概述
AI、LLM、Agent实在是太火爆,关于为LLM增加记忆能力的研究也层出不穷。参考:
- Agent记忆理论与实现:Mem0、MemU、MemOS
- Agent记忆框架(二):Memvid、Memary、MemoryOS
- Agent记忆框架(三):Zep、MIRIX、Memobase、LightMem、LangMem、A-MEM、MemTool
本文继续汇总介绍。
Benchmark
之前一直遗漏一个关键环节,基准测试评估数据集。
LongMemEval
论文,GitHub,另外还有V2版本开源在GitHub。一个全面评估聊天助手长期记忆能力的基准测试。该基准测试设计了500个精心策划的问题,涵盖五个核心长期记忆能力:信息提取、多会话推理、时间推理、知识更新和回避。提出一种统一框架,将长期记忆设计分解为索引、检索和阅读阶段的四个设计选择,并提出几种优化策略,包括会话分解、事实增强键扩展和时间感知查询扩展。
评估AI代理长期记忆能力的权威测试框架:
- 测试任务类型:事实记忆准确性、经验回顾完整性、模式识别能力
- 评估指标体系:准确率、召回率、F1分数、响应延迟、内存效率
LoCoMo
ConvoMem
MemBench
MemPalace
官网,开源(GitHub,55K Star,7.2K Fork)本地运行的AI长期记忆系统。
架构设计创新:
- 三层存储结构:Wing(人物/项目)-Room(主题)-Drawer(原始内容)的层次化设计
- 本地优先原则:数据完全存储在用户本地,无API调用需求
- 可插拔后端:支持ChromaDB、SQLite、Qdrant、PgVector等多种存储后端
- MCP服务器集成:提供29个MCP工具,与Claude Code等工具深度集成
技术实现优势:
- 无LLM依赖的检索:核心检索功能不依赖外部LLM API
- 嵌入式模型:自带
embeddinggemma-300m等多语言嵌入模型 - 知识图谱支持:包含时间实体关系图,支持有效性窗口管理
存储结构借用记忆宫殿的概念:
- Wing(翼)是顶层单位,如一个项目或一个人
- Room(房间)是具体话题,如
auth-migration、deploy-process - Closet(壁橱)是压缩索引,指向原始内容的位置
- Drawer(抽屉)是逐字保存的原始对话文本
- Tunnel(隧道)做跨翼关联,如果不同项目里聊到同一个话题,graph层可自动把它们连起来
4层渐进式加载的记忆栈:
- L0:身份层,大概50个Token,告诉AI它是谁、服务谁
- L1:关键故事层,大概500-800 Token,系统自动从所有记忆里挑出最重要的15个时刻,按房间分组,作为每次AI唤醒时的核心上下文
- L2:按需回忆层,只有聊到某个具体话题的时候才加载对应的房间内容,大概200-500 Token
- L3:深度搜索层,对整个记忆宫殿做全量语义检索
安装:
bash
pip install mempalace
mempalace init ~/projects/myapp
mempalace mine ~/projects/myappCognee
官网,Memory开源(GitHub,17.9K Star,1.9K Fork)框架的后期之秀,专为AI代理构建持久化记忆。能够将原始数据转化为可搜索的智能记忆层,并通过向量检索+图数据库+本体结构的组合,使数据既能进行语义相似检索,又能进行结构化推理。也提供托管云服务。
特点
- 端到端记忆架构:将向量存储、图数据库和推理管道整合为统一的记忆引擎,使AI代理能从图谱中连贯地检索知识
- 高可定制本体体系:支持基于RDF/OWL本体的知识结构定义,你可以通过自定义任务与管道来表示特定行业的实体、属性与关系。RDF和OWL是语义网领域的标准化本体语言,以特定序列化格式(如XML)描述领域的知识结构、语义关系与约束
- 多源数据互联:能够处理对话记录、文档、图片、音频等30多种数据类型,实现多模态信息的记忆构建
- 混合检索能力:提供语义相似性查询和知识图遍历查询的混合策略,可在查询时同时利用向量匹配和图结构关系
- 良好的生态集成能力:支持与广泛的LLM、嵌入模型、结构化输出框架、关系数据库、图数据库、向量数据库的集成。
多重存储架构:
- 关系存储:跟踪文档、数据块以及它们的来源与关联
- 向量存储:保存文本嵌入,用于语义相似度检索
- 图谱存储:记录实体与实体之间的关系
这使得Cognee在检索时能够同时使用向量搜索与知识图谱推理,形成更强的混合查询能力。
不足
- 对开发者要求相对较高,需要同时维护向量库、图数据库甚至本体体系
- 项目相对较新,文档、生态、工具链仍在快速成长中
- 架构复杂度高于一般Memory方案,更适合复杂业务场景
核心架构
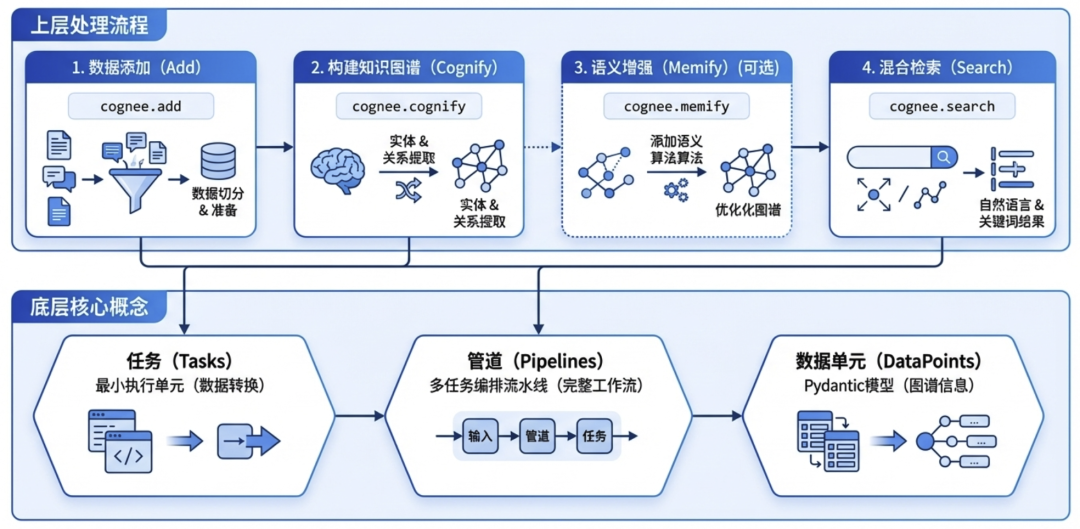
核心组件
- Tasks:最小的数据处理单元,如文本到实体/关系的解析
- Pipelines:多个Task组成工作流,如一次完整的从输入到图谱完成
- DataPoints:图谱中的一个信息实体,即Pydantic模型
上层接口
- 数据添加(Add):使用
cognee.add接口将文本、对话、文件等多种数据源导入系统,系统会自动切分文档并为后续处理做准备 - 构建知识图谱(Cognify):调用
cognee.cognify后,利用内置的抽取任务,从已添加的数据中识别实体/关系,生成知识图谱 - 语义增强(Memify):(可选)在已构建的图谱上运行
cognee.memify,可进一步利用语义算法对图谱进行丰富和优化 - 混合检索(Search):使用
cognee.search可对构建好的知识图谱发起向量相似度与图遍历等的混合查询,返回检索结果
py
import cognee
await cognee.add(
"我叫张伟,是公司的销售总监",
dataset_name="user_profile"
)
# COGNIFY构建知识图谱,触发LLM实体与关系抽取
await cognee.cognify(["user_profile"])
# 混合检索,向量+图
results = await cognee.search("公司的销售总监是谁?")Hindsight
官网,开源(GitHub,16.5K Star,944 Fork)记忆框架。
架构创新在于采用仿生记忆结构,模仿人类记忆的三个认知层次:
-
世界事实层:存储客观、不变的知识体系
技术特点:静态存储、可验证性、结构化组织
示例:编程语言特性、协议规范、数学定理
设计考量:注重准确性和一致性,为上层提供可靠的基础
-
经验层:记录代理与环境的每一次具体交互过程
技术特点:动态时序性、上下文完整性、细节丰富
示例:具体的用户对话记录、任务执行过程、结果反馈
设计考量:保留原始交互的完整信息,为抽象学习提供素材
-
心智模型层:从具体经验中抽象出的认知规律和模式
技术特点:高度抽象、可迁移性、支持推理预测
示例:用户行为模式、问题解决策略、系统性能规律
设计考量:实现真正学习过程,将具体经验升华为通用知识
分层设计的工程优势在于实现渐进式学习机制:具体经验可逐步沉淀为抽象的心智模型;不同任务可灵活访问相应层次的记忆信息;相似经验会被智能合并抽象,有效避免存储爆炸问题。
核心原理
Hindsight定义三种基础记忆操作,构成完整的学习循环系统:
-
Retain(记忆存储):将代理的每一次交互完整记录为经验条目
-
Recall(记忆检索):根据当前任务上下文智能检索相关记忆
算法特点:自动判断需要哪些层次的信息(事实/经验/心智模型)
检索策略:并行执行多维检索,确保全面性和准确性
返回格式:结构化的记忆片段,附带相关性评分和置信度
-
Reflect(反思提炼):定期分析历史经验,抽象出心智模型
触发机制:基于时间窗口或经验积累量自动执行
分析算法:模式识别、聚类分析、关联规则挖掘
更新策略:增量式更新心智模型层,保持学习连续性
采用四维并行检索策略:
- 语义检索维度:基于向量相似性的语义理解
技术实现:Transformer编码器生成语义向量
优势:理解概念相关性、处理语义多样性
适用场景:开放性问题、创意任务、复杂推理 - 关键词检索维度:基于精确匹配的关键词过滤
技术实现:倒排索引、布尔查询优化
优势:保证基础准确性、处理专业术语
适用场景:技术文档查询、代码片段搜索、精确概念定位 - 图关系检索维度:基于记忆关联网络的拓扑搜索
技术实现:图神经网络、关系推理算法
优势:发现间接关联、支持推理链条
适用场景:因果分析、决策过程追溯、复杂系统理解 - 时间范围检索维度:基于时间相关性的时序分析
技术实现:时间序列分析、近期性加权
优势:识别时序模式、处理动态变化
适用场景:趋势分析、周期规律、近期偏好识别
这四种检索策略不是简单的顺序执行,而是真正并行协同:
当前查询 → 语义编码器 → 向量检索 → 初步结果A
↓
关键词分析 → 倒排索引 → 初步结果B
↓
图关系分析 → 图遍历 → 初步结果C
↓
时间分析 → 时序索引 → 初步结果D
↓
[交叉编码器重排序] → 最终排序结果并行检索的工程优势:
- 高召回率通过多维覆盖确保;
- 准确性通过多维度相互校验提升;
- 适应性通过自动权重调整实现。
Python SDK集成示例:
py
from hindsight import HindsightWrapper
from openai import OpenAI
client = OpenAI(api_key="xxx")
# 创建Hindsight包装器
llm_with_memory = HindsightWrapper(
base_llm=client.chat.completions.create,
hindsight_config={
"storage": {
"type": "postgresql",
"url": "postgresql://user:password@localhost:5432/hindsight_db",
"pool_size": 10
},
"retrieval_config": {
"dimensions": ["semantic", "keyword", "graph", "temporal"],
"weights": {"semantic": 0.4, "keyword": 0.3, "graph": 0.2, "temporal": 0.1},
"top_k": 10
},
"learning_config": {
"reflection_interval": "6h",
"min_experiences_for_reflection": 100
}
}
)
# 后续所有LLM调用自动获得记忆能力
response = llm_with_memory(
model="gpt-4",
messages=[
{"role": "system", "content": "基于我们之前的讨论历史,继续分析这个技术问题..."},
{"role": "user", "content": "如何优化Hindsight在资源受限环境下的性能表现?"}
]
)
# 创建团队共享记忆池
team_memory = hindsight.create_shared_context(
name="engineering-team-memory",
description="软件工程团队的集体学习记忆",
agents=[
{"id": "code-reviewer", "role": "代码质量审核"},
{"id": "debug-assistant", "role": "问题调试助手"},
{"id": "design-consultant", "role": "架构设计咨询"}
],
access_policy={
"read": "all_agents",
"write": "all_agents",
"admin": ["team-lead-agent"]
}
)
# 各代理共享同一套学习成果
code_reviewer.recall = team_memory.create_recall_session(agent_id="code-reviewer")
debug_assistant.mental_models = team_memory.get_mental_models(category="debugging")
design_consultant.reflect = team_memory.create_reflect_session(priority="high")memories.ai
官网,功能:提供Video Chat、Clip Search、Video-to-Text、Video Creator、Video Marketer、AI Hardware等多种Agent,支持企业与个人对接自定义场景。
企业级场景:
- 实时威胁检测、人员轨迹跟踪与跌倒检测(安全监控)
- 智能剪辑、创意脚本与营销洞察(媒体与营销)
- 运动赛事分析、球员技术统计(体育)
Large Visual Memory Model,灵感来源于人脑记忆的提示---检索---筛选---监控---重构流程,共分五大模块:
- Query Model:将用户问题或场景线索编码为检索请求
- Retrieval Model:在海量索引中进行粗粒度检索,激活相关视频片段
- Full‑Modal Indexing & Selection:对候选片段做多模态打标,并精筛最关联内容
- Reflection Model:校验召回结果的一致性与准确性,冲突时触发重检
- Reconstruction Model:将碎片化记忆整合补全,生成人类式连贯输出
测评
- 在多项视频分类(K400/K600/K700、UCF101、HMDB)、检索(MSRVTT、MSVD、ActivityNet)和问答(MVBench、NextQA、Temp Compass)基准中刷新SOTA,相比OpenAI、Google等模型呈现大幅领先
- Memories.ai在无限视频上下文能力上远超Gemini或ChatGPT,仅受限于计算资源而非模型架构本身