引言:
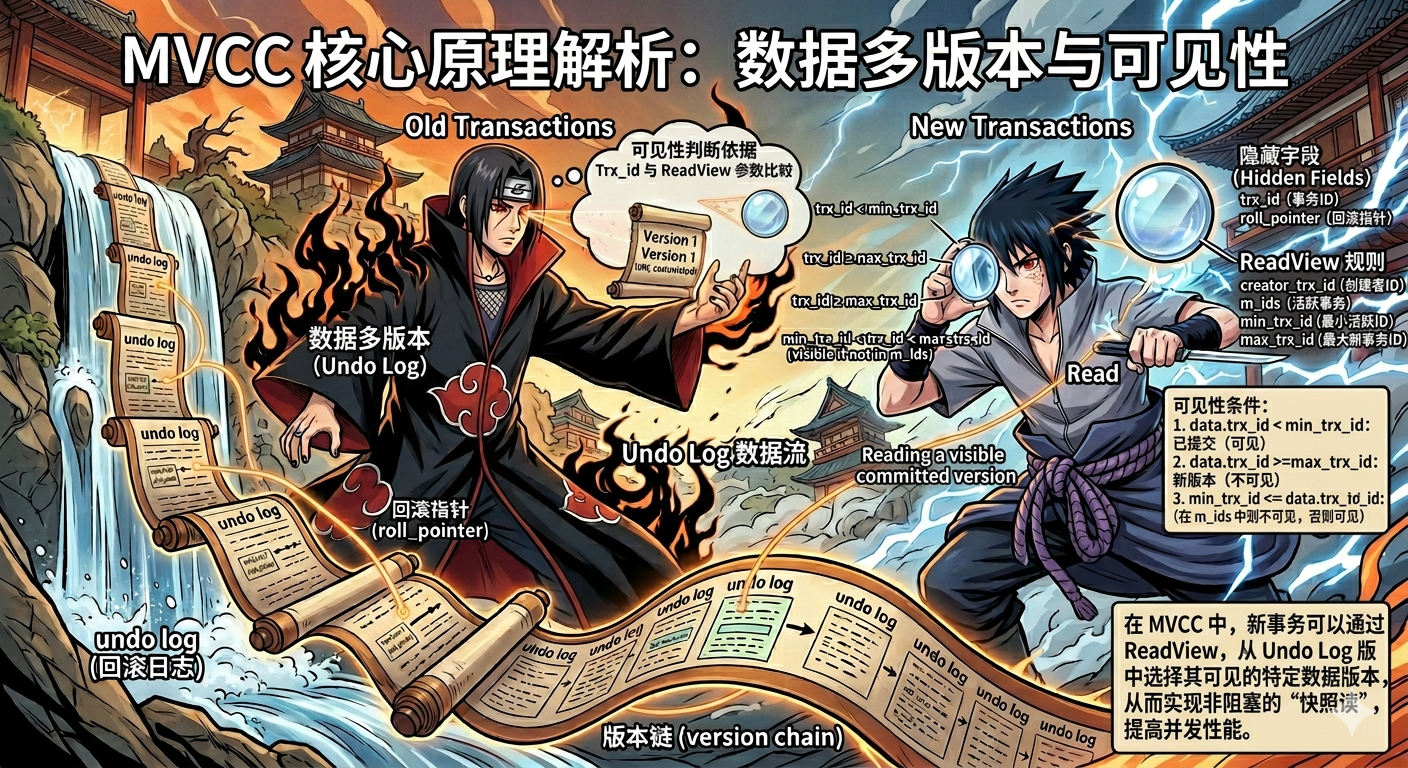
在数据库高并发场景下,海量事务同时读写同一份数据,单纯依赖锁机制相互制衡,只会造成无休止的阻塞等待;脏读、不可重复读与幻读,更如同忍界无解的幻术,牢牢桎梏着系统性能。
正如这幅图中,宇智波鼬借 Undo Log 铺展绵延不绝的数据历史分身版本链,佐助则凭借 ReadView 写轮眼,筛选出仅对当前事务可见的数据快照。
MVCC 正是数据库世界里独一份的宇智波瞳术,它摒弃锁竞争的对抗思路,依托多版本数据与视图可见性规则,为每一笔事务划分独立读写时空,从根源化解并发读写矛盾。
为什么需要 MVCC?
多事务并发访问数据库 时,会引发脏读 、 不可重复读 、 幻读等并发异常。
为平衡数据一致性与并发性能,数据库提供了不同事务隔离级别。传统悲观锁方案也可以解决问题,但是并发效率低。
因此数据库设计者想设计一种办法既保证事务隔离,又尽量不加锁。于是MVCC 出现了。
MVCC是什么?是如何实现的?
先思考一个问题:如果事务A正在读一条数据1000,事务B把它改为2000。那么事务A应该看到哪个值?
不同隔离级别要求不同:
Read Committed 希望看到最新已提交版本
Repeatable Read 希望永远看到第一次读取的版本
所以本质问题变成了:一条数据到底应该给事务看哪个版本?
既然不同事务想看不同版本。那么最直接的方法就是:保存多个历史版本。
核心思想为数据维护多个历史版本,让不同事务读取不同版本的数据,实现无锁读,提升数据库并发性能
底层实现:
MVCC 依靠隐藏字段、undo log 、ReadView 三大核心组件协作,完成数据版本管理 与可见性判断。
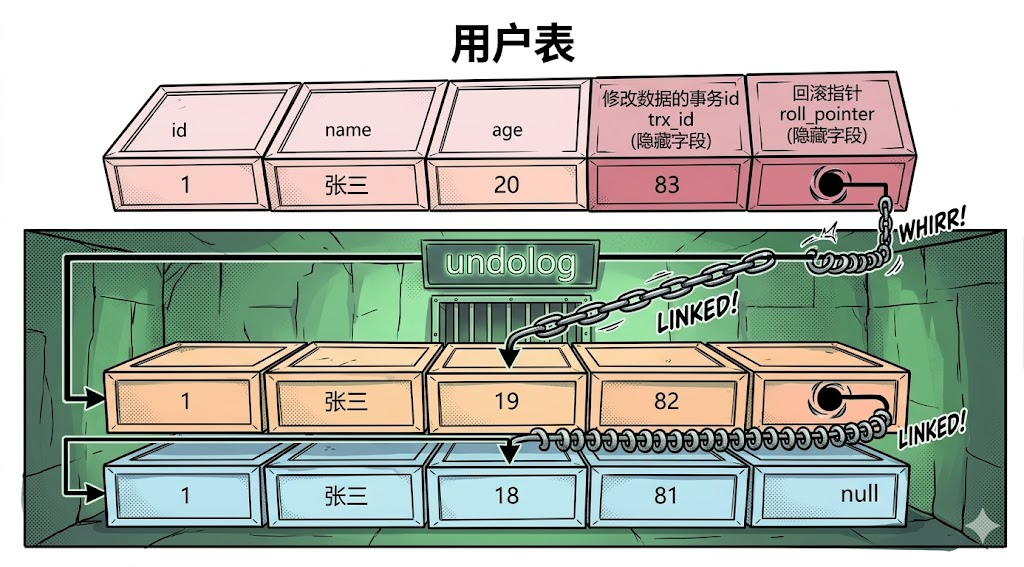
表隐藏字段:
每张数据表默认包含两个关键隐藏字段:
-
trx_id(事务ID):记录最后修改该条数据的事务 ID(事务 ID 全局自增,可判断事务先后顺序);
-
roll_pointer(回滚指针):指向
undo log中的历史数据版本,将所有版本串联成版本 链表,用于追溯历史数据。
undo log(回滚日志):
-
每次数据被修改时,会将修改前的旧数据存入 undo log,生成一个新数据版本;
-
依靠回滚指针串联所有历史版本,形成版本链;
-
**作用:**既支持事务回滚,也为 MVCC 提供历史数据版本。
ReadView(读视图)
ReadView 是事务读取数据时的可见性判断规则,用来判定某条数据版本对当前事务是否可见,包含 4 个核心字段:
-
creator_trx_id:创建当前 ReadView 的事务 ID; -
m_ids:创建视图时,数据库中所有活跃(未提交)的事务 ID 集合; -
min_trx_id:活跃未提交事务中的最小事务 ID; -
max_trx_id:数据库下一个待分配的新事务 ID。
数据版本可见性判断规则
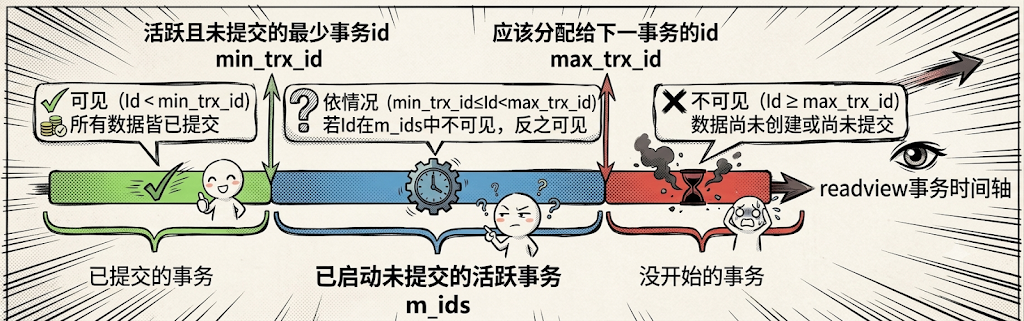
对比数据版本的**trx_id** 与**ReadView** 字段,分三类场景判断可见性:
-
数据 trx_id < min_trx_id:该版本在 ReadView 创建前就已提交,当前事务可见;
-
数据 trx_id ≥ max_trx_id:该版本是 ReadView 创建后新启动的事务生成,当前事务不可见;
-
min_trx_id < 数据 trx_id < max_trx_id:
-
若 trx_id 存在于
m_ids(事务未提交):不可见; -
若 trx_id 不存在于
m_ids(事务已提交):可见。
-
一句话总结 MVCC :
MVCC本质上由两部分组成分别是Undo Log和ReadView。Undo Log用来保存历史版本,ReadView负责判断哪个版本对当前事务可见。
修改数据时,记录事务 ID 到隐藏字段、旧数据存入 undo log 形成版本链;查询数据时,通过 ReadView 对比事务 ID,判断版本可见性,最终读取对应版本数据。
各个隔离级别是如何实现的?
读未提交 **:**最低的隔离级别, 每个事务都可以看到其他事务未提交的数据.
读已提交 **:**解决了脏读的问题,每个事务只能读到其他事务已经提交的数据。
可重复读 **:**mysql默认的隔离级别,解决了脏读和不可重复读。同一个事务内永远读到第一次查询的快照数据。
串行化 **:**事务完全串行执行,不允许并发,底层实现是加锁。
读未提交
无需 MVCC 特殊处理,事务可直接读取其他事务未提交的数据;仅写操作需加锁,防止并发写冲突。
读已提交
通过MVCC实现,读已提交的要求是只能读到已提交的数据,并且后续查询要能看见最新提交的数据,所以事务内每次执行 SELECT 查询都创建新的 ReadView。 每次读取都以最新的事务状态判断可见性,因此能读到其他事务已提交的最新数据,解决脏读。
可重复读
通过MVCC实现,可重复读要求:无论查询多少次,都看到同一份数据。
事务内第一次 SELECT 时生成 ReadView,后续所有查询复用该 ReadView。 事务全程读取同一个数据版本,保证多次查询结果一致,解决脏读、不可重复读。
串行化
不使用 MVCC,依靠全表 / 行锁强制事务串行执行,所有读写操作都需排队,隔离级别最高,但并发性能最差。
MVCC是如何解决幻读?
幻读 **:**同一个事务内多次查询,其他事务新增 / 删除数据,导致前后数据条数不一致。
串行化 **:**强制所有事务从头到尾串行执行,读写都互斥,隔离级别最高,但并发性能最差。
前面提到了MVCC解决了脏读和不可重复读的并发问题,那么幻读是如何被解决的呢?我们当然可以通过串行化可以解决幻读,但是性能太差, 一般不会使用。所以我们利用可重复读的隔离级别解决幻读问题。
可重复读下解决幻读的核心方案
快照读
-
触发场景:普通
SELECT查询 -
实现原理:基于 MVCC 读取数据历史快照,无锁查询
-
效果:只能看到事务启动时的数据版本,无法感知其他事务新增的数据,天然规避大部分幻读。
当前读
快照读存在短板:执行插入、修改等操作时,必须读取数据最新状态做校验,因此产生了当前读。
-
触发场景:
SELECT ... FOR UPDATE、SELECT ... LOCK IN SHARE MODE、增 / 删 / 改语句 -
实现原理:读取数据最新版本,同时加临键锁(锁定目标行 + 数据间隙)
-
效果:阻塞其他事务在锁范围内插入新数据,从而避免幻读。
极端场景:仍会出现 幻读
成因:同一事务中先快照读、后当前读,两种读取方式混用,临键锁也无法规避。
典型案例:
事务 A 先用普通 SELECT(快照读)查询某条数据,结果为空;
事务 B 插入该条数据并提交;
事务 A 再次快照读,依旧查不到数据;但执行
SELECT ... FOR UPDATE(当前读),能查到新数据,出现幻读。
彻底解决 幻读 的方案:
核心思路:通过加锁限制其他事务对数据表做新增、删除操作。
-
表锁:执行
SELECT * FROM 表名 FOR UPDATE,锁定整张表,其他事务所有操作都会阻塞; -
行锁:基于索引列执行
SELECT 索引列=值 FOR UPDATE,锁定指定行与间隙,阻止数据插入。
补充辨析: 可重复读 加锁 vs 串行化
很多人会混淆两种加锁逻辑,二者有本质区别:
-
串行化:全局管控,所有事务强制串行执行,完全牺牲并发能力;
-
可重复读中的锁:仅对当前读做局部加锁控制,普通快照读依旧依靠 MVCC 无锁并发,保留了高并发能力。
文章创作不易,希望大家动动发财的小手,点点赞,评论下。希望给大家带来更优质的内容。