一、故障
分布式系统里,最危险的往往不是失败本身,而是你不知道失败发生在哪
客户端只能看到三种情况:
-
收到回复 ✅
-
没收到回复 ❌
-
等太久了(超时)⏰
客户端看不到的是:
-
请求丢了?
-
服务端挂了?
-
网络慢了?
-
回复丢了?
四类故障:
| 故障类型 | 通俗解释 | 比喻 |
|---|---|---|
| Crash(崩溃) | 进程或机器直接挂了 | 工人晕倒了,不再干活 |
| Omission(遗漏) | 消息丢了,没送到 | 快递在路上丢了 |
| Delay(延迟) | 消息太慢,还没到 | 快递堵路上了 |
| Partition(分区) | 网络断开,两边都活着但互相联系不上 | 两个办公室之间的电话线断了 |
1、Crash fault(崩溃)
进程挂了,机器挂了,服务器停了
特点:他不再继续执行,之后也不再回复
例子:服务端执行到一半,进程崩溃了。客户端一直等不到回复。
客户端知道什么? 只知道没等到结果。不知道是没收到,还是收到了但崩了。
2、Omission Fault(遗漏)
消息本该发送或接收,但它没有出现
两种情况:
| 类型 | 发生了什么 | 服务端执行了吗? |
|---|---|---|
| Request lost | 请求丢了 | ❌ 没有执行 |
| Reply lost | 请求到了,执行了,回复丢了 | ✅ 执行了 |
从客户端看,两种情况一模一样------都是超时
Request Lost:

Reply Lost:

3、Delay(延迟)
不是所有 timeout 都代表故障。可能只是网络慢、对方忙、排队太久、调度延迟
现实问题:
-
如果服务端只是慢,你过早重试 → 制造重复请求
-
你一直傻等 → 用户体验差
4、Network Partition(网络分区)
集群没有整体挂掉,但一部分节点彼此通信不了
每个人都觉得对方挂了,实际上双方都活着
这个故障非常麻烦:因为两边都可能继续各自行动,导致数据不一致
5、总结

二、如何处理以上这些故障
看到timeout,是否应该retry?retry之后会不会导致重复执行?
1、Maybe Semantics(也许语义)
发一次,等一会,没结果就判断为报错
适合:把错误暴露给上层,让应用自己决定是否重试
不适合 :用户以为报错就一定没生效
告诉你:结果不确定(可能任务已经被执行了,也可能没执行)
2、自动retry
client stub会:等待一段timeout的时间;如果没有回复,就重新发送request;重复
但可能导致副作用:如重复扣款
适合哪些操作:
| 场景 | 例子 | 为什么安全 |
|---|---|---|
| 操作是只读的 | 查询余额、读文件 | 读多少次结果都一样 |
| 操作是幂等的 | "把值设为 5"、"删除这个文件" | 重复执行效果一样 |
| 应用层自己能处理重复 | 自己做了去重 | 业务层面兜底 |
3、At-Least-Once(至少一次)(和上面的自动retry差不多)
策略内容:Client 等待一段时间,没收到回复就重发请求。重复几次还没回复就返回错误。
通过重试,尽量让请求最终被执行。但可能导致重复执行
适合:幂等操作,可重复计算的任务,应用能自己消化重复计算的场景
4、At-Most-Once(最多一次)
策略内容:Client 给每个请求附带一个唯一 ID(xid)。Server 记录已经处理过的 xid。收到重复的 xid → 返回缓存的结果,不重新执行。
即:一个请求最多执行一次,重传不会让 handler 再跑一遍
主要问题:识别重复duplicate request,同时需要服务端记住已经处理过什么
如何识别duplicate request?

伪代码:
if seenxid {
return oldReplyxid // 返回缓存的结果
}
reply = handler(req) // 第一次执行
seenxid = true
oldReplyxid = reply
return reply
At Most Once解决了:因为重传导致的重复执行
注意:这一语义需要服务端持久化去重表(否则重启后可能忘记)
5、exactly-once(恰好一次)
很难真正保证,尤其是操作影响外部世界(吐钞、发短信)。因为系统可能在"执行动作"和"记录结果"之间崩溃
6、总结
分布式环境里最难受的不是会失败,而是失败常常表现得不透明 。
timeout 只告诉你"结果未知",未知状态下的重试会影响正确性。
三、物理时钟
前面都在研究:任务到底有没有执行
接下来看:到底谁先发生
单机上的时间:
单机程序会借助时间做很多事情:
- 写日志
- 设置timeout时间
- 做缓存过期清除
在一台机器上,大家至少共享同一个物理时钟
但如果是多机的情况:
每台机器都有自己的物理时钟,会导致以下问题:
| 两种情况 | 通俗解释 | 比喻 |
|---|---|---|
| Clock Skew | 两个时钟此刻的差值 | 你的表和我的表,现在相差 3 分钟 |
| Clock Drift | 时钟走动的速度不一样 | 你的表一天快 1 秒,我的表一天慢 0.5 秒 |
常见判断:时间戳更小,就一定更早发生(错)
原因:因为不同机器的表,本来就可能没对齐
物理时钟不可靠的原因:网络有不可预测的延迟
物理时钟同步:让多台机器的时钟尽量保持一致
检验是否同步的朴素方法:
客户端向时间服务器(Time Server)发 RPC 请求:"现在几点了?"
服务端回复:"现在是 10:00:00.000"
问题在哪?
客户端收到回复的时候,时间已经过去了。比如:
-
服务端回复时:10:00:00.000
-
网络传输耗时:0.010 秒
-
客户端收到时:实际已经是 10:00:00.010
如果客户端直接用服务端回复的"10:00:00.000",它的钟就慢了 0.01 秒。
引入 Cristian 算法
核心思想:测量网络来回花了多久,然后估算出更准确的时间
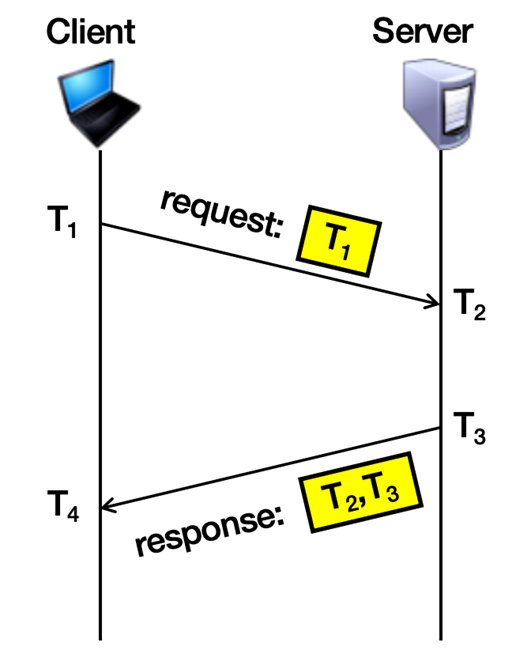
| 记号 | 含义 |
|---|---|
| T1 | 客户端发出请求的时刻 |
| T2 | 服务端收到请求的时刻 |
| T3 | 服务端发出回复的时刻 |
| T4 | 客户端收到回复的时刻 |
Cristian算法的目标:
- 整个来回花费了多久时间
- 自己的时钟和服务器的时钟之间差了多少时间
Cristian算法的前提假设:请求去程和回复回程的网络延迟大致相等
Cristian算法计算:
1)计算整个来回花了多少时间
往返总时间 = T4 - T1
2)计算单程所花费的时间
单程延迟 ≈ (T4 - T1) / 2
3)计算客户端应该用的时间
正确时间 ≈ T3 + 单程延迟
≈ T3 + (T4 - T1) / 2
Cristian算法的局限性:
该算法依赖一系列假设条件
| 依赖 | 说明 |
|---|---|
| 网络延迟别太抖 | 如果去程慢、回程快,平分就不准 |
| 时间服务器足够准 | 如果服务器本身也不准,那白忙了 |
| 来回路径差异不大 | 数据包走的路径可能不一样 |
它得到的是估计值,不是真相
工程上实际常运用的是:NTP协议
| 要点 | 说明 |
|---|---|
| 1 | 通过多次采样,估算 offset(偏差)和 delay(延迟) |
| 2 | Internet 上通常能做到毫秒级精度 |
| 3 | 它仍然不是精确同步,只是"足够好" |
在校验时,如果发现本地时钟有慢的情况,如何调整?
如果本地时钟偏快,不能 直接往回调时间
如:
Go
lastCheck := time.Now()
for {
if time.Now().Sub(lastCheck) > 5秒 {
doSomething()
lastCheck = time.Now()
}
}对于这段程序,
如果校时把你的钟从 10:00:10 突然拨回 10:00:05:
-
time.Now()突然变小了 -
Sub()可能变成负数 -
定时器逻辑全乱套了
而正确的做法应该是:
不是直接"拨回去",而是:
-
调整走表速度:让钟走得慢一点或快一点,慢慢追上
-
保证单调递增:时间只往前走,不往后退
保证 monotonicity(单调性)
物理时钟总结
物理时钟很有用。但如果你的目标是:
-
判断事件先后
-
设计分布式正确性条件
单靠 wall clock(物理时钟)还不够
原因:
-
时钟再准,也有误差(毫秒到秒级)
-
网络延迟不可预测
-
两台机器的钟不可能完全一致
四、逻辑时钟(Lamport Clock)
Lamport的关键:先不要执着于真实几点几分几秒,先抓住真正重要的顺序关系
1、Happens-before
| 规则 | 说明 | 例子 |
|---|---|---|
| 规则1:同一进程内的程序顺序 | 同一个进程里,先执行的在后执行之前 | P1 的 a 事件在 b 事件之前,所以 a → b |
| 规则2:消息发送先于接收 | 发送消息一定在接收消息之前 | P1 发送 m → P2 接收 m,所以 send(m) → recv(m) |
| 规则3:传递性 | 如果 a → b 且 b → c,那么 a → c | 因果链可以传递 |
举例:
P1: a --- b ----send m---->
P2: recv m--- c
根据规则:
-
a → b(同一进程内)
-
b → send(m)(同一进程内)
-
send(m) → recv(m)(消息发送先于接收)
-
recv(m) → c(同一进程内)
所以:a → c(通过传递性)
逻辑时钟更加注重:哪个事件在先;哪些事件之间可以建立因果链;哪些事件无法进行比较
而不在意:绝对时间
但不是所有事件都可以进行比较
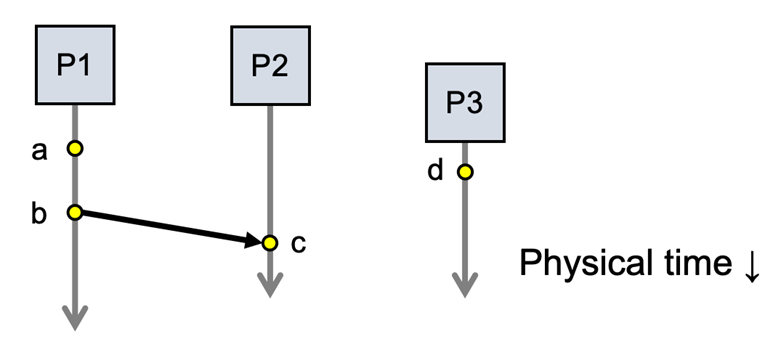
如果两个事件之间不在同一进程顺序里,也没有消息链把它们连起来,那它们可能是 concurrent(并发) ,记作 a || d
注意:
- concurrent 不一定是"同时发生"
Concurrent只是表达:
-
系统没有足够信息证明谁先谁后
-
因为它们之间没有因果关系
即:concurrent 表达的是"不可比较",不是"同时发生"
很多分布式问题并不要求知道真实时间。它们只要求:因果不能被颠倒。明明依赖了前一个事件,排序时别排反。
Lamport Clock 的目标:
-
目标不是贴近 UTC(真实时间)
-
目标是满足:如果 a → b,那么 C(a) < C(b)
2、Lamport Clock 的规则(核心!)
规则1:本地事件
每个进程维护自己的本地计数器 Ci。在每个本地事件发生前:Ci = Ci + 1
比喻:你每做一件事,就在自己的小本本上写一个数字,每次加 1。
进程 P1: 事件 a(1) → 事件 b(2) → 事件 c(3)
进程 P2: 事件 d(1) → 事件 e(2) → 事件 f(3)
规则2:发送消息
发送消息时,先给发送事件打时间戳,再把当前时钟值一起放进消息里。
比喻:你写信的时候,在信封上写个编号,然后把信寄出去。
进程 P1: b(2) → send m(带着 2 出去)
规则3:接收消息
收到消息时:Cj = max(Cj, C(m)) + 1
比喻:你收到一封信,看到信封上的编号是 2。你把自己的编号和 2 比较,取较大的那个,再加 1,作为这个事件的时间戳。
进程 P2: 当前 C2=1,收到消息 m 带着 C(m)=2
C2 = max(1, 2) + 1 = 3
注意:
为什么要取 max 再加 1?
因为接收事件必须晚于两件事:
-
本地已经发生过的事件(所以不能比当前 C2 小)
-
对方发送该消息的事件(所以不能比 C(m) 小)
取 max 是为了同时尊重这两条约束
3、Lamport Clock 保证了什么?不保证什么?
保证:
如果 a → b,那么 C(a) < C(b)
这足够让很多分布式算法避免把因果排反。
比喻:凡是有因果关系的,时间戳一定递增。
不保证(同样重要!)
反过来不成立:C(a) < C(b) 不代表 a → b
原因:可能是两个并发事件,数字碰巧排出了先后。
例:
初始: C1=0, C2=0
P1: 本地事件 a → 得到 C(a)=1
P2: 本地事件 d → e → 得到 C(d)=1, C(e)=2
事件 a(时间戳 1)和事件 d(时间戳 1):C(a) < C(d) 是假的
事件 a(时间戳 1)和事件 e(时间戳 2):C(a) < C(e) 是真的
但 a 和 e 是 concurrent 的(没有因果关系)
数字的先后并不等于因果的先后
4、总结
| Lamport Clock 能做什么 | Lamport Clock 不能做什么 |
|---|---|
| 安全地保留必要顺序 | 精确恢复全部因果关系 |
| 保证 a→b 时 C(a)<C(b) | 判断两个事件是否真的有因果关系 |
| 构造一个一致的事件排序 | 区分"有因果"和"并发" |
它适合用来构造一个一致的事件排序,但不适合判断两个事件是否真的有因果关系。
5、Total Order
为了给任意两个事件都排出一个先后,可以在 Lamport 时间戳的基础上拼上一个进程 ID
例如:
(5, P1) < (5, P2) // 时间戳相同,进程 ID 小的先
Total Order的作用:让系统里所有节点都按同一顺序处理事件
为什么需要这个Total Order?
假设账户余额是 1000,有两个更新:
-
U1 = Deposit(100)(存 100)
-
U2 = Interest(1%)(利息 1%)
如果顺序不同:
-
U1 → U2:(1000+100)×1.01 = 1111
-
U2 → U1:1000×1.01+100 = 1110
结果不一样! 所以系统必须选一个统一顺序,让所有副本按同样的顺序执行。
Total Order的局限性:
Total order 说的是:系统人为选出一个统一顺序。但它不等于这个顺序就是物理世界里的真实先后。
比如:两个并发事件,系统强行排了一个顺序(比如按进程 ID),但这不代表物理上它们真的是一先一后。
五、向量时钟(Vector Clock)
Lamport Clock 只能告诉你"顺序",不能告诉你"因果"
向量时钟(Vector Clock),它可以区分:
-
两个事件有因果关系
-
两个事件是并发的(无因果关系)
向量时钟的核心思想:
不是用一个整数。而是每个进程维护一整个向量:自己知道的每个进程时间进展。这样信息更丰富。代价也更高。
| 时钟类型 | 比喻 |
|---|---|
| Lamport Clock | 你只知道"我做过 5 件事" |
| Vector Clock | 你知道"A 做过 3 件事,B 做过 2 件事,C 做过 4 件事" |
向量时钟保存的信息更多,能判断因果关系。
向量时钟能判断两个事件有没有因果关系(比 Lamport Clock 更精确),但代价是传递的信息量更大。整个分布式系统的核心困难就是两件事:你无法知道"到底有没有执行",也无法知道"到底谁先发生"。
六、本章总结
timeout 只说明结果未知,不说明没执行;物理时间戳只能近似对齐,不能可靠表达全部顺序;真正关键的是故障语义和 happens-before
核心概念:crash / omission / delay / partition;maybe、at-least-once、at-most-once;happens-before、Lamport clock、concurrent