
在人工智能应用真正进入行业现场时,最有价值的项目往往不是只展示一个炫目的模型能力,而是把"数据、训练、推理、接口、前端体验"完整串起来。这个水果识别与问答系统,正是一个非常典型的人工智能落地场景:用户上传一张水果图片,系统可以识别水果类别;用户继续提出问题,模型还能结合图片内容进行中文回答;同时项目支持本地模型服务部署,便于在私有环境中验证和扩展。
它看起来是一个轻量的水果识别项目,背后却覆盖了当前 AI 工程实践中非常热门的几项能力:千问 Qwen2.5-VL 多模态大模型、LoRA/QLoRA 微调训练、4bit 量化加载、Flask API 服务化、本地部署以及前后端演示系统。对于希望理解"大模型如何从 Demo 走向可用系统"的团队来说,这类项目非常适合作为学习、展示和二次开发的样板。
一、为什么选择 Qwen2.5-VL 做多模态底座
传统图像分类模型通常只回答"这是什么",而多模态大模型的价值在于,它既能看图,也能理解自然语言问题。项目使用 Qwen/Qwen2.5-VL-3B-Instruct 作为基础模型,相当于为系统提供了一个已经具备图像理解、视觉推理和中文对话能力的底座。
在实际体验中,这意味着系统不只局限于输出"芒果""红苹果""葡萄"这样的类别名称。它还可以进一步回答用户的问题,例如"这张图里的水果适合怎么保存?""图片中的水果有什么营养特点?""为什么判断它是香蕉?"这让项目从单点识别能力升级为图文问答能力,也更贴近真实业务中的交互方式。
更重要的是,Qwen2.5-VL 这类视觉语言模型具备良好的通用知识和中文表达能力。项目不需要从零训练一个庞大的视觉模型,而是在通用多模态能力之上叠加业务数据,让模型更懂当前场景。这正是大模型落地的主流路线:不是每个行业都重新造一个基础模型,而是基于成熟大模型进行轻量化适配。
二、用 QLoRA 把通用模型训练成"水果识别专家"

项目的数据集采用清晰的目录结构:dataset/类别名/图片。当前共包含 10 类水果,分别是哈密瓜、椰子、樱桃、火龙果、猕猴桃、红苹果、芒果、葡萄、西瓜和香蕉,总计 1525 张图片。训练时按类别切分,训练集、验证集、测试集分别为 1223、151、151 张,避免某些类别只出现在训练集或测试集中。
微调方式采用 LoRA/QLoRA,这是当前大模型私有化训练中非常常见的技术组合。项目以 4bit NF4 方式加载基础模型,通过 bitsandbytes 降低显存占用,再使用 PEFT 的 LoraConfig 注入可训练的低秩参数。LoRA 配置为 r=16、lora_alpha=32、lora_dropout=0.05,目标模块覆盖注意力层的 q_proj、k_proj、v_proj、o_proj,以及 MLP 中的 gate_proj、up_proj、down_proj。
这种方案的优势很明显:基础模型主体保持稳定,只训练少量 Adapter 参数,训练成本和保存成本都更低;后续部署时也只需要加载基础模型并挂载 LoRA adapter,就能获得面向水果识别任务的专门能力。项目最终在测试集上达到 99.34% 的准确率,即 151 张测试图片中正确识别 150 张。这说明在一个边界清晰、数据质量可控的垂直场景中,通用多模态大模型经过轻量微调后,可以快速形成可靠的业务能力。
三、本地部署:从 Notebook 到可访问服务
很多 AI 项目停留在 Notebook 阶段,能训练、能推理,但没有真正进入"用户可访问"的系统形态。这个项目的亮点之一,是把训练后的模型继续封装为本地 Flask 服务,并配套提供前端页面,让模型能力可以被普通用户直接调用。
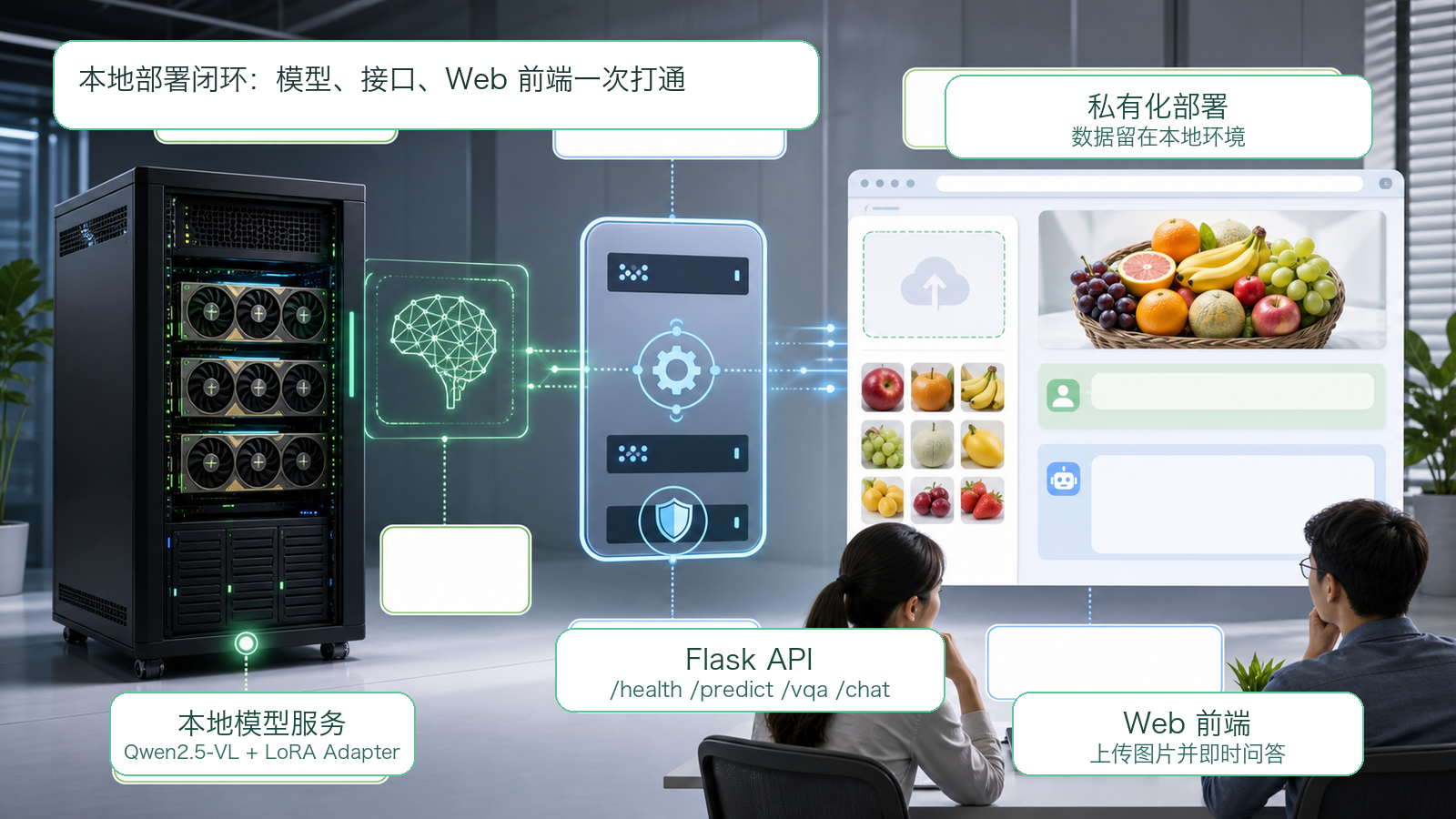
后端服务启动时会加载基础模型目录 Qwen2.5-VL-3B-Instruct,再挂载训练得到的 qwen2_5_vl_3b_fruit_lora adapter。推理侧同样支持 4bit 量化加载,并根据 GPU 能力选择 bf16 或 fp16,以降低部署门槛。为了避免每次请求重复加载模型,服务启动后会复用同一个模型实例,并通过锁控制推理请求。
接口设计也非常清晰:/health 用于检查模型服务、GPU 和类别信息;/predict 用于上传图片并返回水果分类;/vqa 用于上传图片并提出图文问题;/chat 则支持纯文本问答,例如水果营养、保存方式和食用建议。前端采用 Flask 模板、Bootstrap、jQuery 与 AJAX,用户只需填写模型接口地址,就可以在页面中完成图片上传、分类识别和问答交互。
这套结构体现了一个完整 AI 应用的基本闭环:Notebook 负责实验和训练,LoRA adapter 承载业务增量,Flask API 负责服务化,Web 前端负责交互体验。模型可以部署在本地 GPU 服务器,也可以通过内网 API 提供给多个业务页面调用,符合企业私有化验证的常见需求。
四、一个小场景,映射大模型落地方法论
水果识别只是一个切口,但它对应的工程路径具有很强的可迁移性。把"水果"换成农产品分拣、商超货架识别、工业零件质检、药品包装核验、教学实验素材分析,整体方法并不会发生根本变化:先收集领域图片和标签,再基于多模态大模型做 LoRA 微调,最后通过本地服务和业务前端交付给用户。
相比传统方案,这类项目的优势不只是识别准确率。它还具备自然语言交互能力,用户可以围绕图片继续追问;它支持私有化部署,敏感图片不必上传到外部平台;它能通过 Adapter 快速切换场景,便于在多个垂直任务之间复用基础模型能力。
对于企业和开发者来说,这个项目的意义在于把大模型落地拆成了可理解、可复现的几个环节:数据准备、QLoRA 微调、指标评估、模型挂载、API 封装、Web 调用。每一个环节都不神秘,但组合起来就形成了一个真正可以演示、验证和扩展的 AI 系统。