💫《博主主页》:
🔎 CSDN主页: 奈斯DB
🔎 IF Club社区主页: 奈斯、
🔥《擅长领域》:
🗃️ 数据库:阿里云AnalyticDB(云原生分布式数据仓库)、Oracle、MySQL、SQLserver、NoSQL(Redis)
🛠️ 云原生(数据库管控平台方向):K8s、Prometheus、Go、容器化调度、故障自愈、多集群管理
💖如果觉得文章对你有所帮助,欢迎点赞收藏加关注💖

有一件事想了两年。🗓️
记得第一次接触云数据库是2021年,点几下鼠标实例就出来了。当时只觉得:真快啊。 也没多想,用就完了。😶
但用久了,慢慢开始好奇:这东西背后到底怎么实现的?我能不能也搓一个?
然后2024年,我就开始认真开始琢磨这件事。深入了解才发现,云数据库背后依赖的是一整套云原生技术栈:容器化、容器编排、监控告警......这些我都不懂。😇没办法,DBA出身,Oracle、MySQL、Redis这些数据库本身还算熟,但容器、编排、微服务这些,完全是另一个世界。
于是开始补课: 先学Prometheus+Grafana监控,然后Docker,之后K8s,最后Go。📚学一点是一点,心里一直挂着这个事。从2024年到现在,刚好两年。
今年终于动手了。过去三个月,从零写了一个轻量RDS管控平台。
现在长什么样呢?核心链路已经能跑通, 测试环境和预生产都在跑着验证。但像高可用自动切换、按时间点恢复这些企业级能力还在完善,整体完成度我估40%~50%。😅
这篇文章就是复盘:做了什么、用了什么技术、哪里挖了坑、下一步填哪。
平台演示地址(轻点踩,服务器弱):
👉
http://www.rds-db.com
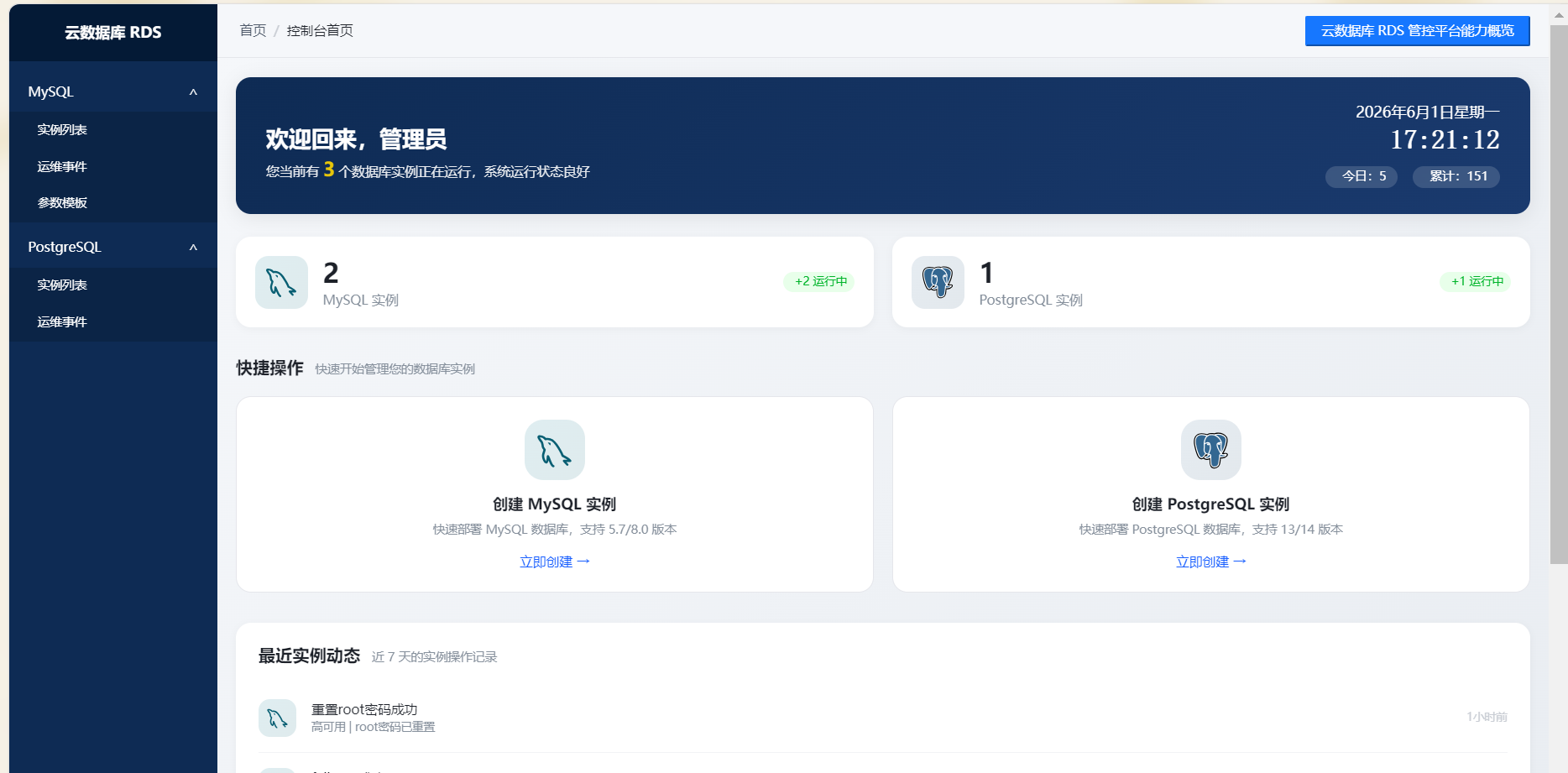
一、为什么写这个
作为DBA,对于Oracle、MySQL、Redis这些还算熟,主从复制、备份恢复、性能调优 算是看家本领。但云原生那套?K8s、Operator、Sidecar......对我来说完全是另一个世界。🌍
刚开始用云数据库那会,纯粹就是用户心态了,点几下就出来,好用、快,完事。😌
后来用多了,开始琢磨:它怎么做到这么快的?底层怎么调的?故障怎么切的?
然后发现,光懂数据库不够,还得懂容器、调度、监控那一整套。
于是从两年前开始,按这个顺序补课:监控→容器→编排→语言。一步步把短板补上,想着总有一天要把老本行(数据库)和新学的(云原生)串起来。🎯
今年终于下定决心,落地成这个项目。✅
二、技术栈
直接列我现在用的这套:
模块 技术栈 备注 前端 React + Ant Design 管理台交互,调用后端REST API 后端 Golang + Gin + GORM 业务逻辑、任务调度、K8s API交互 调度 K8s + client-go 数据库实例的创建、扩缩容、自愈 数据库 MySQL 8.0 + GTID 容器化运行,主从基于GTID复制 备份 XtraBackup + MinIO 全量物理备份,增量备份待完善 监控 Prometheus + Grafana 指标采集、存储、可视化展示 左右拉动查看完整表格 ⬅️➡️
三、核心能力(做到哪算哪)
1. 实例生命周期(大概65%)
能干啥: 创建、删除、重启、改密码。底层K8s StatefulSet。
还缺啥: 在线改规格做了一半,有时候状态同步会乱。克隆实例还没开始。
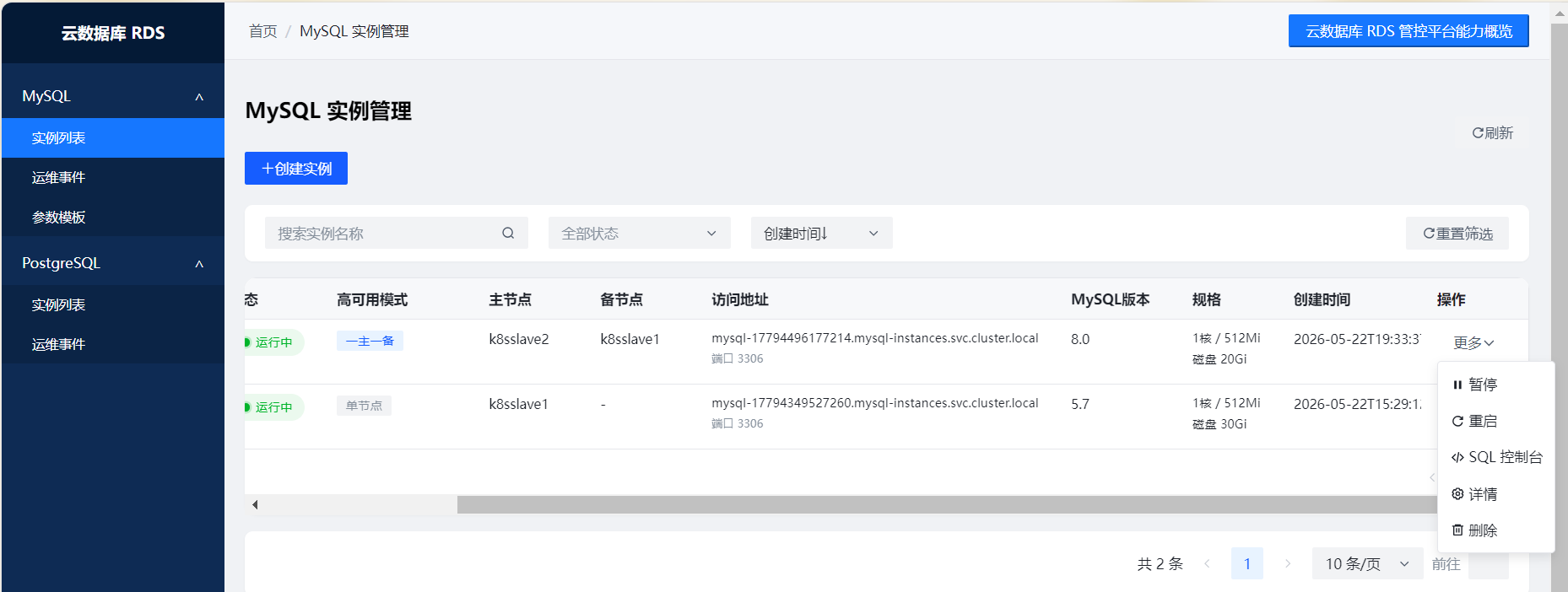
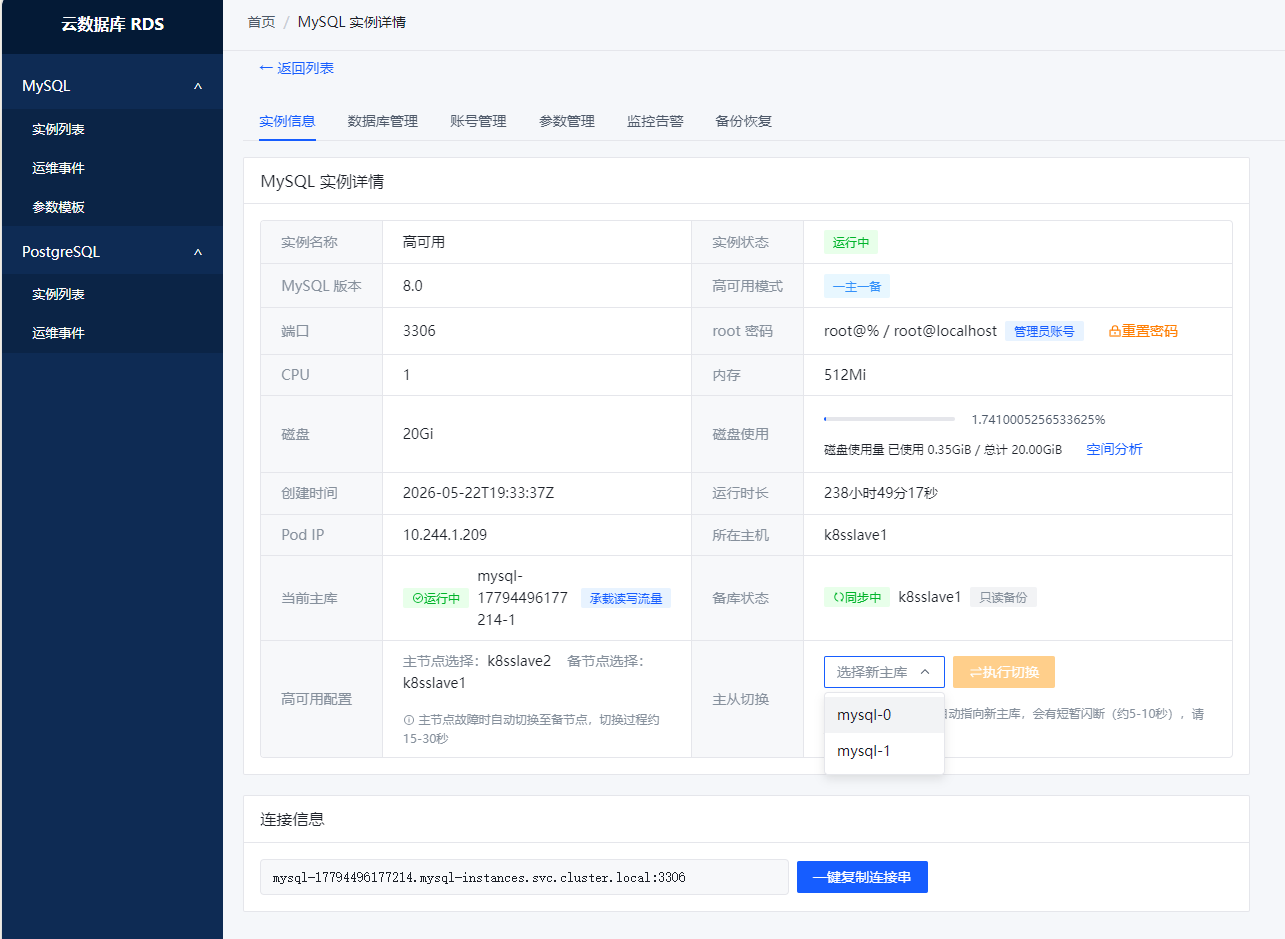
2. 高可用主从(大概35%)
能干啥: 一主一从部署、主从切换(手动/自动都行)。从库挂了能自动重建,主库挂了也能自动切,探活这块已经调稳了。
还缺啥: 切是能切,但切完之后的业务恢复通知不够优雅------目前是靠轮询,没有做回调。另外跨机房部署的场景还没验证过。
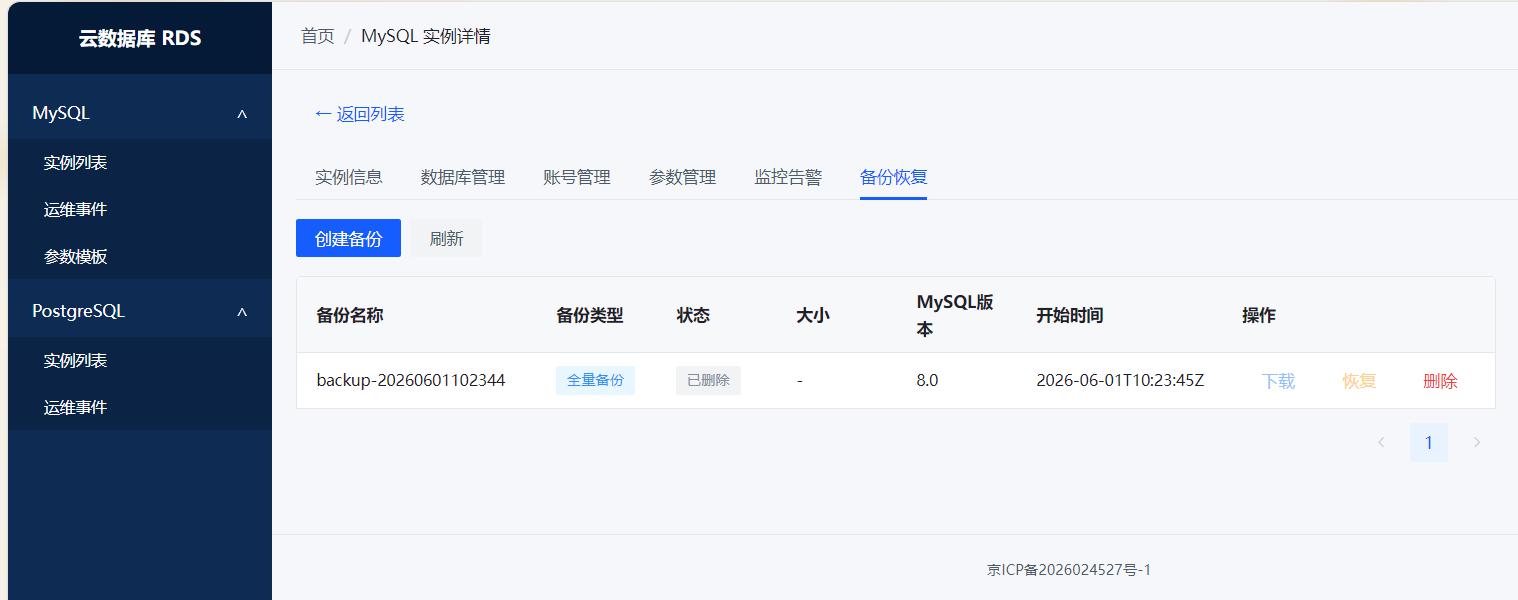
3. 备份恢复(大概45%)
能干啥: 定时全量备份到MinIO、从全量备份恢复。
还缺啥: 增量binlog备份通了但不稳,按时间点恢复能跑通但边界情况会翻车。这俩是下一步重点。
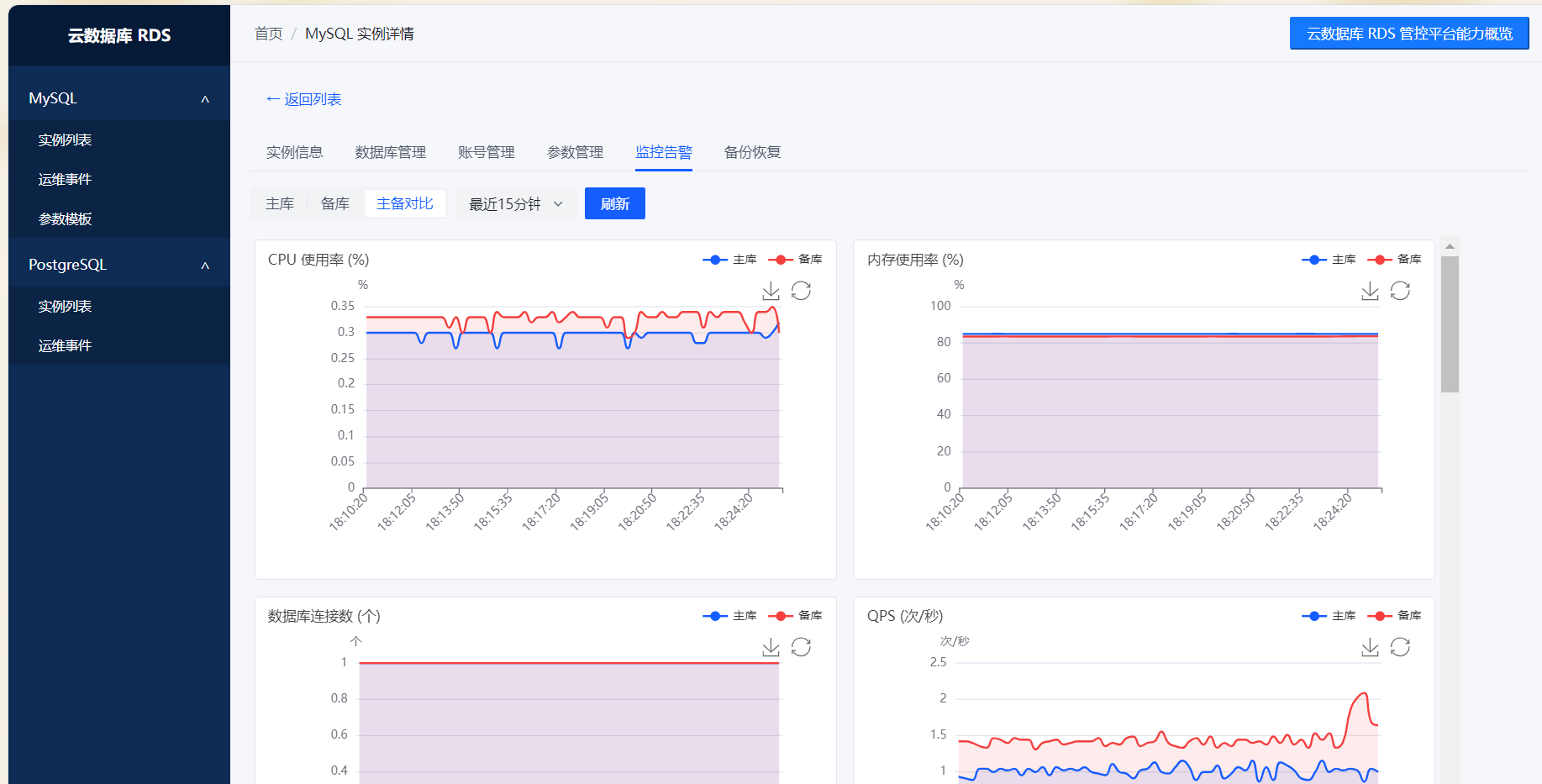
4. 监控告警(大概60%)
能干啥: QPS、连接数、慢查询、复制延迟都有,Grafana面板看着挺唬人。简单告警(实例挂了、延迟高了)也能发。
还缺啥: 告警规则还不够细,有时候误报或漏报。
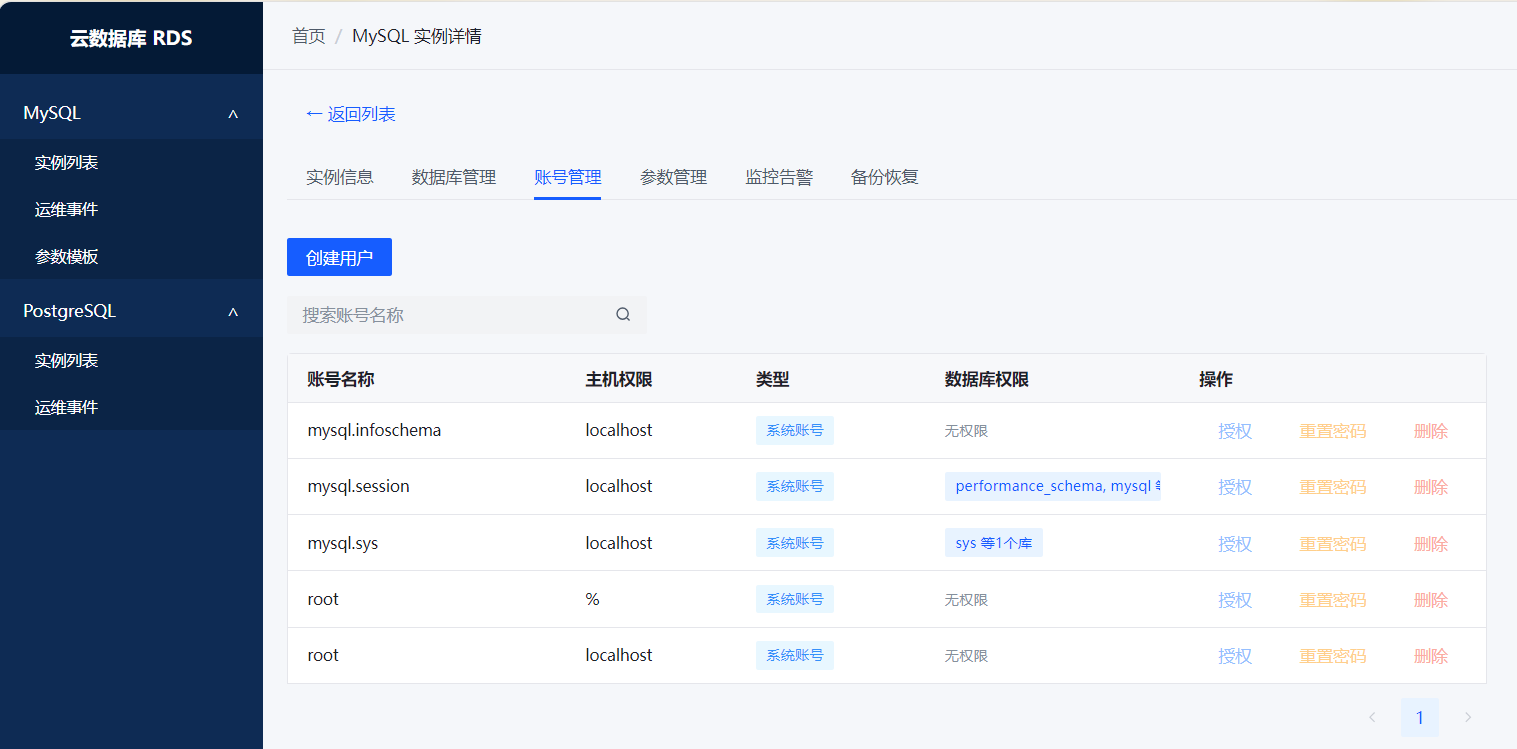
5. 账号权限(大概80%)
能增删账号、改密码、授权到库。表级别权限还没做,白名单也没有。基本够开发环境用。
6. 只读实例(大概20%)
能加只读节点,但读写分离层还没接。现在要读从库得手动改连接。优先级不高,往后放。
四、遇到的坑
说实话,第一次写遇到的坑还有很多很多,基本上一步一卡。😩
挑三个典型的说:
坑一:K8s里MySQL主从切换
切一次出一次问题。
后来老老实实加了Sidecar,做GTID位点校验,先降级旧主再提新主。现在手动切是稳的,自动还在磨。
坑二:PITR的位点对齐
全量备份记录一个位点,binlog从那个位点往后应用。
说起来简单,但容器重启后路径变了、binlog文件顺序乱了,各种幺蛾子。现在能跑,但代码里一堆TODO。
坑三:前端调后端,后端调K8s,超时了咋办?
方案比较粗暴:提交后立刻返回"操作已提交",结果异步查。
体验不丝滑,但不报错就算赢了。
五、接下来打算填的坑
按优先级排:
- 自动故障切换------ 把探活和决策引擎磨稳定
- PITR稳定性------ 把边界情况补上
- 读写分离接入------ 接个ProxySQL,让读流量自动走从库
- 部署文档------ 写个Helm Chart,方便别人本地跑
- 混沌测试------ 杀节点、断网,看系统会不会崩
远期画饼, 支持Redis、审计日志等等。
六、写在最后
其实我也不是非得等做完才发。😅
做到这个程度,核心链路能跑了,测试和预生产也在验证,我觉得就可以拿出来说一说了。剩下的企业级功能边做边补,反正坑就在那里,早晚要填。
发出来的好处是: 逼自己不能烂尾,收到的反馈能及时用到开发里,也给同样在坑里的同学一个活生生的参考。
接下来会继续肝,会继续完善成生产级别。如果你也在做类似的东西,欢迎交流、吐槽、一起踩坑。🍻
地址再贴一次: 👉
http://www.rds-db.com挂了就是我在改代码,隔半天再刷就行。
感谢看完。👋