从"单专家"到"多专家辩论":我初次实现了多大脑对话
续上一篇《白天跑外卖,晚上敲代码...》,这次聊聊多大脑对话的具体实现。
写在前面
上一篇我分享了MVP的整体架构和设计思路。按照之前的规划,这段时间进行了下一步操作:多大脑对话------让医学专家和法律专家在回答同一个问题时,能看到对方的观点,然后互相补充、反驳,最后输出一个更全面的答案。
这个功能花了我不少时间,中间也踩了很多坑,但最终跑通了。这篇文章记录实现过程、踩坑经历和设计思考。如果你也在做多智能体相关的东西,希望能给你一些启发。
项目地址:ai-learning-journey
一、为什么要做"多大脑对话"?
最开始我的系统是"单专家并行"------医学专家回答医学问题,法律专家回答法律问题,然后直接拼接输出。但遇到复合问题(比如"感冒请假被拒"),医学专家会建议休息,法律专家会讲劳动法,两者没有交集,用户还是不知道怎么处理。
理想的模式应该是:
- 两个专家先各自给出第一轮回答。
- 然后互相看到对方的回答,以及原始问题,再思考:我是否同意?有无补充?哪里有矛盾?
- 最后汇总出一个兼顾两边的综合建议。
这就好比让医生和律师坐在一起讨论,而不是各自写一份报告。
二、整体架构
直接上代码结构:
bash
ai-learning-journey/Code update/2026-06-13
├── main.py # 主程序入口
├── dispatcher.py # 分发大脑:路由 + 多轮并发调用专家
├── summarizer.py # 汇总大脑:融合专家答案
├── memory.py # 记忆模块:存储对话历史
├── safe.py # 安全大脑:关键词过滤
├── safety_logger.py # 违规日志
├── api1.py # API调用封装(智谱+阿里云)
└── ...核心逻辑在 dispatcher.py 的 get_experts_answers 函数中。
三、核心实现:共享记忆的多轮辩论
3.1 设计思路
我希望每一轮每个专家都能看到之前所有轮次所有专家的完整回答,而不是只看上一轮。这样信息不会丢失,专家也能基于完整的讨论历史做出判断。
原始结构图
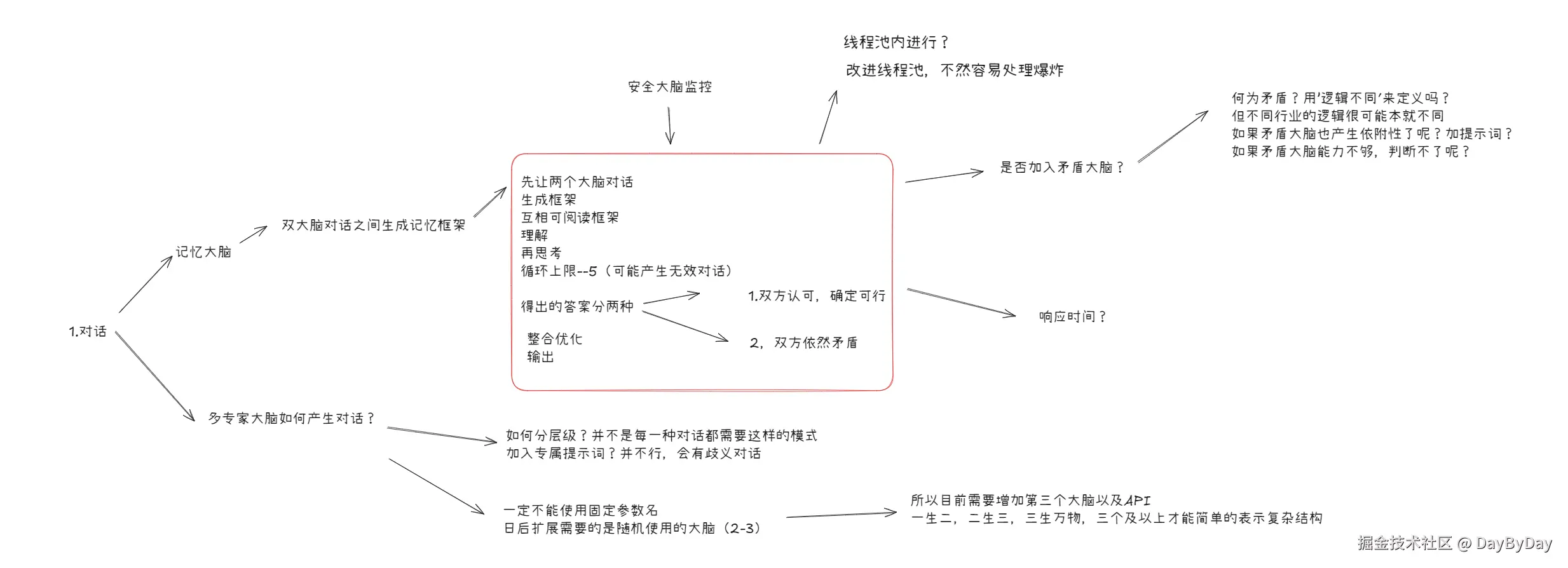
实现方式:
- 用一个
discussion_log列表,记录每一轮每个专家的回答。 - 第0轮:专家只看到用户问题。
- 第1轮及以后:把
discussion_log中的所有历史拼接成文本,附上原始问题,再并发调用专家。
3.2 代码片段
python
def get_experts_answers(question, max_rounds=3):
discussion_log = [] # 存储所有轮次的回答
for round_idx in range(max_rounds):
round_answers = {}
with ThreadPoolExecutor(max_workers=len(expert_list)) as executor:
for exp in expert_list:
# 构造本轮问题
if round_idx == 0:
round_question = question
else:
# 拼接历史讨论
history_text = ""
for i, log in enumerate(discussion_log, 1):
history_text += f"第{i}轮讨论:\n"
for e, ans in log.items():
history_text += f"[{e.upper()}专家]: {ans}\n"
history_text += "\n"
round_question = (
f"用户原始问题:{question}\n\n"
f"以下是到目前为止的讨论记录:\n{history_text}\n"
f"这是第{round_idx+1}轮,请参考上述内容,给出你的回答。"
f"可以认可、反驳、补充之前的所有观点。"
)
# 并发调用
future = executor.submit(call_ai, prompt, round_question, api_name)
# ... 收集结果
discussion_log.append(round_answers)
return discussion_log[-1] # 返回最后一轮3.3 对抗"依附性"
AI有一个毛病:容易附和对方观点("依附性")。为了削弱这一点,我在非首轮的提示词中明确要求:
"请参考上述内容,给出你的回答。可以认可、不认可、同意、反驳、补充之前的所有观点。"
这比默认的"请参考"要强硬得多。实测效果明显,专家会真的提出反对意见。
但是这样设计,模式太固定了,并且提示词太长了,以后会尝试使用动态,多样式提示词。
我还是觉得结构上尽量不要写死,留一点操作空间。
四、踩坑实录:一个关键词引发的血案
4.1 第一次测试:只有医学专家?
写完代码后,我激动地测试了"感冒请假被拒绝"。结果只看到一个通用专家的总结,根本没有专家讨论。
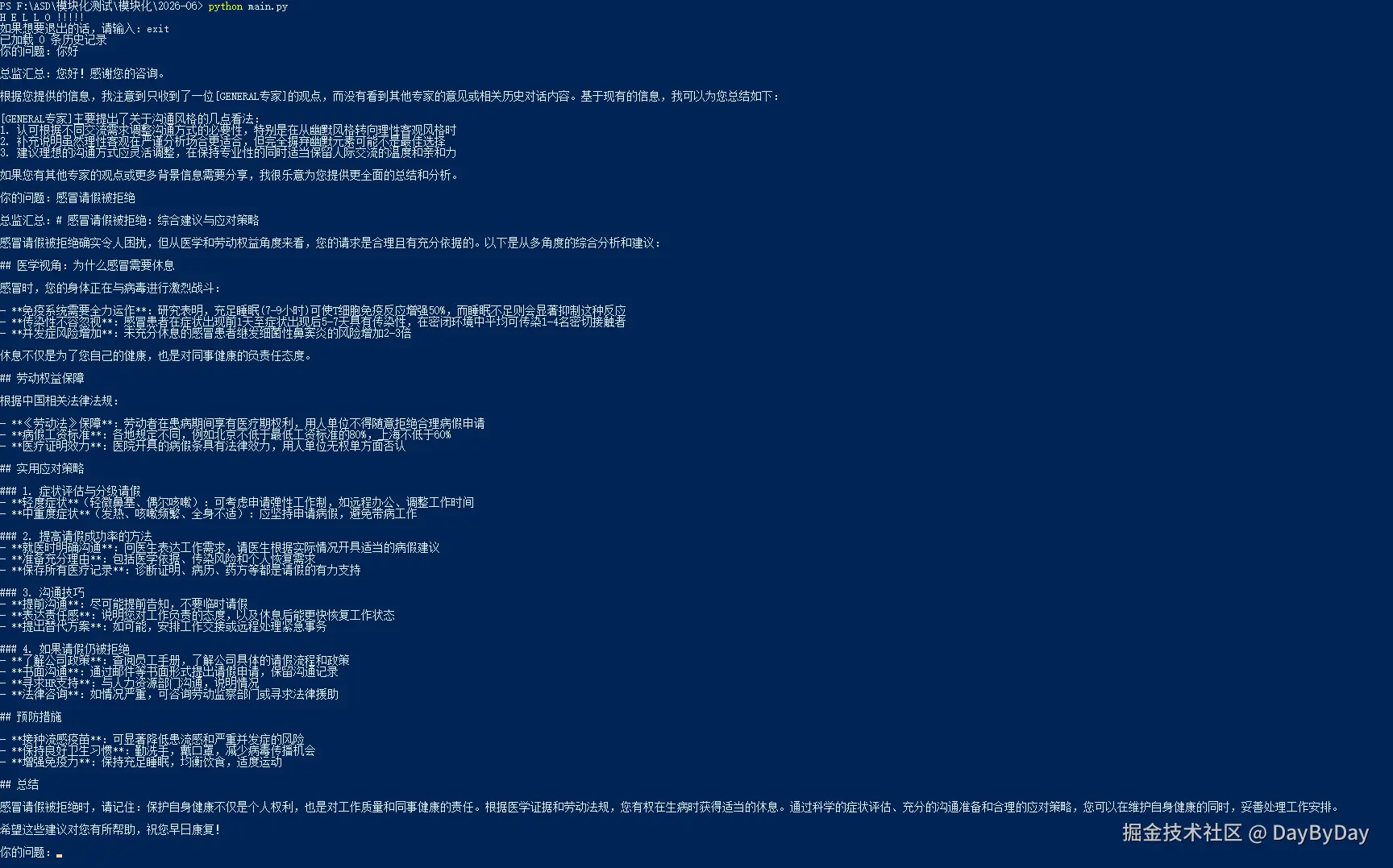
我怀疑两个原因:
- 根本没有触发讨论逻辑。
- 讨论了,但总监汇总时被覆盖了。
为了验证,我在 dispatcher.py 里加了一段打印:
python
print("\n" + "="*50)
print("专家讨论完整记录:")
for i, log in enumerate(discussion_log, 1):
print(f"第{i}轮:")
for exp, ans in log.items():
print(f" {exp}: {ans[:200]}...")
print("="*50 + "\n")再跑一次,发现 discussion_log 里只有医学专家的回答!法律专家根本没出现(这张图片我弄丢了)。
4.2 定位问题
我立刻检查 route 函数的关键词列表:
python
law_keywords = ["法律", "合同", "权益", "官司"] # 没有"请假"!原来法律专家的关键词里漏了"请假",所以问题中的"请假"根本不会触发法律专家。
加上"请假"后,再次运行:
text
用户: 我感冒了,公司不批假
第1轮:
medical: 建议休息,开具医疗证明...
law: 根据劳动法,病假需要提供医疗证明...
第2轮:
medical: 参考法律专家的观点,我补充:如果公司拒绝病假,可以...
law: 医学专家提到传染性,这也可以作为请假的理由...完美!两个专家成功辩论,最终总监汇总输出了一份既有医学建议又有法律依据的答案。
五、效果展示
用户问题:感冒请假被拒绝,怎么办?
最终回答(摘要):
医学专家建议:感冒具有传染性,带病工作可能感染同事,建议休息并开具医疗证明。 法律专家指出:根据劳动法,员工有权申请病假,公司拒绝需提供合理理由。 综合建议:先就医获取证明,再与公司沟通;若仍被拒,可向劳动监察部门投诉。
可以看到,两个专家的观点互相补充,而不是简单拼接。这正是我想要的效果。

六、存在的不足与下一步计划
当前问题
- 路由还是关键词匹配,不够智能(比如"发烧"只匹配医学)。
- 专家数量只有两个(医学、法律),扩展性未验证。
- 内存会话
discussion_log是临时变量,没有持久化(下一版会存入记忆模块)。 - 提示词还有优化空间。
- 日后,如若增加多个大脑,线程池应该是一定会出问题的,但是MVP阶段应该只会用到三个。
- 没有异常处理,或是异常报错之类的。
- 考虑到分层使用,节约资源,以及后期的维护性,等等一些,多大脑对话的构造位置,应该还是外置更优,但是MVP阶段是只打算接在get_experts_answers内了。
下一步计划
- 把关键词改成外部JSON配置(方便动态添加专家)。
- 增加第三个专家(金融),验证架构可扩展性。
- 把专家讨论记录也存入记忆模块(用
dialogue_type区分)。 - 尝试让总监大脑输出更结构化的结果(如"共识、分歧、建议")。
- 如若精力足够,提前优化线程池,以免日后再改(或许在当前阶段属于过度设计了)。
七、诚实的AI使用声明
这个项目的核心架构设计、草稿图、日记、代码调试都是我独立完成的。在写代码过程中,我会用AI助手帮我查语法错误、回忆库函数用法,但所有关键逻辑、模块拆分、异常处理都是我亲手写的。
如果你觉得这代码有参考价值,欢迎star、fork、提issue。
八、写在最后
从"单专家"到"双专家辩论",看似只加了一个循环,但背后的设计思考、调试过程花了整整两天。最大的感悟是:技术难度往往不在代码本身,而在你如何定义"好的答案"。
此外,这个"多大脑对话"还只是雏形,还有很多地方可以优化,不过也确实验证了核心概念:多大脑是真正可以对话的。后续是如何让他们对话得出的结论更精准简洁,可维护,可保护,提升稳定性,安全性,内存处理,等等。
要做的事还有很多,日复一日,期待每一个明天!
项目仓库 :ai-learning-journey