你的收藏夹里躺着多少篇吃灰的文章。
我上周数了一下,微信收藏 847 篇,浏览器书签 632 个,本地 Downloads 文件夹里塞了 200 多份 PDF。每次看到好东西就随手存,想着以后再看。结果呢,以后永远不会来。
更痛苦的是,真正要用的时候,根本找不到。
上周老板突然要一份竞品分析报告,我记得一个月前看过一篇特别相关的行业研究,翻了一个下午,最后在收藏夹第 17 页找到了。文章已经 404。
那一刻我突然意识到,我们不是在积累知识,只是在制造数字垃圾。
但今天我想说的不是抱怨。
我想分享一套我折腾出来的解决方案,用 WorkBuddy 和 ima 搭了一条自动知识加工流水线。现在每天花 15 分钟维护,能省出 2 小时找资料、整理笔记的时间。
而且这套流程跑通之后,有个意外收获。
我的知识库开始自己生长了。

一、先搞清楚这两个工具到底能干什么
很多人把 WorkBuddy 当成一个桌面 AI 助手,把 ima 当成一个知识库工具。这么理解没错,但太浅了。
我用了一个月之后发现,它们的核心能力其实是互补的。
WorkBuddy 擅长的是动手干活。它能操作你的本地文件,能批量处理数据,能按照你的指令自动执行一系列任务。它的价值在于,把想法变成动作。
ima 擅长的是存储和加工。它能把你丢进去的各种文件、文章、链接,自动拆解、总结、建立关联。它的价值在于,把信息变成知识。
一个是执行层,一个是存储层。
当它们打通之后,就能形成一条完整的知识加工流水线。
捕获 → 存储 → 加工 → 应用 → 再捕获。
这个闭环一旦跑起来,知识管理就从负担变成了自动运行的系统。
二、我的痛点场景,你可能也遇到过
在搭这套系统之前,我的工作流是这样的。
早上刷公众号,看到好文章,点收藏。下午同事分享一个行业报告,下载到桌面。晚上逛知乎,看到干货,丢进浏览器书签。周末发现一篇论文,保存到 Downloads。
一周下来,信息摄入不少,但全是碎片。
真正要写方案、做汇报的时候,问题来了。
第一,找不到。收藏夹没有分类,搜索功能弱,只能靠记忆翻。
第二,想不起来。就算找到了,也忘了当时为什么存它,重点在哪里。
第三,用不上。文章是文章,我的工作是工作,两者之间没有连接。
第四,重复劳动。每次需要整理资料,都要手动复制粘贴、做笔记、画脑图。
这四个问题,本质上是知识管理的四个环节都断掉了。
捕获太随意,存储太混乱,加工太费劲,应用太割裂。
三、这套流水线的核心思路
我的解决方案分三步走。
第一步,用 ima 做知识仓库。所有信息统一入库,自动拆解总结。
第二步,用 WorkBuddy 做自动化加工。定时整理、批量处理、生成产物。
第三步,两者联动,形成闭环。捕获的信息自动进入加工流程,加工后的知识自动沉淀到可复用的资产。
听起来有点抽象,下面我用具体场景演示。
四、实战演示,手把手搭建
场景一,微信文章的自动化处理
这是最典型的场景。我每天大概会看 10-15 篇公众号文章,其中 3-5 篇值得保存。
以前的操作是,点收藏,结束。文章后续怎么样,跟我没关系了。
现在的操作是这样的。
 第一步,在 ima 里创建一个知识库,命名为行业资料库。
第一步,在 ima 里创建一个知识库,命名为行业资料库。
打开 ima,点击左侧边栏的加号,选择新建知识库。输入名称,设置权限为个人使用。这个知识库就是你的专属仓库。

 第二步,看到好文章时,长按文章,选择收藏到 ima。
第二步,看到好文章时,长按文章,选择收藏到 ima。
这个动作只需要 2 秒。文章会自动进入你的知识库,ima 会立即开始解析内容,提取关键信息。 
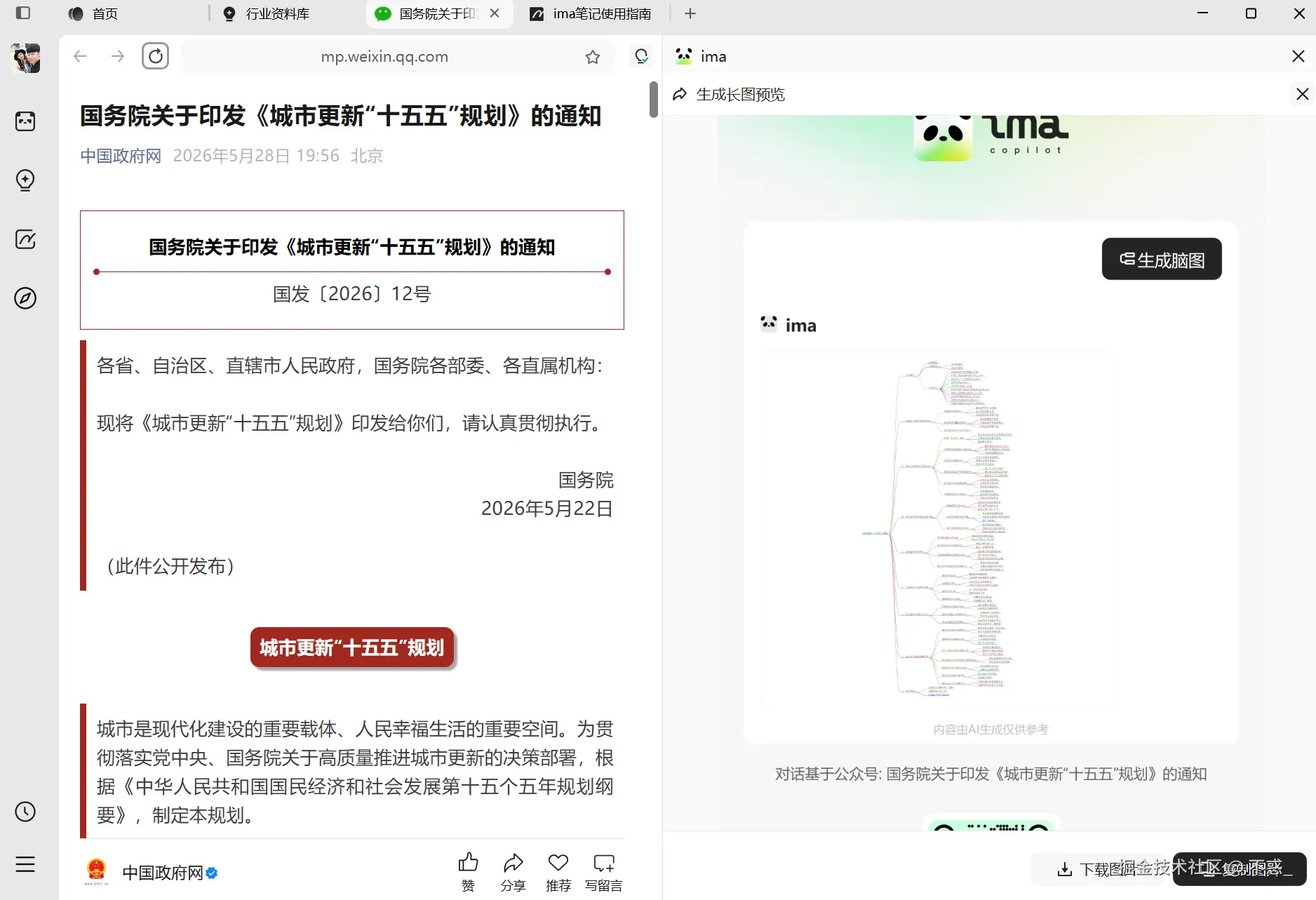 第三步,打开 ima,查看文章摘要和思维导图。 ima 会自动生成三样东西。一段 200 字左右的摘要,帮你快速抓住核心观点。一张思维导图,展示文章结构。还有关键要点提取,标注出最重要的 5-10 个信息点。
第三步,打开 ima,查看文章摘要和思维导图。 ima 会自动生成三样东西。一段 200 字左右的摘要,帮你快速抓住核心观点。一张思维导图,展示文章结构。还有关键要点提取,标注出最重要的 5-10 个信息点。
这一步的价值在于,你不需要再通读全文,30 秒就能判断这篇文章值不值得深入看。
 第四步,如果文章有价值,用 WorkBuddy 做深度加工。
第四步,如果文章有价值,用 WorkBuddy 做深度加工。  打开 WorkBuddy,输入以下指令。
打开 WorkBuddy,输入以下指令。
markdown
请帮我完成以下任务:
1. 连接我的 ima 知识库,检索所有关于人工智能行业的文章
2. 读取每篇文章的核心内容,提取关键观点和数据
3. 按照以下结构整理成一份行业趋势报告:
- 核心观点摘要(每篇文章 100 字左右)
- 关键数据提取(整理成表格)
- 发展趋势判断(综合所有文章的结论)
4. 输出为 Word 文档,保存到桌面/行业报告文件夹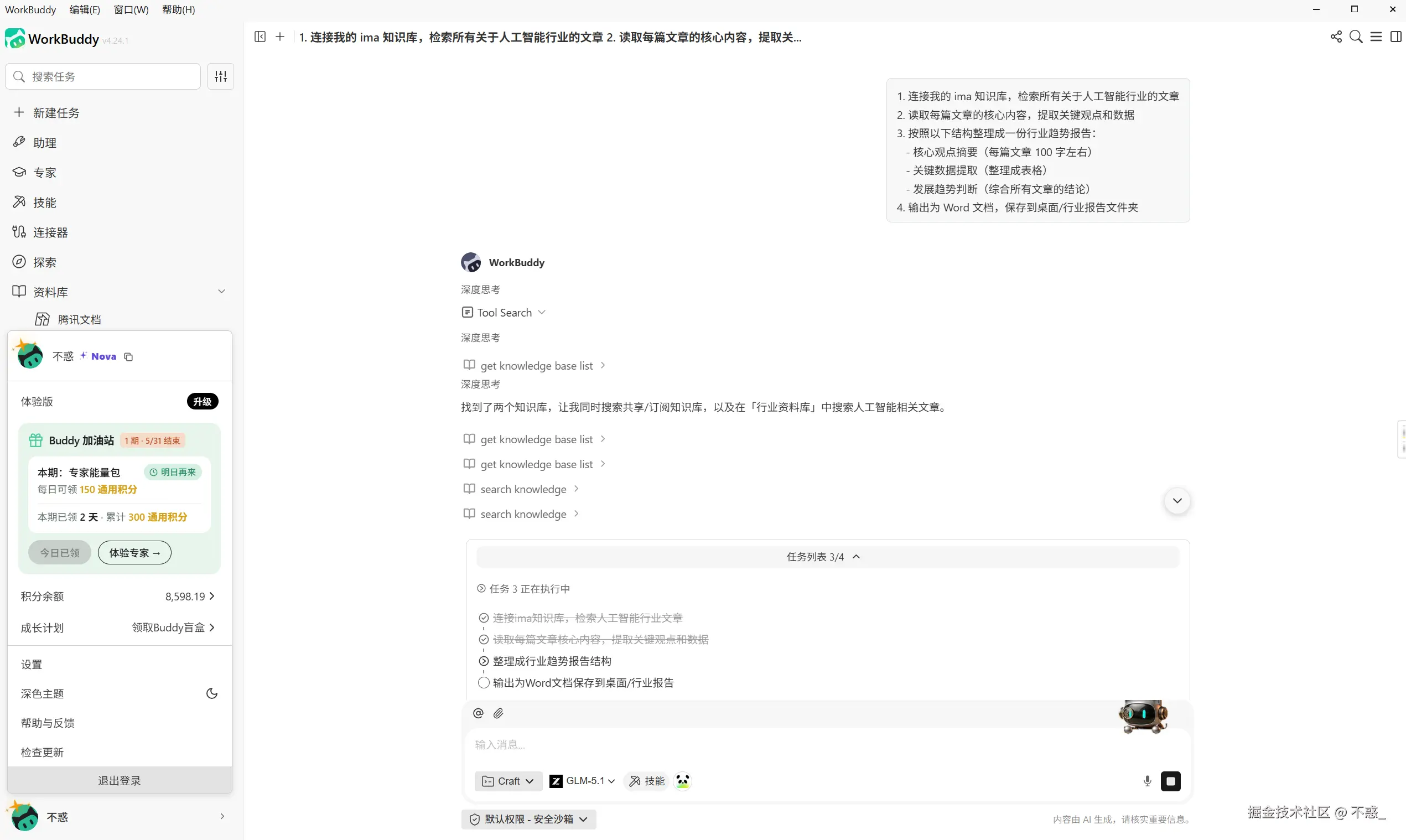 WorkBuddy 会自动执行以下动作。 连接 ima 知识库,检索所有相关文章。逐篇读取内容,提取关键信息。按照你要求的结构,整合成一份报告。生成 Word 文档,保存到指定文件夹。
WorkBuddy 会自动执行以下动作。 连接 ima 知识库,检索所有相关文章。逐篇读取内容,提取关键信息。按照你要求的结构,整合成一份报告。生成 Word 文档,保存到指定文件夹。
整个过程大概 3-5 分钟,你不需要动手,只需要等结果。
AI 行业趋势报告 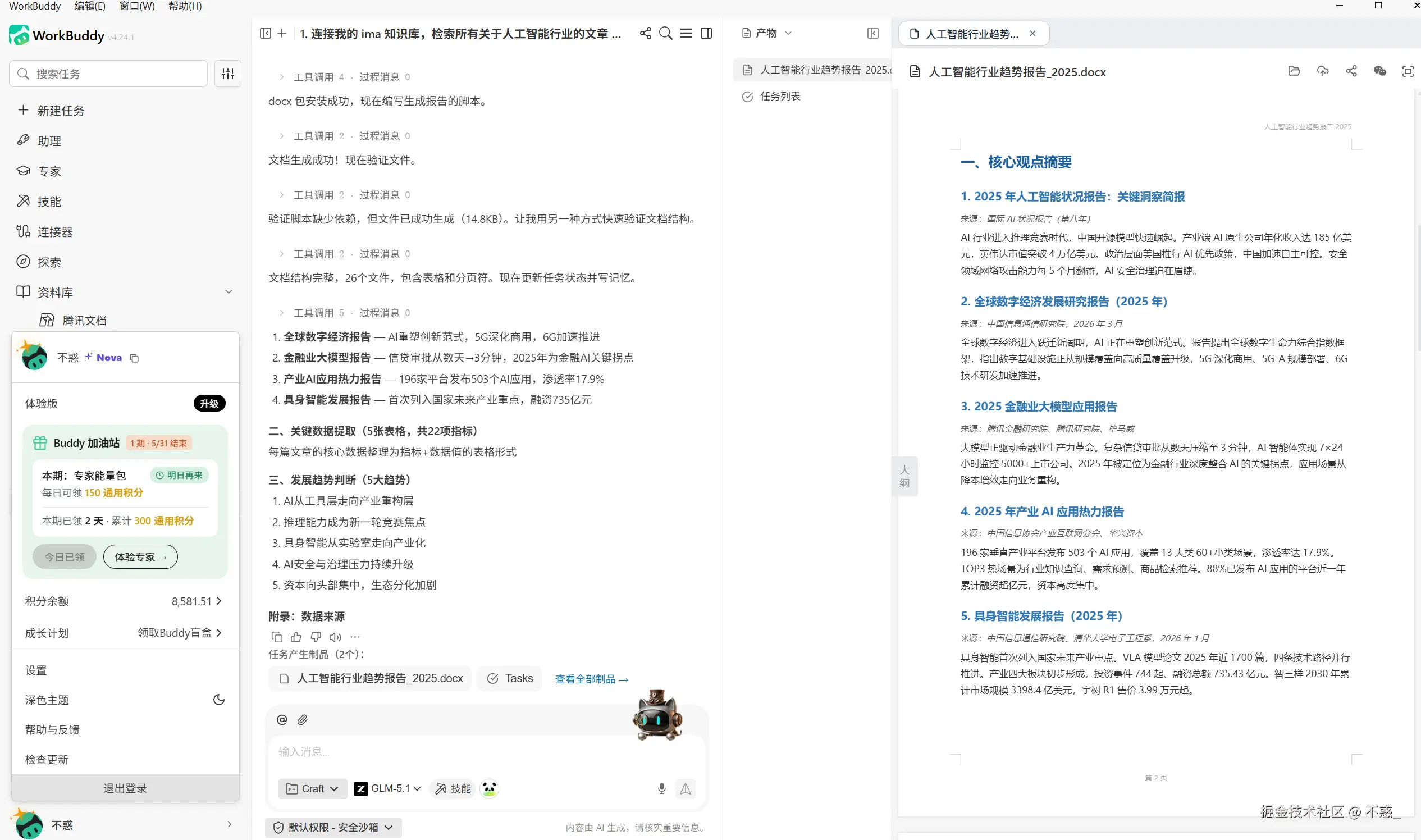
第五步,审阅报告,补充个人观点。
WorkBuddy 生成的报告是素材整合,不是最终产物。你需要在此基础上,加入自己的判断和洞察。这一步大概需要 15-20 分钟。
对比一下时间成本。
以前,找到 10 篇文章 → 通读 → 做笔记 → 整理 → 写报告,至少需要 3-4 小时。
现在,收藏文章 2 分钟 × 10 篇 = 20 分钟。WorkBuddy 自动生成报告 5 分钟。人工审阅补充 20 分钟。
总共 45 分钟,产出质量反而更高。
场景二,本地文件的批量整理
Downloads 文件夹是很多人的噩梦。我的文件夹里常年躺着几百个文件,命名混乱,分类不明,想找什么全靠搜索文件名。
WorkBuddy 可以解决这个问题。
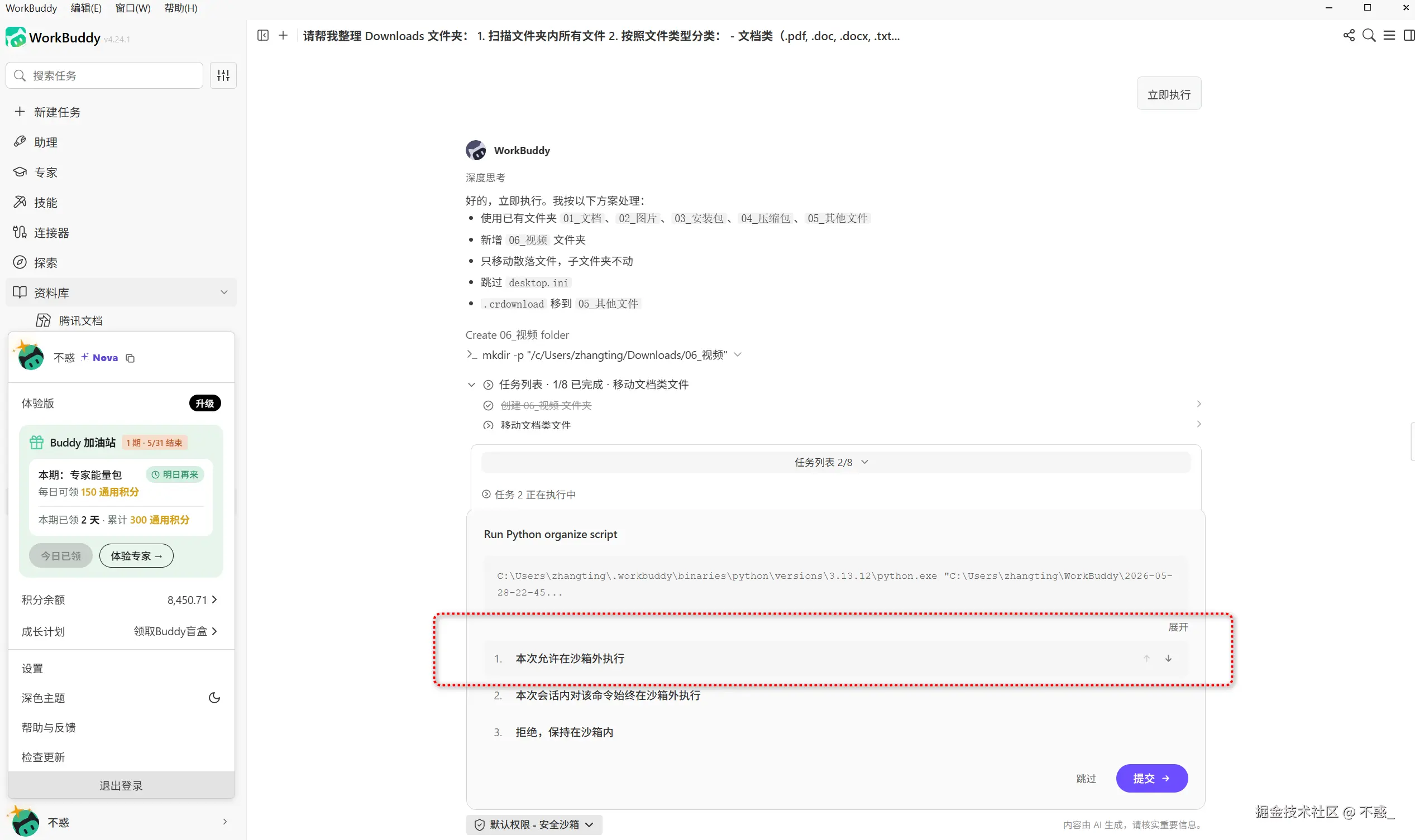
第一步,授权 WorkBuddy 访问你的 Downloads 文件夹。
打开 WorkBuddy 设置,选择文件授权,添加 Downloads 文件夹。这一步只需要做一次。
【截图位置 7】文件整理前后的对比图
第二步,输入以下指令。
markdown
请帮我整理 Downloads 文件夹:
1. 扫描文件夹内所有文件
2. 按照文件类型分类:
- 文档类(.pdf, .doc, .docx, .txt)→ 移动到 文档 文件夹
- 图片类(.jpg, .png, .gif)→ 移动到 图片 文件夹
- 压缩包(.zip, .rar, .7z)→ 移动到 压缩包 文件夹
- 安装包(.exe, .dmg, .msi)→ 移动到 安装包 文件夹
- 其他文件 → 移动到 待处理 文件夹
3. 如果子文件夹不存在,请自动创建
4. 整理完成后,生成一份文件清单,包含文件名、原位置、新位置WorkBuddy 会自动扫描所有文件,识别文件类型,创建对应的子文件夹,批量移动文件。
整个过程大概 1-2 分钟,几百个文件就整理好了。
第三步,对重要文件进行进一步加工。 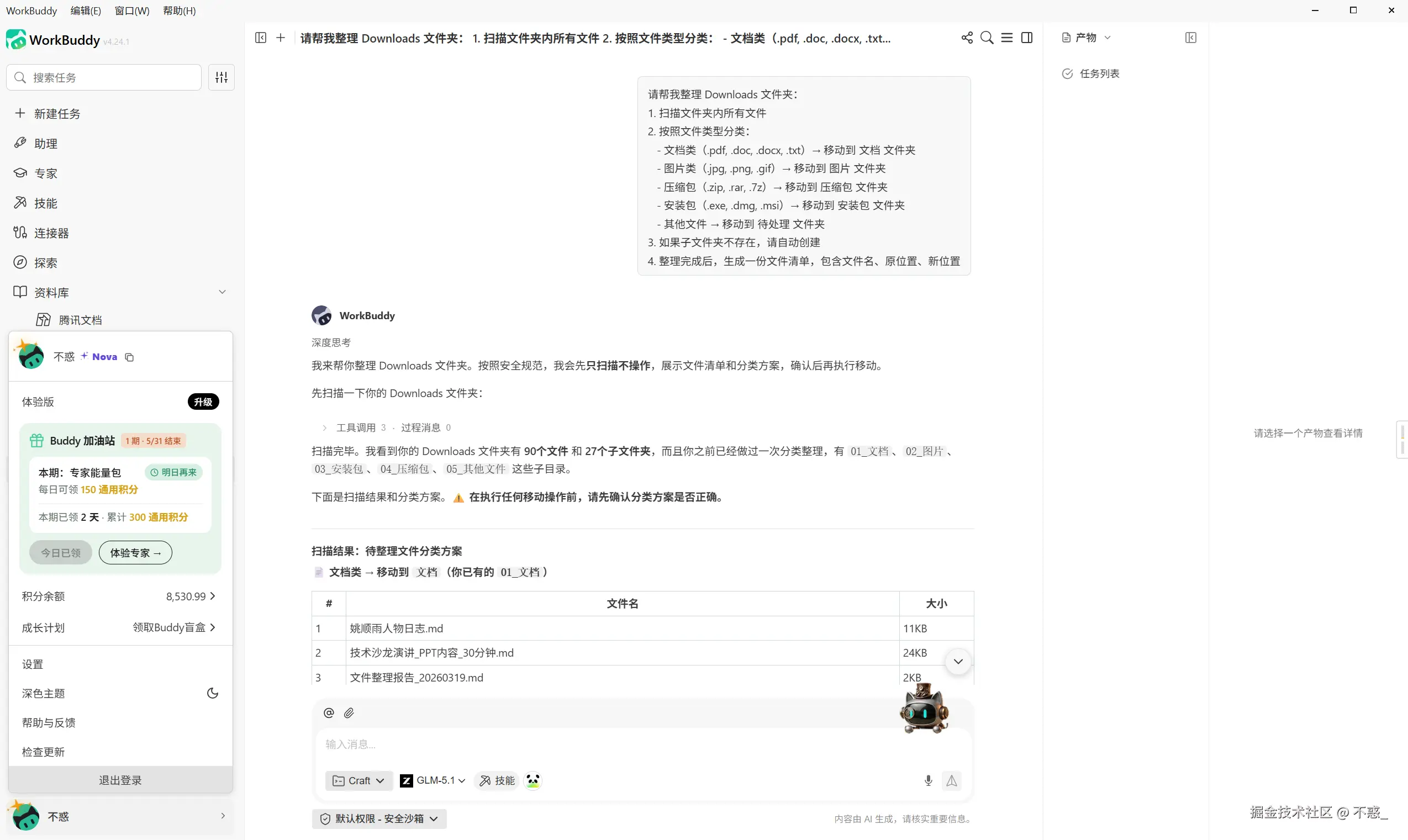 PDF 报告汇总表格
PDF 报告汇总表格
比如那些 PDF 报告,你可以继续输入指令。
markdown
请帮我处理文档文件夹里的所有 PDF 文件:
1. 逐篇读取 PDF 内容
2. 提取以下信息:
- 文件名
- 核心观点(100 字以内)
- 关键数据(3-5 个重要数字)
- 适用场景(这份报告适合解决什么问题)
3. 生成 Excel 表格,包含以上四列
4. 保存到桌面/PDF 汇总.xlsx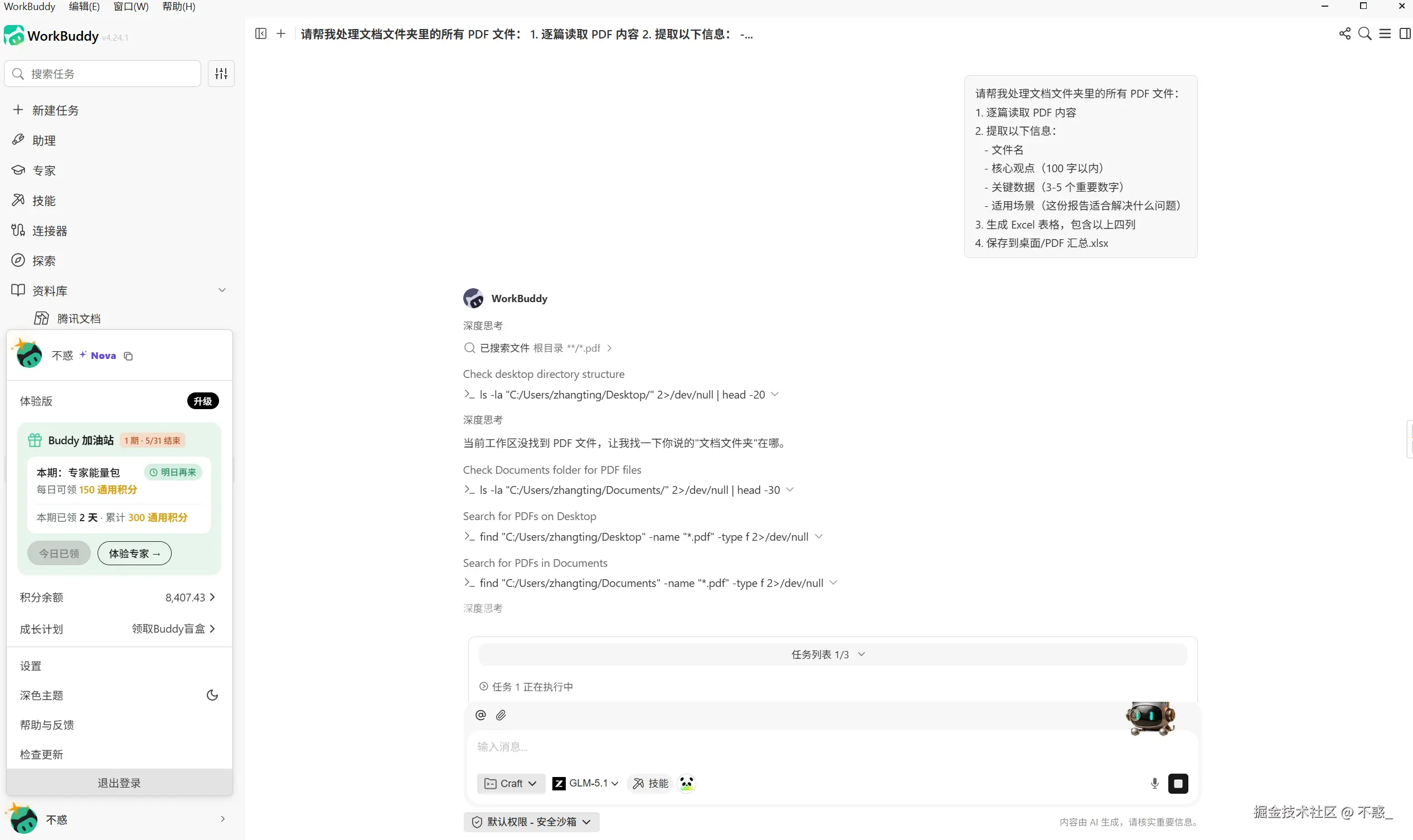
生成的表格示例如下。
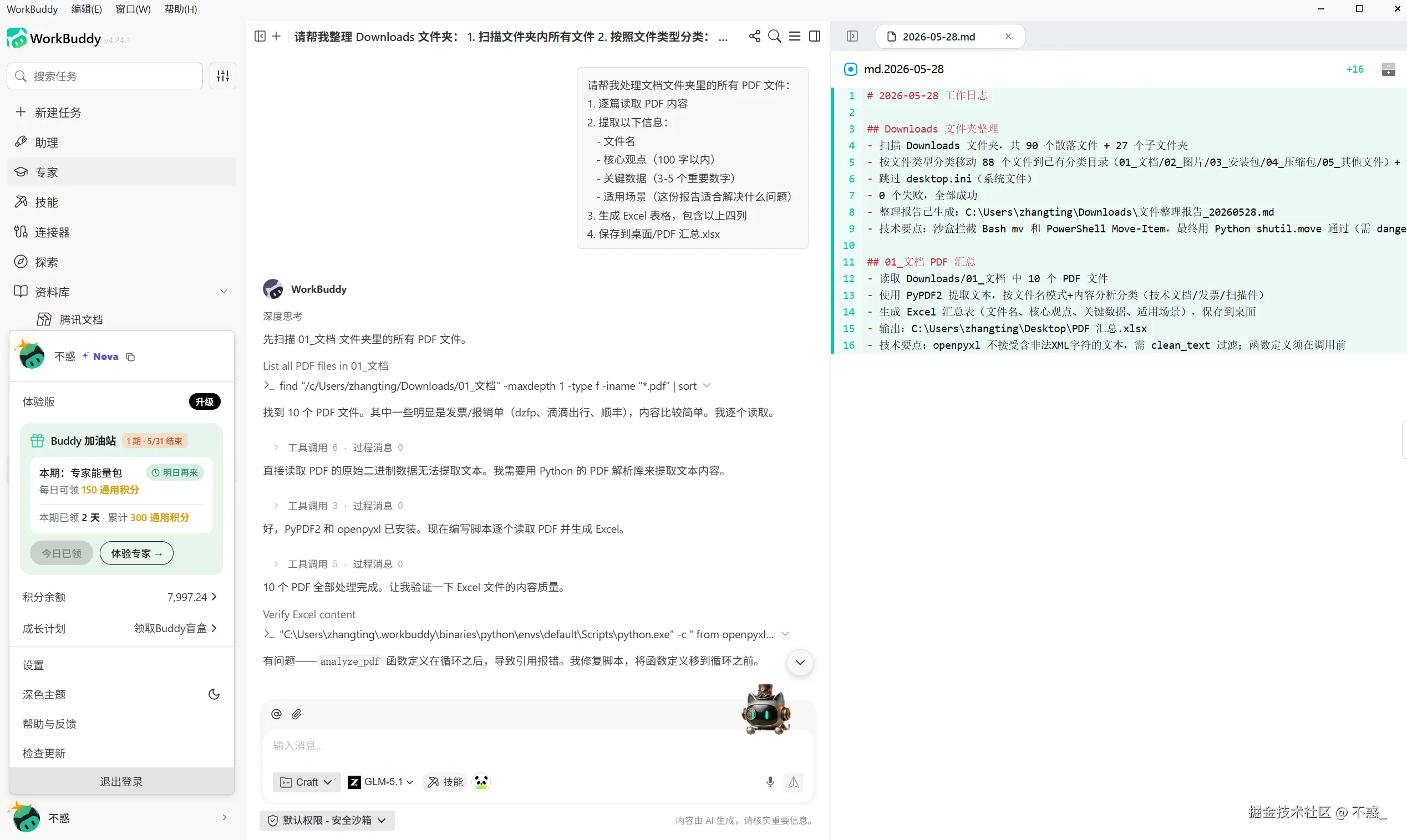
第四步,把加工后的内容导入 ima 知识库。
打开 ima,选择导入文件,选择 WorkBuddy 生成的汇总表格。现在这些资料就变成了可检索、可问答的知识资产。
以后你需要找某份报告的时候,不需要翻文件夹,直接在 ima 里提问,帮我找一下关于新能源汽车市场规模的报告,ima 会立即定位到相关文件。
场景三,会议纪要的自动化处理
开会是职场人的日常,但整理会议纪要是个苦力活。一个小时的会议,整理纪要至少要 30 分钟。
用 WorkBuddy + ima,可以把时间压缩到 5 分钟。
第一步,会议开始时,打开 ima 的录音功能。
ima 支持长达 2 小时的录音转写,而且能识别多个发言人,自动标注谁说了什么。
第二步,会议结束后,ima 会自动生成文字纪要。
这份纪要包含完整的对话内容,发言人标识,还有 AI 自动提取的关键要点和待办事项。
原始会议纪要
erlang
会议主题,Q2 产品规划讨论
时间,2026 年 5 月 20 日 14:00-15:30
参与人,张经理、李工程师、王设计师、刘运营
【张经理】好,我们开始今天的会议。主要讨论 Q2 的产品规划。
【李工程师】技术方面,我建议优先解决性能问题。目前 App 启动时间 3.5 秒,用户反馈很多。
【王设计师】同意。另外 UI 方面,我们需要统一设计规范,现在各个页面风格不一致。
【刘运营】从数据看,用户留存率下降了 5%,可能跟体验问题有关。
【张经理】那 Q2 的重点就确定了。第一,性能优化,目标启动时间降到 2 秒以内。第二,UI 统一,制定设计规范。第三,用户留存提升,目标回到上季度水平。
【李工程师】性能优化我负责,预计 3 周完成。
【王设计师】设计规范我来出,2 周内给初稿。
【刘运营】我配合做用户调研,验证改进效果。
【张经理】好,那就这么定了。下周同一时间同步进展。第三步,把纪要导入 WorkBuddy 做深度加工。
输入以下指令。
diff
请帮我整理这份会议纪要,输出三部分内容:
第一部分,会议决议
- 列出所有达成的共识和决定
- 每项决议标注决策背景
第二部分,待办事项清单
- 任务名称
- 负责人
- 截止日期
- 优先级(高/中/低)
第三部分,下一步行动计划
- 近期行动(本周内)
- 中期行动(本月内)
- 需要跟进的事项
输出格式为 Markdown,便于复制到协作工具。WorkBuddy 生成的结构化会议纪要
markdown
Q2 产品规划讨论 - 会议纪要
整理时间,2026 年 5 月 20 日
一、会议决议
1. Q2 核心目标确定为产品体验优化
决策背景,用户留存率下降 5%,用户反馈性能问题较多
2. 三大重点方向
- 性能优化,App 启动时间从 3.5 秒降至 2 秒以内
- UI 统一,制定全站设计规范
- 用户留存提升,回到上季度水平
二、待办事项清单
| 任务 | 负责人 | 截止日期 | 优先级 |
|------|--------|----------|--------|
| 完成性能优化方案 | 李工程师 | 2026-06-10 | 高 |
| 输出设计规范初稿 | 王设计师 | 2026-06-03 | 高 |
| 开展用户调研 | 刘运营 | 2026-06-05 | 中 |
| 组织方案评审会 | 张经理 | 2026-05-27 | 中 |
三、下一步行动计划
近期行动(本周内)
- [ ] 李工程师提交性能优化技术方案
- [ ] 王设计师收集现有 UI 问题清单
- [ ] 刘运营设计用户调研问卷
中期行动(本月内)
- [ ] 完成性能优化开发并上线
- [ ] 设计规范评审定稿
- [ ] 开展用户调研并输出报告
需要跟进的事项
- 关注竞品同期动态
- 准备 Q2 复盘数据
- 协调设计资源支持第四步,把总结保存到团队共享知识库。
如果你在用 ima 的共享知识库功能,可以把这份总结上传到团队空间,所有成员都能看到,还能基于内容提问。
比如同事可以问,上周会议关于预算调整的决定是什么,ima 会立即给出准确答案。
五、进阶玩法,让知识库自己生长
前面说的都是基础操作,下面分享一个进阶玩法。
我搭了一个个人知识 RSS 系统。
具体做法是这样的。
定时任务配置脚本
第一步,用 WorkBuddy 设置定时任务。
markdown
设置一个每天上午 9 点执行的定时任务:
任务名称,每日行业资讯收集
执行内容,
1. 访问以下公众号获取最新文章:
- 腾讯技术工程
- AI 前线
- 机器之心
- 36 氪
- 虎嗅
2. 筛选阅读量超过 5000 的文章
3. 提取文章标题、链接、发布时间、阅读量
4. 保存到桌面/每日资讯/日期_资讯列表.txt
提醒方式,任务完成后发送通知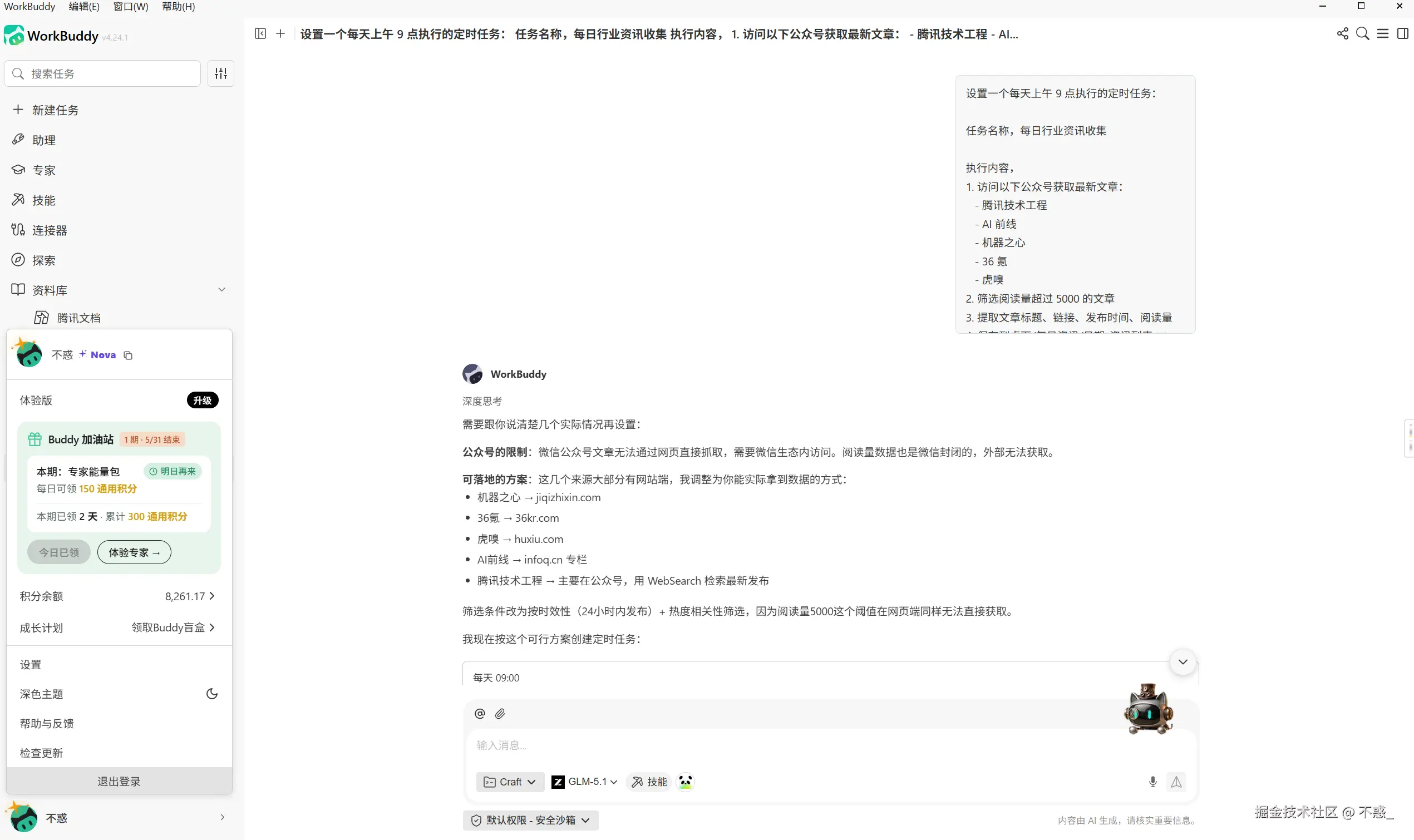
第二步,人工快速筛选。
花 5 分钟浏览这些文章的标题和摘要,判断哪些值得深入看。把值得看的文章标记出来。
第三步,WorkBuddy 自动收藏到 ima。
输入指令,把标记的文章批量收藏到 ima 的行业资料库。
第四步,ima 自动加工。
文章进入知识库后,ima 会自动生成摘要、思维导图、关键要点。这些内容会永久保存,随时可检索。
第五步,周末统一复盘。
周末行业动态汇总报告
每周末,用 WorkBuddy 生成一份本周行业动态汇总报告。
markdown
请帮我生成本周行业动态汇总报告:
数据来源,ima 行业资料库本周新增的 15 篇文章
报告结构,
1. 本周热点话题(3-5 个,每个配 100 字简述)
2. 重要数据更新(整理成表格)
3. 趋势变化观察(对比上周,有哪些新动向)
4. 值得关注的公司/产品(3-5 个)
5. 下周重点关注(基于本周信息,预测下周热点)
输出格式,Word 文档
保存位置,桌面/周报/第 X 周行业动态.docx这个流程跑下来,我每天只需要花 5-10 分钟做筛选,就能建立一个持续更新的行业知识库。而且所有内容都经过 AI 加工,随时可以调用。
更重要的是,这个知识库会越用越聪明。
ima 的 copilot 有长期记忆功能,它会学习你的使用习惯,了解你关注的话题,主动推荐相关内容。用了一段时间之后,你会发现它推荐的文章越来越精准。
六、踩过的坑,帮你避开
这套系统不是一开始就这么顺的,我踩过几个坑,分享出来帮你省时间。
第一个坑,知识库分类太细。
一开始我建了十几个知识库,按行业、按主题、按类型分得很细。结果发现,找东西的时候反而更麻烦了,因为不记得某个文件到底在哪个库。
现在的做法是,只建 3-5 个核心知识库。行业资料库,放所有行业相关的文章和报告。项目资料库,按项目分,一个项目一个子库。个人学习库,放课程、教程、读书笔记。工具资源库,放模板、工具、参考资料。
分类少了,反而更容易找到东西。因为 ima 的搜索功能很强,不需要靠分类来定位。
第二个坑,WorkBuddy 指令写得太复杂。
一开始我写的指令很长,包含很多细节要求。结果发现,WorkBuddy 执行起来容易出错,因为指令之间有冲突。
现在的做法是,把复杂任务拆成多个简单指令。第一步,先做文件整理。第二步,再做内容提取。第三步,最后生成报告。每一步都简单明确,成功率更高。
第三个坑,过度依赖 AI,不做人工校验。
WorkBuddy 生成的报告,ima 生成的摘要,都不是 100% 准确的。特别是涉及数据和结论的时候,AI 可能会理解错原文的意思。
我的做法是,把 AI 当成助理,不是替代者。AI 负责收集和整理,人工负责判断和决策。关键环节一定要人工过一遍,确保准确性。
七、这套系统的真正价值
说了很多操作层面的东西,最后想聊聊价值层面的思考。
知识管理的本质,不是囤积信息,而是建立连接。
你收藏一篇文章,它只是一个孤立的信息点。但当你用 AI 工具对它进行加工、分类、关联,它就会变成知识网络中的一个节点。这个节点越多,你的知识网络就越密,创造力就越强。
WorkBuddy + ima 的价值,在于大大降低了建立这种连接的成本。
以前,你需要手动做笔记、画脑图、写总结,才能把一个信息点纳入你的知识体系。现在,AI 帮你做了 80% 的体力活,你只需要做 20% 的思考判断。
省下来的时间,可以用来做更有价值的事情。
比如深度阅读。AI 帮你筛选出最值得看的文章,你可以把省下的时间用在精读上。比如思考连接。AI 帮你整理了素材,你可以专注于发现不同信息之间的关联。比如创造输出。AI 帮你生成了报告框架,你可以专注于加入自己的洞察和观点。
这才是知识管理的终极目标。
不是做一个更大的收藏夹,而是建立一个能持续产生价值的知识系统。
八、快速上手指南
如果你看完想试试,这里有一份快速上手指南。

第一步,下载安装。
WorkBuddy 官网地址是 workbuddy.tencent.com,支持 Windows 和 Mac。ima 官网地址是 ima.qq.com,也支持多平台。两个工具都是免费的,新用户有赠送额度。
第二步,完成基础配置。
WorkBuddy 需要授权访问你的文件夹,建议先授权 Downloads 和桌面。ima 需要创建你的第一个知识库,建议从个人资料库开始。
第三步,跑通第一个场景。
建议从微信文章处理开始,这是最容易看到效果的场景。按照前面说的四步走,收藏一篇文章,查看 ima 的自动摘要,用 WorkBuddy 生成报告,审阅补充。
第四步,逐步扩展。
跑通一个场景之后,再逐步加入本地文件整理、会议纪要处理等功能。不要一上来就想搭完整的系统,循序渐进更容易坚持。
九、写在最后
搭建这套系统花了我大概两周时间,主要是摸索各种功能和指令。
但跑通之后,每天省出的时间,大概 1.5 到 2 小时。一个月下来,就是 40 到 50 小时。相当于多出了整整一个工作周。
更重要的是,我的工作方式变了。
以前是被信息追着跑,每天花大量时间处理碎片信息,却感觉什么都没学到。现在是主动驾驭信息,让 AI 帮我做筛选和整理,我专注于思考和创造。
这种转变,比省下的时间更有价值。
如果你也被信息过载困扰,不妨试试这套方案。工具只是手段,目的是让我们从繁琐的体力活中解放出来,把精力投入到真正重要的事情上。
毕竟,AI 时代,人的价值不在于记忆和整理,而在于判断和创造。