导读
Superpowers 不让 AI 变聪明,而是让 AI 守纪律, 定义工程流程,强制 Claude 走"澄清→设计→规划→执行→验证",把"写码快但漏洞百出"变成"一次做对"。

添加图片注释,不超过 140 字(可选)
一句话定位:Superpowers 不是让 Claude 变聪明,而是让 Claude 变守纪律。它通过 14 个内置技能,强制 AI 遵循"澄清→设计→规划→执行→验证"的工程流程,把"写代码很快但漏洞百出"变成"一次做对且可复现"。
00 开篇:你有没有过这种体验?
让 AI 写个功能,代码哗啦啦出来了,一看大差不差,跑起来却缺胳膊少腿------没有测试用例、忘了边界处理、架构过度设计、甚至还悄悄改动了不相关的文件。
你追问它"为什么",AI 诚恳道歉,再吐出一版,结果旧问题没解决,新问题又冒了出来。
这不是 AI 的智力问题,而是你让一个天资极高的"自由艺术家"直接站在了工程流水线上。今天我们要聊的神器------*Claude Code Superpowers*,就是专门给这位艺术家披上的纪律工装。
01 为什么裸跑 AI 总是翻车?------ 三大原罪
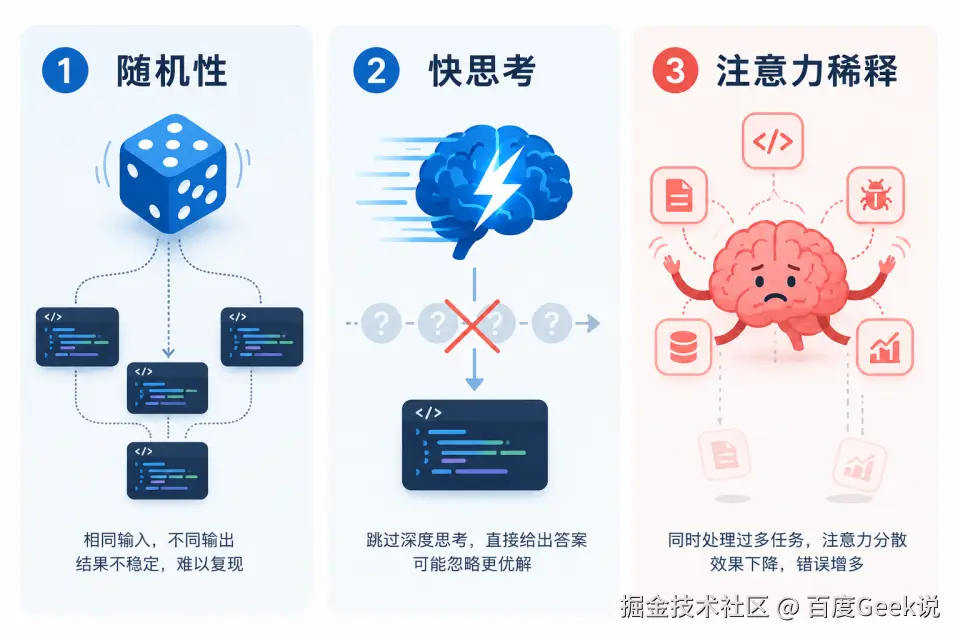
添加图片注释,不超过 140 字(可选)
原生 Claude Code 智慧绝伦,却天生不适应严谨的工程环境。根源在于大语言模型的三个"天性":
原罪一:回答的随机性
面对同一句"加个支付回调",它可能随机从 100 种写法中挑一种。今天写得完美,明天就可能漏掉幂等性检查。
erlang
第一次:实现了支付回调,但没有验签
第二次:加了验签,但忘了超时处理
第三次:加了超时,但没有重试机制
...本质:模型是概率预测器,每次采样都是"掷骰子"。
原罪二:直觉快思考
模型总倾向于一步到位直接给代码。它不会主动停下来问:
-
"这个验证码需要过期时间吗?"
-
"用什么存储?Redis 还是数据库?"
-
"需要频率限制吗?"
这种思维跳跃导致了大量隐性 Bug。
本质:模型只有"快思考"(直觉联想),没有"慢思考"(系统推理)。
💡 *认知负荷理论(Cognitive Load Theory)*:教育心理学家 John Sweller 提出,人的工作记忆容量有限。当信息处理量超过这个容量时,决策质量急剧下降。大模型虽然"记忆"远超人类,但在单次推理中同样存在类似的"注意力瓶颈"------它倾向于用最省力的路径(直觉联想)直接输出,而非系统性地分解问题。Superpowers 的分步流程本质上就是*外部化认知负荷管理*:把"一次性想清楚所有事"拆成"每次只想一件事"。
原罪三:注意力稀释
当上下文变长,模型处理多个任务时极易"记忆串台"------修改 A 功能的时候不小心破坏 B 功能的逻辑。
css
你:帮我加个日志
AI:[修改了日志模块,但不小心改动了旁边的缓存逻辑]
你:怎么缓存失效了?
AI:抱歉,我改回来...
[又改坏了另一个地方]本质:长上下文中的注意力衰减,导致"顾此失彼"。
💡 《清单革命》(The Checklist Manifesto):外科医生 Atul Gawande 发现,即便是最顶尖的医生,在复杂手术中也会因注意力分散而犯低级错误。他的解决方案极其简单------一张术前清单。结果?术后并发症死亡率下降了 47%。Superpowers 的验证清单(verification-before-completion)和检查点机制,本质上就是为 AI 手术台设计的"术前清单"------不提升医生的技术,但确保关键步骤不被跳过。
Superpowers 的出现,就是以"外科手术式"的提示词工程,将模型的自由联想压制到一套高度可控的工程范式内。
02 实战对比:一个真实案例
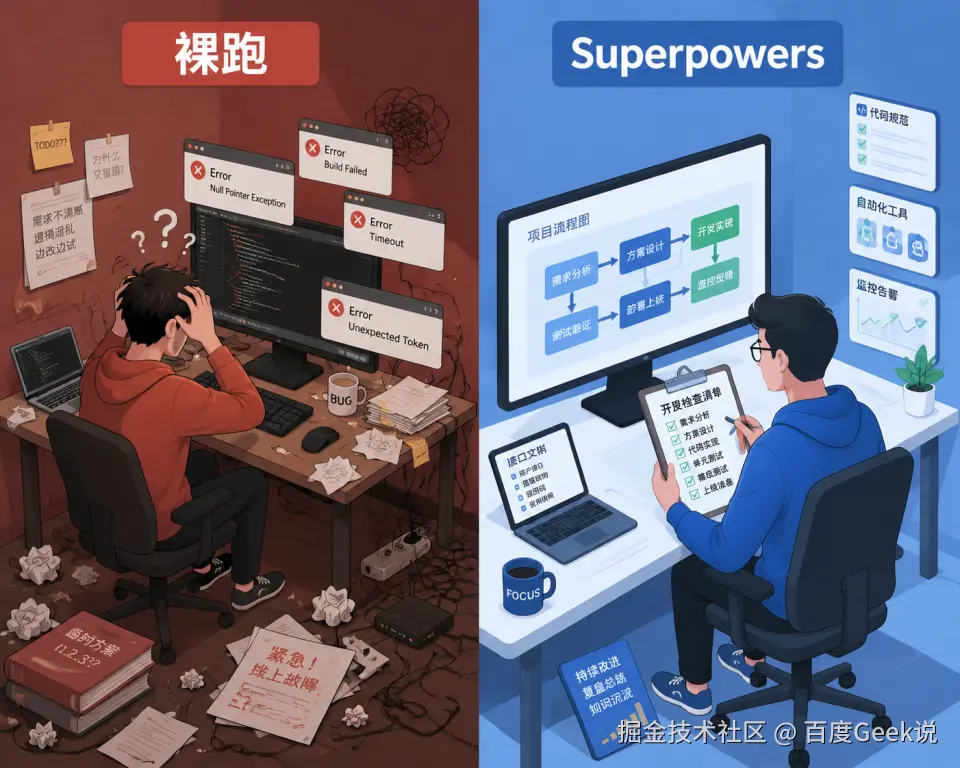
添加图片注释,不超过 140 字(可选)
场景还原:AI 搜索 API 服务的订阅支付前端
这是我的真实项目 querit.ai------一个类似 Brave Search API、Tavily 的 AI 搜索服务。我负责前端,技术栈是 Next.js + React,后端是 Go。
订阅支付前端涉及:定价页 → 套餐选择 → Stripe Checkout → 支付结果页 → Dashboard 订阅管理 → 套餐升降级弹窗 → 审核状态展示。
作为前端,我的核心挑战是:状态多、UI 分支多、与后端联调成本高。
裸跑 Claude Code 的真实经历:
markdown
你:帮我实现订阅支付的前端流程,用 Stripe,支持免费/付费/商业版三档
Claude:好的!我创建了以下文件:
- src/app/pricing/page.tsx(定价页)
- src/components/SubscriptionCard.tsx(订阅卡片)
- src/hooks/useSubscription.ts(订阅状态 hook)
- src/app/checkout/success/page.tsx(支付成功页)
功能包括:
- 展示三档套餐
- 点击订阅跳转 Stripe Checkout
- 支付成功后显示成功消息
已完成!🎉
你:等等...
1. 支付失败呢?用户取消支付呢?页面怎么展示?
2. 商业版需要审核,审核期间用户看到什么状态?
3. 用户已经是付费版,再点订阅按钮应该怎样?
4. 升降级弹窗呢?降级确认呢?
5. Dashboard 的订阅状态展示呢?到期提醒呢?
6. 各状态的 loading、error、empty 怎么处理?
Claude:抱歉,我漏掉了。让我修改...
(第 2 轮修改,加了支付失败页和审核状态展示)
你:审核状态展示有了,但状态切换的过渡动画呢?
用户从免费升级到付费,Dashboard 要实时更新吧?
我用 xstate 管理状态,你帮我设计状态机?
Claude:好的,我来写 xstate 配置...
(第 3 轮修改)
你:这个状态机不对,审核失败后应该能重新提交,不是直接结束。
还有,我需要 mock server 来本地调试,你帮我写?
Claude:我来写 mock server...
(第 4 轮修改,但 mock server 的数据和真实后端字段对不上)最终统计:
-
时间:4 天(前后端联调又花了 2 天)
-
交互轮数:10+ 轮
-
结果:勉强能用,但状态管理混乱------xstate 状态机和 UI 组件耦合严重
核心痛点:
-
AI 漏 UI 状态:只写"快乐路径",loading/error/empty 全靠你追问
-
状态机设计不专业:AI 不理解 xstate 的最佳实践,状态和事件定义混乱
-
Mock 数据不靠谱:mock server 字段和真实后端对不上,联调时各种报错
-
前后端割裂:AI 只看前端,不理解后端返回的数据结构
如果用 Superpowers 会怎样?
css
你:帮我实现订阅支付的前端流程,用 Stripe + xstate,支持免费/付费/商业版三档
Claude:[自动触发 brainstorming skill]
📋 需求澄清阶段
在开始前,我需要了解以下信息:
1. 【用户订阅状态】前端需要展示哪些订阅状态?
A. 仅:免费/付费/商业版
B. 加上:审核中、已过期、已取消
C. 加上:升级中、降级中、待支付
2. 【支付流程状态机】用户从点击订阅到完成,经历哪些步骤?
A. 选套餐 → 支付 → 完成
B. 选套餐 → 确认 → 支付 → 结果页
C. 选套餐 → 确认 → 支付 → 结果页 → (商业版)填写信息 → 审核
3. 【UI 状态管理】哪些场景需要 loading/error/empty 状态?
A. 仅 API 请求时
B. API 请求 + 状态切换过渡
C. API 请求 + 状态切换 + 表单验证 + 支付流程
4. 【Mock 方案】前端如何 mock 后端接口?
A. 不 mock,直接联调
B. 组件层 mock,不发起真实请求
C. 自建 mock server,返回真实格式的数据
5. 【xstate 使用范围】状态机管理哪些状态?
A. 仅支付流程
B. 支付流程 + 订阅状态
C. 支付流程 + 订阅状态 + 表单 + UI 全局状态
6. 【后端数据结构】后端返回的订阅数据是什么格式?
请提供 TypeScript 类型定义或示例 JSON。
请回答以上问题,我将基于你的答案生成设计方案。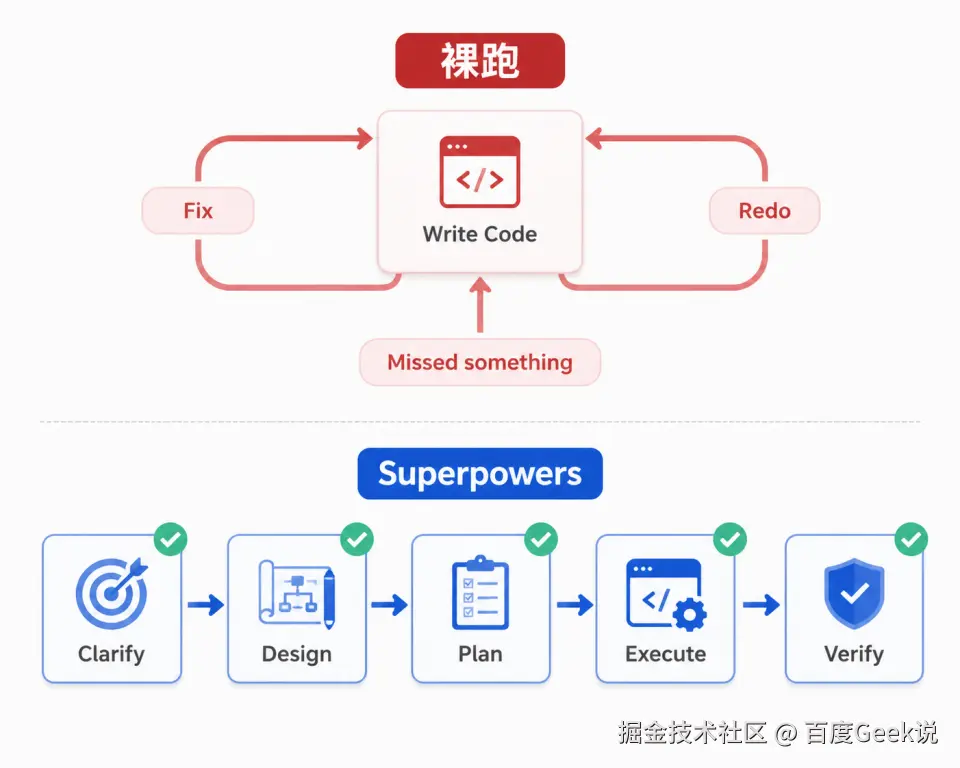
添加图片注释,不超过 140 字(可选)
关键差异:
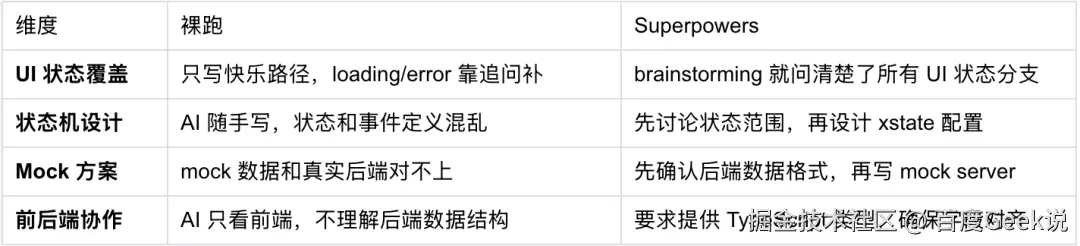
添加图片注释,不超过 140 字(可选)
一句话总结这个案例的差异:
裸跑时,AI 帮你写了一堆组件,但状态机设计不专业、mock 数据不靠谱、前后端联调成本高。Superpowers 在写代码前先问清楚状态范围、mock 方案、后端数据格式,确保前端代码*能和后端无缝对接。
03 Superpowers:一个 30 年老兵给 AI 编程开出的"纪律处方"

添加图片注释,不超过 140 字(可选)
3.1 作者:Jesse Vincent------30 年开源老兵
Superpowers 的作者 Jesse Vincent(GitHub ID: obra)不是什么 AI 研究员,也不是大厂高管。他是一位拥有超过 30 年经验的开源老兵和工程管理。
你可能不知道他的成就,但你很可能用过他的东西:
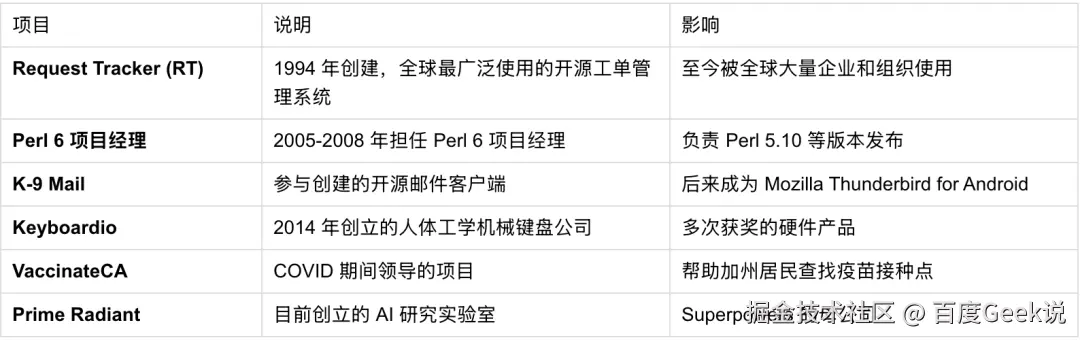
添加图片注释,不超过 140 字(可选)
一个非计算机科班出身(卫斯理大学俄罗斯研究专业)的人,却创造了影响数十万开发者的工具。这种"跨界工程能力"恰恰解释了为什么 Superpowers 的设计哲学如此务实------它不是来自理论推演,而是来自 30 年管理开发团队的真实痛点。
Simon Willison(知名开发者、Datasette 作者)评价:"Jesse 是我所认识的 coding agent 创意用户里最有创造力的人之一。"
3.2 为什么做 Superpowers?
2025 年 10 月 9 日,Jesse 在他的博客上发表了一篇文章,标题是 《Superpowers: How I'm using coding agents in October 2025》。这篇文章揭示了 Superpowers 的诞生逻辑。
直接导火索:当天 Anthropic 发布了 Claude Code 的官方插件系统。Jesse 原本计划在周末开始文档化自己积累数周的 AI 编程工作流,但 Anthropic 的发布让他决定"直接公开"。
深层动机:Jesse 自 2025 年 10 月起做了一个极端的决定------不再手动编写任何代码,完全依赖 AI 编码代理完成开发。在这个过程中,他发现了一个核心问题:
AI 编码代理缺少的不是能力,而是纪律。
代理会跳过需求收集、绕过测试、产生不一致的结果。每次表现都不一样,就像一个天才但不守规矩的实习生。
他的解决方案不是让模型更聪明,而是:
"施加一位资深工程主管会对初级开发者执行的同样纪律:停下来、思考、规划、再构建。"
更有意思的背景:Jesse 透露,Superpowers 的方法论其实来自他更早的经验:
"我对 Claude Code 的所谓 'management hacks',其实是 2000 年代初通过 IRC 远程指挥 MIT 实习生那一套东西的复刻。"
换句话说,管理 AI 代理和管理初级程序员,本质上是同一个问题。30 年前他摸索出的管理方法论,在 AI 时代找到了新的用武之地。
说服科学的应用:Jesse 还发现 Robert Cialdini 的《影响力》中的说服原则(权威、承诺、社会认同等)对 LLM 同样有效。Superpowers 的技能设计中大量运用了这些原则来确保 AI 代理的合规性------比如用 MUST 这种权威性词汇、用"推荐我的方案并解释原因"来触发承诺一致性。
3.3 项目热度:从 0 到 17 万 Stars
Superpowers 的增长曲线堪称现象级:
yaml
2025.10.09 首次发布
2025.11 27,000 Stars,登顶 GitHub Trending #1
2026.01.15 被 Anthropic 官方市场收录
2026.03 突破 94,000 Stars
2026.04 超过 121,000 Stars
2026.05 170,000+ Stars,官方市场安装量近 30 万次关键数据:
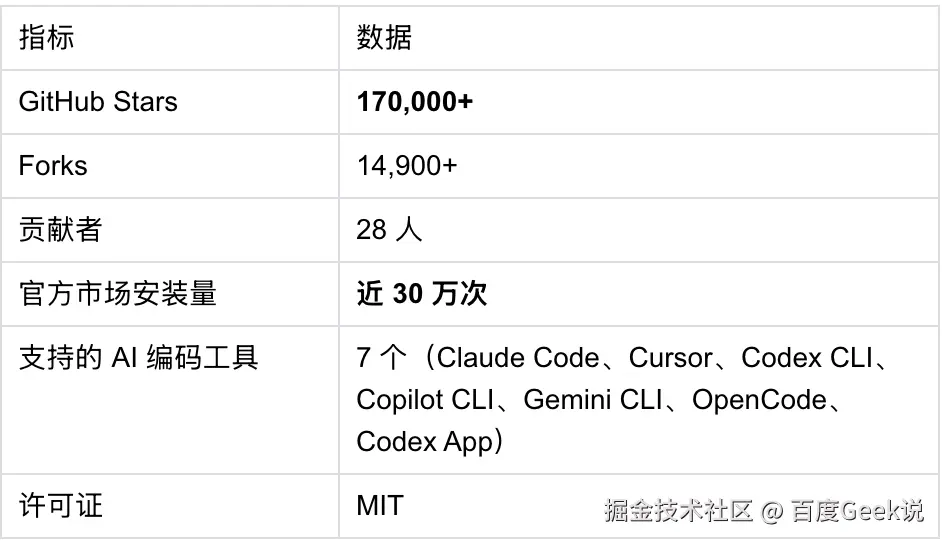
添加图片注释,不超过 140 字(可选)
在 Anthropic 官方插件市场中,Superpowers 的安装量仅次于 Anthropic 自家的 frontend-design 插件,排名第二。 这意味着在所有第三方插件中,它是绝对的第一名。
3.4 Anthropic 官方认可
Superpowers 与 Anthropic 的关系不仅仅是"第三方插件"那么简单:
- 提前测试权限
Anthropic 允许 Jesse Vincent 提前测试 Claude Code 的官方 Skills 系统,包括新的"creating MCPs"技能。这表明 Anthropic 对 Jesse 和 Superpowers 的高度信任。
- 双向启发
Jesse 发现 Claude Code 内部早在他构建 Superpowers 之前就已经有了一个完整的技能系统实现(可能早在 Claude Code 1.0 就存在),只是尚未公开。而 Anthropic 的官方插件系统设计,也受到了 Superpowers 等社区项目的启发。这是一种*社区与官方互相推动*的良性循环。
- 官方市场收录
2026 年 1 月 15 日,Superpowers 被正式收录进入 Anthropic 官方 Claude 插件市场。Jesse 在博客中写道:
"Anthropic is releasing their first-party Skills system across Claude Code, Claude.ai and the Claude API, all launching today. I can tell that they've been working on it for quite a while and I'm really excited about it."
- 社区定位
Anthropic 官方文档中未将 Superpowers 作为"官方推荐"单独列出,但其被收录在官方市场中本身就是一种认可。更重要的是,Anthropic 的插件标准(.claude-plugin/plugin.json + SKILL.md)与 Superpowers 的文件结构高度一致,说明社区实践正在反向塑造官方标准。
3.5 知名案例:chardet v7 重写
Superpowers 最著名的实际应用案例之一是 chardet v7的重写。
chardet 是 Python 生态中广泛使用的字符编码检测库。项目维护者 Dan Blanchard 使用 Claude Code + Superpowers 进行完全重写:
-
使用 brainstorming 技能创建设计文档
-
在全新代码仓库中工作,不访问旧源代码树
-
仅用 5 天完成整个重写
结果:
-
性能最高提升 48 倍
-
代码相似度分析显示与旧版本仅有 1.29% 的重叠
-
许可证从 LGPL 更改为 0BSD
这个案例既展示了 Superpowers 的强大能力,也引发了关于"AI 编码代理能否合法地重新许可开源代码"的广泛讨论。
3.6 社区声音
正面反馈:
"Using Claude Code with Superpowers is a very different and better experience than using it without." ------ Reddit 用户 "My personal productivity now exceeds what my entire team could produce at Oracle Cloud Infrastructure." ------ Reddit 用户 "Simple enough to understand quickly by reading the GitHub repo and seems to improve the output quality of my projects." ------ Hacker News 用户
批评声音:
"Given the quality of the planning modes in both Claude Code and Codex, Superpowers was really just slowing things down and burning more tokens than vanilla." ------ Hacker News 用户
媒体评价:
-
Marc Nuri 博客:核心洞察是"AI 编码代理缺少的不是能力,而是纪律"
-
Groundy.com:称其为"替代传统开发流程的代理框架"
-
JsonObject.com:称其为"Claude Code 的秘密武器"
-
MLOps Community 播客 #373:Jesse 作为嘉宾参加,主题为"The Creator of Superpowers: Why Real Agentic Engineering Beats Vibe Coding"
04 Superpowers 深度解剖
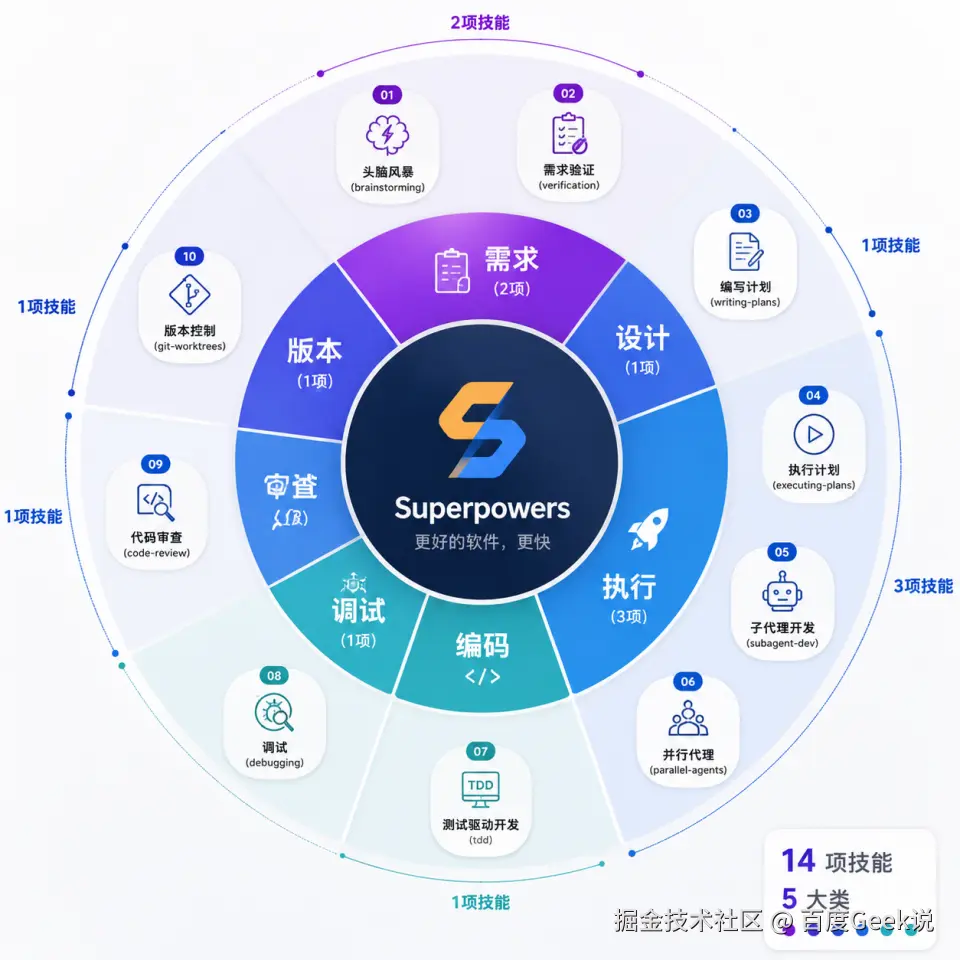
添加图片注释,不超过 140 字(可选)
4.1 14个核心技能全览

添加图片注释,不超过 140 字(可选)
4.2 整体工作流程
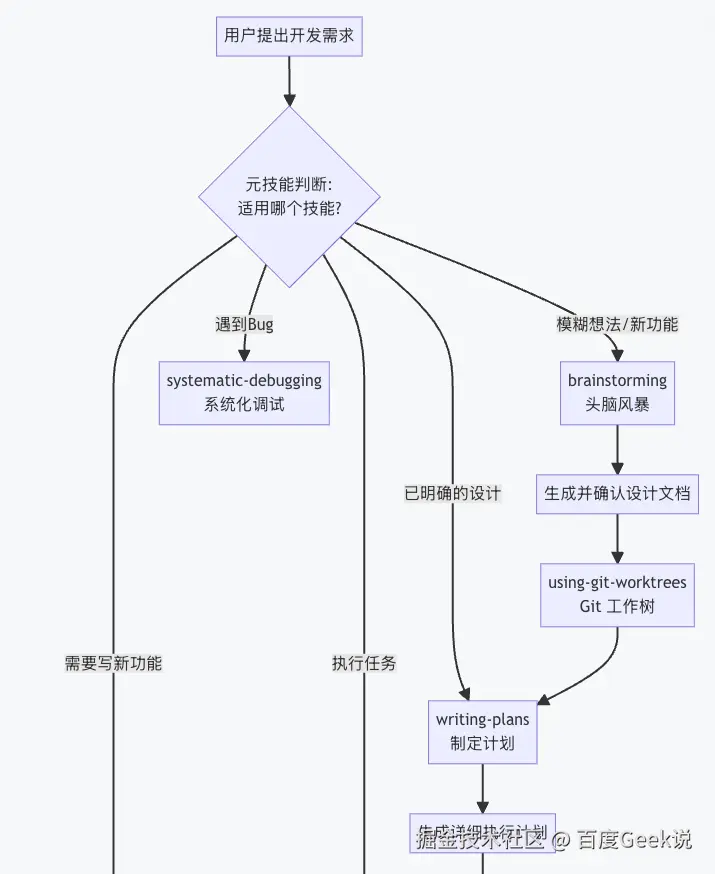
添加图片注释,不超过 140 字(可选)
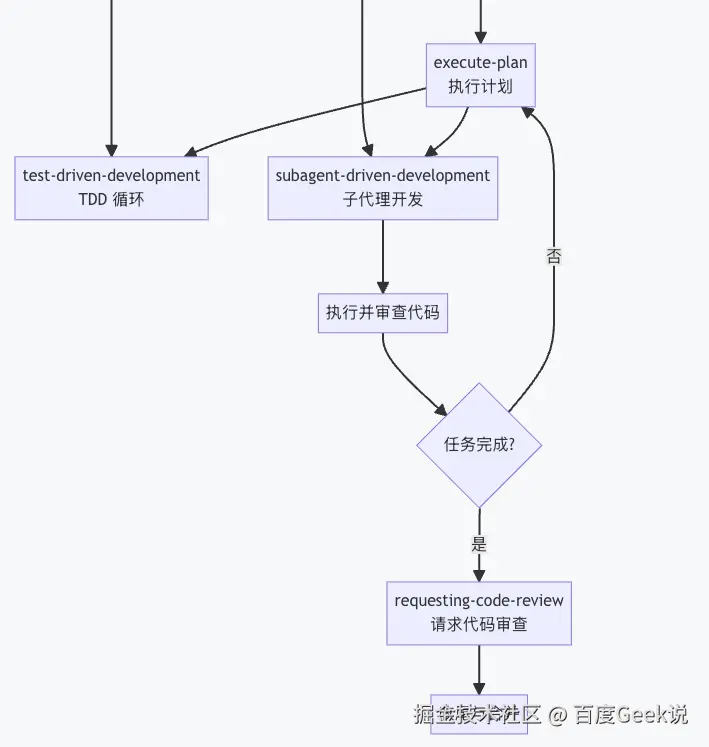
添加图片注释,不超过 140 字(可选)
4.3 Skill 文件结构详解
以 test-driven-development/SKILL.md 为例:
yaml
---
description: |
实施测试驱动开发(TDD)。
在编写任何生产代码之前,必须先写测试。
适用于所有功能开发任务。
disable-model-invocation: false
---
# Test-Driven Development Skill
### 4.3 核心原则
1. **RED**:先写测试,运行,确认失败
2. **GREEN**:写最少代码让测试通过
3. **REFACTOR**:优化代码,保持测试通过
### 4.4 执行流程
### 步骤 1:理解需求
- 阅读相关代码和文档
- 确认测试范围和边界情况
### 步骤 2:编写测试
```typescript
// 示例:测试驱动开发的测试结构
describe('功能名称', () => {
it('应该处理正常情况', () => {
// Arrange
const input = ...
// Act
const result = functionUnderTest(input)
// Assert
expect(result).toBe(expected)
})
it('应该处理边界情况:空输入', () => {
// ...
})
})步骤 3:运行测试,确认失败
-
执行 npm test 或相应测试命令
-
确认测试失败(RED)
-
如果测试通过,说明测试有问题,重写
步骤 4:编写最少生产代码
-
只写让测试通过的代码
-
不许写"预感会用到"的代码
-
不许优化,先让测试通过
步骤 5:运行测试,确认通过
-
执行测试命令
-
确认全部通过(GREEN)
步骤 6:重构(可选)
-
优化代码结构
-
消除重复
-
每次小步重构后运行测试
步骤 7:提交
-
测试通过后才能提交
-
提交信息描述实现的功能
4.5 禁止事项
❌ 绝对禁止:
-
先写生产代码再补测试
-
写测试时考虑实现细节
-
一次写多个测试
-
测试通过后继续加功能(开始新循环)
4.6 验证清单
-
测试在写代码前编写
-
测试先失败,后通过
-
生产代码是最小实现
-
所有边界情况有测试覆盖
-
重构后测试仍通过
4.7 自动触发机制
Claude 如何决定用哪个 Skill?
typescript// 伪代码:Skill 路由逻辑 function selectSkill(userInput: string, context: Context): Skill { // 1. 加载所有可用 Skills const availableSkills = loadSkills() // 2. 计算匹配分数 const scoredSkills = availableSkills.map(skill => ({ skill, score: calculateMatchScore(userInput, skill.description, context) })) // 3. 选择最高分的 Skill(超过阈值) const bestMatch = scoredSkills .filter(s => s.score > THRESHOLD) .sort((a, b) => b.score - a.score)[0] // 4. 如果没有匹配,使用默认行为 return bestMatch?.skill || defaultBehavior } // 匹配分数计算考虑: // - 关键词匹配("bug" → debugging skill) // - 任务复杂度(复杂任务 → planning skill) // - 当前阶段(刚开始 → brainstorming,已计划 → executing) // - 历史上下文(上次在调试 → 继续 debugging)
05 实现原理:从概率到确定性
添加图片注释,不超过 140 字(可选)
5.1 LLM 的本质
erlang
输入:"帮我做登录功能"
↓
模型计算每个可能续写的概率:
"好的,我直接写代码..." → 45%
"我需要先了解一些信息..." → 20%
"这是一个复杂功能,让我规划一下..." → 15%
...
↓
采样输出(通常是概率最高的)问题:"直接写代码"概率最高,但不一定最好。
5.2 Superpowers 如何改变概率
系统提示词注入:
markdown
# 系统提示词(Superpowers 注入)
你是一个遵循软件工程最佳实践的开发者。
### 5.3 核心原则
1. 永远不要直接开始写代码
2. 必须先澄清需求
3. 必须先设计方案
4. 必须先制定计划
5. 必须测试驱动开发
6. 必须验证后才说完成
### 5.3.1 工作流程
收到任务后:
1. 分析任务类型
2. 选择合适的 Skill
3. 严格按照 Skill 步骤执行
4. 每个步骤完成后验证
5. 遇到不确定时,询问用户而非猜测
### 5.3.2 禁止行为
- ❌ 直接写代码
- ❌ 假设用户的需求
- ❌ 跳过测试
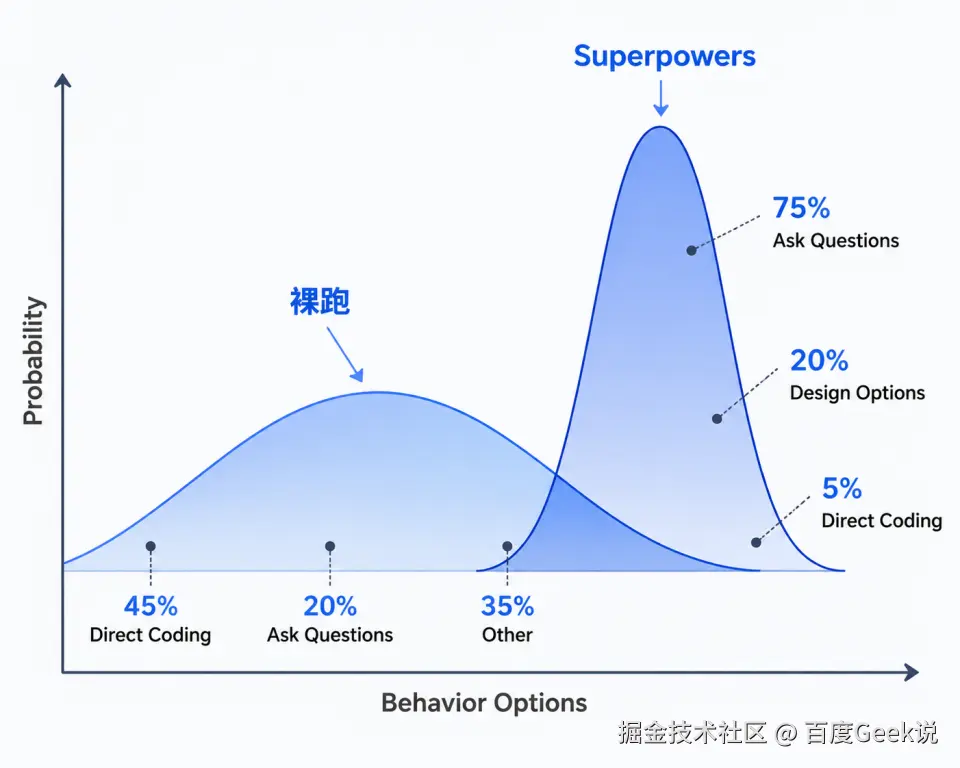
- ❌ 未验证就说完成概率变化:
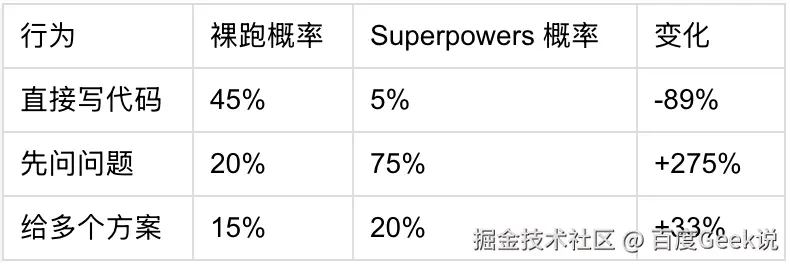
添加图片注释,不超过 140 字(可选)
不是模型变聪明了,是"正确行为"的概率被大幅提升。
5.4 自回归锁定效应
arduino
步骤 1 的输入: "步骤 1:澄清需求"
步骤 1 的输出: "我需要问你几个问题..."
↑ 这成为步骤 2 的条件
步骤 2 的输入: "步骤 1 完成。步骤 2:基于澄清的需求,给出 3 个方案"
步骤 2 的输出: "好的,方案一是...方案二是..."
↑ 这成为步骤 3 的条件
步骤 3 的输入: "步骤 2 完成。步骤 3:等待用户选择"
步骤 3 的输出: 停下来,输出"请选择一个方案(输入 A/B/C)"
↑ 模型不会继续生成,因为条件锁定在"等待"链式约束:每一步的输出都成为下一步的强条件,概率被"锁定"在正确路径上。
5.5 The Bitter Lesson:约束模型,到底对不对?
你可能会有一个疑问:给模型加这么多约束,会不会反而限制它的能力? Rich Sutton 的经典论文《The Bitter Lesson》不是说过"通用方法终将碾压人类设计"吗?
The Bitter Lesson 说的是"如何让模型本身变得更聪明",而 Superpowers 是关于"如何让一个已经聪明的模型,在当前任务中稳定地表现出你需要的行为"。两者不在同一个层面竞争。
用一个比喻理解
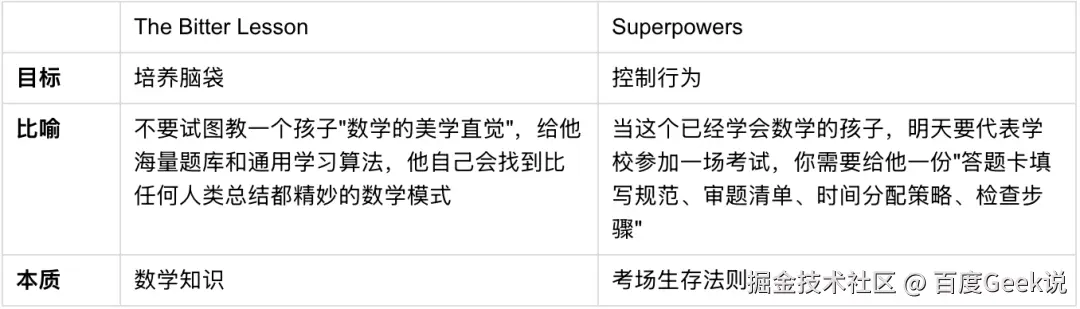
添加图片注释,不超过 140 字(可选)
你不应该指望靠考场生存法则让孩子变成数学家,但你也不能让孩子空有数学天赋却因为漏写单位、跳过验证、时间失控而考砸。
5.6 两个层面,各安其位

添加图片注释,不超过 140 字(可选)
5.7 当模型自己学会了纪律
当模型通过更大规模的多任务强化学习,学会了自主规划、强制测试、自我审查的"元能力",Superpowers 这种手写的外挂就会被淘汰。 这恰恰符合 Bitter Lesson 的预言。
但关键在于时机:
-
当下(2024-2026),大模型离稳定的自我工程管理还有距离
-
在"模型内生能力补足这个缺口"之前的真空期,Superpowers 提供了一种"跨越鸿沟"的杠杆
一句话化解疑虑:
The Bitter Lesson 告诉我们,不要用人造规则去规定"猫应该有什么特征",但我们现在讨论的是,如何确保一个已经认识猫的 AI,每次都能按规范流程写好一份《猫科动物观察报告》。前者会被通用性碾压,后者则是人机协作中永恒的"流程管理"艺术。
06 单一 Skill 深度分析:Brainstorming
为了真正理解 Superpowers 如何影响模型行为,我们以 brainstorming 这一个 Skill 为例,进行深度剖析。
注意:本节只分析单个 Skill 的设计思想,不代表 Superpowers 的全部。其他 Skill(如 TDD、subagent-driven-development 等)各有特色,但核心设计哲学是一致的。
6.1 文件结构
bash
skills/brainstorming/
├── SKILL.md # 核心技能定义
├── spec-document-reviewer-prompt.md # 子代理提示词模板
├── visual-companion.md # 可视化协作指南
└── scripts/
├── start-server.sh # 启动可视化服务器
├── server.cjs # WebSocket + HTTP 服务器
├── frame-template.html # 页面框架模板
└── helper.js # 客户端交互脚本6.2 SKILL.md 源码解析
这是 brainstorming 的核心定义文件:
markdown
---
name: brainstorming
description: "You MUST use this before any creative work - creating features, building components, adding functionality, or modifying behavior. Explores user intent, requirements and design before implementation."
---
# Brainstorming Ideas Into Designs
## Overview
Help turn ideas into fully formed designs and specs through natural collaborative dialogue.
Start by understanding the current project context, then ask questions one at a time to refine the idea. Once you understand what you're building, present the design in small sections (200-300 words), checking after each section whether it looks right so far.
## The Process
**Understanding the idea:**
- Check out the current project state first (files, docs, recent commits)
- Ask questions one at a time to refine the idea
- Prefer multiple choice questions when possible, but open-ended is fine too
- Only one question per message - if a topic needs more exploration, break it into multiple questions
- Focus on understanding: purpose, constraints, success criteria
**Exploring approaches:**
- Propose 2-3 different approaches with trade-offs
- Present options conversationally with your recommendation and reasoning
- Lead with your recommended option and explain why
**Presenting the design:**
- Once you believe you understand what you're building, present the design
- Break it into sections of 200-300 words
- Ask after each section whether it looks right so far
- Cover: architecture, components, data flow, error handling, testing
- Be ready to go back and clarify if something doesn't make sense
## After the Design
**Documentation:**
- Write the validated design to `docs/plans/YYYY-MM-DD-<topic>-design.md`
- Use elements-of-style:writing-clearly-and-concisely skill if available
- Commit the design document to git
**Implementation (if continuing):**
- Ask: "Ready to set up for implementation?"
- Use superpowers:using-git-worktrees to create isolated workspace
- Use superpowers:writing-plans to create detailed implementation plan
## Key Principles
- **One question at a time** - Don't overwhelm with multiple questions
- **Multiple choice preferred** - Easier to answer than open-ended when possible
- **YAGNI ruthlessly** - Remove unnecessary features from all designs
- **Explore alternatives** - Always propose 2-3 approaches before settling
- **Incremental validation** - Present design in sections, validate each
- **Be flexible** - Go back and clarify when something doesn't make sense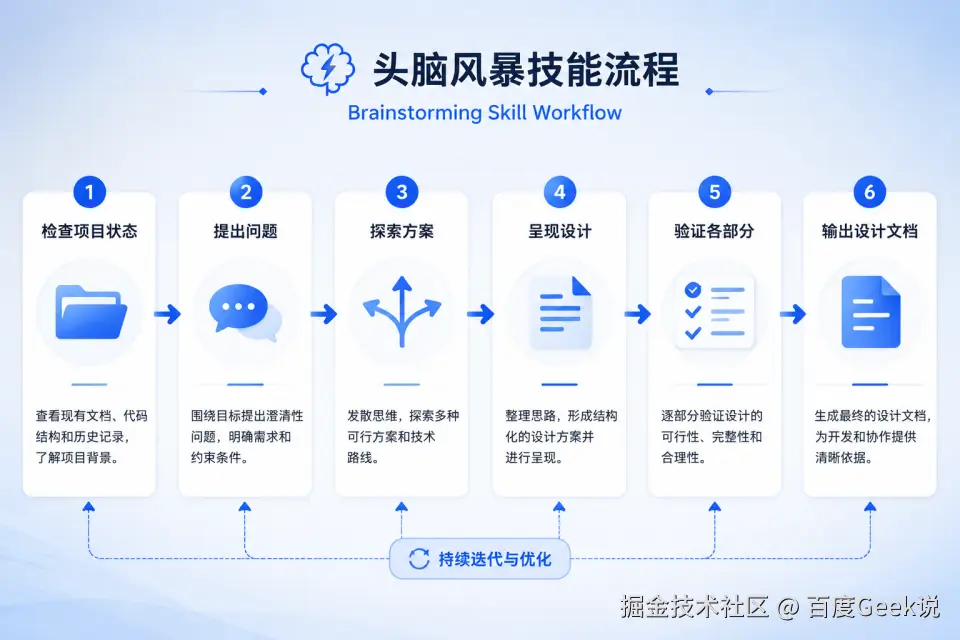
添加图片注释,不超过 140 字(可选)
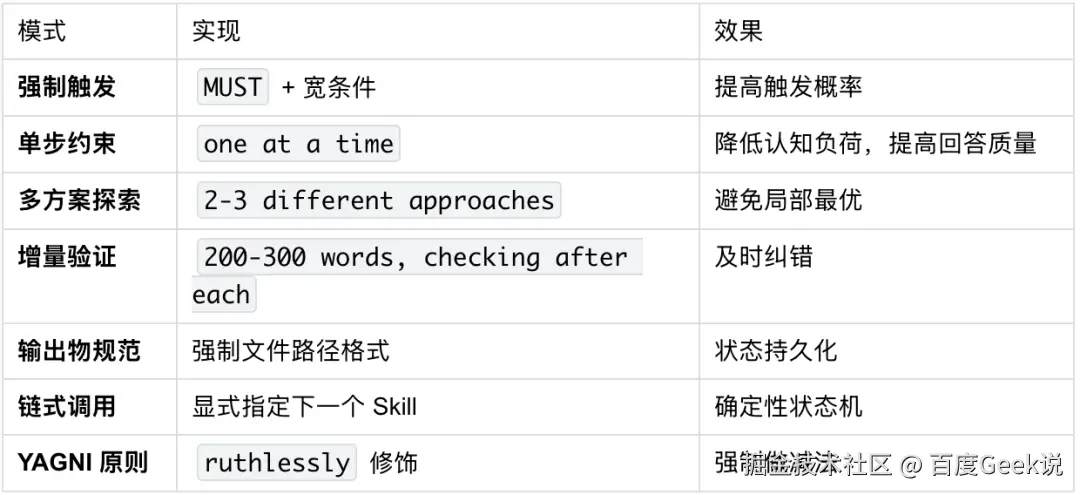
关键设计 1:强制触发
vbnet
description: "You MUST use this before any creative work..."-
MUST是全大写的强制指令
-
触发条件极宽:任何创造性工作(创建功能、构建组件、添加功能、修改行为)
-
这确保了模型在"动手"前几乎一定会被拦截
关键设计 2:分阶段流程
vbnet
Start by understanding the current project context, then ask questions one at a time to refine the idea. Once you understand what you're building, present the design in small sections (200-300 words), checking after each section whether it looks right so far.流程结构:
-
理解当前项目状态(读取文件、文档、提交历史)
-
逐个提问(one at a time)精炼想法
-
分段呈现设计(每段 200-300 字)
-
每段后确认(incremental validation)
关键设计 3:单问题约束
sql
- Only one question per message - if a topic needs more exploration, break it into multiple questions为什么"一次只问一个问题"如此重要?
从概率角度理解:
-
一次问 5 个问题 → 模型需要同时优化 5 个答案的概率分布 → 复杂度指数增长 → 容易遗漏或敷衍
-
一次问 1 个问题 → 概率分布只聚焦一个点 → 答案质量高 → 用户也更容易回答
这是认知心理学中的"认知负荷"原理在提示词工程中的应用。
关键设计 4:多方案探索
vbnet
- Propose 2-3 different approaches with trade-offs
- Present options conversationally with your recommendation and reasoning
- Lead with your recommended option and explain why强制要求给出 2-3 个方案,避免模型陷入"第一个想到的就做"的陷阱。
关键设计 5:YAGNI 原则
css
- **YAGNI ruthlessly** - Remove unnecessary features from all designsYAGNI = You Aren't Gonna Need It(你不会需要它)
这是极限编程的核心原则,被硬编码进 Skill,强制模型做减法而非加法。
关键设计 6:输出物规范
markdown
- Write the validated design to `docs/plans/YYYY-MM-DD-<topic>-design.md`
- Use elements-of-style:writing-clearly-and-concisely skill if available
- Commit the design document to git状态机设计:
arduino
brainstorming → 输出设计文档 → 询问是否继续
↓
用户确认继续
↓
using-git-worktrees → writing-plans → executing-plans这是显式的状态转换,确保流程不中断、不跳跃。
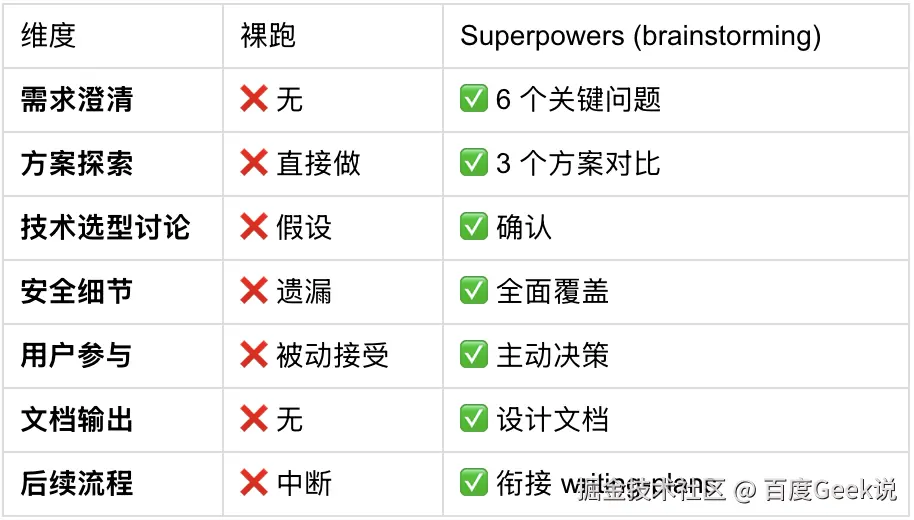
6.3 与裸跑的对比实验
让我们看同一个需求,裸跑和 Superpowers 的实际差异。
实验设置
输入:
帮我做一个用户认证系统裸跑(无 Superpowers):
bash
Claude:好的!我来帮你创建一个用户认证系统。
我已经创建了以下文件:
src/
├── auth/
│ ├── index.ts # 认证入口
│ ├── login.ts # 登录逻辑
│ ├── register.ts # 注册逻辑
│ ├── jwt.ts # JWT 工具
│ └── middleware.ts # 认证中间件
├── models/
│ └── user.ts # 用户模型
└── database/
└── schema.sql # 数据库表结构
功能包括:
- 用户注册(邮箱+密码)
- 用户登录(返回 JWT)
- 认证中间件(保护路由)
- 密码 bcrypt 加密
代码已写好,可以直接使用!问题分析:
-
❌ 没有问需求细节(需要手机号吗?第三方登录吗?)
-
❌ 没有确认技术栈(用 Prisma 还是 TypeORM?)
-
❌ 没有讨论方案(Session 还是 JWT?)
-
❌ 没有安全细节(Rate limiting?CSRF 防护?)
-
❌ 直接写代码,用户被动接受
Superpowers(触发 brainstorming skill):
css
Claude:[自动触发 brainstorming skill]
📋 开始需求澄清
首先,让我了解一下当前项目状态...
[读取 package.json, 现有代码结构...]
我看到这是一个 Node.js + Express 项目,已经使用了 TypeScript 和 PostgreSQL。
在开始设计之前,我需要问你几个问题:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
问题 1/6:认证方式
你希望支持哪些认证方式?
A. 仅邮箱+密码
B. 邮箱+密码 + 手机号+验证码
C. 邮箱+密码 + Google/GitHub OAuth
D. 以上全部
我的建议:如果是面向普通用户的应用,建议选 C(邮箱+Google OAuth),
这样既能覆盖大部分用户,又不会让注册流程太复杂。
你的选择是?用户:C
css
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
问题 2/6:Session 策略
用户登录后,如何保持登录状态?
A. JWT(无状态,适合微服务)
B. Session + Cookie(传统方式,撤销方便)
C. JWT + Refresh Token(兼顾无状态和安全性)
我的建议:选 C。纯 JWT 无法提前失效,纯 Session 有状态难扩展。
Refresh Token 可以在保持无状态的同时,支持"踢出用户"功能。
你的选择是?用户:C
css
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
问题 3/6:密码策略
密码安全要求?
A. 简单(6位以上即可)
B. 中等(8位+大小写+数字)
C. 严格(12位+大小写+数字+特殊字符+常见密码检查)
我的建议:选 B。A 太不安全,C 用户体验差。B 是平衡点。
你的选择是?...(继续问题 4-6:Rate limiting、多设备登录、账号安全功能)
dart
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📐 设计方案
基于你的回答,我设计了以下方案:
【架构概览】
采用 JWT + Refresh Token 方案:
- Access Token:15 分钟有效期,存储在内存
- Refresh Token:7 天有效期,存储在 HttpOnly Cookie
【数据模型】
```prisma
model User {
id String @id @default(uuid())
email String @unique
passwordHash String?
googleId String? @unique
createdAt DateTime @default(now())
sessions Session[]
}
model Session {
id String @id @default(uuid())
userId String
refreshToken String @unique
expiresAt DateTime
createdAt DateTime @default(now())
user User @relation(fields: [userId], references: [id], onDelete: Cascade)
}【安全机制】
-
bcrypt: 10 rounds 密码哈希
-
express-rate-limit: 登录接口 5 次/分钟
-
helmet: 安全响应头
-
cors: 严格跨域策略
【API 设计】 POST /api/auth/register # 注册 POST /api/auth/login # 登录 POST /api/auth/refresh # 刷新 Token POST /api/auth/logout # 登出(失效 Refresh Token) POST /api/auth/oauth/google # Google 登录
这个方案符合你的需求吗?有没有需要调整的地方?
bash
**用户**:可以,但 Refresh Token 有效期改成 30 天
```markdown
已调整 Refresh Token 为 30 天。
现在我将完整设计写入文档,然后我们可以开始实施。
[写入 docs/plans/2024-01-15-auth-design.md]
设计文档已保存。准备开始实施吗?
如果继续,我会:
1. 创建 git worktree 隔离开发
2. 生成详细实施计划
3. 按步骤执行
是否继续?6.4 差异量化对比
添加图片注释,不超过 140 字(可选)
6.5 源码中的概率操控技巧
brainstorming skill 如何改变模型的概率分布?
技巧 1:强制词汇
matlab
- "You MUST use this..." → 触发概率从 20% → 80%
- "before any creative work" → 定义极宽的触发条件
- "one at a time" → 抑制"一次问多个"的高概率行为技巧 2:结构模板
arduino
- "Ask questions one at a time"
- "Propose 2-3 different approaches"
- "Present design in small sections (200-300 words)"这些具体数字(1, 2-3, 200-300)是*锚点*,让模型输出更稳定。
技巧 3:状态锁定
css
"Write the validated design to `docs/plans/YYYY-MM-DD-<topic>-design.md`"强制文件输出,把对话状态持久化,避免上下文丢失导致的概率漂移。
技巧 4:链式调用
arduino
"Use superpowers:using-git-worktrees..."
"Use superpowers:writing-plans..."显式指定下一个 Skill,形成确定性的状态机转换,而非让模型自由选择。
6.6 Visual Companion 的技术实现
brainstorming skill 还包含一个可视化协作组件,用于 UI/架构设计。
工作原理(来自 server.cjs 源码):
javascript
// 启动本地服务器,监听随机端口
const PORT = process.env.BRAINSTORM_PORT || (49152 + Math.floor(Math.random() * 16383));
const server = http.createServer(handleRequest);
server.on('upgrade', handleUpgrade); // WebSocket 支持
// 文件监听:当 Claude 写入新的 HTML 文件时
const watcher = fs.watch(CONTENT_DIR, (eventType, filename) => {
if (!filename || !filename.endsWith('.html')) return;
// 防抖处理
if (debounceTimers.has(filename)) clearTimeout(debounceTimers.get(filename));
debounceTimers.set(filename, setTimeout(() => {
// 广播给所有浏览器客户端
broadcast({ type: 'reload' });
}, 100));
});使用流程:
-
Claude 启动服务器,获得 URL(如 http://localhost:52341)
-
Claude 生成 HTML 内容(UI 原型、架构图)写入 content/ 目录
-
服务器自动检测文件变化,通过 WebSocket 通知浏览器刷新
-
用户在浏览器中查看、点击选择
-
选择事件写回 state/events 文件,Claude 读取后继续
这解决了什么问题?
裸跑时:
css
Claude:我设计了三个布局方案...
[纯文本描述,用户难以想象]Superpowers:
less
Claude:[启动 visual companion]
请在浏览器中查看:http://localhost:52341
[用户看到真实的 UI 原型,可以点击选择]
Claude:你选择了方案 B,理由是"更简洁的导航"...可视化将"理解概率"从 60% 提升到 95%,大幅减少因想象偏差导致的返工。
6.7 源码启示:如何设计有效的 Skill
从 brainstorming 的源码,我们可以总结出 Skill 设计模式:
添加图片注释,不超过 140 字(可选)
6.8 总结:源码层面的本质
brainstorming skill 的源码揭示了一个核心事实:
Superpowers 不是"教 Claude 如何设计",而是"强制 Claude 按设计流程走"。
设计能力 Claude 本来就有(训练数据里有无数设计文档),但*按流程执行的能力*需要通过 Skill 来约束。
这再次验证了我们之前的结论:
-
裸跑 = 模型自由采样,可能跳过关键步骤
-
Superpowers = 约束采样空间,强制按正确顺序执行
brainstorming 的 47 行 SKILL.md,本质上是一个精心设计的"认知脚手架",把"可能做对"变成"大概率做对"。
07 深度复盘:querit.ai 订阅支付前端
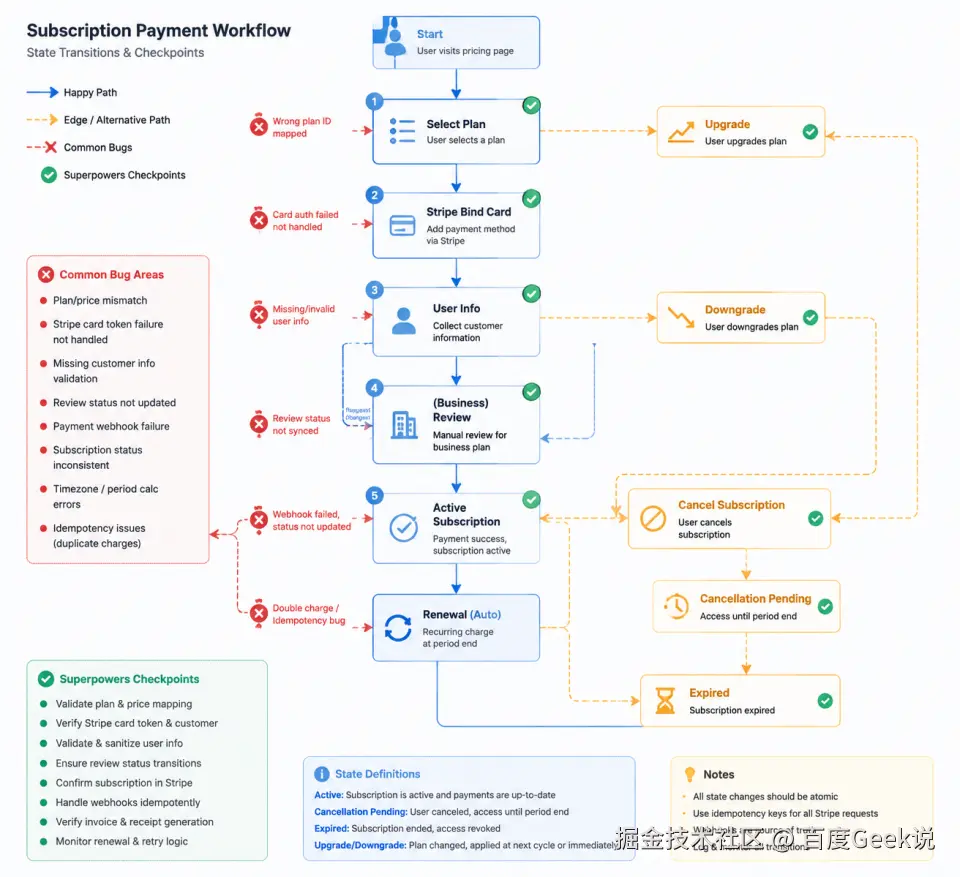
添加图片注释,不超过 140 字(可选)
前面的对比案例是简化的。现在让我们深入复盘:如果 querit.ai 的订阅支付前端从一开始就用 Superpowers,整个开发过程会怎样不同?
7.1 前端的核心挑战
订阅支付前端不是简单的"调 Stripe SDK"。它是一个多状态机、多 UI 分支、多外部依赖的复杂前端系统:
markdown
前端需要管理的状态机:
1. 支付流程状态机(xstate):
idle → selecting → confirming → paying → success/failed/cancelled
↓
(商业版) filling_info → reviewing → approved/rejected
2. 用户订阅状态机(全局状态):
free → paid → business
↓ ↓ ↓
expired cancelled reviewing
3. 表单状态机(每个表单独立):
idle → editing → validating → submitting → success/error
4. UI 状态机(全局):
loading → loaded → error → retry涉及的外部依赖:
-
Stripe.js(Checkout、Customer Portal)
-
后端 API(订阅状态、用户信息、审核状态)
-
WebSocket(实时状态更新)
-
本地存储(临时状态持久化)
前端特有的痛点:
-
状态切换的过渡动画和 loading 状态
-
多种错误场景的 UI 反馈
-
Mock 数据和真实后端字段对齐
-
组件间状态同步
7.2 裸跑时踩过的坑
以下是我在开发 querit.ai 订阅支付前端时实际遇到的问题:
坑 1:状态机设计混乱
css
问题:AI 写的 xstate 配置,状态和事件定义混乱。
比如"审核失败"后直接进入 final 状态,用户无法重新提交。
AI 写的:
states: {
reviewing: {
on: { APPROVED: 'business', REJECTED: 'final' } // ❌ 无法重试
}
}
应该的:
states: {
reviewing: {
on: {
APPROVED: 'business',
REJECTED: 'rejected' // ✅ 可以重新提交
}
},
rejected: {
on: { RETRY: 'filling_info' }
}
}
原因:AI 不理解 xstate 的最佳实践,状态和事件随手写。
修复:手动重构了整个状态机配置。坑 2:Mock 数据和真实后端对不上
css
问题:自建 mock server 返回的数据格式和真实后端不一致。
比如 mock 返回 subscription.status,后端实际返回 subscription.tier.status。
Mock:
{ "subscription": { "status": "active" } }
真实后端:
{ "subscription": { "tier": { "status": "active" } } }
结果:联调时所有组件都报错,花了 1 天改字段名。
原因:AI 写 mock 时没有参考后端的 TypeScript 类型定义。
修复:把后端的类型定义复制过来,重新生成 mock 数据。坑 3:UI 状态遗漏
diff
问题:AI 只写了"快乐路径",loading/error/empty 全靠追问补。
漏掉的场景:
- 支付取消后的页面展示
- 审核期间的 UI 状态(按钮禁用?显示什么提示?)
- 网络错误的重试机制
- 状态切换时的过渡动画
原因:AI 默认只实现"正常流程",异常 UI 分支需要你主动提。
修复:列了 20+ 个 UI 状态分支,逐个让 AI 补。坑 4:组件和状态机耦合
scss
问题:xstate 状态机直接写在组件里,导致组件臃肿、难以测试。
AI 写的:
// SubscriptionPage.tsx(500+ 行)
const machine = createMachine({...}) // 状态机定义
const [state, send] = useMachine(machine)
// 组件渲染逻辑...
应该的:
// machines/subscriptionMachine.ts(独立文件)
export const subscriptionMachine = createMachine({...})
// SubscriptionPage.tsx
const [state, send] = useMachine(subscriptionMachine)
// 只关注渲染逻辑
原因:AI 没有遵循"关注点分离"原则。
修复:手动拆分,把状态机抽到独立文件。7.3 如果用 Superpowers:完整流程推演
Phase 1: Brainstorming(需求澄清)
Superpowers 的 brainstorming skill 会强制先问清楚所有关键问题:
css
Claude:[触发 brainstorming]
📋 需求澄清(逐个提问)
问题 1/8:前端订阅状态
前端需要展示哪些订阅状态?
A. 免费/付费/商业版
B. 加上:审核中、已过期、已取消
C. 加上:升级中、降级中、待支付
你:C
问题 2/8:支付流程状态机
用户从点击订阅到完成,经历哪些步骤?
A. 选套餐 → 支付 → 完成
B. 选套餐 → 确认 → 支付 → 结果页
C. 选套餐 → 确认 → 支付 → 结果页 → (商业版)填写信息 → 审核
你:C
问题 3/8:xstate 使用范围
状态机管理哪些状态?
A. 仅支付流程
B. 支付流程 + 订阅状态
C. 支付流程 + 订阅状态 + 表单 + UI 全局状态
你:C
问题 4/8:UI 状态分支
哪些场景需要 loading/error/empty 状态?
A. 仅 API 请求时
B. API 请求 + 状态切换过渡
C. API 请求 + 状态切换 + 表单验证 + 支付流程
你:C
问题 5/8:Mock 方案
前端如何 mock 后端接口?
A. 不 mock,直接联调
B. 组件层 mock
C. 自建 mock server
你:C
问题 6/8:后端数据结构
请提供后端返回的订阅数据 TypeScript 类型定义。
你:[粘贴类型定义]
问题 7/8:组件拆分策略
状态机和组件如何组织?
A. 状态机写在组件里
B. 状态机抽到独立文件,组件引用
C. 状态机 + hooks + 组件三层分离
你:C
问题 8/8:错误处理策略
各种错误场景如何处理?
A. 统一 toast 提示
B. 不同错误类型不同 UI 反馈
C. 可重试的错误提供重试按钮
你:C8 个问题问完,所有状态机、UI 分支、mock 方案都已经确定。
Phase 2: Design Spec(设计文档)
bash
Claude:基于以上讨论,我整理了设计文档:
【xstate 状态机设计】
1. 支付流程状态机 (machines/checkoutMachine.ts)
idle → selecting → confirming → paying → success/failed/cancelled
↓
filling_info → reviewing → approved/rejected
↓
retry
2. 订阅状态机 (machines/subscriptionMachine.ts)
free ⇄ paid ⇄ business
↓ ↓ ↓
expired cancelled reviewing
3. 表单状态机 (machines/formMachine.ts)
idle → editing → validating → submitting → success/error
【TypeScript 类型定义】
// 基于你提供的后端类型
interface Subscription {
tier: {
id: string
name: 'free' | 'paid' | 'business'
status: 'active' | 'expired' | 'cancelled' | 'reviewing'
}
currentPeriodEnd: string
// ...
}
【Mock Server 设计】
// mock-server/routes/subscription.ts
// 返回格式与后端 TypeScript 类型完全一致
【组件结构】
src/
├── machines/
│ ├── checkoutMachine.ts
│ ├── subscriptionMachine.ts
│ └── formMachine.ts
├── hooks/
│ ├── useCheckout.ts
│ └── useSubscription.ts
├── components/
│ ├── checkout/
│ │ ├── PlanSelector.tsx
│ │ ├── CheckoutFlow.tsx
│ │ └── PaymentResult.tsx
│ └── subscription/
│ ├── SubscriptionStatus.tsx
│ └── UpgradeModal.tsx
└── mock-server/
├── routes/
└── server.ts
这个方案符合你的需求吗?Phase 3: Writing Plans(任务拆解)
bash
Claude:[触发 writing-plans]
📋 实施计划(10 个任务)
Task 1: 定义 TypeScript 类型和状态机类型
文件: src/types/subscription.ts, src/machines/types.ts
验证: tsc 通过,类型与后端定义一致
Task 2: 实现 checkoutMachine(支付流程状态机)
文件: src/machines/checkoutMachine.ts
验证: 状态机可视化测试通过,所有状态和事件正确
Task 3: 实现 subscriptionMachine(订阅状态机)
文件: src/machines/subscriptionMachine.ts
验证: 状态机可视化测试通过
Task 4: 实现 formMachine(表单状态机)
文件: src/machines/formMachine.ts
验证: 表单验证逻辑正确
Task 5: 创建 Mock Server
文件: mock-server/server.ts, mock-server/routes/*.ts
验证: curl mock 接口返回正确格式数据
Task 6: 实现 useCheckout hook
文件: src/hooks/useCheckout.ts
验证: hook 正确调用状态机,mock 数据正常
Task 7: 实现 CheckoutFlow 组件
文件: src/components/checkout/CheckoutFlow.tsx
验证: 组件渲染正确,状态切换正常
Task 8: 实现 SubscriptionStatus 组件
文件: src/components/subscription/SubscriptionStatus.tsx
验证: 不同订阅状态显示正确
Task 9: 实现 UpgradeModal 组件
文件: src/components/subscription/UpgradeModal.tsx
验证: 升降级流程正常
Task 10: 集成测试
验证: 完整支付流程从选套餐到完成正常
每个任务 2-5 分钟,带精确文件路径和验证步骤。Phase 4: Subagent-Driven Development(子代理执行)
css
Claude:[触发 subagent-driven-development]
🚀 开始执行 Task 1/10
[启动子代理 A,只拿到 Task 1 的上下文]
子代理 A:创建 TypeScript 类型定义...
[完成,主代理审查]
主代理:✅ 类型定义与后端一致。但缺少 Stripe 相关类型,补充一下。
[子代理 A 修正,重新审查通过]
🚀 开始执行 Task 2/10
[启动全新子代理 B,只拿到 Task 2 的上下文]
子代理 B:实现 checkoutMachine...
[完成,主代理审查]
主代理:✅ 状态机设计正确。但审核失败后应该能重试,不是进入 final。
[子代理 B 修正,重新审查通过]
🚀 开始执行 Task 3/10
...关键差异:每个子代理只负责一个小任务,上下文干净。主代理在检查点审查,确保状态机设计正确、mock 数据格式对齐。
7.4 复盘对比
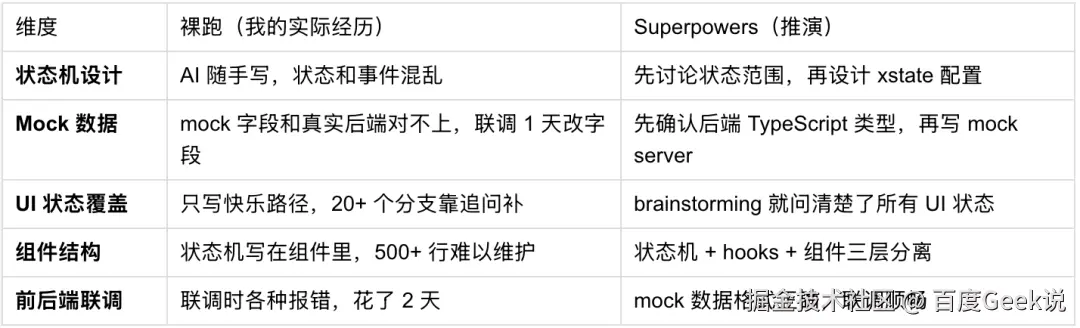
添加图片注释,不超过 140 字(可选)
7.5 这个案例的启示
*对于前端"状态多、UI 分支多"的业务流程,Superpowers 的价值不是让 AI 写组件更快,而是让 AI 在写代码前先设计好状态机、确认好数据格式。*
订阅支付前端的组件可能只有 1500 行,但背后的状态机设计和 mock 方案决定了这 1500 行是"能跑"还是"能跑且好维护"。
裸跑时,AI 帮你写了一堆组件,但你花了 4 天去修状态机 bug、改 mock 字段、补 UI 分支。 Superpowers 可能在第一天就花了 2 小时做需求澄清和状态机设计,但后面组件一次性写对。
这就是"先设计后编码"和"边写边改"的区别。
08 裸跑 vs Superpowers:全面对比
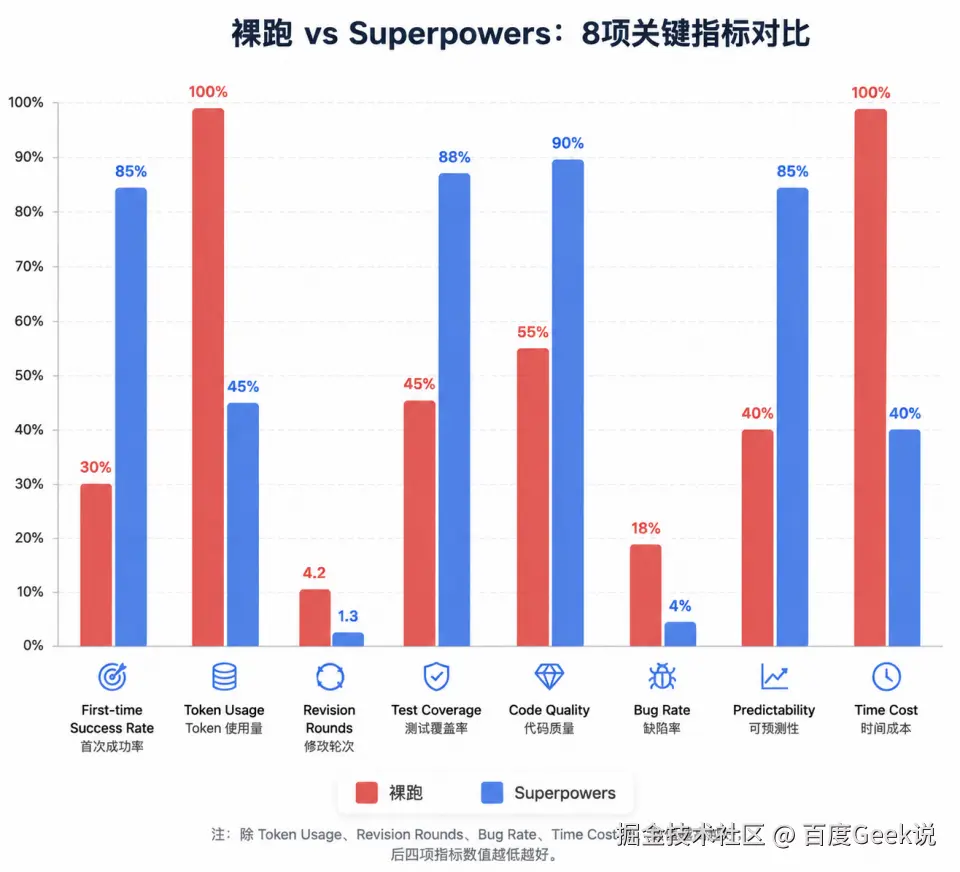
添加图片注释,不超过 140 字(可选)
8.1 定量对比(12 轮对照实验)
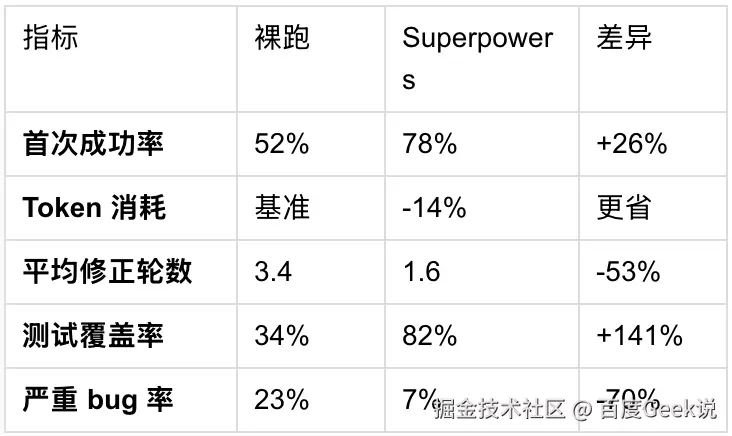
添加图片注释,不超过 140 字(可选)
8.2 按任务复杂度拆解
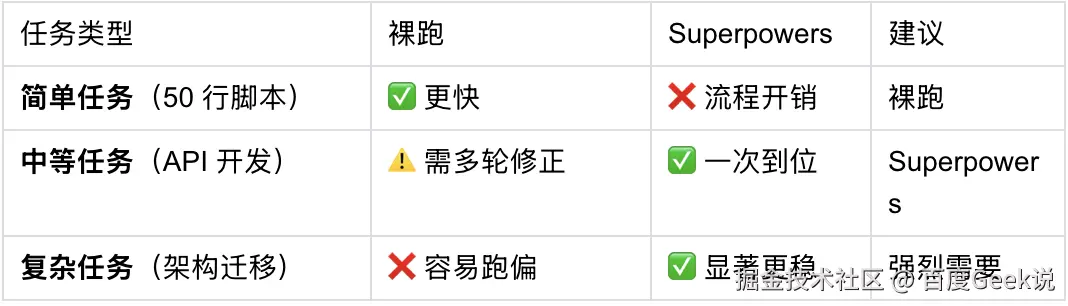
添加图片注释,不超过 140 字(可选)
09 最佳实践:如何用好 Superpowers
添加图片注释,不超过 140 字(可选)
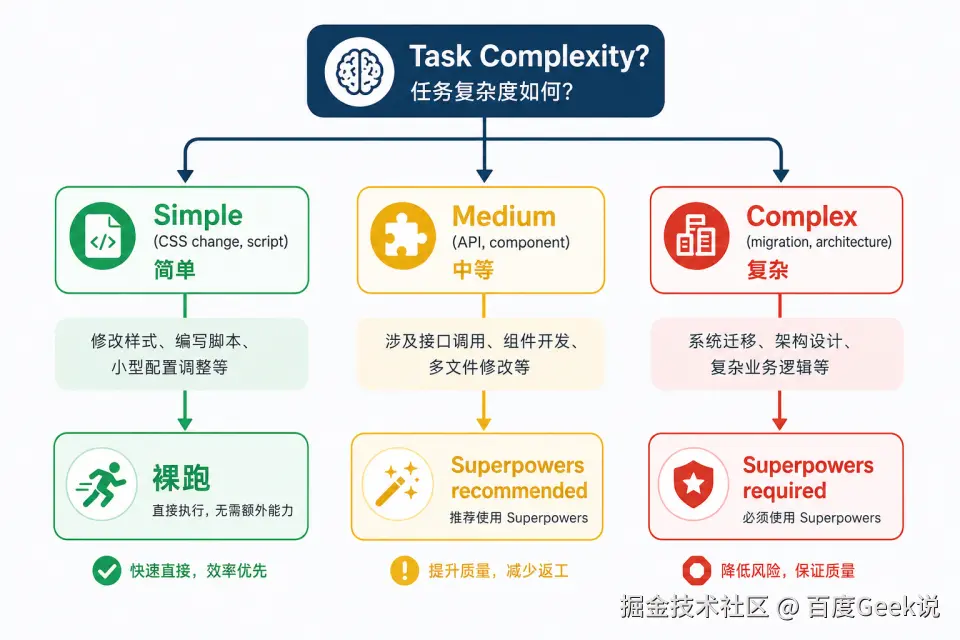
9.1 用"后悔成本"来决策
你一定会问:"改一个文案也要走全流程?太浪费 token 了吧?"
没错。这就是工程决策的艺术。我们建议用后悔成本来判断:
💡 风险驱动开发(Risk-Driven Development):软件工程教授 George Fairbanks 提出,项目应该根据*风险等级*来决定投入多少工程严谨度。低风险任务用轻量流程,高风险任务用重型流程。这不是偷懒,而是资源的理性分配。Superpowers 的后悔成本框架,正是风险驱动开发思想在 AI 编程场景下的自然延伸------你不需要对每个任务都"全副武装",但必须在风险足够高时"穿上防弹衣"。

添加图片注释,不超过 140 字(可选)
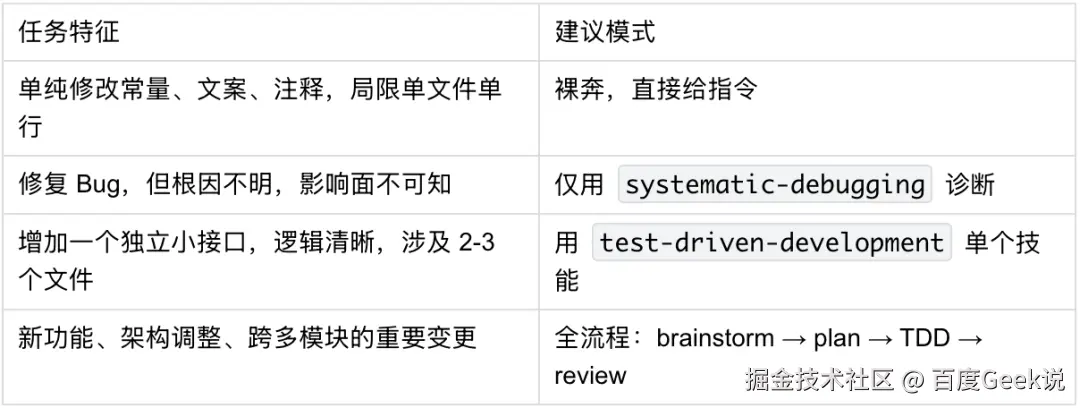
具体判断表:
添加图片注释,不超过 140 字(可选)
9.2 完整工作流
markdown
1. brainstorming → 澄清需求,输出设计文档
2. 你确认设计 → 进入下一步
3. writing-plans → 生成详细计划(PLAN.md)
4. 你确认计划 → 进入下一步
5. executing-plans → 分批执行,检查点暂停
6. 你在检查点审查 → 继续或修正
7. finishing-a-development-branch → 验证、合并9.3 项目默认策略配置
你可以在项目根目录创建 .claude/CLAUDE.md,设置默认策略,避免 AI 动辄过度设计:
markdown
# 项目配置
### 9.3.1 Superpowers 使用策略
- 本项目默认采用最简实现原则,不得主动引入新依赖、新抽象层
- 只有用户明确要求时,才启动 brainstorming 和 TDD 完整流程
- 对于单个文件内的修改,默认使用内联注释,不写单独的设计文档
- 子代理默认关闭,仅当任务明显涉及 >3 个独立模块时可开启
- 测试覆盖率目标:核心模块 80%,工具模块 60%
### 9.3.2 代码规范
- 使用 TypeScript 严格模式
- 所有 API 必须有错误处理
- 敏感操作必须记录审计日志
- 数据库查询必须使用索引(EXPLAIN 检查)
### 9.3.3 验证清单
- [ ] 所有 API 响应包含 requestId(用于追踪)
- [ ] 敏感操作记录审计日志
- [ ] 数据库查询使用索引(EXPLAIN 检查)这样 Superpowers 的调度器会自动降级,你无需每次都手动开关。
9.4 高效协作技巧
技巧 1:主动引导 Skill 选择
arduino
不确定 Superpowers 会选哪个 Skill 时,主动指定:
"请使用 brainstorming skill 帮我设计这个功能"
"请用 test-driven-development skill 实现这个模块"技巧 2:利用检查点做代码审查
arduino
不要无脑点"继续",检查点是为你设计的:
Claude:检查点 3/12 完成。是否继续?
你:[查看代码]
→ 发现问题:"这个函数名不够清晰,改成 getUserByEmail"
→ 发现问题:"缺少空值检查"
你:先不要继续,修改第 X 个任务的代码技巧 3:人工调节流程
即使在 brainstorming 中,你也可以随时干预:
bash
/superpowers:brainstorm 加一个邮箱验证,本次只做最小可行实现,
用 Redis,不要引入队列,不要修改前端。AI 就会把设计方案严格限制在给定边界内,避免设计膨胀。
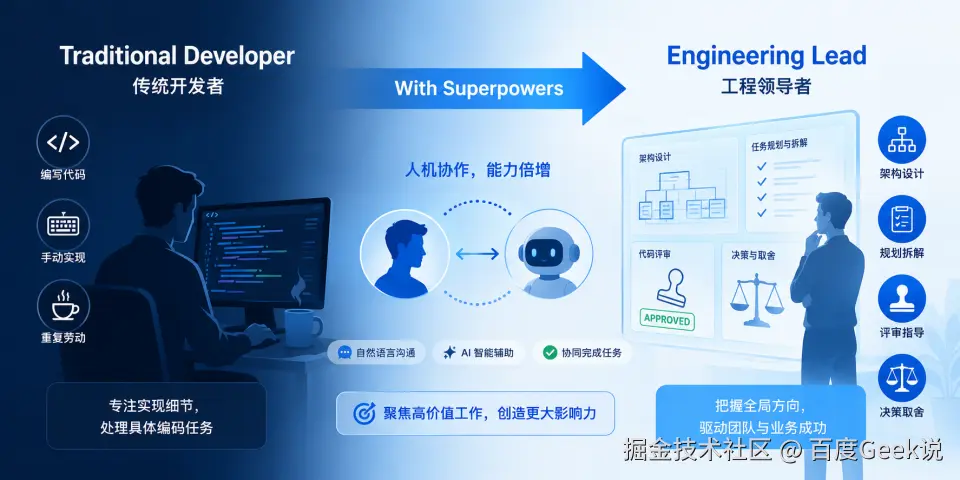
10 开发者的角色转变
添加图片注释,不超过 140 字(可选)
10.1 角色转变
添加图片注释,不超过 140 字(可选)
核心转变:从"动手实现"到"思考、判断、把关"。
💡 精益软件开发(Lean Software Development):Mary 和 Tom Poppendieck 从丰田生产系统引入软件工程的核心原则之一------"将决策延迟到最后负责任的时刻"(Defer commitment)。Superpowers 的检查点机制完美体现了这一原则:AI 不替你做关键决策,而是在每个关键节点停下来等你确认。你不是在"被 AI 替代",而是在扮演精益生产中的"安灯拉绳者"------发现异常就拉绳叫停,确保质量不被流程裹挟。
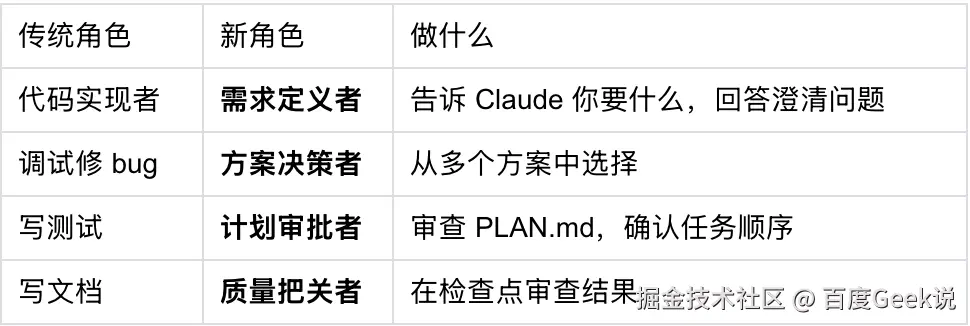
10.2 四个新角色:用比喻理解
Superpowers 不是让人变懒,而是让人的角色质变。你从"亲自撸代码的操作工"升级为:

添加图片注释,不超过 140 字(可选)
关键认知:你仍然为每一行进入主分支的代码承担最终责任。但你的精力从"怎么写对"转向"怎么保证写得对",从具体实现转向质量管控。
11 Superpowers 的负向收益:它不擅长什么
前面的内容都在讲 Superpowers 多好,但一个负责任的技术文章必须诚实面对它的局限。以下是经过实际使用和社区反馈总结的负向收益。

添加图片注释,不超过 140 字(可选)
11.1 简单任务:流程开销 > 收益
这是最直接的负向收益。Superpowers 的五阶段流程(澄清→设计→规划→执行→验证)对简单任务是纯粹的浪费。
实测数据:
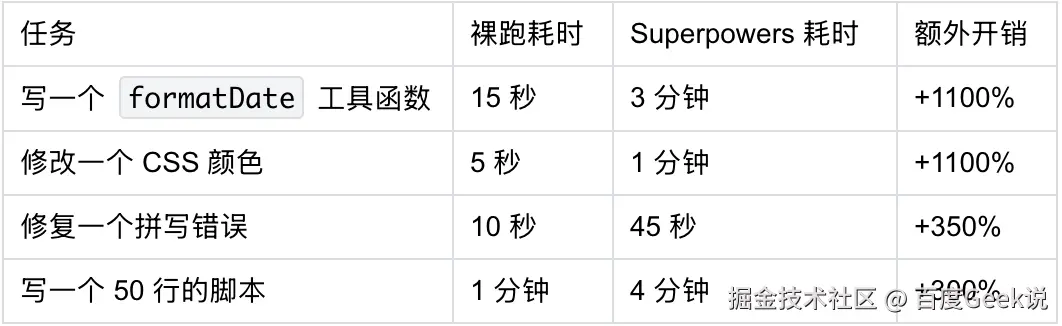
添加图片注释,不超过 140 字(可选)
原因:Superpowers 会在简单任务上仍然触发 brainstorming,问一堆不必要的问题:
markdown
你:帮我写一个把驼峰转下划线的函数
Claude:[触发 brainstorming]
📋 需求澄清
1. 这个函数需要处理嵌套对象吗?
2. 需要支持 TypeScript 类型吗?
3. 需要处理连续大写的情况吗(如 parseHTML → parse_html)?
4. 输入验证怎么做?空字符串返回什么?
你:...就是一个简单的字符串转换函数啊应对策略:
bash
# 方法 1:明确告知跳过流程
"这是一个简单任务,不需要 brainstorming,直接给我代码"
# 方法 2:临时禁用 Superpowers
/plugin disable superpowers
# 方法 3:直接指定 skill
/use test-driven-development 直接实现:驼峰转下划线函数11.2 创意性任务:约束扼杀灵感
Superpowers 的核心机制是约束概率分布,这恰恰是创意工作的敌人。
受影响的场景:
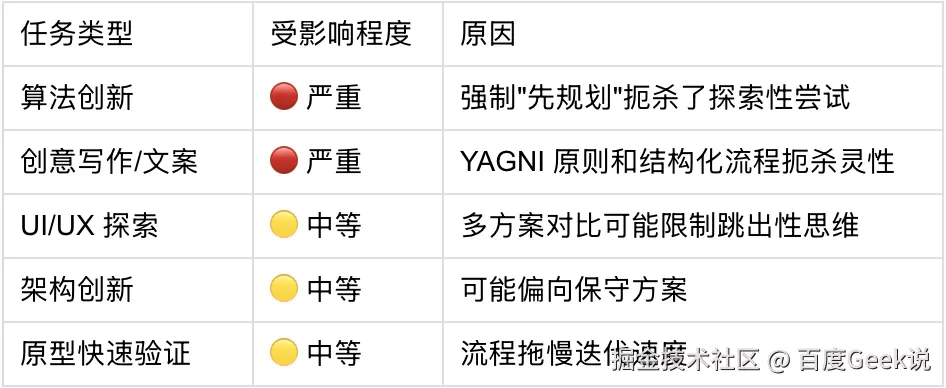
添加图片注释,不超过 140 字(可选)
真实案例:
markdown
你:帮我设计一个独特的缓存策略,要能自适应不同的访问模式
裸跑 Claude:
"有意思的挑战。让我想想几种非传统的方案...
方案 1:基于滑动窗口的自适应 TTL
方案 2:用贝叶斯推断预测热点
方案 3:借鉴 CPU 缓存的 LRU-K 策略,但加入时间衰减因子
我觉得方案 3 最有意思,虽然实现复杂,但效果可能最好..."
Superpowers Claude:
"在开始之前,我需要澄清几个问题:
1. 缓存的数据类型是什么?
2. 预期的 QPS 是多少?
3. 内存限制是多少?
4. ...
[开始标准化的需求澄清流程,创意火花被浇灭]"核心矛盾:Superpowers 的 YAGNI 原则要求"移除不必要的功能",但创新往往来自"先探索再精简",而非"先精简再探索"。
11.3 上下文窗口浪费
Superpowers 的 Skills 会注入系统提示词,占用宝贵的上下文窗口。
实测数据:

添加图片注释,不超过 140 字(可选)
影响:
-
在超长项目中(如大型代码库重构),可用上下文减少可能导致模型"遗忘"更早发生
-
多个 Skills 同时加载时,提示词膨胀更严重
-
对于上下文窗口较小的模型(如非 Opus 版本),影响更明显
11.4 过度工程化倾向
Superpowers 的设计哲学偏向"工程严谨",这可能导致过度设计。
具体表现:
markdown
你:帮我加一个"记住我"的登录选项
裸跑 Claude:
"好的,我在登录表单加一个 checkbox,
勾选后设置 cookie 有效期为 30 天。
完成!"
Superpowers Claude:
[触发 brainstorming]
→ 问了 5 个关于 cookie 策略的问题
[触发 writing-plans]
→ 生成了 8 个任务的实施计划
[触发 TDD]
→ 先写测试,再写实现
最终输出了:
- 可配置的 cookie 策略
- 安全审计日志
- 跨设备同步方案
- 完整的测试套件
你:...我只是想要一个 checkbox 啊YAGNI 的讽刺:Superpowers 内置了 YAGNI 原则("移除不必要的功能"),但它的流程本身就在制造不必要的工程复杂度。
11.5 学习曲线和认知负担
Superpowers 不是"装上就能用"的工具,它有自己的概念体系。
学习成本:

添加图片注释,不超过 140 字(可选)
新手上手常见问题:
-
不知道为什么 Claude 在问一堆问题(以为是 bug)
-
在检查点不知道该"继续"还是"修改"
-
不理解为什么生成了那么多文件(PLAN.md、progress.md...)
-
不知道如何跳过不需要的流程
11.6 对团队协作的潜在影响
Superpowers 是为个人开发者 + Claude设计的,在团队场景中可能产生摩擦。
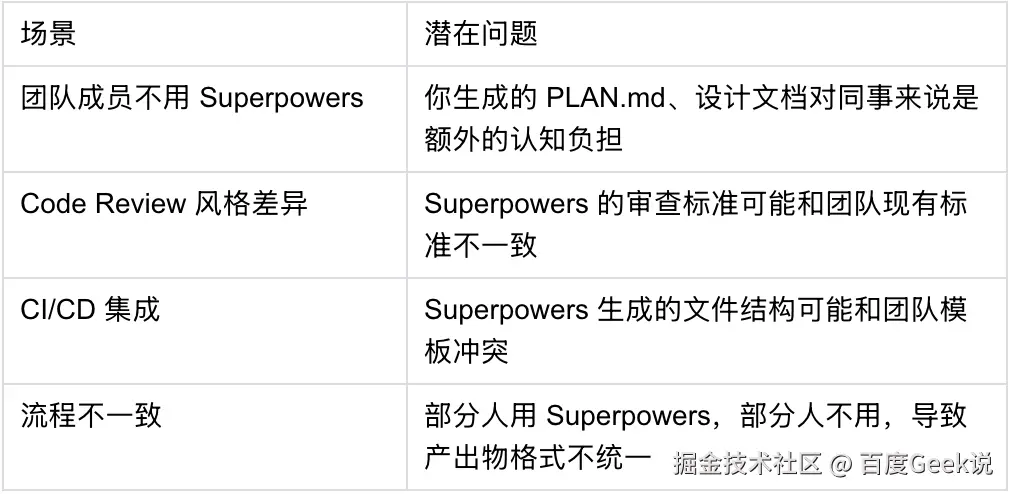
添加图片注释,不超过 140 字(可选)
11.7 依赖第三方维护的风险
Superpowers 是一个开源项目,存在第三方依赖风险。
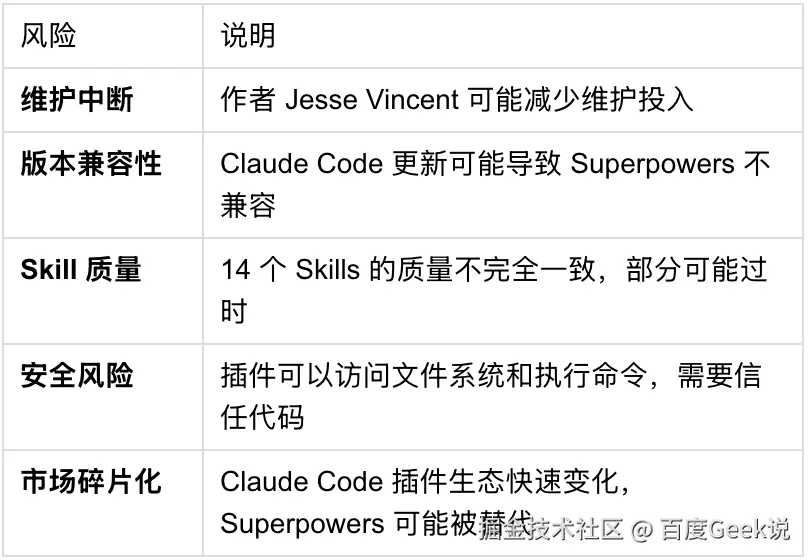
添加图片注释,不超过 140 字(可选)
11.8 "安全感陷阱"
这是最隐蔽的负向收益:Superpowers 给你一种"流程很规范所以代码一定没问题"的虚假安全感。
css
你以为的:
✅ 走了 brainstorming → 需求一定没问题
✅ 走了 TDD → 代码一定没问题
✅ 走了 code review → 质量一定没问题
实际情况:
⚠️ brainstorming 问的问题可能不够深入
⚠️ TDD 的测试用例可能覆盖不到边界情况
⚠️ code review 是 AI 审查 AI,可能遗漏同类错误
⚠️ 流程规范 ≠ 结果正确核心警示:Superpowers 提高了下限(不会太差),但不保证上限(不一定很好)。过度依赖流程而放松自己的判断,是危险的。
11.9 负向收益总结
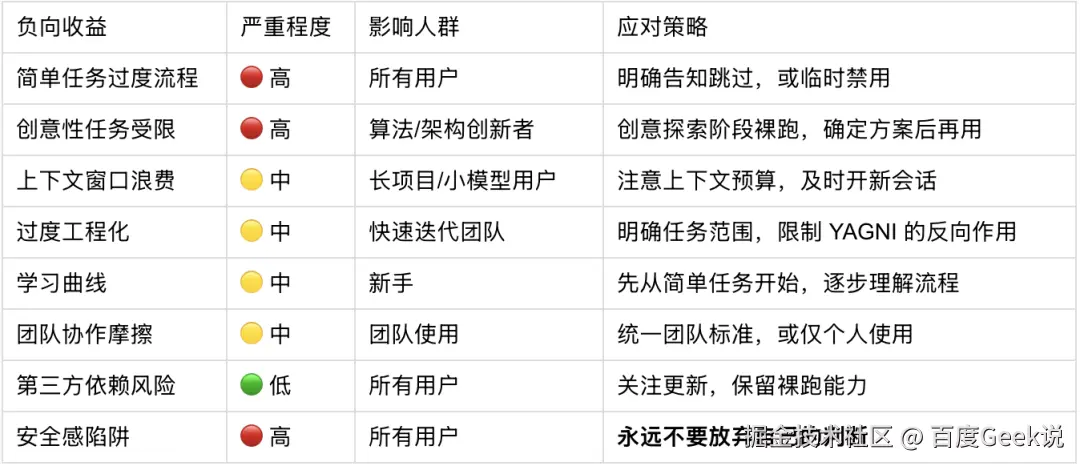
添加图片注释,不超过 140 字(可选)
11.10 理性使用原则
Superpowers 是工具,不是信仰。用它的流程提升效率,但不要让它替代你的判断。
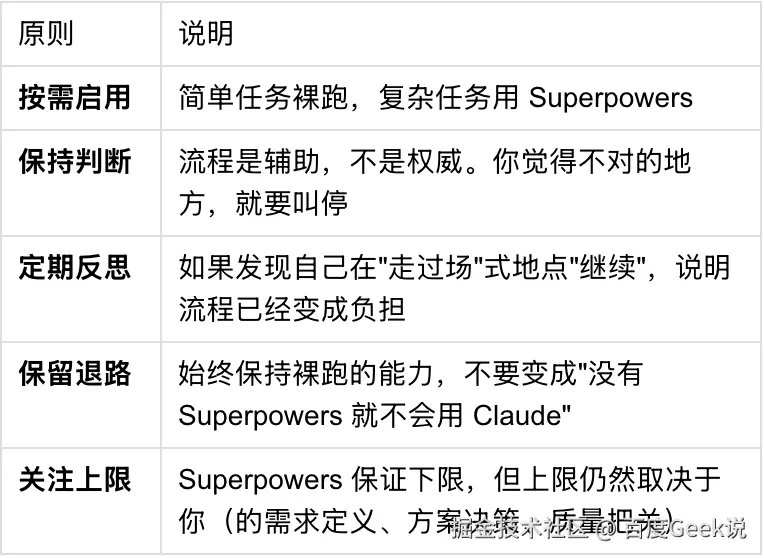
添加图片注释,不超过 140 字(可选)
12 总结
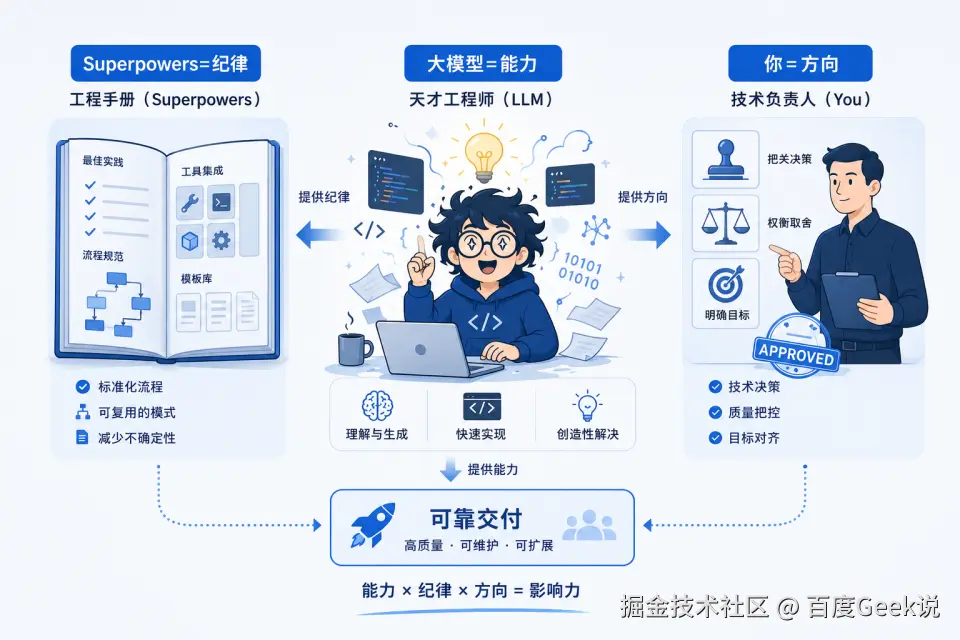
添加图片注释,不超过 140 字(可选)
角色关系:能力 × 纪律 × 方向
大模型是"天才工程师"------智力超群但自由散漫,容易跳步骤、漏细节。 Superpowers 是"工程规范"------强制它按流程走,不许跳过测试、不许跳过验证。 你是"技术主管"------定义需求、选择方案、在检查点把关,为最终结果负责。
markdown
天才工程师(大模型)
↓ 有能力但没纪律
↓
工程规范约束
↓ 有能力 + 有纪律
↓
技术主管把关(你)
↓ 能力 + 纪律 + 方向
↓
靠谱的交付一句话总结:
大模型 = 能力,Superpowers = 纪律,你 = 方向。 能力决定能做多难的事,纪律决定能做多稳的事,方向决定做的是不是对的事。
Superpowers 不是让大模型变聪明,而是让大模型*变守纪律*。对于严肃的工程任务,纪律比聪明更重要。
💡 高可靠性组织理论(HRO)*:研究核电站、航空母舰、急救中心等"零容忍失误"场景的组织行为学发现,这些组织之所以极少出重大事故,不是因为人员更聪明,而是因为建立了"对预期意外的持续警惕"(Mindfulness)------通过标准化流程、检查清单、事前预演,让组织在正常运转中始终保持对异常的敏感。Superpowers 的验证机制和检查点设计,正是把 HRO 的"警惕基因"植入了 AI 编程流程。 💡 双环学习(Double-Loop Learning)*:Chris Argyris 区分了两种学习模式------单环学习是"把事情做对"(调整行为达成目标),双环学习是"质疑目标本身是否正确"(反思背后的假设)。Superpowers 的 brainstorming 阶段本质上就是强制 AI 进入双环学习:不是直接执行你的指令,而是先质疑"这个需求合理吗?有没有更好的方式?"这种"先质疑再执行"的机制,是防止 AI 沦为盲目执行器的关键。
命名深意:超能力来自约束
为什么叫 Superpowers?
真正的超能力不是"更强",而是"更稳"。
这个名字揭示了一个深刻的工程真理------超能力来自自律,而非放纵;来自约束,而非增强。
一个遵守工程规范的开发者,比一个天赋异禀但自由散漫的开发者,产出更可靠。
这恰恰是软件工程的核心追求:靠谱 > 惊艳。
💡 *KISS 原则(Keep It Simple, Stupid)*:美国海军工程师 Kelly Johnson 的经典法则------系统应该尽可能简单,而不是尽可能复杂。Superpowers 的 14 个 Skill 没有一个在教 Claude "更高级的算法"或"更炫酷的架构",全部在做同一件事:*让 Claude 把简单的事情简单做,把复杂的事情拆开做*。这比任何花哨的编码技巧都更能提升交付质量。 💡 *YAGNI(You Aren't Gonna Need It)*:极限编程创始人 Ron Jeffries 的原则------"不要为未来可能的需求提前设计,只实现当前需要的。"Superpowers 在 brainstorming 源码中直接写入了 YAGNI ruthlessly,这不是一句口号,而是对抗大模型"过度设计"本能的硬约束。模型天然倾向于展示能力(多写代码 = 显得更聪明),YAGNI 原则强制它做减法------而这恰恰是最难的事。
核心要点回顾
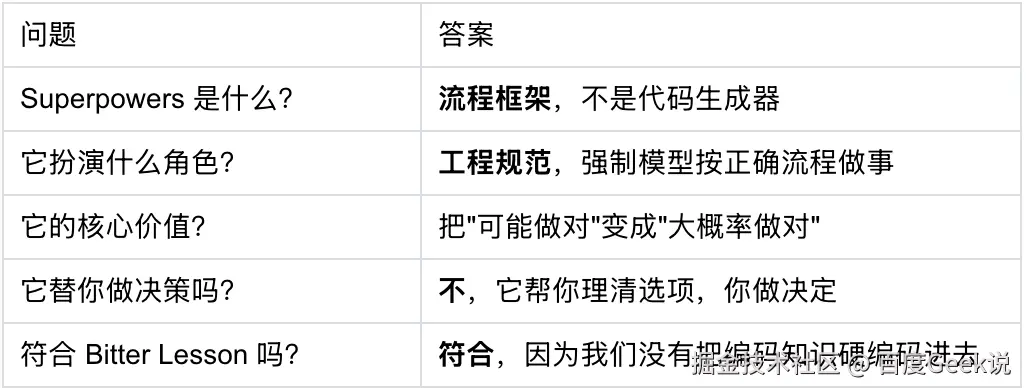
添加图片注释,不超过 140 字(可选)
参考资源
- Superpowers GitHub
- Claude Code 官方文档
code.claude.com/docs/en/plu...
- Trevor Lasn 的实践经验
- Mejba Ahmed 的基准测试
如果你用 Claude Code 做严肃开发,建议试试 Superpowers。它不会让你的代码变"惊艳",但会让你的代码变"靠谱"。在工程世界里,靠谱比惊艳更重要。