;
final CompletableFuture<ObjectStorage.WriteResult> uploadCf = new CompletableFuture<>();
final CompletableFuture<Void> completeCf = new CompletableFuture<>();
public Bulk(long baseOffset) {
this.startNanos = time.nanoseconds();
this.baseOffset = baseOffset;
long forceUploadDelayNanos = Math.min(
Math.max(
// 10ms
minBulkUploadIntervalNanos,
lastBulkForceUploadNanos + batchNanos - startNanos
),
// 250ms
batchNanos);
lastBulkForceUploadNanos = startNanos + forceUploadDelayNanos;
SCHEDULE.schedule(() -> forceUploadBulk(this), forceUploadDelayNanos, TimeUnit.NANOSECONDS);
}
}DefaultWriter.uploadBulk0:构造WAL对象,多个Stream中的数据记录StreamRecordBatch按照顺序排列写入。如果Producer的acks=-1(all),WAL写成功后执行callback,更新confirmOffset,才响应所有相关客户端。
注:acks=1,只要提交wal异步任务,就会更新LEO,直接响应客户端成功,见ElasticLog.append和ReplicaManager.delayedProduceRequestRequired。
java
private void uploadBulk0(Bulk bulk) {
try {
long startTime = time.nanoseconds();
// n个stream的数据按照<streamId, offset>排序
List<Record> records = bulk.records;
// ...
CompositeByteBuf objectBuffer = ByteBufAlloc.compositeByteBuffer();
// ...
// endOffset向上对齐到64MiB
nextOffset = ObjectUtils.ceilAlignOffset(nextOffset);
long endOffset = nextOffset;
ObjectStorage.WriteOptions writeOptions = new ObjectStorage.WriteOptions().enableFastRetry(true);
// 对象存储key
String path = String.format(OBJECT_PATH_FORMAT, objectPrefix, firstOffset, endOffset);
FutureUtil.propagate(objectStorage.write(writeOptions, path, objectBuffer), bulk.uploadCf);
long finalLastRecordOffset = lastRecordOffset;
bulk.uploadCf.whenCompleteAsync((rst, ex) -> {
// 这里触发响应客户端
callback();
}, callbackExecutor);
} catch (Throwable ex) {
bulk.uploadCf.completeExceptionally(ex);
}
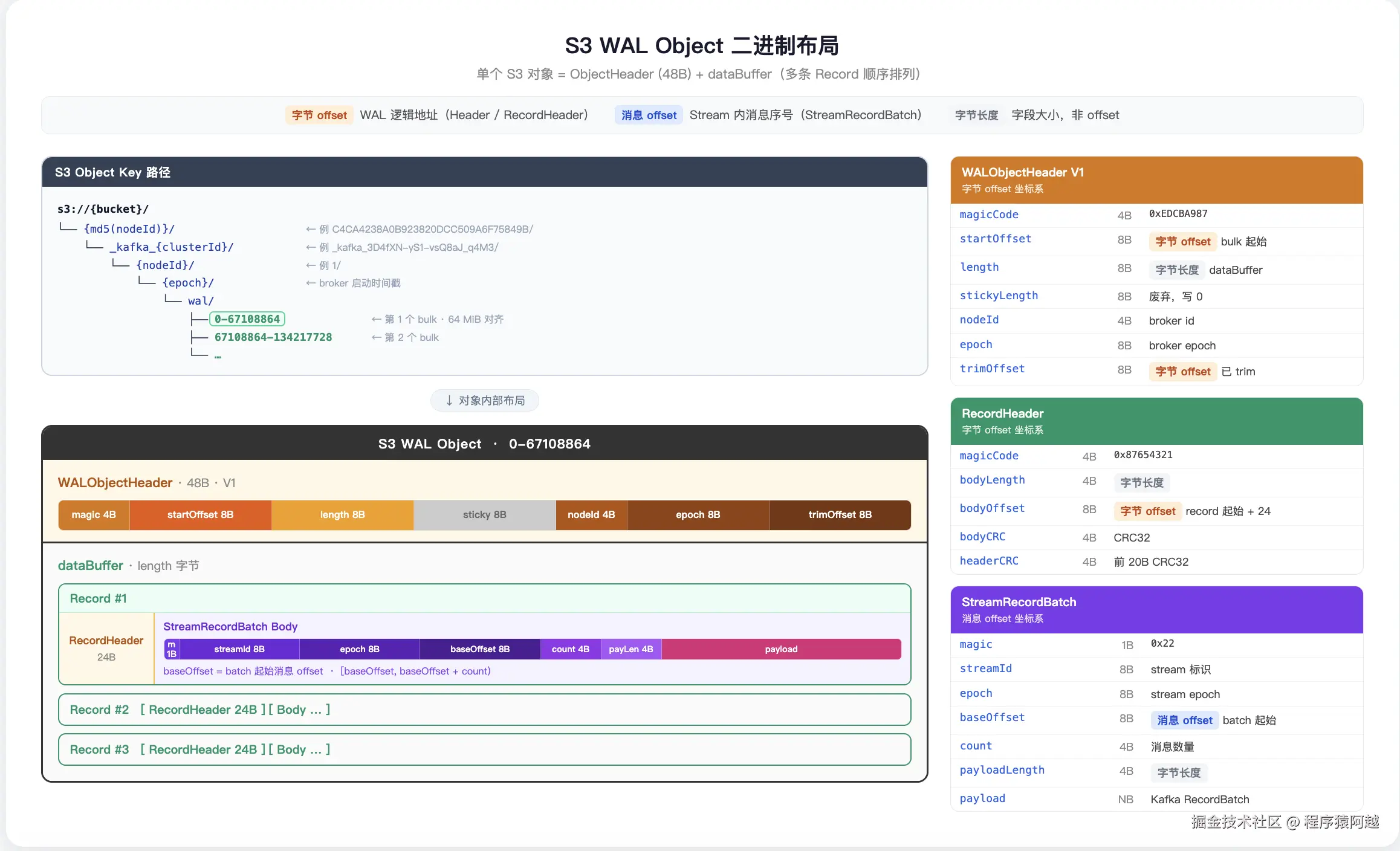
}WAL对象:
1)key=md5({node.id})/kafka{cluster.id}/{node.id}/{启动时间}/wal/{firstOffset}-{endOffset} ,如WAL对象0-67108864可能实际只有8MiB,但是命名会和64MiB对齐;
2)value=WALObjectHeader+RecordHeader0+StreamRecordBatch0+...+RecordHeadern+StreamRecordBatchn。
3-1-3、WAL缓存-LogCache
S3Storage.handleAppendCallback:WAL对象写入成功,将数据缓存到LogCache,用于加速读。
java
private final LogCache deltaWALCache;
private void handleAppendCallback(WalWriteRequest request) {
request.record.retain();
boolean full;
// wal中的数据放到缓存里,加速读
synchronized (deltaWALCache) {
full = deltaWALCache.put(request.record);
deltaWALCache.setLastRecordOffset(request.offset);
}
// 如果缓存满了,触发真实data写,写完可以清理wal对象和内存缓存
if (full) {
uploadDeltaWAL();
}
// ...
}LogCache:维护了blocks列表,列表中最后一个LogCacheBlock是可以写入的缓存块,即activeBlock。StreamRecordBatch会整个放入activeBlock缓存。
java
public class LogCache {
// 缓存 老wal->新wal
final List<LogCacheBlock> blocks = new ArrayList<>();
// 活跃的block,可以把最近的wal加入这里
private LogCacheBlock activeBlock;
// LogCache缓存字节大小
// Math.max(堆内存/2/ 3, (堆内存/2 - 3L * 1024 * 1024 * 1024) / 3 * 2)
// 或 s3.wal.cache.size
private final long capacity;
// 每个LogCacheBlock缓存字节大小
// math.min(capacity / 3, 500L * 1024 * 1024)
private final long cacheBlockMaxSize;
// 每个LogCacheBlock中stream数量上限
// s3.max.stream.num.per.stream.set.object=20000
private final int maxCacheBlockStreamCount;
// 最后一个批次在S3里的起始offset(字节)
private RecordOffset lastRecordOffset;
public boolean put(StreamRecordBatch recordBatch) {
// 尝试释放已经归档的blocks,保证缓存容量90%且blocks数量小于65
tryRealFree();
size.addAndGet(recordBatch.occupiedSize());
readLock.lock();
boolean full;
try {
// 加入缓存
full = activeBlock.put(recordBatch);
} finally {
readLock.unlock();
}
return full;
}
}
public static class LogCacheBlock {
final Map<Long, StreamCache> map = new ConcurrentHashMap<>();
private final AtomicLong size = new AtomicLong();
// true-当前block需要upload,wal->data
public boolean put(StreamRecordBatch recordBatch) {
map.compute(recordBatch.getStreamId(), (id, cache) -> {
if (cache == null) {
cache = new StreamCache();
}
cache.add(recordBatch);
return cache;
});
size.addAndGet(recordBatch.occupiedSize());
return isFull();
}
public boolean isFull() {
// 超出cacheBlockMaxSize 或 maxCacheBlockStreamCount
return size.get() >= maxSize || map.size() >= maxStreamCount;
}
}
static class StreamCache {
List<StreamRecordBatch> records;
long startOffset = NOOP_OFFSET;
long endOffset = NOOP_OFFSET;
Map<Long, IndexAndCount> offsetIndexMap = new HashMap<>();
synchronized void add(StreamRecordBatch recordBatch) {
records.add(recordBatch);
if (startOffset == NOOP_OFFSET) {
startOffset = recordBatch.getBaseOffset();
}
endOffset = recordBatch.getLastOffset();
}
}3-2、写数据对象
activeBlock(LogCacheBlock)包含了多个S3中的wal对象,最终需要将这些wal对象写入data对象,清除wal。
3-2-1、触发时机&主流程
触发路径1,activeBlock满了,S3Storage.handleAppendCallback→S3Storage.uploadDeltaWAL。
java
private void handleAppendCallback(WalWriteRequest request) {
boolean full;
synchronized (deltaWALCache) {
full = deltaWALCache.put(request.record);
deltaWALCache.setLastRecordOffset(request.offset);
}
if (full) {
uploadDeltaWAL();
}
}触发路径2,每隔s3.wal.upload.interval.ms=60000对当前activeBlock触发一次,S3Storage.maybeForceUpload→S3Storage.uploadDeltaWAL。
java
public S3Storage(...) {
if (config.walUploadIntervalMs() > 0) {
this.backgroundExecutor.scheduleWithFixedDelay(this::maybeForceUpload,
config.walUploadIntervalMs(),
config.walUploadIntervalMs(), TimeUnit.MILLISECONDS);
}
}S3Storage.uploadDeltaWAL:wal转data主流程
1)创建新activeBlock用于后续wal缓存写入,老activeBlock需要上传s3;
2)DeltaWALUploadTaskContext-上下文,DefaultUploadWriteAheadLogTask-上传任务;
3)DefaultUploadWriteAheadLogTask上传三步骤:prepare-从controller获取objectId,upload-上传data对象,commit-上传data对象提交元数据到controller;
java
CompletableFuture<Void> uploadDeltaWAL(long streamId, boolean force) {
CompletableFuture<Void> cf;
synchronized (deltaWALCache) {
// 创建新activeBlock,返回老activeBlock
Optional<LogCache.LogCacheBlock> blockOpt = deltaWALCache.archiveCurrentBlockIfContains(streamId);
if (blockOpt.isPresent()) {
LogCache.LogCacheBlock logCacheBlock = blockOpt.get();
DeltaWALUploadTaskContext context = new DeltaWALUploadTaskContext(logCacheBlock);
context.objectManager = this.objectManager;
context.force = force;
cf = uploadDeltaWAL(context);
} else {
cf = CompletableFuture.completedFuture(null);
}
}
return cf;
}
CompletableFuture<Void> uploadDeltaWAL(DeltaWALUploadTaskContext context) {
CompletableFuture<Void> cf = new CompletableFuture<>();
context.cf = cf;
backgroundExecutor.execute(() -> FutureUtil.exec(() -> uploadDeltaWAL0(context), cf, LOGGER, "uploadDeltaWAL"));
return cf;
}
private void uploadDeltaWAL0(DeltaWALUploadTaskContext context) {
context.task = newUploadWriteAheadLogTask(context.cache.records(), objectManager, rate);
// prepare -> upload -> commit
prepareDeltaWALUpload(context);
}
protected UploadWriteAheadLogTask newUploadWriteAheadLogTask(Map<Long, List<StreamRecordBatch>> streamRecordsMap,
ObjectManager objectManager, double rate) {
return DefaultUploadWriteAheadLogTask.builder().config(config).streamRecordsMap(streamRecordsMap)
.objectManager(objectManager).objectStorage(objectStorage).executor(uploadWALExecutor).rate(rate).build();
}
private void prepareDeltaWALUpload(DeltaWALUploadTaskContext context) {
// 1. prepare-从controller获取objectId(自增id)
context.task.prepare().thenAcceptAsync(nil -> {
// 2. upload wal转data 上传s3
DeltaWALUploadTaskContext peek = walPrepareQueue.poll();
Objects.requireNonNull(peek).task.upload();
// 3. commit wal转data 提交到controller
commitDeltaWALUpload(peek);
// 4. 处理下一个任务
DeltaWALUploadTaskContext next = walPrepareQueue.peek();
if (next != null) {
prepareDeltaWALUpload(next);
}
}, backgroundExecutor);
}3-2-2、prepare-获取objectId
DefaultUploadWriteAheadLogTask.prepare:第一步,从controller获取objectId(自增id)
这一步非必须,如果本次WAL里只有一个Stream,将在upload阶段获取objectId。见DefaultUploadWriteAheadLogTask.Builder.build,设置forceSplit。
java
public CompletableFuture<Long> prepare() {
startTimestamp = System.currentTimeMillis();
if (forceSplit) {
prepareCf.complete(NOOP_OBJECT_ID);
} else {
objectManager
// 1代表获取一个id
.prepareObject(1, TimeUnit.MINUTES.toMillis(60))
.thenAcceptAsync(prepareCf::complete, executor)
.exceptionally(ex -> {
prepareCf.completeExceptionally(ex);
return null;
});
}
return prepareCf;
}3-2-3、upload-wal转data写S3
DefaultUploadWriteAheadLogTask.upload0:第二步,把activeBlock中的数据真实写S3的data bucket,构造CommitStreamSetObjectRequest供第三步提交到Controller记录元数据。
java
// streamId -> activeBlock中的StreamRecordBatch
private final Map<Long, List<StreamRecordBatch>> streamRecordsMap;
void upload0(long objectId) {
uploadTimestamp = System.currentTimeMillis();
List<Long> streamIds = new ArrayList<>(streamRecordsMap.keySet());
Collections.sort(streamIds);
CommitStreamSetObjectRequest request = new CommitStreamSetObjectRequest();
ObjectWriter streamSetObject;
if (forceSplit) {
streamSetObject = ObjectWriter.noop(objectId);
} else {
streamSetObject = ObjectWriter.writer(objectId, objectStorage, objectBlockSize, objectPartSize);
}
List<CompletableFuture<Void>> streamObjectCfList = new LinkedList<>();
List<CompletableFuture<Void>> streamSetWriteCfList = new LinkedList<>();
for (Long streamId : streamIds) {
List<StreamRecordBatch> streamRecords = streamRecordsMap.get(streamId);
int streamSize = streamRecords.stream().mapToInt(StreamRecordBatch::size).sum();
if (forceSplit || streamSize >= streamSplitSizeThreshold) {
// forceSplit=true --- 当前上传的LogCacheBlock里只有一个stream
// stream>16MB,1个stream作为StreamObject直接上传,需要获取独立objectId
streamObjectCfList.add(writeStreamObject(streamRecords, streamSize).thenAccept(so -> {
synchronized (request) {
request.addStreamObject(so);
}
}));
} else {
// stream小,每个stream作为一个StreamRange,存储到公共的object
streamSetWriteCfList.add(acquireLimiter(streamSize).thenAccept(nil -> streamSetObject.write(streamId, streamRecords)));
long startOffset = streamRecords.get(0).getBaseOffset();
long endOffset = streamRecords.get(streamRecords.size() - 1).getLastOffset();
request.addStreamRange(new ObjectStreamRange(streamId, -1L, startOffset, endOffset, streamSize));
}
}
request.setObjectId(objectId);
request.setOrderId(objectId);
CompletableFuture<Void> streamSetObjectCf = CompletableFuture.allOf(streamSetWriteCfList.toArray(new CompletableFuture[0]))
// close触发公共object上传
.thenCompose(nil -> streamSetObject.close().thenAccept(nil2 -> {
request.setObjectSize(streamSetObject.size());
request.setAttributes(ObjectAttributes.builder().bucket(streamSetObject.bucketId()).build().attributes());
}));
List<CompletableFuture<?>> allCf = new LinkedList<>(streamObjectCfList);
allCf.add(streamSetObjectCf);
CompletableFuture.allOf(allCf.toArray(new CompletableFuture[0])).thenAccept(nil -> {
commitStreamSetObjectRequest = request;
uploadCf.complete(request);
}).exceptionally(ex -> {
uploadCf.completeExceptionally(ex);
return null;
});
}如果activeBlock中只有一个stream或者单个stream较大(超过16MB),1个Stream对应1个S3对象,每个对象称为StreamObject,都要从Controller获取唯一objectId。
java
public class StreamObject {
private long objectId;
private long objectSize;
private long streamId;
// log-消息偏移量 索引-字节偏移量
private long startOffset;
private long endOffset;
private int attributes = ObjectAttributes.UNSET.attributes();
}如果stream较小,合并到一个S3对象称为StreamSetObject ,这个对象的objectId在prepare阶段获取,每个stream对应一段ObjectStreamRange。
java
public class ObjectStreamRange {
private long streamId;
private long epoch; // -1
// log-消息偏移量 索引-字节偏移量
private long startOffset;
private long endOffset;
private int size;
}后续第三步使用CommitStreamSetObjectRequest提交到Controller存储元数据。
java
public class CommitStreamSetObjectRequest {
// n个ObjectStreamRange合并到一个s3对象,StreamSetObject对象的id
private long objectId;
// compact相关,这里就是objectId
private long orderId;
// StreamSetObject下streamRanges整体字节大小
private long objectSize;
// StreamSetObject下n个小stream的区间
private List<ObjectStreamRange> streamRanges;
// n个大stream 对应n个 S3大对象StreamObject
private List<StreamObject> streamObjects;
// compact相关
private List<Long> compactedObjectIds;
private int attributes = ObjectAttributes.UNSET.attributes();
}S3对象的key={reverseHex(objectId)}/kafka{clusterId}/{objectId},其中reverseHex=8位十六进制并反转。如clusterId=123,objectId=42,key=a2000000/_kafka_123/42
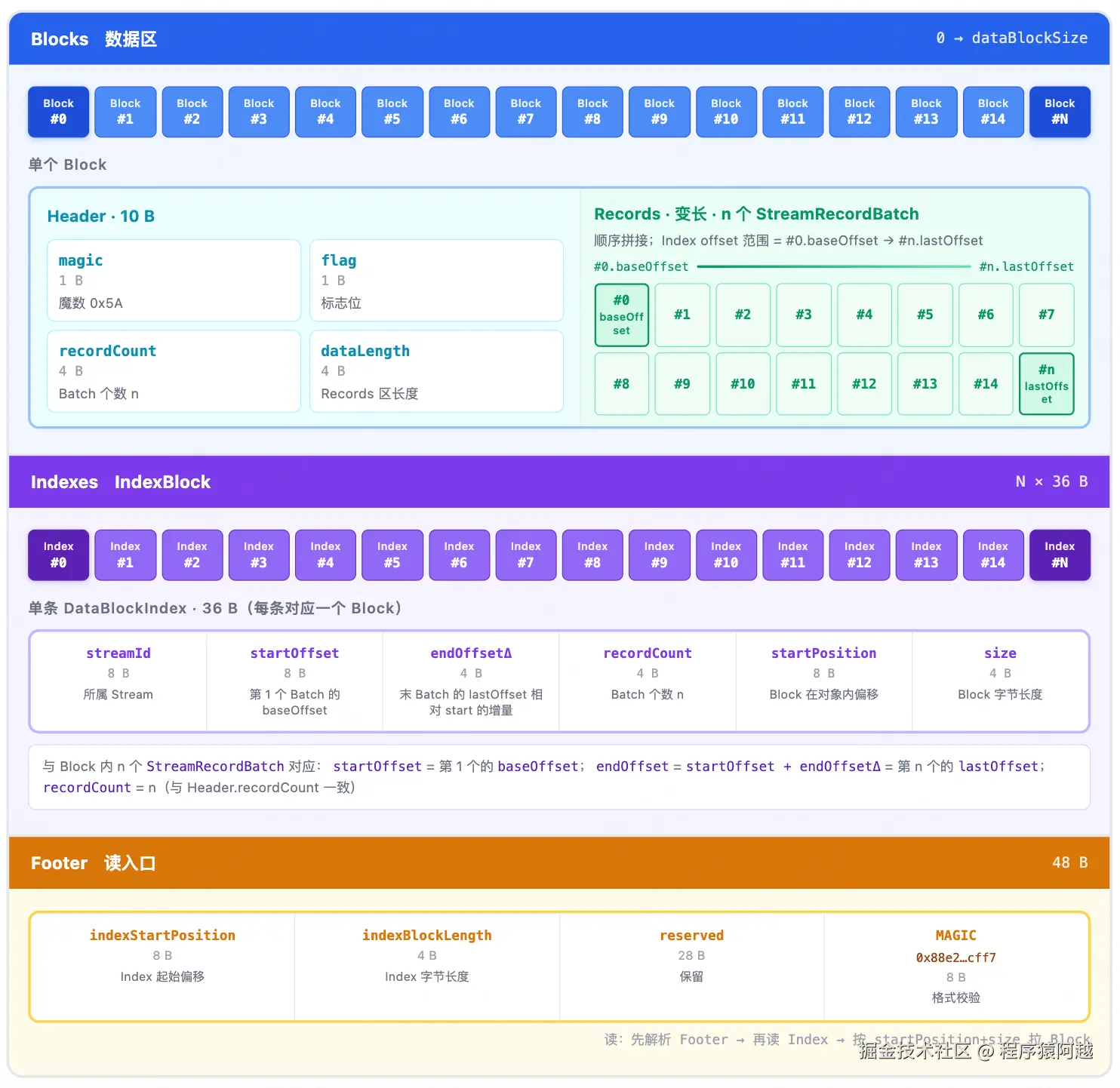
ObjectWriter.DefaultObjectWriter.close:无论多个小Stream合并为一个大对象,还是每个大Stream一个对象,S3数据对象布局都如下
1)数据按照Blocks→Indexes→Footer写入,读取则相反;
2)Block存放真实数据。一个Stream可分布在多个 Block中,但一个 Block只属于一个 Stream。单 Stream内按StreamRecordBatch顺序累加字节大小,累计≥512KB切分为一个Block;
3-2-4、commit-提交元数据到Controller
假设3个stream,2个小stream进StreamSetObject,1 个大stream独立StreamObject。
Controller侧生成5条Record,并更新内存:
1)S3ObjectRecord:2条,对应S3Object;
java
public class S3ObjectControlManager {
private final TimelineHashMap<Long/*objectId*/, S3Object> objectsMetadata;
}
public class S3Object implements Comparable<S3Object> {
private final long objectId;
private long objectSize = -1;
private long timestamp;
// COMMITTED
private S3ObjectState s3ObjectState = S3ObjectState.UNINITIALIZED;
private int attributes;
}2)S3StreamEndOffsetsRecord:1条,更新3个StreamRuntimeMetadata的endOffset;
3)S3StreamSetObjectRecord:1条,对应S3StreamSetObject;
4)S3StreamObjectRecord:1条,对应S3StreamObject;
java
public class StreamControlManager {
// streamId -> Stream元数据
private final TimelineHashMap<Long/*streamId*/, StreamRuntimeMetadata> streamsMetadata;
// nodeId -> Node元数据
private final TimelineHashMap<Integer/*nodeId*/, NodeRuntimeMetadata> nodesMetadata;
}
public class StreamRuntimeMetadata {
private final long streamId;
// leaderEpoch
private final TimelineLong currentEpoch;
// rangeIndex生成器
private final TimelineInteger currentRangeIndex;
// 起始offset
private final TimelineLong startOffset;
// 结束offset
private final TimelineLong endOffset;
// CLOSE or OPEN
private final TimelineObject<StreamState> currentState;
// tags
private Map<String, String> tags;
// rangeIndex->segment元数据
private final TimelineHashMap<Integer/*rangeIndex*/, RangeMetadata> ranges;
// objectId -> streamId+startOffset+endOffset
private final TimelineHashMap<Long/*objectId*/, S3StreamObject> streamObjects;
public class S3StreamObject {
private final long objectId;
private final long streamId;
private final long startOffset;
private final long endOffset;
}
}
public class NodeRuntimeMetadata {
private final int nodeId;
private final TimelineLong nodeEpoch;
private final TimelineObject<Boolean> failoverMode;
private final TimelineHashMap<Long/*objectId*/, S3StreamSetObject> streamSetObjects;
public class S3StreamSetObject implements Comparable<S3StreamSetObject> {
private final long objectId;
private final int nodeId;
private final long orderId;
private final long dataTimeInMs;
}
}S3Storage.commitDeltaWALUpload:回到Broker侧
1)删除S3上的wal对象;2)可以尝试释放wal对应LogCache
java
private void commitDeltaWALUpload(DeltaWALUploadTaskContext context) {
context.task.commit().thenAcceptAsync(nil -> {
// 已经转为data,删除wal
delayTrim.trim(context.cache.lastRecordOffset(), context.trimCf);
// 尝试释放LogCache
freeCache(context.cache);
}, backgroundExecutor)
}LogCache.markFree:尝试释放LogCache
1)tryRealFree:刚才wal虽然已经转换为data放入S3,但是为了加速读,wal对应LogCacheBlock不会立即从内存移除。只有LogCache缓存到达90%,或blocks列表超过64,才会触发内存回收;
2)tryMerge:此外,因为wal有序,可以尝试合并多个LogCacheBlock,加速后续缓存读取;
java
final List<LogCacheBlock> blocks = new ArrayList<>();
// LogCache缓存容量(字节)
// Math.max(堆内存/2/3, (堆内存/2 - 3L * 1024 * 1024 * 1024) / 3 * 2)
private final long capacity;
// 当前缓存(字节)
private final AtomicLong size = new AtomicLong();
// blocks长度64
private final long cacheBlockMaxSize;
public CompletableFuture<Void> markFree(LogCacheBlock block) {
block.free = true;
// 如果LogCache超过90%容量 或 blocks数量超过64 实际释放blocks占用内存
tryRealFree();
CompletableFuture<Void> cf = new CompletableFuture<>();
LOG_CACHE_ASYNC_EXECUTOR.execute(() -> {
try {
// 合并连续blocks,加速后续缓存读取
tryMerge();
cf.complete(null);
} catch (Throwable t) {
cf.completeExceptionally(t);
}
});
return cf;
}四、读
4-1、主流程
ElasticReplicaManager.fetchMessages:读消息入口
1)第一次标记fast-read,只读内存LogCache(WAL),fastFetchExecutor采用4线程处理热读;
2)如果fast-read失败,走LogCache→BlockCache→S3,slowFetchExecutor采用12线程处理冷读;
如果每次都走S3,Fetch线程会被 S3 IO 拖住;fast-read用独立小线程池,保证热读不被冷读阻塞。
scala
override def fetchMessages(params: FetchParams,
fetchInfos: Seq[(TopicIdPartition, FetchRequest.PartitionData)],
quota: ReplicaQuota,
responseCallback: Seq[(TopicIdPartition, FetchPartitionData)] => Unit): Unit = {
fastFetchExecutor.submit(new Runnable {
override def run(): Unit = {
try {
ReadHint.markReadAll()
// 1. 第一次标记fast-read
ReadHint.markFastRead()
fetchMessages0(params, fetchInfos, quota, fastFetchLimiter, 0, responseCallback)
ReadHint.clear()
} catch {
case e: Throwable =>
val ex = FutureUtil.cause(e)
// 2. 如果第一次抛出FastReadFailFastException异常,走slow-read
val fastReadFailFast = ex.isInstanceOf[FastReadFailFastException]
if (fastReadFailFast) {
val timer = Time.SYSTEM.timer(params.maxWaitMs)
slowFetchExecutor.submit(new Runnable {
override def run(): Unit = {
try {
ReadHint.markReadAll()
fetchMessages0(params, fetchInfos, quota, slowFetchLimiter, timer.remainingMs(), responseCallback)
} catch {
case slowEx: Throwable =>
handleError(slowEx)
}
}
})
}
}
}
})
}S3Storage.read0:startOffset=客户端fetchOffset,endOffset=高水位=confirmOffset=wal写入进度。
java
// 1级缓存 WAL
private final LogCache deltaWALCache;
// 2级缓存 持有s3
protected final S3BlockCache blockCache;
private CompletableFuture<ReadDataBlock> read0(FetchContext context,
@SpanAttribute long streamId,
@SpanAttribute long startOffset,
@SpanAttribute long endOffset,
@SpanAttribute int maxBytes) { // 读多少字节
LogCache firstCache = deltaWALCache;
// LogCache只取右连续
List<StreamRecordBatch> logCacheRecords = firstCache.get(context, streamId, startOffset, endOffset, maxBytes);
if (!logCacheRecords.isEmpty() && logCacheRecords.get(0).getBaseOffset() <= startOffset) {
// case1-完全命中LogCache,直接返回
return CompletableFuture.completedFuture(new ReadDataBlock(logCacheRecords, CacheAccessType.DELTA_WAL_CACHE_HIT));
}
if (context.readOptions().fastRead()) {
releaseRecords(logCacheRecords);
logCacheRecords.clear();
// case2-未完全命中LogCache,但fastRead,直接异常
return CompletableFuture.failedFuture(FAST_READ_FAIL_FAST_EXCEPTION);
}
if (!logCacheRecords.isEmpty()) {
endOffset = logCacheRecords.get(0).getBaseOffset();
}
long finalEndOffset = endOffset;
// case3-未完全命中LogCache,非fastRead,走S3BlockCache
CompletableFuture<ReadDataBlock> cf = blockCache.read(context, streamId, startOffset, endOffset, maxBytes).thenApply(blockCacheRst -> {
// S3BlockCache记录
List<StreamRecordBatch> rst = new ArrayList<>(blockCacheRst.getRecords());
// 合并 S3BlockCache记录 + LogCache右连续
int remainingBytesSize = maxBytes - rst.stream().mapToInt(StreamRecordBatch::size).sum();
int readIndex = -1;
for (int i = 0; i < logCacheRecords.size()
&& remainingBytesSize > 0; i++) {
readIndex = i;
StreamRecordBatch record = logCacheRecords.get(i);
rst.add(record);
remainingBytesSize -= record.size();
}
if (readIndex < logCacheRecords.size()) {
releaseRecords(logCacheRecords.subList(readIndex + 1, logCacheRecords.size()));
}
return new ReadDataBlock(rst, blockCacheRst.getCacheAccessType());
})
return FutureUtil.timeoutWithNewReturn(cf, 2, TimeUnit.MINUTES, () -> {
cf.thenAccept(readDataBlock -> {
releaseRecords(readDataBlock.getRecords());
});
});
}4-2、读LogCache
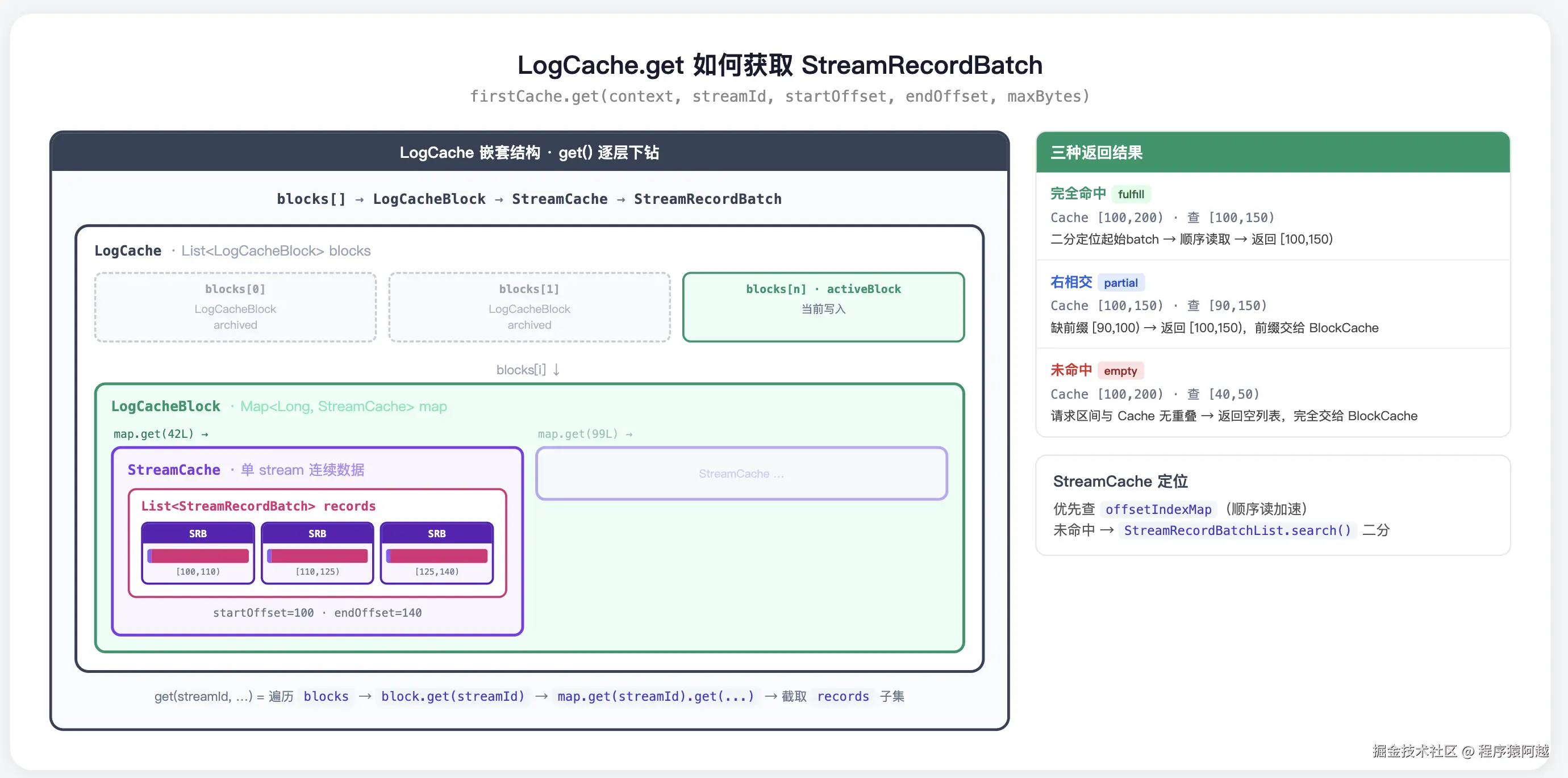
LogCache.get:
从头到尾(WAL写入顺序即从老到新)遍历n个LogCacheBlock,每个LogCacheBlock中都可能有streamId对应的n个StreamRecordBatch。
java
public class LogCache {
// 缓存,包含activeBlock
final List<LogCacheBlock> blocks = new ArrayList<>();
private LogCacheBlock activeBlock;
public List<StreamRecordBatch> get0(Long streamId, long startOffset, long endOffset, int maxBytes) {
List<LogCacheBlock> blocks = this.blocks;
for (LogCacheBlock archiveBlock : blocks) {
List<StreamRecordBatch> records = archiveBlock.get(streamId, nextStartOffset, endOffset, nextMaxBytes);
}
}
public static class LogCacheBlock {
final Map<Long, StreamCache> map = new ConcurrentHashMap<>();
public List<StreamRecordBatch> get(Long streamId, long startOffset, long endOffset, int maxBytes) {
StreamCache cache = map.get(streamId);
if (cache == null) {
return Collections.emptyList();
}
return cache.get(startOffset, endOffset, maxBytes);
}
}
}LogCache.StreamCache.get:
在每个LogCacheBlock中,对StreamRecordBatch列表使用request.startOffset二分查找起始StreamRecordBatch,读取直到到达request.endOffset。
此外,由于消费一般是顺序读,offsetIndexMap缓存上次从StreamRecordBatchs读到的下标,顺序读可以降低复杂度到O(1)。
java
// LogCache.StreamCache.java
List<StreamRecordBatch> records;
long startOffset = NOOP_OFFSET;
long endOffset = NOOP_OFFSET;
Map<Long, IndexAndCount> offsetIndexMap = new HashMap<>();
synchronized List<StreamRecordBatch> get(long startOffset, long endOffset, int maxBytes) {
// startOffset不在StreamCache的范围内,直接返回
if (this.startOffset > startOffset || this.endOffset <= startOffset) {
return Collections.emptyList();
}
// 二分查找 or 命中offsetIndexMap
int startIndex = searchStartIndex(startOffset);
if (startIndex < 0) {
// mismatched
return Collections.emptyList();
}
int endIndex = -1;
int remainingBytesSize = maxBytes;
long rstEndOffset = NOOP_OFFSET;
for (int i = startIndex; i < records.size(); i++) {
StreamRecordBatch record = records.get(i);
endIndex = i + 1;
remainingBytesSize -= Math.min(remainingBytesSize, record.size());
rstEndOffset = record.getLastOffset();
if (record.getLastOffset() >= endOffset || remainingBytesSize == 0) {
break;
}
}
// 如果顺序读取,缓存下一个offset在records中的下标到offsetIndexMap
// 在searchStartIndex中可以快速定位,避免二分
if (rstEndOffset != NOOP_OFFSET) {
map(rstEndOffset, endIndex);
}
return new ArrayList<>(records.subList(startIndex, endIndex));
}
int searchStartIndex(long startOffset) {
IndexAndCount indexAndCount = offsetIndexMap.get(startOffset);
if (indexAndCount != null) {
// 顺序读优化,直接定位records下标
unmap(startOffset, indexAndCount);
return indexAndCount.index;
} else {
// 对records二分查找
StreamRecordBatchList search = new StreamRecordBatchList(records);
return search.search(startOffset);
}
}
final void map(long offset, int index) {
offsetIndexMap.compute(offset, (k, v) -> {
if (v == null) {
return new IndexAndCount(index);
} else {
v.inc();
return v;
}
});
}
final void unmap(long startOffset, IndexAndCount indexAndCount) {
if (indexAndCount.dec() == 0) {
offsetIndexMap.remove(startOffset);
}
}
static class IndexAndCount {
// 在records中的下标
int index;
// 引用次数
int count;
public IndexAndCount(int index) {
this.index = index;
this.count = 1;
}
}4-3、读BlockCache
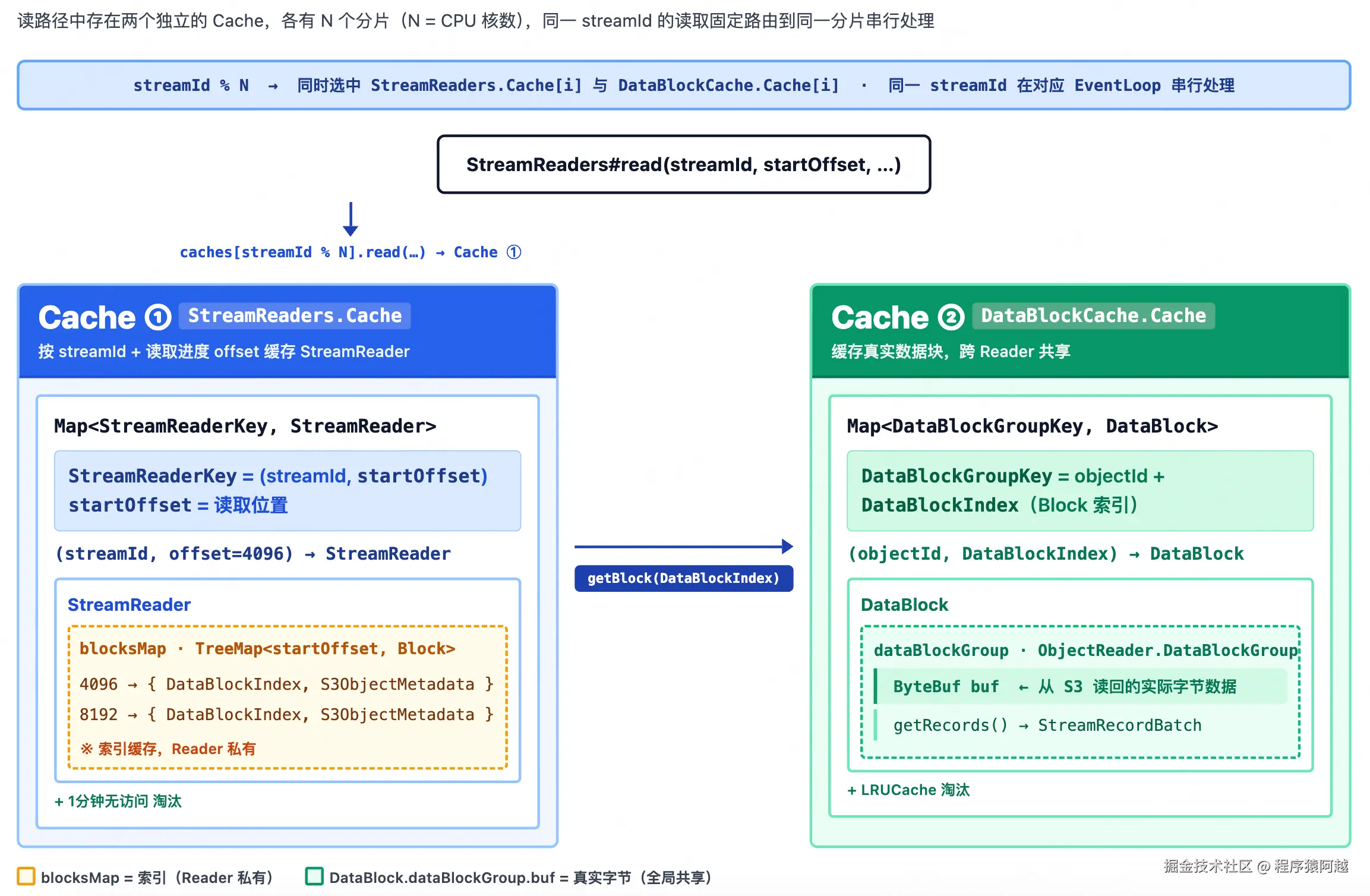
BlockCache的实现是StreamReaders。
StreamReaders.read:读请求会根据streamId分发到固定的EventLoop线程处理,EventLoop线程数=核数。
java
public class StreamReaders implements S3BlockCache {
// 会话级-数据索引缓存
private final Cache[] caches;
// 数据缓存
private final DataBlockCache dataBlockCache;
public StreamReaders(...) {
// concurrency=核数
EventLoop[] eventLoops = new EventLoop[concurrency];
for (int i = 0; i < concurrency; i++) {
eventLoops[i] = new EventLoop("stream-reader-" + i);
}
// 会话级-数据索引缓存
this.caches = new Cache[concurrency];
for (int i = 0; i < concurrency; i++) {
caches[i] = new Cache(eventLoops[i]);
}
// 全局-Block数据缓存
this.dataBlockCache = new DataBlockCache(size, eventLoops);
// 每分钟清理1分钟没访问的StreamReaders.Cache
Threads.COMMON_SCHEDULER.scheduleAtFixedRate(
this::triggerExpiredStreamReaderCleanup,
STREAM_READER_EXPIRED_CHECK_INTERVAL_MILLS,
STREAM_READER_EXPIRED_CHECK_INTERVAL_MILLS,
TimeUnit.MILLISECONDS);
}
class Cache {
private final EventLoop eventLoop;
private final Map<StreamReaderKey, StreamReader> streamReaders;
}
public CompletableFuture<ReadDataBlock> read(TraceContext context, long streamId, long startOffset, long endOffset,
int maxBytes) {
Cache cache = caches[Math.abs((int) (streamId % caches.length))];
return cache.read(streamId, startOffset, endOffset, maxBytes);
}
}4-3-1、StreamReader-会话级数据索引缓存
StreamReaders.Cache.read:以streamId+读取offset维度创建StreamReader,后续顺序读会复用同一个StreamReader。
java
public class StreamReaders implements S3BlockCache {
// 会话级-数据索引缓存
private final Cache[] caches;
// 全局-数据缓存
private final DataBlockCache dataBlockCache;
public CompletableFuture<ReadDataBlock> read(TraceContext context, long streamId, long startOffset, long endOffset,
int maxBytes) {
Cache cache = caches[Math.abs((int) (streamId % caches.length))];
return cache.read(streamId, startOffset, endOffset, maxBytes);
}
static class StreamReaderKey {
final long streamId;
final long startOffset;
}
class Cache {
private final EventLoop eventLoop;
private final Map<StreamReaderKey, StreamReader> streamReaders;
public CompletableFuture<ReadDataBlock> read(long streamId, long startOffset,
long endOffset, int maxBytes) {
CompletableFuture<ReadDataBlock> cf = new CompletableFuture<>();
eventLoop.execute(() -> {
// 清理streamReaders1分钟没使用的StreamReader
cleanupExpiredStreamReader();
// 如果是顺序读 streamReaders会有缓存上次的StreamReader
StreamReaderKey key = new StreamReaderKey(streamId, startOffset);
StreamReader streamReader = streamReaders.remove(key);
if (streamReader == null) {
// 非顺序读/过期/新读 创建StreamReader
streamReader = new StreamReader(...);
}
StreamReader finalStreamReader = streamReader;
// 读
CompletableFuture<ReadDataBlock> streamReadCf = streamReader.read(startOffset, endOffset, maxBytes)
.whenComplete((rst, ex) -> {
if (ex != null) {
finalStreamReader.close();
} else {
// 缓存StreamReader,用于下次顺序读
StreamReader oldStreamReader = streamReaders.put(
new StreamReaderKey(streamId, finalStreamReader.nextReadOffset()), finalStreamReader);
if (oldStreamReader != null) {
oldStreamReader.close();
}
}
});
FutureUtil.propagate(streamReadCf, cf);
});
return cf;
}
}
}StreamReader缓存的是,某个会话(streamId+读取offset)的索引和元数据,即blocksMap。通过这个缓存,下次顺序访问可以避免重复查询元数据和Block索引。
java
public class StreamReader {
// key=DataBlockIndex.startOffset value=元数据+索引
final NavigableMap<Long, Block> blocksMap = new TreeMap<>();
// 全局-Block数据缓存
private final DataBlockCache dataBlockCache;
// 下次读取的offset
long nextReadOffset;
// 上次访问时间
private long lastAccessTimestamp;
// 缓存项
class Block {
// 元数据
final S3ObjectMetadata metadata;
// 索引(见3-2-3对象布局)
final DataBlockIndex index;
// 临时变量,从BlockCache拿来的实际data数据
DataBlock data;
}
}
public class S3ObjectMetadata {
private final long objectId;
private final List<StreamOffsetRange> offsetRanges;
private long objectSize;
}
public class StreamOffsetRange implements Comparable<StreamOffsetRange> {
private final long streamId;
private final long startOffset;
private final long endOffset;
}
public final class DataBlockIndex {
private final int blockId;
private final long streamId;
private final long startOffset;
private final int endOffsetDelta;
private final int recordCount;
private final long startPosition;
private final int size;
}StreamReader.getBlocks0:Cache-Aside,读缓存 → miss → 读S3数据对象里的索引 → 写回缓存。
ini
// 索引项startOffset -> 缓存(索引+S3对象元数据)
final NavigableMap<Long, Block> blocksMap = new TreeMap<>();
// blocksMap最后一个索引的endOffset
long loadedBlockIndexEndOffset = 0L;
private void getBlocks0(GetBlocksContext ctx, long startOffset, long endOffset, int maxBytes) {
Long floorKey = blocksMap.floorKey(startOffset);
CompletableFuture<Boolean> loadMoreBlocksCf;
int remainingSize = maxBytes;
if (floorKey == null || startOffset >= loadedBlockIndexEndOffset) {
// 请求范围超出缓存范围,缓存miss,加载数据到缓存
loadMoreBlocksCf = loadMoreBlocksWithoutData(endOffset);
} else {
// 缓存命中,循环索引
boolean firstBlock = true;
boolean fulfill = false;
for (Map.Entry<Long, Block> entry : blocksMap.tailMap(floorKey).entrySet()) {
Block block = entry.getValue();
long objectId = block.metadata.objectId();
DataBlockIndex index = block.index;
if (!firstBlock || index.startOffset() == startOffset) {
remainingSize -= index.size();
}
if (firstBlock) {
firstBlock = false;
}
// 根据索引查询数据到Block,加入结果集
block = block.newBlockWithData(ctx.readahead);
ctx.blocks.add(block);
if ((endOffset != -1L && index.endOffset() >= endOffset)
|| remainingSize <= 0) {
// 索引的结束offset 超过 请求的endOffset 读完了
fulfill = true;
break;
}
}
if (fulfill) {
// 读完了,可以返回
ctx.cf.complete(ctx.blocks);
return;
} else {
// 没读完,继续加载索引到内存
loadMoreBlocksCf = loadMoreBlocksWithoutData(endOffset);
}
}
int finalRemainingSize = remainingSize;
// 递归调用自己,直到满足fulfill条件
loadMoreBlocksCf.thenAcceptAsync(moreBlocks -> {
// ...
getBlocks0(ctx, nextStartOffset, endOffset, finalRemainingSize);
}, eventLoop);
}
public Block newBlockWithData(boolean readahead) {
Block newBlock = new Block(metadata, index);
ObjectReader objectReader = objectReaderFactory.get(metadata);
DataBlockCache.GetOptions getOptions = DataBlockCache.GetOptions.builder().readahead(readahead).build();
// 全局数据缓存,根据索引查数据
loadCf = dataBlockCache.getBlock(getOptions, objectReader, index).thenAccept(newData -> {
newBlock.data = newData;
}).exceptionally(ex -> {
exception = ex;
newBlock.exception = ex;
return null;
}).whenComplete((nil, ex) -> objectReader.release());
newBlock.loadCf = loadCf;
return newBlock;
}StreamReader.loadMoreBlocksWithoutData0:blocksMap缓存未命中
1)根据streamId+offset范围,找到S3对象元数据;
2)根据objectId+offset范围,获取相关DataBlockIndex索引,对应上面写数据对象,BlockIndexes区域;
java
// 读取offset -> BlockIndex索引+S3对象元数据
final NavigableMap<Long, Block> blocksMap = new TreeMap<>();
private CompletableFuture<Void> loadMoreBlocksWithoutData0(long endOffset) {
if (inflightLoadIndexCf != null) {
// 如果已经在加载,等上次处理完再处理这次的
return inflightLoadIndexCf.thenCompose(rst -> loadMoreBlocksWithoutData0(endOffset));
}
long currentBlocksEpoch = blocksEpoch;
inflightLoadIndexCf = new CompletableFuture<>();
long nextLoadingOffset = calWindowBlocksEndOffset();
AtomicLong nextFindStartOffset = new AtomicLong(nextLoadingOffset);
TimerUtil time = new TimerUtil();
// 1. 查询streamId在offset范围内的S3对象
CompletableFuture<List<S3ObjectMetadata>> getObjectsCf = objectManager.getObjects(streamId, nextLoadingOffset, endOffset, GET_OBJECT_STEP);
// 2. 循环S3对象,找BlockIndex
CompletableFuture<Void> findBlockIndexesCf = getObjectsCf.whenComplete((rst, ex) -> {
StorageOperationStats.getInstance().getIndicesTimeGetObjectStats.record(time.elapsedAndResetAs(TimeUnit.NANOSECONDS));
}).thenComposeAsync(objects -> {
CompletableFuture<Void> prevCf = CompletableFuture.completedFuture(null);
for (S3ObjectMetadata objectMetadata : objects) {
ObjectReader objectReader = objectReaderFactory.get(objectMetadata);
objectReader.basicObjectInfo();
prevCf = prevCf.thenCompose(nil -> {
return objectReader.find(streamId, nextFindStartOffset.get(), -1L, Integer.MAX_VALUE).thenAcceptAsync(findRst -> {
findRst.streamDataBlocks().forEach(streamDataBlock -> {
DataBlockIndex index = streamDataBlock.dataBlockIndex();
Block block = new Block(objectMetadata, index);
// S3对象元数据 + BlockIndex 放到 Block 缓存
if (!putBlock(block)) {
throw new BlockNotContinuousException();
}
nextFindStartOffset.set(streamDataBlock.getEndOffset());
});
}, eventLoop);
}).whenComplete((nil, ex) -> objectReader.release());
}
return prevCf;
}, eventLoop);
}
private boolean putBlock(Block block) {
// ...Block索引连续性校验
lastBlock = block;
blocksMap.put(block.index.startOffset(), block);
loadedBlockIndexEndOffset = block.index.endOffset();
return true;
}
S3StreamsMetadataImage.getObjects0:根据streamId+offset范围,获取S3对象元数据
1)StreamObject,1个stream-1个object,streamId→S3StreamObject,直接拿到结果;
2)StreamSetObject,n个stream-1个object,streamId→Range元数据(segments)-nodeId→Node元数据-objectId→S3对象索引块→相关offset区间;
java
public final class S3StreamsMetadataImage {
// streamId->stream元数据
private final TimelineHashMap<Long, S3StreamMetadataImage> streamMetadataMap;
// nodeId->Node元数据
private final TimelineHashMap<Integer, NodeS3StreamSetObjectMetadataImage> nodeMetadataMap;
}
public class S3StreamMetadataImage {
// segments offset区间->归属nodeId
private final List<RangeMetadata> ranges;
public class RangeMetadata implements Comparable<RangeMetadata> {
private long startOffset;
private long endOffset;
private int nodeId;
}
// SO 一个stream一个s3对象 直接定位
final DeltaList<S3StreamObject> streamObjects;
public class S3StreamObject {
private final long objectId;
private final long streamId;
private final long startOffset;
private final long endOffset;
}
}
public class NodeS3StreamSetObjectMetadataImage {
// SSO n个stream一个s3对象
private final DeltaList<S3StreamSetObject> s3Objects;
public class S3StreamSetObject implements Comparable<S3StreamSetObject> {
private final long objectId;
}
}ObjectReader.DefaultObjectReader.basicObjectInfo:S3 range读对象的Footer和Index区域,获取DataBlockIndex索引。ObjectReader有objectId纬度缓存,对于StreamSetObject,getObjects0已经读到Index了,不会重复调用S3。
S3StreamObject不能像StreamObject一样,直接获取S3对象元数据。需要通过扫描nodeIds(NodeS3StreamSetObjectMetadataImage)→objectIds(S3StreamObject)→S3对象索引块→streamId和offset相关索引块。
为了避免每次遍历所有Node元数据里的S3StreamSetObject,找streamId对应的S3对象索引块,这里还有3个缓存索引。
索引查询入口为S3StreamsMetadataImage.getStartSearchIndex0,入参是nodeId和offset,出参是offset在这个节点元数据的S3StreamSetObject集合中的下标,这样只要从指定位置开始扫描即可。
java
private CompletableFuture<Integer> getStartSearchIndex0(
NodeS3StreamSetObjectMetadataImage node, long startOffset,
GetObjectsContext ctx) {
}NodeS3StreamSetObjectMetadataImage:node元数据LRU缓存offsetIndexMap,用于顺序读。streamId→offset→S3StreamSetObject集合下标,读流程中会缓存endOffset到这里,下次顺序读可以用到。
java
public class NodeS3StreamSetObjectMetadataImage {
private final DeltaList<S3StreamSetObject> s3Objects;
private final StreamOffsetIndexMap offsetIndexMap;
// streamId -> offset -> s3Objects的下标
// private final Map<Long, NavigableMap<Long, Integer>> streamOffsetIndexMap;
}LocalStreamRangeIndexCache:稀疏索引存储(startOffset,endOffset,objectId)。如果nodeId=当前节点,才能走这个缓存,通过offset二分定位objectId。
缓存写入时机:1)当前节点写S3数据对象提交到Controller后写入,定时写入S3,key=hash(sparse-index-{nodeId})/kafka{clusterId}/node-{nodeId};2)启动后重新加载到内存;
java
public class LocalStreamRangeIndexCache {
// streamId->(startOffset,endOffset,objectId)
private final Map<Long, SparseRangeIndex> streamRangeIndexMap = new HashMap<>();
}
public class SparseRangeIndex {
private List<RangeIndex> sortedRangeIndexList;
}
public class RangeIndex {
private final long startOffset;
private final long endOffset;
private final long objectId;
}NodeRangeIndexCache:如果nodeId≠当前节点,读流程中从S3加载其他节点的索引(key=hash(sparse-index-{nodeId})/kafka{clusterId}/node-{nodeId},nodeId等于请求匹配到的nodeId),也是通过offset二分定位objectId。
java
public class NodeRangeIndexCache {
private final ExpireLRUCache nodeRangeIndexMap =
new ExpireLRUCache(MAX_CACHE_SIZE, DEFAULT_EXPIRE_TIME_MS);
static class ExpireLRUCache extends AsyncLRUCache<Long, StreamRangeIndexCache> {
}
static class StreamRangeIndexCache implements AsyncMeasurable {
// streamId->(startOffset,endOffset,objectId)
private final CompletableFuture<Map<Long, List<RangeIndex>>> streamRangeIndexMapCf;
private CompletableFuture<Integer> sizeCf;
}
}4-3-2、DataBlockCache-真实数据缓存
StreamReader.Block.newBlockWithData:上面获取到S3元数据和Block索引,获取真实Block数据。
java
private final DataBlockCache dataBlockCache;
class Block {
final S3ObjectMetadata metadata;
final DataBlockIndex index;
CompletableFuture<Void> loadCf;
DataBlock data;
public Block newBlockWithData(boolean readahead) {
Block newBlock = new Block(metadata, index);
ObjectReader objectReader = objectReaderFactory.get(metadata);
DataBlockCache.GetOptions getOptions = DataBlockCache.GetOptions.builder().readahead(readahead).build();
loadCf = dataBlockCache.getBlock(getOptions, objectReader, index).thenAccept(newData -> {
newBlock.data = newData;
});
newBlock.loadCf = loadCf;
return newBlock;
}
}DataBlockCache.getBlock:每个Block索引的数据缓存在DataBlockCache.Cache.blocks中,cache miss触发读S3。这里已经拿到了DataBlockIndex索引,所以直接发起rangeRead即可。
java
public class DataBlockCache {
final Cache[] caches;
public CompletableFuture<DataBlock> getBlock(GetOptions options,
ObjectReader objectReader,
DataBlockIndex dataBlockIndex) {
Cache cache = cache(dataBlockIndex.streamId());
return cache.getBlock(options, objectReader, dataBlockIndex);
}
private Cache cache(long streamId) {
return caches[(int) Math.abs(streamId % caches.length)];
}
class Cache {
// (objectId,blockIndex) -> block数据块
final Map<DataBlockGroupKey, DataBlock> blocks = new HashMap<>();
final LRUCache<DataBlockGroupKey, DataBlock> lru = new LRUCache<>();
private CompletableFuture<DataBlock> getBlock0(GetOptions options, ObjectReader objectReader,
DataBlockIndex dataBlockIndex) {
long objectId = objectReader.metadata().objectId();
DataBlockGroupKey key = new DataBlockGroupKey(objectId, dataBlockIndex);
DataBlock dataBlock = blocks.get(key);
if (dataBlock == null) {
// 索引对应block缓存没命中
DataBlock newDataBlock = new DataBlock(objectId, dataBlockIndex, this, time);
dataBlock = newDataBlock;
blocks.put(key, newDataBlock);
// 读S3
read(options, objectReader, newDataBlock, eventLoop);
}
lru.touchIfExist(key);
}
}
}
public class DataBlock extends AbstractReferenceCounted {
private final long objectId;
private final DataBlockIndex dataBlockIndex;
// 数据缓存
private ObjectReader.DataBlockGroup dataBlockGroup;
}
class DataBlockGroup implements AutoCloseable {
// 数据缓存
private final ByteBuf buf;
// StreamRecordBatch个数
private final int recordCount;
}
// DefaultObjectReader#read
public CompletableFuture<DataBlockGroup> read(ReadOptions readOptions,
DataBlockIndex block) {
CompletableFuture<ByteBuf> rangeReadCf = objectStorage.rangeRead(
new ObjectStorage.ReadOptions()
.throttleStrategy(readOptions.throttleStrategy).bucket(metadata.bucket()),
metadata.key(),
block.startPosition(),
block.endPosition()
);
return rangeReadCf.thenApply(buf -> {
ByteBuf pooled = ByteBufAlloc.byteBuffer(buf.readableBytes(), BLOCK_CACHE);
pooled.writeBytes(buf);
buf.release();
return new DataBlockGroup(pooled);
});
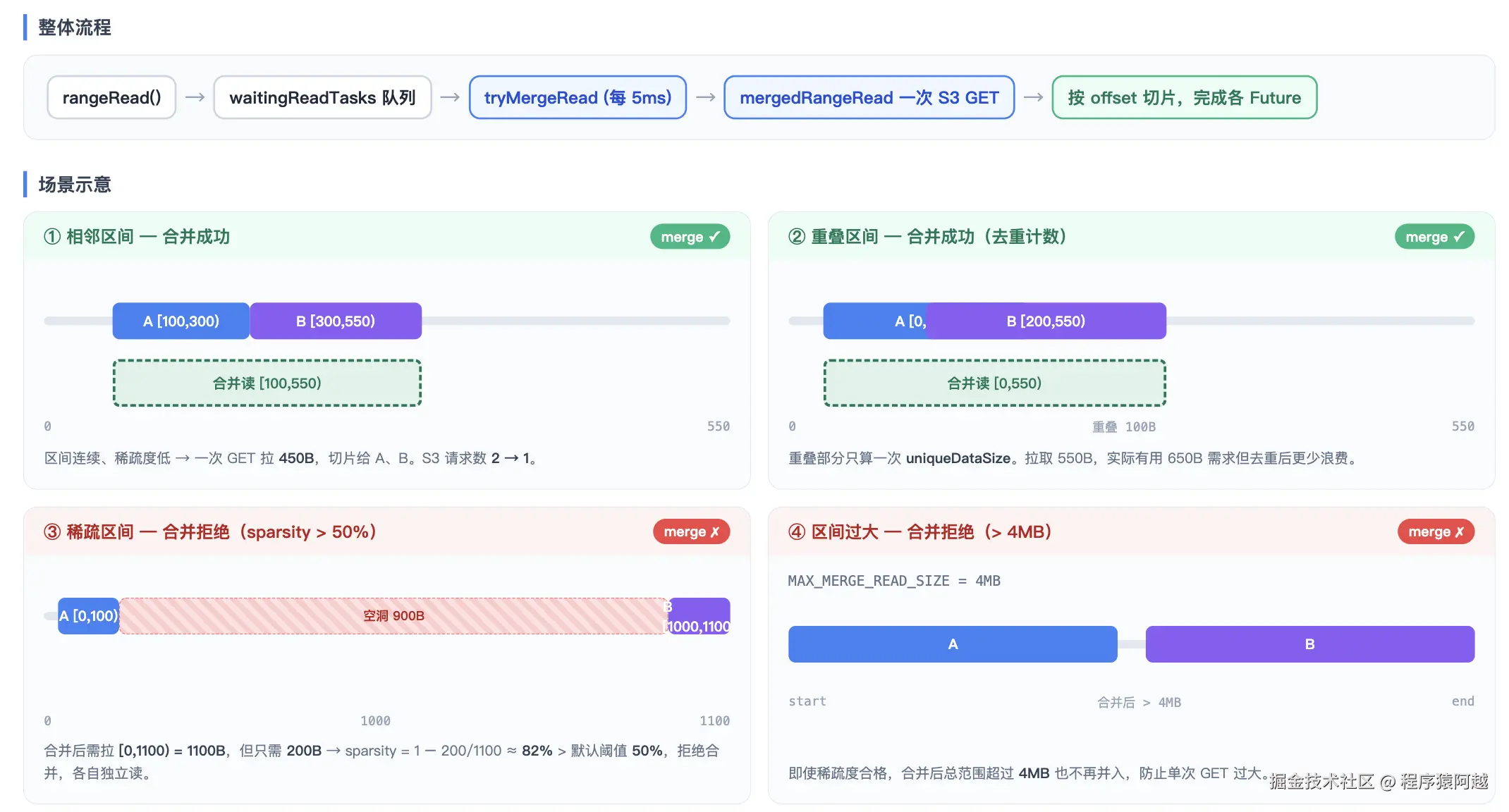
}AbstractObjectStorage.rangeRead:5ms一次合并读。
java
private final List<AbstractObjectStorage.ReadTask> waitingReadTasks = new LinkedList<>();
protected AbstractObjectStorage(...)
if (!manualMergeRead) {
scheduler.scheduleWithFixedDelay(this::tryMergeRead, 5, 5, TimeUnit.MILLISECONDS);
}
}
public CompletableFuture<ByteBuf> rangeRead(ReadOptions options, String objectPath, long start, long end) {
CompletableFuture<ByteBuf> cf = new CompletableFuture<>();
synchronized (waitingReadTasks) {
waitingReadTasks.add(
new AbstractObjectStorage.ReadTask(options, objectPath, start, end, cf));
}
// ...
}合并读:同一 object path 的多个小 range read 合并成一次请求,减少 S3 GET 次数。 读回整块数据后,按各子任务的 [start, end) 切片分发。
五、Compaction
5-1、概述
AutoMQ 将日志数据持久化到 S3,WAL flush 后产生两类对象:
1)Stream Set Object (SSO) :一个 S3 对象包含多个 stream 的数据,由多 stream 批量上传产生,元数据挂在上传的Node上。
2)Stream Object (SO) :一个 S3 对象只服务单个 stream,大 stream(>16MB)单独上传时产生。
随着时间推移,SSO / SO 数量过多 导致 元数据膨胀、读放大。 Compaction 是后台异步任务,负责 合并小对象、拆分过大对象、清理过期数据。
CompactionManager.start:对于SSO,CompactionManager 每5分钟做一次compaction,元数据通过CommitStreamSetObjectRequest提交到Controller。
java
public void start() {
scheduleNextCompaction((long) this.compactionInterval * 60 * 1000);
}
void scheduleNextCompaction(long delayMillis) {
this.compactionScheduledExecutor.schedule(() -> {
this.compact().join();
scheduleNextCompaction(nextDelay);
}, delayMillis, TimeUnit.MILLISECONDS);
}S3StreamClient.startStreamObjectsCompactions:对于SO,S3StreamClient对开启的Stream每分钟做compaction,元数据通过CommitStreamObjectRequest提交到Controller。
java
private void startStreamObjectsCompactions() {
streamObjectCompactionScheduler.scheduleWithFixedDelay(() -> {
// 集群中s3数据对象总数
CompactionHint hint = new CompactionHint(objectManager.getObjectsCount().get());
List<StreamWrapper> operationStreams = new ArrayList<>(openedStreams.values());
operationStreams.forEach(s -> s.compact(hint));
}, compactionJitterDelay, 1, TimeUnit.MINUTES);
}5-2、StreamSetObject Compaction
SSO的compaction主流程:
scss
CompactionManager.start()
→ scheduleNextCompaction() // 定时调度,默认 5 分钟
→ compact()
→ objectManager.getServerObjects() // 读 本broker 所有 SSO 元数据
→ updateStreamDataBlockMap() // 读 S3数据对象的 blockIndex
→ streamManager.getStreams() // 读 stream元数据
→ compact(streamMetadataList, objectMetadataList)
├── forceSplitObjects() // 强制拆分
└── compactObjects() // 压缩CompactionManager.compact:将SSO分为两组
1)120分钟以前的SSO,forceSplitObjects,N 个 SSO 强制拆分 → N个SO;
2)最近的SSO,compactObjects,N 个 SSO 压缩 → 1个 SSO + N 个 SO;
java
private void compact(List<StreamMetadata> streamMetadataList,
List<S3ObjectMetadata> objectMetadataList) throws CompletionException {
Map<Boolean, List<S3ObjectMetadata>> objectMetadataFilterMap = convertS3Objects(objectMetadataList);
List<S3ObjectMetadata> objectsToForceSplit = objectMetadataFilterMap.get(true);
List<S3ObjectMetadata> objectsToCompact = objectMetadataFilterMap.get(false);
if (!objectsToForceSplit.isEmpty()) {
forceSplitObjects(streamMetadataList, objectsToForceSplit);
}
compactObjects(streamMetadataList, objectsToCompact);
}
Map<Boolean, List<S3ObjectMetadata>> convertS3Objects(List<S3ObjectMetadata> streamSetObjectMetadata) {
return new HashMap<>(streamSetObjectMetadata.stream()
.collect(Collectors.partitioningBy(e ->
(System.currentTimeMillis() - e.dataTimeInMs())
>= TimeUnit.MINUTES.toMillis(this.forceSplitObjectPeriod))));
}forceSplitObjects强制拆分:
1)CompactionManager.forceSplitObjects:循环SSO,将每个S3对象切分为SO,发送CommitStreamSetObjectRequest提交。
2)CompactionManager.groupAndSplitStreamDataBlocks:在不超过200MB内存占用的情况下,尽量并行处理,将SSO中同stream的连续offset的blocks合并写入S3成为1个SO。
compactObjects压缩:
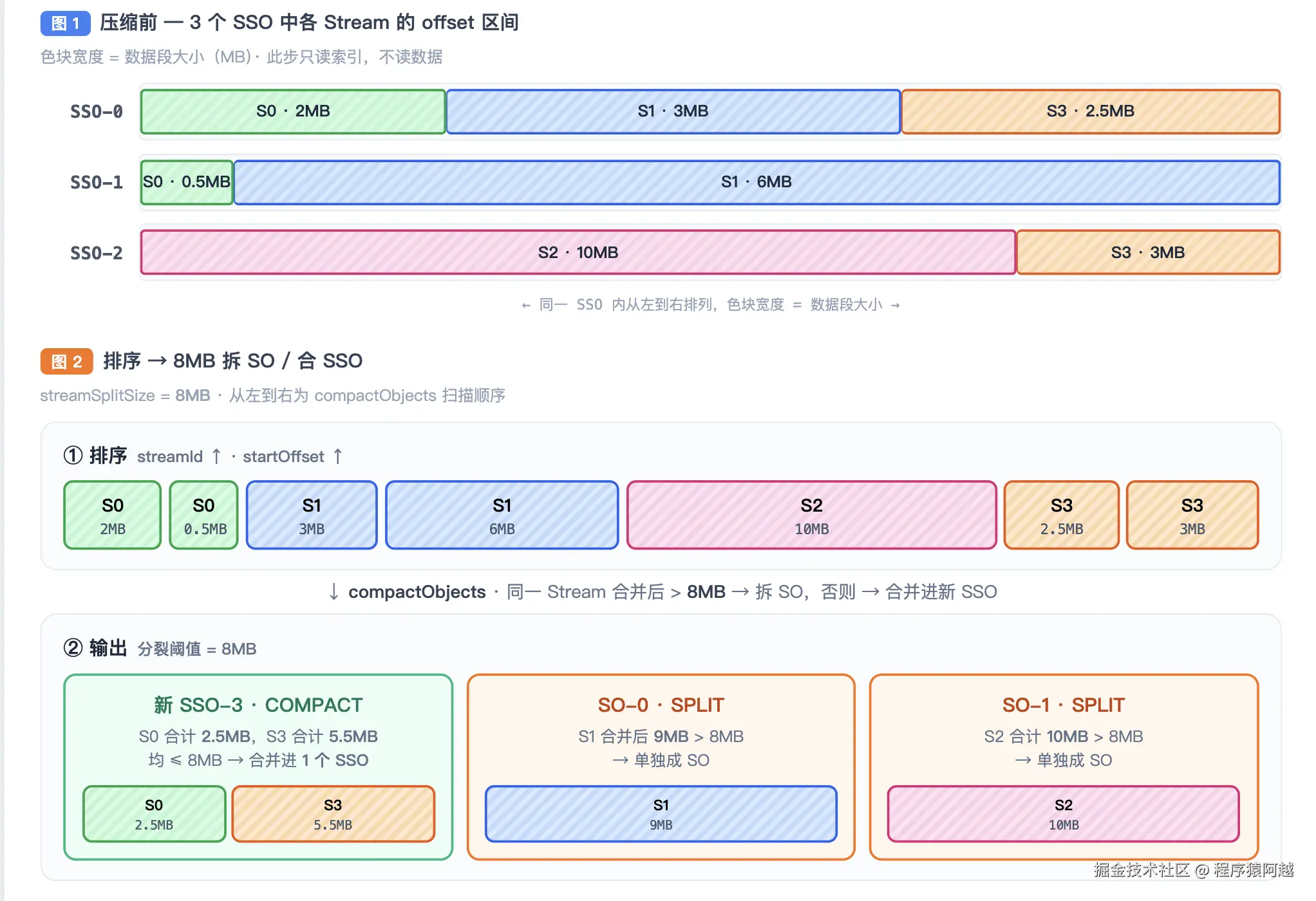
1)CompactionAnalyzer.analyze:入参=SSO的objectId和对应的BlockIndex集合,生成N个CompactionPlan,每个Plan是一轮S3读写,保证内存占用不超过200MB。
即使SSO超过200MB,使用S3的Multi-Part API可以分片上传,保证内存占用不超过200MB。
java
// streamDataBlockMap key = objectId value = [{objectId,DataBlockIndex(streamId)}]
public List<CompactionPlan> analyze(Map<Long, List<StreamDataBlock>> streamDataBlockMap,
Set<Long> excludedObjectIds) {
// 过滤出streamId 至少存在于 两个object 中的这部分 object
streamDataBlockMap = filterBlocksToCompact(streamDataBlockMap);
if (streamDataBlockMap.isEmpty()) {
return Collections.emptyList();
}
// 分为两类CompactedObjectBuilder SPLIT-拆分为SO COMPACT-合并为一个SSO
List<CompactedObjectBuilder> compactedObjectBuilders = groupObjectWithLimits(streamDataBlockMap, excludedObjectIds);
// 按照200MB内存限制,分为N个Plan执行
return generatePlanWithCacheLimit(compactedObjectBuilders);
}CompactionAnalyzer.groupObjectWithLimits:
- SSO索引按照streamId-startOffset排序,顺序处理;
- 最终结果要求,SSO中stream数量 ≤ 2w 个,SO ≤ 1w 个;
- compactObjects压缩算法,相同 stream 超过 8MB 拆分为SO,其他合并为SSO;
java
public class CompactedObjectBuilder {
private final List<StreamDataBlock> streamDataBlocks;
// SPLIT-代表拆分为SO COMPACT-代表合并为一个SSO
private CompactionType type;
}
// streamDataBlockMap key = objectId value = [{objectId,DataBlockIndex(streamId)}]
List<CompactedObjectBuilder> groupObjectWithLimits(Map<Long, List<StreamDataBlock>> streamDataBlockMap,
Set<Long> excludedObjectIds) {
// 按照streamId-startOffset排序
List<StreamDataBlock> sortedStreamDataBlocks = CompactionUtils.sortStreamRangePositions(streamDataBlockMap);
List<CompactedObjectBuilder> compactedObjectBuilders = new ArrayList<>();
CompactionStats stats = null;
int streamNumInStreamSet = -1;
int streamObjectNum = -1;
do {
final Set<Long> objectsToRemove = new HashSet<>();
if (stats != null) {
// 为了满足循环条件,剔除对象不参与本次compaction
if (streamObjectNum > maxStreamObjectNum) {
addObjectsToRemove(CompactionType.SPLIT, compactedObjectBuilders, stats, objectsToRemove);
} else {
addObjectsToRemove(CompactionType.COMPACT, compactedObjectBuilders, stats, objectsToRemove);
}
}
if (!objectsToRemove.isEmpty()) {
excludedObjectIds.addAll(objectsToRemove);
}
sortedStreamDataBlocks.removeIf(e -> objectsToRemove.contains(e.getObjectId()));
objectsToRemove.forEach(streamDataBlockMap::remove);
// 压缩算法
compactedObjectBuilders = compactObjects(sortedStreamDataBlocks);
// 计算SSO中stream数量和SO数量
stats = CompactionStats.of(compactedObjectBuilders);
streamNumInStreamSet = stats.getStreamRecord().streamNumInStreamSet();
streamObjectNum = stats.getStreamRecord().streamObjectNum();
}
// SSO包含<=2w个stream & SO<=1w个
while (streamNumInStreamSet > maxStreamNumInStreamSet || streamObjectNum > maxStreamObjectNum);
return compactedObjectBuilders;
}2)CompactionManager.executeCompactionPlans:循环Plan读写S3,构造CommitStreamSetObjectRequest
java
void executeCompactionPlans(CommitStreamSetObjectRequest request,
List<CompactionPlan> compactionPlans,
List<S3ObjectMetadata> s3ObjectMetadata)
throws CompletionException {
for (int i = 0; i < compactionPlans.size(); i++) {
// S3读写...
// SO
streamObjectCfList.stream().map(CompletableFuture::join)
.forEach(request::addStreamObject);
}
// SSO
objectStreamRanges.forEach(request::addStreamRange);
request.setObjectId(uploader.getStreamSetObjectId());
request.setOrderId(s3ObjectMetadata.get(0).objectId());
request.setObjectSize(uploader.complete());
request.setAttributes(ObjectAttributes.builder().bucket(uploader.bucketId()).build().attributes());
}5-3、StreamObject Compaction
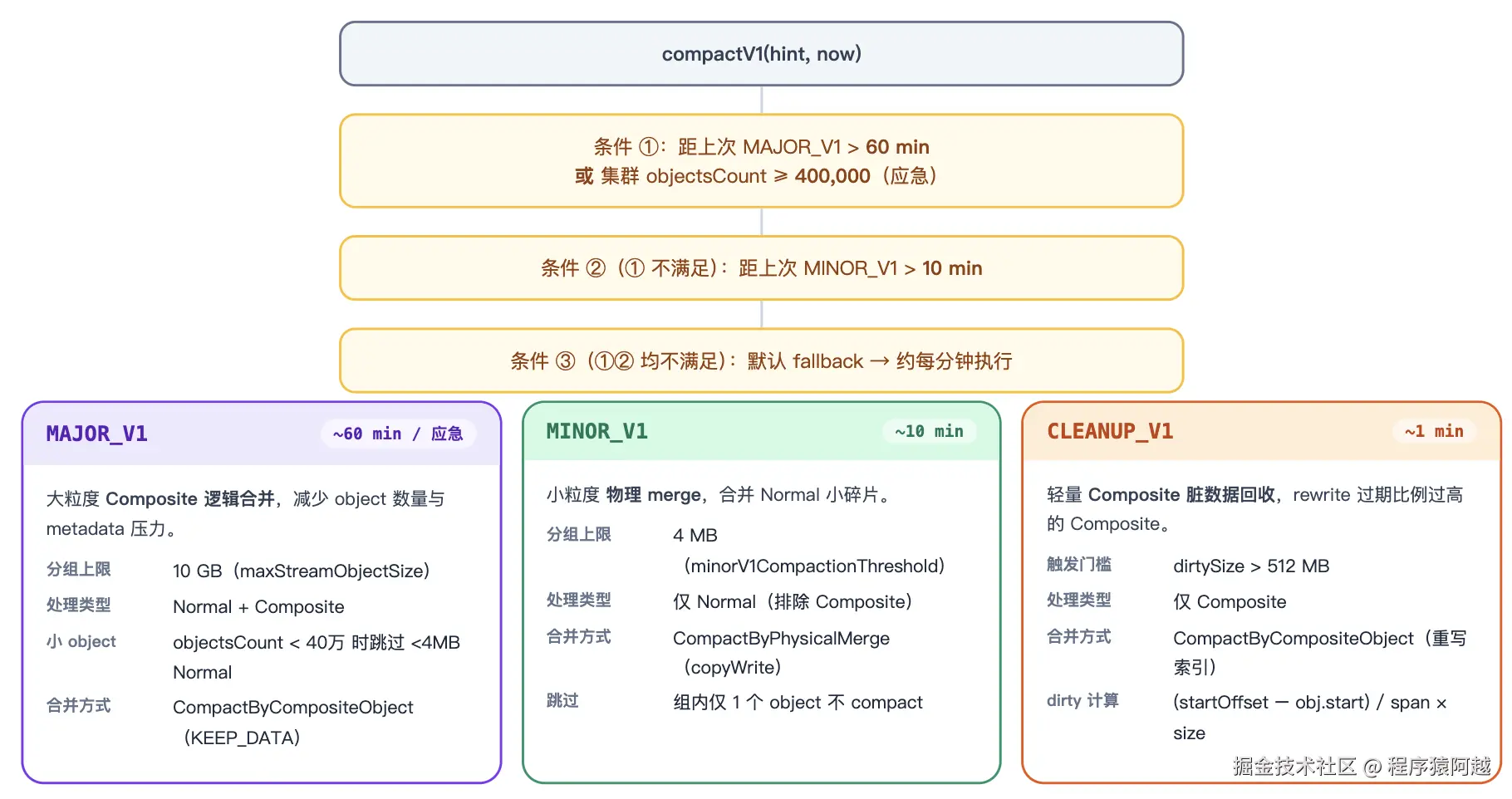
S3StreamClient.StreamWrapper.compactV1:针对每个打开的Stream处理,分为三种类型。无论那种类型
1)根据streamId获取所有SO;
2)cleanupExpiredObject:清理小于startOffset的SO;(如log.retention导致segment删除)
3)group0:根据S3对象元数据,按照大小分组;
4)compact:CompactByPhysicalMerge/CompactByCompositeObject 处理 Compaction;
5)objectManager.compactStreamObject:发送CommitStreamObjectRequest,Controller持久化元数据;
java
private void compactV1(CompactionHint hint, long now) {
if (now - lastMajorV1CompactionTimestamp > MAJOR_V1_COMPACTION_INTERVAL
|| hint.objectsCount >= MAJOR_V1_COMPACTION_MAX_OBJECT_THRESHOLD) {
// 60分钟 or 40w object
compact(MAJOR_V1, hint);
lastMajorV1CompactionTimestamp = System.currentTimeMillis();
} else if (now - lastMinorV1CompactionTimestamp > MINOR_V1_COMPACTION_INTERVAL) {
// 10分钟
compact(MINOR_V1, hint);
lastMinorV1CompactionTimestamp = System.currentTimeMillis();
} else {
// 1分钟(定时调度间隔)
compact(CLEANUP_V1, hint);
}
}
// compact主流程
void compact0(CompactionType compactionType) {
long streamId = stream.streamId();
long startOffset = stream.startOffset();
// 获取stream下所有SO
List<S3ObjectMetadata> objects = objectManager.getStreamObjects(stream.streamId(), 0L, stream.confirmOffset(), Integer.MAX_VALUE).get();
List<S3ObjectMetadata> expiredObjects = new ArrayList<>(objects.size());
List<S3ObjectMetadata> livingObjects = new ArrayList<>(objects.size());
for (S3ObjectMetadata object : objects) {
if (object.endOffset() <= startOffset) {
expiredObjects.add(object);
} else {
livingObjects.add(object);
}
}
// 清理小于startOffset的SO,因为retention,有些数据已经删除
cleanupExpiredObject(expiredObjects);
// 根据类型 将 S3对象分组
List<List<S3ObjectMetadata>> objectGroups = group0(livingObjects,
getMaxGroupSize(compactionType),
getObjectFilter(compactionType, majorV1CompactionSkipSmallObject ? minorV1CompactionThreshold : 0));
for (List<S3ObjectMetadata> objectGroup : objectGroups) {
// 部分场景的group不需要处理
if (!checkObjectGroupCouldBeCompact(objectGroup, startOffset, compactionType)) {
continue;
}
long objectId = objectManager.prepareObject(1, TimeUnit.MINUTES.toMillis(60)).get();
Optional<CompactStreamObjectRequest> requestOpt;
if (MINOR_V1.equals(compactionType)) {
// 小合并 内存 - NormalObject
requestOpt = new CompactByPhysicalMerge(...).compact();
} else {
// 大合并 索引 - CompositeObject
requestOpt = new CompactByCompositeObject(streamId, stream.streamEpoch(), startOffset, objectGroup,
objectId, objectStorage).compact();
}
request = requestOpt.get();
objectManager.compactStreamObject(request).get();
}
}5-3-1、Major Compaction
StreamObjectCompactor.CompactByCompositeObject.compact:
Major Compaction ,处理 4MB以上Nornal对象 和 Composite对象,合并不超过10G。
如果集群中超过40W个对象,也会处理4MB以下Normal对象。一个分区3个Stream,最少3个SO,对应3个对象,即集群规模到达10W分区。
Nornal对象 ,即 正常写流程 和 SSO Compaction 生成的对象,包括Blocks、Indexes、Footer三个区域,其中每个Block包含了n个StreamRecordBatch(真实数据)。

Composite对象,由Major Compaction生成,其实是2级索引,不包含StreamRecordBatch真实数据。
1)Blocks区域:只包含n个LinkBlock,指向Normal对象;
2)Indexes区域:保留最原始的Normal对象的索引数据;
3)Footer区域:魔数与Normal对象区分;
老Composite对象会被合并到新Composite对象中,不会存在Composite指向Composite的情况。
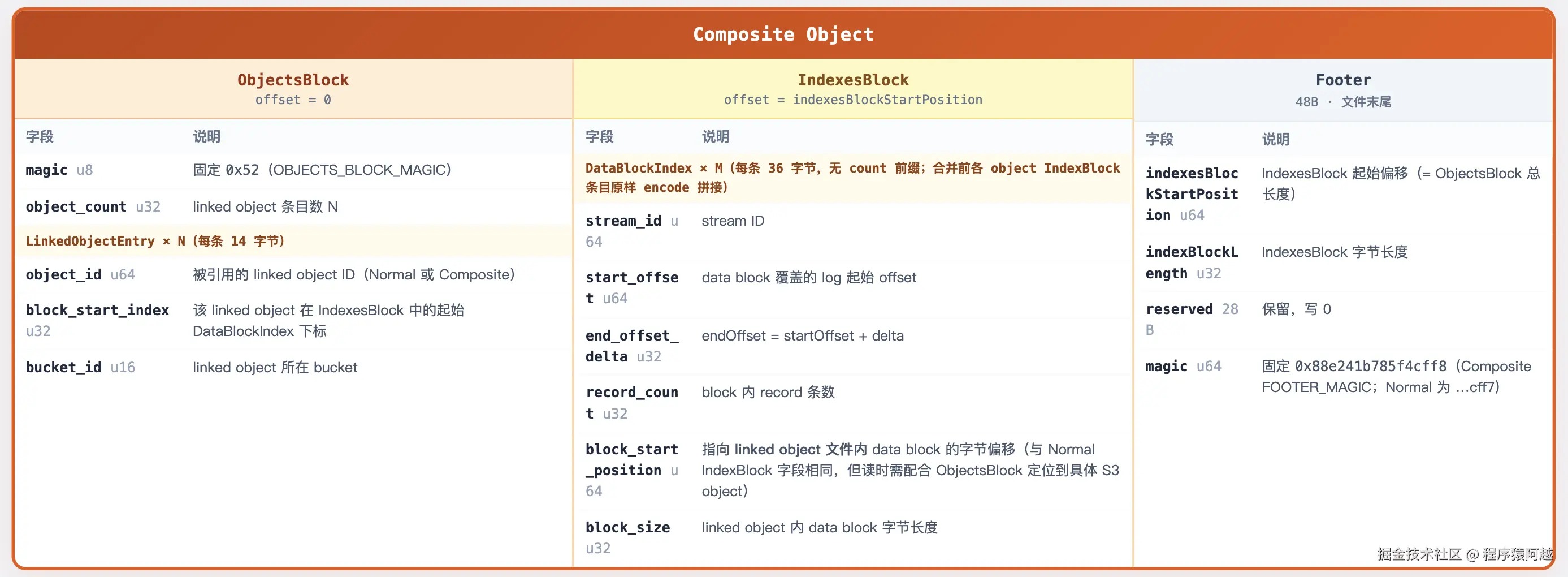
5-3-2、Minor Compaction
StreamObjectCompactor.CompactByPhysicalMerge.compact:
Minor Compaction 处理 4MB以下 对象,合并也不超过4MB,需要在内存中处理合并为大对象,删除老对象。

5-3-3、Cleanup Compaction
Cleanup是为了处理Composite Object指向的 Normal Object因为已经被过期删除,需要重新压缩Composite Object,Compaction 逻辑 和 Major Compaction一致。
StreamObjectCompactor.checkObjectGroupCouldBeCompact:只是Cleanup要求分组中首个对象必须是Composite对象,且指向的对象有512MB数据已经被删除。
java
static boolean checkObjectGroupCouldBeCompact(List<S3ObjectMetadata> objectGroup,
long startOffset,
CompactionType compactionType) {
if (objectGroup.size() == 1 &&
// Minor和Major,如果按照大小分区,只有一个对象,不做compaction
SKIP_COMPACTION_TYPE_WHEN_ONE_OBJECT_IN_GROUP.contains(compactionType)) {
return false;
}
if (CLEANUP_V1.equals(compactionType)) {
// 首个对象是composite
S3ObjectMetadata metadata = objectGroup.get(0);
if (ObjectAttributes.from(metadata.attributes()).type() != Composite) {
return false;
}
// 估算dirtySize = 删除range / 总range * 对象总大小 > 512MB
double dirtySize = ((double) startOffset - metadata.startOffset())
/ (metadata.endOffset() - metadata.startOffset())
* metadata.objectSize();
return dirtySize > MAX_DIRTY_BYTES;
}
return true;
}总结
AutoMQ中:
1)Stream :一个分区Log对应4个Stream,分别是:元数据 、数据log 、时间索引 、事务索引;
2)StreamSlice:一个Segment里的一个文件对应一个StreamSlice,只有最新的Slice可以写入(sealed=false),比如最新的Segment有3个StreamSlice可以写入,分别对应数据log、时间索引、事务索引;
写路径
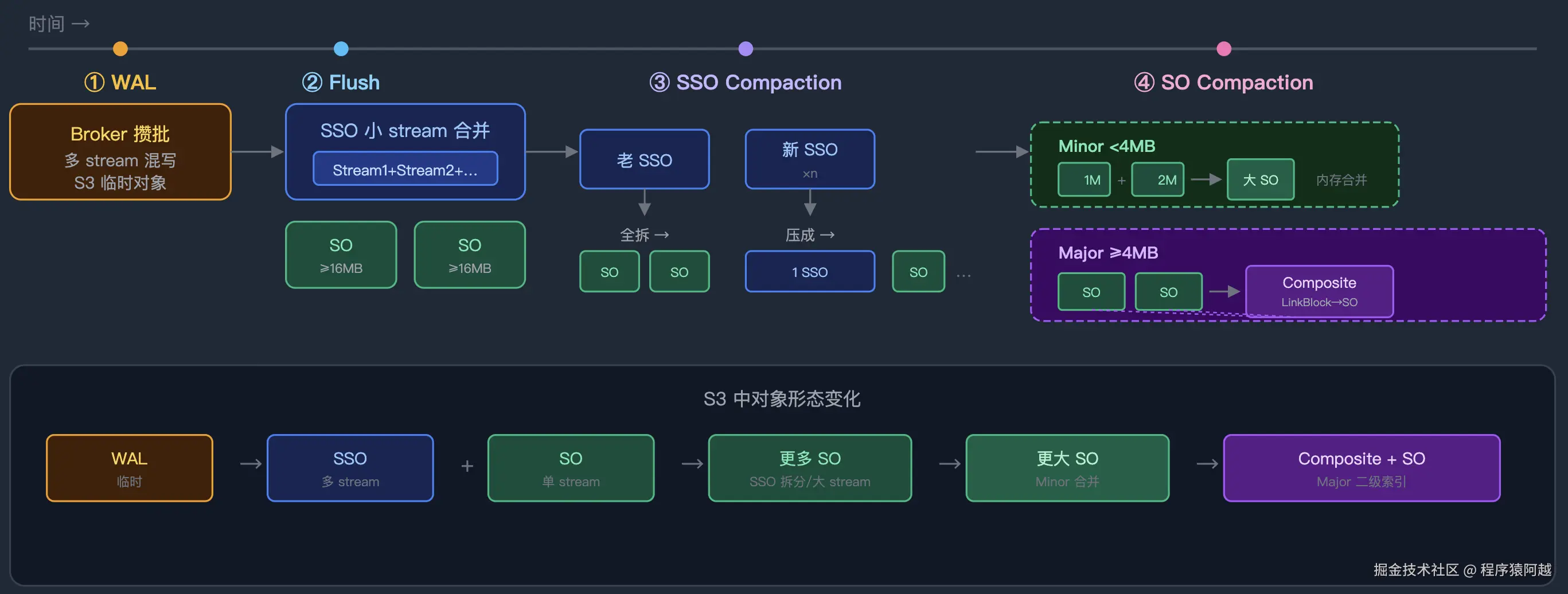
1)Producer发送消息,Broker写WAL(S3),推进HW和confirmOffset,响应Producer,缓存WAL到LogCache以备热读;
2)LogCache满或定时60s,将WAL转换为1个StreamSetObject(SSO)+n个StreamObject(SO),上传S3;
3)定时执行SSO Compaction:循环当前节点的SSO
- 老SSO:120min以前,拆分为stream独立SO;
- 新SSO:大于8MB的stream独立SO,其余压缩一个SSO;
4)定时执行SO Compaction:循环开启的Stream处理
- Minor:小于4MB的SO,内存合并,生成大SO;
- Major:大于4MB的SO,生成Composite格式Object(二级索引)指向原始Object;
读路径
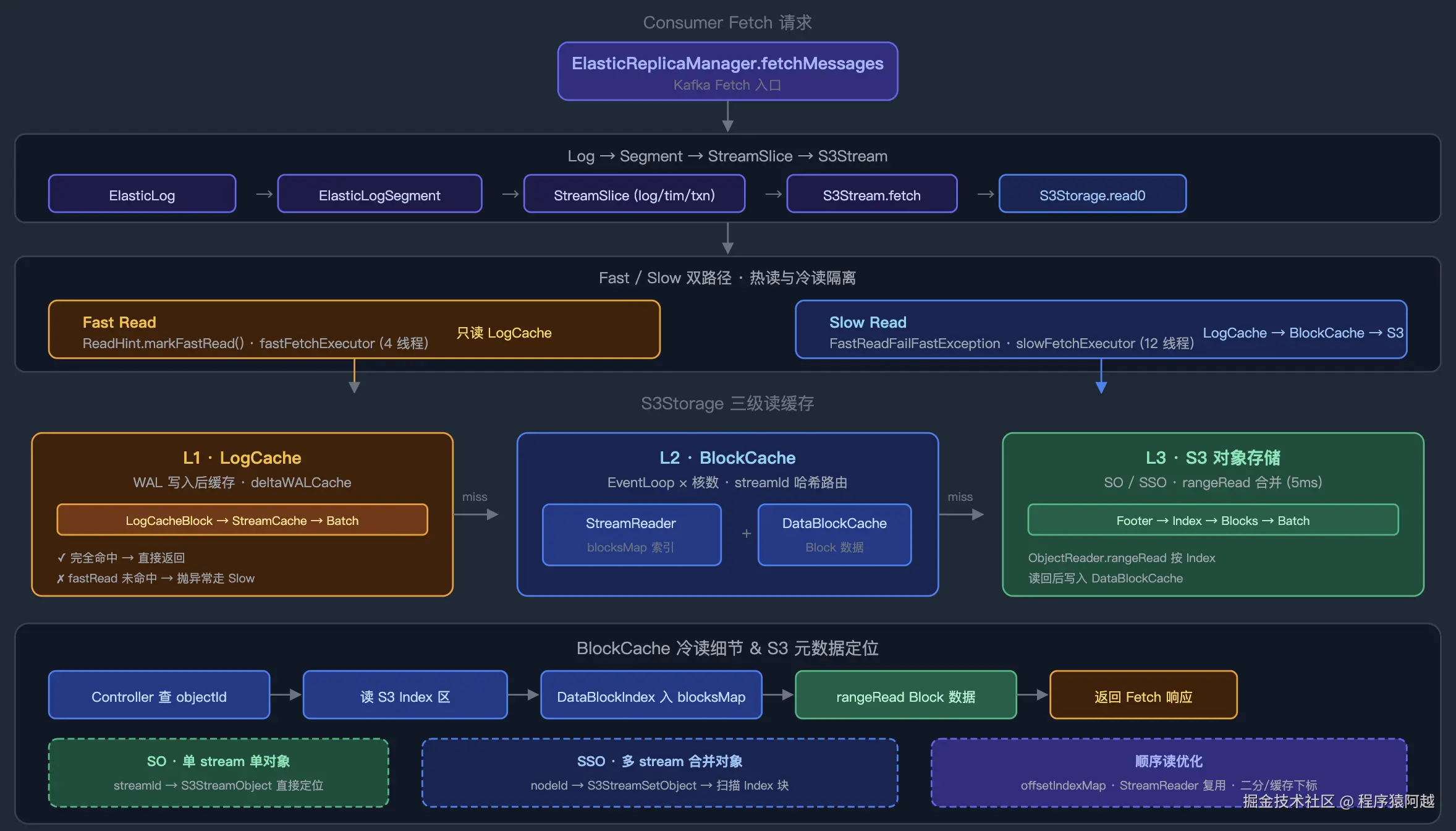
1)LogCache:WAL缓存,热数据,包括最近收到的消息;
2)BlockCache:包括索引缓存和数据缓存,从S3加载得到;
3)cache miss:合并读请求,range read S3;