作者:昇腾实战派 * silas
作者 :昇腾实战派
知识地图 :https://blog.csdn.net/Lumos_Lovegood/article/details/161455142
背景概述
说到分布式训练框架,Megatron-LM、FSDP 和 DeepSpeed 是绕不开的三个名字。本系列聚焦 PyTorch 原生的 FSDP(FullyShardedDataParallel),结合源码梳理其核心机制,并在关键节点与 DeepSpeed ZeRO-3 进行对照,帮助读者在两套实现之间建立清晰的认知映射。
0. 引言
与 DeepSpeed 的分析思路一致,显存和通信是理解 FSDP 精髓的两条主线。第一篇先把"静态"的显存分配搞清楚:在训练开始之前,各类张量究竟存在哪里、占多少、从哪来。
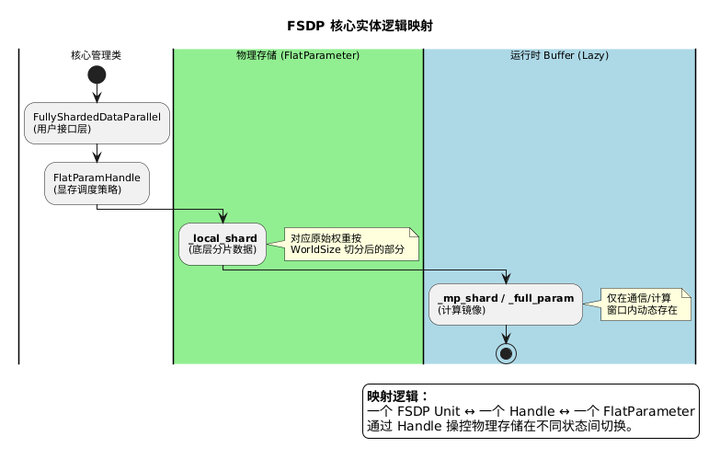
从源码实现上看,FSDP 的核心逻辑由以下三个紧密耦合的实体构成:
- FullyShardedDataParallel (接口层):
- 位于 fully_sharded_data_parallel.py。
- 职责:负责模块递归包装(Wrap)、前向/反向计算流程的编排、以及对外的 API 接口。
- FlatParamHandle (调度层):
- 位于 flat_param.py。
- 职责:FSDP 的"大脑"。负责管理参数的扁平化、分片策略、显存状态切换(Alloc/Free)以及通信原语的触发。
- FlatParameter (存储层):
- 位于 flat_param.py。
- 职责:FSDP 的"心脏"。继承自 nn.Parameter,是真正持有 _local_shard、_full_param 等物理张量的容器,也是显存操作的最终落脚点。
初始化阶段涉及以下几类核心张量,它们共同构成了 FSDP 的静态显存格局:
| 张量类型 | 字段名 | 精度 | 存放位置 | 初始化来源 |
|---|---|---|---|---|
| 参数常驻分片 | flat_param._local_shard | FP32(actor)/ BF16(ref) | GPU / CPU(pinned) | init_flat_param_attributes |
| 低精度分片(混合精度) | flat_param._mp_shard | BF16/FP16 | GPU | init_flat_param_attributes,从 _local_shard cast |
| 完整参数缓冲区 | flat_param._full_param_padded | BF16/FP16 | GPU | init_flat_param_attributes,AllGather 目标 buffer |
| 高精度完整参数缓冲区 | flat_param._full_prec_full_param_padded | FP32 | GPU | init_flat_param_attributes,混合精度专属 |
| 梯度分片 | flat_param._saved_grad_shard | BF16/FP32 | GPU / CPU | 反向传播阶段动态创建 |
1. FSDP 为什么必须引入 FlatParameter
一个容易被忽视的前置问题:FSDP 为什么不能直接复用 PyTorch 的 nn.Parameter,而必须引入 FlatParameter 这一新的抽象?
这不是工程偏好,而是由显存调度粒度、生命周期控制能力以及通信效率共同决定的。
原生 nn.Parameter 的结构性限制:
在 DDP 等单机多卡场景中,nn.Parameter 的特性是优势------每个参数独立、自治,生命周期由 Python 对象和 Autograd 图隐式管理。但在 FSDP 场景下,这些特性直接演化为瓶颈:
- 分配粒度过细:FSDP 需要参数在分片态、完整态、不同精度态之间频繁切换。如果以单个 Parameter 为调度单位,每次 AllGather 就要处理成百上千个小 Tensor,CUDA allocator 压力陡增,显存碎片严重。
- 生命周期不可控:FSDP 的核心原则是「完整参数只在前向/反向的必要窗口内存在」。但原生 Parameter 与模块绑定、与 Autograd 图隐式耦合,一旦被 materialize 成完整形态,往往会在显存中滞留超出计算所需的时间窗口。
- 无法描述「逻辑参数 ≠ 物理存储」的关系:FSDP 内部,一个逻辑参数可能被打平、被 padding、被切片、被重建为 view。nn.Parameter 默认假设一块连续显存对应一个逻辑参数,不具备这种结构化描述能力。
FlatParameter 的核心设计:
FlatParameter 的核心思想可以用一句话概括:把「多个逻辑参数」统一收敛为「一个可调度的显存容器」。
python
# torch/distributed/fsdp/flat_param.py
class FlatParameter(nn.Parameter):
# 四个核心运行时张量,按需 lazy 创建
_local_shard: Tensor # 常驻分片,训练全程不释放
_full_param_padded: Tensor # AllGather 目标 buffer,用完立即释放
_mp_shard: Tensor # 低精度分片,混合精度时的计算载体
_saved_grad_shard: Tensor # 梯度分片,optimizer step 后释放这一改变带来了三个决定性优势:显存分配从「参数级」升级为「组级」(CUDA alloc 次数从 O(num_params) 降为 O(num_flat_params));参数形态切换从逐个操作变为整体操作;零拷贝视图重建成为可能(原始参数在计算阶段只是 flat buffer 上的 view,无需 copy)。
💡 一句话总结:FlatParameter 是 FSDP 一切显存优化的物理基础。它把「参数是什么」(逻辑语义)和「参数存在哪」(物理存储)彻底解耦,前者由元数据描述,后者由 flat_param.data 指针在不同 buffer 之间灵活切换。
2. FSDP Unit 的划分------wrap 策略如何决定 FlatParameter 的边界
在深入 FlatParameter 的构建细节之前,有一个更前置的问题必须先回答:哪些参数会被打平到同一个 FlatParameter 里?
答案由 wrap 策略决定。FSDP 的分片粒度不是逐参数的,而是以 FSDP Unit 为单位------每个被 wrap 成独立 FSDP 实例的子模块,对应一个独立的 FlatParamHandle,其内部所有参数打成一个 FlatParameter。
2.1 wrap 策略的三层结构
VeRL 中的 wrap 策略支持三种子策略的 _or_policy 组合:LoRA lambda policy(叶子模块 + weight.requires_grad)、size_based_auto_wrap_policy(参数量超过阈值)、transformer_auto_wrap_policy(类名匹配 _no_split_modules)。满足任一条件即触发 wrap。
默认情况下(无 LoRA、无 size policy),走 transformer_auto_wrap_policy,以模型自带的 _no_split_modules(如 Qwen2DecoderLayer)作为 wrap 粒度。
2.2 _recursive_wrap:自底向上的 DFS
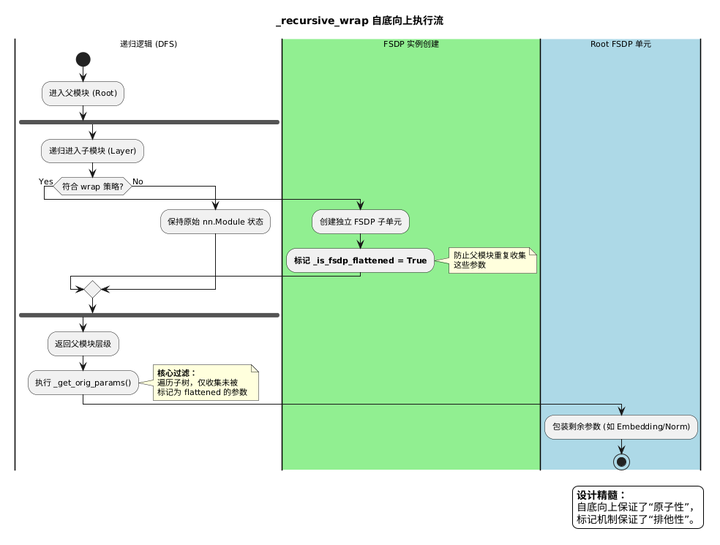
FSDP.init 调用 _auto_wrap(only_wrap_children=True,root 模块由外层 init 自己处理),内部通过 _recursive_wrap 完成自底向上的递归包装。判断逻辑分两个阶段:
python
# torch/distributed/fsdp/wrap.py _recursive_wrap(核心逻辑)
# 阶段 1:recurse=True,是否继续向下递归?transformer policy 永远返回 True
if auto_wrap_policy(module=module, recurse=True, ...):
for name, child in module.named_children():
_, num_wrapped = _recursive_wrap(child, ...)
total_wrapped_numel += num_wrapped
# 阶段 2:recurse=False,当前模块是否 wrap?
# transformer policy:只看 isinstance(module, transformer_layer_cls)
remainder = nonwrapped_numel - total_wrapped_numel # 扣掉子模块已 wrap 的量
if auto_wrap_policy(module=module, recurse=False, nonwrapped_numel=remainder):
return _wrap(module, wrapper_cls, **kwargs), nonwrapped_numelremainder 的设计是 size_based_auto_wrap_policy 的核心:子模块被 wrap 走后,父模块剩余参数量可能低于 min_num_params 阈值,从而不再被 wrap。对 transformer_auto_wrap_policy 来说 remainder 不参与判断,但这一机制值得理解。
2.3 _get_orig_params:flat 边界的最终裁定者
wrap 决定了哪些模块成为独立的 FSDP Unit,flat 边界由 _get_orig_params 最终裁定。每个 FSDP Unit 初始化时,_init_param_handle_from_module 调用它收集「属于自己的参数」:
py
# torch/distributed/fsdp/_init_utils.py
def _get_orig_params(module, ignored_params):
for param in module.parameters(): # recurse=True,遍历整棵子树
if param in ignored_params:
continue
if _is_fsdp_flattened(param): # ★ 核心过滤:跳过已被子 FSDP 接管的参数
continue
yield paramignored_params 是 _get_orig_params 函数的第一个过滤条件,作用是显式排除不需要被当前 FSDP Unit 接管的参数,细粒度调优的时候会用到。
默认配置的话,关键在 _is_fsdp_flattened(param):子 FSDP Unit 初始化时,FlatParamHandle 会对其管辖的所有参数调用 _set_fsdp_flattened(param) 打标记。父 FSDP Unit 轮到初始化时,这些已被标记的参数就会被 _get_orig_params 过滤掉,只把剩余未被子 FSDP 接管的参数打平到一起。
整个执行顺序是严格自底向上的:
_recursive_wrap(DFS,叶子优先)
└→ _fsdp_wrapped_module.model.layers.0 → FSDP.__init__ → FlatParamHandle(打标记)
└→ _fsdp_wrapped_module.model.layers.1 → FSDP.__init__ → FlatParamHandle(打标记)
...
└→ _fsdp_wrapped_module.model.layers.n-1 → FSDP.__init__ → FlatParamHandle(打标记)
root FSDP.__init__ → _get_orig_params 过滤后只剩 embed_tokens/norm/lm_head → FlatParamHandle以 Qwen25-7B 为例,flat 的实际边界如下:
root FSDP
├── _fsdp_wrapped_module.model.layers.0 FSDP
│ FlatParameter_layer0 ← 包含:
│ self_attn.q/k/v/o_proj 的 weight/bias
│ mlp.gate/up/down_proj 的 weight
│ input_layernorm/post_attention_layernorm 的 weight
│
├── _fsdp_wrapped_module.model.layers.1 FSDP
│ FlatParameter_layer1 ← (参数组成与layers.0完全一致)
...
├── _fsdp_wrapped_module.model.layers.27 FSDP
│ FlatParameter_layer27 ← (参数组成与layers.0完全一致)
│
├── FlatParameter_root 包含:
│ model.embed_tokens.weight(Embedding层)
│ model.norm.weight(Qwen2RMSNorm层)
│ lm_head.weight(Linear层)
│💡 一句话总结:wrap 策略决定「哪个模块成为独立的分片单元」,_is_fsdp_flattened 标记机制保证「每个参数只被一个 FSDP Unit 接管」,两者共同决定了 FlatParameter 的边界。这与 DeepSpeed ZeRO-3 逐参数管理(每个 param.ds_tensor 独立分配,无分组概念)形成了最鲜明的设计对比。
2.4 FlatParameter 的结构性局限------以多模态冻结 ViT 为例
理解了 FlatParameter 的边界机制,它的结构性局限也就自然浮现了:一旦参数被打平进同一个 FlatParameter,组内各参数的梯度需求就无法再独立区分。这个问题在多模态模型冻结 ViT 的场景下暴露得最为典型。
问题的触发条件:
多模态训练中,ViT 作为视觉编码器通常被冻结(requires_grad=False),只训练 LLM 部分。wrap 策略会把 ViT 的各层和 LLM 的各层分别 wrap 成独立的 FSDP Unit,这一步是对的。问题出在边界处------root FSDP Unit 在收集「剩余参数」时(_get_orig_params 过滤后),可能同时纳入 ViT 的 patch embedding、LLM 的 embedding 等,把冻结参数和可训练参数混入同一个 FlatParameter。
FSDP 对此有明确校验:use_orig_params=False 时同一 FlatParameter 内混有冻结和非冻结参数会直接抛 ValueError;use_orig_params=True 时校验被绕过,flat_param_requires_grad 用逻辑或聚合为 True,冻结参数跟着可训练参数一起走 AllGather/ReduceScatter,反向时 backward kernel 连坐执行,产生不必要的通信和计算开销。
VeRL 的应对方式是检测到冻结 ViT 时强制切换 use_orig_params=True:
(尽管显存浪费依然存在,但这属于fsdp在该多模态场景下的bug,并非昇腾引入)
py
# verl/verl/workers/fsdp_workers.py(节选)
if self.config.actor.get(「freeze_vision_tower」, False):
vision_tower = get_vl_model_vision_tower(actor_module)
if vision_tower is not None:
vision_tower.requires_grad_(False)
self.use_orig_params = True # 将 ValueError 降级为 warning,但显存浪费依然存在这是绕过而非解决。更彻底的方案是细粒度 wrap + ignored_modules:将视觉塔中被 wrap_policy 点名的大模块(VisionBlock、Merger 等)正常走 FSDP 分片,把剩余"流浪"的小参数(patch embedding、position embedding 等)通过 ignored_modules 完全移出 Root FSDP 管辖------这些参数不进任何 FlatParameter,通信和计算路径对其完全透明。实测在大参数量多模态模型上,该方案相比 use_orig_params=True 可带来可观的显存和耗时收益,后续会单独介绍这部分工作,这里先埋个坑。
FSDP2 的演进方向: FSDP2 用 DTensor 彻底替换了 FlatParameter。DTensor 是逐参数分片的,每个参数独立持有分片信息和梯度状态,冻结参数的 requires_grad=False 直接生效,不再受「组内统一对待」的约束。有意思的是,DTensor 的逐参数分片哲学在粒度上反而更接近 DeepSpeed ZeRO-3------兜了一圈,FSDP2 在这一维度上向 DeepSpeed 的设计靠拢了。
💡 一句话总结:FlatParameter 的「组级」抽象在纯训练场景下是效率优势,在混合冻结场景下却成了结构性负担。FSDP2 用 DTensor 逐参数分片取而代之,是对这一局限的根本性修正。
3. 参数扁平化------FlatParameter 的构建
3.1 从原始参数到 FlatParameter
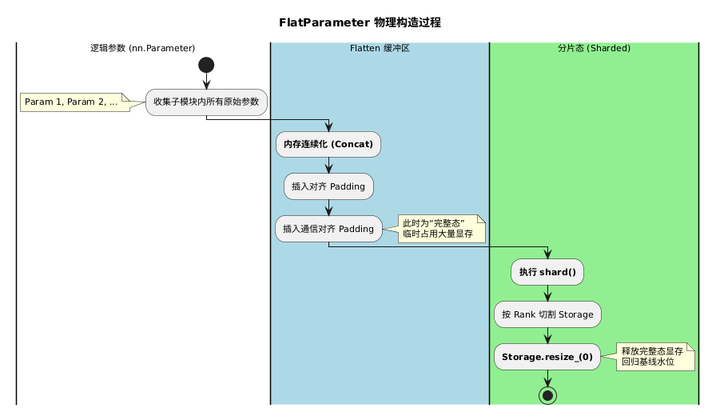
FlatParamHandle.init 依次完成三步:
- 确定所有参数的统一 dtype(_validate_tensors_to_flatten 强制要求 dtype 一致);
- 根据 MixedPrecision 配置确定 _fwd_bwd_param_dtype 和 _reduce_dtype;
- 调用 _init_flat_param_and_metadata 构造 FlatParameter。
_init_flat_param_and_metadata 的核心操作是收集参数、插入两类 padding、最终 concat:
python
# _init_flat_param_and_metadata(核心路径,节选)
for param in params:
# 地址对齐 padding(use_orig_params=True 时),插在每个参数前
if aligned_numel > 0:
numel_to_pad = aligned_numel - (total_numel % aligned_numel)
if numel_to_pad > 0:
params_to_flatten.append(_construct_padding_tensor(numel_to_pad, ...))
params_to_flatten.append(param)
# 通信对齐 padding,追加在末尾,保证总长度能被 world_size 整除
numel_to_pad = world_size - (total_numel % world_size)
if numel_to_pad > 0:
params_to_flatten.append(_construct_padding_tensor(numel_to_pad, ...))
# 等价于 torch.cat([p.flatten() for p in params_to_flatten])
self.flat_param = self.flatten_tensors_into_flat_param(params_to_flatten, ...)3.2 dtype 的决定因素
FlatParameter 的 dtype 直接继承自原始参数。在 VeRL 的典型配置中,actor model 用 FP32 加载(源码注释:必须用 FP32,否则 optimizer 在 BF16 下运行导致训练不正确),混合精度配置 param_dtype=BF16, reduce_dtype=FP32,由此确定:
python
# _init_param_reduce_dtypes(核心逻辑)
self._fwd_bwd_param_dtype = mp_param_dtype or self._orig_param_dtype # BF16
self._reduce_dtype = mp_reduce_dtype or self._orig_param_dtype # FP32_fwd_bwd_param_dtype 决定 _mp_shard 和 _full_param_padded 的 dtype;_reduce_dtype 决定梯度 ReduceScatter 的通信精度。actor 的 _local_shard 为 FP32,ref 的 _local_shard 为 BF16。
4. 参数分片------_local_shard 的诞生
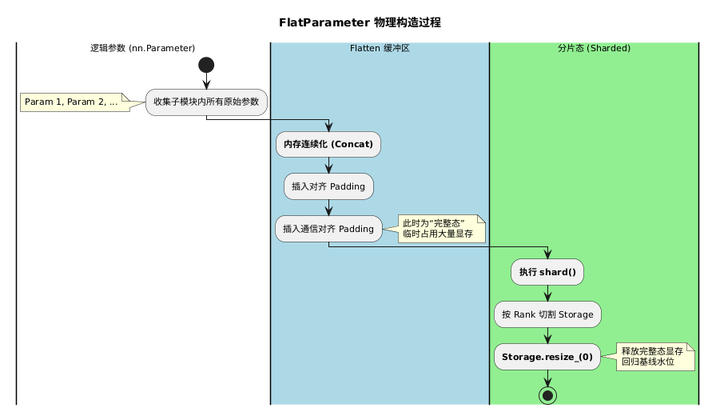
4.1 shard():物理分片的核心操作
FlatParameter 构建完成后,shard() 完成真正的显存切割:
py
# FlatParamHandle.shard()(核心路径)
sharded_flat_param, numel_padded = FlatParamHandle._get_shard(
flat_param, self.rank, self.world_size
)
# 立即释放完整参数的底层存储
flat_param._typed_storage()._resize_(0)
# 指针切换:flat_param 对象不变,内部存储指向当前 rank 的分片
flat_param.set_(sharded_flat_param)
start_idx = sharded_flat_param.numel() * self.rank
end_idx = sharded_flat_param.numel() * (self.rank + 1) - 1
self._init_shard_metadata(numel_padded, start_idx, end_idx)_typed_storage()._resize_(0) 的作用与 DeepSpeed 中 tensor.data.resize_(0) 完全类似------将 Storage 尺寸置零使引用计数归零,但不会立即触发 CUDA 显存回收,需要后续的 torch.cuda.empty_cache() 才能将碎片真正归还给 CUDA 驱动。
4.2 init_flat_param_attributes():_local_shard 的正式赋值
shard() 完成后,init_flat_param_attributes() 被调用,完成各类运行时张量的初始化:
py
# FlatParamHandle.init_flat_param_attributes()(核心路径)
# ★ _local_shard = 分片后的 flat_param.data,dtype 继承自原始参数
flat_param._local_shard = flat_param.data
if self._offload_params:
flat_param._local_shard = flat_param._local_shard.pin_memory()
flat_param._cpu_grad = torch.zeros_like(flat_param._local_shard, device=「cpu」).pin_memory()
# 混合精度:低精度分片,创建后立即 free(lazy)
if self._uses_param_mixed_precision:
flat_param._mp_shard = torch.empty_like(flat_param._local_shard, dtype=self._fwd_bwd_param_dtype)
_free_storage(flat_param._mp_shard)
# AllGather 目标 buffer,同样 lazy
if self.uses_sharded_strategy:
flat_param._full_param_padded = torch.empty(
flat_param.numel() * self.world_size, dtype=self._fwd_bwd_param_dtype
)
_free_storage(flat_param._full_param_padded)
# 混合精度专属:高精度完整参数 buffer(summon_full_params 等场景)
if self._uses_param_mixed_precision:
flat_param._full_prec_full_param_padded = torch.empty(
flat_param.numel() * self.world_size, dtype=flat_param.dtype # FP32
)
_free_storage(flat_param._full_prec_full_param_padded)这里有一个重要的工程细节:_mp_shard、_full_param_padded、_full_prec_full_param_padded 三个 buffer 在初始化时调用 _free_storage()立即释放底层存储。这是 FSDP 「短命完整态」哲学的集中体现:提前占位(创建 Tensor 对象,记录 shape/dtype/device),但不提前占用显存,真正需要时再 lazy 分配(_alloc_storage())。
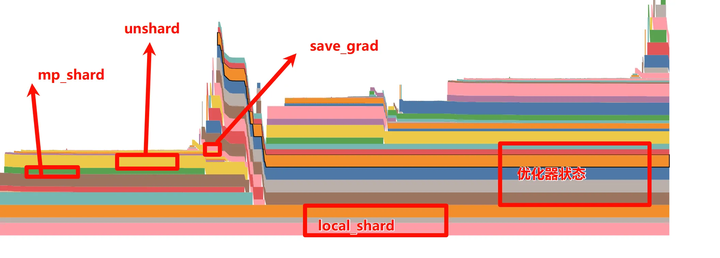
💡 一句话总结:_local_shard 是 FSDP 参数分片的真正存储位置,是每个 rank 训练全程唯一常驻的权重资产,大小 ≈ 完整参数量 / world_size。其余 buffer(_mp_shard、_full_param_padded)只是「提前登记」了坐标,不到用时不占显存。
5. 深度关联:从 VeRL 的 Offload 实现看各类张量的归宿
在 RLHF 训练中,Actor(训练态)与 Ref(推理态)的显存表现截然不同。理解这一点的关键在于:精度决定了 _local_shard 的物理形态,而 Offload 的本质就是对这个物理形态的搬运。
5.1 为什么 Offload 盯着 _local_shard 撸?
根据前文分析,FSDP 在初始化后的静态格局中,唯一长期占用显存的权重资产就是 _local_shard。
- 对于 Actor:_local_shard 是 FP32 精度,为了支撑 AdamW 优化器的数值稳定性。
- 对于 Ref:_local_shard 直接就是 BF16 精度,因为它只负责推理。
VeRL 的 offload_fsdp_model_to_cpu 函数正是通过操作这个"唯一常驻资产"来腾挪显存的。
5.2 VeRL 源码逻辑剖析:指针的"狸猫换太子"
py
@torch.no_grad()
def offload_fsdp_model_to_cpu(model: FSDP, empty_cache: bool = True):
# ... 略去 FSDP2 判断 ...
_lazy_init(model, model) # 确保元数据已就位,FlatParamHandle 已创建
for handle in model._all_handles:
if handle._offload_params: # 已在 CPU 的不再重复搬运
continue
flat_param = handle.flat_param
# 核心断言:验证"逻辑分片"与"物理存储"的一致性
assert (
flat_param.data.data_ptr() == flat_param._local_shard.data_ptr()
and id(flat_param.data) != id(flat_param._local_shard)
and flat_param.data.size() == flat_param._local_shard.size()
)为什么要有这段复杂的断言?
-
位置一致性:在非计算状态下,flat_param.data 应该恰好指向当前 Rank 的分片数据(即 _local_shard)。
-
身份独立性:虽然物理指针(data_ptr)相同,但 FSDP 为了灵活管理,让 _local_shard 和 flat_param.data 成了两个不同的 Python 对象。
py# 物理搬运:将整块 FlatParameter 及其关联存储移往 CPU handle.flat_param_to(torch.device(「cpu」), non_blocking=True) # 指针同步:搬运后 flat_param.data 发生了变化,必须手动更新引用 flat_param._local_shard = flat_param.data
逻辑闭环: 由于 _mp_shard 和 _full_param 在静态下都是 _free_storage 状态(不占显存),搬运 flat_param 就等同于搬运了 _local_shard。VeRL 通过手动重置 _local_shard = flat_param.data,确保了后续训练重新回到 GPU 时,FSDP 依然能找到正确的分片数据基址。
5.3 显存搬运后的状态全貌
我们可以通过下表看清 Offload 之后,各类张量在 VeRL 调度下的新去向:
张量类型 Offload 前位置 Offload 后位置理由_local_shardGPUCPU (Pinned)释放常驻显存,为 Rollout 留出空间_mp_shard 未分配 (Lazy)未分配 (Lazy)不占用搬运带宽_full_param
| 张量类型 | Offload 前位置 | Offload 后位置 | 理由 |
|---|---|---|---|
| _local_shard | GPU | CPU (Pinned) | 释放常驻显存,为 Rollout 留出空间 |
| _mp_shard | 未分配 (Lazy) | 未分配 (Lazy) | 不占用搬运带宽 |
| _full_param | 未分配 (Lazy) | 未分配 (Lazy) | 不占用搬运带宽 |
未分配 (Lazy)未分配 (Lazy)不占用搬运带宽
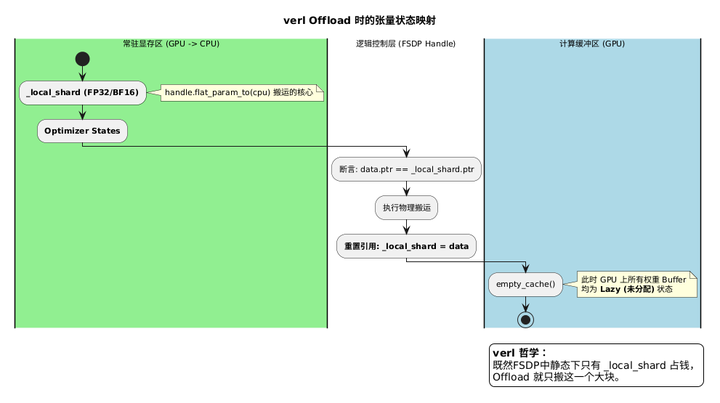
💡 总结:VeRL 的 Offload 实现极其简洁,因为它看穿了 FSDP 的本质------除了分片 _local_shard 是实心的,其余完整态 Buffer 都是空壳。 只要把这个"实心"的分片挪走,GPU 就彻底清净了。
6. 初始化阶段显存全貌
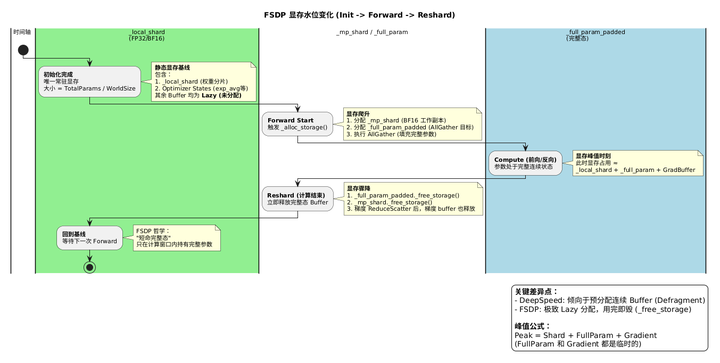
各类张量在初始化完成后各就各位,构成训练启动前的静态显存格局。下表按调用顺序列出每一步分配了什么:
| 调用入口 | 分配的张量 | 说明 |
|---|---|---|
| _init_flat_param_and_metadata | flat_param(完整) | 所有参数 flatten + concat,此时尚未分片 |
| shard() | sharded_flat_param | 按 rank 切分,完整 flat_param 的存储立即释放 |
| init_flat_param_attributes | flat_param._local_shard | 等于 shard() 后的 flat_param.data,FP32(actor)/ BF16(ref) |
| init_flat_param_attributes | flat_param._mp_shard | BF16,lazy 分配(初始化后立即 _free_storage) |
| init_flat_param_attributes | flat_param._full_param_padded | BF16,AllGather 目标 buffer,lazy 分配 |
| init_flat_param_attributes | flat_param._full_prec_full_param_padded | FP32,混合精度专属,lazy 分配 |
| 首次反向传播 | flat_param._saved_grad_shard | 梯度常驻分片,延迟到反向才创建 |
| 首次 optimizer.step() | exp_avg、exp_avg_sq | Adam 动量,与 _local_shard 等大 |
以 Qwen2-7B、8 卡训练(N=8)为例,actor model 单卡各张量的静态显存占用(初始化完成、首次前向前):
| 张量 | 精度 | 计算 | 大小 |
|---|---|---|---|
| _local_shard(FP32 主权重) | FP32 | 7B × 4B / 8 | ≈ 3.5 GB |
| _mp_shard(BF16,lazy) | BF16 | 0(未分配) | 0 GB |
| _full_param_padded(BF16,lazy) | BF16 | 0(未分配) | 0 GB |
| exp_avg + exp_avg_sq | FP32 | 7B × 4B × 2 / 8 | ≈ 7 GB |
| 合计静态显存 | ≈ 10.5 GB |
lazy 分配的 buffer(_mp_shard、_full_param_padded)在初始化结束时不占显存,只在前向开始时按需创建,使用后立即释放。这是 FSDP 控制显存峰值的核心手段,将在第二篇前向/反向部分详细分析。
7. 与 DeepSpeed ZeRO-3 的对照
站在同一目标(每张卡只存 1/N 的参数)上,FSDP 和 DeepSpeed ZeRO-3 走了两条截然不同的路:
| FSDP | DeepSpeed ZeRO-3 | |
|---|---|---|
| 分片管理粒度 | FSDP Unit(由 wrap 策略决定,如一个 Transformer Block) | 逐参数(每个 param.ds_tensor 独立分配) |
| "哪些参数在一起"的决定机制 | transformer_auto_wrap_policy + _is_fsdp_flattened 过滤 | 无分组,ds_id 逐参数管理 |
| AllGather 触发粒度 | FSDP Unit(一次 AllGather 恢复整个 Block) | 逐参数按需 AllGather |
| 参数抽象 | FlatParameter(Unit 内所有参数 concat 成一个一维张量) | 逐参数 param.ds_tensor |
| FP32 主权重位置 | _local_shard(外部 optimizer 直接访问) | fp32_partitioned_groups_flat(optimizer 内部管理) |
| BF16 工作副本位置 | _mp_shard(混合精度时存在) | fp16_partitioned_groups_flat(训练模型专有) |
| 完整参数 buffer | _full_param_padded(lazy 分配,用完即释放) | AllGather 时临时申请 |
| 显存连续化手段 | flatten_tensors(构建时一次性 concat,天然连续) | defragment(将碎片化 ds_tensor 事后整理为连续大块) |
| 梯度 buffer | 无全局 flat buffer(按需分配) | grad_partitions_flat_buffer(全程持久,一次性 malloc) |
| 通信原语(梯度) | ReduceScatter | AllReduce + 本地切片(连续路径)/ ReduceScatter(离散路径) |
两者最核心的设计差异体现在两个维度。粒度上:FSDP 以 FSDP Unit 为调度单位,wrap 策略决定边界,_is_fsdp_flattened 标记保证每个参数只被一个 Unit 接管;DeepSpeed 则是彻底的逐参数管理,_zero_init_param 对每个参数单独调用,没有分组概念。显存持有策略上:DeepSpeed 倾向于"长期持有连续 buffer + 用时填入"(defragment 是典型体现);FSDP 倾向于"只长期持有分片,其余 buffer 短命"(_free_storage 后 lazy 分配是典型体现)。前者以空间换时间(减少 alloc 次数),后者以时间换空间(极致控制峰值显存)。
8. 小结
| 张量 | 分配时机 | 本质 |
|---|---|---|
| flat_param(完整) | _init_flat_param_and_metadata | 所有参数 flatten + concat 的中间态,分片后存储立即释放 |
| _local_shard | init_flat_param_attributes | 常驻分片,训练全程唯一长期占用的权重显存 |
| _mp_shard | init_flat_param_attributes(lazy) | FP32 → BF16 的工作副本,前向前创建,前向后释放 |
| _full_param_padded | init_flat_param_attributes(lazy) | AllGather 目标 buffer,存在窗口极短 |
| _saved_grad_shard | 首次反向传播 | 梯度常驻分片,step 后释放 |
| exp_avg / exp_avg_sq | 首次 optimizer.step() | Adam 动量,与 _local_shard 等大 |
FSDP 的显存节省同样来自一个简单的原则:每张卡只长期持有 1/N 的参数(_local_shard),完整态按需创建、用完即毁。与 DeepSpeed ZeRO-3 不同的是,FSDP 把"按需"做到了极致------甚至 AllGather 的目标 buffer 都是 lazy 分配的,初始化阶段真正占用的显存只有 _local_shard 和 optimizer 状态。
如果你对多模态大模型、强化学习、昇腾 NPU 部署、模型性能优化感兴趣,欢迎持续关注【AI模力圈】。
我们会持续更新:
- 多模态模型结构拆解
- 强化学习算法原理与实践
- 昇腾 NPU 迁移部署与踩坑复盘
- 模型训练与推理性能优化