作者:古琦
背景
在云原生与微服务架构下,一套生产系统往往横跨 Go、Java、Python、Node.js 等多种语言运行时,部署形态又散落在容器、Kubernetes、Serverless 之间。要在这样的异构环境里建立统一的可观测性,传统做法是为每种语言挂载侵入式 Agent 或 SDK------改代码、装包、对齐版本、重新发布,每接入一个新服务都是一次工程项目。在快速迭代的研发节奏下,这种"接入即改造"的成本越来越难以承受。
与此同时,AI Agent 应用正从单次 LLM 调用演变为多步编排的复杂工作流------一次用户请求可能触发数十次大模型调用、工具执行(Tool Call)和向量检索,调用链跨越 Agent 编排层、LLM Provider、向量数据库和外部工具,传统 APM 难以完整覆盖,零代码的可观测性方案在 AI 场景同样不可或缺。
eBPF 提供了另一条思路:在 Linux 内核里挂载安全沙箱化的探针,不修改应用、不重启进程,就能观测进出每个进程的网络流量、库函数调用乃至系统调用。基于这一能力,零代码、跨语言、低开销的可观测性方案开始成为现实------OpenTelemetry eBPF Instrumentation(以下简称 OBI)就是 OpenTelemetry 社区给出的官方答案。
作为 OpenTelemetry 官方维护的开源项目,OBI 一句话概括它做的事情:利用 Linux 内核的 eBPF 技术,在不修改任何应用代码的前提下,自动拦截和分析进出应用的网络流量以及 GPU 操作,生成符合 OpenTelemetry 标准的 trace 和 metrics。
你可以把它想象成一个装在操作系统内核里的"透视镜"。无论你的应用使用 Go、Java、Python、Node.js 还是 .NET 编写,不管你用什么 HTTP 框架、连接什么数据库、调用哪家大模型------OBI 都能在内核和库函数层面拦截通信,解析协议语义,然后输出标准遥测数据。在 AI 可观测性方面OBI 已内置对 OpenAI、Anthropic、Google Gemini、Qwen(通义千问)四大 GenAI Provider 的协议级追踪,能自动识别 LLM 调用并从响应中提取 Tool Call 信息,同时支持 Rerank 和向量检索(Vector Retrieval)操作的追踪,覆盖 RAG 管线的核心环节。
支持 Linux amd64/arm64 架构,内核要求 5.8+(RHEL 系列可降至 4.18+)。部署方式灵活:可以作为独立进程运行、Docker 容器部署、Kubernetes DaemonSet 部署。
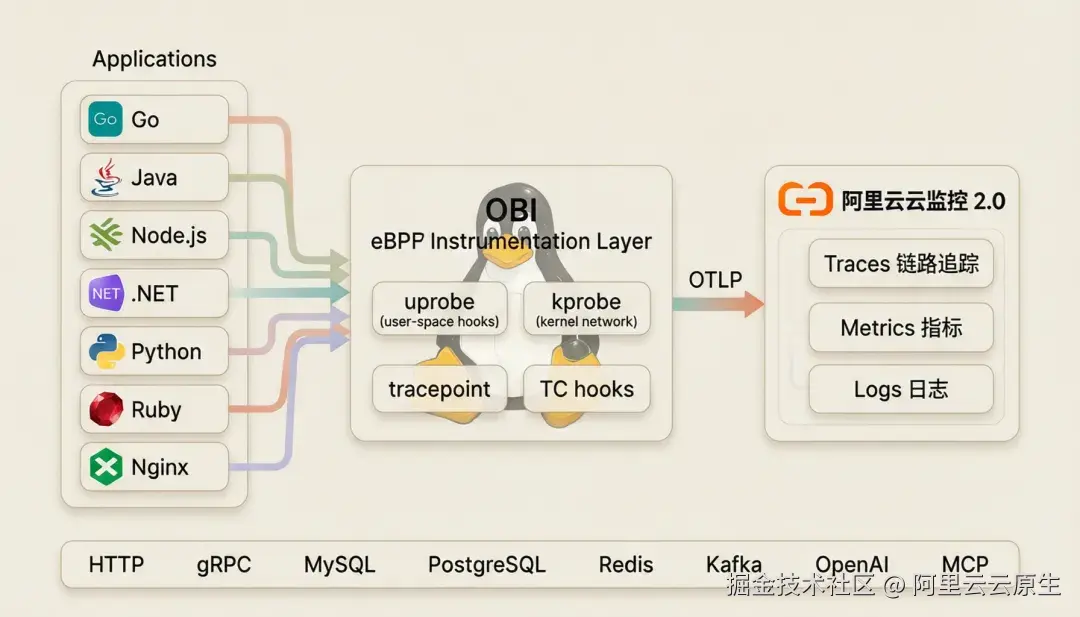
三大支柱:应用监控、网络监控和日志增强
OBI 的核心能力围绕三大可观测性支柱展开:
- 应用可观测性: 分布式追踪(Traces)+ RED Metrics,覆盖 Web、数据库、消息队列、GenAI、GPU 等 15+ 主流协议与场景,自动向 JSON 日志注入 trace_id/span_id,实现 Trace-Log 关联。
- 网络可观测性: L3/L4 网络流量监控,TCP/UDP 流量统计,支持 GeoIP、反向 DNS、CIDR 标注,TCP RTT 测量、TCP 连接失败统计,节点级全局指标。
- 日志增强: 语言无关地向 JSON 日志透明注入 trace_id 和 span_id,实现 Trace-Log 关联(详见后文"日志增强"章节)。
协议全景:从 HTTP 到 CUDA,一网打尽
OBI 的核心竞争力在于协议感知型探测------它不仅记录"有一个网络请求",而是深入理解每个请求的语义。以下是目前支持的完整协议矩阵:
Web 与 RPC
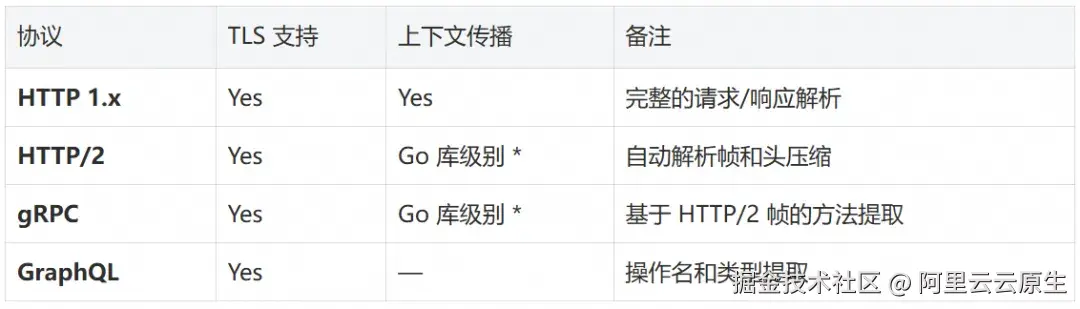
非 Go 语言的跨进程上下文传播通过内核态 tpinjector 的 HPACK 注入统一实现,详见"跨进程传播"章节。
数据库
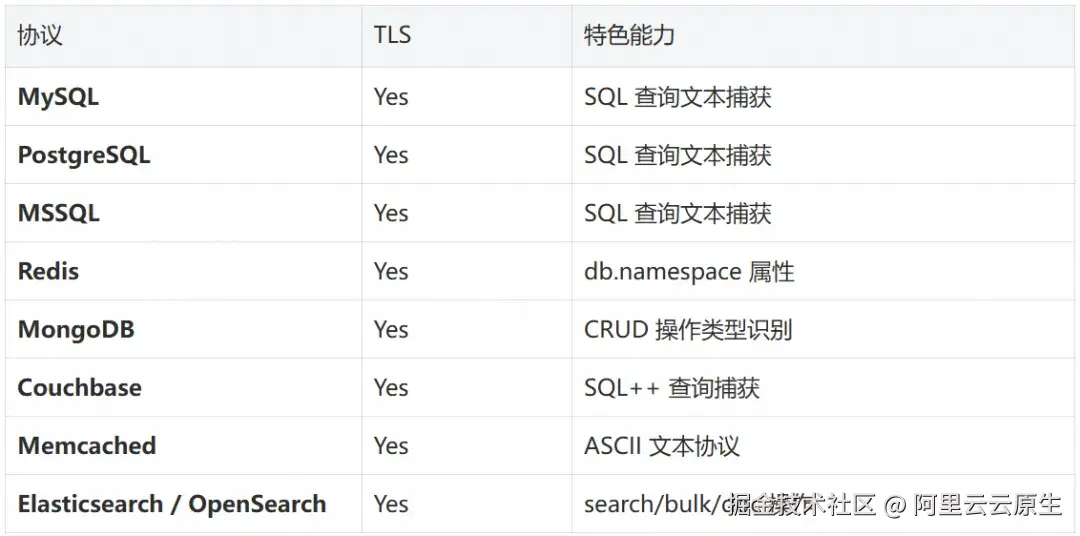
消息队列

协议是怎么被认出来的
OBI 怎么在不解密、不依赖端口约定的情况下判断一段 TCP payload 到底是 MySQL 还是 Redis?核心在 ReadTCPRequestIntoSpan(pkg/ebpf/common/tcp_detect_transform.go),是一个三级瀑布式匹配,按"确定性从高到低"依次尝试,命中即返回:
1. 内核已标注(最快): dispatchKernelAssignedProtocol,用户态直接 switch event.ProtocolType。内核常量(common.go):MySQL=1, Postgres=2, Kafka=4, MQTT=5, MSSQL=6, NATS=7, AMQP=8。SQL 分支用哨兵错误 errFallback(退回下一级)/ errIgnore(丢弃)做精细控制。
2. 确定性通用匹配: detectGenericProtocol,依次 matchSQL → matchFastCGI → matchMongo → matchCouchbase → matchMemcached。SQL 会先试请求缓冲、再试响应缓冲(命中响应时调 reverseTCPEvent 把方向纠正回来)。
3. 启发式兜底(最易误判,放最后): detectHeuristicProtocol,matchRedis → matchMemcached → matchHTTP2 → matchNATS → matchAMQP → matchMQTT → matchKafkaFallback。顺序本身就是 bug 经验的沉淀------例如 HTTP/2 必须排在 MQTT 之前,因为 MQTT 的启发式会误命中 HTTP/2 的连接前导(preface)。
几个值得关注的防误判细节:
- SQL:先用可打印 ASCII 前缀过滤(阈值 = len("SELECT 1"))再大小写无关搜关键字,最后 sqlprune.SQLParseOperationAndTable 提取操作与表名;validSQL 要求"有操作 + (明确 DB 类型 或 有表名)"才算数。
- Postgres:校验 5 字节消息头、类型字节 ∈ {Q,B,C} 且大端长度在 0..3000;还维护 prepared statement 与 portal 的 LRU 缓存还原参数化查询。
- HTTP/2 vs gRPC:先 isLikelyHTTP2 做 RFC 7540 逐帧合理性校验(帧长度上限取 1<<22 约 4MB 作为校验宽容值,注意 RFC 7540 默认帧大小为 2^14 即 16KB;flags 掩码),再看 content-type: application/grpc 或 grpc-status 头区分。
每种协议都有对应的 TCPTo<协议>ToSpan 构造器落成 request.Span。
语言深度集成:不止于网络层
OBI 的探测分为两个层次。第一层是语言无关的网络级追踪 ------任何语言的应用都能通过 TCP 流量拦截获得基本的 trace 和 metrics。第二层是运行时特定的深度集成------对特定语言和框架,OBI 通过 uprobe 直接挂钩库函数,实现更精确的上下文传播和 trace 关联。
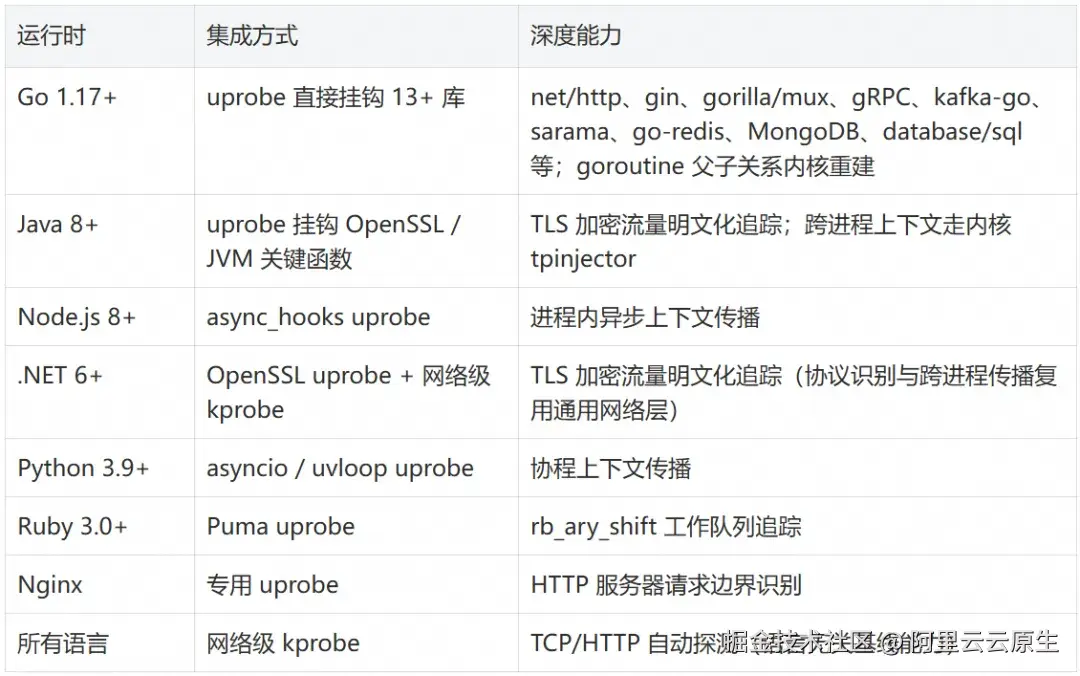
Go 没有 ThreadLocal,OBI 怎么串起一次调用?
Go 的 goroutine 会在 OS 线程间漂移,传统 APM 的线程本地存储完全失效。OBI 的解法是在内核里重建 goroutine 的父子血缘 (bpf/gotracer/go_runtime.c + go_common.h):挂钩 runtime.newproc1 记录谁创建了谁并写入 LRU ongoing_goroutines;一次出站调用要找所属入站请求时,find_parent_goroutine 沿父链向上回溯最多 6 层 (深嵌套是为了兼容 franz-go 这类 Kafka 客户端);再挂 runtime.casgstatus 跟踪状态切换把 OBI 上下文绑定到 goroutine,使同一 OS 线程上的 kprobe 能正确关联。
Python asyncio 单线程多路复用,OBI 怎么区分并发请求?
Python 的 asyncio 事件循环在同一个 OS 线程上交替执行成百上千个协程(Task),传统的"一个线程对应一个请求"假设彻底失效。更麻烦的是 asyncio.to_thread() 会把工作投递到线程池------这些 worker 线程上根本没有 asyncio.Task 身份。OBI 的解法是在内核里追踪 CPython 的 Task 和 Context 对象,重建协程的父子归属关系。
核心由四组 uprobe 构成(bpf/generictracer/python.c):task_step 追踪事件循环切换到哪个 Task;_asyncio_Task___init__ 在 Task 创建时记录父子关系并继承请求连接;PyContext_CopyCurrent 在 Context 被复制时(create_task 或 to_thread 都会触发)将副本绑定到对应 Task;context_run 在 worker 线程激活 Context 时恢复 Task 身份。三张 BPF Map(python_thread_state / python_task_state / python_context_task)协同工作,覆盖 await、create_task、gather 和 to_thread 四种并发模式。
父链回溯机制(find_python_owning_server_trace)与 Go 类似:从当前 Task 沿 parent 指针向上最多走 4 层,直到找到持有入站请求连接(server_traces_aux)的祖先 Task,即可关联到正确的 server span。Task 地址复用问题则靠版本计数器解决------每次 Task 初始化时 version 自增,Context 绑定时快照 version,查找时比对不一致即判定过期。
整套方案锚定在 CPython _asyncio 和 libpython 符号上,不依赖 uvloop 内部实现。uvloop 只是替换了事件循环的 I/O 驱动,asyncio.Task 和 contextvars 的语义不变------因此同一组探针对 asyncio 和 uvloop 均有效,无需额外适配。
跨进程传播对非 Go 语言是内核态统一完成的
前文的语言运行时表格容易给人一种印象:跨进程上下文传播是各语言运行时各自实现的。更准确的表述是:进程内上下文传播确实是各语言专属(Go goroutine 回溯、Node async_hooks、Python asyncio、Ruby Puma 队列、Java/.NET 通过 OpenSSL/JVM uprobe 追踪);但跨进程的 traceparent 传播对所有非 Go 语言是统一在内核态由 tpinjector 完成的(pkg/internal/ebpf/tpinjector + bpf/tpinjector/*.c),三种手法:
- HTTP/1 头注入:
sk_msg程序通过尾调用链改写 payload,插入Traceparent: 头;SSL socket 直接跳过(密文改不了)。 - HTTP/2 HPACK 注入: 按流注入 HPACK 编码的
traceparent,用 huffman 指纹0x3fa9851d6b21834d识别已有头。 - TCP Option 传播(自定义 TCP 选项): 选项 kind=25。出站在
WRITE_HDR_OPT回调里bpf_store_hdr_opt写入 trace_id/span_id;入站在PARSE_ALL_HDR_OPT里bpf_load_hdr_opt取出,写进incoming_trace_map(按归一化connection_info_t为 key),供服务端server_trace_parent消费后删除。启动时sock_iter.c 还会把已建立的长连接灌进 sockhash,让旧连接也能被注入。
部署注意:TCP Option kind=25 属于 IANA 未分配编号,部分防火墙、负载均衡器和云平台中间盒可能剥离未知 TCP 选项,导致传播静默失效。建议在目标网络环境中验证 TCP 选项的透传能力,或优先使用 HTTP 头注入方式(OTEL_EBPF_BPF_CONTEXT_PROPAGATION=headers)。
由 OTEL_EBPF_BPF_CONTEXT_PROPAGATION 控制:headers / tcp / all / disabled,finder.go 据此决定是否加载注入器。
一条 Span 的完整生命周期(数据管线与架构)
内核中抓到的一个字节流,是怎么变成云监控 2.0 中那条 trace 的?这恰恰是 OBI 最硬核的工程部分。OBI 的用户态不是一个大循环,而是一张显式声明、分阶段、可插拔的有向图(DAG)。
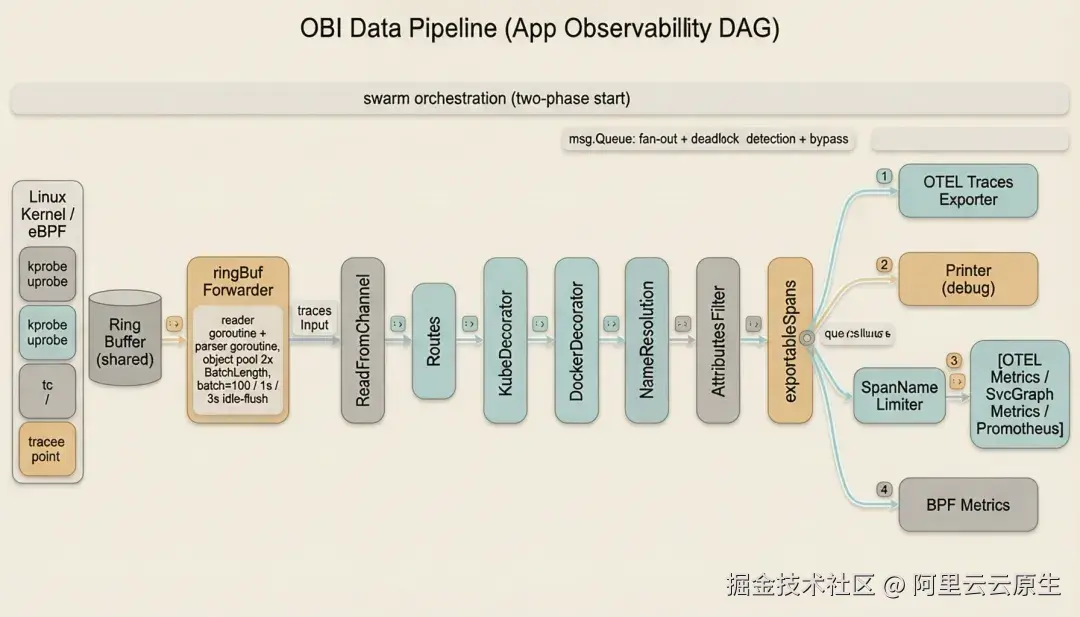
顶层骨架:三条独立 Agent + errgroup
入口 RunWithContextInfo(pkg/instrumenter/instrumenter.go)按 Feature Flag 把三大支柱拆成三个互相独立的 goroutine,用 errgroup 绑定------任意一条挂掉,其余两条随 context 取消一起优雅退出。应用可观测这条线又分三步(pkg/internal/appolly/appolly.go):FindAndInstrument(发现并挂探针)→ ReadAndForward(启动处理管线)→ WaitUntilFinished。
管线编排框架:swarm(两阶段启动)
OBI 自研了一套极简的节点编排框架 pkg/pipe/swarm,核心是"先全部实例化、再统一运行"的两阶段语义。
第一阶段 Instancer.Instance(ctx) 依次调用每个节点的 InstanceFunc------只要有一个初始化失败就立即取消并整体返回 error,一个 RunFunc 都不会启动,避免"半启动"残缺状态。第二阶段 Runner.Start(ctx) 为每个节点拉 goroutine,可配 WithCancelTimeout------context 取消后若某节点超时未退出,Done() 会返回 CancelTimeoutError 并点名是哪个僵尸节点。
节点间通信:msg.Queue(带死锁探测的扇出队列)
节点之间不直接调用,而是通过泛型队列 msg.Queue[T](pkg/pipe/msg/queue.go)传递:
- 扇出(fan-out): 一个队列可被多个下游 Subscribe,SendCtx 把同一条消息投递给所有订阅者;无订阅者时直接丢弃、不会阻塞发送方。
- Bypass(零成本短路): 某分支被配置关闭时,
input.Bypass(output)把上游订阅者直接接管给下游,被禁用的节点不是空跑,而是从图里物理消失。 - 死锁自检:
SendCtx内置sendTimeout定时器(默认 1 分钟),某订阅者 channel 写阻塞超时就告警,PanicOnSendTimeout模式下直接 panic 并打印 A->B->C 路径。 - 多生产者关闭:
ClosingAttempts(n)+MarkCloseable()引用计数,所有生产者都标记可关闭后才真正 close。
应用可观测的完整 DAG
pkg/internal/appolly/instrumenter.go 的 Build() 把整条图显式拼出来:
rust
[per-process eBPF tracers]
| (各进程共享 Ring Buffer)
v
ringBufForwarder (reader goroutine + parser goroutine, 对象池 2x BatchLength)
| tracesInput (批量=100 / 1s / 3s idle-flush)
v
ReadFromChannel -> Routes -> KubeDecorator -> DockerDecorator -> NameResolution -> AttributesFilter
|
v exportableSpans ===== 扇出 fan-out =====
|-- OTEL Traces Exporter
|-- Printer (debug)
|-- SpanNameLimiter -> [OTEL Metrics | SvcGraph Metrics | Prometheus]
`-- BPF Metrics两个工程设计要点:(1)指标子管线按需启动------只有确实配了指标出口才 setupMetricsSubPipeline;(2)K8s 装饰器的特殊超时------routerToKubeDecorator 队列取 max(InformersSyncTimeout, ChannelSendTimeout),因为启动时要先拉全量 informer 快照,不能被默认死锁探测误杀。
内核→用户态的搬运:双 goroutine + 对象池的 ringbuf 转发器
这是整条管线的进水口,也是性能最敏感的地方(pkg/ebpf/common/ringbuf.go,泛型 ringBufForwarder[T],App 侧 T=Span、Stats 侧 T=Record 复用同一套代码):
- 读/解析分离的生产者-消费者:
readerLoop只负责ReadInto原始 record,parserLoop负责解析成 Span,二者通过freeIdx/workIdx两个 channel 传递槽位下标。 - 对象池避免 GC 抖动:预分配
poolSize = 2 * BatchLength个 record 复用(一批给 parser、一批让 reader 并发填充)。 - 批量提交 + 超时兜底:攒够 BatchLength(默认 100)就 flush;攒不够由 BatchTimeout(默认 1s)ticker 兜底;另有 flushOnAvailableBytes 每 3s 检查 ringbuf 残留字节主动 Flush,防止低流量下数据卡在内核。
- 共享 ringbuf:成百上千个被探测进程共用一个
SharedRingBuffer,退出时上千个 closer 并发Close()。
当任一内部队列阻塞,OBI 会主动提示调优旋钮全集:OTEL_EBPF_OTLP_TRACES_BATCH_MAX_SIZE、OTEL_EBPF_OTLP_TRACES_QUEUE_SIZE、OTEL_EBPF_CHANNEL_BUFFER_LEN、OTEL_EBPF_CHANNEL_SEND_TIMEOUT、OTEL_EBPF_BPF_BATCH_LENGTH、OTEL_EBPF_BPF_BATCH_TIMEOUT。
一句话总结: OBI = 一个 swarm 编排的 DAG + 一组带死锁探测的扇出队列 + 一个双 goroutine 对象池 ringbuf 转发器;启动要么全成功要么全回滚,关闭可定位僵尸节点,禁用的功能从图里物理消失。
GPU/CUDA 追踪:覆盖 kernel launch 与显存操作
除了网络协议层面的深度探测,OBI 还将可观测能力延伸到了 GPU 计算领域。通过 uprobe 挂钩 libcuda.so,它能追踪 NVIDIA CUDA 的核心操作------kernel launch、graph launch、内存分配和内存拷贝。这对于运行 AI 训练/推理任务的 GPU 集群来说非常有价值。
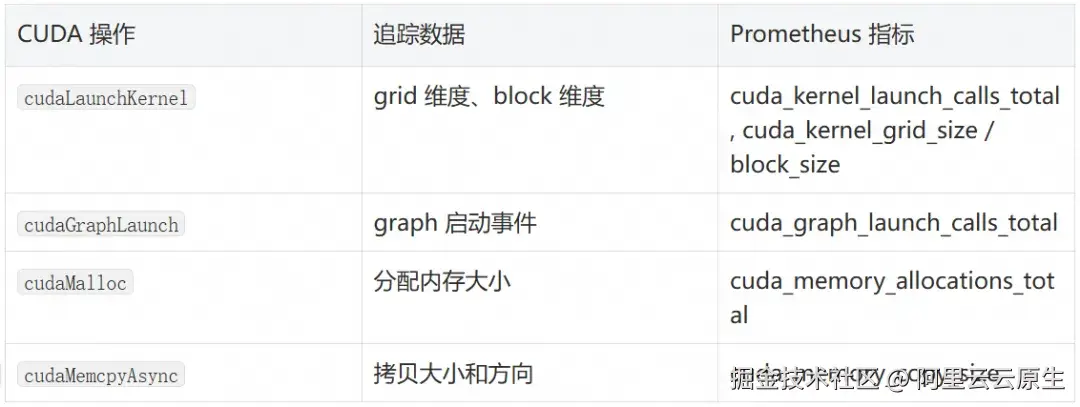
GPU 追踪的配置非常简单:OTEL_EBPF_CUDA_MODE=auto 会自动检测系统是否有 CUDA 库并开启追踪。
GPU 追踪走的是 uprobe 挂钩 libcuda.so + 独立 ring buffer(内核侧 bpf/gpuevent,用户态 pkg/internal/ebpf/gpuevent)。值得点出的工程细节是:CUDA 事件经由与网络 Span 同一套泛型转发器 ringBufForwarder[T](pkg/ebpf/common/ringbuf.go)进入处理管线,因此天然共享相同的批量提交、背压控制与优雅关闭机制,无需为 GPU 单独维护一条搬运逻辑。这也解释了为什么 OTEL_EBPF_CUDA_MODE=auto 能做到零额外配置接入------它本质上只是往既有的处理 DAG 上多挂了一个数据源。
网络层观测:流量、关联与质量
除了应用级的分布式追踪,OBI 还提供了网络级的可观测能力。
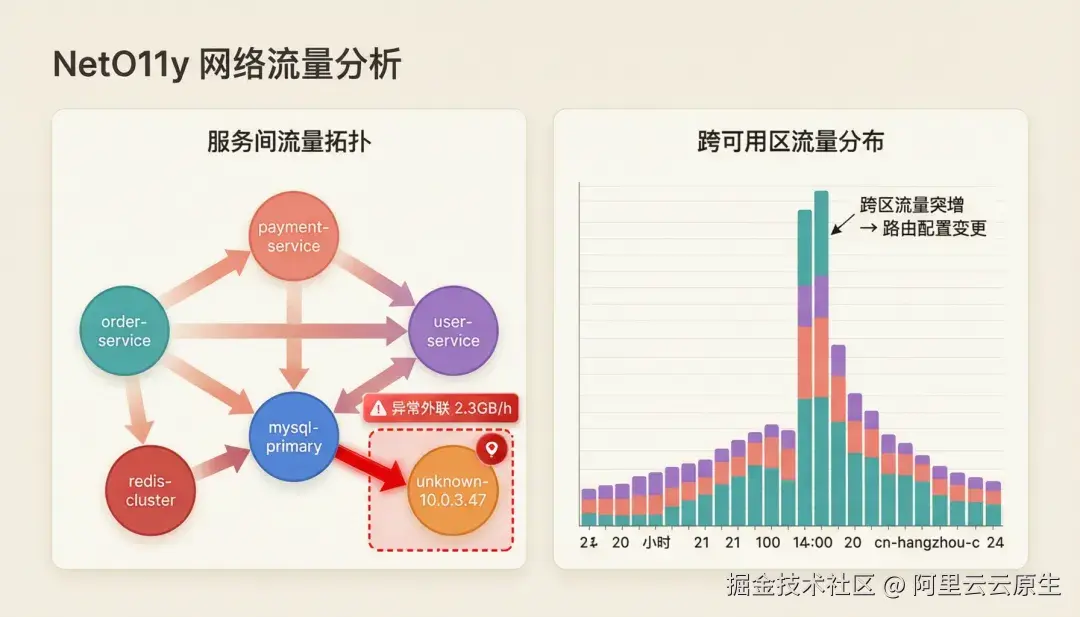
网络流量监控 (NetO11y)
基于 TC(Traffic Control)钩子捕获 L3/L4 网络包,解析 IPv4/IPv6 和 TCP/UDP 头部,生成网络流量指标。数据管线支持丰富的装饰能力------Kubernetes 元数据、反向 DNS、GeoIP 地理定位、自定义 CIDR 范围标注。适合用于集群内及集群间流量分析、网络拓扑可视化和安全审计。
典型定位场景:
- 异常外联发现(安全审计): 服务拓扑中突然出现一个未知 IP 与数据库之间有大量数据传输(如 2.3GB/h),结合 rDNS 反查和 GeoIP 定位发现目标在境外------立即触发安全告警。
- 跨可用区流量突增定位: 某时段跨可用区流量突然翻倍增长,按 CIDR 标注聚合后发现是某个服务的路由配置变更导致所有请求绕行到另一个 AZ------修复后带宽成本回落。
- 服务依赖发现: 无需任何配置,自动生成全集群服务间流量拓扑------当某个服务异常时,立即看到它上下游的全部网络关系和流量变化。
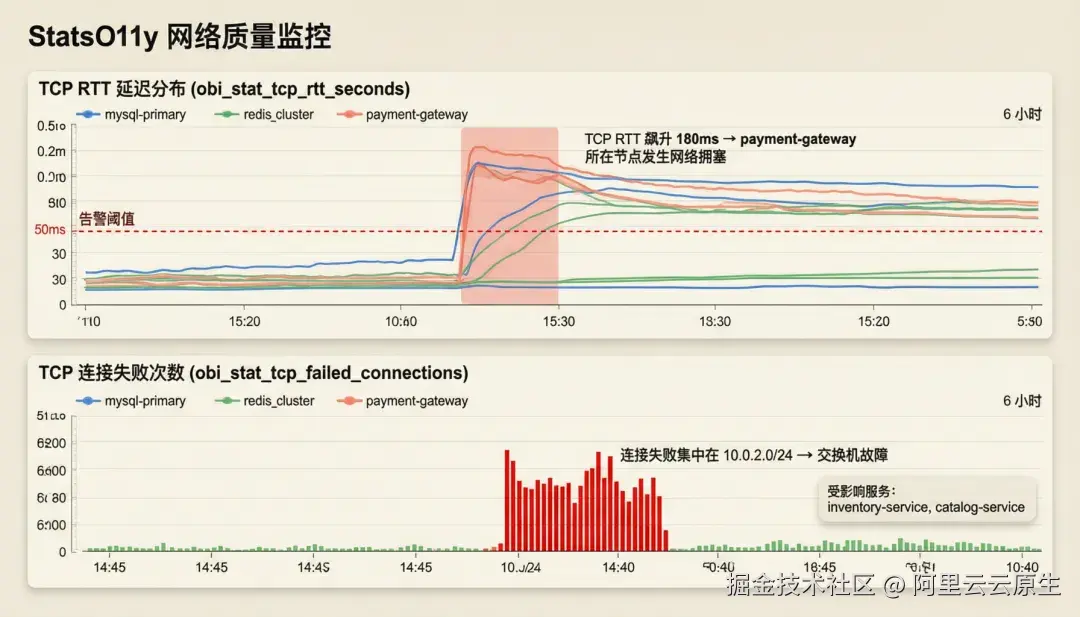
统计指标 (StatsO11y)
通过 kprobe/tracepoint 采集节点级的 TCP RTT(obi_stat_tcp_rtt_seconds)和 TCP 连接失败次数(obi_stat_tcp_failed_connections),帮助你监控底层网络质量。
典型定位场景:
- 网络拥塞快速定界: 某服务响应变慢,TCP RTT 从 2ms 飙升到 180ms------无需逐层排查,直接看 RTT 指标按目标 IP 聚合,1 分钟定位到是 payment-gateway 节点所在交换机拥塞。
- 交换机/网段故障定位: TCP 连接失败数突然集中爆发在 10.0.2.0/24 网段,而其他网段正常------立即推断该网段交换机或路由存在问题,通知网络团队介入。
日志增强:内核拦截+透明注入 trace_id
OBI 的日志增强(Log Enrichment)是语言无关的能力------无论应用用什么语言、什么日志框架,只要它往 stdout/stderr 或 pipe 写 JSON 格式的日志,OBI 就能在内核层面拦截并透明地注入 trace_id 和 span_id。应用代码零修改,日志文件里就自动多出 Trace 关联字段。
实现原理(bpf/logenricher/logenricher.c):通过 kprobe 挂钩 tty_write(终端输出)和 pipe_write(管道输出,覆盖 docker logs / kubectl logs 场景)两个内核函数。当被监控进程的写操作触发时,BPF 程序从用户态缓冲区读取原始日志内容(最大 8KB),同时通过 obi_ctx 获取当前线程/协程的 trace context,然后用 bpf_probe_write_user 将原始日志擦除(用零字节填充),并将事件经 ringbuf 送往用户态。
已知限制:bpf_probe_write_user 直接修改用户态内存,存在两个需关注的风险:(1)从内核擦零到用户态写回之间存在时间窗口,若此期间进程崩溃或日志采集器恰好读取了输出,可能出现日志丢失或空白行;(2)部分安全加固内核(如启用 Lockdown 模式)会禁用该函数,部署前需确认内核配置允许此操作。
用户态处理器(pkg/internal/ebpf/logenricher)接收事件后:尝试将日志行解析为 JSON------若成功,向对象中注入 trace_id 和 span_id 字段(已有则不覆盖),序列化后写回应用的原始输出路径(TTY pts 或 pipe fd);若非 JSON 则原样写回不动。写回路径通过 path_resolver 从内核 file->f_path 解析(TTY 场景)或从 /proc//fd/ 定位(pipe 场景),并用 LRU 缓存避免反复 open。
几个工程亮点:内核侧通过 ksys_write / do_writev kprobe 预记录当前 fd,pipe_write 触发时即可关联到正确的管道;异步写入器(ShardedQueue)按文件路径分片,同一文件的写入严格串行保证日志行序;若应用已自带 OTel SDK 导出 Traces(ExportsOTelTraces),则只注 trace_id 不注 span_id,避免与应用自身的 span 冲突。
在云监控 2.0 中使用 OBI(OpenTelemetry 无侵入监控)
阿里云云监控 2.0(CMS 2.0)是面向云原生时代重构的统一可观测平台,原生基于 OpenTelemetry 协议构建,将 Metrics、Traces、Logs、Profiles、Events 五类信号收敛到同一套数据模型与查询入口下,并与 ARMS、Prometheus、SLS、Grafana 等能力打通,支持云上云下、自建与托管混合接入,解决了过去监控、APM、日志、追踪四套系统各自为政、数据无法关联的问题。OBI 解决了"如何让存量与异构应用零成本接入这个底座"的最后一公里------尤其适合多语言混部、老系统改造受限、以及对生产环境侵入性敏感的场景。
一键接入
通过云监控 2.0 接入中心,选择 OpenTelemetry 无侵入监控,选择集群一键接入 ** **1 。
应用详情
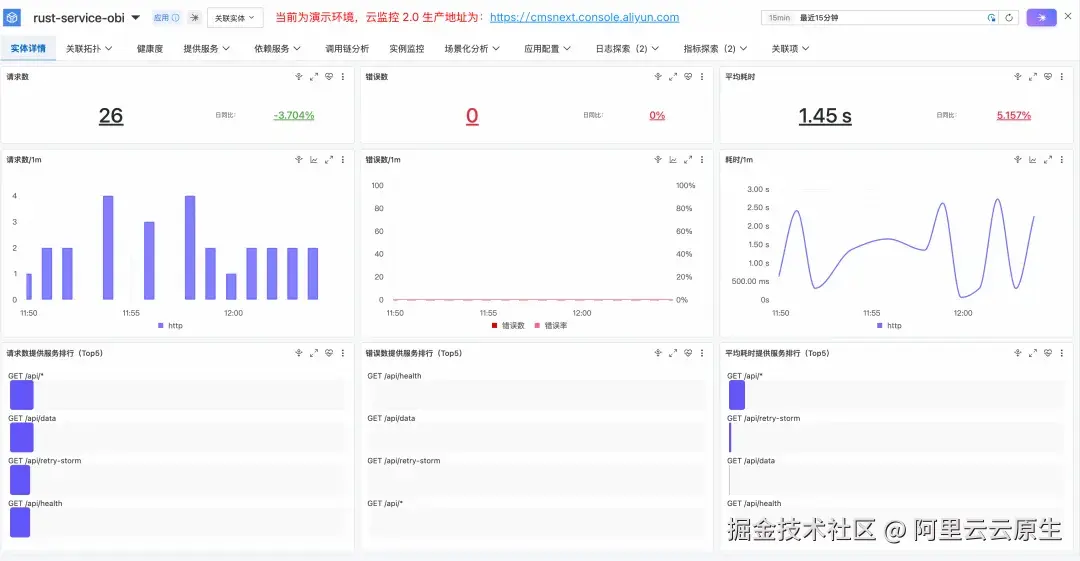
接入后,你可以看到应用的请求数、错误数和耗时,以及接口的调用详情。
调用链分析
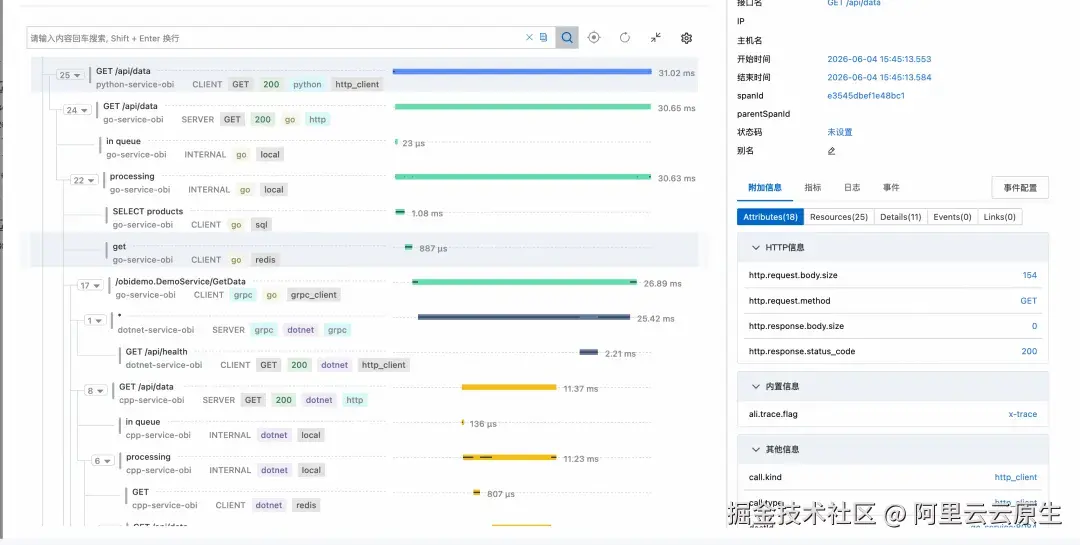
在调用链分析可以看到完整的 Trace 链路,让问题一目了然。
网络监控
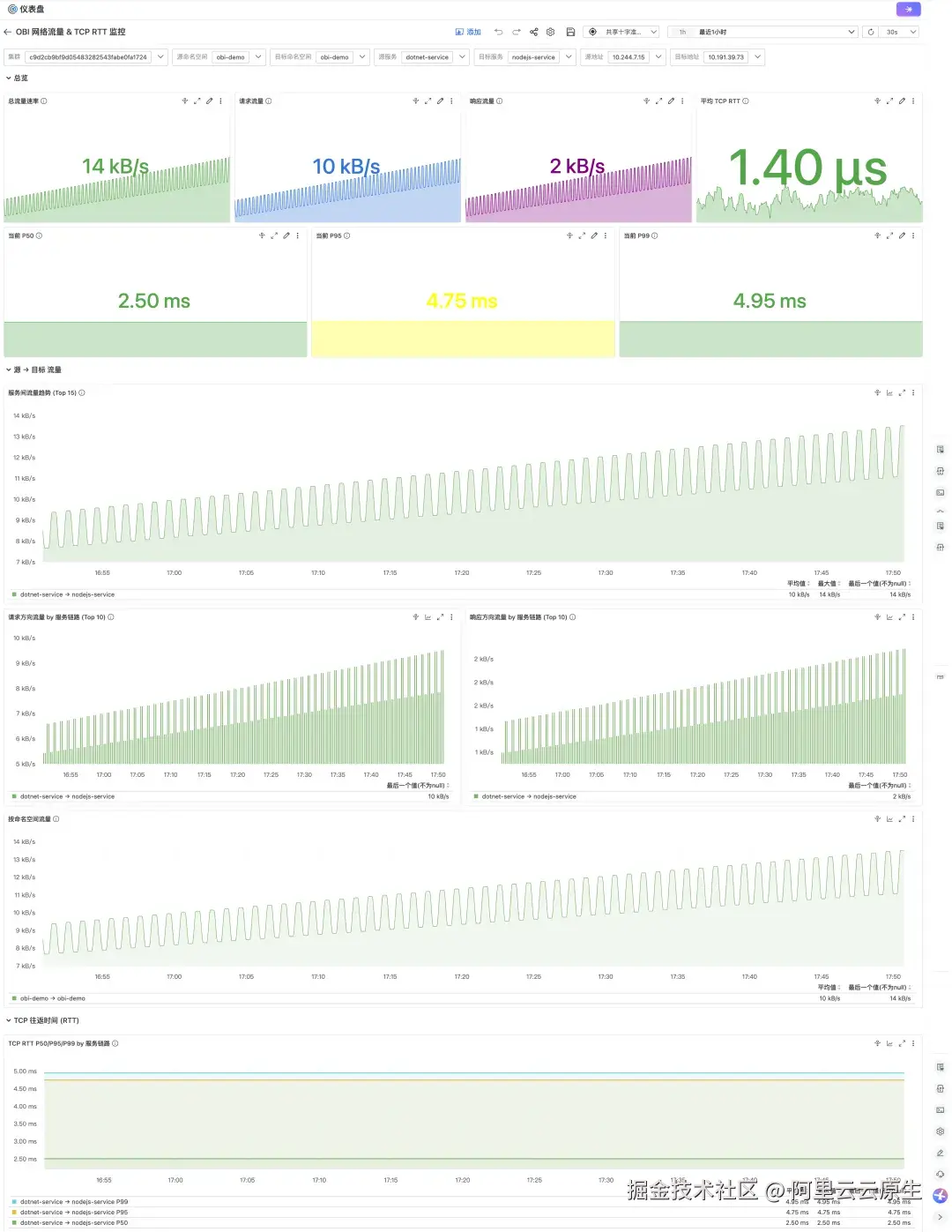
以"源服务→目标服务"链路为核心视角,实时展示 K8s 集群中微服务间的网络流量速率与 TCP 往返时延(P50/P95/P99),用于网络质量巡检、延迟异常定位和流量分布分析。
为了更好的使用 OBI 的能力,通过云监控 2.0 的接入中心可以实现一键的接入,接下来我们将逐步补充 AI Agent 可观测能力 ** **2 、更多的网络监控能力到 OBI 中,欢迎大家一起共建。
相关链接:
1 云监控 2.0 接入中心