LongCat-Video-Avatar 1.5 由美团 LongCat 团队于 2026 年 5 月推出,是一款全新的开源音频驱动视频生成(AI2V)框架。**用户仅需提供一张静态参考图和一段音频,即可生成口型精准同步的动态化身视频。**该模型采用 Whisper 驱动的语音特征提取;步数蒸馏技术将 DiT 生成过程压缩至极速的 8 步,不仅保证高保真画面,还能生成长视频内容。其全领域泛化能力覆盖真实人像、2D/3D 动漫角色及动物化身,为多场景视频生成提供高效、可靠的解决方案。
目前,HyperAI超神经官网已上线了「LongCat-Video-Avatar 1.5 数字人模型」,快来试试吧~
在线使用:LongCat-Video-Avatar 1.5 Digital Human Model | Notebooks | HyperAI
欢迎登录官网查看更多内容:
6 月 06 日- 6 月 12 日,hyper.ai 官网更新速览:
* 优质公共数据集:6 个
* 优质教程精选:3 个
* 社区文章解读:3 篇
* 热门百科词条:5 条
* 7 月截稿顶会:5 个
访问官网:hyper.ai
公共数据集精选
1. ChartNet 图表理解多模态数据集
ChartNet 是由 MIT 联合 IBM Research 等机构于 2026 年发布的大规模高质量多模态数据集,旨在解决现有模型在几何视觉模式、结构化数值与文本描述联合推理上的不足。该数据集包含 420 万合成图表样本、 94,643 人工验证的图表样本和 3 万真实世界图表,覆盖 24 种图表类型与 6 种绘图库。
在线使用:ChartNet Chart Understanding Multimodal Dataset | Datasets | HyperAI
2. OpenSAL360 全景视频显著性数据集
OpenSAL360 是目前最大规模的全方位视频显著性数据集,旨在支持视觉注意力、显著性预测以及多模态视频分析的研究。该数据集包含 500 段来自 YouTube 的多样化全景视频,平均时长 18.1 秒,由超过 2,000 名观察者完成数据标注。
在线使用: OpenSAL360 Panoramic Video Saliency Dataset | Datasets | HyperAI
3. Movie Feelings 电影情感特征数据集
Movie Feelings 是一个电影情感特征数据集,旨在系统刻画电影所引发的细粒度情绪(feelings)特征,突破传统仅基于正负面情感或基础情绪分类的局限。该数据集包含 1,500 部具有代表性且具有文化影响力的电影,时间跨度为 1920 年至 2024 年,覆盖 50 种情感状态。
在线使用:Movie Feelings Dataset | Datasets | HyperAI
4. FigureBench 科学插图生成基准数据集
FigureBench 是由西湖大学文本智能实验室于 2026 年发布的科学插图生成基准数据集,旨在解决从长篇幅科学文本中自动生成高质量科学插图的任务,为自动科学插图生成研究提供了具有挑战性且多样化的测试平台。
在线使用:FigureBench Scientific Illustration Generation Benchmark Dataset | Datasets | HyperAI
5. AI Student Impact AI 辅助学习影响数据集
AI Student Impact Dataset 是涵盖多维度变量的大规模教育行为数据集,旨在系统分析生成式 AI 工具在高校学习场景中的真实影响。该数据集包含 50,000 名学生样本,共 16 个结构化特征字段,覆盖学生的学术背景、 AI 使用行为、学习行为、机构背景、心理健康状态、应用场景等数据。
在线使用:AI Student Impact: The Impact of AI-assisted Learning on Datasets | Datasets | HyperAI
6. Noisy Medical Document 含噪医疗文档图像数据集
Noisy Medical Document 是一个面向 OCR 与医疗文档理解任务的噪声增强医疗文档图像数据集,旨在模拟真实医疗场景中扫描文档所面临的复杂噪声干扰问题,提升 OCR 模型与文档理解模型在真实环境下的鲁棒性与泛化能力。该数据集包含 1,000 张高保真合成医疗文档图像,其中医院账单 500 张、出院小结 500 张。
在线使用:Noisy Medical Document Image Dataset | Datasets | HyperAI
公共教程精选
1. LongCat-Video-Avatar 1.5 数字人模型
LongCat-Video-Avatar 1.5 由美团团队于 2026 年 5 月发布的,是一款全新升级的开源音频驱动视频生成(AI2V)框架。仅需一张静态参考图和一段驱动音频,即可生成高度逼真、口型完美同步的动态化身视频,且能够轻松应对复杂的真实世界场景以及动漫、动物等风格化领域。
在线运行:LongCat-Video-Avatar 1.5 Digital Human Model | Notebooks | HyperAI
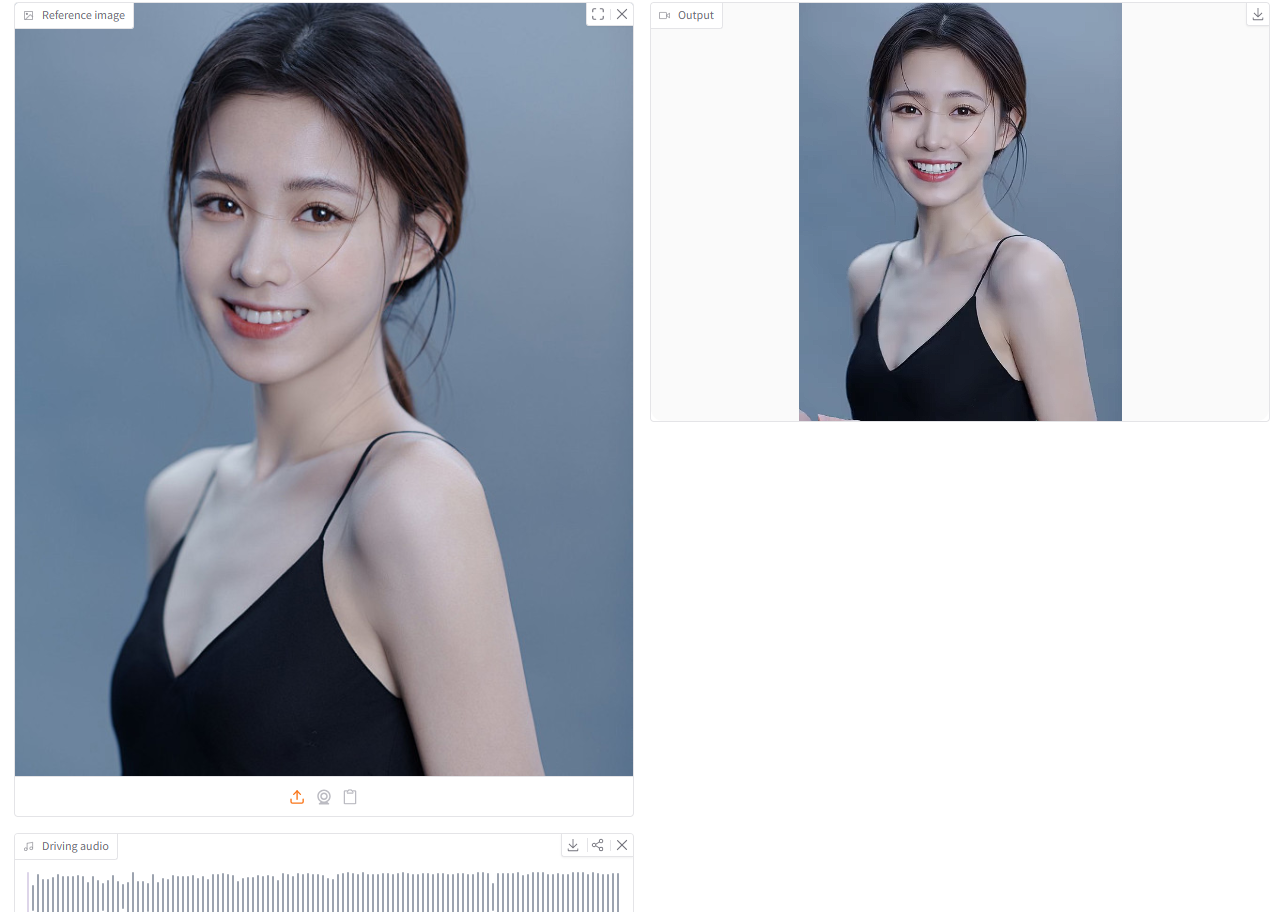
Demo 页面
2. dots.tts:全连续自回归文本转语音系统
dots.tts 由 rednote-hilab 于 2026 年 6 月发布,是一个 2B 参数的全连续、端到端自回归文本转语音系统。它的主干结构由语义编码器、LLM 和自回归 flow-matching 声学头组成,基于 48 kHz AudioVAE 直接建模连续音频表示,不使用离散语音 token。
在线运行:Dots.TTS: A Fully Continuous Autoregressive Text-to-Speech System | Notebooks | HyperAI
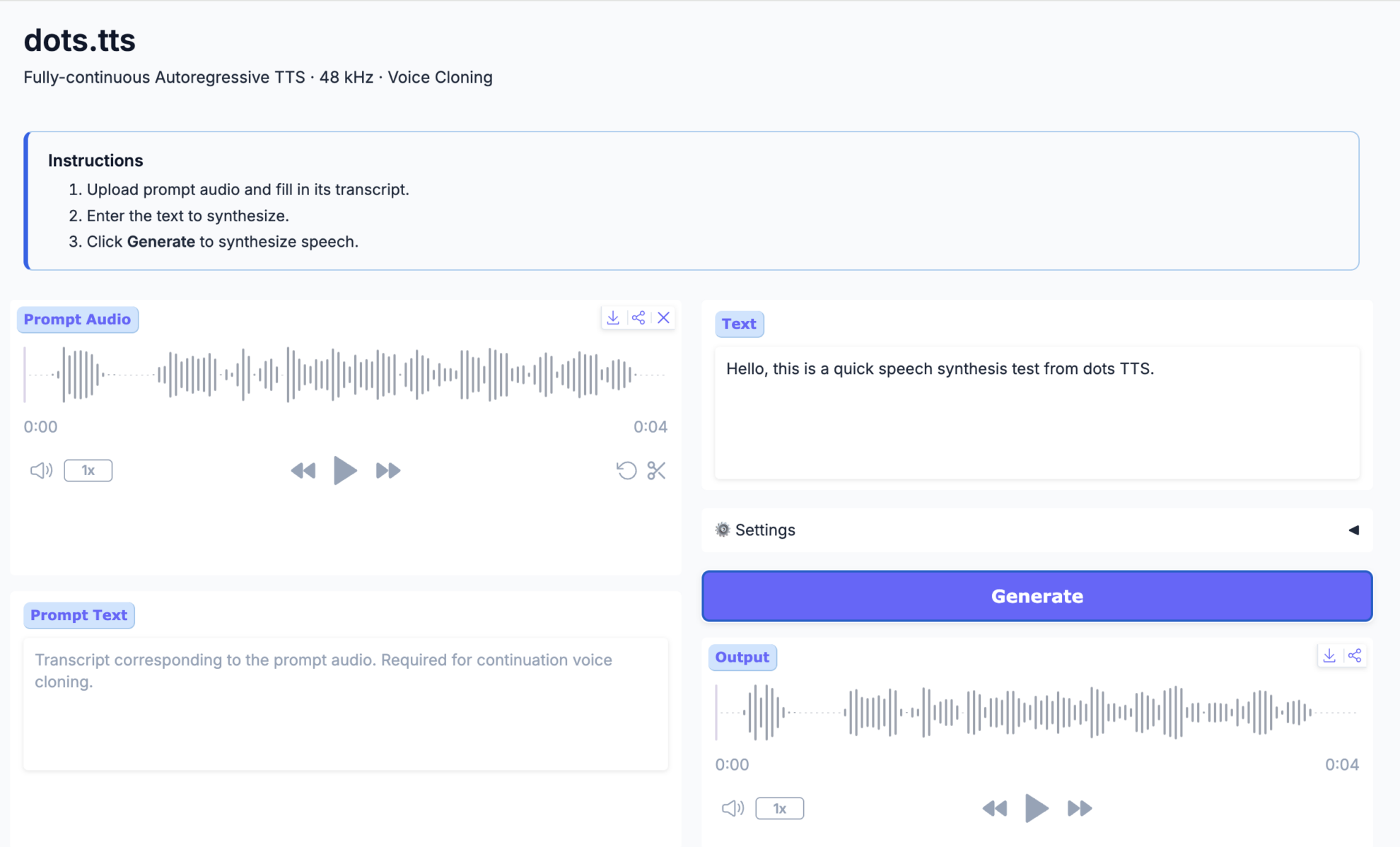
Demo 页面
3. Gemma4 12B-it:图文音统一多模态模型
Gemma 4 12B-it 是 Google DeepMind 发布的 Gemma 4 系列统一多模态模型,采用 encoder-free 架构,将图像和音频直接投影到 LLM 的嵌入空间中,无需独立的编码器即可处理文本、图像和音频三种模态,在 12B 参数量级实现了强大的推理、编码和多模态理解能力。
在线运行:Gemma4 12B-IT: A Unified Multimodal Model for Text, Image, and Audio | Notebooks | HyperAI
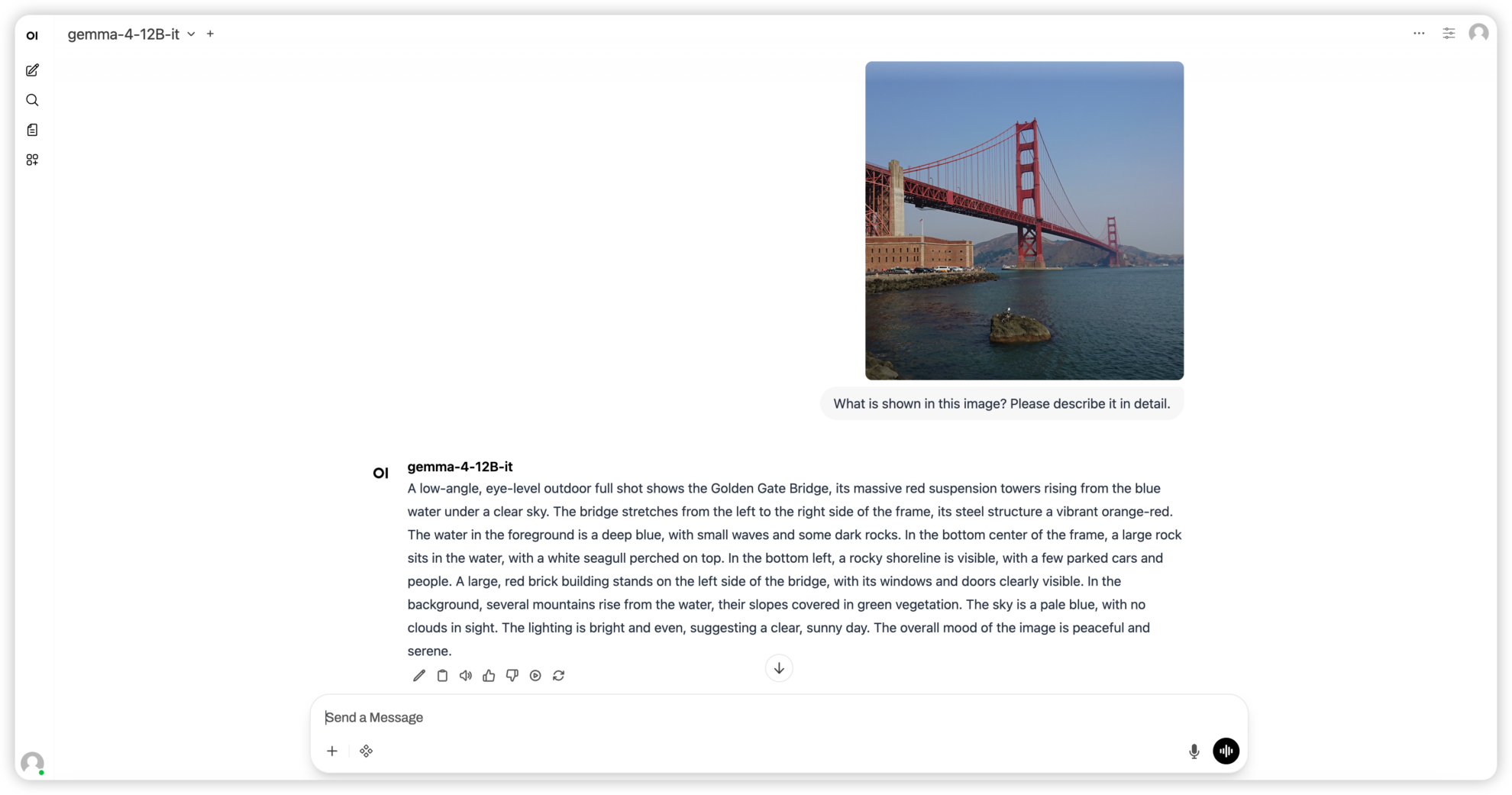
Demo 页面
社区文章解读
1. 基于220种海洋细菌,科学家用基因组尺度模型重构异养微生物分类体系,挖出8类代谢菌群
南加利福尼亚大学牵头的团队依托全球海洋微生物数据库,借助基因组尺度代谢模型解析海量海洋细菌基因组,通过定量微生物对 11 类有机底物的利用敏感性,划分出 8 类差异化代谢菌群。
2. 深度估计准确率冲上0.9,Meta提出VLM³,论证视觉模型天生会学3D,以Qwen3-VL-4B为基础实现多任务的统一建模
Meta 与普林斯顿大学联合提出了 VLM³,以标准视觉语言模型为基础,通过统一的数据组织方式和训练范式,实现了物体级三维理解、公制深度估计、像素匹配以及相机位姿求解四类任务的统一建模,并系统评估了标准 VLM 在细粒度三维感知中的能力边界。
3. 剑桥大学等提出面向对地观测任务的像素级基础模型,在多项任务中精度达SOTA
剑桥大学、阿尔托大学、布里斯托大学的联合研究团队基于巴洛双子算法构建了一种新的时序特征学习范式,能够让模型自主学习地表稳定的时空变化规律,形成具有时序采样不变性的遥感特征表示。在此基础上,研究团队进一步提出了面向哨兵一号/哨兵二号多模态时序数据的像素级遥感基础模型 TESSERA。
热门百科词条精选
1. 世界动作模型 WAM
2. 可解释人工智能 XAI
3. 视觉语言动作模型 VLA
4. 基于规则的系统 Rule-Based System
5. 倒数排序融合 Reciprocal Rank Fusion
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
7 月截稿顶会
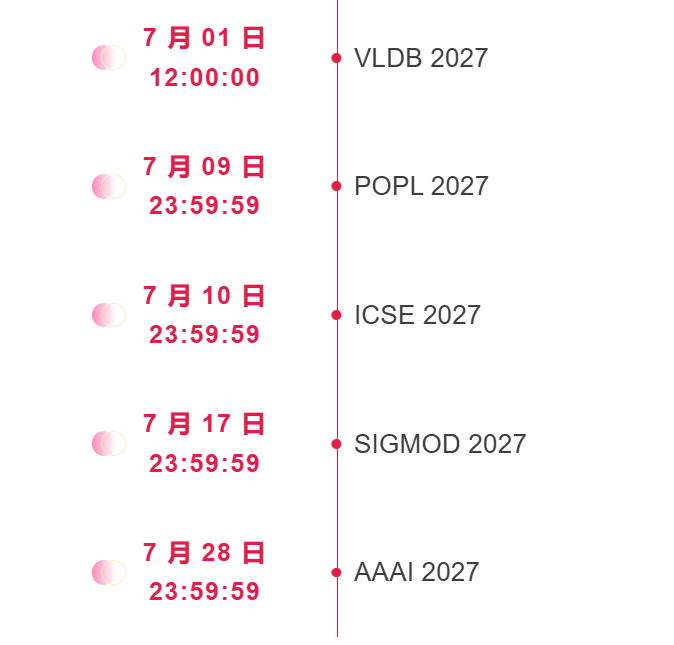
* 截稿时间为 AoE 时间
一站式追踪人工智能学术顶会:Events | HyperAI
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
关于 HyperAI超神经 (hyper.ai)
**HyperAI超神经 (hyper.ai) 是国内领先的人工智能及高性能计算社区,**致力于成为国内数据科学领域的基础设施,为国内开发者提供丰富、优质的公共资源,截至目前已经:
* 为 2100+ 公开数据集提供国内加速下载节点
* 收录 700+ 经典及流行在线教程
* 解读 300+ AI4Science 论文案例
* 支持 700+ 相关词条查询
* 托管国内首个完整的 Apache TVM 中文文档
访问官网开启学习之旅: