
你有没有遇到过这样的情况:
AI 模型在训练时 GPU 利用率忽高忽低,容器资源明明给够了,训练时长却总是超出预期?或者在推理服务上线后,延迟时不时抖动,重启一下又好了,但问题根本找不到?
- "我的模型在裸机上跑只要 2 小时,放到容器里怎么变成 3 小时了?"
- "资源都给了,CPU 和内存也没瓶颈,我不知道还要看什么。"
很多团队在模型效果验证通过后,真正进入上线或规模化使用时,往往会遇到一个共同问题:GPU 看起来很忙,但整体效率并不高;系统投入不少,性能瓶颈却不容易快速定位。
这正是 AI Profiling 的价值所在。
在字节跳动内部,所有低 SMA 的训练任务以及推理服务上线前的压测环节,都会进行 AI Profiling 采集,帮助研发同学通过可视化分析快速定位 GPU 效率低下与性能抖动问题。基于这一内部实践,字节跳动 STE 系统技术与工程团队联合火山引擎容器团队,将该能力产品化封装并融入容器服务 VKE,形成了 VKE AI Profiling ------ 专为容器环境设计的 AI 性能剖析能力,现已对外提供服务。
本文将结合一个真实的 ResNet18 训练案例,介绍如何使用 VKE AI Profiling 做一次完整的性能排查与优化。
AI Profiling:为什么要做,以及该用什么工具
为什么大模型训练与推理需要 Profiling
过去做传统应用,性能问题更多集中在 CPU、内存、数据库和网络。为什么到了大模型这里,还要专门搞一个 Profiling?
答案是------性能链路变长了,而且长得不是一星半点。
以一个典型的企业大模型系统为例:
- 最上层是业务应用和调用接口;
- 中间跑着推理服务、Embedding 服务、批量评测;
- 最下面还叠着模型训练、微调、GPU 调度和算力利用。
这时候性能问题不再只是"某个接口慢了一秒"这么简单。它可能来自:
- 数据加载跟不上,GPU 眼巴巴等着输入;
- Host 到 Device 的数据传输没做 overlap,白白浪费时间;
- 还在用 FP32,Tensor Core 的加速收益一点没吃到;
- Python 框架调度、同步操作打断了训练流水线;
- 多个采样工具分散使用,分析过程重、门槛高、协同成本高。
对于企业来说,Profiling 的意义不是"看一眼时间线截图发群里",而是能快速回答这几个问题:
- 当前瓶颈到底在哪------数据、传输、算子、框架、还是同步?
- 这个问题值不值得我花时间优化?
- 如果优化了,能省多少算力、提升多少迭代效率?
这也是 VKE AI Profiling 更适合企业工程实践的地方:它把使用门槛尽量压下来,让性能分析从"专家工具"变成"研发团队每个人都能上手用起来的工程能力"。
常见 Profiling 工具怎么选
很多团队第一次做 AI 性能分析时,常常会问一个问题:已经有 PyTorch Profiler、Nsight System 这些工具了,为什么还需要统一的 AI Profiling 能力?
核心不在于"谁替代谁",而在于不同工具解决的问题层次不同。
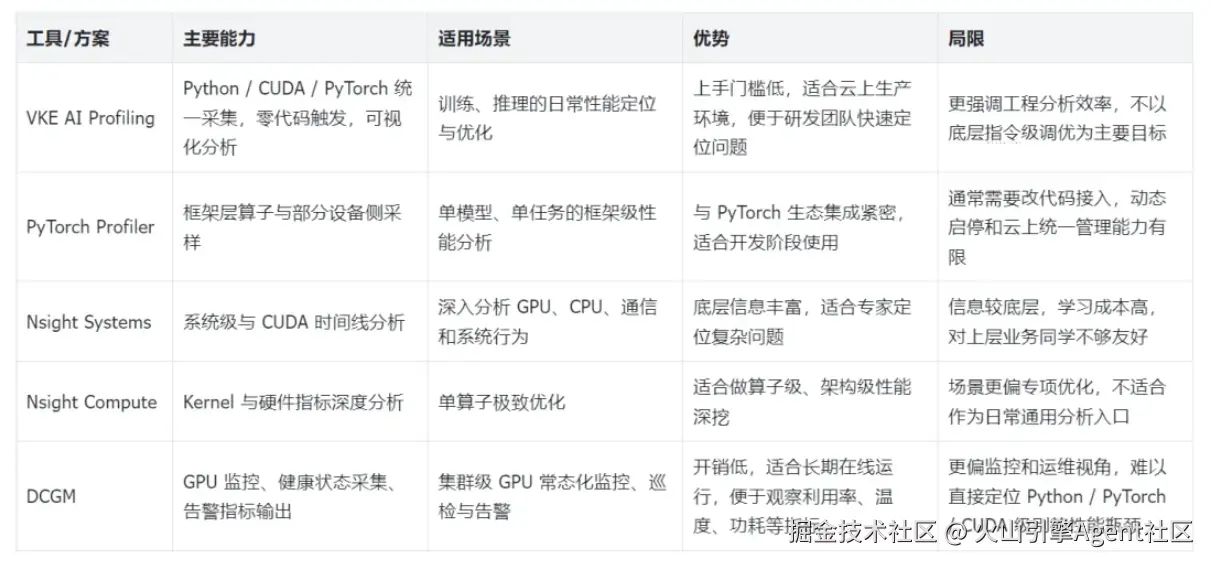
如果从企业落地角度总结:
- 研发同学日常排查,更需要低门槛、低侵入、面向训练和推理全流程的能力;
- 性能专家深挖极限优化,仍然需要更底层的专项工具;
- 最理想的方式不是只选一个工具,而是先用统一 Profiling 能力快速定位,再按需进入更深层分析。
从思路到实战:一个真实的 ResNet18 训练案例
为了让过程更具体,我们选了一个相对经典、容易复现的训练任务做演示:
- 模型: ResNet18
- 数据集: CIFAR10
- 框架: PyTorch 2.1.0,TorchVision 0.16.0
- GPU: 业内主流训练卡
- Profiling 时长: 5 秒
- 采集项: python / cuda / pytorch
虽然这是一个图像训练场景,但分析思路同样适用于其他训练与推理任务。例如:
- 做模型微调或蒸馏时,可以用同样方法看训练过程瓶颈;
- 做推理服务时,也可以按类似方式分析数据预处理、Host/Device 拷贝、算子执行和同步等待。
换句话说,案例虽然是训练,但方法论并不局限于训练。 接下来我们就以这个 ResNet18 任务为例,完整走一遍 Profiling 的分析与优化流程。
初始代码:功能正确,但不一定高效
我们准备了一个基础版的 ResNet18 训练脚本,逻辑非常常见:
- 使用 DataLoader 读取 CIFAR10;
- 将输入搬到 GPU;
- 前向、反向、更新参数;
- 周期性打印 loss。
这类代码通常能顺利跑通,但不代表性能已经合理。很多企业真实项目也是类似情况:先可用,再优化。问题在于,如果缺少性能分析能力,优化往往只能靠经验猜。
为了让后面的优化动作更容易理解,先给出一份可直接运行的简化版训练代码。后文提到的 num_workers、pin_memory、AMP 等优化,都是基于这类标准训练循环逐步展开的。这里将 num_epochs 写为 5,更接近日常训练任务;但对于 Profiling 来说,关注重点通常是稳定阶段的若干个 step,因此实际采集时并不依赖完整跑完全部 epoch。
ini
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as T
device = torch.device("cuda:0")
transform = T.Compose(
[
T.Resize(224),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
)
train_set = torchvision.datasets.CIFAR10(
root="./data",
train=True,
download=True,
transform=transform,
)
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=32,
shuffle=True,
num_workers=1,
)
model = torchvision.models.resnet18(weights=None).to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
model.train()
deftrain_step(data):
inputs = data[0].to(device)
labels = data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
return loss.item()
num_epochs = 5
for epoch inrange(num_epochs):
running_loss = 0.0
for i, batch_data inenumerate(train_loader):
loss = train_step(batch_data)
running_loss += loss
if i % 100 == 99:
print(
f"Epoch [{epoch + 1}/{num_epochs}], "
f"Step [{i + 1}], Loss: {running_loss / 100:.4f}"
)
running_loss = 0.0如果只看后面的局部代码片段,确实容易让人误以为是在"单点改参数"。而放在完整训练循环里看,会更容易理解每一步优化究竟改动了哪里、为什么会产生收益。
零代码采集:先看到问题,再决定值不值得改
使用 VKE AI Profiling 时,不需要先为排查问题大幅改造代码。一次典型操作流程如下:
- 在 VKE 控制台进入 AI Profiling。
- 选择目标训练任务对应的命名空间、容器组和容器。
- 勾选采集项:
python、cuda、pytorch。 - 将采集时间设置为 5 秒,抓取几个稳定 step 即可。
- 下载产物后,在 Perfetto 中查看时间线。
这一步的价值非常直接:先用尽可能低的成本,拿到"问题发生在哪里"的证据。
对于企业团队来说,这比"凭经验改一轮再看结果"更高效,也更容易在研发、算法、平台团队之间达成一致。
从时间线里看问题:三类最常见的训练瓶颈
在这次测试里,我们重点看到了三类很典型的问题:
- 数据加载阶段过慢,GPU 有等待;
- Host 到 Device 的数据拷贝仍有明显耗时;
- 计算阶段没有使用混合精度,训练 step 耗时偏高。
下面按排查顺序展开。
先看基线版本的时间线,可以明显看到 DataLoader 相关阶段占用了较长时间,CPU 侧供数不足时,GPU 计算无法被持续喂满。
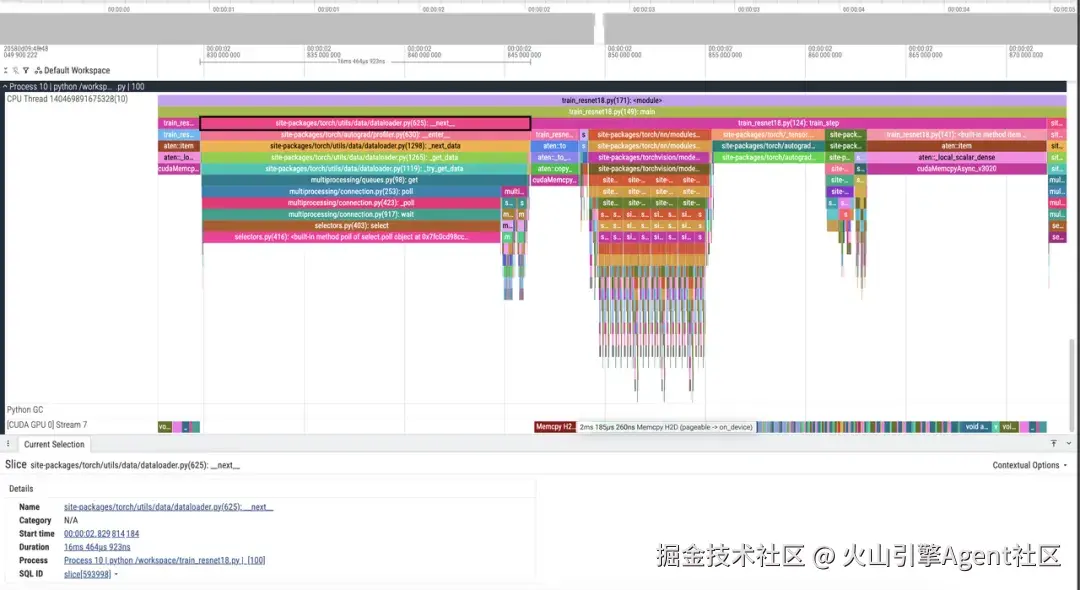
优化一:先解决数据加载瓶颈
在基线版本里,DataLoader 使用 num_workers=1。这在功能上没有问题,但对训练吞吐通常不友好。
当 CPU 侧数据准备跟不上时,GPU 即使算力充足,也会在时间线上表现为间歇性空闲。从成本来说,这是一类非常"亏"的问题,因为它意味着昂贵的 GPU 没有被充分利用。
优化方式很直接:提升 num_workers,让数据加载并行起来。
ini
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=32,
shuffle=True,
num_workers=8,
)在实测环境中,数据加载耗时变化如下:
num_workers=1:16.5 msnum_workers=8:1.49 ms
这一步优化后,数据加载从 16.5ms 降到了 1.49ms。GPU 不用再等着 CPU 喂数据了。
对于在线推理或离线训练系统来说,这类问题都可以理解为"计算资源充足,但上游数据准备没有跟上",本质上是同一类资源错配问题。
从优化后的时间线也能看到,DataLoader 阶段被显著压缩,后续计算段更容易连续铺开。
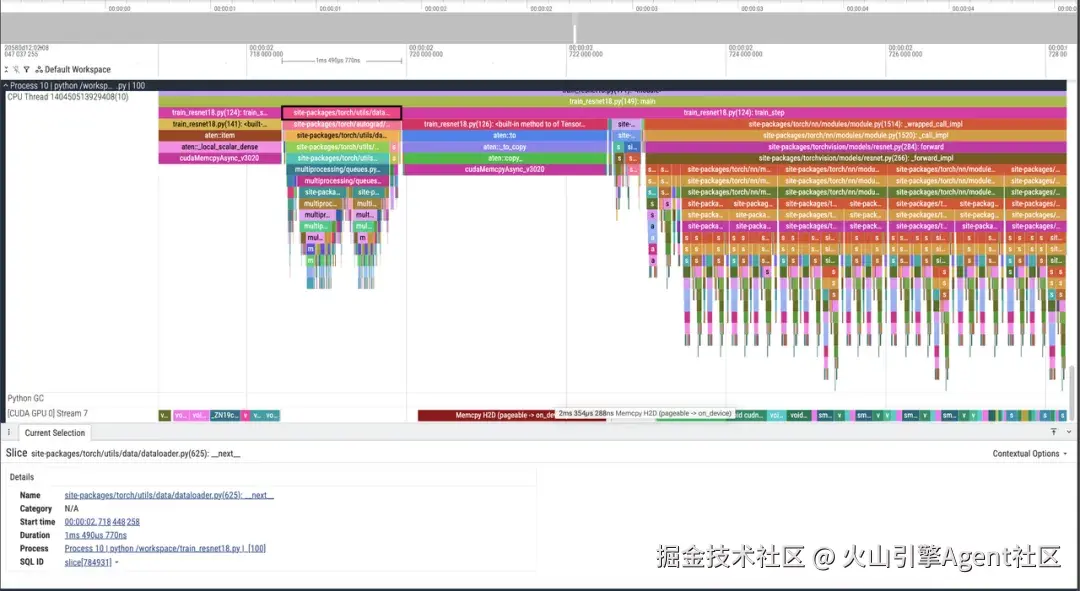
优化二:让数据拷贝尽量和计算重叠
第二个常见问题是数据从 CPU 内存拷贝到 GPU 显存的方式不够高效。
如果只是简单地把数据 .to(device),很多时候会让数据传输成为显式等待点。更常见的优化方式是:
- 在
DataLoader中开启pin_memory=True; - 在数据搬运时配合
non_blocking=True。
示例代码如下:
ini
train_loader = torch.utils.data.DataLoader(
train_set,
batch_size=32,
shuffle=True,
num_workers=8,
pin_memory=True,
)
inputs = data[0].to(device, non_blocking=True)
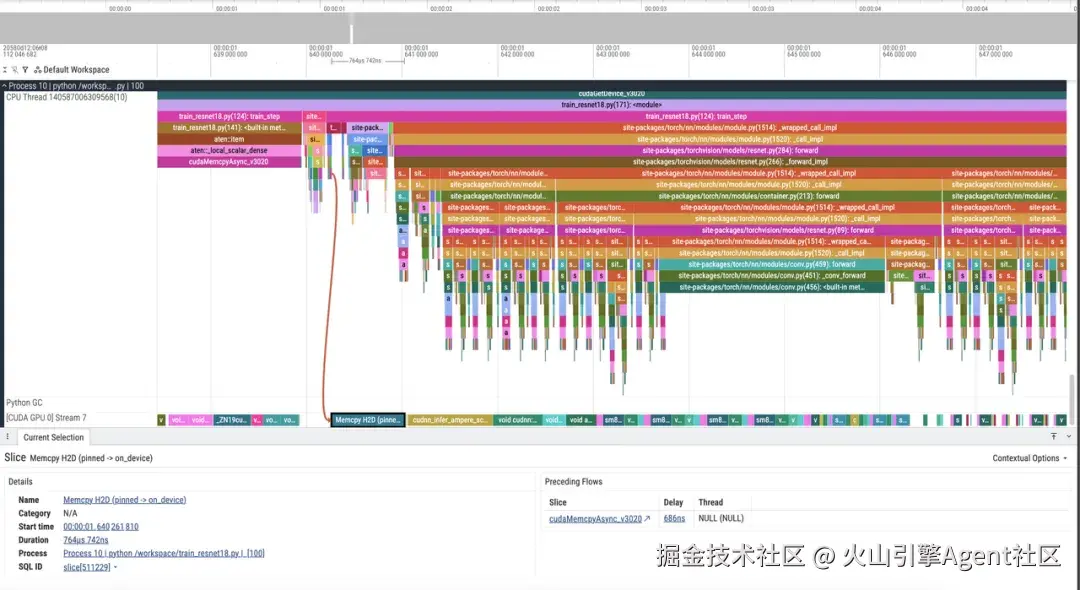
labels = data[1].to(device, non_blocking=True)在实测环境中,数据拷贝耗时从 2.2ms 降低到了:0.76ms。
这个优化看起来不像 AMP 那样"数字很大",但在真实业务里往往非常值得做。因为它通常改动小、风险低,而且对训练和推理都适用。
在时间线里,开启 pin_memory=True 后,Host 到 Device 的拷贝阶段更短,也更容易与后续计算形成更顺畅的衔接。
优化三:混合精度带来更直接的收益
第三步是开启混合精度计算(Automatic Mixed Precision (AMP)):
对于支持 Tensor Core 的 GPU,很多模型在训练和推理中都能通过混合精度获得明显收益。这里我们使用 autocast 来完成基础版本的 AMP 改造:
ini
with torch.cuda.amp.autocast(enabled=True, dtype=torch.float16):
outputs = model(inputs)
loss = criterion(outputs, labels)在这次测试里,我们关注的是 train_step 的平均执行时长。我们的实测结果是:
- AMP 关闭:29 ms
- AMP 开启:22.7 ms
这类优化在模型训练和推理体系中都很常见。很多团队在模型效果达标后,会进一步追求更高吞吐或更低成本,而混合精度通常是最值得优先验证的一步。
从时间线视角看,开启 AMP 后,单次 train_step 的执行段进一步收缩,计算密度更高。
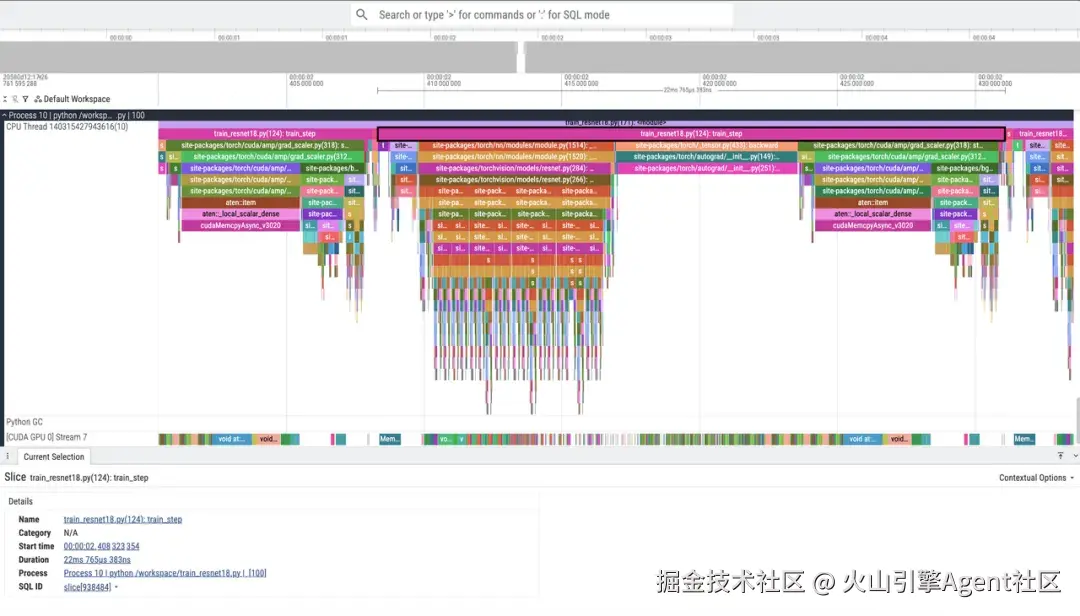
结果汇总:不是"玄学调优",而是可解释的收益
将这三个动作放在一起看,本次训练样例得到了比较清晰的收益:
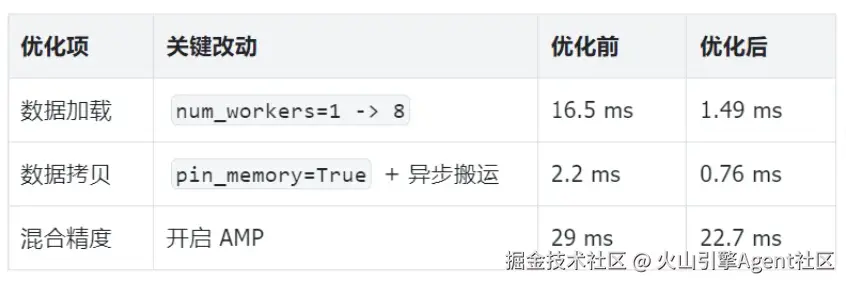
这组结果的价值,不只是展示训练模型更快了一点,而是说明:
- 瓶颈是可以被明确识别的,收益是可以被量化验证的;
- 优化动作和结果之间是有因果对应关系的。
只有当收益被量化之后,性能优化才更容易进入日常研发流程,而不是停留在少数专家的经验里。
小结
为什么这对训练和推理都重要
有人可能会说:你讲的是训练,跟我做推理服务有什么关系?
实际上,两者在工程问题上非常接近。一个大模型系统在生产环境中,常见的性能诉求无非这几类:
- 降低首 token 时延和整体响应时延;
- 提高单卡吞吐,降低 GPU 成本;
- 缩短模型迭代、微调和评测周期;
- 更快定位性能回退,减少排障时间。
这些问题的背后,都离不开 Profiling。举个例子:
- 推理慢,可能不是模型本身,而是预处理、拷贝或同步在阻塞;
- 训练慢,可能不是 GPU 算力不够,而是输入流水线没喂满;
- 成本高,可能不是必须加卡,而是现有资源利用率还没打够。
从这个角度看,AI Profiling 不是一个"锦上添花"的工具,而是 AI 基础设施走向工程化、规模化的必需能力。
还有哪些优化值得继续做
本文只展开三类最容易落地、也最容易看到收益的优化方向。如果团队有更高的性能要求,还可以进一步验证:
- 模型编译,例如 torch.compile 带来的框架调度开销下降;
- 减少不必要的同步,例如延后 loss.item() 的调用;
- 多机多卡训练中的通信与计算重叠;
- 推理场景中的批处理、算子融合与显存优化。
这些方向本文不展开,留给对深度优化更感兴趣的读者继续实践。
写在最后
今天企业做 AI,已经从"有没有模型能力"逐渐走向"有没有稳定的 AI 工程能力"。
在这个过程中,VKE AI Profiling 的意义并不只是提供一次性能采集,而是帮助团队建立一种更高效的工程方式:
- 用统一入口快速发现问题;
- 用真实时间线判断瓶颈位置;
- 用可量化结果验证优化价值。
对于训练场景如此,对于推理场景同样如此。随着大模型系统越来越多地进入真实业务,性能、成本和稳定性会越来越成为核心竞争力的一部分。
如果你的团队已经在推进模型训练优化,或者在做推理性能与成本治理,不妨从一次 5 秒钟的 Profiling 开始。很多时候,真正影响效率的瓶颈,并不在想象中,而在时间线里。