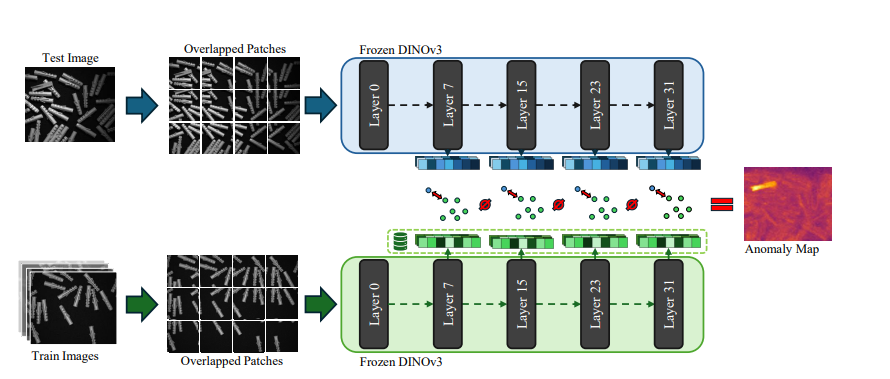
SuperADD 是一个 training-free、class-agnostic 的异常分割管线。这里的 "training-free" 不是完全没有准备阶段,而是不更新神经网络权重:DINOv3 作为冻结特征提取器,正常训练图像只用来构建 memory bank;推理时,图像 patch token 到正常原型库的最近邻距离就是异常分数。
它是 SuperAD 的增强版,主要改动集中在五处:
- 用 DINOv3 替换原先的 DINOv2 特征骨干,利用更强的 dense feature。
- 用 重叠 patch 处理高分辨率图像,缓解边界割裂和显存压力。
- 在建库阶段加入 亮度增强,主动模拟现场光照变化。
- 用 距离感知的 memory bank 子采样,让保留下来的正常原型覆盖更均匀。
- 用 多方向形态学闭运算 清理异常图,让分割结果更连贯。
数学建模:SuperADD 到底在优化什么
先把问题写清楚。给定某个工业类别的正常训练集:
X train = { x i } i = 1 N , x i ∈ 0 , 1 3 × H i × W i \mathcal{X}{\text{train}}=\{x_i\}{i=1}^{N}, \quad x_i \in 0,1^{3\times H_i\times W_i} Xtrain={xi}i=1N,xi∈0,13×Hi×Wi
目标是在测试图像 x x x 上输出像素级异常分数图 A ( x ) ∈ R h × w A(x)\in \mathbb{R}^{h\times w} A(x)∈Rh×w,以及二值异常掩码 B ( x ) ∈ { 0 , 1 } h × w B(x)\in\{0,1\}^{h\times w} B(x)∈{0,1}h×w。核心约束是:训练集中没有异常样本,也不训练新的神经网络参数。
SuperADD 的实质是一个 冻结特征空间中的非参数密度估计 。如果某个测试局部特征 q q q 位于正常特征流形 M normal \mathcal{M}_{\text{normal}} Mnormal 附近,则它到正常 memory bank 的最近邻距离应较小;反之,距离大就表示"这个局部不像正常样本"。
形式上,设冻结的 DINOv3 backbone 为:
F θ ( x ) = { F θ ( l ) ( x ) ∣ l ∈ L } , θ frozen F_\theta(x)=\{F_\theta^{(l)}(x)\mid l\in\mathcal{L}\}, \quad \theta \text{ frozen} Fθ(x)={Fθ(l)(x)∣l∈L},θ frozen
SuperADD 默认选择:
L = { 7 , 15 , 23 , 31 } \mathcal{L}=\{7,15,23,31\} L={7,15,23,31}
第 l l l 层输出 token 特征:
F θ ( l ) ( x ) = Z ( l ) ∈ R H l × W l × C l F_\theta^{(l)}(x)=Z^{(l)}\in\mathbb{R}^{H_l\times W_l\times C_l} Fθ(l)(x)=Z(l)∈RHl×Wl×Cl
每个空间位置 ( u , v ) (u,v) (u,v) 的 token 记为:
z u , v ( l ) ∈ R C l z_{u,v}^{(l)}\in\mathbb{R}^{C_l} zu,v(l)∈RCl
对正常训练集抽取所有 token 后,第 l l l 层的候选正常特征集合为:
P ( l ) = { z i , u , v ( l ) ∣ x i ∈ X proto , 1 ≤ u ≤ H l , 1 ≤ v ≤ W l } \mathcal{P}^{(l)}= \left\{ z_{i,u,v}^{(l)} \mid x_i\in\mathcal{X}_{\text{proto}},\, 1\le u\le H_l,\, 1\le v\le W_l \right\} P(l)={zi,u,v(l)∣xi∈Xproto,1≤u≤Hl,1≤v≤Wl}
这里 X proto \mathcal{X}_{\text{proto}} Xproto 是用于建库的正常图像子集。最终 memory bank 是候选集合的子集:
B ( l ) ⊂ P ( l ) , ∣ B ( l ) ∣ ≤ M \mathcal{B}^{(l)} \subset \mathcal{P}^{(l)}, \quad |\mathcal{B}^{(l)}|\le M B(l)⊂P(l),∣B(l)∣≤M
代码默认 M = 100000 M=100000 M=100000。推理时,第 l l l 层某个 token 的异常分数为最近邻距离:
d ( l ) ( q ) = 1 C l min b ∈ B ( l ) ∥ q − b ∥ 2 d^{(l)}(q)= \frac{1}{C_l} \min_{b\in\mathcal{B}^{(l)}}\|q-b\|_2 d(l)(q)=Cl1b∈B(l)min∥q−b∥2
除以 C l C_l Cl 是为了削弱不同层特征维度差异带来的尺度影响。整张图的第 l l l 层异常图为:
D ( l ) ( x ) u , v = d ( l ) ( z u , v ( l ) ) D^{(l)}(x)u,v=d^{(l)}(z_{u,v}^{(l)}) D(l)(x)u,v=d(l)(zu,v(l))
不同层的 token 网格大小可能相同但语义不同;SuperADD 将它们插值到统一输出分辨率 Ω \Omega Ω,再平均融合:
A ( x ) = 1 ∣ L ∣ ∑ l ∈ L Resize Ω ( D ( l ) ( x ) ) A(x)= \frac{1}{|\mathcal{L}|} \sum_{l\in\mathcal{L}} \operatorname{Resize}_{\Omega} \left(D^{(l)}(x)\right) A(x)=∣L∣1l∈L∑ResizeΩ(D(l)(x))
这就是 SuperADD 的核心异常热力图。
为什么它适合工业场景
MVTec AD 2 这类新基准故意把问题变难:高分辨率图像、透明或重叠物体、暗场/背光照明、正常样本内部差异大,以及非常小的缺陷。真实产线也一样,异常样本稀缺且类型不可穷举,拿"正常样本"建模通常比收集每种缺陷更现实。
SuperADD 的取舍很直接:不要让模型学习一个类别专属分类边界,而是把正常样本的局部视觉模式存下来。测试图像的某个局部如果找不到相似的正常模式,就把它标成可疑区域。
算法流程
1. 正常图像预处理
输入是正常训练图像。代码中的预处理包括三步:
- 亮度随机缩放,默认范围是
0.8到1.2。 - resize,默认
patch_size / 1024,配置里patch_size = 640,因此相当于缩放到原尺寸的0.625。 - 使用 ImageNet 的均值和方差归一化。
亮度增强只用于构建原型库,不用于常规推理。它的作用很朴素:如果产线灯光明暗会变,那正常库里也应该见过类似变化。
可以写成:
x ~ = Norm ( Resize ( clip ( α x , 0 , 1 ) ) ) , α ∼ U ( 0.8 , 1.2 ) \tilde{x}=\operatorname{Norm}\left(\operatorname{Resize}\left(\operatorname{clip}(\alpha x,0,1)\right)\right), \quad \alpha\sim\mathcal{U}(0.8,1.2) x~=Norm(Resize(clip(αx,0,1))),α∼U(0.8,1.2)
其中 α \alpha α 只在建库阶段采样。这个增强不是为了训练网络,而是为了扩展正常特征库的覆盖域:
M normal → M normal illumination \mathcal{M}{\text{normal}} \rightarrow \mathcal{M}{\text{normal}}^{\text{illumination}} Mnormal→Mnormalillumination
换句话说,SuperADD 把光照扰动提前"写入" memory bank,而不是期望阈值在测试时硬扛分布偏移。
2. 重叠切块,送入 DINOv3
SuperADD 默认用 dinov3_vith16plus,读取第 7, 15, 23, 31 层的中间特征。由于工业图像常常很大,算法不会整张图一次塞进骨干网络,而是切成 640 × 640 的 patch,相邻 patch 有 128 像素重叠。
重叠区域不是简单拼回去。代码会为每个 patch 计算一个"有效预测区域",把 patch 边缘容易不稳定的部分裁掉,再拼成完整 token 网格。这个设计对缺陷分割很重要,因为异常通常很小,边界伪影会直接污染热力图。
设 patch 边长为 P P P,重叠宽度为 O O O,DINOv3 的 token patch size 为 s s s。配置中:
P = 640 , O = 128 , s = 16 P=640,\quad O=128,\quad s=16 P=640,O=128,s=16
因此单个输入 patch 对应的 token 网格边长为:
T = P s = 40 T=\frac{P}{s}=40 T=sP=40
重叠区域在 token 空间中宽度为:
T O = O s = 8 T_O=\frac{O}{s}=8 TO=sO=8
假设某一维图像缩放后的长度为 L L L,token 长度为 L t = ⌊ L / s ⌋ L_t=\lfloor L/s\rfloor Lt=⌊L/s⌋。SuperADD 的切块数近似为:
n = ⌈ L t − T T − 2 T O ⌉ + 1 n= \left\lceil \frac{L_t-T}{T-2T_O} \right\rceil + 1 n=⌈T−2TOLt−T⌉+1
这里分母是每次移动后"真正新增"的 token 数。由于左右各有一段重叠,步长不是 T − T O T-T_O T−TO,而是 T − 2 T O T-2T_O T−2TO。这能让中间区域由稳定的 patch 中心预测,减少边界 token 的影响。
3. 为每个层级建立正常原型库
DINOv3 输出的是 patch token 特征。对每个被选中的中间层,SuperADD 把所有正常训练图像的 token 展平成向量集合:
text
正常图像 -> DINOv3 layer l -> token features -> memory bank_l如果全量保存,库会非常大,所以 SuperADD 做了子采样。它不是完全随机抽样,而是先估计局部密度:某个特征周围邻居越多,说明它处在常见区域,被保留的概率就越低;稀疏区域的样本更容易留下来。这样可以在最多 100000 个原型的预算内,让正常外观覆盖更广。
更具体一点,给定候选特征 p i ∈ P ( l ) p_i\in\mathcal{P}^{(l)} pi∈P(l),先计算其 K K K 近邻距离集合:
N K ( p i ) = KNN ( p i , P ( l ) ) \mathcal{N}_K(p_i)= \operatorname{KNN}(p_i,\mathcal{P}^{(l)}) NK(pi)=KNN(pi,P(l))
代码中默认 knn_neighbors = 100。再用一个逐渐增大的距离尺度 τ \tau τ 估计局部拥挤度:
ρ i ( τ ) = 1 + ∑ p j ∈ N K ( p i ) 1 ∥ p i − p j ∥ 2 \< τ \rho_i(\tau)= 1+ \sum_{p_j\in\mathcal{N}_K(p_i)} \mathbf{1}\left\\\|p_i-p_j\\\|_2\<\\tau\\right ρi(τ)=1+pj∈NK(pi)∑1∥pi−pj∥2\<τ
保留概率近似为:
Pr ( p i kept ) = 1 ρ i ( τ ) \Pr(p_i\ \text{kept})= \frac{1}{\rho_i(\tau)} Pr(pi kept)=ρi(τ)1
这意味着密集区域的样本会被强烈压缩,而稀疏区域更容易保留。 τ \tau τ 会逐步乘以 1.1,直到保留下来的样本数量不超过目标上限 M M M。这不是严格的 k-center 或 coreset 优化,但它抓住了一个很实用的目标:
min B ( l ) , ∣ B ( l ) ∣ ≤ M max p ∈ P ( l ) min b ∈ B ( l ) ∥ p − b ∥ 2 \min_{\mathcal{B}^{(l)}, |\mathcal{B}^{(l)}|\le M} \max_{p\in\mathcal{P}^{(l)}} \min_{b\in\mathcal{B}^{(l)}}\|p-b\|_2 B(l),∣B(l)∣≤Mminp∈P(l)maxb∈B(l)min∥p−b∥2
也就是尽量让 memory bank 覆盖正常特征空间,而不是被最常见纹理"刷屏"。
4. 自动阈值校准
训练图像被分成两部分:大多数用于建库,每隔 threshold_fraction = 8 张取一张用于阈值校准。校准图像也是正常图像,因此它们的异常分数代表"正常情况下的高分边界"。
代码中的阈值公式可以概括为:
text
threshold = percentile(anomaly_maps_on_normal_images, 95) × 1.421这一步让算法不用人工为每个类别找阈值,同时又给正常波动留出余量。
设阈值校准集为 X thr \mathcal{X}_{\text{thr}} Xthr,对其中所有像素位置的异常分数做集合:
S normal = { A ( x ) u , v ∣ x ∈ X thr , ( u , v ) ∈ Ω } \mathcal{S}{\text{normal}}= \left\{ A(x)u,v \mid x\in\mathcal{X}{\text{thr}},\, (u,v)\in\Omega \right\} Snormal={A(x)u,v∣x∈Xthr,(u,v)∈Ω}
SuperADD 的阈值 Q 0.95 Q_{0.95} Q0.95 是 95 分位数,代码默认 λ = 1.421 \lambda=1.421 λ=1.421。二值化初始掩码为:
B 0 ( x ) u , v = 1 A ( x ) \[ u , v > γ ] B_0(x)u,v= \mathbf{1}\leftA(x)\[u,v>\gamma\right] B0(x)u,v=1A(x)\[u,v>γ]
这个阈值策略的含义是:允许 95% 的正常像素分数落在阈值以下,并额外乘一个安全系数。它牺牲了一些极弱缺陷的召回,换取跨类别、跨光照的误报稳定性。
5. 推理:最近邻距离就是异常分数
测试时,图像经过同样的 resize、归一化和重叠切块。对每个层级的每个 token,SuperADD 在对应 memory bank 中找最近邻:
text
score_l(q) = min distance(q, memory_bank_l) / feature_dim_l然后把不同层级的距离图上采样到输出尺寸,默认是原图的 1/4 分辨率,再对多层分数取平均:
text
anomaly_map = mean_l(upsample(score_l))直觉上,浅层更关注纹理和边缘,中层/深层更关注结构和语义。把多个层级平均,能同时捕捉划痕、污染、破损、形变等不同尺度的异常。
这一点可以从 bias-variance 的角度理解:单层特征的异常距离 D ( l ) D^{(l)} D(l) 对某些缺陷很敏感,但也更容易受该层特有噪声影响。多层平均相当于一个简单 ensemble:
Var 1 ∣ L ∣ ∑ l D ( l ) ≈ 1 ∣ L ∣ 2 ∑ l Var D ( l ) \operatorname{Var}\left \\frac{1}{\|\\mathcal{L}\|}\\sum_l D\^{(l)} \\right \approx \frac{1}{|\mathcal{L}|^2} \sum_l \operatorname{Var}D\^{(l)} Var∣L∣1l∑D(l)≈∣L∣21l∑VarD(l)
在层间误差不完全相关时,融合后的热力图会更稳定。这也是 SuperADD 没有复杂解码器却能做像素级定位的重要原因。
后处理:把热力图变成可提交掩码
最近邻距离得到的是连续热力图,但工业评测和产线报警通常需要二值掩码。SuperADD 的后处理由四步组成:
- 用自动阈值把异常图二值化。
- 用 16 个方向的线形结构元素做形态学闭运算,默认半径为
26。 - 用较低阈值门控,默认
0.8 × threshold,避免闭运算把低置信噪声也连起来。 - 填充闭合区域,再做一次小半径腐蚀,减少毛刺。
这部分非常"工程",但很关键。缺陷热力图常常断断续续,尤其是细长划痕、裂纹、边缘破损。多方向闭运算相当于从不同角度把断裂的高分区域接起来,再通过填洞和腐蚀输出更干净的 mask。
把后处理写成数学形式更清楚。设线形结构元素为:
K θ , r K_{\theta,r} Kθ,r
其中 θ \theta θ 是方向, r r r 是半径。SuperADD 默认:
r = 26 , Θ = { k π 16 ∣ k = 0 , ... , 15 } r=26,\quad \Theta=\left\{ \frac{k\pi}{16} \mid k=0,\ldots,15 \right\} r=26,Θ={16kπ∣k=0,...,15}
对初始二值图 B 0 B_0 B0,方向 θ \theta θ 上的闭运算,随后用低阈值热力图做门控
默认 η = 0.8 \eta=0.8 η=0.8。最后进行轮廓填充 Fill \operatorname{Fill} Fill 和椭圆核腐蚀 Erode \operatorname{Erode} Erode:
B ( x ) = Erode ( Fill ( B gate ) ) B(x)= \operatorname{Erode} \left( \operatorname{Fill}(B_{\text{gate}}) \right) B(x)=Erode(Fill(Bgate))
这套公式背后的假设是:真实工业缺陷通常具有空间连贯性。单个孤立高分点更像噪声;沿某个方向可连接、内部可填充的高分区域,更可能是真缺陷。
核心创新拆解
创新一:把"训练"转化为特征空间覆盖问题
传统深度异常检测经常训练一个重构器、判别器或一类分类边界。SuperADD 的第一层创新是把学习问题降级为 memory bank 构建问题:
learn parameters → select representative normal features \text{learn parameters} \quad \rightarrow \quad \text{select representative normal features} learn parameters→select representative normal features
这带来两个直接好处。第一,冻结 DINOv3 避免了小样本工业数据上微调不稳定的问题。第二,新增产品类别时,不需要重新训练网络,只需要重新抽取正常图像特征并更新 memory bank。
创新二:DINOv3 dense feature 与异常分割天然契合
分类模型通常强在全局语义,但工业异常分割需要局部一致、空间可对齐的 dense feature。DINOv3 的价值在这里不是"分类更准",而是 patch token 特征更适合做局部匹配:
z u , v ( l ) ≈ local visual descriptor at ( u , v ) z_{u,v}^{(l)} \approx \text{local visual descriptor at }(u,v) zu,v(l)≈local visual descriptor at (u,v)
SuperADD 不接复杂 decoder,而是直接把 token 空间中的最近邻距离映射回图像空间。这样模型的可解释性很强:某处异常分数高,就是因为该处局部特征在正常库中找不到近邻。
创新三:重叠 patch 解决高分辨率和边界伪影的矛盾
工业图像高分辨率很常见,但 ViT 的显存消耗随 token 数快速增长。直接缩小图像会损失小缺陷,整图推理又太贵。SuperADD 采用重叠 patch:
large image → { P i } i = 1 n → center-valid token stitching \text{large image} \rightarrow \{P_i\}_{i=1}^{n} \rightarrow \text{center-valid token stitching} large image→{Pi}i=1n→center-valid token stitching
重叠带来的额外计算换来了两个收益:
- 保持局部高分辨率,细小缺陷不会过早消失。
- 丢弃 patch 边缘不稳定 token,减少拼接缝导致的假异常。
创新四:距离感知子采样比随机子采样更贴合正常流形
如果随机从 P ( l ) \mathcal{P}^{(l)} P(l) 里抽 M M M 个特征,常见纹理会占据大部分容量。例如金属平面、布料重复纹理、包装均匀背景都会生成海量相似 token。距离感知子采样等价于对高密度区域做压缩,对低密度正常模式做保护:
Pr ( p i kept ) ∝ 1 local density ( p i ) \Pr(p_i\ \text{kept}) \propto \frac{1}{\text{local density}(p_i)} Pr(pi kept)∝local density(pi)1
这对异常检测尤其重要,因为很多误报来自"少见但正常"的模式。只要 memory bank 漏掉这些正常稀疏区域,测试时它们就会被误判为异常。
创新五:形态学后处理把模型输出对齐到工业缺陷形态
SuperADD 的后处理看起来不如 backbone 炫,但它是最后 F1 的关键。异常分数图解决的是"哪里不像正常",形态学后处理解决的是"什么形状像缺陷"。两者分别对应:
appearance anomaly and spatial consistency \text{appearance anomaly} \quad \text{and} \quad \text{spatial consistency} appearance anomalyandspatial consistency
多方向闭运算尤其适合裂纹、划痕、边缘缺口这类细长结构。低阈值门控则防止闭运算过度扩张,把没有热力图支持的区域也纳入异常。
复杂度与工程瓶颈
设测试图像缩放后产生 Q l Q_l Ql 个 query token,第 l l l 层 memory bank 大小为 M l M_l Ml,特征维度为 C l C_l Cl。暴力最近邻的主要复杂度为:
O ( ∑ l ∈ L Q l M l C l ) \mathcal{O} \left( \sum_{l\in\mathcal{L}} Q_l M_l C_l \right) O(l∈L∑QlMlCl)
代码里用 torch.cdist 做矩阵化距离计算,GPU 上吞吐较高,但本质仍是 dense nearest neighbor。部署时最大的工程瓶颈通常不是 DINOv3 前向,而是 memory bank 规模和最近邻检索。
常见优化方向包括:
- 用 FAISS 或 IVF/PQ 等近似最近邻索引,把检索从精确暴力搜索改为 ANN。
- 降低 M l M_l Ml,但需要观察稀有正常模式是否被误删。
- 对浅层和深层使用不同 bank 大小,因为浅层 token 数更多、冗余也更高。
- 对稳定产线做特征缓存,减少重复 backbone 计算。
伪代码
python
def build_superadd(normal_images):
prototype_images, threshold_images = split_by_fraction(normal_images, fraction=8)
banks = {layer: [] for layer in [7, 15, 23, 31]}
for img in prototype_images:
x = brightness_augment(img, low=0.8, high=1.2)
x = resize_and_normalize(x)
features = dinov3_overlapping_patches(x, layers=[7, 15, 23, 31])
for layer, tokens in features.items():
banks[layer].extend(flatten(tokens))
for layer in banks:
banks[layer] = distance_aware_subsample(banks[layer], max_size=100000)
normal_scores = []
for img in threshold_images:
score_map = predict_score_map(img, banks)
normal_scores.append(score_map)
threshold = percentile(normal_scores, 95) * 1.421
return banks, threshold
def predict_score_map(img, banks):
x = resize_and_normalize(img)
features = dinov3_overlapping_patches(x, layers=[7, 15, 23, 31])
layer_maps = []
for layer, tokens in features.items():
distances = nearest_neighbor_distance(tokens, banks[layer])
layer_maps.append(upsample(distances / token_dim(tokens)))
return mean(layer_maps)和常见异常检测方法的差别
| 方法思路 | 代表做法 | 优点 | 局限 |
|---|---|---|---|
| 重构误差 | AutoEncoder、GAN | 思路直观,训练后推理快 | 模型可能把异常也重构得很好 |
| 一类分类 | One-Class SVM、Deep SVDD | 学正常边界 | 高维图像和跨类别泛化较难 |
| 特征记忆库 | PatchCore、SuperAD、SuperADD | 不需要异常样本,定位能力强 | memory bank 大,最近邻检索有成本 |
| 文本/视觉大模型提示 | CLIP 类方法 | 类别开放性强 | 像素级小缺陷不一定稳 |
SuperADD 属于特征记忆库路线,但它更强调 类别无关 和 分布偏移鲁棒性:一套架构、一套共享超参数,覆盖 MVTec AD 2 的多个工业类别。
实验表现
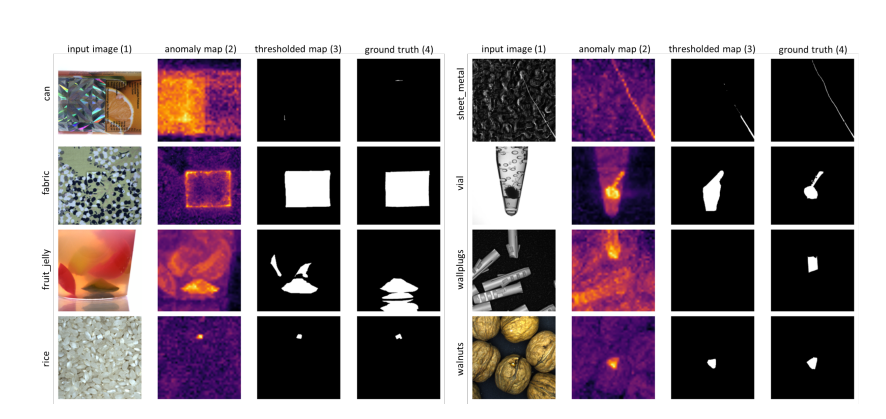
论文报告 SuperADD 在 CVPR 2026 VAND 4.0 Workshop Challenge Industrial Track 的 MVTec AD 2 上取得了以下 segmentation F1:
| 测试集 | Segmentation F1 |
|---|---|
| test public | 62.61% |
| test private | 57.42% |
| test private mixed | 54.35% |
这里的 private mixed 更接近真实部署中的麻烦情况:测试分布发生混合和变化。SuperADD 的重点不是把每个类别调到极致,而是在光照、类别和外观变化下维持一个稳健的通用方案。
优点与代价
优点:
- 不更新 DINOv3 权重,避免小数据训练不稳定。
- 只需要正常图像,贴近工业落地。
- 多层 dense feature 能同时覆盖纹理级和结构级异常。
- 重叠 patch 和亮度增强提升了高分辨率、光照偏移场景的稳定性。
- 类别无关、共享参数,维护成本低。
代价:
- memory bank 会占用显存/内存,最近邻检索也有计算成本。
- 阈值虽然自动估计,但仍是经验式策略;换到极端场景可能要重新校准。
- 后处理参数对细长缺陷有帮助,但也可能连接相邻噪声区域。
- 依赖 DINOv3 权重和较强 GPU,轻量化部署需要额外工程。
适合怎么落地
如果把 SuperADD 放进产线系统,我会把它当作一个强基线:
- 先用每个产品的正常样本建立 memory bank。
- 用少量正常验证图像确认阈值下的误报情况。
- 对高风险类别保留异常热力图,不只看二值 mask,方便人工复核。
- 如果延迟过高,优先优化最近邻检索,比如 FAISS、分层索引或更小的 bank。
- 对稳定产品线,可以把 DINOv3 特征离线缓存,降低重复计算成本。
小结
SuperADD 的漂亮之处不在于提出一个复杂的新网络,而在于把几个成熟但关键的工程选择组合得很扎实:强冻结特征、正常原型库、覆盖均匀的子采样、自动阈值、重叠切块和形态学后处理。它承认工业异常检测的现实:异常少、分布会变、缺陷形态不可枚举。因此它不试图"学会所有异常",而是尽量把"正常是什么样"记得足够完整。
这也是它名字里多出来的那个 D 最有意味的地方:Detect 不是靠分类头喊出来的,而是由每个局部特征和正常世界之间的距离慢慢显形。
参考资料
- Roming et al., SuperADD: Training-free Class-agnostic Anomaly Segmentation -- CVPR 2026 VAND 4.0 Workshop Challenge Industrial Track, arXiv, 2026.
- SuperADD 官方代码库:LukasRoom/SuperADD。
- SuperADD 默认配置:config.json。
- SuperAD 官方代码库:Summerdayhurricane/SuperAD。
- DINOv3 官方代码库:facebookresearch/dinov3。
- Heckler-Kram et al., The MVTec AD 2 Dataset: Advanced Scenarios for Unsupervised Anomaly Detection, arXiv, 2025.