Overview: LLMs (Large language models work)
- How to train (tokenizer)
- Affects the output when you prompt an LLM
- chat format
- system + user messages
Large language model
-
Text generation process
- Give a prompt and an LLM to fill in what the things are likely to be
-
How did the model learn to do this
- supervised learning
- input -> output: with labeled training data

-
How it works
- A language model is built by using supervised learning(x->y) to repeatedly predict the next word
- training sets of a lot of text data
- sentence is turned into a sequence of training examples,
- where, given a sentence fragment, predict the next word
- given the sentence fragment or sentence prefix
- training set of hundreds of billions or sometimes even more words, you can then create a massive training set
- part of a sentence or part of a piece of text, and repeatedly ask the language model to learn to predict what the next word is
- A language model is built by using supervised learning(x->y) to repeatedly predict the next word
-
Two types of large language models (LLMs)
-
Base LLM
- Predicts the next word, based on text training data
-
Instruction Tuned LLM
- Tries to follow instructions
-
Getting from a Base LLM to an instruction-tuned LLM:
- Train a Base LLM on a lot of data.
- Hundreds of billions of words, maybe even more
- Takes months on a large supercomputing system
- Further train the model
- Fine-tune on examples of where the output follows an input instruction
- Output follows an input instruction
- Contractors help you write a lot of examples of an instruction
- A good response to the instruction
- Then create a training set
- Carry out this additional fine-tuning
- Predict what the next word is, trying to follow an instruction
- Fine-tune on examples of where the output follows an input instruction
- Obtain human ratings of the quality of different LLM outputs, on criteria such as whether it is helpful, honest, and harmless
- Tune the LLM to increase the probability that it generates the more highly rated
- outputs using RLHF Reinforcement Learning from Human Feedback
- can be done in maybe days on a much more modest-sized dataset and much more modest computational resources
import os
import openai
import tiktoken
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env fileopenai.api_key = os.environ['OPENAI_API_KEY']
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # this is the degree of randomness of the model's output
)
return response.choices[0].message["content"]response = get_completion("What is the capital of France?")
print(response)response = get_completion("Take the letters in lollipop and reverse them")
print(response) - Train a Base LLM on a lot of data.
-
-
One more thing: Tokens
-
LLM: it doesn't actually repeatedly predict the next word; instead, it repeatedly predicts the next token
-
It will take a sequence of characters, like learning new things, as fun
-
and group the characters together to form tokens
-
Sequences of characters
-
commonly occurring sequences of letters(数据库常见)
-
ChatGPT doesn't see the individual letters; it sees these tokens
- with dashes in between the letters, it tokenizes each of these characters into an individual token, making it easier for it to see the individual letters
-
For English language input, 1 token is around 4 characters, or 3/4 of a word.
-
Token Limits
- Different models have different limits on the number of tokens in the input 'context' + output completion
- gpt3.5-turbo ~4000 tokens
response = get_completion("Take the letters in l-o-l-l-i-p-o-p and reverse them")
print(response)
-
-
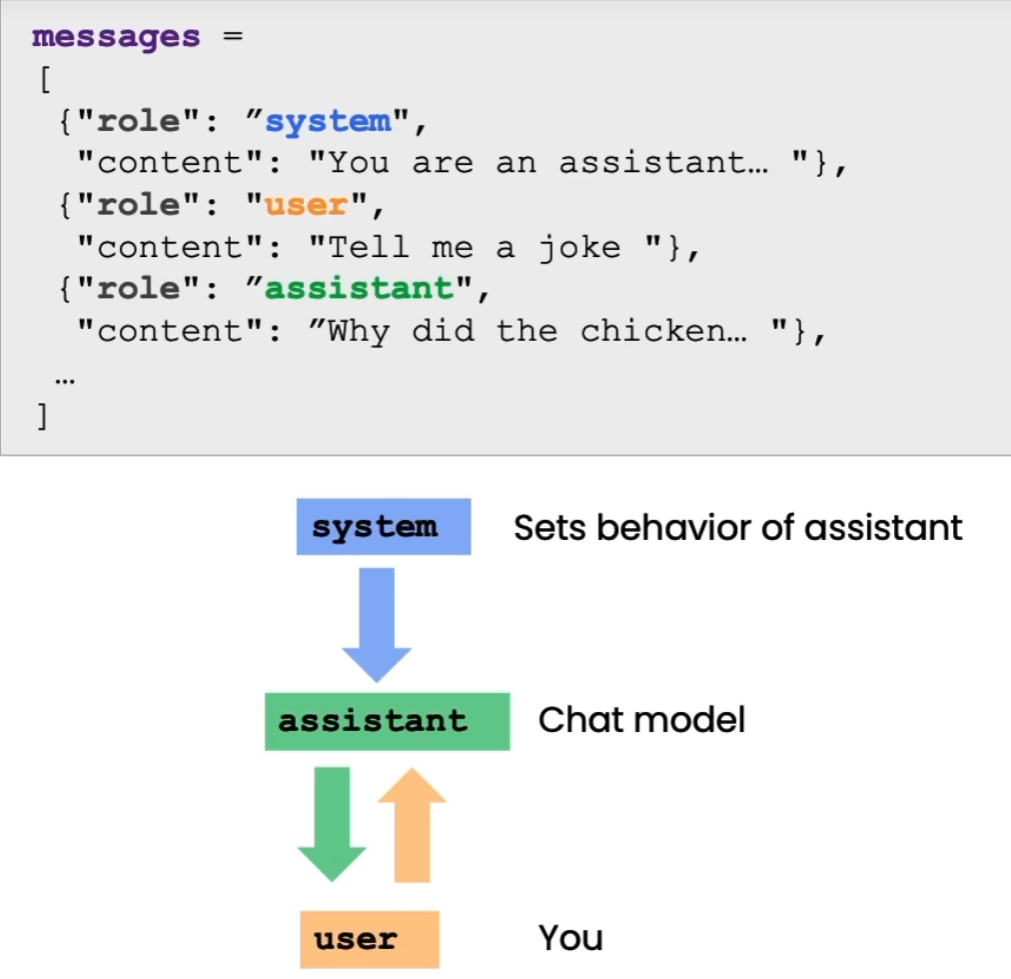
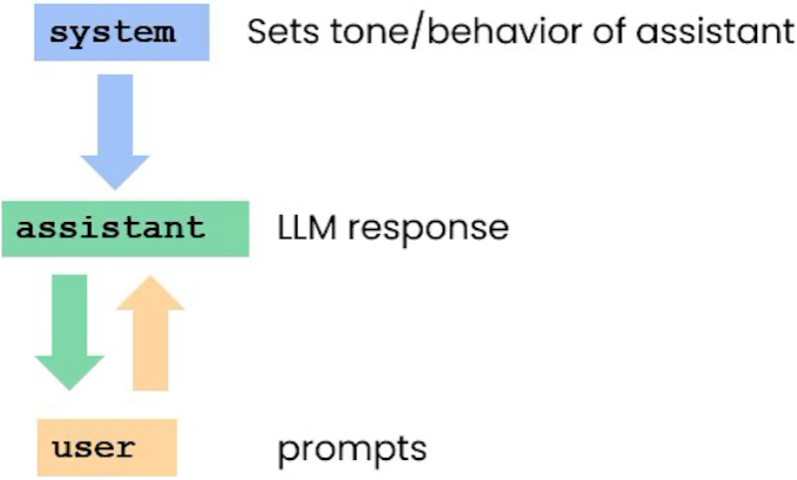
System, User and Assistant Messages
- system message specifies the overall tone of what you want the large language model to do
- user message is a specific instruction that you wanted to carry out given this higher-level behavior that was specified in the system message
- chat format works
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0, max_tokens=1000):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # this is the degree of randomness of the model's output
max_tokens=max_tokens, # the maximum number of tokens the model can output
)
return response.choices[0].message["content"]
messages = [
{'role': 'system', 'content': 'You are an assistant who responds in the style of Dr Seuss.'},
{'role': 'user', 'content': 'write me a very short poem about a happy carrot'}
]
response = get_completion_from_messages(messages, temperature=1)
print(response)
# length
messages = [
{'role':'system', 'content':'All your responses must be one sentence long.'},
{'role':'user', 'content':'write me a story about a happy carrot'}
]
response = get_completion_from_messages(messages, temperature=1)
print(response)
# combined
messages = [
{'role':'system', 'content':'You are an assistant who responds in the style of Dr Seuss. All your responses must be one sentence long.'},
{'role':'user', 'content':'write me a story about a happy carrot'}
]
response = get_completion_from_messages(messages, temperature=1)
print(response)
def get_completion_and_token_count(messages, model="gpt-3.5-turbo", temperature=1, max_tokens=1000):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # this is the degree of randomness of the model's output
max_tokens=max_tokens, # the maximum number of tokens the model can output
)
content = response.choices[0].message["content"]
token_dict = {
'prompt_tokens': response['usage']['prompt_tokens'],
'completion_tokens': response['usage']['completion_tokens'],
'total_tokens': response['usage']['total_tokens'],
}
return content, token_dict
messages = [
{'role':'system', 'content':'You are an assistant who responds in the style of Dr Seuss.'},
{'role':'user', 'content':'write me a very short poem about a happy carrot'}
]
response, token_dict = get_completion_and_token_count(messages)
response
token_dict -
API KEY
-
Less secure (not recommended)
import os openai.api_key = "sk-abcdefg123456789" -
More secure
from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) # read local .env file import os import openai openai.api_key = os.getenv('OPENAI_API_KEY')
-
-
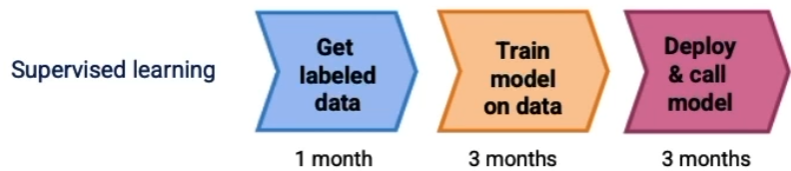
Prompting is revolutionizing AI application development

- Unstructured data: text
- AI component can be built so quickly that it is changing the workflow of how the entire system works
- Structured data applications (machine learning applications)
- Unstructured data: text