你好,我是程序员无隅
🌈 这是我的个人主页: 无隅的主页
🌟 "技术永无止境,希望我的内容能帮到你"
🔥 热门专栏: Java 面试八股文 | LeetCode 算法笔记 | Claude Code 源码解读
本文围绕一个问题展开:如何通过构建领域知识工程体系,让 Code Agent 在复杂业务项目中真正可用。 这件事不只是"给 AI 多喂一点文档",而是要回答三个更实际的问题:什么是 Skill,Skill 应该怎么设计,以及如何防止 Skill 自己也变成过时文档。
一、两个痛点,一个方向
1. 重构中的知识断层
在复杂业务项目里,最难的往往不是代码本身,而是代码背后的前因后果。不是语法看不懂,也不是框架不会用,而是反复遇到一些无法从代码表面回答的问题:
-
遇到不知前因后果的业务逻辑------为什么有这个分支?这个字段为什么这样处理?
-
查阅文档,要么没有,要么过时对不上
-
最终只能去找之前负责的同学,人不在,知识就断了
这种痛苦贯穿了重构项目的梳理、设计和开发全阶段。它暴露的不是单点文档缺失,而是一个更底层的问题:业务知识没有被系统化记录和管理。
2. AI Coding 在复杂项目中撞墙
Code Agent 很擅长处理局部技术问题。修一个小 Bug、补一个接口参数、改一段简单逻辑,效果通常不错。但在复杂业务项目里,只靠 Agent 自己检索代码,很容易撞墙,原因主要有三个:
-
历史逻辑噪声污染:多年迭代留下的废弃逻辑、兼容逻辑、兜底逻辑散落在流程里,干扰 Agent 判断主链路。
-
多线业务耦合:多条产品线共用同一套架构,改一处可能影响另一条线。
-
代码量大但热代码少:仓库很大,真正日常变动的核心代码只占一小部分,剩下大量代码会变成检索噪声。
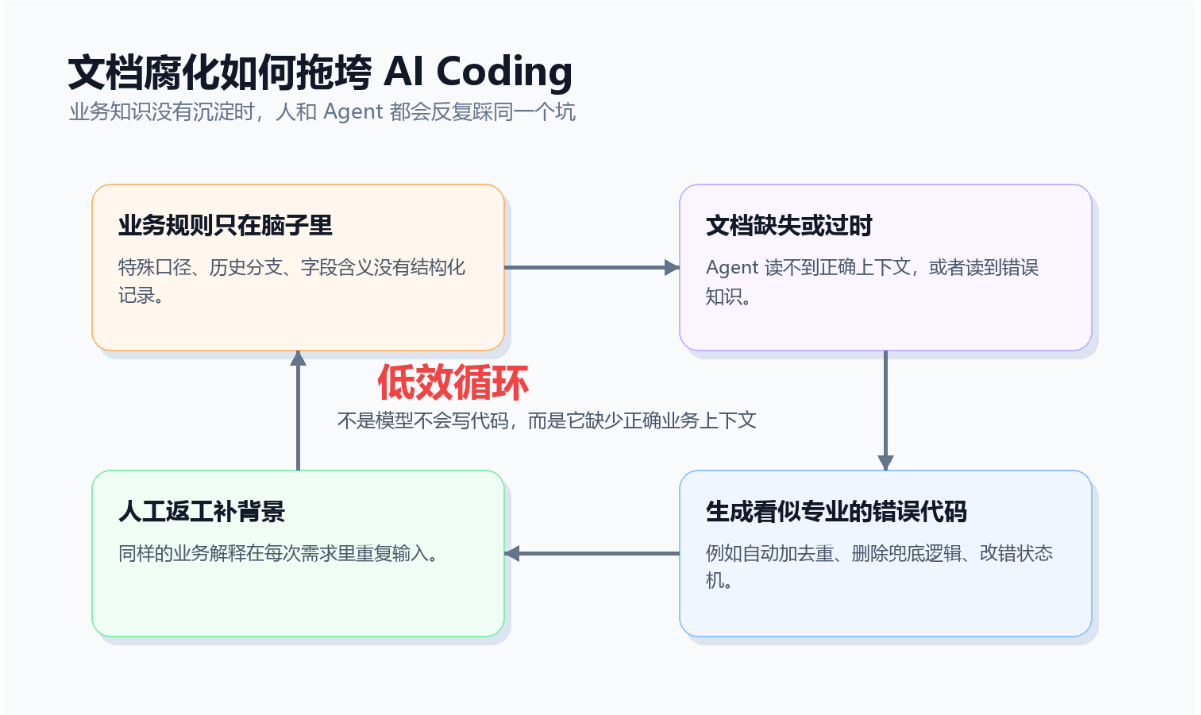
于是 AI Coding 很容易退化成一个低效循环:
手动告诉 Agent 文件位置 -> 补充业务背景 -> 生成代码 -> 发现不对 -> 继续补充背景。
3. 两条线索的汇聚
重构中的知识断层,和 AI Coding 中的上下文缺失,本质上是同一个问题:团队的领域知识没有被结构化管理。 人读不到,Agent 也读不到。
所以方向也很明确:不是让 Agent 盲目多读文档,而是把核心业务知识整理成 Agent 能稳定使用的知识体系。
二、知识体系的设计
1. 从 MCP 到 Skill:方案的演进
最直接的想法是接 MCP,让 Code Agent 连接内部文档系统,实时读取已有业务文档。这个思路有价值,但问题也很明显。
第一,MCP 只能解决"读不读得到",解决不了"文档是不是对的"。 如果文档已经过时,Agent 读到的就是过时知识。
第二,内部文档通常内容很大,而且结构松散。 一次需求可能关联十几份文档,如果都塞进上下文,Token 会爆,注意力也会被稀释。
所以 MCP 更像是知识入口。复杂项目真正需要的是:把领域知识整理成 Code Agent 可路由、可读取、可执行的结构。 这就是 Skill 的位置。
2. Skill 的结构
Skill 可以理解为给 Code Agent 看的领域专家手册。它不是把业务文档换个名字再放一遍,而是把业务知识、代码流程、修改边界和验证方式整理成模型能使用的规范。
一个 Skill 通常遵循渐进式披露:
1)元数据
始终可见,用来做路由判断,例如这个需求是不是应该读取"商品浏览统计"这个 Skill。
2)主文件正文
Skill 被触发时加载,覆盖模块核心知识:业务背景、核心概念、业务规则、代码入口、主流程和修改检查清单。
3)引用资源
只有模型判断需要时才继续读取。更详细的接口定义、字段历史、流程细节,都可以放到引用文件里。
这个设计的价值在于:每次只加载当前需求真正需要的知识,而不是把所有文档一股脑塞进 Prompt。
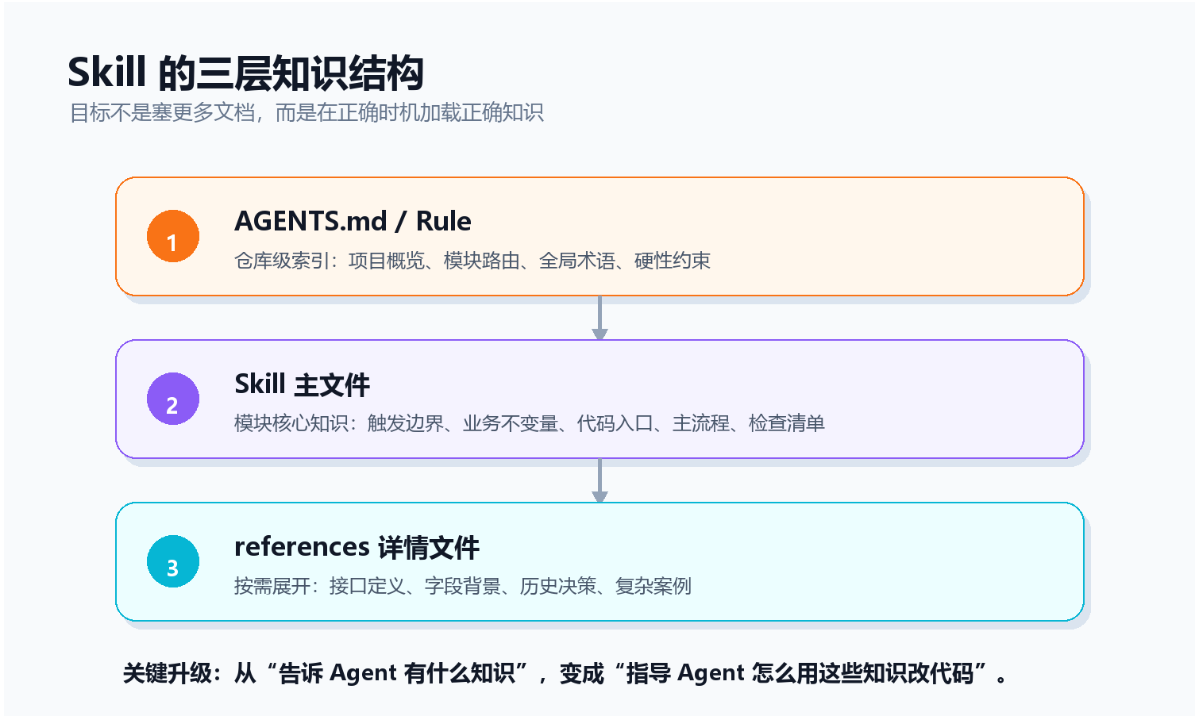
3. 三层知识架构
一套比较清晰的项目知识体系,可以分成三层,对应 Code Agent 的认知路径:先全局定位,再理解模块,最后按需展开细节。
第一层:AGENTS.md + Rule
这一层负责全局索引和硬约束。Agent 拿到需求后,先通过它判断应该读哪个模块的知识,通常包含:
-
项目概览和架构分层
-
全局术语表
-
通用开发规范
-
当前仓库的硬性约束
第二层:Skill 主文件
这一层是模块核心知识。每个业务模块可以对应一个 Skill。Agent 读完主文件后,应该能知道这个模块解决什么问题、主流程在哪里、哪些规则不能破坏。
主文件重点不是写长,而是写准。它应该告诉 Agent:
-
什么需求该读这个 Skill
-
这个模块有哪些业务不变量
-
对应哪些代码入口和核心函数
-
修改时要检查哪些影响面
第三层:引用详情文件
这一层负责按需展开。比如 API 定义、数据模型、历史决策、复杂状态机,不一定每次都要读,但需要时必须能找到。
4. 从知识补充到知识工程
最开始写 Skill,很容易只写业务规则:
-
这个模块做什么
-
这个字段是什么意思
-
这个流程有哪些注意事项
但这样还不够,因为 Agent 仍然要自己猜:这条业务规则到底对应哪段代码?
所以真正关键的升级是:
从"告诉模型有什么知识",升级为"指导模型怎么用这些知识改代码"。
也就是说,Skill 里不能只有业务解释,还要有代码映射。例如:
业务规则 -> 对应流程 -> 代码入口 -> 核心函数 -> 修改检查项这样 Agent 不需要猜测业务规则和代码之间的关系,而是直接拿到映射。这才是从"知识补充"走向"知识工程"。
三、知识会腐化:比没有知识更危险
知识体系最大的风险不是建设成本,而是腐化。
过时的知识比没有知识更危险,因为 Code Agent 会带着错误的确定性去执行。当 Skill 文件说业务流程是:
A -> B -> C而实际代码已经变成:
A -> CAgent 不一定会怀疑 Skill 的正确性,它可能会按照旧流程继续写代码。一旦这种错误模式被引入,影响会被快速放大。
在持续迭代的项目里,代码变更频率通常远高于文档更新频率。所以 Skill 不是写完就结束,必须要有防腐机制。
1. 反向校验:让 Agent 在使用知识时自己发现问题
这是最自然的一层。Agent 为了实现需求,本来就会读两类东西:Skill 里的业务知识,以及仓库里的实际代码。既然两边都要读,就可以顺带做交叉比对。
如果发现 Skill 描述和代码现状不一致,Agent 不应该直接继续改,而应该生成校验报告:
知识指导 Code Agent -> Agent 读实际代码 -> 发现不一致 -> 生成修正建议 -> 人确认 -> 更新知识这个环节几乎没有额外成本。它解决的是存量腐化问题:那些以前没被发现的知识偏差,会在每次真实使用中逐步暴露。
2. 沟通补充:让知识在开发过程中自然生长
知识腐化是一类问题,知识缺失是另一类问题。很多业务背景,只有在具体需求讨论时才会暴露出来。
传统做法是开发完之后再补文档,但实际情况是,这一步几乎不会发生。更好的方式是:在开发沟通结束后,让 Agent 总结本次对话新增的业务知识,生成 Skill 更新建议。
流程可以很简单:
知识缺失 -> 人与 Agent 沟通补充 -> Agent 总结新增知识 -> 人 Review -> 更新 Skill这一步的重点不是"让 AI 自动写文档",而是把知识沉淀嵌入开发过程本身,让它成为沟通的自然副产品。
3. Commit 前校验:堵住增量腐化入口
前两层偏使用时发现,Commit 前校验则是主动防线。代码提交前,系统分析本次 diff 是否命中知识更新规则。如果改动涉及接口定义、数据模型、核心业务分支、状态流转、下游口径,就触发 Skill 检查。
输出应该尽量结构化:
命中模块:哪个 Skill
变更类型:接口 / 字段 / 状态 / 流程
影响范围:哪些业务规则需要同步
建议更新:Skill 中哪一段应该修改这一步的价值在于:代码改了,知识检查也在同一个工作流里发生。 不要等"下次有空再补文档",大多数时候,没有下次。
4. 基线全量巡检:最后的兜底防线
即使有了前面三层,也还是会漏。所以需要低频但全面的基线巡检。每次合并到主干或完成基线发布后,可以通过 CI/CD 增加一个知识健康检查节点:
-
扫描 Skill 中记录的代码锚点是否还存在
-
比对接口定义和实际路由是否一致
-
比对数据模型描述和真实表结构是否一致
-
统计哪些核心代码没有 Skill 覆盖
-
找出长期未更新但代码频繁变化的模块
CI/CD 本质上就是把检查节点自动化。这里不是要造一个复杂平台,而是在已有研发流程里多加一道知识一致性检查。
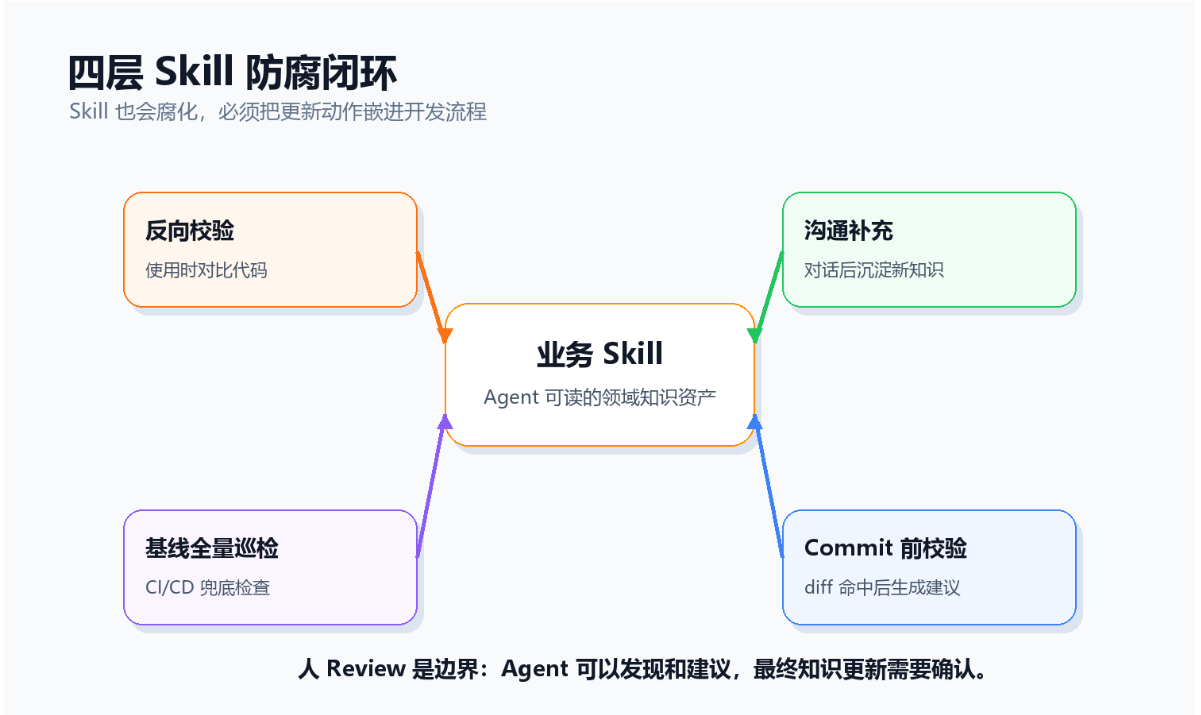
四层机制的分工可以这样理解:反向校验 解决存量知识腐化,沟通补充 解决新知识没有沉淀,Commit 前校验 解决增量代码导致知识过时,基线全量巡检解决遗漏长期积累。
四、为什么不是单纯写 Spec?
SDD,也就是 Spec-Driven Development,强调先写规范,再让 AI 根据规范实现。这个思路有价值,尤其是从 0 到 1 的新项目,Spec 可以从头规划,和代码天然同步。
但在持续迭代的复杂业务项目里,问题会变得很现实:团队日常需求大部分都是中小型改动,一个两三百行的代码修改,可能要维护五六百行的 Spec。需求越碎,Spec 越容易从"开发辅助"变成"额外负担"。
更深层的问题是,很多业务知识不是一次性需求知识,而是长期有效的领域知识。例如状态机约束、数据口径、下游依赖、历史兼容逻辑。它们不应该随着一次需求用完就丢,而应该沉淀到可复用的 Skill 里。
所以这里的选择不是"要不要文档",而是:不为每个需求维护一份一次性 Spec,而是维护一套持续演进的领域知识体系。 前者随用随弃,后者越用越厚。对于长期迭代的复杂业务项目,领域知识的复利价值更高。
五、如果自己要落地,先从一个模块开始
不要一上来全项目铺开。先选一个高频变更、业务规则明确、出错成本较高的模块,从最小可用 Skill 开始。
第一步,写清楚六件事:
-
触发边界
-
业务不变量
-
核心代码入口
-
主流程链路
-
修改检查清单
-
验证方式
第二步,用真实需求验证。不要用 Demo 验证,直接拿最近要改的需求,让 Agent 先读 Skill,再读代码,再输出方案。重点观察三件事:
-
Agent 是否读到了正确模块
-
Agent 是否避开了不该改的业务规则
-
Agent 是否能指出 Skill 和代码不一致的地方
第三步,再补防腐流程。一开始不需要四层都做满,优先做两个最划算的:反向校验 和 Commit 前校验。前者能逐步修复旧知识偏差,后者能挡住新增腐化。
六、面试里怎么表达这件事?
如果只说"我会用 Code Agent 写代码",区分度不高。但如果能说清楚 Skill 背后的知识工程思路,就更接近 Agent 应用开发。
1. 如果面试官问:复杂业务项目里,怎么降低 Code Agent 误改?
我会先把核心业务知识从普通文档升级成 Agent 可读的 Skill。这里的重点不是"多写一份文档",而是把触发边界、业务不变量、核心代码入口、主流程链路、修改检查清单和验证方式都结构化下来。
这样 Agent 在修改相关模块前,不是直接盲目检索代码,而是先读取对应 Skill,再结合真实代码生成方案。如果它发现 Skill 描述和代码现状不一致,就需要输出校验报告,由人确认后再更新 Skill 或调整代码。
2. 如果面试官追问:为什么不用 MCP 直接读文档?
MCP 解决的是访问入口问题,它能让 Agent 读到内部文档,但不能保证文档本身是正确的。如果文档已经过时,Agent 通过 MCP 读到的还是过时知识。
另外,内部文档通常内容很大,而且组织比较松散。让 Agent 每次把大量文档都塞进上下文,容易带来 Token 消耗和注意力分散。Skill 更强调把核心知识压缩成可路由、可加载、可执行的结构,并和代码入口、业务不变量、验证方式绑定起来。
3. 如果面试官继续问:Skill 自己会不会也腐化?
会,所以重点不是"写一个 Skill 文件",而是建立防腐机制。
我的理解是至少要有三层:第一层是在 Agent 使用 Skill 时做反向校验,发现知识和代码不一致就生成修正建议;第二层是在 Commit 前根据 diff 检查是否影响知识体系,避免代码变了但 Skill 没变;第三层是在 CI/CD 里做低频全量巡检,扫描代码锚点、接口定义、数据模型和 Skill 描述是否一致。
最后仍然需要 Human Review。Agent 可以发现问题、生成建议,但业务知识是否应该更新,最终要由人确认。
这套回答的关键词可以收束成一句话:Skill 负责把业务知识结构化,防腐机制负责让知识和代码一起演进。
七、总结
面向 Skill 编程解决的不是"让 Agent 多读一点资料",它真正解决的是:如何把业务知识变成可维护、可校验、可演进的工程资产。
普通文档会腐化,Skill 也会腐化。区别在于,Skill 可以被纳入开发流程:使用时反向校验,沟通后补充知识,Commit 前检查 diff,发布后做全量巡检。
这样,知识不再只靠人想起来才维护,而是和代码变更绑定在一起。这才是它对复杂业务项目最有价值的地方。
参考阅读:
-
阿里妈妈效果创意中心团队:《面向Skills编程:用领域知识工程驱动 Code Agent》