一、核心逻辑运算符语义与执行机制
MongoDB 提供了四种基础的逻辑运算符,它们在查询文档中扮演着不同的角色。
1. $and(逻辑与)
- 语义:要求数组中的所有条件同时成立。
- 执行机制 :MongoDB 在处理
$and时,通常会按照数组中条件的先后顺序进行求值。如果某个条件能够利用索引,引擎会优先通过索引过滤出较小的结果集,然后再将剩余条件作为内存中的过滤条件(Filter)进行二次验证。 - 注意 :虽然 MongoDB 支持隐式的
$and(即同一字段或不同字段直接写在同一文档中),但在需要针对同一字段进行多次不同操作(如$gt和$lt)时,必须显式使用$and。
2. $or(逻辑或)
- 语义:只要数组中有一个或多个条件成立,文档即被匹配。
- 执行机制 :
$or支持短路求值(Short-circuit Evaluation)。一旦某个子条件匹配成功,MongoDB 将跳过剩余条件的判断。在底层执行计划(Execution Plan)中,如果每个子条件都能命中独立的索引,MongoDB 会使用OR阶段(如OR或SUBPLAN)对多个索引扫描的结果进行合并(Merge)与去重。
3. $nor(逻辑非或)
- 语义:要求数组中的所有条件均不成立,文档才会被匹配。
- 执行机制 :
$nor是$or的反义词。由于它要求"排除"特定数据,通常会导致全表集合扫描(COLLSCAN),因为数据库很难仅通过正向索引来高效定位"不满足条件"的文档。
4. $not(逻辑非)
- 语义:对指定的条件表达式取反。
- 执行机制 :
$not是一个元条件(Meta-condition),它必须嵌套在具体的字段操作符之外(如{ field: { $not: { $regex: ... } } })。它通常用于正则表达式匹配或特定的比较操作,不建议用于简单的等值判断(等值取反应使用$ne)。
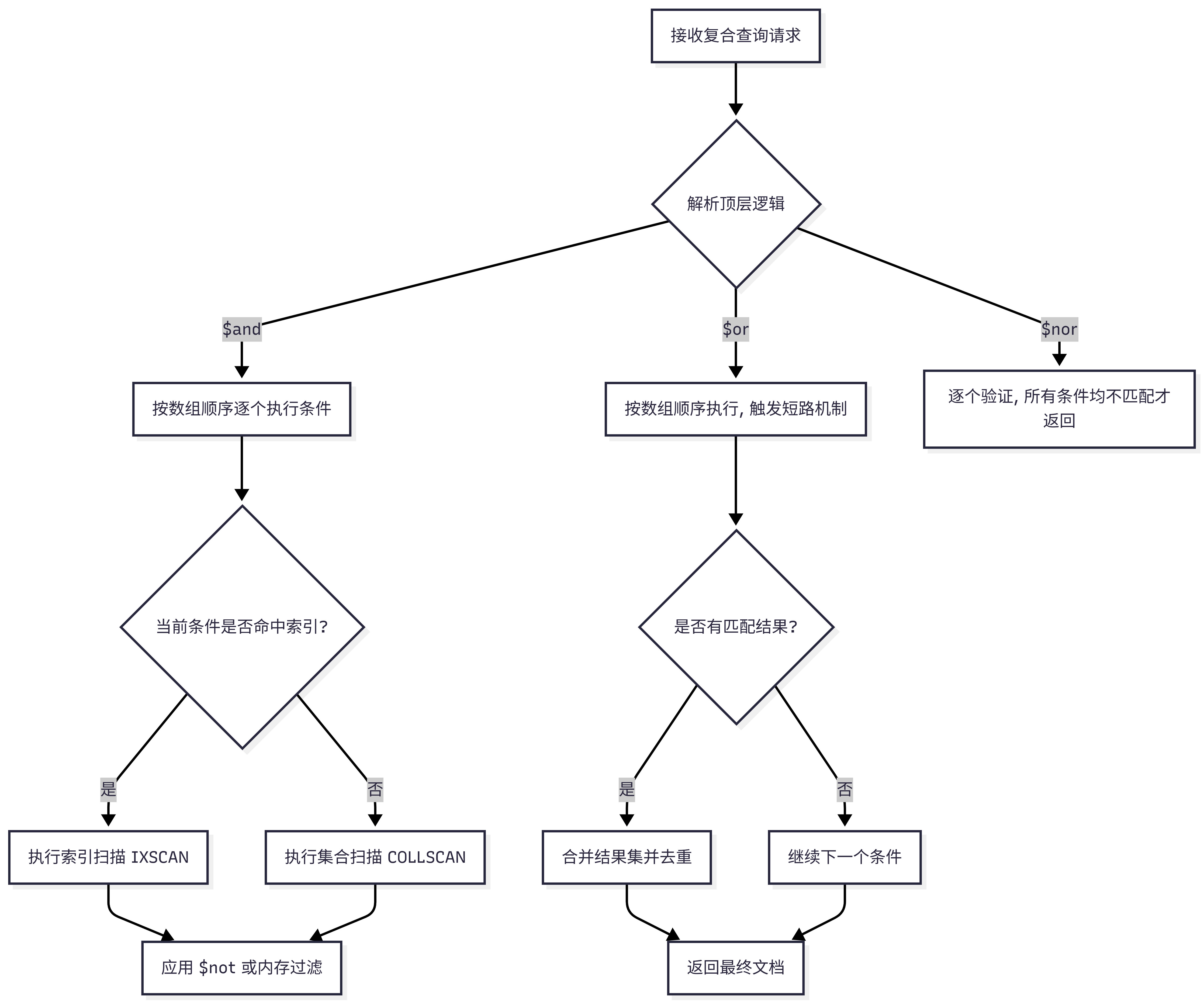
二、复合查询执行逻辑与优先级
当多种逻辑运算符嵌套使用时,MongoDB 遵循严格的求值顺序。理解这一顺序对于编写高效查询至关重要。
复合查询执行优先级:
- 首先解析最外层的逻辑结构。
- 对于
$and,按数组索引顺序从左至右执行。 - 对于
$or,从左至右执行,遇到首个匹配项即触发短路。 - 字段级的
$not在其所属的条件分支内部最后执行。
执行逻辑流程图:
三、逻辑运算符特性与性能对比
从多个维度进行对比:
| 维度 | $and | $or | $nor | $not |
|---|---|---|---|---|
| 核心语义 | 所有条件必须同时满足 | 满足任意一个条件即可 | 所有条件均不满足 | 对单一表达式取反 |
| 索引利用率 | 极高(可结合复合索引) | 高(各子条件独立走索引) | 极低(通常导致 COLLSCAN) | 视内部操作符而定 |
| 短路求值 | 遇到首个 False 即停止 | 遇到首个 True 即停止 | 无(必须验证所有条件) | 不适用 |
| 典型应用场景 | 多条件精确筛选、范围查询 | 多状态枚举、模糊搜索 | 黑名单过滤、数据清洗 | 正则排除、特定值取反 |
| 性能风险 | 顺序不当导致大结果集内存过滤 | 子条件无索引时性能急剧下降 | 大数据量下极易引发慢查询 | 嵌套过深导致解析开销 |
四、生产环境避坑与优化建议
- 优化
$and的条件顺序 :始终将能够命中高选择性(High Selectivity)索引的条件放在$and数组的最前面。让数据库尽早缩小结果集,将低选择性的条件留到内存中过滤。 - 确保
$or的子条件均有索引 :如果$or中的某个子条件无法使用索引,MongoDB 可能会退化为全表扫描。务必通过explain()验证每个分支的执行计划。 - 慎用
$nor进行大数据量过滤 :如果业务允许,尝试将$nor转化为正向的$in或$and查询;若必须使用,请确保在后台低峰期执行或限制返回条数。 - 替代不必要的
$not:对于简单的等值取反,使用$ne(不等于)通常比$not: { $eq: ... }具有更好的可读性和执行效率。
五、实战演练:基于 explain() 的逻辑运算符性能剖析
1. 环境准备与数据初始化
首先,我们在 MongoDB 中创建一个包含 5 条文档的 user 集合,并插入测试数据:
javascript
// 初始化测试数据
db.user.insertMany([
{name:"Programmer's Training Journey", age:2, from: "CTU", score:100 },
{name: "mongdb", age:13, from: "USA", score:90 },
{name: "mysql", age:23, from: "USA", score:86 },
{name: "orcle", age:45, from: "USA", score:75 },
{name: "sqlsrver", age:55, from: "USA", score:66}
]);
// 为 age 和 score 字段创建索引,以便观察索引扫描行为
db.user.createIndex({ age: 1 });
db.user.createIndex({ score: 1 });2. $and 复合查询与短路求值
需求 :查询姓名包含字母 l 且 年龄大于 35 的数据。
javascript
db.user.explain("executionStats").find({
$and: [
{ name: /l/i },
{ age: { $gt: 35 } }
]
});执行计划解析:
- MongoDB 在处理
$and时遵循从左到右的执行顺序。如果第一个条件(如正则匹配)无法命中索引,引擎会进行内存过滤;但如果将其调整为{ age: { $gt: 35 } }在前,引擎将优先通过age索引(IXSCAN)快速缩小结果集,再在内存中过滤name字段。 - 短路特性 :如果文档的
age小于等于 35,MongoDB 将直接跳过name的正则匹配,从而节省计算资源。
3. $or 联合查询与索引合并
需求 :查询姓名包含字母 l 或 年龄大于 35 的数据。
javascript
db.user.explain("executionStats").find({
$or: [
{ name: /l/i },
{ age: { $gt: 35 } }
]
});执行计划解析:
- 在执行计划(winningPlan)中,会看到 SUBPLAN 节点(它是 MongoDB 为 $or 分支生成独立计划的内部阶段)。在这个案例中,由于 name 的正则匹配无法走普通 B-Tree 索引,导致优化器放弃了索引合并策略,整个查询直接退化为 COLLSCAN(集合扫描)
- 性能警示 :如果
$or中的某个子条件完全没有索引支持,整个查询可能会退化为全表扫描。
4. $nor 逻辑非或查询
需求 :查询姓名中不包含 l 且 年龄不大于 35 的数据。
javascript
db.user.explain("executionStats").find({
$nor: [
{ name: /l/i },
{ age: { $gt: 35 } }
]
});执行计划解析:
$nor要求数组中的所有条件均不匹配。在explain输出中,由于否定逻辑难以利用正向索引,该查询通常会触发COLLSCAN,逐条扫描文档并排除符合条件的数据。- 架构建议 :在生产环境中,应尽量避免对大集合使用
$nor,否则极易引发慢查询。
5. $not 取反查询
需求 :查询姓名中不包含 字母 l 的数据。
javascript
db.user.explain("executionStats").find({
name: { $not: /l/i }
});💡 执行计划解析:
$not是一个元操作符,必须嵌套在字段级别使用。与$nor类似,针对正则表达式的$not取反操作同样无法高效利用索引,执行计划中大概率呈现为全表扫描。
六、经典高频面试题与解析
Q1:在 MongoDB 中,{ age: { $gt: 18, $lt: 30 } } 和 { $and: [ { age: { $gt: 18 } }, { age: { $lt: 30 } } ] } 有区别吗?
答 :在逻辑结果上没有区别,MongoDB 会将前者隐式转换为后者。但在实际开发中,推荐显式使用 $and,因为这能显著提升代码的可读性,并且在需要对同一字段进行更复杂的操作(如结合 $or)时,显式写法能避免语法解析错误。
Q2:为什么在生产环境中,强烈不建议对大集合使用 $nor 或 $not?
答 :因为 $nor 和 $not 属于"否定型"查询。B-Tree 索引是为正向查找设计的,否定查询通常无法有效利用索引的有序性,极易导致集合扫描(COLLSCAN)。在千万级数据量下,这会瞬间耗尽 CPU 和 I/O 资源,引发严重的慢查询甚至数据库雪崩。
Q3:如何排查和优化一个包含 $or 的慢查询?
答 :首先使用 db.collection.explain("executionStats") 查看执行计划。重点检查 OR 阶段下的各个子分支:确认是否每个分支都走了 IXSCAN(索引扫描)。如果某个分支出现了 COLLSCAN,则需要为该分支的条件创建合适的索引。此外,检查 executionTimeMillis 和 nReturned,评估是否存在数据倾斜或无效匹配。