深入理解 LLM 分布式训练全栈:从硬件到 LLaMA-Factory
大语言模型的训练是一项复杂的系统工程。从底层的芯片指令,到上层的训练框架,每一层都承担着独特的职责,彼此协作才能完成数百亿参数模型的高效训练。本文将自底向上逐层拆解这套技术栈,并配合实际示例帮助你真正理解每一层的设计意图与工作机制。
整个技术栈的层级关系如下:
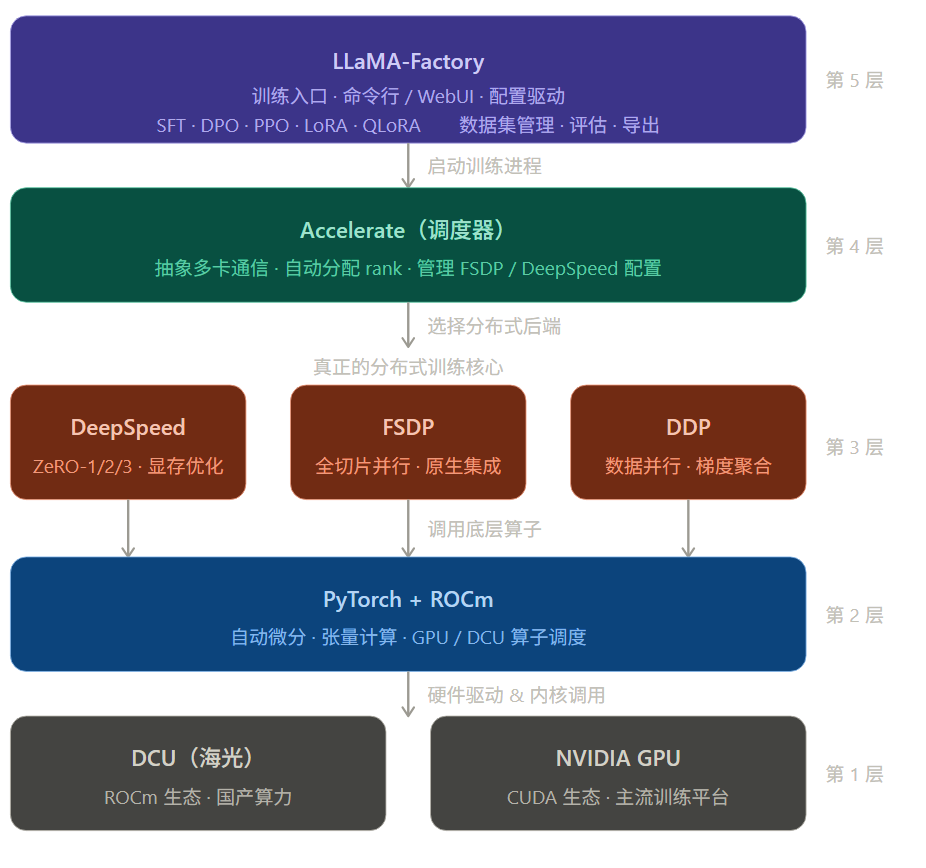
第一层:DCU / GPU 硬件------算力的物理基础
一切计算都要落在硬件上。当前大模型训练主要依赖两类加速芯片:
NVIDIA GPU + CUDA 是业界最成熟的路线。CUDA 是 NVIDIA 专有的并行编程平台,提供了从底层 PTX 指令到高层 cuDNN/cuBLAS 库的完整生态,PyTorch 和所有主流框架默认以 CUDA 为主要后端。
海光 DCU + ROCm 是近年来在国产算力路线上崛起的方案。DCU(Deep Computing Unit)在架构上与 AMD GPU 高度兼容,使用 ROCm(Radeon Open Compute)作为开放计算平台。ROCm 提供了与 CUDA 相似的编程接口(HIP),使得大量 CUDA 代码可以通过较少的修改迁移到 DCU 上运行。
单卡的算力天花板是固定的------A100 的峰值算力约为 312 TFLOPS(BF16),H100 约为 1979 TFLOPS。但 GPT-3 级别的模型训练需要数百万 GPU 小时,因此多卡并行训练是工程的核心命题,这就把问题交给了上层的软件栈。
两类硬件对比
| 指标 | NVIDIA GPU | 海光 DCU |
|---|---|---|
| 编程接口 | CUDA / cuDNN | HIP / MIOpen |
| 生态成熟度 | 最成熟 | 快速追赶 |
| 与 PyTorch 集成 | 原生支持 | 通过 ROCm 支持 |
| 典型型号 | A100、H100、4090 | K100、Z100 |
| 适用场景 | 全场景 | 国产算力替代 |
第二层:PyTorch + ROCm------计算底座
PyTorch 是现代深度学习的事实标准框架,提供了三项核心能力:
自动微分(Autograd)
PyTorch 将每个张量操作记录成计算图,调用 .backward() 时自动沿图反向传播梯度。这是所有优化器工作的前提。
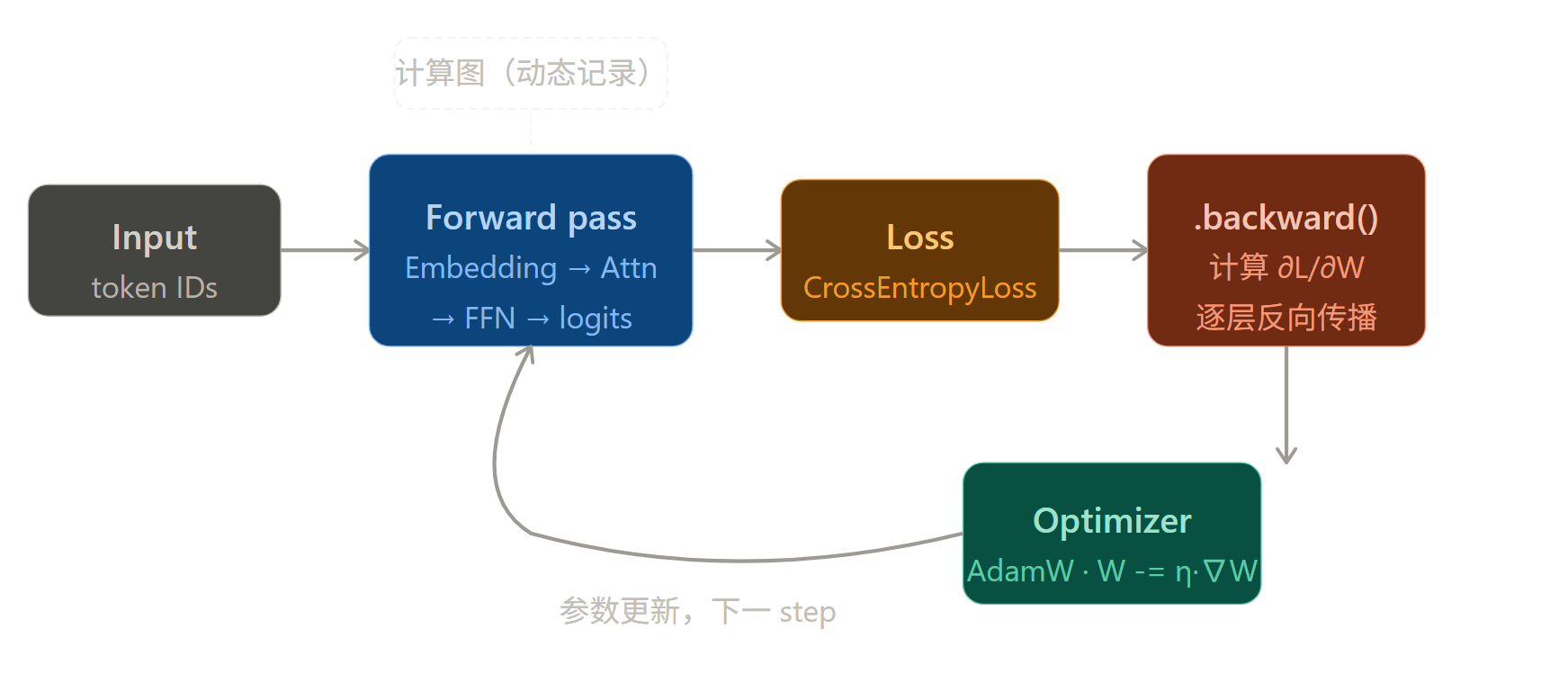
张量计算库
底层通过调用 cuDNN(CUDA 路线)或 MIOpen(ROCm 路线)执行矩阵乘法、卷积等高性能算子。对用户而言,torch.matmul() 就是 torch.matmul()------无论跑在 A100 还是 DCU 上接口完全一致。
设备抽象
通过 device="cuda" 或 device="cuda:0" 指定计算设备,跨设备的数据搬运由框架管理。
最小训练循环示例
python
import torch
import torch.nn as nn
model = MyTransformer().to("cuda")
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
criterion = nn.CrossEntropyLoss()
for batch in dataloader:
input_ids = batch["input_ids"].to("cuda")
labels = batch["labels"].to("cuda")
# 前向传播(自动构建计算图)
logits = model(input_ids)
loss = criterion(logits.view(-1, vocab_size), labels.view(-1))
# 反向传播 + 参数更新
optimizer.zero_grad()
loss.backward() # 自动求导
optimizer.step() # 更新权重这是单卡的写法。一旦模型大到单张卡放不下,或者训练数据量需要多卡并行提速,就需要第三层登场。
第三层:DeepSpeed / FSDP / DDP------真正的分布式训练核心
这一层是整个技术栈中最复杂、最关键的部分。三种框架代表了不同的并行哲学。
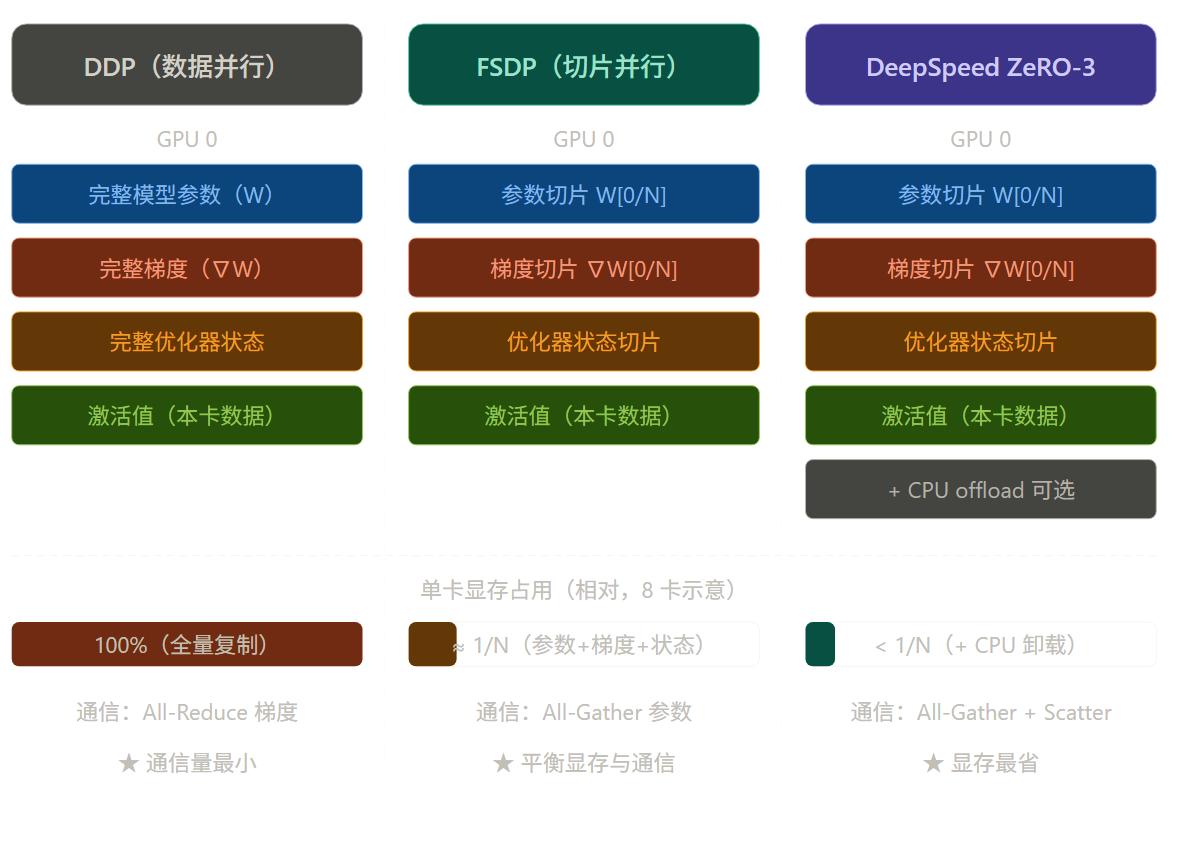
三种方案的显存分配对比
DDP(DistributedDataParallel)
DDP 是 PyTorch 原生的数据并行方案,也是最容易理解的一种:每张卡持有完整的模型副本 ,但每次只处理不同的数据子集。训练结束时,通过 All-Reduce 操作对所有卡上的梯度求平均,然后各卡同步更新权重。
DDP 的优点是逻辑简单、通信开销小;缺点是每张卡都要放下整个模型,所以显存成本没有降低,超大模型放不下。
python
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
model = MyTransformer().to(local_rank)
model = DDP(model, device_ids=[local_rank])
# 其余训练代码与单卡完全相同
# DDP 会在 loss.backward() 后自动触发 All-Reduce启动命令:
bash
torchrun --nproc_per_node=8 train.pyFSDP(Fully Sharded Data Parallel)
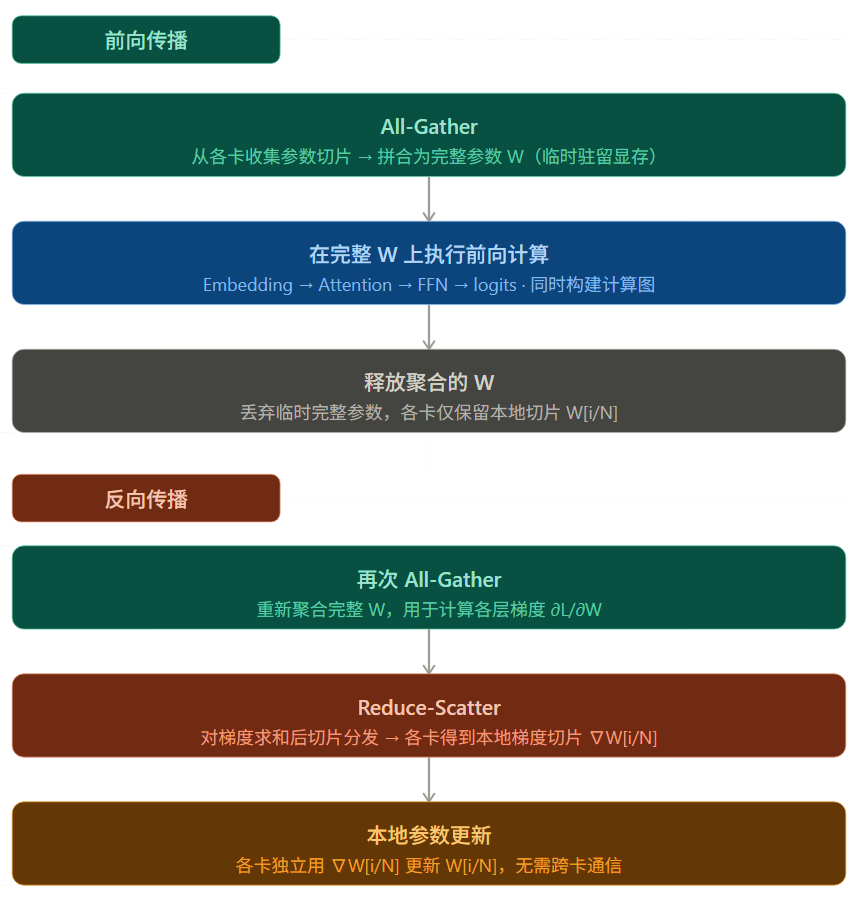
FSDP 是 PyTorch 1.11+ 引入的原生方案,灵感来自 Facebook 的 ZeRO 论文。它将模型的参数、梯度和优化器状态都切片分散 到各卡上------每张卡只保存 1/N 的权重。需要计算时,通过 All-Gather 临时聚合完整参数,计算完毕后立即释放。
这意味着 8 张卡可以放下 8 倍于单卡显存的模型,代价是额外的通信开销。FSDP 是目前 Llama 3、Mistral 等模型开源训练中的主流方案。
python
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp import (
MixedPrecision,
ShardingStrategy,
CPUOffload,
)
model = FSDP(
model,
sharding_strategy=ShardingStrategy.FULL_SHARD, # 全切片
mixed_precision=MixedPrecision(
param_dtype=torch.bfloat16,
reduce_dtype=torch.bfloat16,
buffer_dtype=torch.bfloat16,
),
cpu_offload=CPUOffload(offload_params=False), # 可选 CPU offload
device_id=local_rank,
)FSDP 的关键机制:
DeepSpeed ZeRO
DeepSpeed 由微软研究院开发,其核心是 ZeRO(Zero Redundancy Optimizer)技术,分三个阶段:
| 阶段 | 切片内容 | 显存节省(N 卡) | 通信开销 |
|---|---|---|---|
| ZeRO-1 | 优化器状态 | ~4× | 低 |
| ZeRO-2 | 优化器状态 + 梯度 | ~8× | 中 |
| ZeRO-3 | 优化器状态 + 梯度 + 参数 | ~N× | 高 |
| ZeRO-3 + Offload | 以上 + CPU 卸载 | 极高 | 最高 |
DeepSpeed 还提供了 Gradient Checkpointing、混合精度、FlashAttention 集成等一系列优化,是工业界训练超大模型的主要工具之一。
DeepSpeed 配置文件示例(ds_config.json):
json
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "none"
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": 5e8
},
"bf16": {
"enabled": true
},
"train_micro_batch_size_per_gpu": 2,
"gradient_accumulation_steps": 8,
"gradient_clipping": 1.0,
"steps_per_print": 10
}在训练脚本中集成 DeepSpeed:
python
import deepspeed
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config="ds_config.json",
)
for batch in dataloader:
loss = model_engine(batch)
model_engine.backward(loss) # 替代 loss.backward()
model_engine.step() # 替代 optimizer.step()第四层:Accelerate------调度器与抽象层
直接编写分布式训练代码需要处理大量繁琐的工程细节:进程组初始化、rank 分配、Backend 选择、不同框架的配置文件管理......Hugging Face 的 Accelerate 库正是为了解决这个痛点而生。
Accelerate 的核心思想是:写一次代码,跑在任意规模的硬件上。它在训练脚本和具体的分布式后端(DDP / FSDP / DeepSpeed)之间插入一层抽象,让你不必修改训练逻辑就能切换后端和硬件配置。
Accelerate 的分层抽象
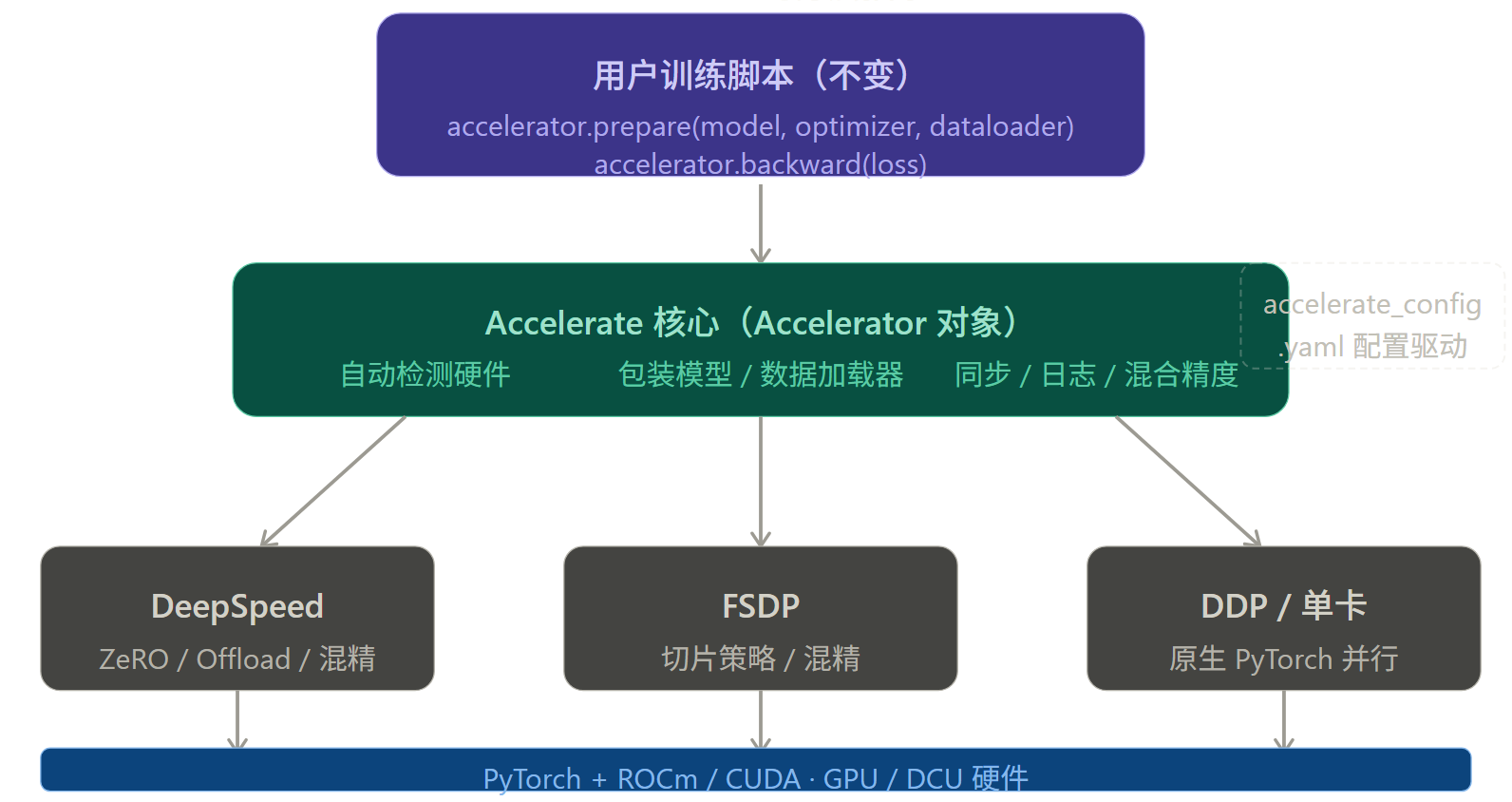
使用 Accelerate 改写训练脚本
对比改造前后的代码差异:
改造前(手动 DDP):
python
dist.init_process_group(backend="nccl")
model = DDP(model.to(local_rank), device_ids=[local_rank])
for batch in dataloader:
batch = {k: v.to(local_rank) for k, v in batch.items()}
loss = model(**batch).loss
loss.backward()
optimizer.step()
optimizer.zero_grad()改造后(Accelerate):
python
from accelerate import Accelerator
accelerator = Accelerator(mixed_precision="bf16")
# Accelerate 自动将模型、优化器、数据加载器包装成分布式版本
model, optimizer, train_dataloader = accelerator.prepare(
model, optimizer, train_dataloader
)
for batch in train_dataloader:
# 无需手动 .to(device),Accelerate 已处理
with accelerator.accumulate(model): # 自动处理梯度累积
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss) # 替代 loss.backward()
optimizer.step()
optimizer.zero_grad()代码改动极少,但现在这段代码可以在单卡、8 卡 DDP、8 卡 FSDP、8 卡 DeepSpeed 之间自由切换。
通过配置文件切换后端
切换到 8 卡 DeepSpeed ZeRO-3(accelerate_config.yaml):
yaml
compute_environment: LOCAL_MACHINE
distributed_type: DEEPSPEED
num_processes: 8
deepspeed_config:
zero_stage: 3
offload_optimizer_device: cpu
offload_param_device: none
overlap_comm: true
contiguous_gradients: true
mixed_precision: bf16切换到 8 卡 FSDP:
yaml
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
num_processes: 8
fsdp_config:
fsdp_sharding_strategy: FULL_SHARD
fsdp_offload_params: false
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_transformer_layer_cls_to_wrap: LlamaDecoderLayer
mixed_precision: bf16启动命令(统一):
bash
accelerate launch --config_file accelerate_config.yaml train.py训练脚本本身完全不需要改动。
生成配置文件
bash
# 交互式向导,引导生成配置文件
accelerate config
# 也可以直接传参启动,不使用配置文件
accelerate launch \
--num_processes 8 \
--use_deepspeed \
--deepspeed_config_file ds_config.json \
train.py第五层:LLaMA-Factory------训练入口
LLaMA-Factory 是这个栈的最顶层,它把前四层的所有复杂性封装成一套配置驱动、开箱即用的训练框架,支持几十种主流开源大模型的微调。
核心功能
开箱即用的算法覆盖:
| 类别 | 支持算法 |
|---|---|
| 监督微调 | SFT(全参数 / LoRA / QLoRA / DoRA) |
| 偏好对齐 | DPO、ORPO、SimPO、KTO |
| 强化学习 | PPO、REINFORCE |
| 预训练继续 | CPT(Continued Pre-Training) |
参数高效微调方法:
| 方法 | 原理 | 适用场景 |
|---|---|---|
| LoRA | 低秩矩阵分解,只训练 adapter | 资源有限,快速迭代 |
| QLoRA | 4-bit 量化基座 + LoRA | 单卡微调大模型 |
| DoRA | 权重分解为幅度 + 方向 | 效果优于 LoRA |
| 全参数 | 更新所有权重 | 算力充足,追求最优效果 |
数据集标准化:
LLaMA-Factory 支持两种主流格式,用户只需将数据转换后在 dataset_info.json 中注册:
json
// dataset_info.json
{
"my_dataset": {
"file_name": "my_data.json",
"formatting": "alpaca",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
}Alpaca 格式示例:
json
[
{
"instruction": "请将以下句子翻译成英文。",
"input": "今天天气真好。",
"output": "The weather is really nice today."
}
]两种使用入口
命令行接口(CLI):
bash
# 启动 4 卡 QLoRA 微调(通过 Accelerate + DeepSpeed)
accelerate launch \
--config_file accelerate_config.yaml \
src/train.py \
--model_name_or_path meta-llama/Llama-3.1-8B-Instruct \
--stage sft \
--do_train \
--dataset alpaca_zh \
--template llama3 \
--finetuning_type lora \
--lora_rank 16 \
--lora_target q_proj,v_proj \
--output_dir ./output/llama3-sft \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--num_train_epochs 3 \
--learning_rate 1e-4 \
--lr_scheduler_type cosine \
--bf16WebUI 接口:
bash
# 启动 Gradio WebUI
llamafactory-cli webuiWebUI 在浏览器中提供可视化配置界面,无需记忆任何命令行参数,适合快速调试和实验。
模型导出与推理
微调完成后,LLaMA-Factory 支持将 LoRA adapter 合并回基座模型:
bash
llamafactory-cli export \
--model_name_or_path meta-llama/Llama-3.1-8B-Instruct \
--adapter_name_or_path ./output/llama3-sft \
--export_dir ./merged_model \
--template llama3 \
--finetuning_type lora贯通全栈:一次训练命令的完整流程
理解每一层之后,来看一次训练命令从下达到实际计算的完整调用链:
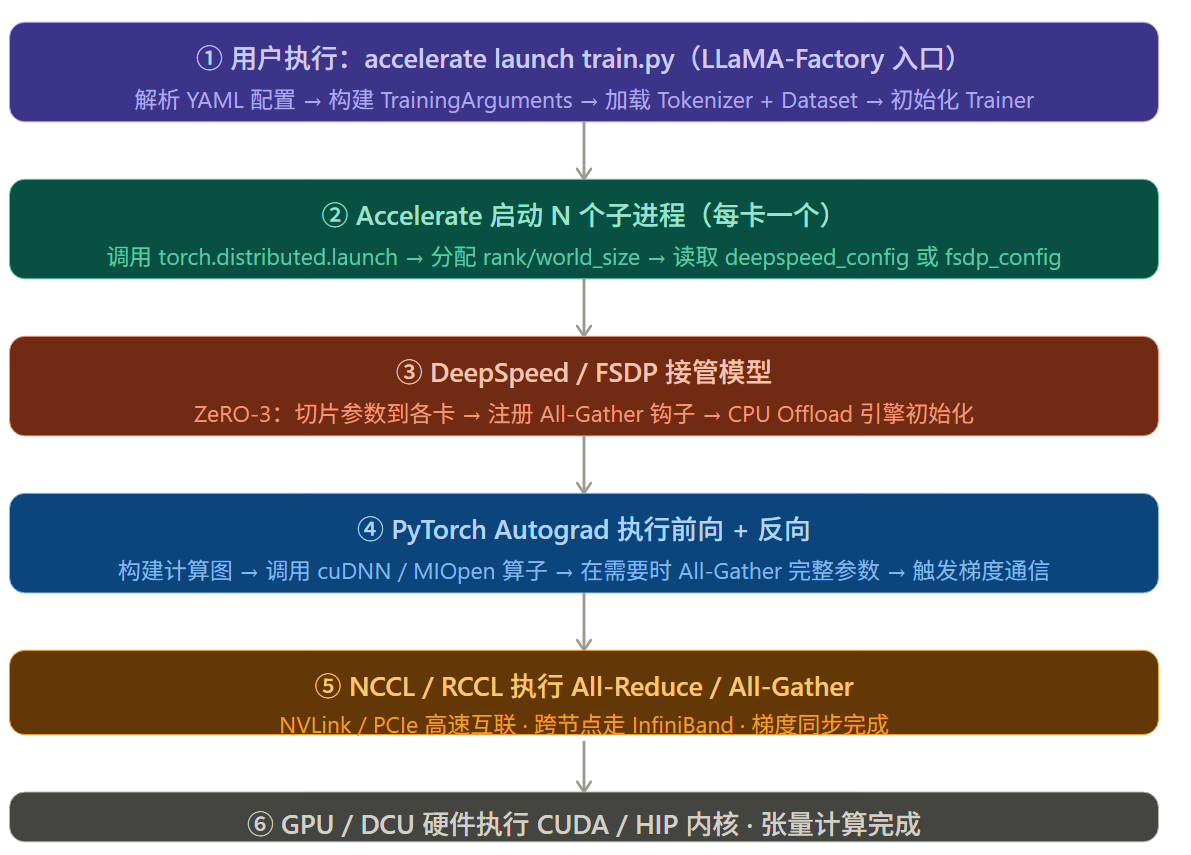
实践:一个完整的 8 卡 QLoRA 微调示例
下面把所有层级串联起来,给出一个可以直接参考的完整配置。
第一步:硬件确认(第一层)
bash
# 确认 GPU 可见
nvidia-smi
# 确认 NCCL 通信正常
python -c "import torch; print(torch.cuda.device_count())"第二步:Accelerate 配置(第四层)
文件:accelerate_config.yaml
yaml
compute_environment: LOCAL_MACHINE
distributed_type: DEEPSPEED
num_processes: 8
deepspeed_config:
zero_stage: 3
offload_optimizer_device: cpu
offload_param_device: none
overlap_comm: true
contiguous_gradients: true
gradient_clipping: 1.0
mixed_precision: bf16第三步:训练参数配置(第五层)
文件:train_args.yaml
yaml
# 模型
model_name_or_path: meta-llama/Llama-3.1-8B-Instruct
# 训练阶段
stage: sft
do_train: true
# 微调方法
finetuning_type: lora
quantization_bit: 4 # QLoRA:4-bit 量化基座模型
lora_rank: 64
lora_alpha: 128
lora_target: all # 对所有线性层添加 LoRA
lora_dropout: 0.05
# 数据
dataset: alpaca_zh,self_cognition
template: llama3
cutoff_len: 4096
max_samples: 50000
preprocessing_num_workers: 16
# 训练超参
output_dir: ./output/llama3-qlora
logging_dir: ./logs
logging_steps: 10
save_steps: 500
num_train_epochs: 3
per_device_train_batch_size: 2
gradient_accumulation_steps: 8
lr_scheduler_type: cosine
learning_rate: 1.0e-4
warmup_ratio: 0.05
bf16: true
report_to: tensorboard第四步:启动训练
bash
accelerate launch \
--config_file accelerate_config.yaml \
src/train.py train_args.yaml这条命令会触发完整的调用链:
LLaMA-Factory → Accelerate → DeepSpeed ZeRO-3 → PyTorch + CUDA → 8 × GPU第五步:监控训练
bash
# 查看 TensorBoard 日志
tensorboard --logdir ./logs
# 实时查看 GPU 显存占用
watch -n 1 nvidia-smi常见问题与调优建议
显存不足(OOM)
按以下顺序逐步尝试:
1. 降低 per_device_train_batch_size(如 4 → 2 → 1)
2. 增加 gradient_accumulation_steps 保持等效 batch size
3. 启用 gradient_checkpointing(牺牲约 30% 速度换显存)
4. 升级 DeepSpeed ZeRO 阶段(1 → 2 → 3)
5. 开启 offload_optimizer_device: cpu
6. 开启 offload_param_device: cpu(速度影响较大)
7. 降低 lora_rank(64 → 32 → 16)
8. 启用 QLoRA(quantization_bit: 4)训练速度慢
1. 检查 GPU 利用率:nvidia-smi dmon -s u
2. 确认 bf16/fp16 混合精度已启用
3. 启用 FlashAttention-2(flash_attn: fa2)
4. 增大 per_device_train_batch_size 直到接近 OOM
5. 减少 DeepSpeed offload(CPU 传输会成为瓶颈)
6. 检查 DataLoader 是否成为瓶颈(增大 num_workers)多机多卡配置
bash
# 节点 0(主节点)
accelerate launch \
--num_machines 2 \
--num_processes 16 \
--machine_rank 0 \
--main_process_ip 10.0.0.1 \
--main_process_port 29500 \
--config_file accelerate_config.yaml \
src/train.py train_args.yaml
# 节点 1
accelerate launch \
--num_machines 2 \
--num_processes 16 \
--machine_rank 1 \
--main_process_ip 10.0.0.1 \
--main_process_port 29500 \
--config_file accelerate_config.yaml \
src/train.py train_args.yaml小结:各层分工一览
| 层级 | 组件 | 核心职责 | 用户感知程度 |
|---|---|---|---|
| 第 1 层 | DCU / GPU 硬件 | 实际算力,执行并行矩阵运算 | 几乎不感知 |
| 第 2 层 | PyTorch + ROCm | 自动微分、张量算子、设备抽象 | 写训练循环时感知 |
| 第 3 层 | DeepSpeed / FSDP / DDP | 显存优化、梯度通信、跨卡协同 | 配置文件中感知 |
| 第 4 层 | Accelerate | 分布式环境抽象、进程管理 | 启动命令时感知 |
| 第 5 层 | LLaMA-Factory | 算法封装、数据管理、训练入口 | 直接使用 |