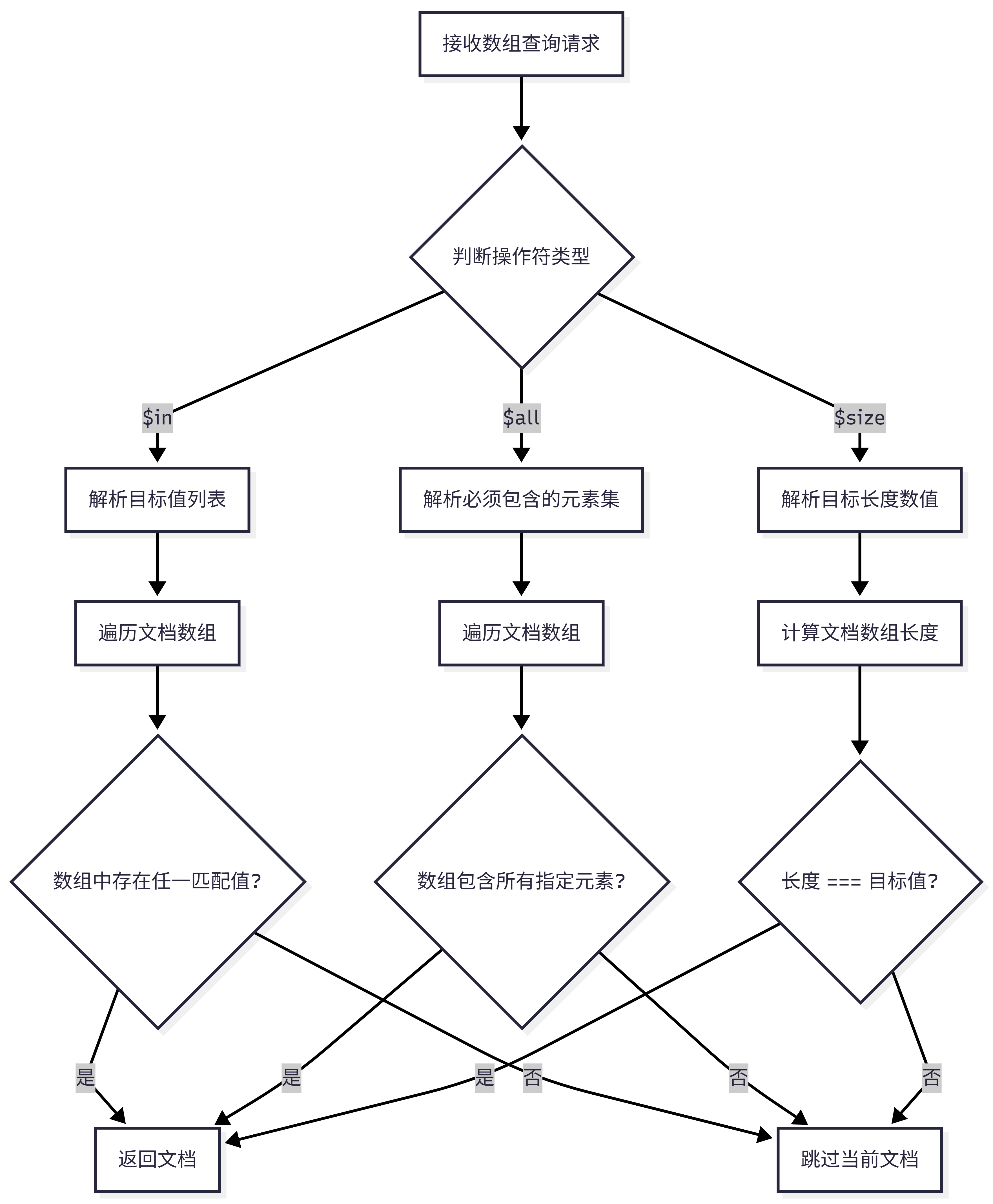
一、$in 操作符:数组元素的"或"匹配
核心机制 :当字段值为数组时,$in 操作符用于匹配数组中至少包含一个指定值的文档。其底层逻辑是"OR(或)"关系。
语法规范:
javascript
db.collection.find({ arrayField: { $in: ["value1", "value2"] } })执行逻辑 :MongoDB 引擎在扫描文档时,只要发现 arrayField 中存在任意一个元素等于 "value1" 或 "value2",即判定该文档匹配成功并返回。
适用场景:多标签筛选、多状态过滤(如查询状态为"待支付"或"已发货"的订单)。
二、$all 操作符:数组元素的"与"匹配
核心机制 :$all 操作符要求目标数组必须包含查询条件中指定的所有元素 。其底层逻辑是"AND(与)"关系,但不关心元素的顺序,且允许数组中包含多余的元素。
语法规范:
javascript
db.collection.find({ tags: { $all: ["tagA", "tagB"] } })执行逻辑:引擎会验证文档的 tags 数组是否同时存在 "tagA" 和 "tagB"。该操作符对元素的顺序不敏感,即使顺序颠倒(如 "tagB", "tagA"),或者数组中包含其他多余元素,只要两者皆在,依然匹配成功;但如果仅存在其中一个,则无法匹配。
适用场景:多权限校验、多标签交集查询(如查询同时拥有"管理员"和"审计员"权限的用户)。
三、$size 操作符:数组长度的精准匹配
核心机制 :$size 用于精准匹配数组中元素的个数。
语法规范:
javascript
db.collection.find({ hobbies: { $size: 3 } })⚠️ 核心限制与避坑 :
$size 仅支持精确的数值匹配 ,绝对不能与范围操作符(如 $gt, $lt, $gte)连用。例如,{ $size: { $gt: 2 } } 是非法的语法,会导致查询报错。如果业务需要查询"数组长度大于 N"的数据,必须借助聚合管道(Aggregation Pipeline),通过 $expr 和 $gt 配合 $size 来实现:
javascript
db.collection.aggregate([
{ $match: { $expr: { $gt: [{ $size: "$hobbies" }, 2] } } }
])性能警告 :$size 操作符无法利用索引 。在大数据量场景下,使用 $size 会触发全集合扫描(COLLSCAN),导致 CPU 飙升。生产环境中应慎用,或考虑在写入时冗余一个 arrayLength 字段并为其建立索引。
四、核心操作符对比与选型指南
为了更直观地理解这三者的差异,请参考下表:
| 特性维度 | $in |
$all |
$size |
|---|---|---|---|
| 匹配逻辑 | OR(满足其一即可) | AND(必须全部包含) | 精确数值匹配 |
| 顺序敏感 | 否 | 否 | 否 |
| 长度敏感 | 否 | 否 | 是 |
| 索引支持 | 支持(多键索引) | 支持(多键索引) | 不支持 |
| 典型场景 | 状态过滤、标签单选 | 权限交集、多标签全选 | 固定长度校验 |
| 性能表现 | 高(命中索引) | 中高(多键索引交集) | 极低(全表扫描) |
五、避坑指南
- 精确匹配 vs
$all的混淆 :直接使用{ tags: ["A", "B"] }是精确匹配,要求数组长度必须为 2,且顺序必须是 A 在前 B 在后。若只需包含 A 和 B 即可,务必使用$all。 - 警惕
$size的性能陷阱 :永远不要在千万级数据量的集合上对$size做条件过滤。架构设计时,若频繁按长度查询,应在应用层写入时计算好长度,存入独立字段并建索引。 - 对象数组的复合查询 :当数组元素是嵌套文档时,若需多个条件作用于同一个元素 ,必须使用
$elemMatch。切勿使用隐式 AND(如{"arr.a": 1, "arr.b": 2}),这会导致条件跨元素匹配,产生严重的脏数据查询结果。
实战演示:对象数组的复合查询与隐式 AND 陷阱
1. 构造测试数据
假设我们有一个 inventory(库存)集合,其中 instock 是一个嵌套文档数组,记录了不同仓库的库存情况:
javascript
db.inventory.insertMany([
{
item: "journal",
instock: [
{ warehouse: "A", qty: 5 },
{ warehouse: "C", qty: 15 }
]
},
{
item: "notebook",
instock: [
{ warehouse: "C", qty: 5 }
]
},
{
item: "paper",
instock: [
{ warehouse: "A", qty: 60 },
{ warehouse: "B", qty: 15 }
]
}
]);2. 需求:查找"仓库 A 且 库存数量小于 20"的记录
我们需要找到那些在同一个仓库(A)中,且该仓库的库存数量(qty)小于等于 20 的商品。
错误示范:使用隐式 AND(跨元素匹配)
很多开发者会习惯性地使用点表示法配合隐式 AND 来编写查询:
javascript
// 错误示范:隐式 AND 导致跨元素匹配
db.inventory.find({
"instock.warehouse": "A", // 只要数组中任意元素的 warehouse 为 A 即可
"instock.qty": { $lte: 20 } // 只要数组中任意元素的 qty <= 20 即可
});执行结果 :返回了 journal 和 paper。
灾难分析 :为什么 paper 会被查出来?我们来看 paper 的数据:instock: [ { warehouse: 'A', qty: 60 }, { warehouse: 'B', qty: 15 } ]。MongoDB 在处理这种点表示法时,是跨元素独立验证的:
- 验证
instock.warehouse == "A":找到了第一个元素{ warehouse: 'A', qty: 60 },条件满足! - 验证
instock.qty <= 20:找到了第二个元素{ warehouse: 'B', qty: 15 },条件满足!
因为这两个条件都在 instock 数组中找到了各自的匹配项(尽管它们根本不是同一个元素),所以 MongoDB 认为 paper 符合查询条件。这导致了严重的业务脏数据(paper 在仓库A的库存明明是60,却被当作小于20查出来了)。
正确做法:使用 $elemMatch 锁定同一元素
要确保 warehouse 和 qty 这两个条件作用于同一个嵌套文档 ,必须使用 $elemMatch:
javascript
db.inventory.find({
instock: {
$elemMatch: {
warehouse: "A",
qty: { $lte: 20 }
}
}
});执行结果 :仅返回 journal。
原理解析 :$elemMatch 强制 MongoDB 引擎在 instock 数组中,寻找至少一个元素 能够同时满足 warehouse == "A" 且 qty <= 20。对于 paper,没有任何一个单独的元素能同时满足这两个条件,因此被正确过滤掉。这从根本上杜绝了条件跨元素匹配的问题。
-
核心原则 :当你的查询条件涉及数组内嵌套对象的多个字段 ,且这些字段必须属于同一个对象 时,
$elemMatch是唯一的正确选择。 -
性能优化建议 :为了加速
$elemMatch的查询,建议为嵌套字段创建复合多键索引(Compound Multikey Index) 。例如:javascriptdb.inventory.createIndex({ "instock.warehouse": 1, "instock.qty": 1 });
六、实战演示:$in、$all 与 $size 的精准应用
构造一个包含商品标签和库存信息的 products 集合来进行测试。
1. 构造测试数据
javascript
db.products.insertMany([
{ item: "Gaming Laptop", tags: ["electronics", "gaming", "computer"], stock: },
{ item: "Office Desk", tags: ["furniture", "office"], stock: },
{ item: "Wireless Mouse", tags: ["electronics", "accessories", "gaming"], stock: },
{ item: "Notebook", tags: ["stationery", "office"], stock: }
]);2. 场景一:使用 $in 匹配"满足其一"的标签
业务需求:找出所有属于"电子产品(electronics)"或"家具(furniture)"分类的商品。
javascript
db.products.find({
tags: { $in: ["electronics", "furniture"] }
}, { _id: 0, item: 1, tags: 1 });执行结果 :返回 Gaming Laptop、Office Desk 和 Wireless Mouse。
原理解析 :只要 tags 数组中包含 "electronics" 或 "furniture" 中的任意一个,文档即被命中。
3. 场景二:使用 $all 匹配"必须全包含"的标签
业务需求:找出同时兼具"电子产品(electronics)"和"游戏(gaming)"属性的商品。
javascript
db.products.find({
tags: { $all: ["electronics", "gaming"] }
}, { _id: 0, item: 1, tags: 1 });执行结果 :返回 Gaming Laptop 和 Wireless Mouse。
原理解析 :Office Desk 虽然有 electronics 但没有 gaming,因此被过滤掉。$all 确保了交集查询的准确性。
4. 场景三:使用 $size 与聚合管道的长度过滤
业务需求 :找出库存批次(stock 数组)恰好有 2 个批次的商品,以及库存批次大于 1 个的商品。
精确匹配(使用 $size):
javascript
db.products.find({
stock: { $size: 2 }
}, { _id: 0, item: 1, stock: 1 });执行结果 :返回 Gaming Laptop 和 Wireless Mouse。
范围匹配(使用聚合 $expr):
javascript
db.products.find({
$expr: { $gt: [{ $size: "$stock" }, 1] }
}, { _id: 0, item: 1, stock: 1 });执行结果 :同样返回 Gaming Laptop 和 Wireless Mouse。
避坑提醒 :切勿尝试 { stock: { $size: { $gt: 1 } } } 这种写法,MongoDB 会直接抛出 BadValue 错误。范围查询必须交给聚合表达式 $expr 来处理。
七、高频面试题与硬核解答
Q1:在 MongoDB 中,查询数组长度大于 3 的文档,为什么不能直接用 { arr: { $size: { $gt: 3 } } }?正确的做法是什么?
答 :因为
$size操作符在 MongoDB 的设计规范中仅接受一个确切的整数参数,不支持任何查询操作符(如$gt、$lt)。正确的做法是使用聚合框架中的$expr操作符,结合$size和$gt进行表达式计算:db.collection.find({ $expr: { $gt: [{ $size: "$arr" }, 3] } })。
Q2:$all 和直接传入数组进行精确匹配有什么本质区别?
答 :本质区别在于对"长度"和"顺序"的容忍度。直接传入数组(如
{ tags: ["A", "B"] })要求文档中的数组必须与查询条件完全相等 ,即长度必须为 2,且元素顺序必须一致。而
$all: ["A", "B"]仅要求数组中至少包含 A 和 B,允许数组中存在其他元素,也不在乎 A 和 B 的先后顺序。
Q3:为什么生产环境不建议对数组字段频繁使用 $size 进行过滤?
答 :MongoDB 的多键索引(Multikey Index)是为数组中的具体元素值建立的,而不是为数组的长度建立的。因此,
$size查询无法命中任何索引,必然导致全集合扫描(COLLSCAN)。在数据量庞大时,这会引发严重的 CPU 瓶颈和 IO 抖动。最佳实践是在文档写入时,将数组长度作为一个冗余字段持久化,并对该冗余字段建立普通 B-Tree 索引。
Q4:当数组中存储的是嵌套对象时,使用 $in 或 $all 需要注意什么?
答 :当数组元素为对象时,
$in和$all默认要求对象的完整字段精确匹配 。如果只需要匹配对象中的部分字段,或者需要对数组内的单个对象应用多个复合条件(如score > 80 AND level = "VIP"),必须使用$elemMatch操作符,否则极易产生"条件分散在不同数组元素上"的虚假命中问题。