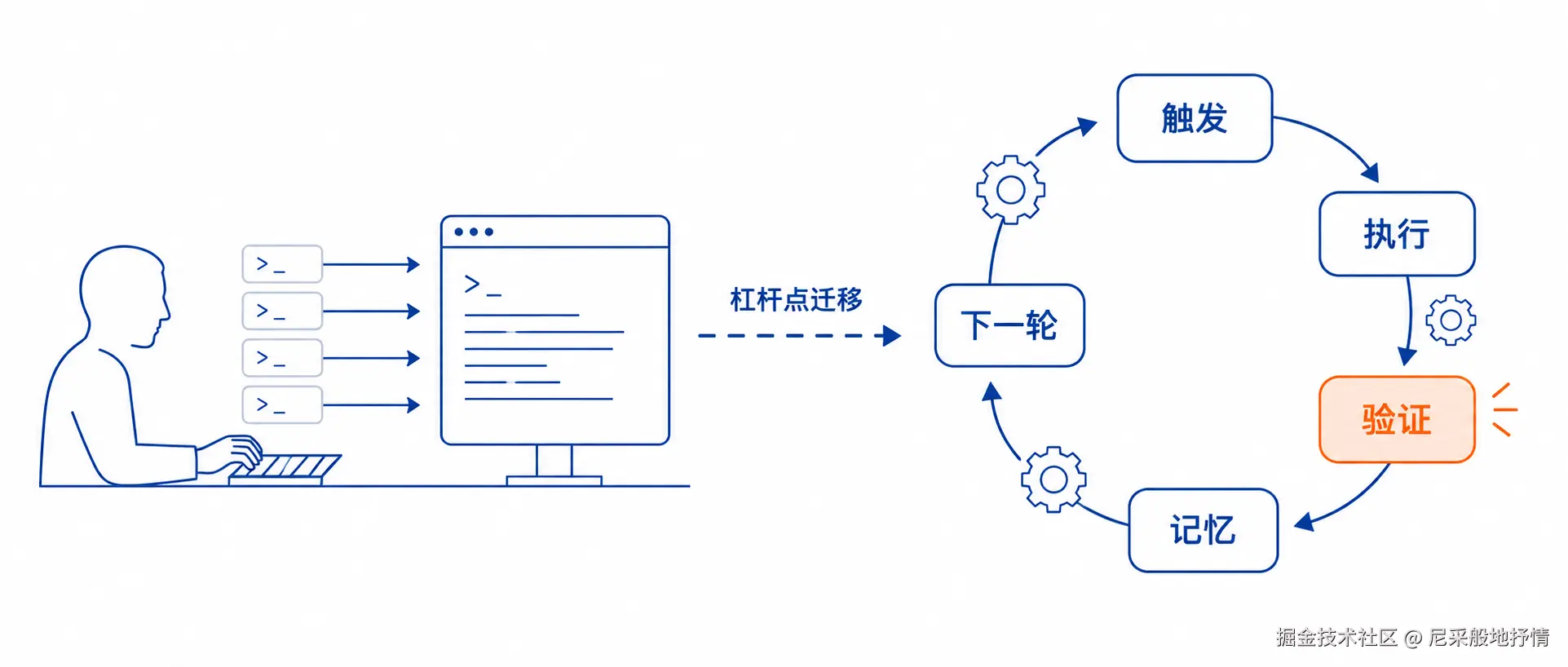
前言:Chrome 工程师 Addy Osmani 这几天把「循环工程」讲透了------你不该再亲自逐轮 prompt Agent,而该设计一套能自我迭代的自治系统。我按自己的 AI 编程实践,把五个积木和一块记忆拆开写了一遍。写这篇不是为了追新概念,而是想回答一个问题:当 Claude Code、Codex 已经能把 /loop、/goal 跑起来的时候,工程师还剩什么不能外包?
你是不是也厌倦了当「人肉搬运工」?
过去两年,我和大多数用 AI 写代码的人一样:打开 Claude Code 或 Cursor,写一段 prompt,等它回,读一遍,再写下一段 prompt。Agent 是工具,我是那个一直握着工具的人。
这套模式在简单任务上很好用。改个 typo、补个类型、写个单测------单次调用就能从 60 分拉到 85 分。各种 Prompt 框架、上下文工程、Harness Engineering 都在卷这件事:怎么让单次 Agent 调用更准、更完整。
但复杂任务一上来,天花板很快就摸到了。目标模糊、解法跑偏、写完就自信地说「搞定了」------而测试满屏红。你让它自查?更不行。写代码的 Agent 当裁判,和球员兼裁判一样,本能偏袒自己。
于是行业引入了「裁判」:第二个 Agent 验收第一个的产出。效果好一些,但流程变成了机械 SOP:
派发任务 → Agent 执行 → 人类验收 → 人类反馈 → Agent 重跑 → 人类再验收 → 下一个任务
有些团队用 AI 替代验收节点,但只要整个链条还要人串联,人类就还是那条肉体协调器。每天大量精力卡在复制粘贴和节点跳转上,而不是在想架构、做判断。
就在这几天,Chrome 团队的 Addy Osmani 发了长文,把这件事讲透了。他用的词是 Loop Engineering------循环工程。Steinberger 说得更直接:「你不该再 prompt coding agent 了,你该设计 prompt agent 的循环。」Claude Code 负责人 Boris Cherny 也说:「我不再手动 prompt Claude 了,我的工作是写 Loop。」
单次 Agent 调用的优化空间正在收敛;下一轮杠杆不在「更好的 prompt」,而在「谁来做那个循环」。
Loop Engineering 到底是什么
一句话:Loop Engineering 是用系统设计,取代你亲自逐轮 prompt Agent。
-
Harness Engineering 关心的是:单个 Agent 跑在什么样的环境里,单次执行质量能到多高。
-
Loop Engineering 关心的是:如何构建一套有状态感知、能自我修正、可重复运行的闭环,在少介入甚至零介入的情况下,通过多轮迭代达到你定义的完成条件。
一个 loop 可以想成递归目标 :你定义目的和停止条件,系统自己找活、派活、验收、记状态,然后决定下一轮干什么。你设计它一次,之后不是你在 prompt,是系统在 prompt。
Osmani 把它和 Harness 的关系说得很清楚:Harness 是单个 Agent 的「厂房」;Loop 是厂房上面那层------带定时器、能孵化子助手、能喂自己的工厂控制系统。
一年前要做 loop,你得自己堆 bash、自己维护。现在 Claude Code 和 Codex 五个积木基本都齐了 ,名字略有不同,形状几乎一样。工具之争可以往后放,先学会设计一个换工具还能用的循环。

五个积木,加一块记忆
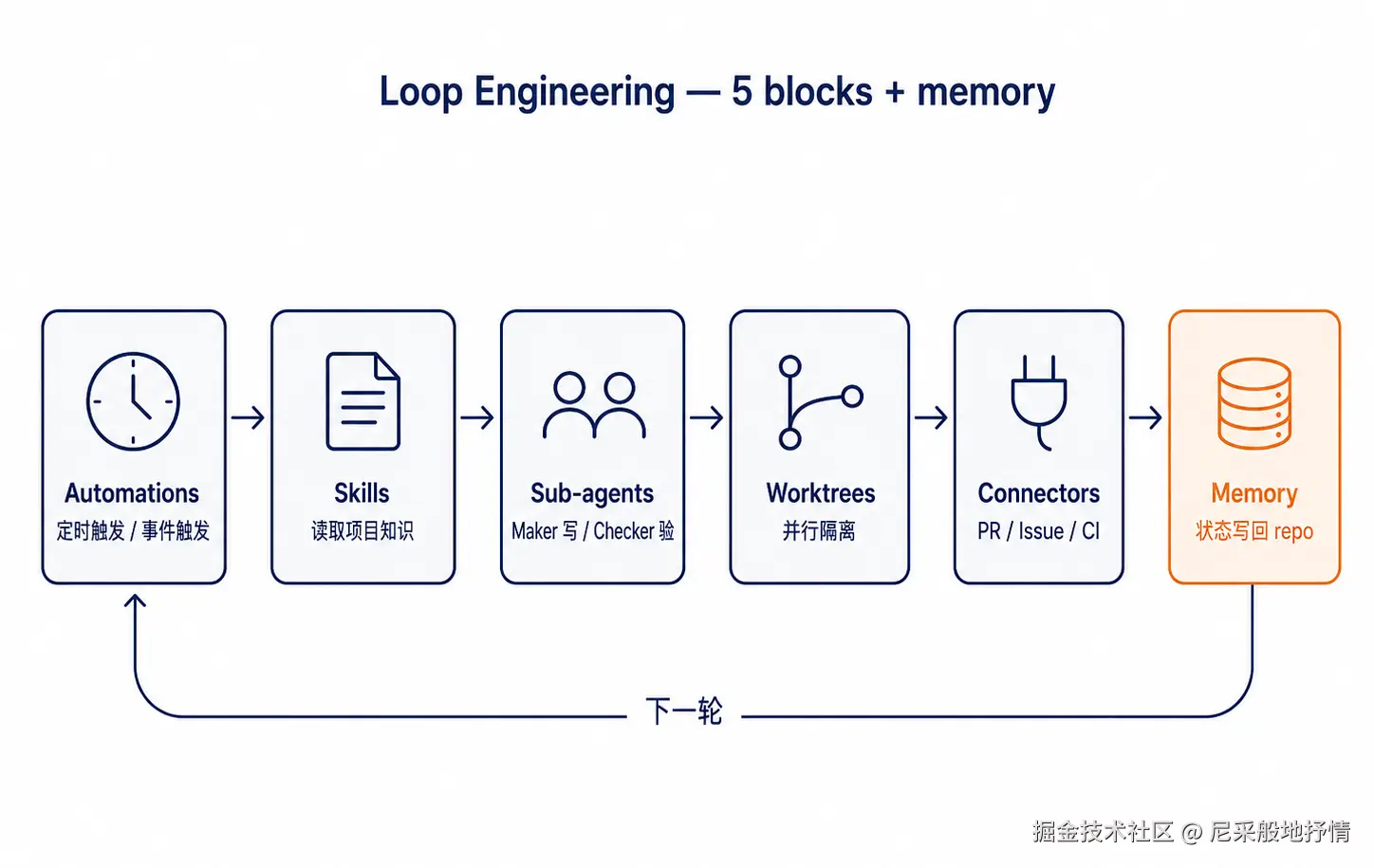
Osmani 列了五个能力,再加第六样------记忆。我按自己的理解重新映射一遍,并补上行业里其他实践。
自动触发:让循环真的是「循环」
没有定时或事件触发,你做的只是一次性自动化,不是 loop。
-
Codex:Automations 面板,选项目、prompt、频率、本地 checkout 或 background worktree;有发现进 Triage inbox,没发现自动归档。OpenAI 内部拿它做每日 issue 分拣、CI 失败摘要、commit briefing。
-
Claude Code :
/loop按间隔重跑;cron;hooks 在生命周期节点跑 shell;也可以推到 GitHub Actions 关电脑后继续跑。
更值得关注的是会话内的 /goal:不是跑 N 次就停,而是直到你写的完成条件为真 。每一轮结束后,另一个小模型 判断是否真的完成------写代码的不是判卷的那个。你给的条件比如:test/auth 全绿且 lint clean,然后走开。Codex 也有同名 /goal,支持暂停、恢复。
/goal 把「球员 / 裁判分离」嵌进了停止条件本身------这是 loop 能 unattended 运行的前提之一。
并行隔离:多 Agent 不互踩
两个 Agent 改同一个文件,和两个工程师没沟通就 commit 同一行一样灾难。Git worktree = 同一 repo 历史、独立工作目录、独立分支。Codex 内置多 thread;Claude Code 有 --worktree 和 subagent 的 isolation: worktree。
Worktree 解决的是机械碰撞 ;你能 review 多少 PR,才是实际上限------Osmani 称之为 orchestration tax(编排税)。
领域知识:别每轮当金鱼
Agent 每次会话都是冷启动。项目约定、构建步骤、「我们不用 X 因为上次事故」------不写进 skill,它就会用自信的错误猜测填空。Osmani 管这叫 intent debt(意图债)。
Skill 格式两边趋同:SKILL.md + 可选脚本/引用。Codex 用 $skill-name 调用;Claude Code 同理。没有 skill,loop 每轮从零推导项目;有了 skill,意图可以复利。
我自己维护的模板仓库里,.agents/skills/ 下已经堆了十几份 skill------不是装饰品,而是让 Agent 不用我重复讲第二遍 的硬约束。这和 Loop Engineering 是咬合的:循环跑得越久,外部记忆写得越值钱。
连接器:loop 要能碰真实世界
只能看文件系统的 loop 很小。MCP 让 Agent 读 issue tracker、查库、打 staging API、发 Slack。插件把 skill + connector 打包,队友一键装你的整套环境。
差别在于:Agent 说「这是修复方案」 vs loop 自己开 PR、更新 ticket、CI 绿了再 ping 频道。
子智能体:写的人别判自己的卷
Loop 里最有用的结构:maker 和 checker 分开 。Codex 在 .codex/agents/ 用 TOML 定义;Claude Code 在 .claude/agents/。常见分工:一个探索、一个实现、一个对照 spec 验证。
Loop 在你不看的时候跑,你信任的 verifier 才是你能走开的理由。代价是 token------每个子 Agent 各自烧一轮,只在「第二意见值这个钱」的地方花。
记忆:Agent 忘,仓库不忘
模型跨 run 会忘。状态必须落在对话外:markdown 状态文件、Linear 板、repo 里的 PROGRESS.md。听起来笨,却是所有长运行 Agent 的脊梁------记过什么、试过什么、还剩什么,明天早上 automation 从这里接着干。
拼起来:一个我认可的 loop 形状
Osmani 给了一个日常可用的模板,我觉得值得原样记住:
-
每天早上,automation 对 repo 跑 triage skill:读昨日 CI 失败、open issues、近期 commits,写入 markdown 或 Linear。
-
对每个值得做的 finding,开独立 worktree,sub-agent A 起草修复,sub-agent B 对照 project skills 和现有测试 review。
-
Connector 开 PR、更新 ticket;搞不定的进 triage inbox 等人。
-
状态文件是脊柱------明天从今天的断点继续。
你设计一次,没有一步是你当场 prompt 的。Codex 或 Claude Code 换哪个,积木是一样的。
行业里还有几条平行叙事,和上面五块是同一思想的不同切面:
实践
核心动作
可验证细节
Anthropic /loop
Issue 定时拉取 → 改代码 → 跑测 → 提 PR
Boris Cherny:「我的工作是为 Claude 写 loop」
Codex /goal
TDD 自治循环,测试全绿才停
消灭「已经为您写好」的完成幻觉
Karpathy AutoResearch
Verifier 打分 → 反馈带入下一轮
个人测试:2 天 700 轮,训练效率 +11%
Dynamic Workflow
流程不硬编码,运行时选模式
从固定死循环走向「看情况组 loop」
Loop Engineering 不是某一家工具的功能,而是应用层架构的自然演进------从优化单次输出,回到构建长生命周期自治系统。
Loop 变强了,有三件事反而更尖锐
Osmani 的警惕,我完全同意。Loop 改变的是工作方式,不会把你从工程责任里删掉。
第一,验收仍然是你。 Unattended loop = unattended 犯错。Verifier 让「完成了」更像一个 claim 而不是 proof。我常说的一句话:你的工作是 ship 你确认能跑的代码,不是 ship loop 声称能跑的代码。
第二,理解会腐烂(comprehension debt)。 Loop 越快产出你没写过的代码,「代码库里有什么」和「你脑子里有什么」的裂缝越大。顺滑的 loop 会加速这种腐烂,除非你主动读它产出的东西。
第三,认知投降(cognitive surrender)。 Loop 自己跑的时候,最容易停止有主见,loop 给什么就 merge 什么。设计 loop 可以是解药,也可以是逃避思考的加速器------同一个动作,相反结果。
还有 token 成本:富 token 和穷 token 的人,loop 策略完全不同。无人值守跑一夜,账单可能比你想象的大一截。
以及 slop:循环放大了产出速度,也放大了垃圾代码的体积。没有质量门禁的 loop,是在挖更深的坑。
两个人搭一模一样的 loop,结果可以截然相反------一个用来加速自己已理解的工作,一个用来逃避理解。Loop 分不清,你分得清。
我的最小实践建议
如果你今天只想动一步,我会建议从这个顺序开始,而不是一上来就「全自动修 bug」:
Step 1:先写 skill,再谈 loop。
把「每次都要重复解释的项目约定」写进一个 skill。这是意图债的还款。
Step 2:用 /goal 跑一个边界清晰的子任务。
完成条件写成可机器验证的:pnpm test:unit 全绿、某个 spec 文件通过。感受 maker/checker 分离的 stop condition。
Step 3:加一块磁盘记忆。
哪怕只是一个 loop-state.md:本次目标、试过什么、卡在哪。明天 automation 能接上,才算 loop。
Step 4:再考虑定时 automation。
从只读 triage 开始(CI 摘要、open issue 列表),不要第一天就 unattended 改 main 分支。
Step 5:人工验收留在关键节点。
我现在的平衡点:loop 负责找活、起草、跑测;merge 权在我。直接 prompt Agent 依然有效------不是非此即彼,是杠杆点迁移了。
Cherny 的意思不是工作变简单了,是杠杆点换了:从「写更好的 prompt」到「写更好的循环」。Loop design 比 prompt engineering 难,因为你要对完成条件、失败模式、token 预算和质量下限负责。
Build the loop. Stay the engineer.------设计循环,但像打算继续做工程师的人去设计,而不是像只按播放键的人。