1. 一个多线程的性能问题
咱们直接上码,先整一个诡异场景。假设我们有俩全局计数器,两个线程各玩各的,疯狂自增:
c++
struct Counters
{
std::atomic<long long> counter1{ 0 };
std::atomic<long long> counter2{ 0 };
};
Counters counters; // 全局,两个计数器紧挨在一起
void hammer_counter(int id)
{
auto& c = (id == 0) ? counters.counter1 : counters.counter2;
for (int i = 0; i < 100'000'000; ++i) {
c.fetch_add(1, std::memory_order_relaxed);
}
}
int main()
{
using clock = std::chrono::high_resolution_clock;
auto start = clock::now();
std::thread t1(hammer_counter, 0);
std::thread t2(hammer_counter, 1);
t1.join();
t2.join();
auto end = clock::now();
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << "Time: " << ms << " ms\n";
std::cout << counters.counter1 + counters.counter2 << "\n";
}逻辑上,这俩线程完完全全不共享任何数据,各自的 fetch_add 只是碰了不同变量。我们使用 GCC 编译后(-O2)然后跑一跑,耗时1849 ms,自以为还行。但如果我们给其中一个计数器塞一个 alignas(64) 把它俩物理隔开,再跑一次后时间能直接腰斩,直接降到 347 ms。惊不惊喜?意不意外?
这就是 false sharing(伪共享),代码逻辑上没有共享,但硬件上它们挤在同一条 cache line 里,硬生生造出了事实上的共享。
现代 CPU 的缓存一致性是以 cache line(通常 64 字节)为最小管理单元的。我们那俩 atomic<long long> 各占 8 字节,编译器把它们舒舒服服排一起,整条 cache line 就被这俩家伙共同占据。
核心 0 修改 counter1 时,它的 L1 缓存会把整条 line 标记为 Modified;核心 1 的缓存里哪怕只缓存了 counter2,也会被一致性协议无情地 pass 掉。等核心 1 想写 counter2 时,它得先从核心 0 那儿把最新的 line 撸过来,延迟直接炸穿。
这整个过程,我们两个线程表面上没通信,但缓存子系统在背后疯狂地相互使绊子,每次写操作都触发一次 cache line 的乒乓传输,总线带宽和内联通信开销直接把我们的多线程优势吃得渣都不剩。
2. 现代 CPU 的存储结构
先放张存储结构金字塔图:
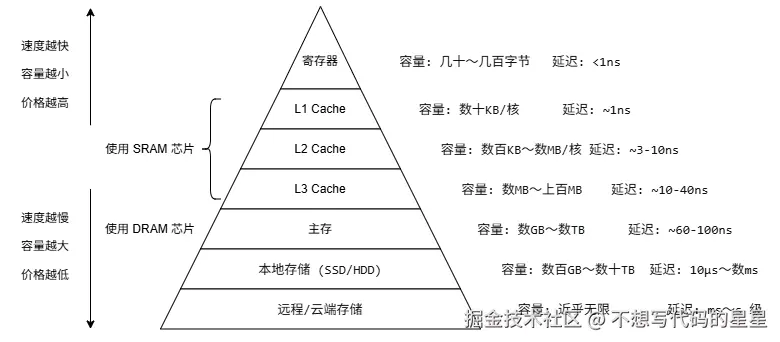
缓存层次与缓存行
先从最表面看:CPU 跑得太快了,DRAM 太慢。为了让这两者别天天互相干瞪眼,于是在中间塞了 SRAM 做缓存,并且搞成了金字塔:L1 极快但极抠门,L2 大一点但也慢一点儿,L3 再大再慢,最后才是主存。
这个层次结构有一个核心设计决策,几乎所有后来的怪现象都来源于此:数据在缓存和主存之间不是逐字节搬运的,而是以固定大小的块为单位,这个块就叫 cache line,绝大多数现代 CPU 上是 64 字节。
我们哪怕只想要某个 int 的第 3 个 bit,CPU 也会满脸不情愿地把周围 63 个邻居字节全部拽上,一起塞进缓存。
为什么?因为空间局部性:程序访问一个地址后,大概率会访问相邻地址。但问题是如果两个核心各自只想要这 64 字节里不同的小变量,这个设计立刻变成灾难。我们动自己的 8 字节,它动它的 8 字节,在逻辑上是完全隔离的,但物理上它们隶属于同一个 cache line。CPU 的缓存控制逻辑不看变量名,只看行号,所以它会认为我们在争抢同一行数据。
由此,这俩变量就被迫绑定了:任何一方的修改,都将触发整行的所有权转移。这就是为什么说 CPU 的记忆力像条金鱼,它只记得 64 字节的块,完全分不清块里面谁是谁。我们在软件层面辛辛苦苦做了隔离,它硬件层面啪一下又给粘回去了,还顺便收我们一笔小费。
缓存一致性协议(MESI)
多个核心的 L1/L2 缓存是私有的,同一块主存数据可能在多个核心的私有缓存里都有副本。某个核心修改了自己的那份副本后,其他核心里的过期数据怎么办?让程序员自己管?那多核编程的难度就真上天了。
于是硬件工程师们发明了监听式一致性协议,其中最著名的就是 MESI 及其变种MESIF、MOESI 等。MESI 把一条 cache line 的生命划分为四种状态,每一个状态都代表一种平衡:
- Modified(修改) :这行数据只在当前核心的缓存里,而且被改过,与主存不一致。它是这条线唯一的拥有者。其他核心想要读或写这行,必须得求它把数据吐出来。
- Exclusive(独占) :这行数据只在当前核心的缓存里,但和主存一致,干干净净。它是唯一拥有者,可以随时自由地修改它,一旦修改就跳转成 Modified,不需要通知任何人。不过一旦它感知到有其他核心在总线窥探想要读这行,就得不情不愿地降级成 Shared。
- Shared(共享) :这行数据可能在多个核心的缓存里,而且都和主存一致,谁都没改过。多个核心可以和平地读,但谁想写就必须先把自己状态提升成 Exclusive 或 Modified,这就意味着要发消息把其他核心里的 Shared 拷贝全部干掉,也就是 Invalid 广播。
- Invalid(无效) :这行所在的缓存行就是一张废纸,不可用。要读要写都得从其他核心或主存重新掏数据。
放一张 MESI 状态转换图:
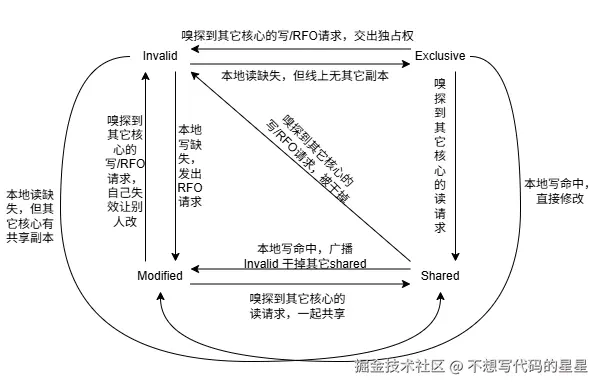
现在来看看我们那个伪共享的例子里,两个 atomic 变量紧挨着,挤在同一条 cache line 上。线程 A 在核心 0 写 counter1,线程 B 在核心 1 写 counter2:
- 初始可能两个核心都持有该行的 Shared 副本(假如之前读到过)。
- 核心 0 想写 counter1:它必须先把行状态变成 Exclusive/Modified。于是它往总线上发一个 RFO,告诉所有核心:"这行我要独占修改,你们手里的副本全给我标 Invalid!" 其他核心照办,核心 0 拿到 Modified 行,写入 counter1。
- 就在核心 0 刚写完,还没捂热乎,核心 1 也想写 counter2。但它的缓存行现在是 Invalid,于是它得发一个信号:"我要这行,而且我要改!" 一致性协议强行把核心 0 的 Modified 行写回或直接转发给核心 1,核心 0 被迫把状态降级为 Invalid。核心 1 得到行,置为 Modified,然后写 counter2。
- 然后核心 0 又要写下一次 counter1,自己的行又 Invalid 了,于是重复步骤 2......
所以每个核心的每次写,都会让对方的缓存行当场作废。这种 Invalid 往返,哪怕我们只是在写一个逻辑上毫无瓜葛的变量,结果也是双方的 cache line 像乒乓球一样在两个核心的 L1/L2 之间疯狂弹跳。
这就是所谓的 cache line bouncing,每一次弹跳都意味着几十个 CPU 周期的延迟,而我们可怜的 fetch_add 每次都在等这趟往返。我们以为自己在做无锁、无竞争的高性能并行,实际上造了一个硬件级别的读-写锁,而且还是每个操作都要加解锁的那种。
所以缓存一致性协议这东西,本质上是为了多核时代能普适性地跑正确,献祭了极端情况下的性能。而我们唯一能做的,就是不要让它觉得两个变量在同一条 cache line 里有任何关系------用 padding、用对齐把我们逻辑上不共享的数据,物理上也给拆散。
一些示例
我们整几个小示例看看。
1. 并发累加全局数组
c++
constexpr size_t CACHE_LINE = 64; // 64 字节
constexpr size_t NUM_THREADS = 4;
constexpr size_t ITERATIONS = 10'000'000;
// 问题版
struct FalseSharing
{
std::atomic<long long> value{ 0 };
};
struct BadCounters
{
FalseSharing counter[NUM_THREADS]; // 直接堆在一起
};
// 修复版
struct alignas(CACHE_LINE) PaddedCounter
{
std::atomic<long long> value{ 0 };
// 填充到一条缓存行
char padding[CACHE_LINE - sizeof(std::atomic<long long>)];
};
struct GoodCounters
{
PaddedCounter counter[NUM_THREADS]; // 每个都对齐到缓存行边界
};
template<typename CountersType>
void run_test(const char* description)
{
CountersType counters;
auto worker = [&counters](int id) {
for (size_t i = 0; i < ITERATIONS; ++i) {
counters.counter[id].value.fetch_add(1, std::memory_order_relaxed);
}
};
auto start = std::chrono::high_resolution_clock::now();
std::vector<std::thread> threads;
for (size_t i = 0; i < NUM_THREADS; ++i)
threads.emplace_back(worker, i);
for (auto& t : threads) t.join();
auto end = std::chrono::high_resolution_clock::now();
long long total = 0;
for (size_t i = 0; i < NUM_THREADS; ++i)
total += counters.counter[i].value.load();
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << description << ": " << ms << " ms, total = " << total << "\n";
}
int main()
{
run_test<BadCounters>("Bad (false sharing) ");
run_test<GoodCounters>("Good (padded) ");
}运行输出(因环境不同,数据仅供参考):
Bad (false sharing) : 471 ms, total = 40000000
Good (padded) : 88 ms, total = 40000000
跑出来的时间差还蛮大的,我们把线程数调到 8,差距会更大些。
问题在于 BadCounters::counter 是个数组,每个原子变量只有 8 字节,四个凑一起 32 字节,还得捎带上旁边的邻居,整行被四个线程同时踩踏。每次 fetch_add 都捅一次 MESI 马蜂窝。
修复版的就是逼每个计数器独占一条缓存行,alignas 保证起始地址,char padding\[\] 把剩下的字节填满,让缓存子系统再也没法找茬。这是最暴力也是最直接的策略。
2. 无锁队列中的小坑
这个坑比较阴险,因为它藏在我们精心实现的无锁队列里。假设一个简化版的多生产者多消费者队列,用头尾索引管理环形缓冲区:
c++
// 坏版本:head 和 tail 紧贴在一起
struct BadQueue
{
static constexpr size_t QSIZE = 256;
std::atomic<size_t> head{ 0 };
std::atomic<size_t> tail{ 0 };
int buffer[QSIZE];
// 假入队、出队操作,只是疯狂修改索引
void enqueue() { tail.fetch_add(1, std::memory_order_relaxed); }
void dequeue() { head.fetch_add(1, std::memory_order_relaxed); }
};
// 好版本:把热点的 head 和 tail 用填充隔开
struct GoodQueue
{
static constexpr size_t QSIZE = 256;
alignas(64) std::atomic<size_t> head{ 0 };
alignas(64) std::atomic<size_t> tail{ 0 };
int buffer[QSIZE];
void enqueue() { tail.fetch_add(1, std::memory_order_relaxed); }
void dequeue() { head.fetch_add(1, std::memory_order_relaxed); }
};
template<typename Q>
void run_bench()
{
Q q;
constexpr size_t OPS = 50'000'000;
auto enqueuer = [&]() {
for (size_t i = 0; i < OPS; ++i) q.enqueue();
};
auto dequeuer = [&]() {
for (size_t i = 0; i < OPS; ++i) q.dequeue();
};
auto start = std::chrono::high_resolution_clock::now();
std::thread t1(enqueuer);
std::thread t2(dequeuer);
t1.join();
t2.join();
auto end = std::chrono::high_resolution_clock::now();
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << "Time: " << ms << " ms, head=" << q.head << ", tail=" << q.tail << "\n";
}
int main()
{
std::cout << "Bad queue: ";
run_bench<BadQueue>();
std::cout << "Good queue: ";
run_bench<GoodQueue>();
}最后输出:
Bad queue: Time: 1516 ms, head=50000000, tail=50000000
Good queue: Time: 515 ms, head=50000000, tail=50000000
多生产者单消费者或者多消费者场景里,队列的头尾索引是被不同角色频繁更新的。当它们住在同一条缓存行时,生产者的 tail++ 会让消费者的缓存行失效,消费者的 head++ 同样回敬一脚。队列本身没竞争,但索引的伪共享制造了巨大的竞争幻象。
修复版就是给头尾各来一个 alignas(64),还有些著名无锁库会故意把消费者端的元数据和生产者端的元数据分别放在不同的缓存行,或者不同的页上。
3. 线程池工作项分配中的伪共享
线程池里,每个工作线程通常有自己的状态,比如处理了多少个任务。我们可能会搞个全局数组记录这些统计:
c++
struct ThreadState
{
std::atomic<size_t> tasksCompleted{ 0 };
// 一些其他热更新字段
};
// 不良:线程状态数组紧密排列
struct BadPool
{
static constexpr size_t THREADS = 8;
static constexpr size_t TASKS_PER = 10'000'000;
ThreadState states[THREADS]; // 线程状态全部紧挨
void worker(size_t id)
{
for (size_t i = 0; i < TASKS_PER; ++i) {
states[id].tasksCompleted.fetch_add(1, std::memory_order_relaxed);
}
}
};
// 良好:每个线程状态对齐到缓存行
struct alignas(64) PaddedThreadState
{
std::atomic<size_t> tasksCompleted{ 0 };
char pad[64 - sizeof(std::atomic<size_t>)];
};
struct GoodPool
{
static constexpr size_t THREADS = 8;
static constexpr size_t TASKS_PER = 10'000'000;
PaddedThreadState states[THREADS];
void worker(size_t id)
{
for (size_t i = 0; i < TASKS_PER; ++i) {
states[id].tasksCompleted.fetch_add(1, std::memory_order_relaxed);
}
}
};
template<typename Pool>
void run_pool()
{
Pool pool;
std::vector<std::thread> threads;
auto start = std::chrono::high_resolution_clock::now();
for (size_t i = 0; i < Pool::THREADS; ++i)
threads.emplace_back(&Pool::worker, &pool, i);
for (auto& t : threads) t.join();
auto end = std::chrono::high_resolution_clock::now();
auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
size_t total = 0;
for (size_t i = 0; i < Pool::THREADS; ++i)
total += pool.states[i].tasksCompleted.load();
std::cout << "Time: " << ms << " ms, total=" << total << "\n";
}
int main()
{
std::cout << "Bad thread pool: ";
run_pool<BadPool>();
std::cout << "Good thread pool: ";
run_pool<GoodPool>();
}程序输出:
Bad thread pool: Time: 847 ms, total=80000000
Good thread pool: Time: 127 ms, total=80000000
8 个线程疯狂更新各自的任务计数,看起来天各一方。但 ThreadState 每个才 8 字节,8 个紧密排列才 64 字节,正好挤满一条缓存行。每个线程写自己的计数器,相当于 8 个核心同时在那条缓存行上拉锯,MESI 直接把我们的多核变成单核广播电台。
修复后每个状态独占一行,8 个核心各写各的行,互不干涉,性能瞬间回到线性加速该有的样子。这种场景在真实线程池、事件循环里比比皆是,我们只要看到每个线程频繁更新的状态字段,哪怕是统计用,也需要给它们分配独立缓存行。
检测和定位 False Sharing
1. perf c2c
perf c2c 是 perf 工具集里的共享缓存行分析器,能精确到哪一行代码、哪个数据结构、在哪个核心上。
使用方法不算复杂,但输出比较多。典型工作流:
bash
# 采集数据:-g 会记录调用图,数据量较大,可酌情使用
perf c2c record -a -g -u ./test
# 生成报告
perf c2c report --stdio报告一出来,我们会看到一张巨大的表格,里面塞满各种 HITM、L1d 命中/缺失、跨核心访问的统计。我们需要盯住的关键指标是 HITM(Hit Modified):某个核心想去读或写一行,结果这行在另一个核心的缓存里是 Modified 状态,必须从那边拽过来。HITM 越高,说明缓存行在两个核心间弹跳得越狠,伪共享的嫌疑就越大。
perf c2c 会直接指给我们引发冲突的源代码行和数据结构偏移,我们可能会看到这样的输出:
test
30.91% 59.41% 0x5fa2b5b544a9 [.] BadQueue::dequeue() test BadQueue::dequeue()+43
69.09% 40.59% 0x5fa2b5b54475 [.] BadQueue::enqueue() test BadQueue::enqueue()+47这样就能直接定位到问题所在处。不过 perf c2c 好是好,但它的 --stdio 输出分析起来还是蛮头疼的,-g 记录调用栈也会让数据文件膨胀得飞快。
2. 常规计数器与采样
如果没有 c2c,或者我们的 CPU 架构不支持,那就得回归原始:盯着硬件计数器的异常波动,再结合采样定位热点。
第一步,先用 perf stat 看几个核心指标:
bash
perf stat -e cache-references,cache-misses,\
L1-dcache-loads,L1-dcache-load-misses,\
context-switches,cpu-migrations \
./test一个健康的多线程程序,如果线程间没有真共享,cache-misses 不应该随着线程数线性暴涨。伪共享的特征是:
- L1-dcache-load-misses 异常高,远高于预期。
- cache-references 和 cache-misses 比率惊人,可能接近 50% 或者更高。
- context-switches 和 cpu-migrations 却低得可怜,这说明开销不来自内核调度,全来自硬件缓存协议。
第二步,用采样找出热点指令:
bash
perf record -e cache-misses -g ./test
perf report然后我们能看到 BadQueue::dequeue() 这类东西异常的高,按常理来说 relaxed 原子操作不应该这么贵,但它偏偏贵了,这就是硬件在替我们加戏。看到这种现象,我们基本可以宣判伪共享有罪,只是还不知道具体是哪两个变量搅在一起的。
所以这种方法只能告诉我们有伪共享,不能精准告诉我们"谁和谁"。还是得对着自己的结构体定义,开始猜谜。
3. 二分填充法实验
当所有工具都让我们失望,或者我们只是想亲手处决伪共享以获得快感时,可以上终极手段:二分填充法。思路很简单:在可疑数据结构里,有策略地插入 padding,看性能是否突变。
具体操作:
- 确认性能问题的存在:跑一次基准测试,记下时间 T_bad。
- 把我们怀疑被伪共享的热点字段,在它们之间塞入大块 padding(比如 128 字节),重跑一次。如果时间大幅下降,说明确实有伪共享,进入第三步;要是怀疑错对象了,换一组字段。
- 逐步减少 padding,看看性能拐点在哪里。比如,先从 128 字节开始,然后减到 64,再减到 32,直到性能又开始下降。那个临界点就是对方缓存行大小真实生效的地方,也就确认了伪共享的边界。
- 最后,根据临界点精确设计 padding,或者用 alignas 直接对齐到那个值。
就先写个伪代码,感兴趣的也可以实操一下:
c++
struct Suspect
{
std::atomic<size_t> a;
// padding 变量
char pad[PADDING_SIZE];
std::atomic<size_t> b;
};
// 分别用 PADDING_SIZE = 0, 8, 16, 32, 64, 128 编译并测试我们经过测试会得到一组性能数据,然后画个图:X 轴是 padding 大小,Y 轴是执行时间。当 padding 小于 CPU cache line 大小时,时间会保持在高位,因为还在同一行;一旦 padding ≥ cache line 大小,时间会断崖式下跌。那个断崖的边沿,就是我们的 CPU 真实的缓存行大小。
二分法最坑的地方不是它笨,而是它暴露了某些平台缓存行大小根本不固定。假如我们在一台 ARM 大小核的板子上这么测,可能会发现在大核上 64 就够,小核上 128 才安全,而标准库那个宏返回的是 64。最终只能向 128 妥协,虽然浪费了一倍的缓存,但至少性能回来了。
常见陷阱
1. 伪共享与假阳性
先说一个让我想起就胃疼的概念:假阳性(false positive)。在伪共享的语境里,假阳性指的是:我们检测到两个变量有缓存行冲突,我们花大力气把它们隔开了,跑完测试一看------性能纹丝不动,甚至更差。为什么?因为那点冲突根本就不是瓶颈,我们杀了个替罪羊。
伪共享的性能影响是有门槛的。如果两个核心只是偶尔碰一下相邻变量,MESI 协议的无效化开销可能被其他计算完全掩盖,我们几乎观测不到。真正致命的伪共享必须具备以下条件:
- 写入频率极高:每个核心都在疯狂 fetch_add 或写入,每秒百万次起跳。偶尔写一次的配置变量,就算挤在一行也没事。
- 冲突窗口密集:一个核心刚写完,另一个核心马上要读或写,时间上紧密衔接。如果两个核心的写入时间错开了,比如一个线程工作 10ms,另一个线程 10ms 后才开始,缓存行早就被写回或自然过期了,根本弹跳不起来。
- 涉及的变量必须在不同核心的私有缓存之间反复迁移。如果它们都落在同一个 L2 共享缓存里(比如大小核架构下的共享 L2),冲突可能只停留在 L2 内部,不产生跨核心的 Invalid 消息,开销大大降低。
很多人拿着 perf c2c 看到一个 HITM 就叫伪共享,然后疯狂 padding,最后发现时间只降了 1%,这就是典型的假阳性。过度填充会增加内存占用,导致缓存命中率反而下降。我们把本来可以装进同一缓存行的冷数据也拆开了,结果缓存里塞满了无用的 padding 字节,有用的数据被踢出去了,这种优化叫负优化。
真正需要动手的信号是:perf stat 看到 L1 缓存 miss 率 > 5% 且 cache-misses 占 cache-references 比例超过 10%,同时 perf c2c 显示某个缓存行上有 > 50% 的 HITM 集中在两个频繁写入的变量上,并且这两个变量的写入频率确实在每秒百万次级别。三者齐备,再动手也不迟,否则就是在给自己找麻烦。
2. std::atomic 的坑
std::atomic 是解决多线程数据竞争的必备,但在伪共享面前,需要注意些地方,否则就是一面帮我们一面割我们。理解这些东西,我们才能明白为什么有些伪共享需要解决,有些却不需要。
原子操作强制缓存行所有权
普通的非原子写,比如给一个 int 赋值,在大多数 CPU 上是纯存储操作,可能只停留在 store buffer 里,最终写回缓存。而如果只是读,可能直接拿 Shared 状态的副本,根本不触发所有权请求。
但原子操作,哪怕是 memory_order_relaxed 的 fetch_add,在 x86 上都是 LOCK 前缀的指令(lock xadd),它会强制获取缓存行的 Exclusive 所有权,无论我们是否真的需要顺序一致性。这就意味着,每个原子 RMW(读-改-写) 都会无情地把其他核心的缓存行 Invalid 掉,把 MESI 协议逼到最激烈的冲突模式。如果这两个原子变量恰好在同一缓存行,普通变量还能偶尔偷懒用 Shared 状态共存,原子变量绝无可能,每次都是 Modified → Invalid → Modified 的死循环。
内存屏障可能放大冲突
如果我们用了 memory_order_seq_cst,那更是雪上加霜。Seq-cst 不仅要求获取缓存行所有权,还要插入全局的内存屏障,清空 store buffer,等待所有核心确认。这个屏障的延迟可能把一次伪共享冲突的代价从几十周期放大到几百周期。还有就是编译器有时会合并或重排原子操作,导致我们看到的冲突模式在汇编层面跟源码层面不一样,进一步干扰判断。
原子变量阻止编译器优化 padding
如果我们用了一个 std::atomic 并把它放在结构体里,编译器虽然不会随意重排结构体成员,但为了对齐,可能会在成员间插入填充。如果我们在原子变量旁边放一个普通变量,而这个普通变量恰好在同一缓存行且被其他线程频繁写入,仍然可能引发伪共享。
所以安全起见,我们的隔离应该把整个结构体都当成神圣而不可侵犯的地方,而不是只隔离原子变量本身。换句话说,别在同一个结构体里混用原子变量和普通变量,除非我们完全控制了布局。
结尾
伪共享是一个硬件正确性 与软件性能之间最阴险的冲突。它在逻辑上完全合法,在硬件上完全符合缓存一致性协议,但在性能上却是一场彻头彻尾的灾难。它让不做人的 CPU 微架构在我们最需要线性加速的场景下,偷偷把我们的并行程序退化成了带全局锁的串行老古董。
识破它、定位它、消灭它,是提高并发性能的路径之一。