中国电信 TeleAI 开源 KungfuBot / PBHC 框架分析笔记
主题:类人行为驱动的人形机器人全身运动控制框架
主要对象:
KungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills与开源仓库TeleHuman/PBHC整理时间:2026-06-14
结论先行:这不是一个"大模型直接控制机器人跳舞"的项目,而是一套"人类动作数据 -> 物理约束动作处理 -> 机器人动作重定向 -> 强化学习全身模仿控制 -> 仿真/真机部署"的端到端运动技能学习框架。
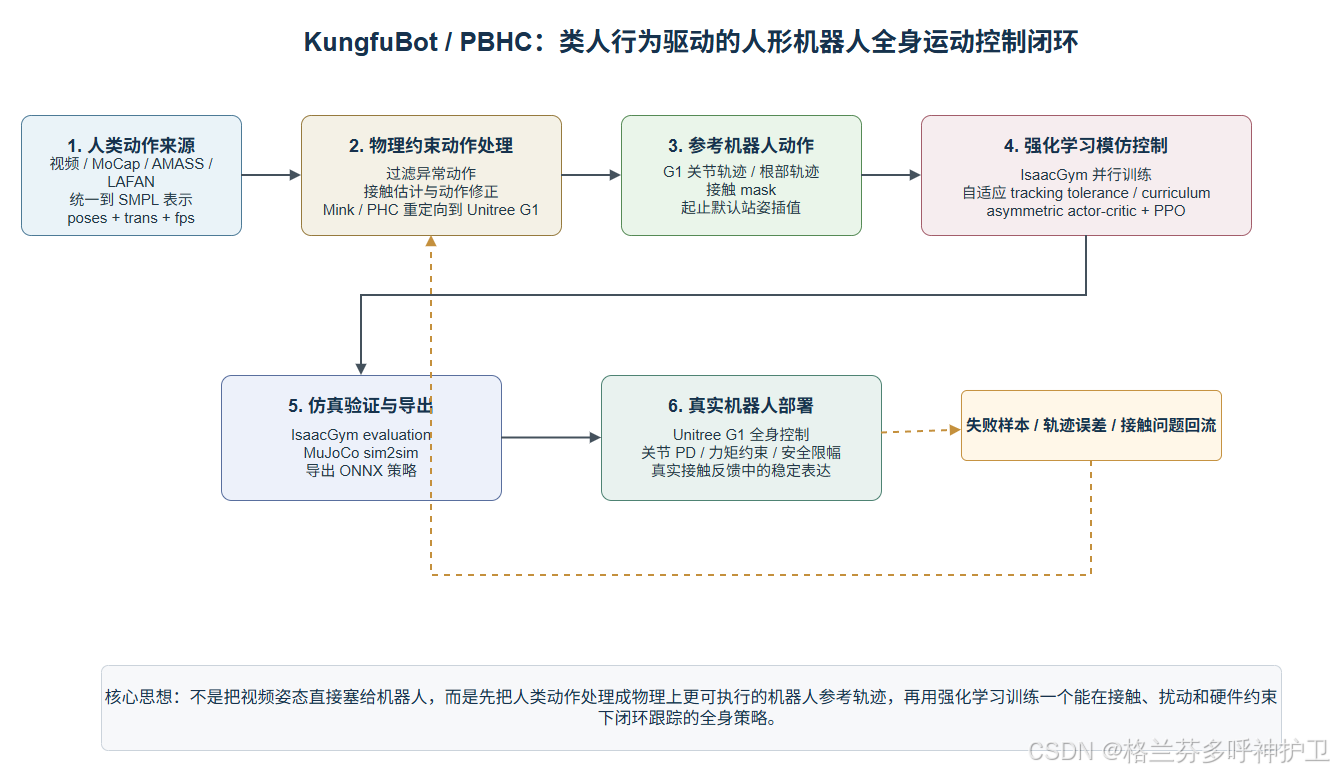
1. 项目是什么
中国电信人工智能研究院 TeleAI 参与开源的这一框架,在论文和仓库中主要称为 KungfuBot 或 PBHC ,全称可理解为 Physics-Based Humanoid Control 。官方论文题目是 KungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills ,作者机构包含 Institute of Artificial Intelligence (TeleAI), China Telecom 。仓库为 TeleHuman/PBHC,README 称其为该论文的官方实现,并在后续加入对 KungfuBot2 通用动作跟踪工作的支持。
这个框架的目标是让人形机器人通过模仿人类动作学会高动态全身技能,例如武术、舞蹈、跳踢、转身、马步等。它的核心难点在于:视频或人体动作捕捉数据本身并不等于机器人能执行的动作。人和机器人身体结构不同,关节自由度不同,腿长、质量分布、关节限位、脚底接触、力矩能力都不同;高动态动作还会出现飞行相、快速转身、单脚支撑、踢腿、手脚协同等复杂接触状态。因此 PBHC 把问题拆成两段:
- 先把人类动作处理成尽可能满足物理约束的机器人参考动作。
- 再训练一个闭环策略,使机器人在仿真和真机中稳定跟踪这些参考动作。
这也是它被称为"类人行为驱动"的原因:动作技能的目标来自人类行为数据,而不是工程师手写每个步态、姿态和轨迹。
2. 一句话架构
text
视频 / AMASS / MoCap / LAFAN
-> SMPL 人体动作统一表示
-> 动作过滤、接触估计、物理修正
-> SMPL 到 Unitree G1 的动作重定向
-> 机器人参考动作可视化、插值、质量检查
-> IsaacGym 中训练强化学习模仿策略
-> IsaacGym / MuJoCo 验证
-> 导出 ONNX,接入真机部署模块它本质上是一套 数据管线 + 运动重定向工具 + 强化学习训练框架 + sim2sim/real 部署接口,而不是单一控制算法。
3. 开源工程长什么样
根据官方仓库 README,PBHC 当前开源内容主要包括以下模块:
| 模块 | 作用 | 关键点 |
|---|---|---|
motion_source/ |
从视频、AMASS、LAFAN 等来源收集动作,并统一到 SMPL 格式 | 视频动作提取使用 GVHMR;SMPL 数据含 poses、trans、mocap_framerate 等字段 |
smpl_retarget/ |
将 SMPL 人体动作重定向到机器人 | 支持 Mink 与 PHC 两条 pipeline;论文实验主要使用 Mink |
smpl_vis/ |
可视化 SMPL 动作 | 用于检查人体动作本身是否合理 |
robot_motion_process/ |
可视化、插值、分析重定向后的机器人动作 | 支持参考动作与策略 rollout 轨迹对比,也支持在部署前补默认站姿插值 |
humanoidverse/ |
强化学习策略训练、评估和部署 | 基于 IsaacGym 训练;支持 MuJoCo sim2sim;可导出 ONNX |
description/ |
SMPL 与 Unitree G1 机器人描述文件 | 机器人模型、关节和仿真资产的基础 |
example/ |
示例动作和预训练 checkpoint | 官方提供如 Horse-stance pose 示例 |
安装环境方面,官方测试环境包括 Ubuntu 20.04、NVIDIA RTX 4090、Python 3.8、IsaacGym Preview 4。训练命令中常见配置是 num_envs=4096,调试可降到 128;论文实验每个动作训练约 50000 iterations。
4. 为什么需要"动作处理管线"
直接从视频提取的人体姿态有三类问题:
- 视觉重建误差:视频人体重建模型可能在遮挡、快速运动、转身、脚底接触处出错。
- 人体-机器人差异:SMPL 是人体模型,机器人是带关节限位、固定足底形状、特定质量分布和特定自由度的机械系统。
- 物理不可执行:人体动作看起来合理,不代表机器人能在重力、摩擦、力矩和接触约束下稳定执行。
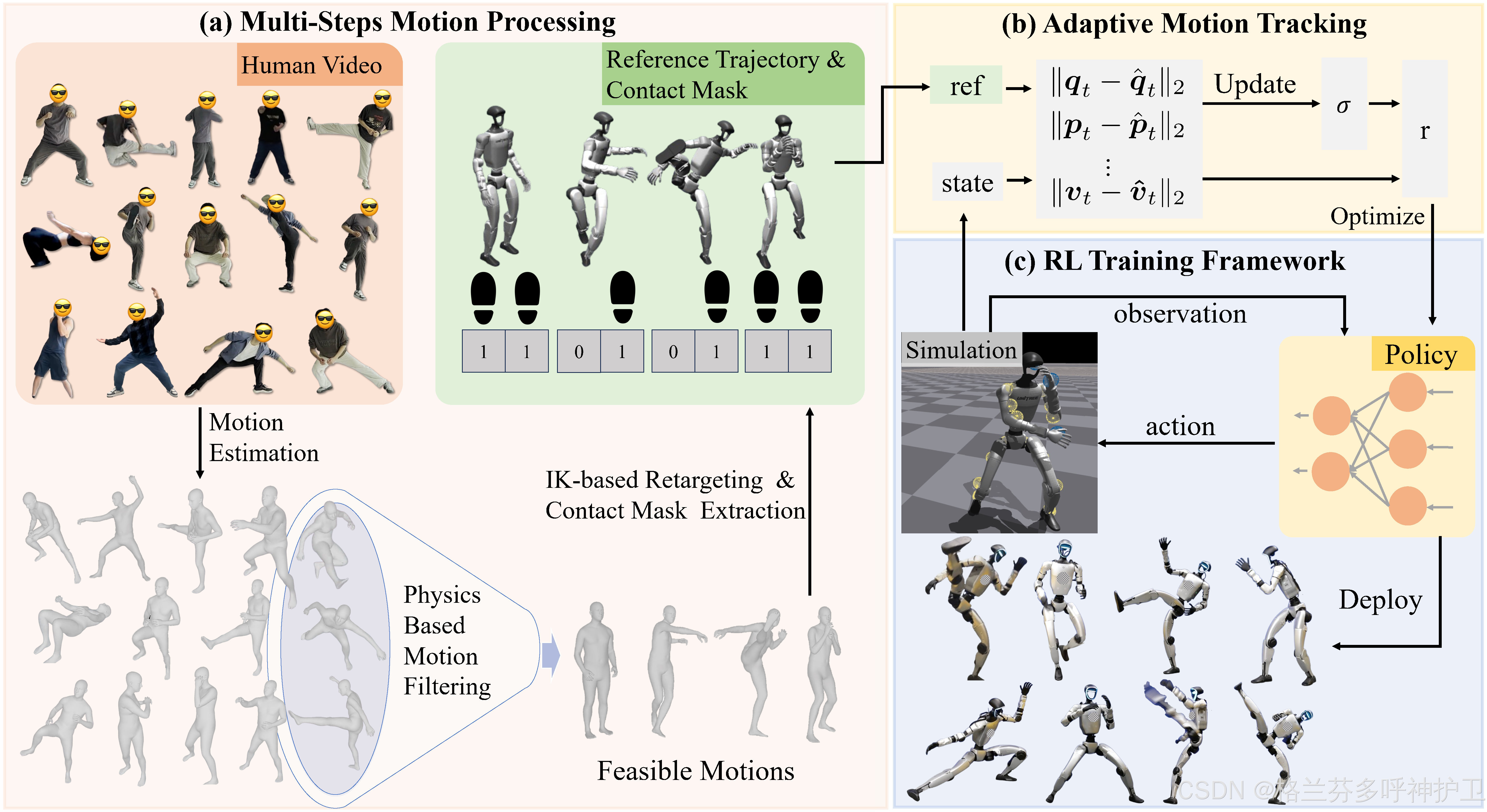
PBHC 因此设计了多阶段 motion processing pipeline:
text
原始动作
-> 提取到 SMPL
-> 过滤异常动作
-> 估计脚底/身体接触状态
-> 修正不合理接触和轨迹
-> 重定向到机器人关节空间
-> 可视化检查
-> 插入默认站姿过渡其中 接触 mask 很关键。高动态动作最难的部分往往不是关节角本身,而是"什么时候哪只脚应该支撑、什么时候离地、什么时候落地"。接触状态错了,策略很容易学到滑步、穿地、摔倒或力矩异常。
5. 重定向:从人到 G1 机器人
PBHC 以 Unitree G1 为主要测试平台。重定向的目标是把 SMPL 人体动作转换为机器人可跟踪的参考轨迹,通常包括:
- 根部位姿和速度;
- 机器人各关节角;
- 关键刚体位置;
- 接触 mask;
- 动作帧率和时间序列;
- 起止过渡姿态。
仓库中提供两类重定向路线:
| 路线 | 技术特点 | 适合理解 |
|---|---|---|
| Mink pipeline | 基于微分逆运动学,将人体关键点/姿态映射到机器人 | 更像"在线求解一个符合约束的机器人姿态序列" |
| PHC pipeline | 基于梯度优化的人体到机器人 motion fitting | 更像"通过优化让机器人轨迹拟合人体动作" |
官方 README 说明两者都可用,结果会有差异;论文实验使用 Mink pipeline。工程上,重定向不是越像人越好,而是在"动作表现力、物理可执行性、机器人结构限制"之间做折中。比如人类可以脚尖、脚掌、膝盖、髋部非常灵活地配合,但 G1 的自由度、足底形状、关节力矩边界会限制最终动作。
6. 强化学习模仿控制
重定向之后,PBHC 并不是直接播放关节轨迹。直接播放属于开环控制,遇到接触误差、地面摩擦差异、关节延迟、模型误差时容易失稳。PBHC 训练的是一个闭环策略:
text
当前机器人状态 + 参考动作相位/目标
-> 策略网络
-> 关节目标或控制量
-> 低层 PD / 执行器控制
-> 机器人状态反馈
-> 下一步修正这类策略的价值是:它不是死板复现每一帧,而是在尽量贴近参考动作的同时,学会维持平衡、处理接触、吸收扰动、补偿模型误差。
6.1 自适应动作跟踪
论文的一个核心贡献是 Adaptive Motion Tracking。直觉上,如果一开始就要求策略严格贴合高动态动作,训练信号会过于苛刻,策略很可能学不起来;如果一直放得太松,动作又会变形,机器人只能稳定但不像人。
PBHC 的做法是把跟踪奖励中的容忍度动态调节:
- 当当前跟踪误差大时,放宽跟踪精度要求,让策略先学会不摔倒和大体动作结构;
- 当策略逐渐跟上后,再收紧容忍度,让动作细节更接近参考;
- 这个机制相当于自动 curriculum learning,不完全依赖人工设计训练阶段。
用工程语言说,它解决的是"高动态动作模仿训练中,奖励太难与太软之间的矛盾"。
6.2 非对称 Actor-Critic
论文还采用 asymmetric actor-critic。一般可理解为:
- actor 是最终部署到机器人上的策略,输入必须尽量接近真机可获得的信息;
- critic 只在训练时使用,可以拿到仿真中的 privileged information,帮助估值更准确、训练更稳定;
- 训练完成后部署 actor,不部署 critic。
这是一种常见的 sim-to-real 强化学习手法。它既利用仿真器中的丰富状态帮助训练,又避免真机部署依赖无法实时获得的信息。
6.3 低层控制与全身控制
PBHC 的"全身控制"不是传统意义上手写 QP-WBC 控制器,而是通过学习策略统一输出全身关节控制目标,再由低层控制器执行。它关注的是:
- 腿部支撑、摆动和落脚;
- 躯干姿态与质心稳定;
- 手臂和上身的动作表达;
- 根部运动与全身姿态协调;
- 接触切换中的稳定性;
- 关节限位、速度、力矩和安全约束。
因此它更接近"学习型全身运动策略",而不是"解析模型控制器"。不过在真实系统中,低层 PD、关节安全限幅、急停、安全区域仍然是必需的工程保护层。
7. 训练、评估与部署流程
官方仓库给出的典型训练流程如下:
- 准备动作数据,例如视频、AMASS 或 LAFAN。
- 转换到 SMPL 格式。
- 使用
smpl_retarget/将动作重定向到 G1。 - 用
robot_motion_process/可视化并检查动作质量。 - 在
humanoidverse/中用 IsaacGym 训练 motion tracking policy。 - 用
eval_agent.py在 IsaacGym 中可视化评估。 - 用
sample_eps.py或ratio_eps.py输出轨迹、跟踪精度、episode 长度等指标。 - 导出 ONNX。
- 用 MuJoCo 做 sim2sim 验证。
- 接入真机部署模块,并加安全约束后上机器人。
真机部署部分,仓库 README 特别强调应先做 sim2sim 测试,并在真实机器人上加入关节限位、速度/加速度上限、力矩约束、急停按钮、安全围栏和低速初始试验。这一点很重要:高动态动作策略的"能跑"不等于"可以直接上真机表演"。
8. 和传统控制方案的区别
| 维度 | 传统 WBC / MPC / 手写步态 | PBHC / KungfuBot |
|---|---|---|
| 动作来源 | 工程师设计轨迹、步态库、任务优化目标 | 人类动作数据驱动 |
| 控制形式 | 显式动力学模型、优化求解、规则约束 | 强化学习策略 + 低层控制 |
| 优势 | 可解释、约束清晰、安全边界更容易分析 | 动作表现力强,能覆盖复杂全身技能 |
| 难点 | 高动态复杂动作设计成本高 | 训练成本高,sim2real 和安全验证难 |
| 典型场景 | 稳定行走、站立、推拉、移动操作 | 武术、舞蹈、复杂姿态模仿、技能库扩展 |
更准确地说,PBHC 不是替代所有传统控制,而是在"复杂类人动作技能"这一类问题上,用数据和学习方法降低手工设计成本。未来实际产品中,很可能是混合架构:基础行走、站立保护、安全边界由传统控制保障,复杂动作技能由学习策略提供。
9. 技术亮点
9.1 把动作数据工程化
很多 humanoid imitation 论文只展示训练结果,但 PBHC 开源了较完整的数据处理链路:视频提取、SMPL 统一、过滤、修正、重定向、可视化、插值。这使它更像一个可复用的动作技能生产线。
9.2 面向高动态动作
论文强调已有方法更擅长平滑、低速动作,PBHC 目标是高动态技能。高动态动作对接触、惯性、身体姿态、落地冲击都更敏感,因此它比普通 locomotion tracking 更接近"技能级全身控制"。
9.3 自适应 tracking tolerance
自适应跟踪机制把训练难度随学习进度调整,减少手工 curriculum 设计。对高动态动作来说,这比固定奖励尺度更稳。
9.4 开源范围相对完整
PBHC 不只给训练脚本,也给了 motion source、retarget、visualization、training、evaluation、sim2sim、example checkpoint。对研究者和工程团队来说,这比单个 policy demo 更有参考价值。
10. 关键局限
- 硬件门槛高:官方测试环境包含高端 NVIDIA GPU 和 IsaacGym。普通开发机难以完整复现大规模训练。
- 平台绑定明显:开源实现以 Unitree G1 为主要机器人模型。迁移到其他人形机器人,需要重新建模、重定向、限位配置和训练。
- 真机部署不是开箱即用:仓库提供接口思路,但真实机器人部署模块仍需开发者根据硬件实现。
- 安全验证成本高:高动态动作天然有跌倒、撞击、过力矩风险,必须有机械保护、场地保护和控制保护。
- 非商业许可证:仓库 README 标注代码采用 CC BY-NC 4.0,不可用于商业用途,例如商业产品广告 demo。
- 动作质量强依赖上游数据:视频提取质量、接触估计、重定向结果都会影响最终策略。输入动作越脏,后续训练越难。
11. 对机器人"大脑-小脑"架构的启发
如果把机器人系统分成大脑、小脑和身体,PBHC 更像"小脑运动技能学习框架":
- 大脑负责选择任务和技能,例如"打一段武术动作""做舞蹈动作""执行某个展示动作"。
- PBHC 这类小脑策略负责把技能变成稳定的全身运动。
- 身体层负责关节伺服、传感反馈、电机保护和急停。
它还不解决完整任务规划、视觉语义理解、自然语言交互和复杂操作决策问题。但它补上了人形机器人非常关键的一环:如何从人类行为数据中生产可部署的全身运动技能。
12. 如果要复现,建议路线
建议不要一上来就训练高动态武术动作,而是按难度递进:
- 跑通官方安装与 IsaacGym 示例。
- 用官方
example/pretrained_horse_stance_pose做 evaluation。 - 用 MuJoCo sim2sim 跑官方导出的 ONNX。
- 可视化官方 sample motion,理解 motion 数据格式。
- 选择一个低速、短时、接触简单的动作重新 retarget。
- 用
num_envs=128做调试训练,确认 reward 和 rollout 正常。 - 再扩大到
num_envs=4096和更长训练。 - 只在 sim2sim 通过后,再考虑真机部署。
对工程团队而言,最值得先吸收的不是"让机器人打功夫",而是这条动作技能生产流程:
text
动作采集 -> 物理清洗 -> 机器人重定向 -> 闭环策略训练 -> 仿真验证 -> 安全部署这条流程可以迁移到舞蹈、康复动作、工业示教动作、体育训练动作、展示动作库等方向。
13. 总结
PBHC / KungfuBot 的价值在于,它把人形机器人的动作技能学习从"单个炫技 demo"推进到"可复用的开源工程流程"。它以人类动作作为技能来源,通过物理约束动作处理和机器人重定向,把不可直接执行的人体动作变成机器人参考轨迹;再通过自适应强化学习模仿训练,得到能在接触和扰动中闭环跟踪的全身策略。
它目前更适合研究、验证和技能库构建,不适合未经安全改造直接商业部署。真正落地时,需要把它与传统稳定控制、安全监控、任务规划和真机工程保护结合起来。
参考资料
- 论文:KungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills,arXiv:2506.12851,v1 提交于 2025-06-15,v2 修订于 2025-10-27。
- 项目页:https://kungfu-bot.github.io/
- GitHub 仓库:TeleHuman/PBHC
- 仓库 README:PBHC README
- 安装说明:PBHC INSTALL.md
- 动作来源说明:motion_source README
- 重定向说明:smpl_retarget README
- 策略训练与部署说明:humanoidverse README