Flink SQL
Flink SQL 是 Apache Flink 中强大且灵活的查询方式,Flink SQL 支持标准的 ANSI SQL 语法,基于 Apache Calcite 解析 SQL,保留识别符大小写,相较于 Flink Table API,SQL编程更为简单且支持多样化的查询操作。
Flink SQL 支持数据定义语言(DDL)、数据操作语言(DML)和查询语言,涵盖了 SELECT、CREATE、DROP、ALTER、ANALYZE、INSERT、UPDATE、DELETE 等操作。同时,Flink SQL 支持多种数据类型,包括复合类型,如 POJOs、元组、Rows以及 Scala case 类型,这些复合类型的字段可以通过SQL内置函数来访问,支持任意层次的嵌套。
注:ANSI SQL(American National Standards Institute Structured Query Language)是 SQL(结构化查询语言)的一个标准化版本,由美国国家标准学会(American National Standards Institute,简称 ANSI)制定和管理。旨在定义一组通用的 SQL 语法规范,使不同的数据库管理系统(DBMS)能够遵循相同的语法标准,从而提高 SQL 的可移植性和互操作性。
Apache Calcite 是一个开源的、高度可定制的 SQL 解析器和查询优化框架。它能够将输入的 SQL 查询语句解析成一个语法树,然后进行语义分析和查询优化,最终生成执行计划。
通过Flink SQL 编程可以使用简单的语法完成复杂的数据操作,下面对于Flink SQL中的一些常见重点使用方面进行介绍。
窗口与聚合
Flink SQL中也支持窗口操作,在Flink1.13版本之前,Flink SQL中设置窗口可以通过分组窗口(Group Window)函数,支持滚动窗口、滑动窗口、会话窗口,如下所示:
| Group Window Function | 描述 |
|---|---|
| TUMBLE(time_attr,interval) | 基于时间定义滚动窗口 |
| HOP(time_attr,interval,interval) | 基于时间定义滑动窗口 |
| SESSION(time_attr,interval) | 基于时间定义会话窗口 |
通过分组窗口函数指定窗口使用形式如下:
CREATE TABLE Orders (
user BIGINT,
product STRING,
amount INT,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time - INTERVAL '1' MINUTE
) WITH (...);
SELECT
user,
TUMBLE_START(order_time, INTERVAL '1' DAY) AS wStart,
SUM(amount)
FROM Orders
GROUP BY
TUMBLE(order_time, INTERVAL '1' DAY),
user以上示例中定义了1天时间周期的滚动窗口,在进行窗口聚合时,还需要将"TUMBLE(...)"语句与其他分组字段写入group by中,较为麻烦,并且分组窗口聚合函数功能有限,所以在Flink1.13版本后,通过窗口聚合函数设置窗口的方式被弃用,Flink SQL中引入了**窗口表值函数(table-valued function,TVF)**来定义窗口,窗口表值函数取代了传统的分组窗口函数,窗口表值函数更符合SQL标准,并且更强大,支持复杂的基于窗口的计算,如窗口TopN、窗口Join计算。Apache Flink提供了以下几种窗口表值函数(TVF)来定义窗口:
-
滚动窗口(Tumbling Windows)
-
滑动窗口(Hop Windows)
-
累积窗口(Cumulate Windows)
目前在Flink SQL中还不支持Session会话窗口,未来版本会支持。在使用以上各类窗口表值函数时,需要注意每个元素在逻辑上有可能属于多个窗口,例如滑动窗口会创建重叠的窗口,其中一个单独的元素可以分配给多个窗口。
此外,在进行SQL 编程时,如果在SQL中只是指定窗口表值函数进行数据查询没有任何意义,往往窗口表值函数会结合聚合函数(COUNT/SUM/AVG/MAX/MIN)进行聚合(Aggregation)查询,下面对于以上各种窗口表值函数进行介绍。
滚动窗口(Tumbling Windows)
在Flink SQL中Tumbling Window 滚动窗口与Table API或者DataStream API中的滚动窗口一样,滚动窗口需要指定固定长度并且不会重叠。
Flink SQL中通过TUMBLE表值函数来设置滚动窗口,如下:
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])TUMBLE参数解释如下:
-
data:指定Table 表。
-
timecol:指定表中的时间列,必须是TIMESTAMP或者TIMESTAMP_LTZ类型。
-
size:指定窗口长度,即多久生成一个窗口。
-
offset:可选参数,指定窗口偏移量。
TUMBLE表值函数会根据时间属性字段分配滚动窗口。在流处理模式下,时间属性字段必须是事件时间或处理时间属性。在批处理模式下,窗口表函数的时间属性字段必须是TIMESTAMP或TIMESTAMP_LTZ类型的属性。
TUMBLE的返回值包括原始关系的所有列,以及额外的三列,分别命名为"window_start"(窗口起始时间)、"window_end"(窗口结束时间)和"window_time"(窗口时间),这里的window_time窗口时间表示该窗口中包含的事件时间最大值,该值为window_end-1ms。原始时间属性"timecol"将在窗口表值函数之后成为常规的时间戳列。下面通过一个案例来演示Flink SQL 中滚动窗口使用。
案例:读取Kafka中基站日志数据,每5s设置滚动窗口,统计每个基站通话时长。
- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL TumblingWindow
Table result = tableEnv.sqlQuery("select " +
"sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" TUMBLE(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND)" +
") " +
"group by sid,window_start,window_end");
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
val result: Table = tableEnv.sqlQuery("" +
"select " +
" sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" TUMBLE(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND)" +
") " +
"group by sid,window_start,window_end")
//打印结果
result.execute.print()以上代码中读取Kafka中基站日志数据,基于事件时间列"call_time"设置了watermark,并进行滚动窗口设置,通过以上编程可见,Flink SQL编程中Java 代码和Scala代码编写方式非常类似,代码编写完成后,可以向Kafka stationlog-topic中输入如下数据。
#向kafka stationlog-topic中输入如下数据
001,181,182,busy,1000,10
002,182,183,fail,3000,20
001,183,184,busy,2000,30
002,184,185,busy,6000,40
003,181,183,busy,5000,50
#输入此条数据后会生成第一个窗口结果
001,181,182,busy,7000,10
002,182,183,fail,9000,20
001,183,184,busy,11000,30
002,184,185,busy,6000,40
#输入此条数据后会生成第二个窗口结果
003,181,183,busy,12000,50控制台输出结果如下:
+----+----+-------------------------+-------------------------+--------+
| op |sid | window_start | window_end |sum_dur |
+----+----+-------------------------+-------------------------+--------+
| +I |001 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 | 40 |
| +I |002 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 | 20 |
| +I |001 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:10.000 | 10 |
| +I |003 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:10.000 | 50 |
| +I |002 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:10.000 | 100 |滑动窗口(Hop Windows)
Flink SQL中的滑动窗口与Table API和DataStream API中的滑动窗口类似,可以指定参数设置窗口大小,同时还需要指定参数控制窗口多久滑动一次,滑动窗口可以有重叠。Flink SQ中通过HOP 表值函数来设置滑动窗口,如下:
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])HOP参数解释如下:
-
data:指定Table 表。
-
timecol:指定表中的时间列,必须是TIMESTAMP或者TIMESTAMP_LTZ类型。
-
slide:指定窗口滑动间隔时间。
-
size:指定窗口长度。
-
offset:可选参数,指定窗口偏移量。
HOP表值函数在流处理模式下,时间属性字段必须是事件时间或处理时间属性,在批处理模式下,窗口表函数的时间属性字段必须是TIMESTAMP或TIMESTAMP_LTZ类型的属性。与TUMBLE表值函数一样,HOP的返回值包括原始关系的所有列,以及额外的三列,分别命名为"window_start"(窗口起始时间)、"window_end"(窗口结束时间)和"window_time"(窗口时间),这里的window_time窗口时间表示该窗口中包含的事件时间最大值,该值为window_end-1ms。原始时间属性"timecol"将在窗口表值函数之后成为常规的时间戳列。下面通过一个案例来演示Flink SQL 中滑动窗口使用。
案例:读取Kafka中基站日志数据,每隔5s统计最近10s每个基站所有主叫通话总时长。
- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL TumblingWindow
Table result = tableEnv.sqlQuery("select " +
"sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" HOP(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND , INTERVAL '10' SECOND)" +
") " +
"group by sid,window_start,window_end");
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
val result: Table = tableEnv.sqlQuery("" +
"select " +
" sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" HOP(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND, INTERVAL '10' SECOND)" +
") " +
"group by sid,window_start,window_end")
//打印结果
result.execute.print()以上代码与Tumbling滚动窗口类似,只是使用了HOP滑动窗口。代码编写完成后,可以向Kafka stationlog-topic中输入如下数据。
#向kafka stationlog-topic中输入如下数据
001,181,182,busy,1000,10
002,182,183,fail,3000,20
001,183,184,busy,2000,30
002,184,185,busy,6000,40
003,181,183,busy,5000,50
#[0~5000)窗口触发
001,181,182,busy,7000,10
002,182,183,fail,9000,20
001,183,184,busy,11000,30
002,184,185,busy,6000,40
#[0~10000)窗口触发
003,181,183,busy,12000,50
#[5000~15000)窗口触发
003,181,183,busy,17000,50控制台输出结果如下:
+----+----+-------------------------+-------------------------+--------+
| op |sid | window_start | window_end |sum_dur |
+----+----+-------------------------+-------------------------+--------+
| +I |001 | 1970-01-01 07:59:55.000 | 1970-01-01 08:00:05.000 | 40 |
| +I |002 | 1970-01-01 07:59:55.000 | 1970-01-01 08:00:05.000 | 20 |
| +I |001 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:10.000 | 50 |
| +I |003 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:10.000 | 50 |
| +I |002 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:10.000 | 120 |
| +I |001 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:15.000 | 40 |
| +I |003 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:15.000 | 100 |
| +I |002 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:15.000 | 100 |累积窗口(Cumulate Windows)
累积窗口是Flink SQL中特有的窗口函数。滚动窗口和滑动窗口适合固定周期统计指标,除了这种固定周期统计指标场景外,还有一种特殊场景:当统计周期较长时,需要在统计周期内间隔输出某指标的统计值,并且这些输出的值是逐步累积的,这种情况下滚动窗口和滑动窗口就不能满足需求,这种场景中就可以使用累积窗口来解决。
例如:我们按天来实时统计网站的PV,每小时输出今天到此刻PV总量。如果我们设置1天一个滑动窗口,那么需要等到24点才会计算一次,这样输出频率太低,满足不了我们的需求;如果每隔一段时间统计过去1天的PV值,这样虽然计算频率增高,但是计算的结果并不是我们想要的今天到此刻的PV值。这种特殊的窗口统计就是"累积窗口",我们可以通过Flink SQL提供的累计窗口表值函数来解决。
Flink SQL中通过CUMULATE 表值函数来设置累积窗口,如下:
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)CUMULATE 参数解释如下:
-
data:指定Table 表。
-
timecol:指定表中的时间列,必须是TIMESTAMP或者TIMESTAMP_LTZ类型。
-
step:指定窗口累积步长,即多久输出一次累积结果。
-
size:指定窗口长度,即多久生成一个窗口。
CUMULATE 表值函数在流处理模式下,时间属性字段必须是事件时间或处理时间属性,在批处理模式下,窗口表函数的时间属性字段必须是TIMESTAMP或TIMESTAMP_LTZ类型的属性。与TUMBLE表值函数一样,CUMULATE 的返回值包括原始关系的所有列,以及额外的三列,分别命名为"window_start"(窗口起始时间)、"window_end"(窗口结束时间)和"window_time"(窗口时间),这里的window_time窗口时间表示该窗口中包含的事件时间最大值,该值为window_end-1ms。原始时间属性"timecol"将在窗口表值函数之后成为常规的时间戳列。下面通过一个案例来演示Flink SQL 中累积窗口使用。
案例:读取Kafka中基站日志数据,按日统计,每5s输出每个基站所有主叫通话时长。
- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL TumblingWindow
Table result = tableEnv.sqlQuery("select " +
"sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" CUMULATE(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND , INTERVAL '1' DAY)" +
") " +
"group by sid,window_start,window_end");
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
val result: Table = tableEnv.sqlQuery("" +
"select " +
" sid,window_start,window_end,sum(duration) as sum_dur " +
"from TABLE(" +
" CUMULATE(TABLE stationlog_tbl,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND, INTERVAL '10' DAY)" +
") " +
"group by sid,window_start,window_end")
//打印结果
result.execute.print()代码编写完成后,可以向Kafka stationlog-topic中输入如下数据,可以看到随着数据的输入,每隔5秒会展示一次当日统计结果。
#向kafka stationlog-topic中输入如下数据
001,181,182,busy,1000,10
002,182,183,fail,3000,20
001,183,184,busy,2000,30
002,184,185,busy,6000,40
003,181,183,busy,5000,50
#[0~5000)窗口触发
001,181,182,busy,7000,10
002,182,183,fail,9000,20
001,183,184,busy,11000,30
002,184,185,busy,6000,40
#[0~10000)窗口触发
003,181,183,busy,12000,50
#[5000~15000)窗口触发
003,181,183,busy,17000,50控制台输出结果如下:
+----+-----+-------------------------+-------------------------+--------+
| op | sid | window_start | window_end |sum_dur |
+----+-----+-------------------------+-------------------------+--------+
| +I | 001 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:05.000 | 40 |
| +I | 002 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:05.000 | 20 |
| +I | 001 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:10.000 | 50 |
| +I | 003 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:10.000 | 50 |
| +I | 002 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:10.000 | 120 |
| +I | 001 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:15.000 | 80 |
| +I | 003 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:15.000 | 100 |
| +I | 002 | 1970-01-01 00:00:00.000 | 1970-01-01 08:00:15.000 | 120 |Over开窗函数
Flink SQL中我们可以使用SUM/COUNT/MAX/MIN/AVG等聚合函数对group by分组数据进行聚合,这种操作只能针对Group By 分组数据得到一个结果,输入数据行与数据结果之间是一种"多对一"的关系;在Flink Table API中我们知道可以通过Over开窗函数实现针对每行数据的分组聚合,即可以针对每行数据都会有聚合统计结果,输入行与输出结果是一种"多对多"的关系。
Flink中不仅仅Table API中支持开窗函数,在Flink SQL中也支持Over开窗函数,SQL中的开窗函数语法如下:
SELECT
agg_func(agg_col) OVER (
[PARTITION BY col1[, col2, ...]]
ORDER BY time_col
range_definition
), ...
FROM ...以上语句中的解释如下:
-
agg_fun:指定聚合函数,例如SUM、AVG、MAX、MIN、COUNT等。
-
PARTITION BY:可选项,用于将结果集划分成不同的分组,类似group by。在Flink流式处理中,如果不指定partition by 而设置Over开窗函数,则Flink所有数据分到一个分组中,并由一个并行度处理。
-
ORDER BY:按照给定的排序列对分组的数据进行排序,排序列可以基于事件也可以基于数量,但如果是Flink流处理,只支持按照时间属性的升序排列。
-
range_definition:用于定义窗口聚合的行范围,该范围通过BETWEEN语句定义窗口上下限:BETWEEN <下界> AND <上界>,边界的行也包含在聚合中,Flink仅支持CURRENT ROW 作为窗口上边界。可以通过RANGE Intervals和Rows Intervals来定义窗口聚合范围。
#基于RANGE Intervals定义Over窗口聚合范围
RANGE BETWEEN INTERVAL '30' MINUTE PRECEDING AND CURRENT ROW
#基于Rows Intervals定义Over窗口聚合范围
ROWS BETWEEN 10 PRECEDING AND CURRENT ROW如下是SQL中使用开窗函数的一个示例:
SELECT order_id, order_time, amount,
SUM(amount) OVER (
PARTITION BY product
ORDER BY order_time
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
) AS one_hour_prod_amount_sum
FROM Orders以上示例中针对Orders订单表设置了Over开窗函数:按照product产品分组,订单时间升序排序,统计当前订单前1小时内订单总金额。以上输出统计结果时每个订单都会对应一个聚合值。
有时针对同一个Over窗口我们设置很多个聚合操作,为了使查询更可读,我们可以通过WINDOW子句来设置窗口,如下所示:
SELECT order_id, order_time, amount,
SUM(amount) OVER w AS sum_amount,
AVG(amount) OVER w AS avg_amount
FROM Orders
WINDOW w AS (
PARTITION BY product
ORDER BY order_time
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW)总之,在FlinkSQL查询中通过Over开窗函数,可以更加灵活地进行数据分析和聚合操作,而无需使用子查询或连接来实现类似的功能,下面我们通过案例来学习Over开窗函数使用。
案例一:读取Kafka基站日志数据,设置开窗函数,统计每个基站近5秒通话时长。
- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL Over Window
Table result = tableEnv.sqlQuery("" +
"select " +
" sid,call_time," +
" SUM(duration) OVER (" +
" PARTITION BY sid " +
" ORDER BY time_ltz " +
" RANGE BETWEEN INTERVAL '5' SECOND PRECEDING AND CURRENT ROW" +
" ) as sum_dur " +
"FROM stationlog_tbl");
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//SQL Over Window
val result: Table = tableEnv.sqlQuery("" +
"select " +
" sid,call_time," +
" SUM(duration) OVER (" +
" PARTITION BY sid " +
" ORDER BY time_ltz " +
" RANGE BETWEEN INTERVAL '5' SECOND PRECEDING AND CURRENT ROW" +
" ) as sum_dur " +
"FROM stationlog_tbl");
//打印结果
result.execute.print()以上Java和Scala代码启动后,向Kafka stationlog-topic 依次输入如下数据:
001,181,182,busy,1000,10
002,182,183,fail,3000,20
001,183,184,busy,2000,30
002,184,185,busy,6000,40
003,181,183,busy,5000,50
001,181,182,busy,7000,10
002,182,183,fail,9000,20
001,183,184,busy,11000,30随着以上实时数据的输入,可以看到当Watermark达到某事件的事件时间时,该事件会被输出,同时Over开窗函数到此事件聚合值也会被输出,并且统计的是此事件到过去5秒内的事件通话时长总和,控制台输出结果如下:
+----+-----+----------+--------+
| op | sid |call_time |sum_dur |
+----+-----+----------+--------+
| +I | 001 | 1000 | 10 |
| +I | 002 | 3000 | 20 |
| +I | 001 | 2000 | 40 |
| +I | 003 | 5000 | 50 |
| +I | 001 | 7000 | 40 |
| +I | 002 | 6000 | 60 |
| +I | 002 | 9000 | 60 |案例二:读取Kafka基站日志数据,设置开窗函数,统计每个基站近5秒通话时长及通话次数。
- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL Over Window
Table result = tableEnv.sqlQuery("" +
"select " +
" sid,call_time," +
" SUM(duration) OVER w as sum_dur," +
" COUNT(*) OVER w as cnt " +
"FROM stationlog_tbl " +
"WINDOW w AS (" +
" PARTITION BY sid " +
" ORDER BY time_ltz " +
" RANGE BETWEEN INTERVAL '5' SECOND PRECEDING AND CURRENT ROW)");
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//SQL Over Window
val result = tableEnv.sqlQuery("" +
"select " +
" sid,call_time," +
" SUM(duration) OVER w as sum_dur," +
" COUNT(*) OVER w as cnt " +
"FROM stationlog_tbl " +
"WINDOW w AS (" +
" PARTITION BY sid " +
" ORDER BY time_ltz " +
" RANGE BETWEEN INTERVAL '5' SECOND PRECEDING AND CURRENT ROW)");
//打印结果
result.execute.print()以上Java和Scala Flink SQL代码为了避免在select 后出现Over窗口函数的冗余不方便阅读,这里使用了WINDOW函数来定义Over开窗函数,这种方式SQL代码可读性大大提升。代码运行后在socket中输入数据:
001,181,182,busy,1000,10
002,182,183,fail,3000,20
001,183,184,busy,2000,30
002,184,185,busy,6000,40
003,181,183,busy,5000,50
001,181,182,busy,7000,10
002,182,183,fail,9000,20
001,183,184,busy,11000,30随着以上实时数据的输入,可以看到当Watermark达到某事件的事件时间时,该事件会被输出,同时Over开窗函数到此事件聚合值也会被输出,并且统计的是此事件到过去5秒内的事件通话时长总和与通话总次数,控制台输出结果如下:
+----+----+----------+--------+----+
| op |sid |call_time |sum_dur |cnt |
+----+----+----------+--------+----+
| +I |001 | 1000 | 10 | 1 |
| +I |002 | 3000 | 20 | 1 |
| +I |001 | 2000 | 40 | 2 |
| +I |003 | 5000 | 50 | 1 |
| +I |002 | 6000 | 60 | 2 |
| +I |001 | 7000 | 40 | 2 |
| +I |002 | 9000 | 60 | 2 |Joins
Flink SQL中针对动态表支持各种灵活的Join方式,支持的Join类型有常规Join(Regular Joins)、间隔Join(Interval Joins)、时态Join(Temporal Joins)、维度Join(Lookup Join),下面分别进行介绍。
常规Join(Regular Joins)
常规Join是最通用的连接类型,包括INNTER JOIN、LEFT JOIN、RIGHT JOIN、FULL OUTER JOIN。Flink 两表关联通过ON指定关联条件,目前只支持等值连接,两流中的数据都会被保存到状态中,只要关联条件匹配,任意流中INSERT和UPDATE操作都会导致结果输出。在Flink SQL中使用Join时,最好设置状态的存活时间,避免状态的无限增长。各种Join的使用示例如下。
#INNTER JOIN
SELECT *
FROM Orders
INNER JOIN Product
ON Orders.product_id = Product.id
#LEFT JOIN
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.product_id = Product.id
#RIGHT JOIN
SELECT *
FROM Orders
RIGHT JOIN Product
ON Orders.product_id = Product.id
#FULL OUTER JOIN
SELECT *
FROM Orders
FULL OUTER JOIN Product
ON Orders.product_id = Product.id下面通过案例演示FULL OUTER JOIN 使用方式。该案例中通过读取Kafka中订单数据及商品数据,进行关联,输出订单详细信息。这里涉及从Kafka对应topic中读取数据,所以首先在Kafka中创建对应的topic。
#启动Kafka后创建对应的topic
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic order-topic --partitions 3 --replication-factor 3
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic product-topic --partitions 3 --replication-factor 3
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list
...
order-topic
product-topic
...- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka 订单数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table order_tbl (" +
" order_id string," +
" product_id string," +
" order_amount double," +
" order_time bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(order_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'order-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//读取Kafka 商品信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table product_tbl (" +
" product_id string," +
" product_name string," +
" dt bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'product-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL Full Outer Join
Table result = tableEnv.sqlQuery("" +
"select " +
" a.order_id,b.product_name,a.order_amount,a.order_time " +
"from " +
" order_tbl a " +
"full outer join product_tbl b " +
"on a.product_id = b.product_id");
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka 订单数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table order_tbl (" +
" order_id string," +
" product_id string," +
" order_amount double," +
" order_time bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(order_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'order-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//读取Kafka 商品信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table product_tbl (" +
" product_id string," +
" product_name string," +
" dt bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'product-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//SQL Full Outer Join
val result = tableEnv.sqlQuery("" +
"select " +
" a.order_id,b.product_name,a.order_amount,a.order_time " +
"from " +
" order_tbl a " +
"full outer join product_tbl b " +
"on a.product_id = b.product_id")
//打印结果
result.execute.print()以上代码编写完成启动后,向对应的Kafka topic中输入如下数据:
#order-topic输入数据
order_1,product_1,20,1000
order_2,product_2,24,2000
order_3,product_3,26,3000
order_4,product_4,35,4000
order_5,product_5,19,5000
#product-topic输入数据
product_1,苹果,1000
product_2,桃子,2000
product_3,香蕉,3000
product_4,西瓜,4000
product_6,草莓,6000可以看到两表关联得到如下结果:
+----+---------+-------------+-------------+-----------+
| op |order_id |product_name |order_amount |order_time |
+----+---------+-------------+-------------+-----------+
| +I | order_4 | <NULL> | 35.0 | 4000 |
| +I | order_5 | <NULL> | 19.0 | 5000 |
| +I | order_2 | <NULL> | 24.0 | 2000 |
| +I | order_1 | <NULL> | 20.0 | 1000 |
| +I | order_3 | <NULL> | 26.0 | 3000 |
| -D | order_4 | <NULL> | 35.0 | 4000 |
| +I | order_4 | 西瓜 | 35.0 | 4000 |
| -D | order_2 | <NULL> | 24.0 | 2000 |
| +I | order_2 | 桃子 | 24.0 | 2000 |
| -D | order_3 | <NULL> | 26.0 | 3000 |
| +I | order_3 | 香蕉 | 26.0 | 3000 |
| -D | order_1 | <NULL> | 20.0 | 1000 |
| +I | order_1 | 苹果 | 20.0 | 1000 |
| +I | <NULL> | 草莓 | <NULL> | <NULL> |间隔Join(Interval Joins)
Flink SQL中的Interval Join与 Table API中Interval Join一样,可以在指定时间区间内关联两个流数据,Interval Join基于时间区间进行关联,使用时至少需要一个等值join关联条件和一个限制两个流关联时间范围的条件,限制时间范围的条件可以基于两流ProcessTime/EventTime来定义。
Flink SQL中Interval Join使用示例如下:
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time指定两流关联时间范围的有效设置如下:
ltime = rtime
ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND下面通过案例来演示Flink SQL中Interval Join使用。该案例中从Kafka中读取用户登录流和广告点击流数据,通过IntervalJoin分析用户点击广告的行为。这里涉及从Kafka对应topic中读取数据,所以首先在Kafka中创建对应的topic。
#启动Kafka后创建对应的topic
#启动Kafka后创建对应的topic
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic login-topic --partitions 3 --replication-factor 3
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic click-topic --partitions 3 --replication-factor 3
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list
...
login-topic
click-topic
...- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka 登录数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table login_tbl (" +
" user_id string," +
" login_time bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(login_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'login-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//读取Kafka 点击广告信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table click_tbl (" +
" user_id string," +
" product_id string," +
" dt bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'click-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL 方式实现Interval Join
Table result = tableEnv.sqlQuery("" +
"select " +
" l.user_id," +
" l.login_time," +
" c.product_id," +
" c.dt " +
"from login_tbl as l " +
"join click_tbl as c " +
"on l.user_id = c.user_id " +
"and l.time_ltz between c.time_ltz - INTERVAL '2' SECOND and c.time_ltz + INTERVAL '2' SECOND");
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka 登录数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table login_tbl (" +
" user_id string," +
" login_time bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(login_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'login-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//读取Kafka 点击广告信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table click_tbl (" +
" user_id string," +
" product_id string," +
" dt bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'click-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//SQL 方式实现Interval Join
val result = tableEnv.sqlQuery("" +
"select " +
" l.user_id," +
" l.login_time," +
" c.product_id," +
" c.dt " +
"from login_tbl as l " +
"join click_tbl as c " +
"on l.user_id = c.user_id " +
"and l.time_ltz between c.time_ltz - INTERVAL '2' SECOND and c.time_ltz + INTERVAL '2' SECOND");
//打印结果
result.execute().print()以上代码中设置了两表进行关联的时间范围为正负2秒,代码运行后,向Kafka对应的topic中输入如下数据:
#login-topic 中数据流
user_1,6000
#click-topic 中数据流
user_1,product_1,3000
user_1,product_2,4000
user_1,product_3,5000
user_1,product_4,6000
user_1,product_5,7000
user_1,product_6,8000
user_1,product_7,9000通过两表Interval Join后,输出结果如下:
+----+--------+-----------+-----------+-----+
| op |user_id |login_time |product_id | dt |
+----+--------+-----------+-----------+-----+
| +I | user_1 | 6000 | product_2 |4000 |
| +I | user_1 | 6000 | product_3 |5000 |
| +I | user_1 | 6000 | product_4 |6000 |
| +I | user_1 | 6000 | product_5 |7000 |
| +I | user_1 | 6000 | product_6 |8000 |时态Join(Temporal Joins)
Flink SQL中也支持使用时态表,通过时态表可以追踪表中的数据变化、访问数据历史版本数据。时态表不能单独使用,只能与其他表进行Join关联时使用。
与Flink Table中使用时态表一样,在SQL编程中创建时态表需要使用主键约束和事件时间,只要定义一张表时包含事件时间和主键约束,那么这张表就是时态表。以下是在SQL编程中创建时态表的示例(基于事件时间):
-- 定义一张时态表
CREATE TABLE product_changelog (
product_id STRING,
product_name STRING,
product_price DECIMAL(10, 4),
update_time TIMESTAMP(3),
PRIMARY KEY(product_id) NOT ENFORCED, -- (1) 定义主键约束
WATERMARK FOR update_time AS update_time -- (2) 通过 watermark 定义事件时间
) WITH (
'connector' = 'kafka',
'topic' = 'products',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'debezium-json'
);以上Flink SQL创建时态表中,指定了"update_time"为事件时间,"product_id"为主键。在SQL编程中创建时态表有以下注意点:
-
创建时态表函数时需要指定时间属性和主键。时间属性格式必须为TIMESTAMP/TIMESTAMP_LTZ,指定主键主要是保证该时态表中数据能按照主键进行更新或删除。
-
时态表中必须为CDC(Change Data Capture,数据变更捕获)数据,即数据是有增删改查的UNBOUND实时流,不能是BOUND有边界的流。
-
在读取Kafka中数据时如果设置主键定义时态表,"format"不能是单独的"json"格式,这里指定为"debezium-json"格式,这种格式支持Flink SQL 从Kafka中读取数据时读取 INSERT / UPDATE / DELETE 消息,以支持Kafka Connector表的主键。
Flink SQL时态表不能单独查询,需要通过与其他表进行Join从时态表中查询数据,SQL中创建时态表可以基于ProcessTime也可以是EventTime。基于两种时间构建的时态表在使用方式上有差别,下面分别介绍。
1. Event Time Temporal Join
基于事件时间构建的时态表与其他表进行Join关联时,支持LEFT JOIN和INNER JOIN,时态表必须作为Join关联的右表放在右侧,使用示例如下:
SELECT [column_list]
FROM table1 [AS <alias1>]
[LEFT] JOIN table2 FOR SYSTEM_TIME AS OF table1.rowtime [AS <alias2>]
ON table1.column-name1 = table2.column-name1Flink SQL中通过"FOR SYSTEM_TIME AS OF..."语法来指定左表的事件时间列,以便在时态表中查询该时间对应的版本数据。基于EventTime的时态表中会存储上一个watermark到当前时刻的所有版本数据,watermark之前的数据不会存储。
基于Event Time 的时态表查询除了以上这种SQL Join关联方式外,还可以通过定义时态表函数来查询时态表中的数据,目前时态表函数仅支持通过Table API方式定义,不支持SQL DDL方式定义,在SQL编程中使用时态表函数查询时态表中数据的使用方式如下:
#currency_rates为创建的时态表,定义时态表函数
TemporalTableFunction rates = tEnv
.from("currency_rates")
#指定“update_time”为时间属性,“currency”为主键
.createTemporalTableFunction("update_time", "currency");
#创建和注册时态表函数,这样可以在SQL中使用rates函数
tEnv.createTemporarySystemFunction("rates", rates);
#SQL方式从时态表中查询数据
SELECT
rate,amount,...
FROM
orders,
LATERAL TABLE (rates(order_time))
WHERE rates.currency = orders.currency注意:以上"LATERAL TABLE..."是Flink SQL中调用表函数的方式,Table API中是通过"joinLateral(...)"方式调用表函数。
2. Processing Time Temporal Join
基于Processing Time的时态表中就不存在数据版本的概念,这种时态表中存储的数据只有对应主键的最新版本,其他表在与基于Processing Time的时态表进行关联时,不支持SQL "FOR SYSTEM_TIME AS OF..."语法关联方式,只支持使用时态表函数从时态表中查询数据,通过"LATERAL TABLE"进行关联,时态表函数也是作为右表放在关联的右侧,永远返回对应主键的最新值,使用方式同Event Time Temporal Join 中时态表函数使用方式。
下面通过案例分别演示在Flink SQL中通过时态表函数和"FOR SYSTEM_TIME AS OF..."语法两种方式来查询基于EventTime的时态表数据。案例中通过读取Kafka "visit-topic"中用户浏览商品数据形成普通表 visit_tbl ,读取Kafka "product-topic"中商品信息数据形成时态表 product_tbl ,然后针对两表进行Join关联完成从时态表中查询对应时刻的商品价格。
首先我们需要创建对应的Kafka topic ,"product-topic"在前面已经创建过,这里只需要创建"visit-topic"即可。
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic visit-topic --partitions 3 --replication-factor 3
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list
visit-topic
product-topic此外,在编写代码从Kafka中读取"product-topic"数据形成时态表时,我们还需要使用"debezium-json"格式,该格式需要在Java和Scala项目中导入如下依赖:
<!-- Flink 支持 Debezium Json 所需依赖包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>下面分别使用时态表函数和"FOR SYSTEM_TIME AS OF ..."方式查询时态表中数据。
A. 时态表函数方式查询时态表数据
- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka 浏览商品数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table visit_tbl (" +
" left_product_id string," +
" left_visit_time bigint," +
" left_time_ltz AS TO_TIMESTAMP_LTZ(left_visit_time,3)," +
" WATERMARK FOR left_time_ltz AS left_time_ltz - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'visit-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//读取Kafka 商品信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table product_tbl (" +
" right_dt bigint," +
" right_product_id string," +
" right_product_name string," +
" right_price double," +
" PRIMARY KEY(right_product_id) NOT ENFORCED," +
" right_time_ltz AS TO_TIMESTAMP_LTZ(right_dt,3)," +
" WATERMARK FOR right_time_ltz AS right_time_ltz - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'product-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'debezium-json'" +
")");
TemporalTableFunction temporalTableFunction = tableEnv.from("product_tbl")
.createTemporalTableFunction($("right_time_ltz"), $("right_product_id"));
tableEnv.createTemporarySystemFunction("temporalTableFunction",temporalTableFunction);
//SQL 方式实现 Temporal Join
Table result = tableEnv.sqlQuery("" +
"select " +
" left_product_id,left_visit_time,right_product_name,right_price " +
"from visit_tbl v,LATERAL TABLE (temporalTableFunction(left_time_ltz)) " +
"WHERE left_product_id = right_product_id"
);
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka 浏览商品数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table visit_tbl (" +
" left_product_id string," +
" left_visit_time bigint," +
" left_time_ltz AS TO_TIMESTAMP_LTZ(left_visit_time,3)," +
" WATERMARK FOR left_time_ltz AS left_time_ltz - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'visit-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//读取Kafka 商品信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table product_tbl (" +
" right_dt bigint," +
" right_product_id string," +
" right_product_name string," +
" right_price double," +
" PRIMARY KEY(right_product_id) NOT ENFORCED," +
" right_time_ltz AS TO_TIMESTAMP_LTZ(right_dt,3)," +
" WATERMARK FOR right_time_ltz AS right_time_ltz - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'product-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'debezium-json'" +
")")
//创建时态表函数,"right_time_ltz"为时间属性,"right_product_id"为主键
val temporalTableFunction: TemporalTableFunction = tableEnv.from("product_tbl")
.createTemporalTableFunction($("right_time_ltz"), $("right_product_id"))
tableEnv.createTemporarySystemFunction("temporalTableFunction", temporalTableFunction)
//SQL 方式实现 Temporal Join
val result = tableEnv.sqlQuery("" +
"select " +
" left_product_id,left_visit_time,right_product_name,right_price " +
"from visit_tbl v,LATERAL TABLE (temporalTableFunction(left_time_ltz)) " +
"WHERE left_product_id = right_product_id"
)
//打印结果
result.execute().print()以上Java和Scala代码中,读取Kafka中数据形成普通表和时态表,两表中都设置了watermark,为了能看出从时态表中关联对应时刻的数据,这里设置watermark演示时间为5秒。时态表中设置format格式为"debezium-json"格式,该格式形式及解释如下:
{
"before":{ -- 变更操作之前的行数据
"right_dt":1000,
"right_product_id":"p_001",
"right_product_name":"电脑",
"right_price":3
},
"after":{ -- 变更操作之后的行数据
"right_dt":3000,
"right_product_id":"p_001",
"right_product_name":"电脑",
"right_price":9
},
"op":"u" -- 数据操作类型。可以指定为c(create),u(update),d(delete)
}代码编写完成启动后,首先向kafka "product-topic"中输入如下数据:
{"before": null,"after": {"right_dt": 1000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 3.0},"op": "c"}
{"before": null,"after": {"right_dt": 2000,"right_product_id": "p_002","right_product_name": "手机","right_price": 4.0},"op": "c"}
{"before": {"right_dt": 1000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 3.0},"after": {"right_dt": 3000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 9.0},"op": "u"}
{"before": {"right_dt": 2000,"right_product_id": "p_002","right_product_name": "手机","right_price": 4.0},"after": {"right_dt": 4000,"right_product_id": "p_002","right_product_name": "手机","right_price": 6.0},"op": "u"}
{"before": {"right_dt": 3000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 9.0},"after": {"right_dt": 5000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 2.0},"op": "u"}然后向Kafka "visit-topic"中输入如下数据:
#visit-topic 输入浏览产品数据,形成左表数据
p_002,1000
p_001,2000
p_002,3000
p_001,4000
p_001,5000
p_002,5000
#当输入此条数据时,wm达到5000,会输出结果
p_003,10000当输入"p_003,10000"数据时,左右表watermark达到5000,会有对应结果输出,控制台输出结果如下:
+----+----------------+----------------+-------------------+------------+
| op |left_product_id |left_visit_time |right_product_name |right_price |
+----+----------------+----------------+-------------------+------------+
| +I | p_001 | 2000 | 电脑 | 3.0 |
| +I | p_002 | 3000 | 手机 | 4.0 |
| +I | p_002 | 5000 | 手机 | 6.0 |
| +I | p_001 | 4000 | 电脑 | 9.0 |
| +I | p_001 | 5000 | 电脑 | 2.0 |通过以上结果可以看到,左表中对应时刻下的主键能从时态表中查询到对应时刻的时态数据。
B. "FOR SYSTEM_TIME AS OF ..."方式查询时态表数据
- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka 浏览商品数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table visit_tbl (" +
" left_product_id string," +
" left_visit_time bigint," +
" left_time_ltz AS TO_TIMESTAMP_LTZ(left_visit_time,3)," +
" WATERMARK FOR left_time_ltz AS left_time_ltz - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'visit-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//读取Kafka 商品信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table product_tbl (" +
" right_dt bigint," +
" right_product_id string," +
" right_product_name string," +
" right_price double," +
" PRIMARY KEY(right_product_id) NOT ENFORCED," +
" right_time_ltz AS TO_TIMESTAMP_LTZ(right_dt,3)," +
" WATERMARK FOR right_time_ltz AS right_time_ltz - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'product-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'debezium-json'" +
")");
//SQL 方式实现 Temporal Join
Table result = tableEnv.sqlQuery("" +
"select " +
" left_product_id,left_visit_time,right_product_name,right_price " +
"from visit_tbl " +
"JOIN product_tbl FOR SYSTEM_TIME AS OF visit_tbl.left_time_ltz " +
"ON left_product_id = right_product_id"
);
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka 浏览商品数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table visit_tbl (" +
" left_product_id string," +
" left_visit_time bigint," +
" left_time_ltz AS TO_TIMESTAMP_LTZ(left_visit_time,3)," +
" WATERMARK FOR left_time_ltz AS left_time_ltz - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'visit-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//读取Kafka 商品信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table product_tbl (" +
" right_dt bigint," +
" right_product_id string," +
" right_product_name string," +
" right_price double," +
" PRIMARY KEY(right_product_id) NOT ENFORCED," +
" right_time_ltz AS TO_TIMESTAMP_LTZ(right_dt,3)," +
" WATERMARK FOR right_time_ltz AS right_time_ltz - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'product-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'debezium-json'" +
")")
//SQL 方式实现 Temporal Join
val result = tableEnv.sqlQuery("" +
"select " +
" left_product_id,left_visit_time,right_product_name,right_price " +
"from visit_tbl " +
"JOIN product_tbl FOR SYSTEM_TIME AS OF visit_tbl.left_time_ltz " +
"ON left_product_id = right_product_id"
);
//打印结果
result.execute().print()以上通过"FOR SYSTEM_TIME AS OF ..."方式查询时态表中数据Java和Scala代码类似。代码编写完成启动后,首先向kafka "product-topic"中输入如下数据:
{"before": null,"after": {"right_dt": 1000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 3.0},"op": "c"}
{"before": null,"after": {"right_dt": 2000,"right_product_id": "p_002","right_product_name": "手机","right_price": 4.0},"op": "c"}
{"before": {"right_dt": 1000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 3.0},"after": {"right_dt": 3000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 9.0},"op": "u"}
{"before": {"right_dt": 2000,"right_product_id": "p_002","right_product_name": "手机","right_price": 4.0},"after": {"right_dt": 4000,"right_product_id": "p_002","right_product_name": "手机","right_price": 6.0},"op": "u"}
{"before": {"right_dt": 3000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 9.0},"after": {"right_dt": 5000,"right_product_id": "p_001","right_product_name": "电脑","right_price": 2.0},"op": "u"}然后向Kafka "visit-topic"中输入如下数据:
#visit-topic 输入浏览产品数据,形成左表数据
p_002,1000
p_001,2000
p_002,3000
p_001,4000
p_001,5000
p_002,5000
#当输入此条数据时,wm达到5000,会输出结果
p_003,10000当输入"p_003,10000"数据时,左右表watermark达到5000,会有对应结果输出,控制台输出结果如下:
+----+----------------+----------------+-------------------+------------+
| op |left_product_id |left_visit_time |right_product_name |right_price |
+----+----------------+----------------+-------------------+------------+
| +I | p_001 | 2000 | 电脑 | 3.0 |
| +I | p_002 | 3000 | 手机 | 4.0 |
| +I | p_002 | 5000 | 手机 | 6.0 |
| +I | p_001 | 4000 | 电脑 | 9.0 |
| +I | p_001 | 5000 | 电脑 | 2.0 |通过以上结果可以看到,左表中对应时刻下的主键能从时态表中查询到对应时刻的时态数据。
维度Join(Lookup Join)
Lookup Join 通常用于从外部系统查询维度数据丰富Flink主表,使用Lookup Join时要求左表(主表)必须有ProcessingTime时间列,维度表通过connector连接器获取,作为右表放在右侧 。在查询方式上 Lookup Join 与查询Temporal Join用法一样,通过"FOR SYSTEM_TIME AS OF ..."语法来完成,并指定左右表关联的条件列。Lookup维度表Temporal时态表相比,Lookup维表中没有时间列,而Temporal 时态表中有时间列,所以Lookup Join在一定程度上也可以看成是基于ProcessingTime 的Temporal Join。
以下是Lookup Join使用方式:
-- 创建Lookup 维度表
CREATE TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
);
-- 从维表中查询数据
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;下面通过案例来演示Lookup Join使用,案例中我们从Kafka "visit-topic"中读取用户浏览商品数据,然后通过MySQL Connector 获取商品信息形成维度数据进行Lookup Join操作。这里需要从MySQL中查询商品维度数据,所以我们首先在MySQL中创建对应的维度表,并插入数据。
#登录mysql,使用mydb库
user mydb;
#创建product_tbl商品信息表
create table mydb.product_tbl(product_id varchar(255) PRIMARY KEY,product_name varchar(255),price double );
#向product_tbl中插入数据
INSERT INTO product_tbl VALUES ('p_001', '电脑', 3.0), ('p_002', '手机', 4.0);由于前面已经在Kafka中创建过"visit-topic",这里不需重复创建,直接编写代码即可。
- Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka 浏览商品数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table visit_tbl (" +
" product_id string," +
" visit_time bigint," +
" proc_time AS PROCTIME()," +
" rowtime AS TO_TIMESTAMP_LTZ(visit_time,3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'visit-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//读取 MySQL 商品信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table product_tbl (" +
" product_id string," +
" product_name string," +
" price double" +
") with (" +
" 'connector' = 'jdbc'," +
" 'url' = 'jdbc:mysql://node2:3306/mydb'," +
" 'table-name' = 'product_tbl'," +
" 'username' = 'root'," +
" 'password' = '123456'" +
")");
//SQL 方式实现 Temporal Join
Table result = tableEnv.sqlQuery("" +
"select " +
" l.product_id,l.visit_time,l.rowtime,r.product_name,r.price " +
"from visit_tbl l " +
"JOIN product_tbl FOR SYSTEM_TIME AS OF l.proc_time r " +
"ON l.product_id = r.product_id"
);
//打印结果
result.execute().print();- Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka 浏览商品数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table visit_tbl (" +
" product_id string," +
" visit_time bigint," +
" proc_time AS PROCTIME()," +
" rowtime AS TO_TIMESTAMP_LTZ(visit_time,3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '5' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'visit-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//读取 MySQL 商品信息,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table product_tbl (" +
" product_id string," +
" product_name string," +
" price double" +
") with (" +
" 'connector' = 'jdbc'," +
" 'url' = 'jdbc:mysql://node2:3306/mydb'," +
" 'table-name' = 'product_tbl'," +
" 'username' = 'root'," +
" 'password' = '123456'" +
")")
//SQL 方式实现 Temporal Join
val result = tableEnv.sqlQuery("" +
"select " +
" l.product_id,l.visit_time,l.rowtime,r.product_name,r.price " +
"from visit_tbl l " +
"JOIN product_tbl FOR SYSTEM_TIME AS OF l.proc_time r " +
"ON l.product_id = r.product_id"
);
//打印结果
result.execute().print()以上代码编写完成后,首先向Kafka "visit-topic"中输入如下数据:
#visit-topic 输入浏览产品数据
p_001,1000
p_002,2000输入数据会与MySQL中查询到维度数据进行关联,输出结果如下:
+----+-----------+-----------+-------------+------+
| op |product_id |visit_time |product_name |price |
+----+-----------+-----------+-------------+------+
| +I | p_001 | 1000 | 电脑 | 3.0 |
| +I | p_002 | 2000 | 手机 | 4.0 |继续向MySQL中进行数据更新,操作如下:
INSERT INTO product_tbl
VALUES
('p_001', '电脑', 9.0),
('p_002', '手机', 6.0)
ON DUPLICATE KEY UPDATE
product_name = VALUES(product_name),
price = VALUES(price);然后再向Kafka "visit-topic"中输入如下数据,可以看到新输入的数据会与更新后的维度数据进行关联并输出结果,如下:
#visit-topic 输入浏览产品数据
p_001,3000
p_002,4000
#控制台输出结果如下
+----+-----------+-----------+-------------+------+
| op |product_id |visit_time |product_name |price |
+----+-----------+-----------+-------------+------+
| +I | p_001 | 3000 | 电脑 | 9.0 |
| +I | p_002 | 4000 | 手机 | 6.0 |SQL Joins对比
下面结合上文内容,对Flink SQL中几种Join特点和使用场景做对比,如下表所示。
| Flink Joins | 特点 | 使用场景 |
|---|---|---|
| Regular Joins | 通用Joins类型,不支持时间窗口,一侧的数据变化都会与另一侧流的所有数据进行关联,会保留所有数据状态 | 适用离线处理或小数据量场景 |
| Interval Joins | 流与流之间的连接,两条流一段时间区间内的Join | 适合事件时间双流join场景 |
| Temporal Joins | 连接两个实时流,其中维度实时流根据时间维度进行更新 | 实时流与动态更新的维度数据关联场景 |
| Lookup Joins | Flink实时流与外部存储介质维度数据进行关联,充实主表数据 | 实时数据关联维度数据场景 |
Window Join
Flink SQL中支持窗口连接(Window Join),允许在两个时间窗口进行Join连接。Window Join要求Join on条件中必须要有左右窗口的开始时间和结束时间相等条件。与SQL中普通Join不同,窗口连接不产生中间结果,而只在窗口的末尾产生最终结果,且Flink自动清理不再需要的窗口状态。
Flink SQL中Window Join支持INNER/LEFT/RIGHT/FULL OUTER/ANTI/SEMI JOIN,这些Window Join 在使用时都会通过窗口表值函数(TVF)来设置窗口,左右两表设置的窗口类型目前必须一致,Flink未来版本有可能支持左右表设置不同窗口类型。这里把INNER/LEFT/RIGHT/FULL OUTER统称为COMMON Join ,下面分别进行介绍。
通用Join(COMMON Join)
以下是Flink SQL 中Window INNER/LEFT/RIGHT/FULL OUTER Join的使用语法:
SELECT ...
FROM L [LEFT|RIGHT|FULL OUTER] JOIN R -- L 和R 是左右窗口
ON L.window_start = R.window_start AND L.window_end = R.window_end AND ...下面我们通过案例来演示Flink SQL中Window Full Outer Join 。该案例通过读取Kafka中"left-topic"和"right-topic"形成两个表,基于表设置窗口并进行Full Outer Join 连接,由于Java代码和Scala代码非常类似,这里只给出Java代码实现。
首先我们在Kafka中创建对应的topic:
#在Kafka中创建left-topic和right-topic
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic left-topic --partitions 3 --replication-factor 3
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic right-topic --partitions 3 --replication-factor 3
[root@node1 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list
...
left-topic
right-topic
...Window Full Outer Join实现代码如下:
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka left-topic数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table left_tbl (" +
" id int," +
" name string," +
" age int," +
" dt bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'left-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//读取Kafka right-topic数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table right_tbl (" +
" id int," +
" name string," +
" score int," +
" dt bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'right-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL 方式实现 Window Full Outer Join
TableResult result = tableEnv.executeSql("" +
"SELECT " +
" L.id," +
" L.name," +
" L.age," +
" R.score," +
" COALESCE(L.window_start,R.window_start) as window_start ," +
" COALESCE(L.window_end,R.window_end) as window_end " +
"FROM (" +
" SELECT * FROM TABLE(TUMBLE(TABLE left_tbl,DESCRIPTOR(rowtime), INTERVAL '5' SECOND))" +
") AS L " +
"FULL OUTER JOIN (" +
" SELECT * FROM TABLE(TUMBLE(TABLE right_tbl,DESCRIPTOR(rowtime), INTERVAL '5' SECOND))" +
") AS R " +
"ON L.id = R.id AND L.window_start = R.window_start AND L.window_end = R.window_end");
//输出结果
result.print();以上代码中对左右两表通过窗口表值函数(TVF)设置了窗口,然后通过FULL OUTER JOIN 进行了窗口关联,在关联条件中必须指定左右两个窗口的开始和结束时间相等。创建左右两表时使用了事件时间并设置了watermark,延迟时间为2秒,当左右两个窗口结束时间达到时,关联结果才会输出,这里设置了"table.exec.source.idle-timeout"自动推进watermark。此外,SQL语句中"COALESCE(col1,col2,default)"函数的意思是如果col1列不为null那就返回col1的值,否则返回不为null的col2的值,如果col1和col2的值都为null,那么返回default的值。
代码执行后,向Kafka "left-topic"和"right-topic"中按照如下顺序输入数据:
#kafka left-topic中输入数据
1,zs,18,1000
2,ls,19,2000
3,ww,20,3000
4,ml,21,4000
5,tq,22,4999
#kafka right-topic中输入数据
1,zs,100,2000
2,ls,200,1000
3,ww,300,4000
4,ml,400,3000
6,gb,600,4999
#kafka left-topic中输入数据,当输入此条数据时,窗口触发
6,xx,22,7000控制台输出量两个窗口Full Outer Join之后的结果如下:
+----+-------+-------+-------+-------+-------------------------+-------------------------+
| op | id | name | age | score | window_start | window_end |
+----+-------+-------+-------+-------+-------------------------+-------------------------+
| +I | 1 | zs | 18 | 100 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 |
| +I | 2 | ls | 19 | 200 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 |
| +I | 4 | ml | 21 | 400 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 |
| +I | 5 | tq | 22 |<NULL> | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 |
| +I |<NULL> |<NULL> |<NULL> | 600 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 |
| +I | 3 | ww | 20 | 300 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 |半连接(SEMI Join)
半连接(SEMI JOIN) 这种连接操作用于从一个表中选择那些在另一个表中存在的数据行,可以通过"where ... in"或者"where exists"语句实现半连接查询,使用示例如下:
#where...in语句半连接
SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE L.num IN (
SELECT num FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R
WHERE L.window_start = R.window_start AND L.window_end = R.window_end
);
#where exists 语句半连接
SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE EXISTS (
SELECT * FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R
WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end
);下面通过案例来说明Window semi join的使用。该案例同样读取Kafka "left-topic"和"right-topic"形成两张表,对两表设置5秒滑动窗口,并通过半连接查询在相同窗口内左表ID存在于右表中的数据。由于Java和Scala代码非常类似,这里只给出Java代码实现。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka left-topic数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table left_tbl (" +
" id int," +
" name string," +
" age int," +
" dt bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'left-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//读取Kafka right-topic数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table right_tbl (" +
" id int," +
" name string," +
" score int," +
" dt bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'right-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL 方式实现 Window Full Outer Join
TableResult result = tableEnv.executeSql("" +
"SELECT * FROM (" +
" SELECT * FROM TABLE(TUMBLE(TABLE left_tbl,DESCRIPTOR(rowtime), INTERVAL '5' SECOND))" +
") L WHERE EXISTS (" +
" SELECT * FROM ( " +
" SELECT * FROM TABLE(TUMBLE(TABLE right_tbl,DESCRIPTOR(rowtime), INTERVAL '5' SECOND)) " +
" ) R WHERE L.id = R.id AND L.window_start = R.window_start AND L.window_end = R.window_end" +
")" );
//输出结果
result.print();以上代码从Kafka中读取数据使用了事件时间,并设置watermark,延迟时间设置了2秒,并设置自动推进watermark。代码执行后,向Kafka "left-topic"和"right-topic"中输入如下数据:
#向Kafka left-topic中输入数据
1,x1,18,1000
1,x2,19,2000
2,x3,20,3000
3,x4,21,4000
4,x5,22,4999
#向Kafka right-topic中输入数据
1,s1,100,2000
2,s2,200,1000
2,s3,300,4000
5,s4,400,3000
6,s5,600,4999
#向Kafka left-topic中输入数据,触发窗口执行
7,x7,22,7000当窗口触发时,可以看到控制台输出相同窗口中左表ID存在于右表的数据。
+----+---+-----+----+-----+-------------------------+-------------------------+-------------------------+-------------------------+
| op |id |name |age | dt | rowtime | window_start | window_end | window_time |
+----+---+-----+----+-----+-------------------------+-------------------------+-------------------------+-------------------------+
| +I | 1 | x1 | 18 |1000 | 1970-01-01 08:00:01.000 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:04.999 |
| +I | 1 | x2 | 19 |2000 | 1970-01-01 08:00:02.000 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:04.999 |
| +I | 2 | x3 | 20 |3000 | 1970-01-01 08:00:03.000 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:04.999 |反连接(ANTI Join)
反连接(ANTI JOIN) 与半连接(SEMI JOIN)类似,半连接可以从一个表中选择那些在另一个表中存在的数据行,而反连接可以从一个表中选择那些不存在另一个表中的数据行。反连接使用方式有"where...not in ..."和"where not exists..."两种方式,如下示例:
#where...not in 语句反连接
SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE L.num NOT IN (
SELECT num FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.window_start = R.window_start AND L.window_end = R.window_end
);
#where not exists ... 语句反连接
SELECT *
FROM (
SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L WHERE NOT EXISTS (
SELECT * FROM (
SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R WHERE L.num = R.num AND L.window_start = R.window_start AND L.window_end = R.window_end
);下面通过案例来说明Window anti join的使用。该案例同样读取Kafka "left-topic"和"right-topic"形成两张表,对两表设置5秒滑动窗口,并通过反连接查询在相同窗口内左表ID不存在于右表中的数据。由于Java和Scala代码非常类似,这里只给出Java代码实现。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka left-topic数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table left_tbl (" +
" id int," +
" name string," +
" age int," +
" dt bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'left-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//读取Kafka right-topic数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table right_tbl (" +
" id int," +
" name string," +
" score int," +
" dt bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'right-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL 方式实现 Window Full Outer Join
TableResult result = tableEnv.executeSql("" +
"SELECT * FROM (" +
" SELECT * FROM TABLE(TUMBLE(TABLE left_tbl,DESCRIPTOR(rowtime), INTERVAL '5' SECOND))" +
") L WHERE NOT EXISTS (" +
" SELECT * FROM ( " +
" SELECT * FROM TABLE(TUMBLE(TABLE right_tbl,DESCRIPTOR(rowtime), INTERVAL '5' SECOND)) " +
" ) R WHERE L.id = R.id AND L.window_start = R.window_start AND L.window_end = R.window_end" +
")" );
//输出结果
result.print();以上代码与Window SEMI JOIN 代码几乎完全相同,只是将"EXISTS"改成"NOT EXISTS"即可。代码运行后,向Kafka "left-topic"和"right-topic"中输入如下数据:
#向Kafka left-topic中输入数据
1,x1,18,1000
1,x2,19,2000
2,x3,20,3000
3,x4,21,4000
4,x5,22,4999
#向Kafka right-topic中输入数据
1,s1,100,2000
2,s2,200,1000
2,s3,300,4000
5,s4,400,3000
6,s5,600,4999
#向Kafka left-topic中输入数据,触发窗口执行
7,x7,22,7000当窗口触发时,可以看到控制台输出相同窗口中左表ID不存在于右表的数据。
+----+---+-----+----+-----+-------------------------+-------------------------+-------------------------+-------------------------+
| op |id |name |age | dt | rowtime | window_start | window_end | window_time |
+----+---+-----+----+-----+-------------------------+-------------------------+-------------------------+-------------------------+
| +I | 3 | x4 | 21 |4000 | 1970-01-01 08:00:04.000 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:04.999 |
| +I | 4 | x5 | 22 |4999 | 1970-01-01 08:00:04.999 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:04.999 |Top-N
TOP-N查询是指按照表中某列排序获取前N个最大或者最小值,在Flink SQL中可以通过Over开窗函数实现针对批或流的TOP-N数据获取,其语法如下:
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER (
[PARTITION BY col1[, col2...]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]
) AS rownum
FROM table_name
)
WHERE rownum <= N [AND conditions]这里针对Over开窗函数不再解释,ROW_NUMBER() 会对每个分组和排序好的Over窗口内的每行数据分配一个唯一的连续编号,该编号从1开始,目前在Flink SQL中仅支持ROW_NUMBER() 函数,不支持RANK() OVER和DENSE_RANK()函数。最后的where条件可以过滤获取最大或者最小的前N行。
在Flink SQL处理实时数据中使用"ROW_NUMBER() OVER(PARTITION BY ... ORDER BY ...) AS rank"获取TOPN数据时,会随着实时数据的输入不断更新最终的TOPN结果,如果前N行数据发生了变化,那么更改的记录将作为变更日志流发送到下游。此外,我们还可以通过"ROW_NUMBER() OVER(PARTITION BY ... ORDER BY ...) AS rank"语句获取排序后rank为1的行来实现去重操作。
下面我们通过读取Kafka中基站日志数据,通过OVER开窗函数按照基站分组,按照通话时长升序排序获取TOP-2通话数据。由于Java代码和Scala代码类似,这里只给出Java代码实现。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL 通过 Over Window 实现TOPN 统计
Table result = tableEnv.sqlQuery("" +
"SELECT " +
" t.sid,t.duration,t.rk " +
"FROM (" +
" SELECT sid,duration," +
" ROW_NUMBER() OVER (PARTITION BY sid ORDER BY duration asc) as rk " +
" FROM stationlog_tbl" +
") t WHERE t.rk <= 2");
//打印结果
result.execute().print();以上代码编写完成后,向Kafka "stationlog-topic"中输入如下数据:
#向Kafka stationlog-topic中输入如下数据
001,181,182,busy,1000,30
001,182,183,fail,3000,20
001,183,184,busy,2000,10
002,184,185,busy,6000,40
002,181,183,busy,5000,80
002,181,182,busy,7000,70可以看到随着数据流的实时输入,控制台中输出结果如下:
+----+----+---------+---+
| op |sid |duration |rk |
+----+----+---------+---+
| +I |001 | 30 | 1 |
| -U |001 | 30 | 1 |
| +U |001 | 20 | 1 |
| +I |001 | 30 | 2 |
| -U |001 | 20 | 1 |
| +U |001 | 10 | 1 |
| -U |001 | 30 | 2 |
| +U |001 | 20 | 2 |
| +I |002 | 40 | 1 |
| +I |002 | 80 | 2 |
| -U |002 | 80 | 2 |
| +U |002 | 70 | 2 |Window Top-N
Flink SQL中针对每个窗口内的数据也可以获取TOP-N数据,这就是Window TOP-N查询,实现Window TOP-N查询也是通过Over开窗函数,其语法如下:
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER (
[PARTITION BY window_start,window_end,[,col_key1...]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]
) AS rownum
FROM table_name -- 该表是通过窗口表值函数TVF定义的窗口表
)
WHERE rownum <= N [AND conditions]Window TOP-N查询中只有在对应窗口结束时才会输出该窗口对应的TON-N结果,并且Flink会自动清除不再需要的窗口状态。下面我们通过读取Kafka中基站日志数据,设置5秒一个滑动窗口,针对每个滑动窗口使用Over开窗函数来获取TOP-2通话数据。由于Java代码和Scala代码类似,这里只给出Java代码实现。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//SQL 通过 Over Window 实现TOPN 统计
Table result = tableEnv.sqlQuery("" +
"SELECT " +
" t.window_start,t.window_end,t.sid,t.duration,t.rk " +
"FROM (" +
" SELECT window_start,window_end,sid,duration," +
" ROW_NUMBER() OVER (PARTITION BY window_start,window_end,sid ORDER BY duration asc) as rk " +
" FROM (" +
" SELECT " +
" window_start,window_end,sid,duration " +
" FROM " +
" TABLE(TUMBLE(TABLE stationlog_tbl,DESCRIPTOR(time_ltz),INTERVAL '5' SECONDS))" +
" )" +
") t WHERE t.rk <= 2");
//打印结果
result.execute().print();以上代码编写完成后,向Kafka "stationlog-topic"中输入如下数据:
#向Kafka stationlog-topic中输入如下数据
001,181,182,busy,1000,30
001,182,183,fail,3000,20
001,183,184,busy,2000,10
002,184,185,busy,4000,40
002,181,183,busy,3000,80
002,181,182,busy,1000,70
#输入该条数据,触发窗口执行
002,182,183,fail,9000,50可以看到当窗口触发执行后会统计每个窗口内对应的sid下的通话时长TOP-2数据,控制台中输出结果如下:
+----+------------------------+------------------------+----+---------+---+
| op | window_start | window_end |sid |duration |rk |
+----+------------------------+------------------------+----+---------+---+
| +I |1970-01-01 08:00:00.000 |1970-01-01 08:00:05.000 |001 | 10 | 1 |
| +I |1970-01-01 08:00:00.000 |1970-01-01 08:00:05.000 |001 | 20 | 2 |
| +I |1970-01-01 08:00:00.000 |1970-01-01 08:00:05.000 |002 | 40 | 1 |
| +I |1970-01-01 08:00:00.000 |1970-01-01 08:00:05.000 |002 | 70 | 2 |定义函数
在Flink的Table API和SQL编程中,Flink提供了丰富多样的内置函数来更好的进行数据分析,这些函数主要分为两大类:标量函数和聚合函数。标量函数针对一个或多个数据列,执行各种操作并返回单一值的函数,这些函数包括UUID()、UPPER()、LOWER()和REPLACE()等。而聚合函数则对多行数据进行处理,并生成一个汇总结果,典型的有COUNT()、SUM()和AVG()等。
Flink内置函数几乎囊括了标准SQL中常见的函数,而且还在持续地扩展中,以满足不断变化的数据分析需求。这些函数在Table API和SQL编程中的使用方式略有不同,具体细节可以在Flink官方网站上查阅内置函数的使用文档(https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/functions/systemfunctions/)。
除了内置函数,Flink还为用户提供了自定义函数的能力。在一些复杂的数据分析场景中,如果内置函数无法满足需求,用户可以编写自定义函数来实现特定的数据处理逻辑。下面对Flink Table API 和SQL编程中的自定义函数进行介绍。
自定义函数分类及使用
Flink Table API和SQL编程中支持的自定义函数有如下四种:
-
标量函数(Scalar Functions):将输入的一行数据中一个或者多个标量值转换成一个新的标量值,类似其他框架中的UDF函数,输入与输出是一对一的关系。
-
表函数(Table Functions):将输入的一行数据中一个标量值转换成多行数据,类似其他框架中的UDTF函数,输入与输出是一对多的关系。
-
聚合函数(Aggregate Functions):将输入的多行数据中一个或多个标量值转换聚合成一个新的标量值,类似其他框架中的UDAF,输入与输出是多对一的关系。
-
表聚合函数(Table Aggregate Functions)将输入的多行数据中一个或多个标量值转换聚合成多行数据,输入与输出是多对多的关系。
后续小节将会演示每种自定义函数的创建方式,当我们创建好自定义函数后,在Table API和SQL中使用自定义函数略有不同。在Table API中使用自定义函数时,可以先对自定义函数进行注册,然后再使用,或者直接通过内联方式使用自定义函数。而在SQL编程中使用自定义函数,只能先通过注册,然后再使用的方式。
// 定义函数逻辑
public static class SubstringFunction extends ScalarFunction {
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, end);
}
}
TableEnvironment env = TableEnvironment.create(...);
// 在 Table API 里不经注册直接“内联”调用函数
env.from("MyTable").select(call(SubstringFunction.class, $("myField"), 5, 12));
// 注册函数
env.createTemporarySystemFunction("SubstringFunction", SubstringFunction.class);
// 在 Table API 里调用注册好的函数
env.from("MyTable").select(call("SubstringFunction", $("myField"), 5, 12));
// 在 SQL 里调用注册好的函数
env.sqlQuery("SELECT SubstringFunction(myField, 5, 12) FROM MyTable");实际开发中我们使用SQL编程更多,所以这里建议对自定义函数进行注册然后再使用的方式。
自定义函数实战
标量函数(Scalar Functions)
标量函数就是自定义标量函数可以把0到多个标量值映射成1个标量值,实现自定义标量函数需要通过一个类继承ScalarFunction抽象类并实现其中的eval方法,在该方法中实现自己处理数据的业务逻辑。自己定义的类必须声明为 public ,而不是 abstract ,并且可以被全局访问,不允许使用非静态内部类或匿名类。
下面通过一个案例演示自定义标量函数定义及使用。该案例通过FlinkSQL读取Kafka中基站日志数据形成表,然后通过自定义标量函数实现通话信息的输出。
- Java代码
public class ConcatStringUDF extends ScalarFunction {
public String eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object... args) {
StringBuilder sb = new StringBuilder();
for (Object arg : args) {
sb.append(arg.toString()+"|");
}
return sb.substring(0,sb.toString().length()-1);
}
}
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//注册自定义标量函数
tableEnv.createTemporarySystemFunction("my_concat", ConcatStringUDF.class);
//Table API 方式调用自定义标量函数
/*Table result1 = tableEnv.from("stationlog_tbl")
.select($("sid"),
call("my_concat",
$("call_out"),
$("call_in"),
$("call_type"),
$("duration")).as("call_info")
);
result1.execute().print();*/
//SQL 方式调用自定义标量函数
Table result2 = tableEnv.sqlQuery("" +
"SELECT sid,my_concat(call_out,call_in,call_type,duration) as call_info " +
"FROM stationlog_tbl");
result2.execute().print();- Scala代码
object ScalarFunctionTest {
def main(args: Array[String]): Unit = {
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//注册自定义标量函数
tableEnv.createTemporarySystemFunction("my_concat", classOf[ConcatStringUDF])
//Table API 方式调用自定义标量函数
/*val result1: Table = tableEnv.from("stationlog_tbl")
.select($"sid",
call("my_concat", $"call_out", $"call_in", $"call_type", $"duration").as("call_info"))
result1.execute().print()*/
//SQL 方式调用自定义标量函数
val result2: Table = tableEnv.sqlQuery("" +
"select " +
" sid," +
" my_concat(call_out,call_in,call_type,duration) as call_info " +
"from stationlog_tbl")
result2.execute().print()
}
}
class ConcatStringUDF extends ScalarFunction {
@varargs
def eval(@DataTypeHint(inputGroup = InputGroup.ANY) args: AnyRef*): String = {
args.map(f => f.toString).mkString("|")
}
}以上Java代码和Scala代码实现自定义标量函数进行了注册,并且包含Table API和SQL编程使用自定义标量函数方式。自定义标量函数需要注意如下几点:
-
自定义标量函数类必须是public的,Java中需要单独写出该类,由于Scala语法问题,默认Scala中定义的类是public的,可以和Object写在一起。
-
自定义标量函数时,传入的参数Flink都会自动推断类型,可以按照实际需要传入参数并指定每个参数类型。
-
在以上案例中我们传入多个参数,在Java中通过Object ...来接收多个参数,在Scala中通过AnyRef*来接收这些参数,需要单独指定类型推断"@DataTypeHint(inputGroup = InputGroup.ANY)",表示传入的是多个不同类型的参数。
-
在Scala代码实现中如果一个方法是"AnyRef*"多参数的,那么需要通过"@varargs"注解进行标注。
以上代码中编写完成,向Kafka "stationlog-topic"中输入如下数据:
001,181,182,busy,1000,10
002,182,183,fail,3000,20
001,183,184,busy,2000,30
002,184,185,busy,6000,40
003,181,183,busy,5000,50控制台中输出结果如下:
+----+------+------------------+
| op | sid | call_info |
+----+------+------------------+
| +I | 001 | 181|182|busy|10 |
| +I | 002 | 182|183|fail|20 |
| +I | 001 | 183|184|busy|30 |
| +I | 002 | 184|185|busy|40 |
| +I | 003 | 181|183|busy|50 |表函数(Table Functions)
Flink 中自定义表函数与自定义标量函数一样,函数的参数可以是一个或者多个标量,但与标量函数只能返回一个值不同,表函数可以返回任意多行,类似标准SQL中的"explode"函数,并且表函数返回的每行中还可以由多个列组成。
实现自定义表函数需要继承TableFunction抽象类并实现其中的eval方法,实现类中可以有多个参数不同的eval重载方法,会自动按照传入的参数进行匹配,evel方法中需要通过"collect"方法发送返回的数据。自己定义的类必须声明为 public ,而不是 abstract ,并且可以被全局访问,不允许使用非静态内部类或匿名类。
在Table API中,表函数是通过".joinLateral(...)"或者".leftOuterJoinLateral(...)"来使用的,在前面小节中讲解通过表函数查询时态数据我们接触过"joinLateral(...)"的使用,在SQL编程中是通过"LATERAL TABLE(表函数)"方式来使用表函数的,与Table API中"joinLateral(...)"功能一样。
下面通过一个案例来演示表函数的定义与使用。案例中通过Flink SQL读取Kafka中数据形成表,针对表中某列数据进行切分,返回切分数据内容及切分各部分字符数。
- Java代码
@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))
public class SplitStringUDTF extends TableFunction<Row> {
public void eval(String str) {
String[] split = str.split("\\|");
for (String s : split) {
collect(Row.of(s,s.length()));
}
}
}
public class TableFunctionTest {
public static void main(String[] args) {
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka 数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table str_tbl (" +
" id string," +
" strs string," +
" dt bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//注册自定义表函数
tableEnv.createTemporarySystemFunction("my_split", SplitStringUDTF.class);
//Table API 方式调用自定义表函数
/*Table result1 = tableEnv.from("str_tbl")
.joinLateral(call("my_split", $("strs")).as("str","len"))
.select($("id"),$("str"),$("len"));
result1.execute().print();*/
//SQL 方式调用自定义表函数
Table result2 = tableEnv.sqlQuery("" +
"select id,str,len from str_tbl," +
"lateral table(my_split(strs)) as T(str,len)");
result2.execute().print();
}
}- Scala代码
object TableFunctionTest {
def main(args: Array[String]): Unit = {
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka 数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table str_tbl (" +
" id string," +
" strs string," +
" dt bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(dt,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//注册自定义表函数
tableEnv.createTemporarySystemFunction("my_split", classOf[SplitStringUDTF])
//Table API 方式调用自定义表函数
/*val result1: Table = tableEnv.from("str_tbl")
.joinLateral(call("my_split", $"strs").as("str", "len"))
.select($"id", $"str", $"len")
result1.execute().print()*/
//SQL 方式调用自定义表函数
val result2: Table = tableEnv.sqlQuery("" +
"select " +
" id," +
" str," +
" len " +
"from " +
" str_tbl," +
" lateral table(my_split(strs)) as T(str,len)")
result2.execute().print()
}
}
@FunctionHint(output = new DataTypeHint("ROW<word STRING, length INT>"))
class SplitStringUDTF extends TableFunction[Row] {
def eval(str: String): Unit = {
str.split("\\|").foreach(s => collect(Row.of(s, Int.box(s.length))))
}
}以上Java代码和Scala代码实现自定义表函数进行了注册,并且包含Table API和SQL编程使用自定义表函数方式。自定义表函数需要注意如下几点:
-
自定义表函数类必须是public的,Java中需要单独写出该类,由于Scala语法问题,默认Scala中定义的类是public的,可以和Object写在一起。
-
自定义表函数时,传入的参数Flink都会自动推断类型,可以按照实际需要传入参数并指定每个参数类型。
-
实现TableFuncation抽象类时,需要指定返回的数据类型,如果包含多列需要执行返回类型为Row类型,Row类型每个位置都会形成返回的单独列,必须通过"@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))"方式指定Row中返回数据列的类型,并且类型必须为引用类型。
-
Java中的基本数据类型到引用数据类型会自动装箱操作,Scala中没有自动装箱操作,int类型需要通过"Int.box(value)"来指定为引用类型。
以上代码中编写完成,向Kafka "stationlog-topic"中输入如下数据:
1,zhangsan|lisi,1000
2,wangwu|maliu,3000
3,tianqi|gaoba,2000控制台中输出结果如下:
+----+-----+----------+------+
| op | id | str | len |
+----+-----+----------+------+
| +I | 1 | zhangsan | 8 |
| +I | 1 | lisi | 4 |
| +I | 2 | wangwu | 6 |
| +I | 2 | maliu | 5 |
| +I | 3 | tianqi | 6 |
| +I | 3 | gaoba | 5 |聚合函数(Aggregate Functions)
自定义聚合函数可以把一个表多行(每行可以有一列或者多列)聚合成一个标量值。如下图所示,表MyTable中有三列:id、name、price,表中有5行数据,现在要找出表中价格最贵的price,就可以通过自定义聚合函数来实现。
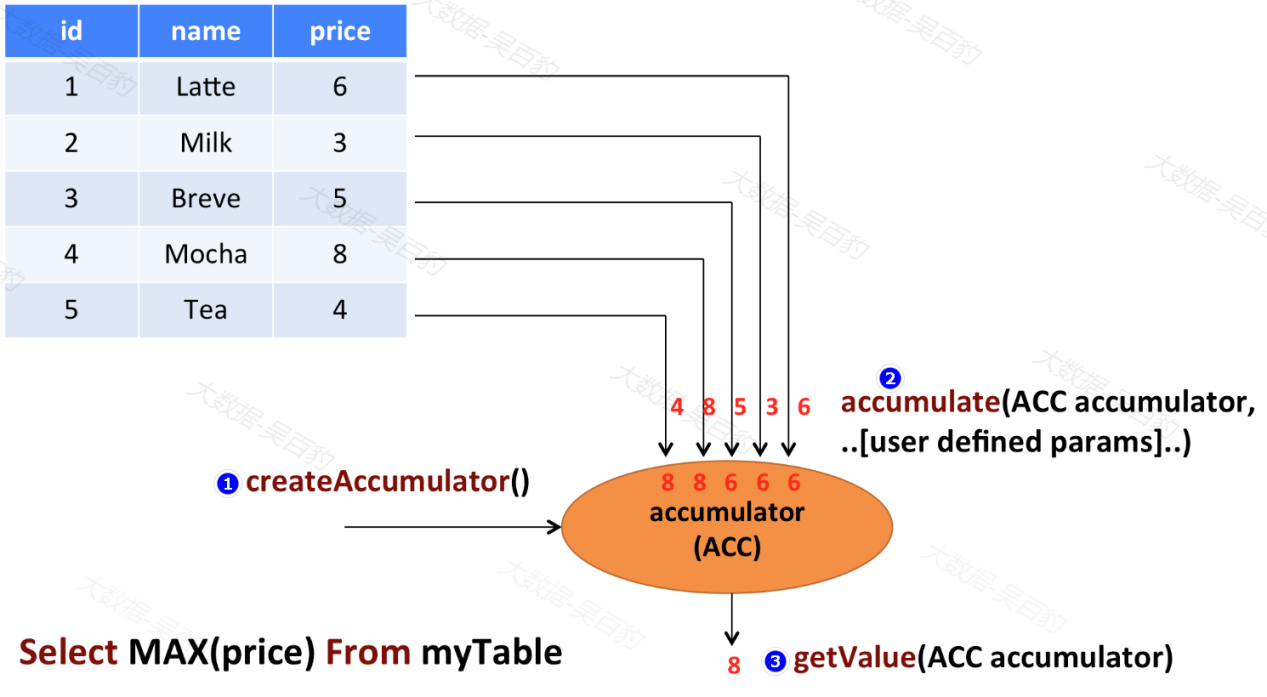
如上图所示,Flink Table API和SQL编程中针对实时数据自定义聚合函数需要继承AggregateFunction抽象类并实现其中3个方法:
-
createAccumulator():首先创建accumulator用于存储聚合中间结果状态。
-
accumulate():每行需要聚合的数据通过该方法进行计算,更新accumulator的值。该方法可以有多个不同参数和类型的重载,需要用户自己定义,根据业务情况传入对应的参数。
-
getValue():最后当所有数据都处理完成之后,调用该方法计算和返回最终聚合结果。
用户自己定义继承AggregateFunction的类必须声明为 public ,而不是 abstract ,并且可以被全局访问,不允许使用非静态内部类或匿名类。实现类中的所有方法必须都是public的,不能是static的,并且名字和上面一样写的一样。
下面通过一个案例来演示聚合函数的定义与使用。该案例通过FlinkSQL读取Kafka中基站日志数据形成表,然后通过自定义聚合函数实现每个基站平均通话时长统计。
- Java代码
public class AvgDurationUDAF extends AggregateFunction<Double,Tuple2<Long,Integer>> {
//初始化累加器
@Override
public Tuple2<Long, Integer> createAccumulator() {
return Tuple2.of(0L,0);
}
//累加器的计算逻辑
public void accumulate(Tuple2<Long, Integer> acc, Long duration){
//累加器第一个字段为总通话时长,第二个字段为通话次数
acc.f0 += duration;
acc.f1 += 1;
}
//返回结果
@Override
public Double getValue(Tuple2<Long, Integer> accumulator) {
if(accumulator.f1 == 0){
return null;
}else {
return accumulator.f0*1.0/accumulator.f1;
}
}
}
public class AggregateFunctionTest {
public static void main(String[] args) {
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//注册自定义聚合函数
tableEnv.createTemporarySystemFunction("my_avg", AvgDurationUDAF.class);
//Table API 方式调用自定义表函数
/*Table result1 = tableEnv.from("stationlog_tbl")
.groupBy($("sid"))
.select($("sid"),
call("my_avg", $("duration")).as("avg_duration")
);
result1.execute().print();*/
//SQL 方式调用自定义表函数
Table result2 = tableEnv.sqlQuery("" +
"select sid, my_avg(duration) as avg_duration " +
"from stationlog_tbl " +
"group by sid");
result2.execute().print();
}
}- Scala代码
object AggregateFunctionTest {
def main(args: Array[String]): Unit = {
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//注册自定义聚合函数
tableEnv.createTemporarySystemFunction("my_avg", classOf[AvgDurationUDAF])
//Table API 方式调用自定义表函数
// val result1: Table = tableEnv.from("stationlog_tbl")
// .groupBy($"sid")
// .select($"sid",
// call("my_avg", $"duration").as("avg_duration")
// )
//
// result1.execute().print()
//SQL 方式调用自定义表函数
val result2: Table = tableEnv.sqlQuery("" +
"select sid,my_avg(duration) as avg_duration " +
"from stationlog_tbl " +
"group by sid"
)
result2.execute().print()
}
}
class AvgDurationUDAF extends AggregateFunction[JDouble,JTuple2[JLong,JInteger]]{
//初始化累加器
override def createAccumulator(): JTuple2[JLong,JInteger] = JTuple2.of(0L,0)
//累加器的计算逻辑
def accumulate(acc: JTuple2[JLong,JInteger], duration: JLong): Unit = {
acc.f0 = acc.f0 + duration
acc.f1 = acc.f1 + 1
}
//返回结果
override def getValue(acc: JTuple2[JLong,JInteger]): JDouble = {
if(acc.f1 == 0){
null
}else{
acc.f0 / acc.f1
}
}
}以上Java代码和Scala代码都实现了自定义类继承AggregateFunction并实现其中方法完成自定义聚合函数。抽象类AggregateFunction<T,ACC>中,T代表聚合返回的结果,ACC代表聚合中间结果的类型,在编写代码时需要注意以下几点:
-
自定义聚合函数中ACC选择是Tuple类型,由于涉及到更新ACC的值,而Scala中的Tuple类型不能支持更新,所以这里在编写Scala代码时选择的是"org.apache.flink.api.java.tuple.Tuple2"类型,并且Tuple类型中的类型也都是Java对应的对象,Flink 的类型推导对于 Scala 的类型推导支持的不是很好,这样可以避免Scala编程中底层转换对象的一些错误。
-
自定义聚合函数中的accumulate方法需要自己手动写出,并不会override的方式实现,聚合业务需要传入几个参数则定义传入几个参数的实现即可。例如聚合有2个列传入,相当于2个参数,那么就可以这样定义accumulate方法:accumulate(acc,col1,col2)
-
getValue()统计每个基站的通话平均值并返回,由于Flink多并行执行,所以有可能一些并行度中没有数据导致分母为零,所以这里判断分母是否为零,如果为零则返回null即可。实际上在Java底层自动屏蔽了线程中分母为零的情况,而在Scala代码中没有屏蔽,所以这里统计进行判断处理。
以上代码中编写完成,向Kafka "stationlog-topic"中输入如下数据:
001,181,182,busy,1000,10
002,182,183,fail,3000,20
001,183,184,busy,2000,30
002,184,185,busy,6000,40
001,181,183,busy,5000,50可以看到最终结果输入如下:
+----+-----+--------------+
| op | sid | avg_duration |
+----+-----+--------------+
| +I | 001 | 10.0 |
| +I | 002 | 20.0 |
| -U | 001 | 10.0 |
| +U | 001 | 20.0 |
| -U | 002 | 20.0 |
| +U | 002 | 30.0 |
| -U | 001 | 20.0 |
| +U | 001 | 30.0 |表聚合函数(Table Aggregate Functions)
表聚合函数可以把一个表多行(每行可以有一列或者多列)聚合成多行形成一张表,即聚合结果中可以有多行多列。如下图所示,表MyTable中有三列:id、name、price,表中有5行数据,现在要找出表中价格最贵的top2 price,类似top2计算,就可以通过自定义表聚合函数来实现。
如上图所示,Flink Table API和SQL编程中针对实时数据自定义表聚合函数需要继承TableAggregateFunction抽象类并实现其中3个方法:
-
createAccumulator():首先创建accumulator用于存储聚合中间结果状态。
-
accumulate():每行需要聚合的数据通过该方法进行计算,更新accumulator的值。该方法可以有多个不同参数和类型的重载,需要用户自己定义,根据业务情况传入对应的参数。
-
emitValue():最后当所有数据都处理完成之后,调用该方法返回最终聚合结果。
用户自己定义继承TableAggregateFunction的类必须声明为 public ,而不是 abstract ,并且可以被全局访问,不允许使用非静态内部类或匿名类。实现类中的所有方法必须都是public的,不能是static的,并且名字和上面一样写的一样。
需要特别注意的是目前表聚合函数只能通过Table API进行调用,不支持SQL方式使用自定义表聚合函数。
下面通过一个案例来演示表聚合函数的定义与使用。该案例通过FlinkSQL读取Kafka中基站日志数据形成表,然后通过自定义表聚合函数实现每个基站通话时长top2。
- Java代码
public class Top2DurationTableUDAF extends TableAggregateFunction<Tuple2<Long,Integer>,Tuple2<Long,Long>> {
//创建累加器,累加器存储最大值和次大值
@Override
public Tuple2<Long, Long> createAccumulator() {
return Tuple2.of(Long.MIN_VALUE,Long.MIN_VALUE);
}
//累加器的计算逻辑:判断传入的duration是否大于累加器中的最大值或者次大值,如果大于则替换
public void accumulate(Tuple2<Long, Long> acc, Long duration){
if(duration>acc.f0){
acc.f1 = acc.f0;
acc.f0 = duration;
}else if(duration>acc.f1){
acc.f1 = duration;
}
}
//返回结果,将累加器中的最大值和次大值返回
public void emitValue(Tuple2<Long, Long> acc, Collector<Tuple2<Long, Integer>> out){
if(acc.f0!=Long.MIN_VALUE){
out.collect(Tuple2.of(acc.f0,1));
}
if(acc.f1!=Long.MIN_VALUE){
out.collect(Tuple2.of(acc.f1,2));
}
}
}
public class TableAggregateFunctionTest {
public static void main(String[] args) {
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")");
//注册自定义表聚合函数
tableEnv.createTemporarySystemFunction("my_top2", Top2DurationTableUDAF.class);
//Table API 方式调用自定义表聚合函数
Table result1 = tableEnv.from("stationlog_tbl")
.groupBy($("sid"))
.flatAggregate(call("my_top2", $("duration")).as("top2_duration","rank"))
.select($("sid"), $("top2_duration"), $("rank"));
result1.execute().print();
}
}- Scala代码
object TableAggregateFunctionTest {
def main(args: Array[String]): Unit = {
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig.set("table.exec.source.idle-timeout", "5000")
//读取Kafka基站日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table stationlog_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")")
//注册自定义表聚合函数
tableEnv.createTemporarySystemFunction("my_top2", classOf[Top2DurationTableUDAF])
//Table API 方式调用自定义表聚合函数
val result: Table = tableEnv.from("stationlog_tbl")
.groupBy($"sid")
.flatAggregate(call("my_top2", $"duration").as("top2_duration", "rank"))
.select($"sid", $"top2_duration", $"rank")
result.execute().print()
}
}
/**
* 自定义表聚合函数,获取每个基站通话时长top2
* TableAggregateFunction<T,ACC>: T-最终聚合结果类型,ACC-累加器类型
*/
class Top2DurationTableUDAF extends TableAggregateFunction[JTuple2[JLong,JInteger],JTuple2[JLong,JLong]]{
//创建累加器,累加器存储最大值和次大值
override def createAccumulator(): JTuple2[JLong, JLong] = {
JTuple2.of(JLong.MIN_VALUE,JLong.MIN_VALUE)
}
//累加器的计算逻辑:判断传入的duration是否大于累加器中的最大值或者次大值,如果大于则替换
def accumulate(acc: JTuple2[JLong, JLong], duration: JLong): Unit = {
if(duration > acc.f0){
acc.f1 = acc.f0
acc.f0 = duration
}else if(duration > acc.f1){
acc.f1 = duration
}
}
//返回结果,将累加器中的最大值和次大值返回
def emitValue(acc: JTuple2[JLong, JLong], out: Collector[JTuple2[JLong, JInteger]]): Unit = {
if(acc.f0 != JLong.MIN_VALUE){
out.collect(JTuple2.of(acc.f0,1))
}
if(acc.f1 != JLong.MIN_VALUE){
out.collect(JTuple2.of(acc.f1,2))
}
}
}以上Java代码和Scala代码都实现了自定义类继承TableAggregateFunction并实现其中方法完成自定义表聚合函数。抽象类TableAggregateFunction<T,ACC>中,T代表聚合返回的结果,ACC代表聚合中间结果的类型。在代码中ACC定义为Tuple2<Long,Long>用来存储每个基站通话时长top2,tuple2第一个位置是通话时长最大值,tuple2第二个位置是通话时长次大值。T定义成了Tuple2<Long,Integer>,表示最终返回Tuple2类型数据,返回的tuple2第一个位置表示最大值/次大值,第二个位置表示对应的rank排名。
在编写代码时需要注意以下几点:
-
自定义表聚合函数中ACC选择是Tuple类型,由于涉及到更新ACC的值,而Scala中的Tuple类型不能支持更新,所以这里在编写Scala代码时选择的是"org.apache.flink.api.java.tuple.Tuple2"类型,并且Tuple类型中的类型也都是Java对应的对象,Flink 的类型推导对于 Scala 的类型推导支持的不是很好,这样可以避免Scala编程中底层转换对象的一些错误。
-
自定义表聚合函数中的accumulate方法需要自己手动写出,并不会override的方式实现,聚合业务需要传入几个参数则定义传入几个参数的实现即可。例如聚合有2个列传入,相当于2个参数,那么就可以这样定义accumulate方法:accumulate(acc,col1,col2)
-
emitValue()统计每个基站通话时长top2,通过Collector来返回多行结果。
以上代码中编写完成,向Kafka "stationlog-topic"中输入如下数据:
001,181,182,busy,1000,30
001,182,183,fail,3000,20
001,183,184,busy,2000,10
002,184,185,busy,6000,40
002,181,183,busy,5000,80
002,181,182,busy,7000,70可以看到最终结果输入如下:
+----+-----+---------------+-----+
| op | sid | top2_duration |rank |
+----+-----+---------------+-----+
| +I | 001 | 30 | 1 |
| -D | 001 | 30 | 1 |
| +I | 001 | 30 | 1 |
| +I | 001 | 20 | 2 |
| -D | 001 | 30 | 1 |
| -D | 001 | 20 | 2 |
| +I | 001 | 30 | 1 |
| +I | 001 | 20 | 2 |
| +I | 002 | 40 | 1 |
| -D | 002 | 40 | 1 |
| +I | 002 | 80 | 1 |
| +I | 002 | 40 | 2 |
| -D | 002 | 80 | 1 |
| -D | 002 | 40 | 2 |
| +I | 002 | 80 | 1 |
| +I | 002 | 70 | 2 |